一种基于关键词搜索时间序列的传染病疫情预测与监控系统、方法及其应用
文献发布时间:2023-06-19 12:24:27
技术领域
本发明涉及疫情预测技术领域,特别是涉及一种基于关键词搜索时间序列的传染病疫情预测与监控系统、方法及其应用。
背景技术
传染病疫情的扩散是由千千万万个传播者决定的,而公开数据具有一定滞后性:一来通患者具有明显症状然后才去医院就诊,从就诊到确诊也需要一定时间,二来,确诊后数据的收集到公开也需要时间,除此之外,个别机构还可能存在瞒报问题,由此造成对疫情处理的滞后性,影响疫情规模的有效估计和及时控制。
发明内容
本发明的目的是针对现有技术中存在的传染病疫情数据获取滞后的问题,而提供一种基于关键词搜索时间序列的传染病疫情预测与监控系统。
本发明的另一个目的是提供所述预测与监控系统的预测监控方法。
本发明的另一个目的是提供所述预测监控方法在新冠肺炎预测中的应用。
为实现本发明的目的所采用的技术方案是:
一种基于关键词搜索时间序列的传染病疫情预测与监控系统,包括搜索关键词筛选模块、搜索热度指数网络请求模块和机器学习预测模块,其中:
所述搜索关键词筛选模块用于生成与传染病疫情相关的相关关键词;
所述搜索热度指数网络请求模块用于通过搜索引擎接口获取所述相关关键词对应的搜索热度;
所述机器学习预测模块基于历史数据训练回归模型,并基于新的数据进行预测。
在上述技术方案中,所述机器学习预测模块部署于云端。
在上述技术方案中,所述机器学习预测模块利用python flask框架进行服务器后端部署,搭建http服务。
在上述技术方案中,服务器端开放端口处理互联网传输的请求,互联网的请求通过 http协议完成。
本发明的另一方面,所述传染病疫情预测与监控系统的预测监控方法,包括机器学习预测模块训练阶段和机器学习预测模块预测阶段,其中:所述机器学习预测模块预测阶段包括以下步骤:
步骤S1,在所述搜索关键词筛选模块中,选取与传染病发作症状相关联的关键词作为相关关键词,组成关键词表;
步骤S2,在搜索热度指数网络请求模块中,输入步骤S1中的所述相关关键词,通过搜索引擎接口获取所述相关关键词在实验时间段内对应的搜索热度指数;
步骤S3,数据预处理:把搜索热度指数均值低于热度阈值的相关关键词过滤掉,计算所述关键词与其搜索热度指数之间的相关系数(皮尔逊相关系数),并将相关系数低于相关系数阈值的相关关键词过滤掉;
步骤S4,将步骤S3预处理后的所述相关关键词输入经过训练的所述机器学习预测模块,进行预测,产出预测结果,获得预测日的新增病例数量。
在上述技术方案中,所述步骤S3中的热度阈值为500,相关系数阈值为0.4-0.6。
在上述技术方案中,所述机器学习预测模块训练阶段包括以下步骤。
步骤1,在所述搜索关键词筛选模块中,选取与传染病发作症状相关联的关键词作为相关关键词,组成关键词表;
步骤2,在搜索热度指数网络请求模块中,输入步骤1中的所述相关关键词,通过搜索引擎接口获取所述相关关键词在实验时间段内对应的搜索热度指数;
步骤3,数据预处理:把搜索热度指数均值低于热度阈值的相关关键词过滤掉,计算所述关键词与其搜索热度指数之间的相关系数(皮尔逊相关系数),并将相关系数低于相关系数阈值的相关关键词过滤掉;
步骤4,获取实验时间段内,每日新增病例数量(包括新增确诊人数和疑似人数);
步骤5,建立训练样本:假设第T日的新增传染病确诊人数与前m日的相关关键词的搜索量存在关联关系,即每个样本的特征包含T-m日到T-1日预处理后的每个相关关键词的检索量,设每日有n个相关关键词,另外增加T-m日到T-1日每日新增病例为特征,每个样本包含m(n+1)个特征,每个样本的目标值为第T日的新增病例数量,通过滑动时间窗的方法在目标时间段获得多组样本,所述时间窗的窗长为m天,样本数量=总时间长度-时间窗长+1,每个样本的目标值为第T日的真实新增病例数量,如果使用模型预测未来第N天的新增病例数量,则每个样本的目标值为第T+N日的真实新增病例数量;
基于训练样本数据建立回归模型,模型采用lasso回归模型,求解回归系数的目标函数中使用的惩罚函数是L1范数:
y=θX+e
y为预测第N天的新增病例数量,X为输入的特征向量(所有特征的合集),e为预测误差,通过训练样本数据训练θ向量,使lasso损失函数最小;Lasso回归损失函数表达式:
L1=argmin||y-θX||+λ||θ||
在上述技术方案中,λ为为0.1或自定义数值。
在上述技术方案中,θ向量的计算采用坐标轴下降法:
步骤(1)把θ向量随机取一个初值
步骤(2)第k轮的迭代,
步骤(3)检查θ向量和θ向量在各个维度上的变化情况,如果在所有维度上变化都小于 0.0001,那么即为最终结果,否则继续步骤(2)中第k+1轮的迭代。
在上述技术方案中,所述步骤3中的热度阈值为400-600,相关系数阈值为0.4-0.6。
本发明的另一方面,还包括所述预测监控方法在流感或新冠肺炎预测中的应用。
与现有技术相比,本发明的有益效果是:
1.相关搜索关键词的搜索热度可以一定程度反映各地居民的健康状况,并且这些数据基本是可以实时统计的,再通过机器学习技术基于这些实时的搜索信息预测出疫情状况,有助于有关部分及时的制定相关决策。
2.本发明可使用省份或城市粒度的训练和测试数据进行训练和预测,监控各个省市的疫情情况,或提前预测新型肺炎等传染疾病将在哪些省份存在爆发风险。比如图2所示,在其他信息量不足的情况下提前预判某城市病毒扩散的形式。
3.可以通过机器学习技术基于关键搜索词实时的搜索信息预测出新型肺炎等疾病的传播情况,包括传播加速或收敛,解决了相关指标统计滞后的问题,可以及时量化和监控各地当前的疾病传播情况,并做出预警和有效决策。
附图说明
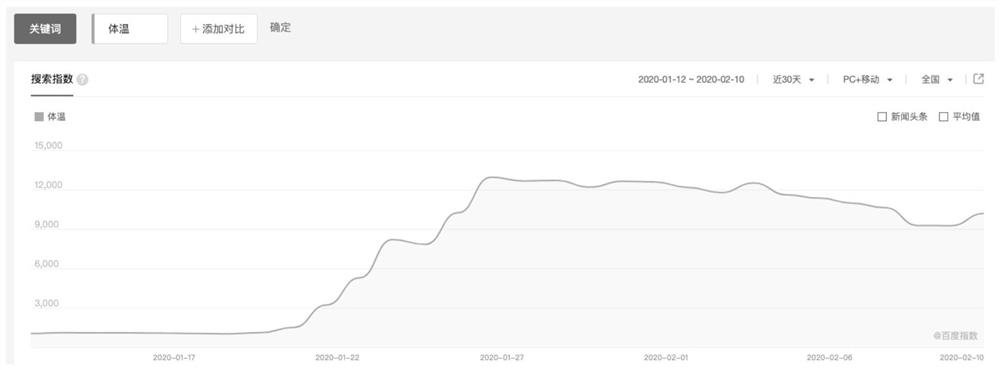
图1是关键词“体温”搜索热度指数随新型肺炎爆发情况;
图2是某地区关键词“体温”搜索热度指数随疫情爆发情况,曲线显示1月22日左右疫情已经爆发。
具体实施方式
以下结合具体实施例对本发明作进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
实施例1
一种基于关键词搜索时间序列的传染病疫情预测与监控系统,包括搜索关键词筛选模块、搜索热度指数网络请求模块和机器学习预测模块,其中:
所述搜索关键词筛选模块用于生成与传染病疫情相关的相关关键词;
所述搜索热度指数网络请求模块用于通过搜索引擎接口获取所述相关关键词对应的搜索热度;
所述机器学习预测模块基于历史数据训练回归模型,并基于新的数据进行预测。
所述机器学习预测模块部署于云端。利用python flask框架进行服务器后端部署,搭建http服务。云端系统可以选用阿里云。服务器端开放某一端口如8080,处理互联网传输的请求。互联网的请求通过http协议完成,搜索关键词可以包含在url参数中,如
实施例2
以新冠肺炎为例,对基于关键词搜索时间序列的传染病疫情预测与监控系统的预测监控方法,进行详细说明。
所述预测监控方法包括机器学习预测模块训练阶段和机器学习预测模块预测阶段,其中:所述机器学习预测模块训练阶段包括以下步骤:
所述搜索关键词筛选模块选取与新型肺炎发作症状相关联的若干关键词组成关键词表,包括
步骤1,在所述搜索关键词筛选模块中,选取与传染病发作症状相关联的关键词作为相关关键词,相关关键词包括“发烧”,“发热”,“乏力”,“咳嗽”,“体温”等。
步骤2,在搜索热度指数网络请求模块中,输入步骤1中的所述相关关键词,通过搜索引擎接口获取所述相关关键词在实验时间段内对应的搜索热度指数;选取一段时间段为实验时间段,如2020年1月20日到2020年3月20日,相关搜索引擎如百度。
步骤3,数据预处理:把搜索热度指数均值低于热度阈值(选定为500)的相关关键词过滤掉,计算所述关键词与其搜索热度指数之间的相关系数(皮尔逊相关系数),并将相关系数低于相关系数阈值(选定为0.5)的相关关键词过滤掉;
步骤4,通过国内权威渠道的公开报道获取实验时间段内,每日新增病例数量(包括新增确诊人数和疑似人数);
步骤5,建立训练样本:假设第T日的新增传染病确诊人数与前m日的相关关键词的搜索量存在关联关系,即每个样本的特征包含T-m日到T-1日预处理后的每个相关关键词的检索量,设每日有n个相关关键词,另外增加T-m日到T-1日每日新增病例为特征,每个样本包含m(n+1)个特征,每个样本的目标值为第T日的新增病例数量,通过滑动时间窗的方法在目标时间段获得多组样本,所述时间窗的窗长为m天,样本数量=总时间长度-时间窗长 +1,每个样本的目标值为第T日的真实新增病例数量,如果使用模型预测未来第N天的新增病例数量,则每个样本的目标值为第T+N日的真实新增病例数量;
基于训练样本数据建立回归模型,模型采用lasso回归模型,求解回归系数的目标函数中使用的惩罚函数是L1范数:
y=θX+e
y为预测第N天的新增病例数量,X为输入的特征向量(所有特征的合集),e为预测误差,通过训练样本数据训练θ向量,使lasso损失函数最小;Lasso回归损失函数表达式:
L1=argmin||y-θX||+λ||θ||
Lasso的基本思想是在回归系数的绝对值之和小于一个常数的约束条件下,使残差1范数最小化,从而能够产生符合条件的回归系数,得到可以解释的模型。Lasso的复杂程度由λ来控制,λ越大对变量较多的线性模型的惩罚力度就越大,从而最终获得一个变量较少的模型。λ为0.1或自定义数值。
由于L1正则化项用的是绝对值之和,导致损失函数有不可导的点。也就是说,梯度下降法等优化算法会失效。这里θ向量的计算采用坐标轴下降法:
步骤(1)把θ向量随机取一个初值
步骤(2)第k轮的迭代,
步骤(3)检查θ向量和θ向量在各个维度上的变化情况,如果在所有维度上变化都小于 0.0001,那么即为最终结果,否则继续步骤(2)中第k+1轮的迭代。
所述机器学习预测模块训练阶段预测过程如下,基于最新10天的搜索关键词数据及其他特征,经过和训练样本构造过程相同的预处理和特征提取过程,输入到机器学习模型,产出预测结果。
实施例3
实施例2的方法同样适用于其他传染类的疾病,比如流感等,搜索关键词可替换为流涕,发热等。其他过程一致。
以上所述仅是本发明的优选实施方式,应当指出的是,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 一种基于关键词搜索时间序列的传染病疫情预测与监控系统、方法及其应用
- 基于非线性、变系数预测模型的传染病疫情预测分析方法