基于AdaBoost改进的神经网络水质参数预测建模方法
文献发布时间:2023-06-19 19:27:02
技术领域
本发明涉及一种水质参数建模方法,具体涉及一种基于AdaBoost改进的神经网络水质参数预测建模方法。
背景技术
针对水质参数的监测,大多数传统的化学方法普遍存在价格昂贵、操作复杂且分析时间长,还需要消耗试剂,容易造成对水体的二次污染等问题。在实际应用中,水体类型复杂多变,衡量水质的参数也多种多样。水环境的污染因素具有复杂性、随机性和综合性,不同水质的污染源和影响因素不同,导致光谱数据也千变万化。
如图1所示,现有用于水质参数建模的反向传播神经网络(backpropagationneuralnetwork,BPNN),具有较强的非线性拟合能力,可以将学习成果运用于新知识的能力。但用于水质参数建模的反向传播神经网络存在“过拟合”现象、容易陷入局部极值,导致反向传播神经网络训练失败的缺点。
发明内容
本发明的目的是解决现有水质参数建模用BPNN神经网络存在“过拟合”现象及容易陷入局部极值而导致网络训练失败的技术问题,而提供一种基于AdaBoost改进的神经网络水质参数预测建模方法,能够按比例组合多个BPNN模型的预测结果,取长补短,从而降低误差、提高模型的稳定性。
为解决上述技术问题,本发明所采用的技术方案为:
基于AdaBoost改进的神经网络水质参数预测建模方法,其特殊之处在于,包括以下步骤:
1)对测得的水质样本数据进行预处理;将预处理后的样本集划分为训练集和测试集;其中训练集为
2)初始化步骤1)中所得的训练集中m个的样本权重,使用AdaBoost算法训练J个弱预测器后,得到水质参数浓度强预测器;所述AdaBoost算法中的弱预测器采用BPNN水质参数浓度预测模型;
3)使用测试集数据对强预测器进行测试,得到水质参数浓度预测模型。
进一步地,步骤2)具体为:
2.1)初始化步骤1)中所得的训练集中m个样本权重
2.2)采用BPNN水质参数浓度预测模型,对步骤2.1)初始化后的m个训练集
其中,err
2.3)设置误差阈值t,权重因子s,J个弱预测器的误差因子,并将第j个误差因子E
2.4)根据步骤2.2)中所得的err
W
当err
当err
其中,W
2.5)归一化步骤2.4)所得的样本权重:
2.6)计算第j个弱预测器权重
2.7)根据步骤2.6)中所得的第j个弱预测器权重
进一步地,步骤3)具体为:
将步骤1)中得到的测试集代入步骤2.7)所得的强预测器中,输出预测结果,得到水质参数浓度预测模型。
进一步地,还包括步骤4):评估水质参数浓度预测模型;
使用RMSEP和R
与现有技术相比,本发明技术方案的有益效果是:
1、本发明基于AdaBoost改进的神经网络水质参数预测建模方法,采用AdaBoost算法对传统BPNN建模进行改进后,针对各类水体中水质参数建模,使使得水质参数浓度预测模型具备良好的非线性拟合能力及预测稳定性,还可以更好的适用于各类水体、各类水质参数预测中,还解决了使用BPNN建模时容易陷入局部极值导致网络训练失败的技术问题的问题。
2、本发明基于AdaBoost改进的神经网络水质参数预测建模方法,结合BPNN较强的非线性拟合能力,改善了BPNN建模泛化能力弱的问题,AdaBoost能够按比例组合多个BPNN模型的预测结果以降低误差,增强了水质参数模型预测的稳定性,提升了水质参数浓度预测精度。
3、本发明基于AdaBoost改进的神经网络水质参数预测建模方法,具有测量方便快捷、无需引入其他试剂等优点,不会对水体产生二次污染,因此可以用于水质参数浓度的测量。该方法利用测量物质吸收紫外可见光谱辐射的原理,将光谱数据代入预测模型对新样本的浓度进行预测,灵敏度高、准确度好。
4、本发明基于AdaBoost改进的神经网络水质参数预测建模方法,能够将混合溶液样本中TOC浓度的预测结果由R
附图说明
图1为现有AdaBoost算法示意图。
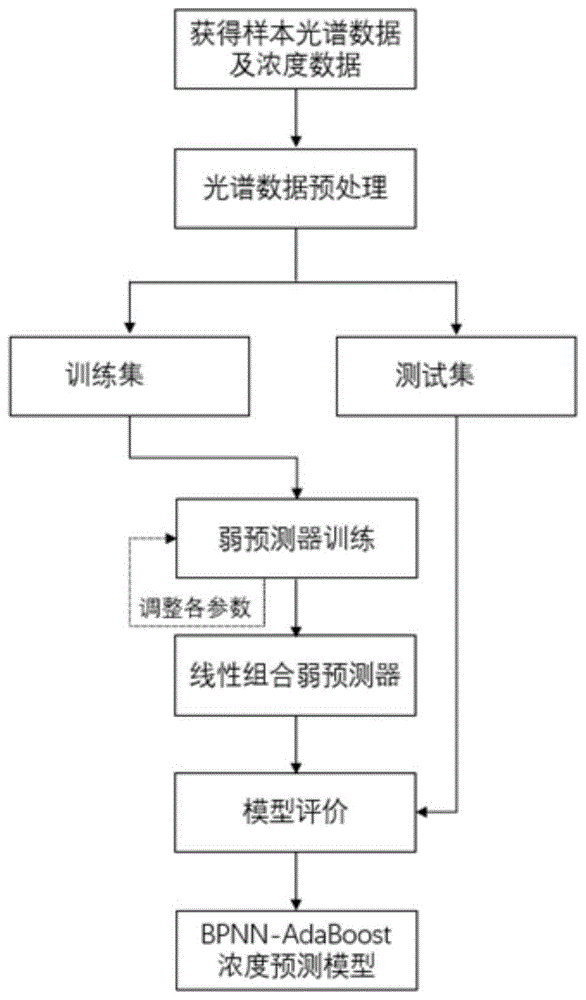
图2为本发明基于AdaBoost改进的神经网络水质参数预测建模方法中,BPNN-AdaBoost浓度预测模型建模流程图。
图3为本发明基于AdaBoost改进的神经网络水质参数预测建模方法实施例中,50个TOC浊度混合溶液原始光谱曲线图。
图4为本发明基于AdaBoost改进的神经网络水质参数预测建模方法实施例中,经光谱信息提取后的部分TOC浊度混合溶液光谱曲线图。
图5为使用传统的BPNN建模后,预测样本中TOC浓度的预测结果示意图。
图6为本发明基于AdaBoost改进的神经网络水质参数预测建模方法实施例中,预测样本中TOC浓度的预测结果示意图。
具体实施方式
如图1所示,现有的AdaBoost算法原理是通过调整训练集m个样本的权重和弱预测器权值,组合弱预测器形成一个强预测器。基于m个样本的训练集训练弱预测器,每次下一个弱预测器都是在上一个样本的不同权值集上训练获得的。每个样本的权重由其学习效果决定,而学习效果是经过前面步骤中的弱预测器的输出估计得到的。
使用基于AdaBoost改进的神经网络水质参数预测建模方法,对水质参数浓度进行建模预测的基本思路是:
首先,对测得的样本数据进行预处理,初始化样本权重后,使用BPNN作为弱预测器对预处理后的训练集数据训练,得到弱预测器权重,并根据预测结果对样本权重进行调整,再进入下一轮的弱预测器训练;达到预设的迭代次数后,对所有弱预测器的预测结果依据弱预测器权重进行线性组合,得到最终的强预测器;最后,使用测试集数据对强预测器的预测效果进行评价。
本发明在对上述算法进行验证及评价时,将样本数据一部分作为训练集建立模型,另一部分作为测试集,对模型的预测准确性进行验证,最后得到以BPNN为弱预测器的AdaBoost算法水质参数浓度预测模型。
如图2所示,本发明的AdaBoost算法具体步骤为:
步骤1)对测得的水质样本数据进行预处理;将预处理后的样本集划分为训练集和测试集;其中训练集为
本实施例中,获取样本集的紫外可见光谱数据;对紫外可见光谱数据进行预处理,去除由仪器产生的噪声及液体中固体沉淀物质颗粒对紫外可见光谱曲线产生的影响;将样本划分为训练集和测试集。
2)初始化步骤1)中所得的训练集中m个的样本权重后,使用AdaBoost算法训练J个弱预测器后,得到水质参数浓度强预测器;所述AdaBoost算法中的弱预测器采用BPNN水质参数浓度预测模型;
2.1)初始化步骤1)中所得的训练集
2.2)采用BPNN水质参数浓度预测模型,结合步骤2.1)初始化后的m个样本权重对训练集
其中,err
2.3)设置误差阈值t,权重因子s,J个弱预测器的误差因子,并将第j个误差因子E
2.4)根据步骤2.2)中所得的err
W
当err
当err
其中,W
2.5)归一化步骤2.4)所得的样本权重:
2.6)计算第j个弱预测器权重
由
2.7)根据步骤2.6)中所得的第j个弱预测器权重
步骤3)使用测试集数据对强预测器的预测效果进行评价,得到水质参数浓度预测模型。
将步骤1)中得到的测试集代入步骤2.7)所得的强预测器中,输出预测结果,得到水质参数浓度预测模型。
步骤4):评估水质参数浓度预测模型;
在进行准确率评估时主要基于验证参数的均方根误差(RMSEP)和决定系数(R
为了进一步说明本发明基于AdaBoost改进的神经网络水质参数预测建模方法,举例如下:
使用TOC浊度混合溶液对提出的BPNN-AdaBoost建模预测方法进行验证。其中TOC的浓度范围为0.1-0.9mg/L,浓度间隔为0.2mg/L;浊度的浓度范围为0.5-5NTU,浓度间隔为0.5NTU,溶液中两种物质的浓度排列组合,获得共计50个样本。该50个样本的原始光谱曲线如图3所示;经预处理后的TOC浓度为0.3mg/L、浊度浓度范围为0.5-5NTU的样本光谱曲线如图4所示,其具体对应的浓度值见图例。从图3与图4中可以看出,在TOC浓度相同色度浊度不同的情况下,浊度会对样本的全谱段光谱曲线产生明显影响。
从50个样本中随机选取了10个样本作为测试集,其余40个样本作为训练集。对比了仅使用传统BPNN和提出的BPNN-AdaBoost方法建模预测样本中TOC浓度的预测结果,在两种建模方法下,BPNN的各项参数设置保持一致。通过预测结果计算的R
表1不同方法预测混合溶液样本中TOC浓度结果对比
上述实验中,由表1可以看出,在使用提出BPNN-AdaBoost后,其预测结果较传统BPNN有明显提升,具体表现为R
两种建模预测方法下,测试集10个样本预测值与其实测值的相对误差如图5、图6所示,也可看出采用BPNN-AdaBoost方法建模预测的结果优于传统BPNN建模的预测结果,采用BPNN进行预测时个别样本的相对误差超过100%,也说明采用BPNN-AdaBoost方法建模预测的稳定性较高。本实施例中,将混合溶液样本中TOC浓度的预测结果由R
- 基于近邻神经网络的油藏地质建模静态参数分布预测方法
- 基于近邻神经网络的油藏地质建模静态参数分布预测方法