基于渐进式未知域扩展的单域泛化方法
文献发布时间:2023-06-19 12:22:51
技术领域
本发明涉及计算机视觉领域,尤其涉及一种基于图像数据增强的分布外样本分类识别方法。
背景技术
在当前海量带标签数据集(比如图像分类数据集Imagenet)的支持下,深度学习在图像分类领域取得了巨大突破,然而对海量样本的依赖也限制了深度学习技术在有限样本数据集分类任务上的进一步突破,于是数据增强技术被提出以提升有限样本数据的利用率。传统的数据增强方法主要包括旋转、平移、随机颜色、Mixup等手段来扩增样本,可以在一定程度上对模型进行正则,减小过拟合风险。当前的单域泛化技术主要是应用数据增强方法,通过对源域样本进行数据增强合成接近目标域的样本。然而此类技术通常需要对目标域的类型有明确限定,且需要对数据增强的类型和幅度进行仔细选择,以确定合适的超参数。
当前的数据增强方法往往是经验式的,缺乏理论指导,主要有如下两方面的缺点:
当前数据增强方法的增强空间有限,仅限于已经被提出的有限的几个类别,比如随机旋转、随机crop、随机颜色等等。无法自动合成任意类别的图像。
当前数据增强方法往往具有很大的超参数搜索空间,以google在AutoAugment中的研究为例,常用的数据增强参数搜索空间大小为2.9*10
发明内容
本发明针对上述问题,根据本发明的第一方面,提出一种基于渐进式未知域扩展的单域泛化网络,包括样本生成器G、分类模型M以及循环生成器Gcyc,其中样本生成器G用于将样本泛化到多个领域,分类模型M用于对输入分类,并用于验证样本生成器G生成样本的有效性与安全性,循环生成器Gcyc用于验证样本生成器G生成样本的安全性,
其中经过样本生成器G泛化后的样本作为分类模型M的训练样本对分类模型M进行训练,以及作为循环生成器Gcyc的输入,由循环生成器Gcyc进行验证。
在本发明的一个实施例中,其中,样本生成器G与循环生成器Gcyc具有相同的结构,分别包括编码器G
在本发明的一个实施例中,其中,分类模型M包括分类神经网络和投影头P,其中分类神经网络包括特征提取器F和分类头C。
在本发明的一个实施例中,其中所述分类神经网络为CNN。
根据本发明的第二方面,提出一种用于本发明的基于渐进式未知域扩展的单域泛化网络的训练方法,所述方法包括包含K个步骤,其中前K-1个步骤分别对K-1个分布外领域训练样本生成器,其中第k步骤包括对第k步领域训练样本生成器G
在本发明的一个实施例中,其中在第k步训练中还包括,将分类模型M的权重参数复制到M
在本发明的一个实施例中,其中,每取到一个批次的样本后,先训练分类模型M,将分类模型M的权重参数复制到M
在本发明的一个实施例中,其中,采用以下损失函数
对分类模型M进行训练,其中
用于最小化输出类别与真实类别的误差,其中F、C分别表示分类模型M中的特征提取器和分类头,
以及
用于使样本和其变体的由F输出的特征在特征空间中尽可能接近来对分类模型M进行训练,其中
在本发明的一个实施例中,其中在第k步训练中还包括通过安全性约束与有效性约束对样本生成器进行训练,其中,
所述安全性约束包括以样本生成器G合成的样本应该能够被分类模型M正确分类,其公式如下
以及样本生成器G合成的样本能够通过循环生成器Gcyc恢复出原始样本为训练目标实现,其公式如下
其中F,C表示分类模型M的特征提取器和分类头,n为随机信号,x为输入样本,y为真实类别;
所述有效性约束为以最小化样本生成器G合成样本的信息与原始样本的互信息熵为训练目标实现,其公式如下,
其中,
根据本发明的第三方面,提出一种计算机可读存储介质,其中存储有一个或者多个计算机程序,所述计算机程序在被处理器执行时用于实现本发明的基于渐进式未知域扩展的单域泛化网络的训练方法。
根据本发明的第四方面,提出一种计算系统,包括:存储装置、以及一个或者多个处理器;其中,所述存储装置用于存储一个或者多个计算机程序,所述计算机程序在被所述处理器执行时用于实现本发明的基于渐进式未知域扩展的单域泛化网络的训练方法。
本发明提出一种针对单域训练模型在未知领域泛化的数据增强方法,针对容易过拟合的样本属性,均匀的合成不同属性值的样本,使得增强数据集近似成为无偏数据集。本发明在分布外样本分类、分布外图像分割任务中有效的提升了分类正确率,并且可以推广至其他有限有偏样本的分类任务中。
附图说明
此处的附图被并入说明书中并构成本说明书的一部分,示出了符合本发明的实施例,并与说明书一起用于解释本发明的原理。显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。在附图中:
图1示出了PDEN示意图;
图2(a)示出了样本生成器示意图;
图2(b)示出了循环生成器示意图;
图3示出了对AdaIN的改进;
图4示出了分类模型M的结构;
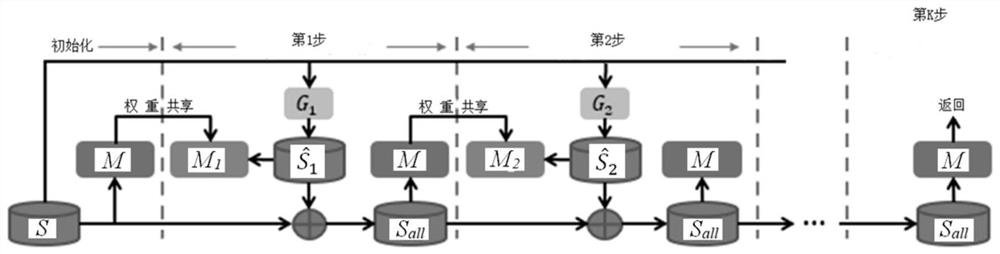
图5示出了本发明的整体流程图;
图6示出了第k步分布外领域生成器的训练过程示意图。
具体实施方式
本发明发现现有主流的深度分类模型的性能都依赖于海量无偏的训练数据,当现实场景无法提供大量无偏的训练样本时,深度学习容易过拟合到分类无关的有偏属性上。现有的数据增强技术并不能解决由于数据集有偏导致模型过拟合的问题。
针对上述问题,发明人进行了研究,提出了一种基于渐进式未知域扩展的单域泛化方法的PDEN(Progressive Domain Expansion Network)。本发明的PDEN包括样本生成器G、分类模型M、循环生成器Gcyc,其中样本生成器G用于将样本泛化到多个领域,分类模型M用于对输入分类,并用于验证样本生成器G生成样本的有效性与安全性,循环生成器Gcyc用于验证样本生成器G生成样本的安全性,如图1所示。样本生成器G在本发明的以下描述中也称为分布外领域生成器。
如图2(a)所示,分布外领域生成器包括编码器G
G(x,n)=G
作为参照,现有的AdaIN用于风格转换,其公式为
用于将风格图片w的均值与标准差迁移到内容图片z上,σ和μ分别是均值和标准差,而本发明中将n信号经L
Gcyc表示样本重建器,Gcyc的结构和样本生成器G相同,但它们的输入有一些区别,其中样本生成器G的输入中包含随机变量n,Gcyc中,这个随机变量被替换为恒定的0向量,如图2(b)所示。
在一个实施例中,分类模型M包括分类神经网络和投影头P,其中分类神经网络包括特征提取器F和分类头C,如图4所示。根据本发明的一个实施例,分类模型M可采用卷积神经网络CNN加投影头P的结构,其中CNN包括特征提取器F和分类头C。
根据本发明的一个实施例,为了保证数据质量,采用了渐进式未知领域样本合成的策略,图5示出了该实施例的整体流程图。在该实施例中,会针对每一个分布外领域分别训练其样本生成器,图5所示的流程中,包含了K个步骤,例如31个步骤。其中前K-1个步骤中分别对K-1个分布外领域训练样本生成器,第k步骤中对第k个领域训练样本生成器G
(1)初始化,令S
(2)在第k步中,k=1,2,3,…K-1,将分类模型M的权重参数复制到第k步分类模型M
(3)在第K步中,将K-1步中训练后的分类模型M输出。
其中在前K-1步的每一步中,需要对多个批次(batch)的样本进行训练,例如几百个批次。如图6所示,在前K-1步的第k步中,k=1,2,…,K-2,K-1,分类模型与样本生成器联合训练,每取到一个批次的样本后,先训练分类模型M,再将分类模型M的权重参数复制到第k步分类模型M
对M的训练所采用的损失函数首先要考虑通过最小化输出类别与真实类别的误差来对M进行训练,如以下公式3所示:
其中F、C分别表示分类模型M中的特征提取器和分类头,
其次,还要使样本和其变体的由F输出的特征在特征空间中尽可能接近,如以下公式(4)所示:
其中
将公式(3)与(4)相加,就是分类模型M的最小损失函数,如以下公式(5)所示。
分布外领域生成器G负责合成“安全”、“有效”的未知领域样本,分类模型学习不同领域样本中的领域不变特征表示。
为了确保分布外领域生成器G能够合成“安全”、“有效”的未知领域样本,根据本发明的一个实施例,提出安全性约束和有效性约束的概念,其分别指如下两个约束条件:
安全性约束:该约束主要目标是使得G合成的样本不会对分类模型产生负面影响,包括2个部分。第1部分,G合成的样本应该能够被M正确分类;第2部分G合成的样本能够通过循环生成器Gcyc恢复出原始样本。
有效性约束:该约束主要目标是使得G合成的样本相对于原始训练集的样本,能够带来信息增益。通过G和M的联合优化,最小化G合成样本的信息与原始样本的互信息熵。即通过以“最小化G合成样本的信息与原始样本的互信息熵”为训练目标实现。这里通过对抗训练,让合成样本和原始样本的互信息最小,这意味着合成样本中会产生更多样的内容,从而提升数据的多样性,多样性的训练数据则会提升模型的分布外泛化性。
在一个实施例中,上述两个约束条件通过深度模型的损失函数来实现,以下将详细介绍。
分布外领域生成器的优化目标(即损失函数)如下公式(6)、(7)、(8)所示,其中F,C表示M的特征提取器和分类头,P表示M中的投影头(包括一个全连接层),y为真实类别,在公式(6)、(7)、(8)中G代表样本生成器G
本发明针对分类识别中的单域泛化任务,提出了一种针对单领域数据集的渐进式领域扩展方法(PDEN),并在MNIST、CIFAR、SYNTHIA等单域泛化任务的公开数据集上进行了测试,同时与目前深度学习中主流的数据增强方法进行比较。所述主流的数据增强方法包括:经验风险最小化ERM:其为仅使用交叉熵损失进行训练的基线方法;CCSA:其将来自不同领域的相同种类的样本对齐,以得到鲁棒的特征空间进行领域生成;d-SNE:其最小化同一类样本对之间的最大距离,并最大化不同类样本对之间的最小距离;GUD:其提出了一种对抗性的数据增强方法来合成更多的硬样本,提高了分类器的鲁棒性;MADA:其最小化语义空间并最大化像素空间的距离,以生成更有效的样本;JiGen:其提出了一种多任务学习方法,其将目标识别任务与拼图分类任务相结合,以提高模型的跨域泛化能力;AutoAugment(AA):其提出了一种针对特定数据集的自动搜索改进的数据扩充策略的方法;RandAugment(RA):其基于AA,具有更好的数据扩充策略,大大减少了策略空间。
结果如下表所示:本发明的方法(PDEN)在性能上超越了深度学习中主流的数据增强方法。其中,表1表示在Digit单域泛化数据集上的性能,表2表示在CIFAR10单域泛化数据集上的性能,表3表示在SYNTHIA数据集上的性能。
表1 Digit单域泛化数据集上的性能对比
表2 CIFAR单域泛化数据集上的性能对比
表3 SYNTHIA数据集上的性能对比
为使本领域任何普通技术人员能够实现或者使用本公开内容,上面围绕本公开内容进行了描述。对于本领域普通技术人员来说,对本公开内容进行各种修改是显而易见的,并且,本文定义的通用原理也可以在不脱离本公开内容的精神或保护范围的基础上适用于其它变型。此外,除非另外说明,否则任何方面和/或实施例的所有部分或一部分可以与任何其它方面和/或实施例的所有部分或一部分一起使用。因此,本公开内容并不限于本文所描述的例子和设计方案,而是与本文公开的原理和新颖性特征的最广范围相一致。
- 基于渐进式未知域扩展的单域泛化方法
- 一种基于域自适应学习和域泛化的人脸欺骗检测方法