一种矿井涌水量预测方法和装置
文献发布时间:2023-06-19 19:30:30
技术领域
本发明属于煤矿水害防治技术领域,尤其涉及一种矿井涌水量预测方法和装置。
背景技术
矿井涌水是指突然有大量的水从含水层、采空区或其他强含水层地质体通过导水通道涌入矿井的事件。每当矿井的涌水量超出排水系统的承受能力时,就会导致水害事故的发生。矿井涌水量的大小,不仅直接关系到矿井开采方案和排水设计的合理性,更影响到煤矿是否能安全生产,因此,对涌水量进行准确的预测对矿山的安全开采具有重要意义。
目前常用的矿井涌水量预测方法包含两大类:动力学方法和统计学方法。其中动力学方法包括解析法、数值法、水均衡法等,统计学方法包括时间序列分析法、水文地质比拟法、模糊数学法、灰色系统理论等。然而这些传统的方法存在数据实时更新慢、计算效率低、建模困难、所需参数较多且难以获取、适用条件限制大等缺点。
发明内容
本发明要解决的技术问题是,本发明提供一种矿井涌水量预测方法和装置,结合多源数据,如含水层水位数据、日开采推进距离、过去涌水量数据,对未来矿井涌水量数据进行准确预测,本发明可为煤矿的安全开采提供有力的技术保障。
为实现上述目的,本发明采用如下的技术方案:
一种矿井涌水量预测方法,包括以下步骤:
步骤S1、获取历史矿井涌水数据;
步骤S2、根据所述历史矿井涌水数据作为训练集对LSTM预测模型进行训练;
步骤S3、计算训练好的LSTM预测模型的最优超参数;
步骤S4、通过最优超参数对训练好的LSTM预测模型进行更新迭代,获得最终LSTM预测模型;
步骤S5、通过所述最终LSTM预测模型对预测未来某一时刻的矿井涌水量进行预测。
作为优选,历史矿井涌水数据包含:历史时间段的矿井涌水量数据、含水层水位数据、工作面每日开采推进距离。
作为优选,步骤S2包括:
根据所述历史矿井涌水数据构建涌水量时间序列数据集;
将涌水量时间序列数据集作为LSTM预测模型的输入,将经过差分法(DIFF)处理后的涌水量数据集作为LSTM预测模型的输出,对LSTM预测模型进行训练。
作为优选,步骤S3中,采用贝叶斯优化方法计算训练好的LSTM预测模型的最优超参数并对训练好的LSTM预测模型进行评估。
本发明还提供一种矿井涌水量预测装置,包括:
获取模块,用于获取历史矿井涌水数据;
训练模块,用于根据所述历史矿井涌水数据作为训练集对LSTM预测模型进行训练;
选取模块,用于计算训练好的LSTM预测模型的最优超参数;
更新模块,用于通过最优超参数对训练好的LSTM预测模型进行更新迭代,获得最终LSTM预测模型;
预测模块,用于通过所述最终LSTM预测模型对预测未来某一时刻的矿井涌水量进行预测。
作为优选,历史矿井涌水数据包含:历史时间段的矿井涌水量数据、含水层水位数据、工作面每日开采推进距离。
作为优选,训练模块包括:
构建单元,用于根据所述历史矿井涌水数据构建涌水量时间序列数据集;
训练单元,用于将涌水量时间序列数据集作为LSTM预测模型的输入,将经过差分法(DIFF)处理后的涌水量数据集作为LSTM预测模型的输出,对LSTM预测模型进行训练。
作为优选,选取模块采用贝叶斯优化方法计算训练好的LSTM预测模型的最优超参数并对训练好的LSTM预测模型进行评估。
本发明涉通过对水文观测孔测得的含水层水位值、工作面每日推进距离及过去矿井涌水量实测值构建时间序列数据;将时间序列数据集变换为监督学习数据集,作为模型的输入,将经过差分法(DIFF)处理后的涌水量数据作为输出变量,建立长短时循环记忆神经网络(LSTM)预测模型;通过贝叶斯优化方法选取训练好的LSTM预测模型的最优超参数,通过最优超参数对训练好的LSTM预测模型进行更新迭代,获得最终LSTM预测模型;通过最终LSTM预测模型来预测未来某一时刻的矿井涌水量。本发明提供的方法直接利用含水层水位数据,每日推进距离,过去涌水量数据对未来涌水量数据进行精确的预测,这种数据驱动方法可以在不考虑物理过程的情况下学习矿井涌水的变化规律,同时有效减小数据的自相关性,为区域化涌水量的精确预测提供了可行性手段,对于矿山水害预警具有重要的实践价值。
附图说明
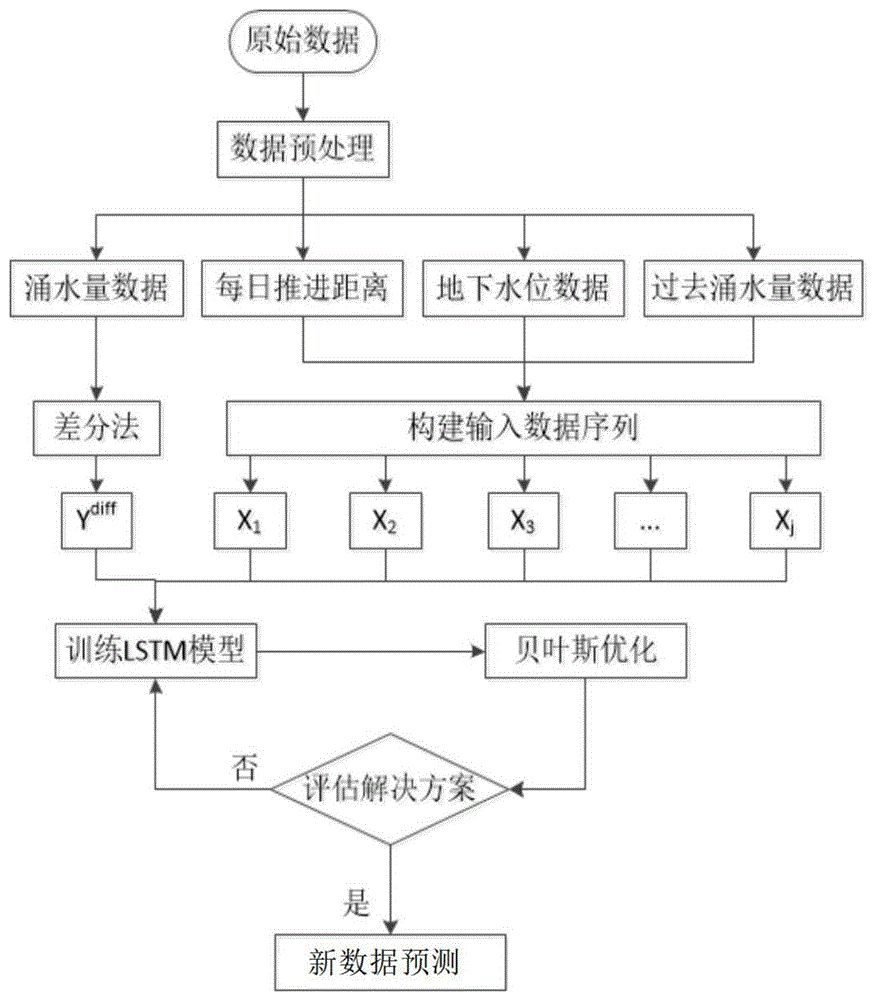
图1为本发明实施例矿井涌水量预测方法的流程示意图;
图2为本发明实施例的LSTM预测模型网络结构示意图;
图3为本发明实施例的LSTM记忆单元计算示意图;
图4为本发明实施例亭南煤矿207工作面涌水量的预测结果示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本发明作进一步详细的说明。
实施例1:
如图1所示,本发明实施例提供一种矿井涌水量预测方法,包括以下步骤:
步骤S1、获取历史矿井涌水数据,所述历史矿井涌水数据包含:历史时间段的矿井涌水量数据、含水层水位数据、工作面每日开采推进距离,同时对历史矿井涌水数据进行预处理,其包含对缺失值进行补充和对异常值进行替换;
步骤S2、根据所述历史矿井涌水数据作为训练集对LSTM预测模型进行训练;
步骤S3、计算训练好的LSTM预测模型的最优超参数;
步骤S4、通过最优超参数对训练好的LSTM预测模型进行更新迭代,获得最终LSTM预测模型;
步骤S5、通过所述最终LSTM预测模型对预测未来某一时刻的矿井涌水量进行预测。
作为本发明实施例的一种实施方式,步骤S2包括:
根据预处理后的历史矿井涌水数据构建涌水量时间序列数据集;
将涌水量时间序列数据集作为LSTM预测模型的输入,将经过差分法(DIFF)处理后的涌水量数据集作为LSTM预测模型的输出,对LSTM预测模型进行训练。
进一步,将时间序列数据集变换为监督学习数据集,作为LSTM预测模型的输入。
进一步,将涌水量时间序列数据进行差分处理(DIFF),直至序列数据平稳,将涌水量时间序列数据作为LSTM预测模型的标签;将涌水量时间序列数据进行差分处理(DIFF),一阶差分公式和二阶差分公式如下:
y
y
其中,y
作为本发明实施例的一种实施方式,如图2所示,步骤S2具体包括:
步骤21、获得确定时间段的某矿井的涌水量数据,建立时间序列数据Y,
Y={y(t
其中,i=1,2,3…n,y(t
步骤22、收集该时间段内的地下水位数据,对数据进行预处理,补充缺失值并剔除异常值,建立模型的输入特征时间序列数据X,
X
其中,x
步骤23、建立LSTM预测模型的对应关系:
其中,
步骤24、对输入输出数据进行归一化处理:
其中,x
步骤25、采用归一化后的前j天的涌水量数据、地下水位数据每日推进距离和涌水量数据作为训练集对LSTM预测模块进行训练,得到训练好的LSTM预测模型。
如图3所示,LSTM模型的遗忘门、输入门和输出门的公式为:
f
i
o
h
以归一化后的前j天的涌水量数据、地下水位数据、每日推进距离作为输入层的神经元,其中,f
作为本发明实施例的一种实施方式,步骤S3中,采用贝叶斯优化方法计算训练好的LSTM预测模型的最优超参数并对训练好的LSTM预测模型进行评估,具体包括:
步骤31、采用的贝叶斯优化方法包含两个核心部分,概率代理模型和EI采集函数,概率代理模型可表示为:
p(f│D)=(p(D│f)p(f))/(p(D))
其中,f=f(x)为LSTM预测模型的目标函数,即损失函数,p(f│D)为f的似然分布,p(f)为f的先验概率,p(D)是f的边缘似然分布,D={(x
通过概率替代模型计算出f(x)的方差和均值后,应用于EI采集函数。EI采集函数的核心是寻找最大改善期望的下一个数据点x
其中,Φ(·)为累计分布函数,φ(·)为标准正态分布的概率密度分布函数,f(x
重复上述过程,不断通过概率代理模型的后验分布选择超参数,直至取得最优解。
步骤32、训练好的LSTM预测模型的评估依据平均绝对百分比误差(MAPE)和平均绝对误差(MAE),具体计算方法如下:
其中,n为样本数量,
贝叶斯优化方法采用python包中的bayes_opt模块来调用,具体流程为:设定超参数域的取值范围,进行目标函数的选择,选择目标函数的替代模型(概率模型),输出贝叶斯优化方法得到的使目标函数最小的超参数值。
LSTM预测模型评估时,将测试集的数据输入到训练好的模型中,将预测的涌水量值和实际值对比,若满足预测的精度要求,则可用没有标签值的新输入数据进行预测。
下面结合具体实例,对本发明实施例子矿井涌水量预测方法进行详细说明:
步骤1:本案例选用亭南煤矿207工作面作为样本,预测的样本数据为2017年9月到2018年6月的日均涌水量数据,输入数据为对应时间段的地下水位数据,工作面每日掘进进尺,及过去涌水量数据。同时,将整理的数据进行数据预处理,对缺失值进行补充和对异常值进行替换。
步骤2:将涌水量数据进行差分处理,直至序列平稳,并将平稳序列作为标签数据。首先进行对涌水量数据进行一阶差分处理,通过python的statsmodels模块的adfuller函数进行ADF检验,ADF测试值为-20.9948同时小于1%、5%、10%不同程度拒绝原假设的统计值-3.443、-2.867、-2.569,说明非常好地拒绝该假设,同时P值为0.00000小于0.01,说明涌水量数据经过一阶差分即可变成平稳序列;
步骤3:构建模型的对应关系,首先采用前10天的涌水量数据、地下水位数据和每日推进距离对应当天的标签数据,同时对序列数据进行归一化处理;
步骤4:构建LSTM模型,抽取前80%作为训练集,其余20%作为验证集,模型的初始学习率设置为0.001,L2损失函数的正则化系数设置为0.001,训练次数为100次;
步骤5:使用贝叶斯优化算法对LSTM模型的隐藏层单元数,时间步长,学习率,正则化系数,批大小,训练次数进行寻优,求解出最优超参数值分别为64,3,0.001,0.001,64,100;
步骤6:依据步骤5寻优获得的最优超参数对模型进行更新迭代,获得最终的预测模型;
步骤7:应用步骤6取得的模型对2018年11月13日至2019年2月20日的涌水量进行预测,对预测结果进行反归一化及反差分得到最终预测数据。结果如图4所示,MAE为6.14,MAPE为0.72%,均满足工程的精度要求。
由上述可知,BO-DIFF-LSTM神经网络模型的预测效果优秀,可以很好的消除序列的自相关性,该方法可为煤矿的安全开采提供有力的技术保障。
实施例2:
本发明实施例还提供一种矿井涌水量预测装置,包括:
获取模块,用于获取历史矿井涌水数据;
训练模块,用于根据所述历史矿井涌水数据作为训练集对LSTM预测模型进行训练;
选取模块,用于计算训练好的LSTM预测模型的最优超参数;
更新模块,用于通过最优超参数对训练好的LSTM预测模型进行更新迭代,获得最终LSTM预测模型;
预测模块,用于通过所述最终LSTM预测模型对预测未来某一时刻的矿井涌水量进行预测。
作为本发明实施例的一种实施方式,历史矿井涌水数据包含:历史时间段的矿井涌水量数据、含水层水位数据、工作面每日开采推进距离。
作为本发明实施例的一种实施方式,训练模块包括:
构建单元,用于根据所述历史矿井涌水数据构建涌水量时间序列数据集;
训练单元,用于将涌水量时间序列数据集作为LSTM预测模型的输入,将经过差分法(DIFF)处理后的涌水量数据集作为LSTM预测模型的输出,对LSTM预测模型进行训练。
作为本发明实施例的一种实施方式,选取模块采用贝叶斯优化方法计算训练好的LSTM预测模型的最优超参数并对训练好的LSTM预测模型进行评估。
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,在任何熟悉本技术领域的技术人员在本发明所述的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内,因此,本发明的保护范围应该以权利要求的保护范围为准。