数据处理方法、装置、存储介质及芯片
文献发布时间:2024-01-17 01:23:17
技术领域
本申请涉及模型处理技术领域,具体而言,涉及一种数据处理方法、装置、存储介质及芯片。
背景技术
数据处理模型通常采用 TCN(Temporal Convolutional Network,时序卷积网络)体系结构。
相关技术中,TCN结构的数据处理模型在提取特征数据集中的数据,以及将模型数据的数据进行回传的过程均在不连续的内存上进行,该过程需要跳内存读数据,导致数据处理效率低下。
发明内容
本申请旨在解决现有技术或相关技术中存在的技术问题之一。
为此,本申请的第一方面提出了一种数据处理方法。
本申请的第二方面提出了一种数据处理装置。
本申请的第三方面提出了一种可读存储介质。
本申请的第四方面提出了一种计算机程序产品。
本申请的第五方面提出了一种芯片。
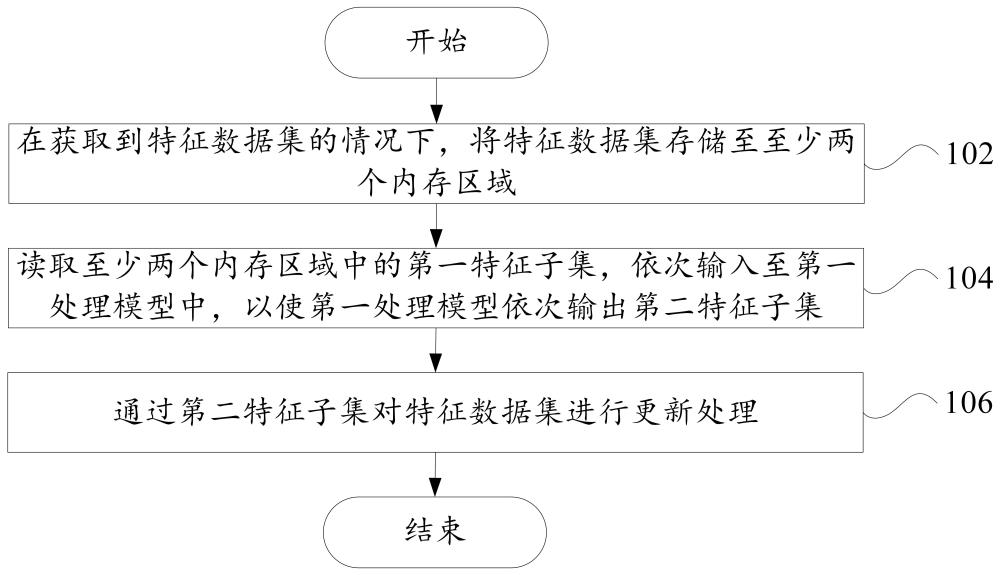
有鉴于此,根据本申请的第一方面提出一种数据处理方法,包括:在获取到特征数据集的情况下,将特征数据集存储至至少两个内存区域,至少两个内存区域中分别存储至少两组第一特征子集;读取至少两个内存区域中的第一特征子集,依次输入至第一处理模型中,以使第一处理模型依次输出第二特征子集;通过第二特征子集对特征数据集进行更新处理。
本申请的技术方案中提出了一种数据处理方法,该数据处理方法能够在选取输入至第一处理模型中的特征数据,以及第一处理模型输出特征数据的过程中,在连续的内存区域上进行数据复制,从而提高了在特征数据集中选取第一特征子集,以及通过第二特征子集更新特征数据集的效率,进一步提高了数据处理的效率。
在该技术方案中,第一处理模型用于对特征数据集中的第一特征子集进行推理,并输出第二特征子集。在接收到特征数据集之后,通过对特征数据集进行分组处理,得到多组第一特征子集,分组得到的多组第一特征子集分别存在不同的内存区域中,相邻两个内存区域均为连续的内存区域。每组第一特征子集均能够输入至第一处理模型进行处理,处理后能够得到相应的第二特征子集。在第一处理模型输出第二特征子集之后,通过第二特征子集对获取到的特征数据集进行更新。在将第一特征子集输入至第一处理模型,以及根据第一处理模型输出的第二特征子集更新特征数据集的过程中,均需要进行数据的复制和读取,由于第一特征子集所存储的区域为连续的内存区域,故能够保证读取和回传数据的过程均在连续的内存区域上进行,从而提高了特征数据的读取和回传效率,进一步提高了数据处理的整体效率。
具体来说,第一处理模型为非空洞卷积模型,在获取到特征数据集的情况下,需要提取特征数据集中的部分特征数据输入至第一处理模型中。本申请的技术方案通过提前对接收到的特征数据集进行分组,保证每组第一特征子集均为能够直接输入至第一处理模型中的特征数据集,实现了在将第一特征子集输入至第一处理模型时,仅需要将不同内存区域的第一特征子集依次输入至第一处理模型中即可。每组第一特征子集分别存储在不同的内存区域中,且相邻两个内存区域为连续的内存区域,故在将第一特征子集输入至第一处理模型的过程,以及将第一处理模型对第一特征子集推理结束后输出的第二特征子集依次复制到相应的内存区域中即可。
在该技术方案中,在将第一特征子集输入至第一处理模型中,第一处理模型对第一特征子集进行处理后,能够输出第二特征子集。通过第二特征子集对特征数据集中的第一特征子集进行替换更新处理,通过更新后的特征数据集能够确定数据处理结果,在提高第一处理模型的推理速度的同时,还保证了推理结果的准确性。
本申请的技术方案中,通过将特征数据集进行分组,得到相应的多组能够直接输入至第一处理模型中的第一特征子集,并将多组第一特征子集分别存储在不同的内存区域中,使将第一特征子集输入至第一处理模型,以及根据第一处理模型输出的第二特征子集更新特征数据集的过程,均能够在连续的内存区域上进行,无需跳内存读取数据,提高了特征数据的复制效率,从而提高了数据处理的整体效率。
在一些技术方案中,可选地,在获取到特征数据集的情况下,将特征数据集存储至至少两个内存区域,包括:将特征数据集分组处理,得到至少两组第一特征子集;将至少两组第一特征子集中的每组第一特征子集,分别存储至至少两个内存区域,其中,至少两个内存区域为连续内存区域。
本申请的技术方案中,通过对特征数据集进行分组处理,能够得到分组后的多组第一特征子集,每组第一特征子集均能够直接输入至第一处理模型中进行推理。并将多组第一特征子集分别存储在不同的内存区域中,并且相邻的第一特征子集存储在相邻且连续的内存区域中,保证在选取第一特征子集,以及通过第二特征子集对第一特征子集进行更新的过程中,均能够在连续的内存区域上进行。
在该技术方案中,特征数据集包括多个特征数据,通过对多个特征数据进行分组处理,能够得到多组第一特征子集,其中,每组第一特征子集中的特征数据的数量相等,且多组第一特征子集之间不包括相同的特征数据。
本申请的技术方案中,通过对特征数据集进行分组得到多组第一特征子集,再将多组第一特征子集存储至连续的内存区域中,保证了第一特征子集能够直接输入至第一处理模型进行推理,还保证了读取第一特征子集和通过第二特征子集更新特征数据集时均能够在连续内存上进行复制,提高了数据复制效率。
在一些技术方案中,可选地,将特征数据集分组处理,得到至少两组第一特征子集,包括:获取第一处理模型中卷积算子的算子参数;根据算子参数,确定第一特征子集中的数据数量,以及第一特征子集的数据在特征数据集中的选取间隔;按照数据数量和选取间隔,对特征数据集进行分组处理。
本申请的技术方案中,第一处理模型中包括卷积算子,根据该卷积算子相应的算子参数,能够确定对特征数据集进行分组的分组规则。通过上述分组规则能够对特征数据集进行分组,并保证分组得到的第一特征子集能够直接输入至特征数据集。
在该技术方案中,分组规则中包括选取间隔和数据数量,其中,选取间隔为相邻两次选取第一特征子集之间的数据间隔量,数据数量为每次选取第一特征子集中的特征数据量。
本申请的技术方案中,根据每组第一特征子集中的数据数量,以及相邻两次选取第一特征子集中的特征数据之间的数据间隔,对特征数据集进行分组,得到多组第一特征子集,并通过将多组第一特征子集存储在连续的内存区域中,保证了分组得到的第一特征子集均能够直接输入至第一处理模型中进行处理。
在一些技术方案中,可选地,算子参数包括扩张因子和卷积核尺寸;根据算子参数,确定第一特征子集中的数据数量,以及第一特征子集的数据在特征数据集中的选取间隔,包括:根据扩张因子,确定选取间隔;以及根据卷积核尺寸,确定数据数量。
本申请的技术方案中,第一处理模型中的卷积算子的算子参数包括扩张因子,以及卷积核尺寸。通过扩张因子能够确定分组规则中的选取间隔,即间隔相邻两次选取特征数据之间所间隔的数据数量。通过卷积核尺寸能够确定分组规则中的数据数量,数据数量为每个第一特征子集中的数据数量。
本申请的技术方案中,通过获取第一卷积算子的扩张因子和卷积核尺寸,能够确定数据选取信息,在将第一处理模型中的第一卷积算子替换为第二卷积算子之后,根据数据选取信息确定在特征数据集中选取多个第一特征子集之间的选取间隔,以及选取得到的每个第一特征子集中的数据数量,即数据数量,提高输入至优化后的第二处理模型中的第一特征子集的准确性,在提高推理效率的同时,保证第二处理模型与第一处理模型推理的匹配程度。
本申请的技术方案中,根据第一处理模型中的卷积算子的卷积核尺寸和扩张因子,确定选取间隔和数据数量。在特征数据集输入至第一处理模型之前,通过数据选取信息对特征数据集进行选取,得到第一特征子集,通过将第一特征子集输入至第一处理模型中,提高输入至第一处理模型中的第一特征子集的准确性,同时提高处理效率。
在一些技术方案中,可选地,将至少两组第一特征子集中的每组第一特征子集,分别存储至至少两个内存区域,包括:获取至少两个内存区域的读取顺序;获取至少两组第一特征子集在特征数据集中的第一排列顺序;根据第一排列顺序和读取顺序,依次将至少两组第一特征子集,存储至至少两个内存区域,以使读取顺序与第一排列顺序相匹配。
本申请的技术方案中,在将多组第一特征子集存储至相应的内存区域之前,需要先对多组第一特征子集进行排序,以及确定多个内存区域之间的读取顺序,并按照读取顺序和第一特征子集的第一排列顺序,将多组第一特征子集存储在多个内存区域中,通过按照多个连续的内存区域的读取顺序进行读取,即能够按照第一排列顺序读取相应的第一特征子集。
在该技术方案中,在获取第一特征子集时,按照读取顺序依次读取内存区域中的第一特征子集,使读取第一特征子集的过程保持在连续内存上进行。将第一特征子集按照第一排列顺序依次存储在内存区域中,从而保证按照读取顺序读取内存区域时,即能够按照第一排列顺序读取到相应的第一特征子集。
本申请的技术方案中,通过将第一特征子集按照第一排列顺序,以及内存区域的读取顺序将多个第一特征子集存储在多个内存区域中,能够保证读取多个第一特征子集的连续性,以及输入至第一处理模型的准确性。
在一些技术方案中,可选地,通过第二特征子集对特征数据集进行更新处理,包括:在第一处理模型输出至少两个第二特征子集的情况下,获取至少两个第二特征子集的第二排列顺序;按照第二排列顺序,将至少两个第二特征子集依次输入至至少两个内存区域中,以替换相应的第一特征子集。
本申请的技术方案中,在第一处理模型输出多个第二特征子集之后,获取多个第二特征子集的第二排列顺序,并按照该第二排列顺序输入至内存区域中,从而替换原内存区域中存储的第一特征子集,完成对特征数据集的更新,得到更新后的特征数据集。
在该技术方案中,在对特征数据集进行更新时,按照先入先出的规则进行更新,即先输入至第一处理模型处理的第一特征子集,优先被相应的第二特征子集替换掉。第二排列顺序可以为第一处理模型中输出第二特征子集的顺序。
本申请的技术方案中,通过第二排列顺序将第二特征子集输入至语音数据集中,从而对语音数据集进行更新,保证回传第二特征子集时能够在连续的内存区域中进行。
在一些技术方案中,可选地,在第一处理模型输出至少两个第二特征子集的情况下,获取至少两个第二特征子集的第二排列顺序,包括:获取至少两个第二特征子集的输出时刻;按照输出时刻,对至少两个第二特征子集进行排序,得到第二排列顺序。
本申请的技术方案中,根据第一处理模型输出至少两个第二特征子集的输出时刻,对至少两个第二特征子集进行排序,能够得到第二排列顺序,保证第二特征子集按照第二排列顺序更新语音数据集。
具体来说,多个第一特征子集输入至第一处理模型的先后顺序,与第一处理模型输出多个第二特征子集的先后顺序相匹配。
本申请的技术方案中,将多个第二特征子集按照第一处理模型的输出时刻进行排序,从而得到第二排列顺序,并按照第二排列顺序将第二特征子集更新至特征数据集中,提高了对特征数据集更新的准确性。
在一些技术方案中,可选地,通过第二特征子集对特征数据集进行更新处理之后,还包括:获取第一处理模型的预设处理次数;在特征数据集的更新次数达到预设处理次数,停止对特征数据集进行更新处理。
本申请的技术方案中,通过对根据第二特征子集更新特征数据集的次数进行计数,并在计数得到的更新次数达到预设处理次数的情况下,确定对特征数据集完成更新,则停止对特征数据集进行更新的过程,同步停止提取特征数据集中的第一特征子集的过程。
在该技术方案中,预设处理次数为提前设置的次数阈值,特征数据集的更新次数即为第一处理模型的推理次数。通过获取特征数据集的更新次数,能够确定第一处理模型的推理次数,在推理次数达到预设处理次数时,则确定完成对特征数据集的更新,得到更新后的特征数据集。
本申请的技术方案中,通过将获取的特征数据集的更新次数与提前设置的预设处理次数进行比较,在更新次数达到预设处理次数时,确定特征数据集更新为更新后的特征数据集,停止向第一处理模型继续输入第一特征子集,进一步提高了数据处理效率。
在一些技术方案中,可选地,特征数据集包括以下任一项:音频特征集、图像特征集、文本特征集。
本申请的技术方案中,第一处理模型可以为语音识别模型、文本处理模型、图像处理模型中的任一种,即通过选择不同的第一处理模型能够对不同的特征数据集进行处理,从而适应不同的应用场景。
在该技术方案中,第一处理模型可以为语音识别模型。在第一处理模型为语音识别模型的情况下,特征数据集包括音频特征集。通过将该语音识别模型部署在家居设备中,实现对家居的语音控制、语音唤醒等功能。
在该技术方案中,第一处理模型可以为文本处理模型,在第一处理模型为文本处理模型时,特征数据集包括文本特征集。通过将文本处理模型部署到家居设备中,能够实现家居设备对文本内容的机器翻译等功能。
在该技术方案中,第一处理模型可以为图像处理模型,在第一处理模型为图像处理模型时,特征数据集包括图像特征集。通过将图像处理模型部署到烹饪设备中,能够实现烹饪设备对食材图像的自动识别。
本申请技术方案中,第一处理模型均可以为时序卷积网络模型,即TCN(TemporalConvolutional Network,时序卷积网络)模型。
本申请技术方案中提供的数据处理方法可能的应用场景包括:语音唤醒、机器翻译等与时间序列相关的任务。
在一些技术方案中,可选地,在特征数据集包括音频特征集的情况下,数据处理方法包括:在获取到音频特征集的情况下,将音频特征集存储至至少两个内存区域,至少两个内存区域中分别存储至少两组第一特征子集;读取至少两个内存区域中的第一特征子集,依次输入至语音识别模型中,以使语音识别模型依次输出第二特征子集;通过第二特征子集对音频特征集进行更新,得到目标特征集;根据目标特征集,输出语音识别结果。
本申请的技术方案中,在特征数据集包括音频特征集时,第一处理模型可以为语音识别模型。在第一处理模型为语音识别模型的情况下,特征数据集包括音频特征集。通过将该语音识别模型部署在家居设备中,实现对家居的语音控制、语音唤醒等功能。
本申请的技术方案中,在接收到音频特征集之后,通过对音频特征集进行分组处理,得到多组第一特征子集,分组得到的多组第一特征子集分别存在不同的内存区域中,相邻两个内存区域均为连续的内存区域。每组第一特征子集均能够输入至语音识别模型进行处理,处理后能够得到相应的第二特征子集。在语音识别模型输出第二特征子集之后,通过第二特征子集对获取到的音频特征集进行更新。在将第一特征子集输入至语音识别模型,以及根据语音识别模型输出的第二特征子集更新音频特征集的过程中,均需要进行数据的复制和读取,由于第一特征子集所存储的区域为连续的内存区域,故能够保证读取和回传数据的过程均在连续的内存区域上进行,从而提高了音频特征的读取和回传效率,进一步提高了数据处理的整体效率。
通过输入至第一处理模型的特征子集,以及第一处理模型输出的特征子集对该临时数组进行维护更新,在维护更新的次数达到预设次数,即第一处理模型对特征数据集的推理次数达到预设次数时,确定第一处理模型完成相应的推理步骤。
在一些技术方案中,可选地,在读取至少两个内存区域中的第一特征子集,依次输入至第一处理模型中之前,还包括:在获取到第二处理模型的情况下,基于第二处理模型中的模型参数,生成第一卷积算子;通过第一卷积算子替换第二处理模型中的第二卷积算子,得到第一处理模型。
本申请的技术方案中,通过将第二处理模型中第二卷积算子替换为第一卷积算子,并且第一处理模型配置相应的数据选取信息,能够得到输入数据尺寸较小的第一处理模型。在将第一处理模型部署到算力较低的边端设备时,能够提高第一处理模型在边端设备中的数据处理速度。
在一些技术方案中,可选地,第二卷积算子为第二处理模型中的卷积算子,该卷积算子可以为空洞卷积算子,第一卷积算子为非空洞卷积算子,通过将第二卷积算子替换为第一卷积算子,并调整第二处理模型的输入数据尺寸得到第一处理模型,完成对第二处理模型的优化。
在一些技术方案中,可选地,第二处理模型为优化前的神经网络模型,第二处理模型的输入数据尺寸较大,且第二处理模型具有将接收到的数据集进行选取的功能。第一处理模型为对第二处理模型进行优化得到的神经网络模型,第一处理模型中输入数据尺寸小于第二处理模型的输入数据尺寸,且第一处理模型不具备对数据集进行选取的功能。基于第二处理模型确定对特征数据集进行选取的数据选取信息,在将特征数据输入至第一处理模型之前,基于数据选取信息对特征数据集进行数据选取。再将提前选取得到的特征子集输入至第一处理模型进行处理,由于第一处理模型的输入数据尺寸小于第二处理模型的输入数据尺寸,在算力较小的家居设备中,第一处理模型的推理速度快于第二处理模型的推理速度。
本申请的技术方案中,第二处理模型的输入数据尺寸大于第一处理模型的输入数据尺寸,且第二处理模型中卷积算子的输入数据尺寸与第一处理模型中卷积算子的输入数据尺寸相同,在提高模型推理速度的同时,保证了第二处理模型与第一处理模型的计算结果等效。
本申请的技术方案中,通过将第二处理模型优化为第一处理模型,降低了输入至第一处理模型的输入数据尺寸,并将选取特征数据集中的特征子集的步骤在模型推理步骤之前执行,能够提高第一处理模型的推理效率。在上述任一技术方案中,第一处理模型包括:时序卷积网络模型。
本申请技术方案中,第一处理模型可以为时序卷积网络模型,即TCN(TemporalConvolutional Network,时序卷积网络)模型。
根据本申请第二方面提出了一种数据处理装置,包括:存储模块,用于在获取到特征数据集的情况下,将特征数据集存储至至少两个内存区域,至少两个内存区域中分别存储至少两组第一特征子集;读取模块,用于读取至少两个内存区域中的第一特征子集,依次输入至第一处理模型中,以使第一处理模型依次输出第二特征子集;更新模块,用于通过第二特征子集对特征数据集进行更新处理。
本申请的技术方案中提出了一种数据处理装置,通过该数据处理装置能够在选取输入至第一处理模型中的特征数据,以及第一处理模型输出特征数据的过程中,在连续的内存区域上进行数据复制,从而提高了在特征数据集中选取第一特征子集,以及通过第二特征子集更新特征数据集的效率,进一步提高了数据处理的效率。
本申请的技术方案中,通过将特征数据集进行分组,得到相应的多组能够直接输入至第一处理模型中的第一特征子集,并将多组第一特征子集分别存储在不同的内存区域中,使将第一特征子集输入至第一处理模型,以及根据第一处理模型输出的第二特征子集更新特征数据集的过程,均能够在连续的内存区域上进行,无需跳内存读取数据,提高了特征数据的复制效率,从而提高了数据处理的整体效率。
根据本申请第三方面提出了一种可读存储介质,可读存储介质上存储有程序或指令,程序或指令被处理器执行时实现如上述第一方面中任一技术方案中的数据处理方法的步骤。因而具有上述第一方面中任一技术方案中的数据处理方法的全部有益技术效果,在此不再做过多赘述。
根据本申请第四方面提出了一种计算机程序产品,计算机程序产品被处理器执行时实现如上述第一方面中任一技术方案中的数据处理方法的步骤。因而具有上述第一方面中任一技术方案中的数据处理方法的全部有益技术效果,在此不再做过多赘述。
根据本申请第五方面提出了一种芯片,芯片包括程序或指令,当芯片运行时,用于实现如上述第一方面中任一技术方案中的数据处理方法的步骤。因而具有上述第一方面中任一技术方案中的数据处理方法的全部有益技术效果,在此不再做过多赘述。
本申请的附加方面和优点将在下面的描述部分中变得明显,或通过本申请的实践了解到。
附图说明
本申请的上述和/或附加的方面和优点从结合下面附图对实施例的描述中将变得明显和容易理解,其中:
图1示出了本申请的一些实施例中提供的数据处理方法的示意流程图之一;
图2示出了本申请的一些实施例中提供的第一处理模型中算子的连接示意图
图3示出了本申请的一些实施例中提供的数据处理方法的示意流程图之二;
图4示出了本申请的一些实施例中提供的数据处理方法的示意流程图之三;
图5示出了本申请的一些实施例提供的特征数据集的示意图之一;
图6示出了本申请的一些实施例提供的第一特征子集的示意图;
图7示出了本申请的一些实施例中提供的数据处理方法的示意流程图之四;
图8示出了本申请的一些实施例提供的特征数据集的示意图之二;
图9示出了本申请的一些实施例提供的数据处理装置的结构框图。
具体实施方式
为了能够更清楚地理解本申请的上述目的、特征和优点,下面结合附图和具体实施方式对本申请进行进一步的详细描述。需要说明的是,在不冲突的情况下,本实施例及实施例中的特征可以相互组合。
在下面的描述中阐述了很多具体细节以便于充分理解本申请,但是,本申请还可以采用其他不同于在此描述的其他方式来实施,因此,本申请的保护范围并不受下面公开的具体实施例的限制。
下面参照图1至图9描述根据本申请一些实施例的数据处理方法、装置、存储介质及芯片。
根据本申请的一个实施例中,如图1所示,提出了一种数据处理方法,包括:
步骤102,在获取到特征数据集的情况下,将特征数据集存储至至少两个内存区域;
其中,至少两个内存区域中分别存储至少两组第一特征子集;
步骤104,读取至少两个内存区域中的第一特征子集,依次输入至第一处理模型中,以使第一处理模型依次输出第二特征子集;
步骤106,通过第二特征子集对特征数据集进行更新处理。
本申请的实施例中提出了一种数据处理方法,该数据处理方法能够在选取输入至第一处理模型中的特征数据,以及第一处理模型输出特征数据的过程中,在连续的内存区域上进行数据复制,从而提高了在特征数据集中选取第一特征子集,以及通过第二特征子集更新特征数据集的效率,进一步提高了数据处理的效率。
在一些实施例中,可选地,第一处理模型用于对特征数据集中的第一特征子集进行推理,并输出第二特征子集。在接收到特征数据集之后,通过对特征数据集进行分组处理,得到多组第一特征子集,分组得到的多组第一特征子集分别存在不同的内存区域中,相邻两个内存区域均为连续的内存区域。每组第一特征子集均能够输入至第一处理模型进行处理,处理后能够得到相应的第二特征子集。在第一处理模型输出第二特征子集之后,通过第二特征子集对获取到的特征数据集进行更新。在将第一特征子集输入至第一处理模型,以及根据第一处理模型输出的第二特征子集更新特征数据集的过程中,均需要进行数据的复制和读取,由于第一特征子集所存储的区域为连续的内存区域,故能够保证读取和回传数据的过程均在连续的内存区域上进行,从而提高了特征数据的读取和回传效率,进一步提高了数据处理的整体效率。
具体来说,第一处理模型为非空洞卷积模型,在获取到特征数据集的情况下,需要提取特征数据集中的部分特征数据输入至第一处理模型中。本申请的实施例通过提前对接收到的特征数据集进行分组,保证每组第一特征子集均为能够直接输入至第一处理模型中的特征数据集,实现了在将第一特征子集输入至第一处理模型时,仅需要将不同内存区域的第一特征子集依次输入至第一处理模型中即可。每组第一特征子集分别存储在不同的内存区域中,且相邻两个内存区域为连续的内存区域,故在将第一特征子集输入至第一处理模型的过程,以及将第一处理模型对第一特征子集推理结束后输出的第二特征子集依次复制到相应的内存区域中即可。
如图2所示,第一处理模型中包括:FullyConnected算子、Add算子、concatenation算子和DephwiseConv2D算子,FullyConnected算子的输出通道与Add算子的输入通道相连接,Add算子的一个输出通道与concatenation算子的输入通道相连接,Add算子的另一个输出通道作为第一处理模型的输出通道,Add算子的输出通道与concatenation算子的一个输入通道相连接,concatenation算子的另一个输入通道作为第一处理模型的输入通道,concatenation算子的输出端与DephwiseConv2D算子相连接。其中,FullyConnected算子为全连接算子、Add算子为叠加算子、concatenation算子为串联算子,第一处理模型中的DephwiseConv2D算子为卷积算子。由图2所示,第一处理模型中的模型的输入数据的数据尺寸为1×1×7×256,即第一特征子集的数据尺寸为1×1×7×256,卷积算子的输入数据的数据尺寸为1×1×8×256,第一处理模型的输出数据的数据尺寸为1×1×1×256,第二特征子集的数据尺寸为1×1×1×256。上述数据格式为N×H×W×C,N为批次,H为高度,W为宽度,C为通道数。
在一些实施例中,可选地,在将第一特征子集输入至第一处理模型中,第一处理模型对第一特征子集进行处理后,能够输出第二特征子集。通过第二特征子集对特征数据集中的第一特征子集进行替换更新处理,得到更新后的特征数据集,通过该更新后的特征数据集能够确定数据处理的结果(例如语音识别结果),在提高第一处理模型的推理速度的同时,还保证了推理结果的准确性。
本申请的实施例中,通过将特征数据集进行分组,得到相应的多组能够直接输入至第一处理模型中的第一特征子集,并将多组第一特征子集分别存储在不同的内存区域中,使将第一特征子集输入至第一处理模型,以及根据第一处理模型输出的第二特征子集更新特征数据集的过程,均能够在连续的内存区域上进行,无需跳内存读取数据,提高了对特征数据的复制效率,从而提高了数据处理的整体效率。
如图3所示,在一些实施例中,可选地,在获取到特征数据集的情况下,将特征数据集存储至至少两个内存区域,包括:
步骤302,将特征数据集分组处理,得到至少两组第一特征子集;
步骤304,将至少两组第一特征子集中的每组第一特征子集,分别存储至至少两个内存区域。
其中,至少两个内存区域为连续内存区域。
本申请的实施例中,通过对特征数据集进行分组处理,能够得到分组后的多组第一特征子集,每组第一特征子集均能够直接输入至第一处理模型中进行推理。并将多组第一特征子集分别存储在不同的内存区域中,并且相邻的第一特征子集存储在相邻且连续的内存区域中,保证在选取第一特征子集,以及通过第二特征子集对第一特征子集进行更新的过程中,均能够在连续的内存区域上进行。
在一些实施例中,可选地,特征数据集包括多个特征数据,通过对多个特征数据进行分组处理,能够得到多组第一特征子集,其中,每组第一特征子集中的特征数据的数量相等,且多组第一特征子集之间不包括相同的特征数据。
本申请的实施例中,通过对特征数据集进行分组得到多组第一特征子集,再将多组第一特征子集存储至连续的内存区域中,保证了第一特征子集能够直接输入至第一处理模型进行推理,还保证了读取第一特征子集和通过第二特征子集更新特征数据集时均能够在连续内存上进行复制,提高了数据复制效率。
如图4所示,在一些实施例中,可选地,将特征数据集分组处理,得到至少两组第一特征子集,包括:
步骤402,获取第一处理模型中卷积算子的算子参数;
步骤404,根据算子参数,确定第一特征子集中的数据数量,以及第一特征子集的数据在特征数据集中的选取间隔;
步骤406,按照数据数量和选取间隔,对特征数据集进行分组处理。
本申请的实施例中,第一处理模型中包括卷积算子,根据该卷积算子相应的算子参数,能够确定对特征数据集进行分组的分组规则。通过上述分组规则能够对特征数据集进行分组,并保证分组得到的第一特征子集能够直接输入至特征数据集。
在一些实施例中,可选地,分组规则中包括选取间隔和数据数量,其中,选取间隔为相邻两次选取第一特征子集之间的数据间隔量,数据数量为每次选取第一特征子集中的特征数据量。
本申请实施例中,根据每组第一特征子集中的数据数量,以及相邻两次选取第一特征子集中的特征数据之间的数据间隔,对特征数据集进行分组,得到多组第一特征子集,并通过将多组第一特征子集存储在连续的内存区域中,保证了分组得到的第一特征子集均能够直接输入至第一处理模型中进行处理。
在一些实施例中,可选地,算子参数包括扩张因子和卷积核尺寸;根据算子参数,确定第一特征子集中的数据数量,以及第一特征子集的数据在特征数据集中的选取间隔,包括:根据扩张因子,确定选取间隔;以及根据卷积核尺寸,确定数据数量。
本申请的实施例中,第一处理模型中的卷积算子的算子参数包括扩张因子,以及卷积核尺寸。通过扩张因子能够确定分组规则中的选取间隔,即间隔相邻两次选取特征数据之间所间隔的数据数量。通过卷积核尺寸能够确定分组规则中的数据数量,数据数量为每个第一特征子集中的数据数量。
本申请的实施例中,通过获取第一卷积算子的扩张因子和卷积核尺寸,能够确定数据选取信息,在将第一处理模型中的第一卷积算子替换为第二卷积算子之后,根据数据选取信息确定在特征数据集中选取多个第一特征子集之间的选取间隔,以及选取得到的每个第一特征子集中的数据数量,即数据数量,提高输入至优化后的第二处理模型中的第一特征子集的准确性,在提高推理效率的同时,保证第二处理模型与第一处理模型推理的匹配程度。
示例性地,第一处理模型中的卷积算子的输入数据和卷积核在H(高度)维度上大小都是1直接相乘,在H维度上不做扩张。在W(宽度)维度上,卷积核尺寸为7,扩张因子为8,则第一卷积算子在输入至第一处理模型的特征数据集中每隔7个选取一个数据,总共选取7个数据与第一卷积核相乘。
图5示出了本申请的一些实施例提供的特征数据集的示意图之一,如图5所示,1至56表示数据集合的序号,每个方格表示一个数据集合,每个数据集合中包括1×256个数据。其中,选取间隔为7,数据数量为7。
图6示出了本申请的一些实施例提供的第一特征子集的示意图,如图6所示,在上述如图5中所示的特征数据集中筛选出8组7×256的第一特征子集,其中,每一列即为一组第一特征子集。
本申请的实施例中,根据第一处理模型中的卷积算子的卷积核尺寸和扩张因子,确定选取间隔和数据数量。在特征数据集输入至第一处理模型之前,通过数据选取信息对特征数据集进行选取,得到第一特征子集,通过将第一特征子集输入至第一处理模型中,提高输入至第一处理模型中的第一特征子集的准确性,同时提高处理效率。
如图7所示,在一些实施例中,可选地,将至少两组第一特征子集中的每组第一特征子集,分别存储至至少两个内存区域,包括:
步骤702,获取至少两个内存区域的读取顺序;
步骤704,获取至少两组第一特征子集在特征数据集中的第一排列顺序;
步骤706,根据第一排列顺序和读取顺序,依次将至少两组第一特征子集,存储至至少两个内存区域,以使读取顺序与第一排列顺序相匹配。
本申请的实施例中,在将多组第一特征子集存储至相应的内存区域之前,需要先对多组第一特征子集进行排序,以及确定多个内存区域之间的读取顺序,并按照读取顺序和第一特征子集的第一排列顺序,将多组第一特征子集存储在多个内存区域中,通过按照多个连续的内存区域的读取顺序进行读取,即能够按照第一排列顺序读取相应的第一特征子集。
在一些实施例中,可选地,在获取第一特征子集时,按照读取顺序依次读取内存区域中的第一特征子集,使读取第一特征子集的过程保持在连续内存上进行。将第一特征子集按照第一排列顺序依次存储在内存区域中,从而保证按照读取顺序读取内存区域时,即能够按照第一排列顺序读取到相应的第一特征子集。
本申请的实施例中,通过将第一特征子集按照第一排列顺序,以及内存区域的读取顺序将多个第一特征子集存储在多个内存区域中,能够保证读取多个第一特征子集的连续性,以及输入至第一处理模型的准确性。
在一些实施例中,可选地,通过第二特征子集对特征数据集进行更新处理,包括:在第一处理模型输出至少两个第二特征子集的情况下,获取至少两个第二特征子集的第二排列顺序;按照第二排列顺序,将至少两个第二特征子集依次输入至至少两个内存区域中,以替换相应的第一特征子集。
本申请的实施例中,在第一处理模型输出多个第二特征子集之后,获取多个第二特征子集的第二排列顺序,并按照该第二排列顺序输入至内存区域中,从而替换原内存区域中存储的第一特征子集,完成对特征数据集的更新,得到更新后的特征数据集。
在一些实施例中,可选地,在对特征数据集进行更新时,按照先入先出的规则进行更新,即先输入至第一处理模型处理的第一特征子集,优先被相应的第二特征子集替换掉。第二排列顺序可以为第一处理模型中输出第二特征子集的顺序。
图8示出了本申请的一些实施例提供的特征数据集的示意图之二,如图8所示,第一组第一特征子集为1、9、17、25、33、41、49,第二组第一特征子集为2、10、18、26、34、42、50,第三组第一特征集子3、11、19、27、35、43、51。在第一处理模型输出三个第二特征子集57、58、59,且三个第二特征子集的第二排列顺序为57、58、59的情况下,则将第二特征子集57替换第一特征子集1,以及将第二特征子集58替换第一特征子集2,再将第二特征子集59替换第一特征子集3。
本申请的实施例中,通过第二排列顺序将第二特征子集输入至语音数据集中,从而对语音数据集进行更新,保证回传第二特征子集时能够在连续的内存区域中进行。
在一些实施例中,可选地,在第一处理模型输出至少两个第二特征子集的情况下,获取至少两个第二特征子集的第二排列顺序,包括:获取至少两个第二特征子集的输出时刻;按照输出时刻,对至少两个第二特征子集进行排序,得到第二排列顺序。
本申请的实施例中,根据第一处理模型输出至少两个第二特征子集的输出时刻,对至少两个第二特征子集进行排序,能够得到第二排列顺序,保证第二特征子集按照第二排列顺序更新语音数据集。
具体来说,多个第一特征子集输入至第一处理模型的先后顺序,与第一处理模型输出多个第二特征子集的先后顺序相匹配。
本申请的实施例中,将多个第二特征子集按照第一处理模型的输出时刻进行排序,从而得到第二排列顺序,并按照第二排列顺序将第二特征子集更新至特征数据集中,提高了对特征数据集更新的准确性。
在一些实施例中,可选地,通过第二特征子集对特征数据集进行更新处理之后,还包括:获取第一处理模型的预设处理次数;在特征数据集的更新次数达到预设处理次数,停止对特征数据集进行更新处理。
本申请的实施例中,通过对根据第二特征子集更新特征数据集的次数进行计数,并在计数得到的更新次数达到预设处理次数的情况下,确定对特征数据集完成更新,则停止对特征数据集进行更新的过程,同步停止提取特征数据集中的第一特征子集的过程。
在一些实施例中,可选地,预设处理次数为提前设置的次数阈值,特征数据集的更新次数即为第一处理模型的推理次数。通过获取特征数据集的更新次数,能够确定第一处理模型的推理次数,在推理次数达到预设处理次数时,则确定完成对特征数据集的更新,得到更新后的特征数据集。
示例性地,提前对第一处理模型设置计数器,通过该计数器对特征数据集的更新次数进行计数,在更新次数达到预设处理次数后,完成当前推理过程。
本申请的实施例中,通过将获取的特征数据集的更新次数与提前设置的预设处理次数进行比较,在更新次数达到预设处理次数时,确定特征数据集更新为更新后的特征数据集,停止向第一处理模型继续输入第一特征子集,进一步提高了数据处理效率。
在一些实施例中,可选地,特征数据集包括以下任一项:
音频特征集、图像特征集、文本特征集。
本申请的实施例中,第一处理模型可以为语音识别模型、文本处理模型、图像处理模型中的任一种,即通过选择不同的第一处理模型能够对不同的特征数据集进行处理,从而适应不同的应用场景。
在该实施例中,第一处理模型可以为语音识别模型。在第一处理模型为语音识别模型的情况下,特征数据集包括音频特征集。通过将该语音识别模型部署在家居设备中,实现对家居的语音控制、语音唤醒等功能。
在该实施例中,第一处理模型可以为文本处理模型,在第一处理模型为文本处理模型时,特征数据集包括文本特征集。通过将文本处理模型部署到家居设备中,能够实现家居设备对文本内容的机器翻译等功能。
在该实施例中,第一处理模型可以为图像处理模型,在第一处理模型为图像处理模型时,特征数据集包括图像特征集。通过将图像处理模型部署到烹饪设备中,能够实现烹饪设备对食材图像的自动识别。
本申请实施例中,第一处理模型均可以为时序卷积网络模型,即TCN(TemporalConvolutional Network,时序卷积网络)模型。
本申请实施例中提供的数据处理方法可能的应用场景包括:语音唤醒、机器翻译等与时间序列相关的任务。
在一些实施例中,可选地,在特征数据集包括音频特征集的情况下,数据处理方法包括:在获取到音频特征集的情况下,将音频特征集存储至至少两个内存区域,至少两个内存区域中分别存储至少两组第一特征子集;读取至少两个内存区域中的第一特征子集,依次输入至语音识别模型中,以使语音识别模型依次输出第二特征子集;通过第二特征子集对音频特征集进行更新,得到目标特征集;根据目标特征集,输出语音识别结果。
本申请的实施例中,在特征数据集包括音频特征集时,第一处理模型可以为语音识别模型。在第一处理模型为语音识别模型的情况下,特征数据集包括音频特征集。通过将该语音识别模型部署在家居设备中,实现对家居的语音控制、语音唤醒等功能。
本申请的实施例中,在接收到音频特征集之后,通过对音频特征集进行分组处理,得到多组第一特征子集,分组得到的多组第一特征子集分别存在不同的内存区域中,相邻两个内存区域均为连续的内存区域。每组第一特征子集均能够输入至语音识别模型进行处理,处理后能够得到相应的第二特征子集。在语音识别模型输出第二特征子集之后,通过第二特征子集对获取到的音频特征集进行更新。在将第一特征子集输入至语音识别模型,以及根据语音识别模型输出的第二特征子集更新音频特征集的过程中,均需要进行数据的复制和读取,由于第一特征子集所存储的区域为连续的内存区域,故能够保证读取和回传数据的过程均在连续的内存区域上进行,从而提高了特征数据的读取和回传效率,进一步提高了数据处理的整体效率。
示例性地,语音识别模型可以用于语音唤醒场景、文本翻译场景、图像识别场景中的任一项。
本申请实施例中提供的数据处理方法可能的应用场景包括:语音唤醒、机器翻译等与时间序列相关的任务。
在一些实施例中,可选地,输入至第一处理模型中的特征数据集中的特征数据可以为语音数据的MFCC(Mel-Frequency Cepstral Coefficients,梅尔频率倒谱系数)特征或Fbank(Filter bank,滤波器组特征)特征。第一处理模型输出的是因素的分类,在语音唤醒任务中,无需要记录对当前语音数据的推理次数,在推理数据达到预设次数,对输出数据通过解码模块判断是否对家居设备进行唤醒。如果是其他应用场景则对应其他类型数据,例如:如果是机器翻译任务,则特征数据集为文本数据中的文本特征。
示例性地,以家居设备实现语音唤醒任务为例进行说明:
在接收到语音指令中的MFCC特征集之后,按照通过模型优化方法得到的数据选取信息,提取MFCC特征集中的特征子集。此时,对该特征数据集建立一个临时数组,例如:1×1×56×256大小的临时数组,该临时数组为特征数据集,每次推理按照扩张规则选取数据作为模型的输入1×1×7×256,第一处理模型的前一次推理的输出为1×1×1×256,按照先入先出规则更新1×256大小的数据。
通过输入至第一处理模型的特征子集,以及第一处理模型输出的特征子集对该临时数组进行维护更新,在维护更新的次数达到预设次数,即第一处理模型对特征数据集的推理次数达到预设次数时,确定第一处理模型完成相应的推理步骤。
在一些实施例中,可选地,在读取至少两个内存区域中的第一特征子集,依次输入至第一处理模型中之前,还包括:在获取到第二处理模型的情况下,基于第二处理模型中的模型参数,生成第一卷积算子;通过第一卷积算子替换第二处理模型中的第二卷积算子,得到第一处理模型。
本申请的实施例中,通过将第二处理模型中第二卷积算子替换为第一卷积算子,并且第一处理模型配置相应的数据选取信息,能够得到输入数据尺寸较小的第一处理模型。在将第一处理模型部署到算力较低的边端设备时,能够提高第一处理模型在边端设备中的数据处理速度。
在一些实施例中,可选地,第二卷积算子为第二处理模型中的卷积算子,该卷积算子可以为空洞卷积算子,第一卷积算子为非空洞卷积算子,通过将第二卷积算子替换为第一卷积算子,并调整第二处理模型的输入数据尺寸得到第一处理模型,完成对第二处理模型的优化。
在一些实施例中,可选地,第二处理模型为优化前的神经网络模型,第二处理模型的输入数据尺寸较大,且第二处理模型具有将接收到的数据集进行选取的功能。第一处理模型为对第二处理模型进行优化得到的神经网络模型,第一处理模型中输入数据尺寸小于第二处理模型的输入数据尺寸,且第一处理模型不具备对数据集进行选取的功能。基于第二处理模型确定对特征数据集进行选取的数据选取信息,在将特征数据输入至第一处理模型之前,基于数据选取信息对特征数据集进行数据选取。再将提前选取得到的特征子集输入至第一处理模型进行处理,由于第一处理模型的输入数据尺寸小于第二处理模型的输入数据尺寸,在算力较小的家居设备中,第一处理模型的推理速度快于第二处理模型的推理速度。
示例性地,第二处理模型可以为空洞卷积模型,空洞卷积模型为在标准卷积核中注入空洞,以此更快地增加模型的感受野,但是由于空洞卷积的卷积核不连续,在扩张率设置较高的情况下,算子在资源有限的家居设备上运算时,由于内存不连续,导致缓存命中率低,从而使得空洞卷积算子的执行效率低、推理速度慢。第一处理模型可以为标准卷积模型,通过将第二处理模型替换为第一处理模型,提高了算子执行效率,加快模型推理速度。
本申请的实施例中,第二处理模型的输入数据尺寸大于第一处理模型的输入数据尺寸,且第二处理模型中卷积算子的输入数据尺寸与第一处理模型中卷积算子的输入数据尺寸相同,在提高模型推理速度的同时,保证了第二处理模型与第一处理模型的计算结果等效。
本申请的实施例中,通过将第二处理模型优化为第一处理模型,降低了输入至第一处理模型的输入数据尺寸,并将选取特征数据集中的特征子集的步骤在模型推理步骤之前执行,能够提高第一处理模型的推理效率。
在一些实施例中,可选地,第一处理模型包括:时序卷积网络模型。
本申请实施例中,第一处理模型可以为时序卷积网络模型,即TCN(TemporalConvolutional Network,时序卷积网络)模型。在根据本申请的一个实施例中,如图9,提出一种数据处理装置900,包括:
存储模块902,用于在获取到特征数据集的情况下,将特征数据集存储至至少两个内存区域,至少两个内存区域中分别存储至少两组第一特征子集;
读取模块904,用于读取至少两个内存区域中的第一特征子集,依次输入至第一处理模型中,以使第一处理模型依次输出第二特征子集;
更新模块906,用于通过第二特征子集对特征数据集进行更新处理。
本申请的实施例中提出了一种数据处理装置,通过该数据处理装置能够在选取输入至第一处理模型中的特征数据,以及第一处理模型输出特征数据的过程中,在连续的内存区域上进行数据复制,从而提高了在特征数据集中选取第一特征子集,以及通过第二特征子集更新特征数据集的效率,进一步提高了数据处理的效率。
本申请的实施例中,通过将特征数据集进行分组,得到相应的多组能够直接输入至第一处理模型中的第一特征子集,并将多组第一特征子集分别存储在不同的内存区域中,使将第一特征子集输入至第一处理模型,以及根据第一处理模型输出的第二特征子集更新特征数据集的过程,均能够在连续的内存区域上进行,无需跳内存读取数据,提高了特征数据的复制效率,从而提高了数据处理的整体效率。
在一些实施例中,可选地,数据处理装置900,包括:
分组模块,用于将特征数据集分组处理,得到至少两组第一特征子集;
存储模块902,用于将至少两组第一特征子集中的每组第一特征子集,分别存储至至少两个内存区域,其中,至少两个内存区域为连续内存区域。
本申请的实施例中,通过对特征数据集进行分组处理,能够得到分组后的多组第一特征子集,每组第一特征子集均能够直接输入至第一处理模型中进行推理。并将多组第一特征子集分别存储在不同的内存区域中,并且相邻的第一特征子集存储在相邻且连续的内存区域中,保证在选取第一特征子集,以及通过第二特征子集对第一特征子集进行更新的过程中,均能够在连续的内存区域上进行。
在该实施例中,特征数据集包括多个特征数据,通过对多个特征数据进行分组处理,能够得到多组第一特征子集,其中,每组第一特征子集中的特征数据的数量相等,且多组第一特征子集之间不包括相同的特征数据。
本申请的实施例中,通过对特征数据集进行分组得到多组第一特征子集,再将多组第一特征子集存储至连续的内存区域中,保证了第一特征子集能够直接输入至第一处理模型进行推理,还保证了读取第一特征子集和通过第二特征子集更新特征数据集时均能够在连续内存上进行复制,提高了数据复制效率。
在一些实施例中,可选地,数据处理装置900,包括:
获取模块,用于获取第一处理模型中卷积算子的算子参数;
确定模块,用于根据算子参数,确定第一特征子集中的数据数量,以及第一特征子集的数据在特征数据集中的选取间隔;
分组模块,用于按照数据数量和选取间隔,对特征数据集进行分组处理。
本申请的实施例中,第一处理模型中包括卷积算子,根据该卷积算子相应的算子参数,能够确定对特征数据集进行分组的分组规则。通过上述分组规则能够对特征数据集进行分组,并保证分组得到的第一特征子集能够直接输入至特征数据集。
在该实施例中,分组规则中包括选取间隔和数据数量,其中,选取间隔为相邻两次选取第一特征子集之间的数据间隔量,数据数量为每次选取第一特征子集中的特征数据量。
本申请实施例中,根据每组第一特征子集中的数据数量,以及相邻两次选取第一特征子集中的特征数据之间的数据间隔,对特征数据集进行分组,得到多组第一特征子集,并通过将多组第一特征子集存储在连续的内存区域中,保证了分组得到的第一特征子集均能够直接输入至第一处理模型中进行处理。
在一些实施例中,可选地,算子参数包括扩张因子和卷积核尺寸;数据处理装置900,包括:
确定模块,用于根据扩张因子,确定选取间隔;
确定模块,用于根据卷积核尺寸,确定数据数量。
本申请的实施例中,第一处理模型中的卷积算子的算子参数包括扩张因子,以及卷积核尺寸。通过扩张因子能够确定分组规则中的选取间隔,即间隔相邻两次选取特征数据之间所间隔的数据数量。通过卷积核尺寸能够确定分组规则中的数据数量,数据数量为每个第一特征子集中的数据数量。
本申请的实施例中,通过获取第一卷积算子的扩张因子和卷积核尺寸,能够确定数据选取信息,在将第一处理模型中的第一卷积算子替换为第二卷积算子之后,根据数据选取信息确定在特征数据集中选取多个第一特征子集之间的选取间隔,以及选取得到的每个第一特征子集中的数据数量,即数据数量,提高输入至优化后的第二处理模型中的第一特征子集的准确性,在提高推理效率的同时,保证第二处理模型与第一处理模型推理的匹配程度。
本申请的实施例中,根据第一处理模型中的卷积算子的卷积核尺寸和扩张因子,确定选取间隔和数据数量。在特征数据集输入至第一处理模型之前,通过数据选取信息对特征数据集进行选取,得到第一特征子集,通过将第一特征子集输入至第一处理模型中,提高输入至第一处理模型中的第一特征子集的准确性,同时提高处理效率。
在一些实施例中,可选地,数据处理装置900,包括:
获取模块,用于获取至少两个内存区域的读取顺序;
获取模块,用于获取至少两组第一特征子集在特征数据集中的第一排列顺序;
存储模块902,用于根据第一排列顺序和读取顺序,依次将至少两组第一特征子集,存储至至少两个内存区域,以使读取顺序与第一排列顺序相匹配。
本申请的实施例中,在将多组第一特征子集存储至相应的内存区域之前,需要先对多组第一特征子集进行排序,以及确定多个内存区域之间的读取顺序,并按照读取顺序和第一特征子集的第一排列顺序,将多组第一特征子集存储在多个内存区域中,通过按照多个连续的内存区域的读取顺序进行读取,即能够按照第一排列顺序读取相应的第一特征子集。
在该实施例中,在获取第一特征子集时,按照读取顺序依次读取内存区域中的第一特征子集,使读取第一特征子集的过程保持在连续内存上进行。将第一特征子集按照第一排列顺序依次存储在内存区域中,从而保证按照读取顺序读取内存区域时,即能够按照第一排列顺序读取到相应的第一特征子集。
本申请的实施例中,通过将第一特征子集按照第一排列顺序,以及内存区域的读取顺序将多个第一特征子集存储在多个内存区域中,能够保证读取多个第一特征子集的连续性,以及输入至第一处理模型的准确性。
在一些实施例中,可选地,数据处理装置900,包括:
获取模块,用于在第一处理模型输出至少两个第二特征子集的情况下,获取至少两个第二特征子集的第二排列顺序;
替换模块,用于按照第二排列顺序,将至少两个第二特征子集依次输入至至少两个内存区域中,以替换相应的第一特征子集。
本申请的实施例中,在第一处理模型输出多个第二特征子集之后,获取多个第二特征子集的第二排列顺序,并按照该第二排列顺序输入至内存区域中,从而替换原内存区域中存储的第一特征子集,完成对特征数据集的更新,得到更新后的特征数据集。
在该实施例中,在对特征数据集进行更新时,按照先入先出的规则进行更新,即先输入至第一处理模型处理的第一特征子集,优先被相应的第二特征子集替换掉。第二排列顺序可以为第一处理模型中输出第二特征子集的顺序。
本申请的实施例中,通过第二排列顺序将第二特征子集输入至语音数据集中,从而对语音数据集进行更新,保证回传第二特征子集时能够在连续的内存区域中进行。
在一些实施例中,可选地,数据处理装置900,包括:
获取模块,用于获取至少两个第二特征子集的输出时刻;
排序模块,用于按照输出时刻,对至少两个第二特征子集进行排序,得到第二排列顺序。
本申请的实施例中,根据第一处理模型输出至少两个第二特征子集的输出时刻,对至少两个第二特征子集进行排序,能够得到第二排列顺序,保证第二特征子集按照第二排列顺序更新语音数据集。
具体来说,多个第一特征子集输入至第一处理模型的先后顺序,与第一处理模型输出多个第二特征子集的先后顺序相匹配。
本申请的实施例中,将多个第二特征子集按照第一处理模型的输出时刻进行排序,从而得到第二排列顺序,并按照第二排列顺序将第二特征子集更新至特征数据集中,提高了对特征数据集更新的准确性。
在一些实施例中,可选地,数据处理装置900,包括:
获取模块,用于获取第一处理模型的预设处理次数;
确定模块,用于在特征数据集的更新次数达到预设处理次数,停止对特征数据集进行更新处理。
本申请的实施例中,通过对根据第二特征子集更新特征数据集的次数进行计数,并在计数得到的更新次数达到预设处理次数的情况下,确定对特征数据集完成更新,则停止对特征数据集进行更新的过程,同步停止提取特征数据集中的第一特征子集的过程。
在该实施例中,预设处理次数为提前设置的次数阈值,特征数据集的更新次数即为第一处理模型的推理次数。通过获取特征数据集的更新次数,能够确定第一处理模型的推理次数,在推理次数达到预设处理次数时,则确定完成对特征数据集的更新,得到更新后的特征数据集。
本申请的实施例中,通过将获取的特征数据集的更新次数与提前设置的预设处理次数进行比较,在更新次数达到预设处理次数时,确定特征数据集更新为更新后的特征数据集,停止向第一处理模型继续输入第一特征子集,进一步提高了数据处理效率。
在一些实施例中,可选地,特征数据集包括以下任一项:
音频特征集、图像特征集、文本特征集。
本申请的实施例中,第一处理模型可以为语音识别模型、文本处理模型、图像处理模型中的任一种,即通过选择不同的第一处理模型能够对不同的特征数据集进行处理,从而适应不同的应用场景。
在该实施例中,第一处理模型可以为语音识别模型。在第一处理模型为语音识别模型的情况下,特征数据集包括音频特征集。通过将该语音识别模型部署在家居设备中,实现对家居的语音控制、语音唤醒等功能。
在该实施例中,第一处理模型可以为文本处理模型,在第一处理模型为文本处理模型时,特征数据集包括文本特征集。通过将文本处理模型部署到家居设备中,能够实现家居设备对文本内容的机器翻译等功能。
在该实施例中,第一处理模型可以为图像处理模型,在第一处理模型为图像处理模型时,特征数据集包括图像特征集。通过将图像处理模型部署到烹饪设备中,能够实现烹饪设备对食材图像的自动识别。
本申请实施例中,第一处理模型均可以为时序卷积网络模型,即TCN(TemporalConvolutional Network,时序卷积网络)模型。
本申请实施例中提供的数据处理方法可能的应用场景包括:语音唤醒、机器翻译等与时间序列相关的任务。
在一些实施例中,可选地,在特征数据集包括音频特征集的情况下,数据处理装置900,包括:
存储模块902,用于在获取到音频特征集的情况下,将音频特征集存储至至少两个内存区域,至少两个内存区域中分别存储至少两组第一特征子集;
读取模块904,用于读取至少两个内存区域中的第一特征子集,依次输入至语音识别模型中,以使语音识别模型依次输出第二特征子集;
更新模块906,用于通过第二特征子集对音频特征集进行更新,得到目标特征集;根据目标特征集,输出语音识别结果。
本申请的实施例中,在特征数据集包括音频特征集时,第一处理模型可以为语音识别模型。在第一处理模型为语音识别模型的情况下,特征数据集包括音频特征集。通过将该语音识别模型部署在家居设备中,实现对家居的语音控制、语音唤醒等功能。
本申请的实施例中,在接收到音频特征集之后,通过对音频特征集进行分组处理,得到多组第一特征子集,分组得到的多组第一特征子集分别存在不同的内存区域中,相邻两个内存区域均为连续的内存区域。每组第一特征子集均能够输入至语音识别模型进行处理,处理后能够得到相应的第二特征子集。在语音识别模型输出第二特征子集之后,通过第二特征子集对获取到的音频特征集进行更新。在将第一特征子集输入至语音识别模型,以及根据语音识别模型输出的第二特征子集更新音频特征集的过程中,均需要进行数据的复制和读取,由于第一特征子集所存储的区域为连续的内存区域,故能够保证读取和回传数据的过程均在连续的内存区域上进行,从而提高了特征数据的读取和回传效率,进一步提高了数据处理的整体效率。
在一些实施例中,可选地,生成模块,用于在获取到第二处理模型的情况下,基于第二处理模型中的模型参数,生成第一卷积算子;
替换模块,用于通过第一卷积算子替换第二处理模型中的第二卷积算子,得到第一处理模型。
本申请的实施例中,通过将第二处理模型中第二卷积算子替换为第一卷积算子,并且第一处理模型配置相应的数据选取信息,能够得到输入数据尺寸较小的第一处理模型。在将第一处理模型部署到算力较低的边端设备时,能够提高第一处理模型在边端设备中的数据处理速度。
在一些实施例中,可选地,第二卷积算子为第二处理模型中的卷积算子,该卷积算子可以为空洞卷积算子,第一卷积算子为非空洞卷积算子,通过将第二卷积算子替换为第一卷积算子,并调整第二处理模型的输入数据尺寸得到第一处理模型,完成对第二处理模型的优化。
在一些实施例中,可选地,第二处理模型为优化前的神经网络模型,第二处理模型的输入数据尺寸较大,且第二处理模型具有将接收到的数据集进行选取的功能。第一处理模型为对第二处理模型进行优化得到的神经网络模型,第一处理模型中输入数据尺寸小于第二处理模型的输入数据尺寸,且第一处理模型不具备对数据集进行选取的功能。基于第二处理模型确定对特征数据集进行选取的数据选取信息,在将特征数据输入至第一处理模型之前,基于数据选取信息对特征数据集进行数据选取。再将提前选取得到的特征子集输入至第一处理模型进行处理,由于第一处理模型的输入数据尺寸小于第二处理模型的输入数据尺寸,在算力较小的家居设备中,第一处理模型的推理速度快于第二处理模型的推理速度。在一些实施例中,可选地,第一处理模型包括:时序卷积网络模型。
本申请实施例中,第一处理模型可以为时序卷积网络模型,即TCN(TemporalConvolutional Network,时序卷积网络)模型。
在根据本申请的一个实施例中,提出了一种可读存储介质,可读存储介质上存储有程序或指令,程序或指令被处理器执行时实现如上述任一实施例中的数据处理方法的步骤。因而具有上述任一实施例中的数据处理方法的全部有益技术效果,在此不再做过多赘述。
在根据本申请的一个实施例中,提出了一种计算机程序产品,计算机程序产品被处理器执行时实现如上述任一实施例中的数据处理方法的步骤,因而具有上述任一实施例中的数据处理方法的全部有益技术效果,在此不再做过多赘述。
在根据本申请的一个实施例中,提出了一种芯片,芯片包括程序或指令,当芯片运行时,用于实现如上述第一方面中任一实施例中的数据处理方法的步骤。因而具有上述第一方面中任一实施例中的数据处理方法的全部有益技术效果,在此不再做过多赘述。
本申请提出一种基于数据分组的空洞卷积内存优化方法,通过对数据回传时维护的中间数组进行分组,保证每次数据复制时需要的数据内存是连续,从而提高数据回传效率减少耗时,该方案利于资源受限的终端设备。
本申请提供的技术方案可以应用于linux/rtos/android/ios等不同边端系统,面向armv7/v8及dsp等不同边端平台提供指令级加速。本申请的技术方案展现出轻量级部署、通用性强、易用性强、高性能推理等特点,全面解决智能设备低资源瓶颈,大幅缩短AI模型部署周期,在边端AI部署领域达到业界领先水平。并且本申请提供的技术方案可以应用于自研芯片中,例如可以应用于业界首款支持语音、连接、显示三合一芯片FL119中。相关成果已全面赋能语音冰箱、空调、机器人等智能家电量产落地,提智增效。
需要明确的是,在本申请的权利要求书、说明书和说明书附图中,术语“多个”则指两个或两个以上,除非有额外的明确限定,术语“上”、“下”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了更方便地描述本申请和使得描述过程更加简便,而不是为了指示或暗示所指的装置或元件必须具有所描述的特定方位、以特定方位构造和操作,因此这些描述不能理解为对本申请的限制;术语“连接”、“安装”、“固定”等均应做广义理解,举例来说,“连接”可以是多个对象之间的固定连接,也可以是多个对象之间的可拆卸连接,或一体地连接;可以是多个对象之间的直接相连,也可以是多个对象之间的通过中间媒介间接相连。对于本领域的普通技术人员而言,可以根据上述数据地具体情况理解上述术语在本申请中的具体含义。
在本申请的权利要求书、说明书和说明书附图中,术语“一个实施例”、“一些实施例”、“具体实施例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或特点包含于本申请的实施例或示例中。在本申请的权利要求书、说明书和说明书附图中,对上述术语的示意性表述不一定指的是相同的实施例或实例。而且,描述的具体特征、结构、材料或特点可以在任何的一个或多个实施例或示例中以合适的方式结合。
以上仅为本申请的优选实施例而已,并不用于限制本申请,对于本领域的技术人员来说,本申请可以有各种更改和变化。凡在本申请的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本申请的保护范围之内。
- 存储系统的数据处理方法、装置、系统及可读存储介质
- 音频数据的处理方法及装置、存储介质、电子装置
- 数据处理方法、装置、存储介质和电子装置
- 数据处理方法、装置、存储介质和电子装置
- 数据库集群数据处理方法及装置、存储介质和终端
- 存储数据处理方法、装置、芯片、电子设备及存储介质
- 一种存储碎片化数据的处理方法、装置、存储介质及芯片