一种基于文档的石化行业危化品库区知识图谱构建方法
文献发布时间:2024-04-18 19:58:21
技术领域
本发明涉及石化行业危化品技术领域,特别是一种基于文档的石化行业危化品库区知识图谱构建方法。
背景技术
凡具有腐蚀性、自然性、易燃性、毒害性、爆炸性等性质,在运输、装卸和储存保管过程中容易造成人身伤亡和财产损毁而必须要特别防护的物品,均属危险品。危险品具有特别的物理、化学性能,运输中如防护不当,极易发生事故,并且事故所造成的后果较一般车辆事故更加严重。现有的危化品事故进行处理都是人工来完成,这样现场风险隐患的分析判断通过人工来完成,工作量巨大、且非常容易出现人为失误。
危险化学品事故的发生涉及因素众多,既有危险化学品自身的稳定性、理化性质、毒理性质、环境危害性质等,还要考虑事故发生后的人体健康效应、生态效应、环境效应、社会效应等。涉及的数据存在信息范围广、数据量大、数据类型复杂、数据来源多、质量参差不齐问题。同时,危险化学品领域完整的知识信息匮乏,目前无高质量的公开数据集,阻碍科研进展,使深度学习等新技术在危险化学品领域中的应用难以落地。
借助知识图谱与中文信息处理技术构建危险化学品事故的推理分析模型,既可以在事前对危险化学品事故的预防建立预案,又可以辅助建立应急响应预案提升危险化学品事故的处理能力。
知识图谱是一种揭示实体之间关系的语义网络,结点可以代表相关的实体,边则代表了两个实体之间存在的关系,实体之间以存在的关系相互连接,形成了一个包含丰富语义的网络,在计算机中表达出现实世界中存在的实体及相互联系,有助于发掘出实体间深层次的联系,便于进行相关的推理和分析。
发明内容
为克服上述问题,本发明的目的是提供一种基于文档的石化行业危化品库区知识图谱构建方法,将结果用知识图谱的方式将其直观展示,为事故因果分析提供了新的分析工具和途径。
本发明采用以下方案实现:一种基于文档的石化行业危化品库区知识图谱构建方法,其特征在于:所述方法通过危化品和危化品事故应急处置文件为基础构建知识图谱的模式层和数据层;
所述模式层从危化品标准数字化实现和应急响应业务逻辑出发,先找出危化品领域中的综合抽象概念,然后不断自上而下,对上层概念逐步细化为更为具体的下层概念,自顶向下定义概念实体、属性与层级语义关系,构建准确、结构层次分明的概念体系架构;通过不断的对领域知识中的下层概念、术语进行归纳、聚类、泛化处理,综合出上一级的抽象概念模型;
所述数据层自底而上,对危化品规范文件、学术文献、事故案例不同数据,根据危化品自身特性和事故应对措施中采用基于深度学习方式抽取实体信息及语义关联,对不同来源知识进行对齐与融合,建立具体要素与概念节点间的映射,形成模式层到数据层的映射,使用基于孪生神经网络的实体对齐模型将多个知识图谱融合形成综合化的危化品库区知识图谱。
进一步的,进行学术文献分析和调研,找寻危化品的规范文件,包括以下几个步骤:
2.1确定研究的范围和目标:阅读学术文献,明确是危化品的规范性文件的内容和范围;
2.2收集规范性文件:使用学术搜索引擎、图书馆资源、政府机构网站渠道,收集与危化品的国家标准、地方标准和行业标准文件;
2.3筛选和评估文件:对收集到的文件进行筛选和评估,选择与研究目标相关的文件;评估文件的可信度和权威性;
2.4总结和分类文件:对筛选后的文件进行总结和分类,整理出国家标准、地方标准和行业标准文件,并将应急预案和事故处置规范性文件与之关联;
2.5分析文件内容:仔细阅读和分析所收集的文件,了解危化品的规范要求、安全措施、事故应急处理流程内容;
2.6文件研判:根据对文件的分析和理解,撰写文件综述和报告,概括总结国内关于危化品的规范性文件,包括国家标准、地方标准、行业标准、应急预案和事故处置规范性文件的要点和关键信息。
进一步的,将收集的文件转化为可编辑文本格式并进行格式转换、去除冗余信息操作,以确保数据的一致性和可用性;以下是具体的任务和步骤:
3.1文件格式转换:对于已经获取的电子文件,检查其格式并将其转换为可编辑的文本格式;
3.2PDF利用OCR技术提取:收集的电子文件大多为PDF格式,采用OCR技术提取其中的文字,获取可编辑的文本内容;
3.3去除冗余信息:在文件转换和OCR提取后,存在一些冗余信息,使用python语言,对文本进行清理和格式化,去除冗余信息;
3.4数据一致性和校对:对于转换后的文本内容,进行校对和核对,确保数据的准确性和一致性;检查文本是否正确提取;
3.5文件命名和组织:对文本文件进行命名和组织;根据文件的内容、标准编号、日期因素来命名文件,并将它们按照一定的目录结构进行组织和分类。
本发明的有益效果在于:本发明将知识图谱技术应用于石化行业危化品领域,通过标准数字化的手段,将分散在大量文本数据内的重要信息以结构化的形式展现、存储,对于危化品行业数字化高质量发展具有重要意义。且本发明以更科学的方式对石化行业危化品库区领域的知识进行存储,提高该领域的知识共享与利用效率。
附图说明
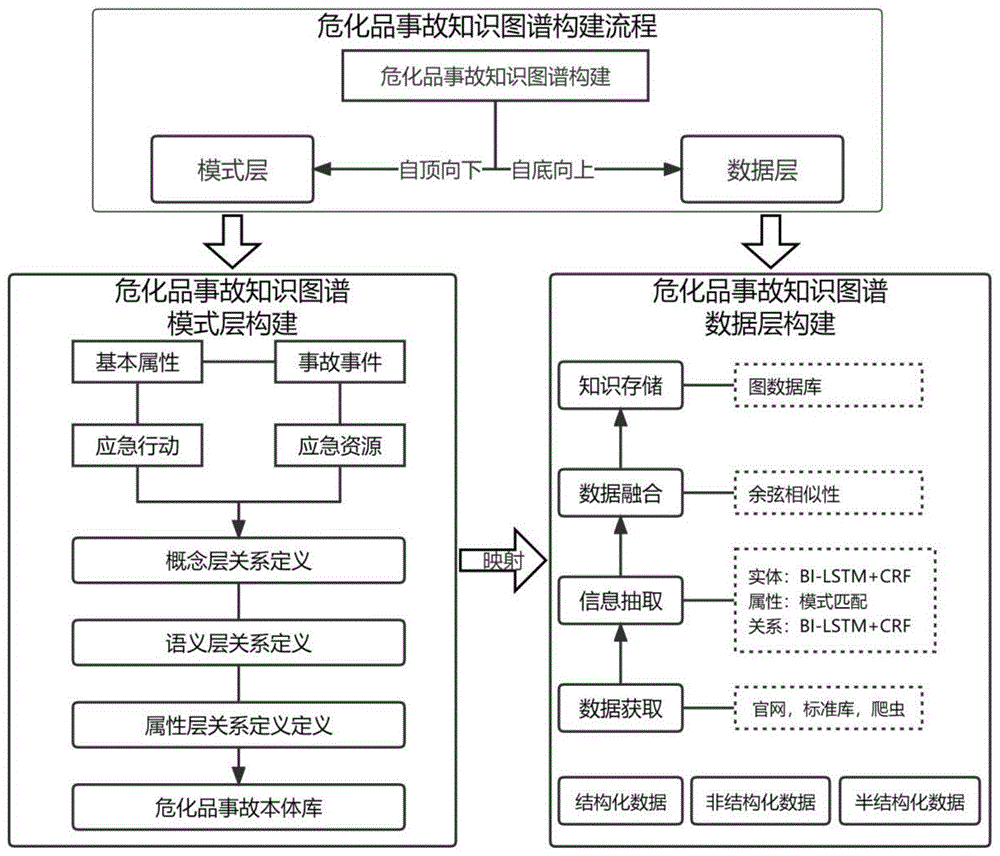
图1是本发明石化行业危化品库区知识图谱构建基本流程。
图2是本发明的本体之间语义关联关系示意图。
图3是本发明一实施例中石化行业危化品库区知识图谱模式层示意图。
具体实施方式
下面结合附图对本发明做进一步说明。
请参阅图1所示,本发明的一种基于文档的石化行业危化品库区知识图谱构建方法,所述方法通过危化品和危化品事故应急处置文件为基础构建知识图谱的模式层和数据层;
所述模式层从危化品相关标准数字化实现和应急响应业务逻辑出发,先找出危化品领域中的综合抽象概念,然后不断自上而下,对上层概念逐步细化为更为具体的下层概念,自顶向下定义概念实体、属性与层级语义关系,构建准确、结构层次分明的概念体系架构;通过不断的对领域知识中的下层概念、术语进行归纳、聚类、泛化等处理,综合出上一级的抽象概念模型。
所述数据层自底而上,对危化品相关规范文件、学术文献、事故案例等不同数据,从危化品自身特性和事故应对措施中采用基于深度学习方法抽取实体信息及语义关联,对不同来源知识进行对齐与融合,建立具体要素与概念节点间的映射,形成模式层到数据层的映射,使用基于孪生神经网络的实体对齐模型将多个知识图谱融合形成综合化的危化品库区知识图谱。
其中,进行文献分析和调研,找寻危化品的规范性文件。包括以下几个步骤:
2.1确定研究的范围和目标:阅读相关文献,明确是危化品的规范性文件的内容和范围,
2.2收集规范性文件:使用学术搜索引擎、图书馆资源、政府机构网站等渠道,收集与危化品相关的国家标准、地方标准和行业标准等文件。这些文献可以包括法律法规、技术规范、安全手册等。
2.3筛选和评估文件:对收集到的文件进行筛选和评估,选择与研究目标最相关的文件。评估文件的可信度和权威性,优先选择由相关政府机构、标准化组织或权威研究机构发布的文件。
2.4总结和分类文件:对筛选后的文件进行总结和分类,整理出国家标准、地方标准和行业标准等相关文件,并将应急预案和事故处置等规范性文件与之关联。
2.5分析文件内容:仔细阅读和分析所收集的文件,了解危化品的规范要求、安全措施、事故应急处理流程等内容。注意抓取关键信息,如标准编号、适用范围、技术要求等。
2.6文件研判:根据对文件的分析和理解,撰写文件综述和报告,概括总结国内关于危化品的规范性文件,包括国家标准、地方标准、行业标准、应急预案和事故处置等规范性文件的要点和关键信息。在整个过程中,确保采用准确可靠的文件来源,以确保所得到的信息具有权威性和可信度。这将为后续的技术路线制定和危化品管理提供重要的参考依据。
将收集的文件转化为可编辑文本格式并进行必要的格式转换、去除冗余信息等操作,以确保数据的一致性和可用性。以下是一些具体的任务和步骤:
3.1文件格式转换:对于已经获取的电子文件,检查其格式并将其转换为可编辑的文本格式。常见的文件格式包括PDF、Word文档等。
3.2 PDF利用OCR技术提取:收集的电子文件大多为PDF格式,而且其中的内容是扫描图像而不是可编辑文本,采用OCR技术提取其中的文字,获取可编辑的文本内容。
3.3去除冗余信息:在文件转换和OCR提取后,存在一些冗余信息,如页眉、页脚、注释、参考文件等。使用python语言,对文本进行清理和格式化,去除这些冗余信息,以便于后续的数据处理和分析。
3.4数据一致性和校对:对于转换后的文本内容,进行一次仔细的校对和核对,确保数据的准确性和一致性。检查文本是否正确提取,特别是针对数字、公式、表格等复杂内容的提取。如有必要,可以手动修正和调整文本。
3.5文件命名和组织:为了方便后续的使用和检索,建议对文本文件进行合理的命名和组织。根据文件的内容、标准编号、日期等因素来命名文件,并将它们按照一定的目录结构进行组织和分类。
知识图谱的概念层次体系按照本体的思想设计,对于概念的层次关系、类属关系、关联关系进行编排,形成结构层次较为明确清晰的知识图谱模式层概念框架。知识图谱的模式层本体库包含了基本属性、事件事故、应急行动、应急资源四类核心要素,并对核心要素之间的语义关系进行定义,危化品事故应急知识图谱模式层的综合本体库可表示为:
O
O
针对危化品应急领域综合本体库当中的基本属性、事件事故、应急行动、应急资源四类核心要素的本体定义进行阐述。
4.1危化品基本属性本体构建:
(1)基本属性本体是有关危化品概念层次关系、属性关系以及关联关系的统一描述,将一个基本属性本体表示为:
O
将O
参照《常用危险化学品应急速查手册》、《危险化学品目录》、《首批重点监管的危险化学品安全措施和事故应急处置原则》等国家标准。将OBA涵义表示危化品的基本属性,主要包括化学性质(危险品名称OnA、分子式、相对分子质量、CAS号、有害物成分);物理性质(外观与性状、PH值、熔点、沸点、相对密度、相对蒸汽密度、饱和蒸汽压、临界温度、临界压力、LogP)安全性和危险性(闪点、引燃温度、燃烧热、爆炸下限、爆炸上限、危险性类别)其他特征(溶解性、主要用途、稳定性)等。
4.2危化品事故案例本体的构建:
事故事件本体是有关应急任务概念层次关系、属性关系以及关联关系的统一描述,将一个事故案例本体表示为:
O
将事件事故区分为事故类型和事故等级两个模块,其中A
参照《AQT 3052-2015危险化学品应急救援指挥导则》,我们将事故事件区分为事故类型和事故等级两个模块,其中AFR代表事故类型火灾爆炸事故,APS代表事故类型中毒窒息事故,AL代表事故类型泄漏事故,AAL代表事故等级,根据事故危害程度、设计范围,事故划分为四级I级(特别重大事故)、II(重大事故)、III(较大事故)、IV(一般事故)四个级别。
应急行动本体构建:
应急行动本体是有关应急任务概念层次关系、属性关系以及关联关系的统一描述,将一个应急行动本体表示为:
O
将应急行动分为以下几个行为:M
参照《GAT 970-2011危险化学品泄漏事故处置行动要则》、《XF/T 1275-2015石油储罐火灾扑救行动指南》、《SYT 6306-2008常压储罐的灭火处理》等国家标准。将应急行动分为以下几个步骤:侦检、警戒、防护、处置、洗消、恢复。
应急资源本体构建:
应急资源本体是有关应急任务概念层次关系、属性关系以及关联关系的统一描述,将一个应急资源本体表示为:
O
将应急资源分为:H
参照《DB43/T 1778-2020化工园区应急管理与救援规范》,将应急资源分为:防护装备、车辆、检测设备、警戒器材、通信器材、救生器材、破拆器材、灭火设备、堵漏器材、防污输送器材、排烟照明器材。
需要对处理的文本进行筛选,并选择具有代表性的文本进行实体、属性和关系等标注。这些标注将用于后续的BILSTM-CRF模型训练。同时,还需要建立监督和质量控制机制,以确保标注的准确性和一致性。以下是对该步骤的详细描述:
5.1文本筛选:根据需求和目标,确定筛选标准,以从处理的文本中选择具有代表性的样本。这可以基于文本的主题、领域、长度等因素进行筛选。
5.2标注实体、属性和关系:使用标注工具或平台,对选定的文本进行人工标注。需要确定标注的实体类别(如人名、地点、组织等)、属性(如日期、价格、数量等)和实体之间的关系(如上下级关系、同义关系等)。
5.3建立监督机制:确保标注的准确性和一致性,建立监督机制是至关重要的。这可以包括以下措施:
1)提供标注准则和指南:准备详细的标注准则和指南,确保标注人员理解标注任务的要求和标准。
2)进行标注培训:为标注人员提供培训,使他们熟悉标注工具和标注任务,并理解标注准则。
3)定期讨论和解决问题:与标注人员进行定期讨论,解答疑问,澄清标注标准,并及时解决标注过程中遇到的问题。
5.4建立质量控制机制:确保标注的一致性和质量,建立质量控制机制是必要的。以下是一些常见的质量控制措施:
1)双重标注:对一部分文本进行多人标注,然后比对标注结果,评估标注者之间的一致性,并进行必要的修正和调整。
2)定期评估和反馈:对标注结果进行定期评估,与标注人员进行反馈,并提供指导,以确保标注的准确性和一致性。
3)抽样检查:随机抽取已标注的文本进行检查,验证标注的准确性,并纠正可能存在的错误。
5.5标注工具选择:选择适合标注任务的工具或平台。有许多开源和商业标注工具可供选择,如Labelbox、Doccano、Brat等。考虑需求、标注复杂度、团队协作等因素,选择最适合的工具。
5.6标注数据管理:建立一个有效的标注数据管理系统,确保标注数据的安全性和可追溯性。这可以包括数据备份、版本控制、权限管理等措施,以防止数据丢失或被篡改。
5.7标注速度和质量平衡:在标注过程中,需要平衡标注速度和质量。尽量提高标注效率,同时确保标注准确无误。这可以通过定期检查和反馈,与标注人员进行交流,以及提供标注任务的适当时间预估来实现。
5.8标注结果评估:对标注结果进行评估和验证,以确保标注的准确性和一致性。这可以采用人工抽样检查、自动评估指标等方法。根据评估结果,对标注人员进行反馈和指导,并进行必要的修正和调整。
5.9标注数据扩充:在标注过程中,可以考虑将已标注的样本用于模型的训练,并通过半监督学习或主动学习方法来扩充标注数据。这有助于提高模型的性能和泛化能力。
5.10数据隐私和安全:在进行人工标注时,确保对敏感信息进行妥善处理,并采取适当的数据安全措施。这包括限制标注人员的访问权限、对数据进行匿名化处理等,以保护数据的隐私和安全。
将使用BILSTM-CRF(双向长短期记忆网络-条件随机场)模型进行命名实体识别。该模型结合了BILSTM和CRF两个部分,能够有效地捕捉文本中的上下文信息和标签之间的依赖关系,从而实现准确的实体识别。以下是对该步骤的详细描述:
6.1数据准备:准备标注好的数据集,其中包含已经人工标注的文本以及对应的实体标签。确保数据集的质量和标注的准确性。
6.2数据预处理:对数据进行预处理,包括分词、构建词向量、将文本转换为模型可接受的输入格式等。
6.3特征提取:从预处理的数据中提取特征,以供BILSTM-CRF模型使用。常用的特征包括词向量、字符级别特征、词性标记等。可以根据实际需求选择适合的特征。
6.4模型构建:构建BILSTM-CRF模型。该模型通常由两个部分组成:一个BILSTM层用于捕捉上下文信息,一个CRF层用于建模标签之间的转移概率。可以使用深度学习框架如TensorFlow、PyTorch或Keras来实现模型。
6.5模型训练:使用标注好的数据集对BILSTM-CRF模型进行训练。将数据集分为训练集、验证集和测试集,通过迭代优化模型参数来提高模型的性能。选择适当的损失函数(如交叉熵损失函数)和优化算法(如Adam或SGD)进行模型训练。
6.6超参数调优:调整模型的超参数以获得更好的性能。超参数包括学习率、隐藏层大小、dropout率等。可以使用交叉验证等技术来寻找最佳的超参数组合。
6.7模型评估:使用测试集对训练好的BILSTM-CRF模型进行评估。常用的评估指标包括准确率、召回率、F1值等。通过评估结果来衡量模型的性能,并进行必要的调整和改进。
6.8模型应用:在实际应用中使用训练好的BILSTM-CRF模型进行命名实体识别。将待识别的文本输入模型,获取预测的实体标签
6.9错误分析和调优:对模型进行错误分析,识别常见的错误类型和模式。例如,模型可能对特定类型的实体或特定上下文情境识别不准确。根据错误分析结果,调整模型的架构、特征选择或数据预处理方法,以改进模型的性能。
6.10模型优化和迭代:基于错误分析和调优的结果,优化模型并进行迭代训练。可能需要尝试不同的模型架构、特征工程方法或超参数设置,以进一步提升命名实体识别的准确性和鲁棒性。
6.11模型部署:将训练好的BILSTM-CRF模型部署到实际生产环境中。将模型集成到应用程序或系统中,并确保其能够高效地处理输入文本,并输出准确的命名实体识别结果。
6.12持续改进和更新:持续监测模型的性能,并根据实际应用中的反馈和需求进行改进和更新。可以考虑定期重新训练模型,使用更大规模的数据集或引入其他技术和模型来进一步提升命名实体识别的效果。
所述方法还包括将危化品库区知识图谱基于Neo4j图数据库基础上构建石化行业危化品库区数据库,来实现危化品库区知识图谱存储和危化品库区可视化展示。
Neo4j是一种广泛使用的图数据库,适用于构建知识图谱。它提供了强大的图数据库功能和查询语言Cypher,可以有效地存储和查询图形数据。以下是使用Neo4j构建知识图谱的详细步骤:
7.1定义实体和关系类型:根据需求,确定知识图谱中的实体类型和关系类型。创建相应的节点标签和关系类型,以便将数据存储到Neo4j中。
7.2导入数据:将实体和关系数据导入到Neo4j中。可以使用Cypher查询语言或Neo4j提供的导入工具(如LOAD CSV)来将数据从外部源导入到数据库中。确保数据的格式符合Neo4j的要求,并进行必要的数据清洗和转换。
7.3创建节点和关系:使用Cypher语言创建节点和关系。通过使用CREATE语句,为每个实体创建一个节点,并使用关系语句创建实体之间的关系。设置节点和关系的属性,以添加相关的信息。
7.4查询和检索:使用Cypher查询语言进行图谱数据的查询和检索。根据需求,编写相应的查询语句,以获取特定实体、关系或其属性信息。可以使用MATCH、CREATE、DELETE等语句进行数据操作。
7.5索引和优化:为图谱数据创建索引以提高查询性能。Neo4j支持创建节点和属性的索引,以加快查询速度。根据查询的频率和性能需求,选择适当的属性进行索引,并使用PROFILE命令分析查询性能。
7.6更新和维护:根据需要对知识图谱进行更新和维护。添加新的实体和关系,更新现有的属性或关系,确保知识图谱与实际数据保持同步。执行必要的数据清理和数据质量控制,以确保图谱的准确性和一致性。
7.7可视化和探索:使用Neo4j提供的可视化工具(如Neo4j Browser、Neo4jBloom)或其他第三方工具,对知识图谱进行可视化和探索。通过图形界面,直观地浏览和理解图谱中的实体、关系和属性。
通过以上步骤,可以使用Neo4j构建一个功能丰富的知识图谱。利用Neo4j的图数据库功能和强大的查询语言,可以进行复杂的图形数据操作和高效的知识发现。记得在构建过程中根据需要进行索引和性能优化,以获得更好的查询效率和用户体验。
所述危化品库区知识图谱的本体以库区危化品以及危化品事故应急处置为核心(参见图3所示),危化品相关知识主要围绕自身理化特性和库区储存条件展开,库区危化品事故的重要节点为应急行动,通过应急行动将应急救援行动与应急资源连接起来。
所述危化品库区知识图谱依据石化行业危化品自身的类型和理化特性,在不同事故类型下会引发不同的事故后果,在应急救援的各个环节需要采取针对性的应急措施,调用合适的应急资源。
本专利将知识图谱技术应用于石化行业危化品领域,通过标准数字化的手段,将分散在大量文本数据内的重要信息以结构化的形式展现、存储,对于危化品行业数字化高质量发展具有重要意义。本专利以更科学的方式对石化行业危化品库区领域的知识进行存储,提高该领域的知识共享与利用效率。本专利的有益效果在于:具体的危化品事故情景下会产生实时的应急资源需求,使用知识图谱图谱技术,通过存储库区内危化品的相关性质及其储存条件,以及这些危化品引发不同类型的危化品事故后,在不同应急救援行动下所需的应急资源。为危化品事故突发事件的决策提供有力参考,以支持危化品事故应急资源信息可视化和应急响应方案推理,提高应急响应速度和决策效率,促进应急管理工作的智能化与精准化。
以上所述仅为本发明的较佳实施例,凡依本发明申请专利范围所做的均等变化与修饰,皆应属本发明的涵盖范围。
- 一种基于产业链的行业知识图谱构建方法
- 一种基于大数据的危化品车辆动态分析方法及其系统
- 基于水利行业标准的知识图谱自动化构建方法和系统
- 一种基于知识图谱的综合管廊行业知识问答系统构建方法