一种基于自适应联邦学习的需求响应基线负荷估计方法
文献发布时间:2024-04-18 19:58:26
技术领域
本发明属于智能电网人工智能技术领域,具体涉及一种基于自适应联邦学习的需求响应基线负荷估计方法。
背景技术
为了提高配电网络的运行安全性和可靠性,配电网络运营商鼓励用户进行需求响应,并为他们提供经济补偿。这种补偿通常是根据用户基线负荷进行结算。然而,使用单一的用户基线负荷估计方法,包括基于历史数据的方法和基于非参与者数据的方法,存在可能导致用户基线负荷严重错估的风险。对于基于历史数据的方法,在用户在需求响应事件期间和非事件日的负荷曲线存在显著差异时,可能会出现用户基线负荷的不准确估计。对于对照组方法,如果相同群组中的对照组大小较小,非参与者数据的方法的性能可能会显著降低。准确的用户基线负荷估计对参与者和电网运营商至关重要。由于过度补偿,配电网络运营商将至少退还其收入的一半。与此同时,低额补偿将降低用户参与需求响应的意愿。
因此,现阶段设计一种基于自适应联邦学习的需求响应基线负荷估计方法,来解决以上问题。
发明内容
本发明目的在于提供一种基于自适应联邦学习的需求响应基线负荷估计方法,用于解决上述现有技术中存在的技术问题,如:对于基于历史数据的方法,在用户在需求响应事件期间和非事件日的负荷曲线存在显著差异时,可能会出现用户基线负荷的不准确估计。对于对照组方法,如果相同群组中的对照组大小较小,非参与者数据的方法的性能可能会显著降低。
为实现上述目的,本发明的技术方案是:
一种基于自适应联邦学习的需求响应基线负荷估计方法,包括以下步骤:
步骤1,提出基于深度学习的居民用户基线负荷估计方法,用于区分各种条件并从基于历史数据和非参与者数据的基线负荷估计中选择合适的估计值;
步骤2,构建横向联邦学习框架以使用存储在本地数据集中的样本来训练神经网络;在横向联邦学习框架中,局部神经网络模型的参数通过中央服务器上的Fedavg算法进行聚合;
步骤3,在联邦学习框架中,提出自适应学习率方法,用于居民用户基线负荷选择任务。
进一步的,步骤S1具体如下:
使用需求响应参与者和非参与者数据,其中神经网络的输入是通过回归方法使用历史数据估计的基线负荷、需求响应参与者的负荷,以及通过非参与者使用对照组方法估计的基线负荷;支持向量回归方法的输入是需求响应参与者n在需求响应事件前的几个非事件日的负荷数据;支持向量回归方法的输出是每日估计的基线负荷;
如果选择X个非事件日的历史负荷来估计居民用户基线负荷,并且需求响应事件周期的时间点数量为S,样本数为M;有S个支持向量回归模型来拟合历史数据,每个回归模型对应需求响应周期内的一个时间槽;对于每个回归模型,输入维度为{M,X},输出维度为{M,1};
对于负荷模式聚类方法,其过程如下:首先,通过对非事件日的历史负荷进行平均,确定所有用户的负荷模式;考虑到天气条件对最近历史负荷曲线的影响,考虑的历史天数限制在需求响应事件前的一个月内;随后,使用K-means聚类方法将所有用户基于其负荷模式分成多个簇;K-means聚类的输入是所有用户的负荷模式,通过欧氏距离将数据点分配给最近的簇质心,并在收敛时更新质心;最后,通过对同一簇内的控制组在需求响应事件当天的负荷进行平均,计算每日估计的基线负荷;
设T表示一个需求响应事件日的时间点集合;T分为两部分:需求响应事件周期和非需求响应事件周期,分别用δ和δ
居民用户基线负荷估计用于确定需求响应计划的补偿结算;对于基于激励的需求响应计划,每个参与需求响应的参与者的经济补偿是固定或时变激励价格与需求响应事件期间负荷减少量的乘积;居民用户基线负荷估计的评估中,使用平均绝对误差作为精度的度量指标,平均绝对误差记为MAE,使用偏差作为准确性的度量指标;MAE反映在每个时间段估计值和实际居民用户基线负荷值之间的平均偏差,其为绝对值;偏差反映所有时间段的估计值和实际居民用户基线负荷值的累积偏差;
居民用户基线负荷估计的精度由MAE来衡量,即估计基线和实际基线之间差值的平均绝对值,如下式所示:
式中:MAE
然后,引入Bias来衡量居民用户基线负荷估计的准确性,它是估计基线和实际基线之间差值的平均值,如下式所示:
式中:Bias
引入多变性来评估居民用户基线负荷估计方法的稳定性,通过相对误差比(RER)来衡量,误差比记为RER;RER是估计误差的标准差与需求响应事件期间平均负荷之比,表示如下:
RER
式中:RER
引入综合性能指标来对居民用户基线负荷估计方法进行综合评估,综合性能指标记为OPI;需求响应参与者n在需求响应事件日d的OPI定义如下:
式中:
深度学习方法的基线选择基于支持向量回归方法和负荷模式聚类方法的OPI(O=O
神经网络的输出是一个向量Q
进一步的,步骤S2具体如下:
联邦学习的学习过程分为本地训练和全局聚合两个步骤:
1)本地训练:每个本地数据集的代理随机初始化神经网络的参数,并使用本地数据进行本地训练。在进行一定次数的本地训练后,本地的参数将被上传到中央服务器。
2)全局聚合:在每次全局聚合中,中央服务器获取本地神经网络的参数,然后使用FedAvg算法更新全局神经网络。完成一次全局聚合后,更新后的全局参数将分发给每个联邦学习参与者进行新一轮的本地模型训练。全局聚合步骤对于联邦学习的成功非常关键,因为它允许联邦学习参与者在保护数据隐私和安全的同时共同学习。通过聚合本地模型,全局模型可以捕捉不同数据集之间的共同模式和特征,从而提高性能和泛化能力。
设K表示联邦学习参与者的数量,联邦学习的目标函数如下所示:
式中:x表示神经网络的输入,y表示真实标签。
本地神经网络的参数更新如下:
式中:
当本地更新步骤t=τ时,每个本地神经网络的参数将上传到中央服务器进行全局聚合。由于联邦学习参与者之间的本地训练集大小不同,全局神经网络的参数将作为所有联邦学习参与者的本地神经网络的加权平均值确定。对于每个参与者的本地神经网络,分配的权重与总数据量与该参与者本地数据集大小的比例成正比。具体计算如下:
式中:
假设所有本地采样集合被整合成一个集中式集合。令
式中:ω
进一步的,步骤S3具体如下:
深度学习自适应学习率表达式如下:
式中:η
在深度学习中,模型训练是通过随机选择包含一定数量样本的批量数据进行的;第k个联邦学习参与者的学习率计算如下:
式中:η
每个局部模型通过计算本地样本的平均绝对差异来得到,如下式所示:
然后,每个联邦学习参与者的
最后,
与现有技术相比,本发明所具有的有益效果为:
本方案其中一个有益效果在于,历史数据法和非参与者数据法适用于不同的条件,各自具有其优势。为了利用这些方法的互补特性,提出了一种深度学习方法来智能选择CBL估计方法。考虑到用户隐私的重要性,引入了增强的联邦学习框架来在住宅单元内训练本地神经网络。在该框架中,提出了一种新颖的自适应学习率方法,用于CBL选择任务,旨在提高低全局聚合频率下联邦学习的性能。与众所周知的和目前最先进的CBL估计方法相比,所提出的水平联邦学习方法在各种条件下展示了最佳的CBL估计结果综合性能。值得注意的是,所提出的方法有效解决了仅依赖单一CBL估计方法可能导致严重估计错误的问题。此外,与本地深度学习相比,联邦学习展示了减轻由于有限本地数据引起的模型过拟合问题的能力,同时确保隐私保护。此外,与传统联邦学习方法相比,所提出的自适应联邦学习方法在低全局聚合频率下增强了神经网络的性能。
附图说明
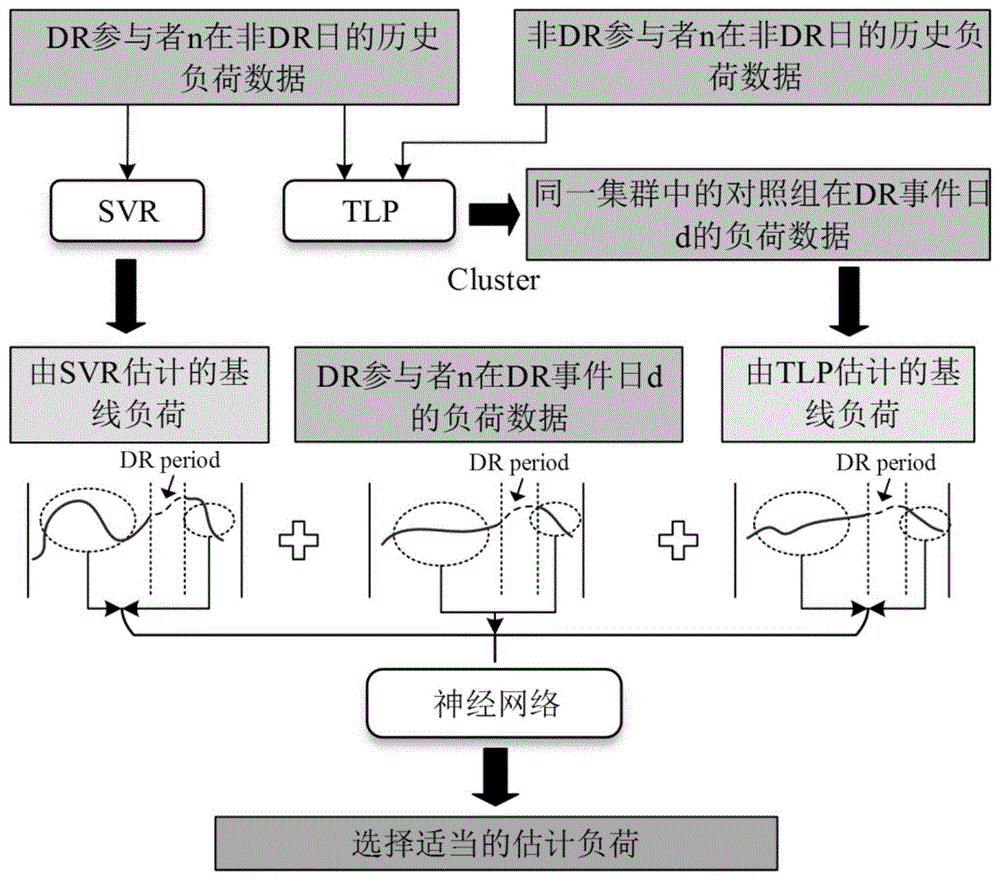
图1为本申请实施例的深度学习方法流程示意图。
图2为本申请实施例的横向联邦学习方法流程示意图。
图3为本申请实施例的数据集划分示意图。
图4为本申请实施例的各种方法性能指标数据分布示意图。
图5为本申请实施例的各种方法估计的基线负荷与实际的基线负荷示意图。
图6为本申请实施例的各种方法估计的基线负荷与实际的基线负荷示意图。
图7为本申请实施例的深度学习与横向联邦学习的训练标签预测准确率示意图。
图8为本申请实施例的三种学习率方法的训练标签预测准确率示意图。
具体实施方式
为了使本发明的目的,技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明,即所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。通常在此处附图中描述和示出的本发明实施例的组件可以以各种不同的配置来布置和设计。
因此,以下对在附图中提供的本发明的实施例的详细描述并非旨在限制要求保护的本发明的范围,而是仅仅表示本发明的选定实施例。基于本发明的实施例,本领域技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。
参考图1与图2,一种基于自适应联邦学习的需求响应基线负荷估计方法,包括以下步骤:
步骤1:提出了一种基于深度学习的居民用户基线负荷估计方法,用于区分各种条件并智能地从基于历史数据和非参与者数据的基线负荷估计中选择合适的估计值。该框架不仅提供了一种利用需求响应参与者的历史负荷数据和非参与者的负荷数据的特殊方法,而且具有简单和可扩展性;
步骤2:为了保护用户的数据隐私,构建了横向联邦学习框架以使用存储在本地数据集中的样本来训练神经网络。在该框架中,局部神经网络模型的参数通过中央服务器上的Fedavg算法进行聚合,而不是共享私人用户信息;
步骤3:在联邦学习框架中,提出了一种自适应学习率方法,用于居民用户基线负荷选择任务,以提高在低全局聚合频率下本地神经网络的性能。
进一步的,步骤1提出了一种基于深度学习的居民用户基线负荷估计方法,用于区分各种条件并智能地从基于历史数据和非参与者数据的基线负荷估计中选择合适的估计值。
所提出的深度学习方法提供了一个特别的流程来使用需求响应参与者和非参与者数据,其中神经网络的输入是通过回归方法使用历史数据估计的基线负荷、需求响应参与者的负荷,以及通过非参与者使用对照组方法估计的基线负荷。支持向量回归方法的输入是需求响应参与者n在需求响应事件前的几个非事件日的负荷数据。支持向量回归方法的输出是每日估计的基线负荷。例如,如果选择了X个非事件日的历史负荷来估计居民用户基线负荷,并且需求响应事件周期的时间点数量为S,样本数为M。有S个支持向量回归模型来拟合历史数据,每个回归模型对应需求响应周期内的一个时间槽。对于每个回归模型,输入维度为{M,X},输出维度为{M,1}。
对于典型负荷模式聚类方法,其过程如下:首先,通过对非事件日的历史负荷进行平均,确定所有用户(包括需求响应参与者和非参与者)的典型负荷模式。考虑到天气条件对最近历史负荷曲线的影响,考虑的历史天数通常限制在需求响应事件前的一个月内,本发明将其设置为5天。随后,使用K-means聚类方法将所有用户基于其典型负荷模式分成多个簇。K-means聚类的输入是所有用户的负荷模式,该算法通过欧氏距离将数据点分配给最近的簇质心,并在收敛时更新质心。簇的数量可以根据用户总数在2到20之间进行调整。最后,通过对同一簇内的控制组在需求响应事件当天的负荷进行平均,计算每日估计的基线负荷。
设T表示一个需求响应事件日的时间点集合。T可以进一步分为两部分:需求响应事件周期(用δ表示)和非需求响应事件周期(用δ
不同于负荷预测,居民用户基线负荷估计通常用于确定需求响应计划的补偿结算。对于基于激励的需求响应计划,每个参与需求响应的参与者的经济补偿是固定或时变激励价格与需求响应事件期间负荷减少量的乘积。在这种情况下,负荷预测旨在准确预测负荷曲线,而居民用户基线负荷估计侧重于准确的补偿结算。本发明中,居民用户基线负荷估计的评估使用了多种指标,其中使用平均绝对误差(MAE)作为精度的度量指标,使用偏差作为准确性的度量指标。MAE反映了在每个时间段估计值和实际居民用户基线负荷值之间的平均偏差,其为绝对值。偏差反映了所有时间段的估计值和实际居民用户基线负荷值的累积偏差,可能为正或负。单一评估指标,如MAE,可能无法提供对居民用户基线负荷估计方法性能的适当评估。例如,所有时间段的累积正误差可能导致显著的补偿结算误差。此外,不同数据条件下方法的稳定性对于居民用户基线负荷估计也很重要,因为不稳定的估计可能会对用户参与未来需求响应事件产生不利影响。因此,深度学习方法的基线选择取决于居民用户基线负荷估计的综合性能,该性能通过多个指标进行衡量,包括精度、准确性和多变性。
居民用户基线负荷估计的精度由MAE来衡量,即估计基线和实际基线之间差值的平均绝对值,如下式所示:
式中:MAE
然后,引入Bias来衡量居民用户基线负荷估计的准确性,它是估计基线和实际基线之间差值的平均值,如下式所示:
式中:Bias
接下来,引入多变性来评估居民用户基线负荷估计方法的稳定性,它通过相对误差比(RER)来衡量。RER是估计误差的标准差与需求响应事件期间平均负荷之比,表示如下:
RER
式中:RER
除了上述提到的MAE、Bias和RER之外,本发明引入了综合性能指标(OPI)来对居民用户基线负荷估计方法进行综合评估。需求响应参与者n在需求响应事件日d的OPI定义如下:
式中:
深度学习方法的基线选择基于支持向量回归方法和典型负荷模式聚类方法的OPI(O=O
神经网络的输出是一个向量Q
进一步的,步骤2构建了横向联邦学习框架以使用存储在本地数据集中的样本来训练神经网络。
联邦学习是一种适用于提出的基线负荷估计的深度学习方法的特殊形式的分布式学习。由于隐私问题的考虑,该模型只能使用每个本地数据集进行训练,其中本地数据的大小和特征可能会有所不同。使用本地数据进行训练可能会导致偏差的结果,而联邦学习可以通过捕捉不同数据集之间的共同模式和特征来提高本地模型的性能。在联邦学习中,每个本地联邦学习参与者只共享其本地模型的更新,而不是完整的数据集,以更好地保护用户隐私和数据安全。
整个联邦学习的学习过程分为本地训练和全局聚合两个步骤:
1)本地训练:每个本地数据集的代理随机初始化神经网络的参数,并使用本地数据进行本地训练。在进行一定次数的本地训练后,本地的参数将被上传到中央服务器。
2)全局聚合:在每次全局聚合中,中央服务器获取本地神经网络的参数,然后使用FedAvg算法更新全局神经网络。完成一次全局聚合后,更新后的全局参数将分发给每个联邦学习参与者进行新一轮的本地模型训练。全局聚合步骤对于联邦学习的成功非常关键,因为它允许联邦学习参与者在保护数据隐私和安全的同时共同学习。通过聚合本地模型,全局模型可以捕捉不同数据集之间的共同模式和特征,从而提高性能和泛化能力。
设K表示联邦学习参与者的数量,联邦学习的目标函数如下所示:
式中:x表示神经网络的输入,y表示真实标签。
本地神经网络的参数更新如下:
式中:
当本地更新步骤t=τ时,每个本地神经网络的参数将上传到中央服务器进行全局聚合。由于联邦学习参与者之间的本地训练集大小不同,全局神经网络的参数将作为所有联邦学习参与者的本地神经网络的加权平均值确定。对于每个参与者的本地神经网络,分配的权重与总数据量与该参与者本地数据集大小的比例成正比。具体计算如下:
式中:
假设所有本地采样集合被整合成一个集中式集合。令
式中:ω
进一步的,步骤3提出了一种自适应学习率方法,以提高在低全局聚合频率下本地神经网络的性能。
传统的深度学习自适应学习率是随着更新步骤的增加而减小学习率,以改善学习过程中的稳定性,表达式如下:
式中:η
实际上,由于经济标准、能源消费习惯等各种因素,不同用户的负荷曲线可能存在差异。因此,本地模型的显著差异可能导致全局聚合的不稳定性,全局模型可能关注偏差的共同特征。为了解决这个问题,在提出的基于联邦学习的居民用户基线负荷估计任务中设计了一种改进的自适应学习率方法,以减少性能损失。居民用户基线负荷的选择是基于支持向量回归方法和典型负荷模式聚类方法中最大的OPI值。然而,在某些情况下,支持向量回归和典型负荷模式聚类所估计的基线负荷可能相似,因此这两种方法的OPI值可能相似。与两种方法的OPI值显著不同的情况相比,对于神经网络来说,正确选择具有相似OPI值的居民用户基线负荷较不重要。因此,所提出的自适应学习率方法的关键思想是增加重要样本(即两种居民用户基线负荷估计方法的OPI值显著不同)的学习率,并降低不重要样本(即两种居民用户基线负荷估计方法的OPI值相似)的学习率。在深度学习中,模型训练是通过随机选择包含一定数量样本(即32个样本)的小批量数据进行的。第k个联邦学习参与者的学习率计算如下:
式中:η
中央服务器不拥有每个联邦学习参与者的抽样数据。因此,每个局部模型通过计算本地样本的平均绝对差异来得到,如下式所示:
然后,每个联邦学习参与者的
最后,
案例分析:
本发明使用的数据来自“低碳伦敦”项目。该项目收集了2011年11月28日至2014年2月28日期间,时间间隔为30分钟的5547个居民用户的负荷数据。项目中的用户被分为两组:分时电价用户组和标准用户组。为了评估所提出方法在各种条件下的有效性,选择了标准用户组在2013年全年的负荷数据作为本研究的数据集。在评估过程中使用的基准真实值是非参与需求响应活动的参与者在类需求响应事件日(即在没有需求响应事件的情况下显示相似条件的日子)的实际负荷。该数据集包含不同季节中展现出明显负荷形状差异的居民用户的负荷曲线。利用这个数据集可以评估所提出方法在不同季节的性能和稳健性,并考虑到居民用户负荷模式在一年中的变化。原始数据集中存在重复数据和缺失值。因此,采用数据处理方法对原始数据集进行处理。具体而言,删除具有相同时间标签和负荷值的重复数据。然后,排除每日负荷数据中缺失值超过4个的数据。接下来,使用下式处理每日负荷数据中缺失值少于4个的情况。
式中:l
1)类需求响应事件日的选择(即具有与实际需求响应事件日相似条件但没有需求响应事件的日子):在实验中,将类需求响应事件日的实际负荷视为基准真实值。首先,计算全年所有客户的每日聚合负荷,得到365个聚合每日负荷曲线。然后,记录与聚合每日负荷中排名前10的数值相对应的时间段,得到一个包含3650个数字的列表。从该列表中,选择在排名前10的数字中连续的时间段,重点关注出现频率最高的时间段。这些选定的连续时间段被定义为需求响应事件时段。对于这些类需求响应事件日,选择18:00至20:30的2.5小时作为需求响应事件时段,即在一个需求响应事件中有5个时间段。最后,为了确定类需求响应事件日,从需求响应事件时段内的聚合每日负荷中选择具有最高用电量的前50天。这些选定的日子反映了高用电量的情况,与实际需求响应事件非常相似。
2)训练集、验证集和测试集的划分:所提出的水平联邦学习方法和回归方法需要训练集用于拟合模型,验证集用于调整参数,测试集用于测试性能。本发明中三个数据集的划分如图3所示。
从下表中可以看出,训练集和验证集中的需求响应参与者是相同的,而训练集和验证集中的类需求响应事件日是不同的。为了测试神经网络的泛化能力,测试集中的客户和类需求响应事件日与训练集和验证集中的不同。具体来说,将客户分为六组,包括五组用于训练和验证,对应于图3中的M个代理,还有一组用于测试,对应于测试代理。每个组中的需求响应客户数量如下表所示。此外,随机选择10个事件样式日作为验证日,再随机选择10个事件样式日作为测试日。最后,剩下的30个事件样式日被视为训练日。
3)基准方法:为了验证所提出方法的有效性,本发明引入了8种基准方法,包括6种知名的CBL估计方法:High5of10;Mid4of6;Low5of10;典型负荷模式聚类法(typical loadpattern cluster);同步模式匹配法(SPM);支持向量回归法(support vectorregression),以及两种最新的CBL估计方法:协同优化法(CO-optimization)和时空回归法(Spatio-temporal regression)。
①传统的基于历史数据的CBL估计方法:High5of10、Mid4of6、Low5of10和支持向量回归属于传统的基于历史数据的CBL估计方法。这些方法使用需求响应事件前的非事件日的负荷数据来估计CBL。High5of10从10个非事件日中选择负荷最高的5天。Mid4of6从6个非事件日中选择4天,排除负荷最高和负荷最低的一天。Low5of10从10个非事件日中选择负荷最低的5天。支持向量回归选择需求响应事件前的5个非事件日的日负荷作为模型的输入。支持向量回归的参数通过网格搜索方法进行优化。为了确定最佳参数,考虑了一系列候选正则化参数[0.001,0.01,0.1,1,10,100]和核系数[0.001,0.01,0.1,1,10,100]。根据径向基函数(RBF)核在验证数据集上的最佳性能,选择了最佳参数。在我们的实验中,最佳参数确定为正则化参数C=0.01和核系数gamma=1。
②传统的基于非参与者数据方法:典型负荷模式聚类和同步模式匹配属于非参与数据方法。为了保证这两种方法的性能,将控制组与需求响应组的大小比例设置为3。例如,在测试集的348个客户中,随机选择了116个需求响应参与者,剩下的232个客户被视为控制组。本发明介绍了K均值聚类方法,聚类数设置为5。典型负荷模式聚类使用历史典型负荷模式对非参与者进行聚类。在本发明中,典型负荷模式通过对需求响应事件前的5个非事件日的日负荷进行平均计算得到。同步模式匹配使用需求响应事件日非事件期间的负荷数据将非参与者分组为5个簇。同步模式匹配中权重优化问题的目标是最小化非事件期间负荷的平均绝对误差(MAE)。使用Python 3.8中的Gurobi求解器优化同一簇中控制组所有客户的权重。
③协同优化方法:在协同优化中,需求响应事件日的基线负荷通过对需求响应事件前的5个非事件日的日负荷和需求响应事件后的5个非事件日的日负荷进行加权平均计算得到。协同优化中权重优化问题的目标是最小化非事件期间负荷的平均绝对误差(MAE)和偏差(Bias),该问题同样通过Gurobi求解。
④时空回归法:时空回归法使用了历史数据和非参与数据。具体而言,时空回归法方法将需求响应事件前3个非事件日的需求响应事件期间的负荷数据、需求响应事件日非事件期间(即需求响应期间前后的5个时间段)的负荷数据以及在同一簇中控制组的负荷数据的需求响应期间作为LASSO回归方法的输入。
⑤提出的深度学习和自适应联邦学习方法:深度学习的学习率设置为0.005。在自适应学习的上下文中,学习率和放大参数v对神经网络的性能有重要影响。较小的学习率被认为对提高收敛性很重要,因此选择了学习率为0.0001的值。此外,v被设置为13以进一步优化自适应学习过程。为了高效处理训练数据,使用了批量大小为512。神经网络的大小是一个关键因素,关于所提出的神经网络结构和超参数的详细信息在下表中显示。在联邦学习中,模型测试频率和全局聚合频率都设置为20轮。
/>
在下表中,展示了提到的11种方法进行的CBL估计结果的比较,其中给出了MAE、Bias和RER的平均值、最大值、最小值和标准差。从表中可以明显看出,所提出的联邦学习方法在与其他CBL估计方法相比中实现了最低的MAE和OPI值。此外,所提出的自适应联邦学习方法在考虑的CBL估计方法中展示了最低的MAE、Bias和RER最大值。此外,所提出的自适应联邦学习方法的MAE、Bias和RER的标准差值是比较的CBL估计方法中最低的。总体而言,这些发现表明所提出的自适应联邦学习方法在性能方面优于其他CBL方法。
为了进一步验证所提出的联邦学习方法的高效性和优越性,图4展示了这些基线负荷估计方法在测试集中的MAE、Bias和RER的分布情况。示意图清晰地说明了所提出的联邦学习方法的显著优势,即在各种条件下能够有效减少性能指标中的异常值,并提高基线负荷估计结果的准确性和精度。虽然两种最先进方法的平均MAE值似乎很小,但它们可能会生成明显错误的基线值,导致配电网络运营商经济损失或部分需求响应参与者的意愿减少。相比之下,所提出的自适应联邦学习方法通过智能选择由支持向量回归和典型负载模式聚类方法估计的适当基线负荷结果来解决这个问题,如图5和图6所示。
图7展示了横向联邦学习和本地深度学习在测试集中的标签预测准确率。示意图显示,联邦学习的训练过程具有更大的稳定性,从而显著提高了标签预测的准确率。这意味着联邦学习有效地缓解了由于有限的本地数据而产生的模型过拟合问题。
为了验证提出的自适应联邦学习方法的优越性,对比了提出的方法、一个使用固定学习率的传统联邦学习方法以及另一个使用递减学习率的传统联邦学习方法。传统联邦学习方法的学习率设置为0.001,递减联邦学习方法的初始学习率设置为0.002。模型参数的全局聚合频率设置为100个epochs。比较结果如图8所示。从示意图中可以明显看出,当模型的全局聚合频率较低时,与两种传统联邦学习方法相比,提出的自适应联邦学习方法确保了更稳定的学习过程。
以上是本发明的较佳实施例,凡依本发明技术方案所作的改变,所产生的功能作用未超出本发明技术方案的范围时,均属于本发明的保护范围。
- 多重复合交互需求响应的用户基线负荷估计方法及系统
- 基于负荷分类的电力需求响应基线计算方法的选取方法