一种空气质量预报方法及系统
文献发布时间:2023-06-19 10:08:35
技术领域
本发明涉及空气质量检测领域,特别是涉及一种基于加权K-means划分区域的CNN-LSTM空气质量预报方法及系统。
背景技术
近年来,随着工业化与城市化进程的不断加快,空气污染问题也越发严重。世界卫生组织2019年发布的健康报告指出,空气污染位居十大健康威胁首位。空气污染会对公众的日常生活造成负面影响,严重的甚至会引发一系列健康问题。开展环境空气质量预报工作是保障及时妥善应对重污染天气的重要技术手段,对区域大气污染联合减排也具有指导意义。
现有的空气质量预报方法主要包括数值分析法与统计分析法。然而,数值预报法通常需要准确的输入数据和昂贵的计算资源来进行空气质量预报,而统计预报法对于非线性变化的污染物浓度预报准确性较低。在需要即时准确预报的情况下,使用现有的空气质量预报模型具有很大的挑战性。
目前通过人工智能、机器学习等方法实现环境空气质量预报已成为各国环保领域的研究热点和发展趋势。Liu等使用时空极值学习机算法预测北京市未来72小时PM2.5污染物浓度,但该算法准确率还有提升空间。深度学习方法是近年来新兴的一种机器学习算法,通过对大量数据的学习训练,发现其中的内在特征,从而提升分类或者预测的准确性。主流的深度学习方法包括卷积神经网络(Convolutional Neural Network,CNN)、循环神经网络(Recurrent NeuraNetwork,RNN)、长短期记忆网络(Long Short-Term Memory,LSTM)模型以及各个模型相结合的方法。已有国内外研究学者提出将深度学习模型应用于空气质量预报领域。目前主流的混合深度学习模型是由CNN和LSTM组成,可以提取出训练数据的时空特征。Huang等以北京市为案例,通过对过去24小时PM2.5浓度与气象数据进行训练分析,给出未来1小时的PM2.5浓度预报,但该方法并未考虑到站点间的空间相关性问题。
空气污染物浓度的变化会受到空间因素与气象因素的影响。为精准预报空气污染物浓度,模型通过输入其他监测站点的历史数据,从而分析污染物的空间演变特征。然而,输入空间相关性较强的监测站点数量难以确定。如果模型输入的监测站点数量较少,会导致模型分析污染物空间演变特征不够充分;反之,如果模型输入的监测站点数量过多,会增加对于空间相关度较低的站点的不必要分析,导致模型的运算量显著提升,影响污染物预报的准确性与时效性。此外,如何设计CNN-LSTM模型,从而对空气污染物进行空间与时序分析,仍是研究学者面临的难题。
针对上述问题,本文提出一种基于加权K-means划分区域的CNN-LSTM空气质量预报方法及系统。
发明内容
本发明的目的是提供一种空气质量预报方法及系统,解决监测范围内空间相关性较强的监测站点数量难以确定这一问题,基于多监测站点的空气质量历史数据与气象数据结合CNN-LSTM模型有效提高污染物浓度预报的精度。
为实现上述目的,本发明提供了如下方案:
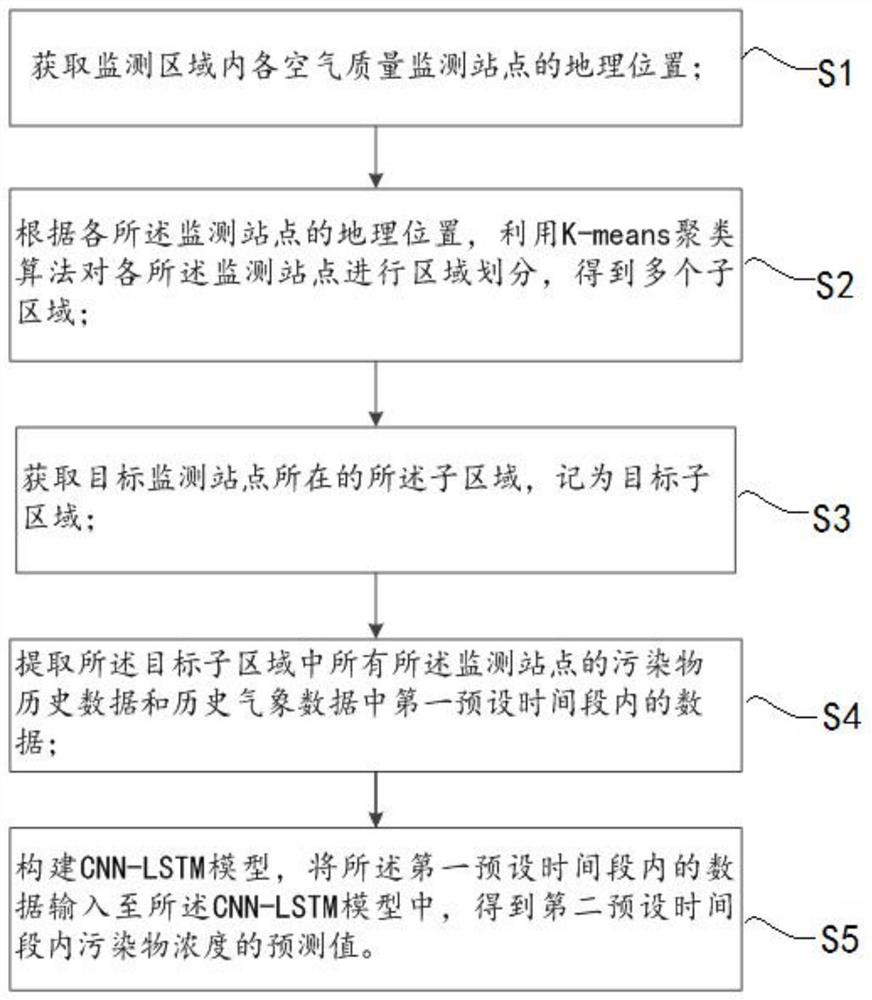
一种空气质量预报方法,包括:
获取监测区域内各空气质量监测站点的地理位置;
根据各所述监测站点的地理位置,利用K-means聚类算法对各所述监测站点进行区域划分,得到多个子区域;
获取目标监测站点所在的所述子区域,记为目标子区域;
提取所述目标子区域中所有所述监测站点的历史污染物数据和历史气象数据中第一预设时间段内的数据;
构建CNN-LSTM模型,将所述第一预设时间段内的数据输入至所述CNN-LSTM模型中,得到第二预设时间段内的污染物浓度的预测值。
本发明还提供了一种空气质量预报系统,包括:
监测站点区域划分模块,用于获取监测区域内各空气质量监测站点的的地理位置;根据各所述监测站点的地理位置,利用K-means聚类算法对各所述监测站点进行区域划分,得到多个子区域;
目标子区域获取模块,用于获取目标监测站点所在的所述子区域,记为目标子区域;
数据获取模块,用于提取所述目标子区域中所有所述监测站点的污染物历史数据和历史气象数据中第一预设时间段内的数据;
空气质量预报模块,用于构建CNN-LSTM模型,将所述第一预设时间段内的数据输入至所述CNN-LSTM模型中,得到第二预设时间段内的污染物浓度的预测值。
根据本发明提供的具体实施例,本发明公开了以下技术效果:
本发明使用加权K-means算法对各空气质量监测站点进行区域划分,得到目标监测站点所在区域内所有监测站点空气质量历史数据与气象数据,基于第一预设时间段内多站点空气质量历史数据与气象数据,利用CNN-LSTM模型分析得出第二预设时间段内污染物浓度演变的时空趋势,从而实现精准的空气质量预报。另外,加权K-means算法对各空气质量监测站点进行区域划分,能够准确的确定监测范围内与目标监测站点空间相关性较强的其他监测站点数量及位置,那么基于这些监测站点的空气质量历史数据与气象数据能够更真实的反映目标监测站点所在区域的空气质量,提高空气质量预报的准确性。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
图1为本发明实施例1提供的空气质量预报方法流程图;
图2为本发明实施例1提供的CNN-LSTM模型架构图;
图3为本发明实施例1提供的目标子区域中所有监测站点的历史污染物数据和历史气象数据不同的时间段的划分示意图;
图4为本发明实施例1提供的CNN模型结构图;
图5为本发明实施例1提供的LSTM模型结构图;
图6为本发明实施例1提供的空气质量预报框架图;
图7为本发明实施例1提供的SSE随聚类簇数k的变化曲线;
图8为本发明实施例1提供的SC随聚类簇数k的变化曲线;
图9为本发明实施例1提供的基于K-means的区域划分结果示意图;
图10为本发明实施例2提供的空气质量预报系统结构框图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明的目的是提供一种空气质量预报方法及系统,解决监测范围内空间相关性较强的监测站点数量难以确定这一问题,基于多监测站点的空气质量历史数据与气象数据结合CNN-LSTM模型有效提高污染物浓度预报的精度。
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本发明作进一步详细的说明。
实施例1
如图1所示,本实施例提供了一种空气质量预报方法,包括:
步骤S1:获取监测区域内各空气质量监测站点的地理位置;
步骤S2:根据各所述监测站点的地理位置,利用K-means聚类算法对各所述监测站点进行区域划分,得到多个子区域;
K-means聚类算法是一种常见的无监督机器学习方法,通过监测区域内各空气质量监测站点(样本)进行全局分析,划分成为不同的簇。由于每个簇内的样本特征相似,簇间样本特征相异,使用K-means聚类算法可以确定与目标监测站空间相关性较强的相邻站点。
步骤S2具体包括:
步骤S201:获取各所述监测站点的经纬度坐标,对各所述经纬度坐标进行归一化;
根据空气污染物监测站的地理位置划分区域,因此选择监测站的经度与纬度的归一化值作为K-means聚类的输入,从而进行空间划分。
假设有监测范围内包含m个监测站点样本,表示为
坐标归一化公式如下:
其中,y
步骤S202:设定聚类簇数为k;随机选取k个所述监测站点作为初始的聚类中心;初始的聚类中心表示为{μ
步骤S203:计算每个所述监测站点到每个所述聚类中心的欧式距离;
其中,欧式距离计算公式为:λ
步骤S204:将每个所述监测站点分配至所述欧式距离最小的所述聚类中心,得到k个聚类簇;
步骤S205:更新每个所述聚类簇中的聚类中心μ′
步骤S206:判断更新后的聚类中心与更新前的聚类中心是否相同,得到判断结果;
当判断结果为是时,得到的k个所述聚类簇为多个所述子区域;
当判断结果为否时,所述更新后的聚类中心替换所述更新前的聚类中心,返回步骤203,直至更新前后聚类中心不再变化。
在K-means聚类算法中最关键的部分是确定k值,评价聚类质量有效性的指标误差平方和(Sum ofthe Squared Errors,SSE),但仅根据误差平方和不能确定k值时,需要引入轮廓系数(Silhouette Coefficient,SC)作为另一项判定聚类质量有效性的指标,所以可以根据误差平方和与轮廓系数确定所述聚类簇数k的值。具体包括:
预设所述聚类簇数k的取值范围,设定循环步长,对所述取值范围内每个k值,利用K-means聚类算法对各所述监测站点进行区域划分,计算误差平方和与轮廓系数;
以所述聚类簇数k的取值范围为横坐标,误差平方和为纵坐标,绘制第一变化曲线(SSE随聚类簇数k的变化曲线);以所述聚类簇数k的取值范围为横坐标,轮廓系数为纵坐标,绘制第二变化曲线(SC随聚类簇数k的变化曲线);
当所述第一变化曲线中,选取曲线迅速下降转为平缓下降时对应的k值为最佳值。当SSE的值越接近0,说明分类效果越好。当k小于最佳的聚类个数时,随着k的增加每个簇的聚合度会明显增加,因此SSE会迅速下降;当k大于最佳的聚类数目时,每个聚类簇的聚合度增加速度会放缓,所以SSE下降会趋于平缓。因此,最佳聚类数为SSE迅速下降转为平缓下降所对应的k值。
但面对SSE下降趋势转变不明显的情况时,需要引入轮廓系数作为另一项判定聚类质量有效性的指标。即当所述第一变化曲线中,曲线下降趋势不明显时,选取所述第二变化曲线中,轮廓系数在[-1,1]之间,选取曲线中轮廓系数最大时对应的k值为最佳值。
计算误差平方和与轮廓系数的公式分别为:
其中,SSE为误差平方和,α
其中,SC为轮廓系数,a(i)为第i个所述监测站点到同一聚类簇中其他监测站点的平均距离,b(i)为第i个所述监测站点到距离最近簇C
步骤S3:获取目标监测站点所在的所述子区域,记为目标子区域;
步骤S4:提取所述目标子区域中所有所述监测站点的历史污染物数据和历史气象数据中第一预设时间段内的数据。
气象数据包括时均气压、气温、相对湿度、风速、风向以及降水量。
步骤S5:构建CNN-LSTM模型,将所述第一预设时间段内的数据输入至所述CNN-LSTM模型中,得到第二预设时间段内的污染物浓度的预测值。
需要说明的是,可以设置第一预设时间段为过去24小时,第二预设时间段为未来6小时,那么则利用过去24小时的历史污染物浓度与历史气象数据,预测未来6小时的污染物浓度。
如图2所示,CNN模型用于对历史污染物浓度数据进行分析,得出污染物的空间演变特征,LSTM模型用于将CNN模型提取得到的特征进行更深层次的时序特征提取,同时结合历史气象数据进行分析,最终经过全连接层计算,得出污染物的时空特征。
所以可得知步骤S5具体包括:
步骤S501:利用CNN模型对所述目标子区域中所有所述监测站点的所述历史污染物数据中的第一预设时间段内的数据进行数据分析,得出污染物的空间演变特征;
步骤S502:利用LSTM模型对所述污染物的空间演变特征进行更深层次的时序特征分析,同时对第一预设时间段内的所述历史气象数据进行分析,得出污染物的时空特征,即得到第二预设时间段内的污染物浓度的预测值。
CNN模型的结构如图4所示。假设输入数据为一个5×5的二维矩阵,横坐标代表监测站点,纵坐标代表污染物的历史浓度数据,共计25条输入数据。假设卷积层中卷积核的尺寸为3×3,经过一次卷积运算后,可以得到一个空间特征。假设卷积核移动的步长为1,则经过卷积核自左向右,自上而下共9次运算后,可以提取得到9个空间特征。最后这些空间特征经过全连接层的计算,得到一维特征,共计5个。需要说明的是此处CNN模型的具体介绍仅仅为了使本领域技术人员更清楚的理解CNN模型,对本发明不具有任何限定作用。
LSTM模型由多个子单元组成,一个LSTM单元的结构如图5所示:由遗忘门f
f
i
g
o
c
h
其中,W
要想利用CNN-LSTM模型实现污染物浓度的预测,必然需要对CNN-LSTM模型进行训练优化,那么步骤5中构建CNN-LSTM模型可具体包括:
步骤S511:提取所述目标子区域中所有所述监测站点的历史污染物数据和历史气象数据中第一时间段内的数据作为训练集;提取所述目标子区域中所有所述监测站点的历史污染物数据和历史气象数据中第二时间段内的数据作为验证集;提取所述目标子区域中所有所述监测站点的历史污染物数据和历史气象数据中第三时间段内的数据作为测试集;
步骤S512:利用所述训练集对CNN-LSTM模型进行训练,利用所述验证集对训练后的CNN-LSTM模型进行验证,利用所述测试集对验证后的CNN-LSTM模型进行测试,得到训练优化后的CNN-LSTM模型。
值得注意的是,本发明中,将所述目标子区域中所有所述监测站点的历史污染物数据和历史气象数据分为了不同的时间段,请参阅图3,其中,第一时间段、第二时间段、第三时间段的数据为模型训练数据、第一预设时间段的数据为用于未来污染物浓度预测的数据,每个时间段是各不相同的,并且,第一时间段、第二时间段、第三时间段的划分没有先后时间顺序。
为了判断构建的CNN-LSTM模型对空气质量的预报能力,可以利用均方根误差和平均绝对误差对CNN-LSTM模型的预报性能进行评价,具体包括:
根据如下公式计算均方根误差和平均绝对误差的值;
其中,RMSE为均方根误差,MAE为平均绝对误差,n为测试集样本数量,o
当RMSE与MAE的值越小时,说明CNN-LSTM模型预报与真实值越接近,预报性能越好。
本实施例中,基于K-means划分区域的CNN-LSTM空气质量预报框架如图6所示,主要包括区域划分和模型预报两个部分。在区域划分步骤中,使用K-means聚类算法对各空气质量监测站点进行区域划分,并在模型预报部分,选用目标站点所在区域内所有站点的污染物历史数据,结合气象数据作为CNN-LSTM模型的输入,从而给出目标站点的污染物浓度值预报结果。
为了能够使本领域技术人员更好的理解本方案,选取南通市作为研究案例城市,研究目标监测站点为虹桥站点,该实验方案可以拓展到其他更大的预测范围。实验分为两个部分。第一部分为基于K-means的区域划分,对南通市各空气质量监测站点进行空间聚类分析以划分区域;第二部分为基于CNN-LSTM模型的污染物浓度预报,使用CNN-LSTM模型分别进行基于单站点与多站点污染物历史数据的性能评估。
基于加权K-means的区域划分:
使用加权K-means方法对南通市19个空气质量监测点位进行空间上的区域划分。将各监测站点经度与纬度进行归一化处理后,作为加权K-means聚类算法的输入属性,加权因子根据站点所属的区域,居住区,商业教育区以及工业区。
在使用K-means进行区域划分前,首先需要确定聚类簇数(聚类分类数)k。为此本文选用误差平方和SSE与轮廓系数两项聚类评价指标对聚类质量有效性进行判定,从而选取最佳的簇数k。
当选择不同k值时,SSE的变化曲线如图7所示,k的取值范围为[1,12]。从图7中可以看出,当k小于4时,SSE下降趋势明显,当k大于4时,SSE下降趋势放缓,但未能与k小于4时SSE曲线的下降趋势表现出明显变化,需要引入轮廓系数SC作为另一项判定聚类质量有效性的指标。
图8为SC随聚类分类数k的变化曲线,k的取值范围为[2,12]。由图8可知,当k取值为8时,SC取得最大值,但此时会出现一个分类簇内只有一个样本的情况。为考虑到不同空气质量监测站点之间的影响,需要保证每个分类区域内至少有两个站点,因此实验最终选择聚类分类数k为7,图9为基于K-means的区域划分结果,表1为南通市各空气质量监测站点所对应的区域。本文选择南通市崇川区虹桥空气质量监测站点作为研究站点,经K-means划分区域后归为区域2,因此在验证CNN-LSTM模型性能的实验中,选用区域2内所有站点的污染物历史数据作为CNN模型的输入,共计5个站点:城中子站,虹桥,南郊,星湖花园,紫琅学院。
表1各空气质量监测站点所对应的区域
基于多站点的CNN-LSTM污染物浓度预报:
选择南通市崇川区虹桥空气质量监测站点作为研究目标。由上述分类结果可得,在多站点模型中,污染物浓度数据选择城中子站,虹桥,南郊,星湖花园,紫琅学院共计5个站点2017年至2019年PM2.5浓度历史时均数据。在单站点模型中,污染物浓度数据仅选择虹桥一个站点历史数据。气象数据包括时均气压、气温、相对湿度、风速、风向以及降水量。为保证数据整齐便于CNN-LSTM模型分析,当出现某一时刻某站点污染物浓度数值缺失情况时,则删除其他站点与气象数据同时刻的数值,最终得到时均值共计25263条。
本实施例选择2017年1月1日至2019年11月30日的数据作为自训练数据,选择2019年12月1日至2019年12月31日数据作为预报测试数据,针对虹桥空气质量监测站点时均PM2.5浓度进行预报。所有模型的输入为过去24小时的PM2.5污染物浓度与气象数据,预报结果为未来6小时的PM2.5污染物浓度。将时间序列数据转化为模型训练样本后,最终得到训练样本共24502个,测试样本共732个。实验中模型超参数的设置如表2所示:
表2实验中模型超参数的设置
表3基于不同模型的时均值预报结果对比
表3为基于不同模型的时均值预报结果对比,从表3中可以看出,在基于单站点的预报实验中CNN-LSTM模型预报结果的均方根误差RMSE与平均绝对误差MAE均略低于LSTM模型,尽管CNN模型无法从中提取出空间方面的演变特征,CNN模型依然能从单站点的污染物历史浓度数据中提取出较为浅层的时序特征,从而提升预报性能。在采用多站点数据进行训练后,模型的预报性能得到了进一步的提升。各模型时均预报结果与实测值的对比,所有模型预报值均与实际值的趋势保持一致,但预报结果整体上低于实测值,此外对于出现污染物浓度骤增、骤减情况时,CNN-LSTM模型给出的预报结果均有一定的滞后,这是深度学习模型训练样本特征长度固定所导致出现的情况。由于深度学习模型是通过对过去一段时间的污染物浓度值进行计算,从而给出未来污染物浓度。而且深度学习模型具有一定的泛化性,能够同时对污染物浓度较高或较低的情况给出预报结果,因此当模型输入为一段数值变化较小的污染物浓度时,给出的结果往往较为精确;但遇到污染物浓度骤增、骤减情况时,模型仍然误以为未来污染物浓度变化不大,给出的预报结果与实际有较大误差。尽管基于多站点的CNN-LSTM模型会存在一定的预报滞后性,但面对重污染天气时给出的预报数值,比基于单站点的CNN-LSTM模型更加接近真实值。在误差指标方面,与单站点CNN-LSTM模型相比,RMSE下降了5.2%,MAE下降了6.7%。因此,加入加权K-means划分区域的多站点数据后,CNN-LSTM模型能有效提高污染物浓度的预报精度。
使用加权K-means对各空气质量监测站点进行区域划分,并设计基于多站点的CNN-LSTM模型,结合多站点空气质量历史数据与气象数据,以分析污染物浓度演变的时空趋势,从而给出精准的空气质量预报。通过对南通市各监测站点的区域划分,数据训练与预测实验,结果表明,基于加权K-means划分区域的CNN-LSTM空气质量预报方法在PM2.5浓度预报精度上优于传统单站点模型。本文目前对南通市各监测站点进行区域划分,未来可以加入其他城市站点数据,使用K-means进行更大区域的划分,使得CNN-LSTM模型可以更好地分析污染物的时空演变趋势,从而更加准确有效地进行环境空气质量预报。
实施例2
如图10所示,本实施例提供了一种空气质量预报系统,包括:
监测站点区域划分模块M1,用于获取监测区域内各空气质量监测站点的的地理位置;根据各所述监测站点的地理位置,利用K-means聚类算法对各所述监测站点进行区域划分,得到多个子区域;
所述监测站点区域划分模块M1包括:
监测站点坐标获取单元,用于获取各所述监测站点的经纬度坐标,对各所述经纬度坐标进行归一化;
初始聚类中心确定单元,用于设定聚类簇数为k;随机选取k个所述监测站点作为初始的聚类中心;
欧式距离计算单元,用于计算每个所述监测站点到每个所述聚类中心的欧式距离;
监测站点分配单元,用于将每个所述监测站点分配至所述欧式距离最小的所述聚类中心,得到k个聚类簇;
聚类中心更新单元,用于更新每个所述聚类簇中的聚类中心μ′
判断单元,用于判断更新后的聚类中心与更新前的聚类中心是否相同,得到判断结果;
当判断结果为是时,得到的k个所述聚类簇为多个所述子区域;
当判断结果为否时,所述更新后的聚类中心替换所述更新前的聚类中心,返回步骤“计算每个所述监测站点到每个所述聚类中心的欧式距离”,直至更新前后所述聚类中心不再变化。
目标子区域获取模块M2,用于获取目标监测站点所在的所述子区域,记为目标子区域;
数据获取模块M3,用于提取所述目标子区域中所有所述监测站点的污染物历史数据和历史气象数据中第一预设时间段内的数据;
空气质量预报模块M4,用于构建CNN-LSTM模型,将所述第一预设时间段内的数据输入至所述CNN-LSTM模型中,得到第二预设时间段内的污染物浓度的预测值。
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例公开的系统而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。
本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处。综上所述,本说明书内容不应理解为对本发明的限制。
- 一种空气质量预报方法及系统
- 一种预驱动中长期空气质量预报系统和方法