信息处理方法以及信息处理装置
文献发布时间:2023-06-19 10:06:57
技术领域
本发明涉及进行需求的预测的技术。
背景技术
使用移动体来提供服务的研究正在进行。例如,通过向用户处派遣作为移动店铺发挥功能的自主移动体(移动店铺车辆),能够提高购物的便利性。另外,通过使可自主行驶的合乘汽车行驶,能够提高交通的便利性。
在通过这样的移动体进行营业的情况下,优选预测要发生的需求,决定移动体的配置场所、营业体制。例如,如专利文献1公开那样,能够使用机械学习算法,进行需求的预测。
现有技术文献
专利文献
专利文献1:日本特开2019-109648号公报
发明内容
用于进行机械学习的模型能够使用过去利用服务时的数据(购买数据等)来学习。但是,在想要将不存在服务的提供实绩的区段作为对象进行需求的预测的情况下,存在得不到充分的预测精度这样的问题。
本发明是考虑上述课题而完成的,其目的在于高精度地进行无服务的提供实绩的区段中的需求预测。
本发明所涉及的信息处理方法是预测移动体提供的服务的需求的信息处理装置执行的信息处理方法。
具体而言,其特征在于,包括:分类步骤,使用第一分类模型将第一区段所包含的多个单位区域分别分类为多个类别;第一构筑步骤,根据分类出的所述类别和所述第一区段中的实绩数据,决定针对所述多个类别的各个类别应用的第一参数组,从而构筑第一需求预测模型;第二构筑步骤,使用所述第一分类模型具有的分类基准来构筑第二分类模型,使用所述第一参数组来构筑第二需求预测模型;以及预测步骤,使用所述第二分类模型和所述第二需求预测模型,进行第二区段中的需求预测。
另外,本发明所涉及的信息处理装置是预测移动体提供的服务的需求的信息处理装置。
具体而言,其特征在于,具有控制部,该控制部执行:使用第一分类模型将第一区段所包含的多个单位区域分别分类为多个类别;根据分类出的所述类别和所述第一区段中的实绩数据,决定针对所述多个类别的各个类别应用的第一参数组,从而构筑第一需求预测模型;使用所述第一分类模型具有的分类基准来构筑第二分类模型,使用所述第一参数组来构筑第二需求预测模型;以及使用所述第二分类模型和所述第二需求预测模型,进行第二区段中的需求预测。
另外,本发明的其他方案是用于使计算机执行上述信息处理装置执行的信息处理方法的程序、或者、非临时地存储该程序的计算机可读存储介质。
根据本发明,能够高精度地进行无服务的提供实绩的区段中的需求预测。
附图说明
图1是示出利用机械学习进行的需求预测的概要的图。
图2是第一实施方式所涉及的信息处理装置的结构概略图。
图3是说明存储于数据存储部的数据的图。
图4是说明学习阶段中的处理的图。
图5是说明预测阶段中的处理的图。
图6是示出信息处理装置之间的数据流程的图。
图7是第二实施方式所涉及的信息处理装置的结构概略图。
图8是在第二实施方式中学习部以及预测部进行的处理的流程图。
图9是说明第二实施方式的变形例的图。
(符号说明)
100:信息处理装置;101:存储部;101A:模型存储部;101B:数据存储部;102:控制部;1021:学习部;1022:预测部;1023:导出部;1024:导入部;103:输入输出部。
具体实施方式
考虑通过可自主行驶的移动体提供服务的方式。例如,能够将在车辆内具有用于店铺营业的设施、设备的移动店铺车辆派遣至预定的区段,将设施、设备展开来进行营业。另外,通过可自主行驶的移动体,还能够提供旅客、货物的运送服务。
具有店铺功能的自主移动体进行营业的区段、地点、具有客货运送功能的自主移动体的车辆调度目的地能够根据需求决定。例如,通过使用与对象区段的特征、天气、时间段等有关的数据、和与实际上发生的需求有关的数据(例如表示销售额的数据。以下实绩数据)进行机械学习,能够预测在某个条件下发生何种程度的需求。
但是,在新开始服务的区段等完全无服务的提供实绩的区段中,有无法使用机械学习进行需求的预测的情况。虽然也可以通过在有实绩的区段中发生的数据构筑机械学习模型,但在区段的特性不同的情况下,未必能得到预期的结果。
在本实施方式中,提供用于应对该问题的、预测移动体提供的服务的需求的信息处理方法。
具体而言,使用第一分类模型将第一区段所包含的多个单位区域分别分类为多个类别,根据分类出的所述类别和所述第一区段中的实绩数据,决定针对所述多个类别的各个类别应用的第一参数组,从而构筑第一需求预测模型。
然后,使用所述第一分类模型具有的分类基准来构筑第二分类模型,使用所述第一参数组来构筑第二需求预测模型,使用所述第二分类模型和所述第二需求预测模型,进行第二区段中的需求预测。
服务是指,提供移动的服务、提供资源的服务、提供空间的服务、销售商品的服务等只要是对消费者提供价值的服务,则可以是任意服务。
第一区段是有服务的提供实绩的区段,第二区段是无该服务的提供实绩的区段。
首先,将包含于第一区段的多个单位区域分类为多个类别。其原因在于,根据单位区域的特征,需求的预测方法将发生很大变化。然后,根据第一区段中的实绩数据,针对多个类别的每一个,生成用于进行需求预测的权重的集合(第一参数组)。
生成的权重的集合是专门用于在第一区段中生成的类别的例子,所以在想要将第二区段作为对象进行处理时,可能产生问题。
因此,在本实施方式所涉及的方法中,分类模型使用在将第一区段所包含的单位区域分类为类别时使用的分类基准,构筑第二分类模型。另外,使用第一参数组,构筑用于在第二区段中进行需求预测的模型。
根据上述结构,能够在第一区段和第二区段中,通过同一基准将单位区域分类为类别。即,能够直接利用专门用于类别的权重的集合,开始第二区段中的需求预测。
此外,也可以其特征在于,所述第一分类模型根据与所述单位区域所包含的设施或者建筑物关联起来的多个要素进行所述分类。
通过利用与消费者集中的设施、建筑物等关联起来的要素进行类别分类,能够可靠地表现出单位区域的特征。
另外,也可以根据分类出的所述类别和在所述第二区段中发生的实绩数据,决定针对所述多个类别的各个类别应用的第二参数组,从而构筑专门用于所述第二区段的第三需求预测模型。
在第二区段中开始服务之后,在第二区段中发生实绩数据,所以通过利用该实绩数据来构筑需求预测模型,能够期待提高预测精度。
另外,也可以其特征在于,在将所述第二区段作为对象进行需求预测时,根据在所述第二区段中发生的实绩数据的积累度,变更所述第二需求预测模型和所述第三需求预测模型的利用比例。
例如,也可以在第二区段中未充分发生实绩数据的期间中,增大第二需求预测模型的利用比例,随着在第二区段中发生的实绩数据的量增加,增大第三需求预测模型的利用比例。
另外,也可以其特征在于,在所述第二区段中发生的实绩数据被积累预定量以上的情况下,将在将所述第二区段作为对象进行需求预测时利用的模型,从所述第二需求预测模型切换为所述第三需求预测模型。
在第二区段中发生的实绩数据是否积累预定量以上既可以通过数据的总量判断,也可以通过利用该实绩数据进行的学习的次数(第三需求预测模型被更新的次数等)判断。
(第一实施方式)
参照图1,说明第一实施方式所涉及的信息处理装置的概要。本实施方式所涉及的信息处理装置是将表示进行商品或者服务的提供的实绩的数据(实绩数据)作为训练数据,构筑机械学习模型(以下预测模型),使用该预测模型,预测估计有何种程度的需求的装置。实绩数据是指,表示商品或者服务的提供实绩的数据,例如,包括商品、服务的内容、个数等。
预测模型将提供商品或者服务的区段特有的数据、和天气、时间段等一般的数据用作用于进行需求的预测的数据。将前者称为区段数据,将后者称为一般数据。区段数据例如是将对象区段分割为网格,表示每个网格的特征(例如在网格内存在的设施、建筑物的数量、类别、可停留人数等)的数据。一般数据例如是对象区段的天气、气温、对象时间段、在对象区段中存在的人的数量等。这些数据被变换为特征量,作为说明变量来使用。
在图1的例子中,在学习阶段中,在将从区段数据以及一般数据得到的特征量(成为需求预测的背景的特征量)分类成类别之后,针对每个该类别,生成参数(权重)。另外,在预测阶段中,将提供的特征量分类为类别,利用符合该类别的参数,进行需求预测。类别分类例如能够通过聚类等进行。这样,通过独立地进行类别分类和参数的生成,能够得到针对每个预测条件最佳化的参数。
但是,在用这样的方法,想要在不存在实绩数据的区段中进行需求的预测的情况下,产生几个问题。
例如,考虑使用利用在第一区段中发生的实绩数据来进行学习的预测模型,进行新开始服务的第二区段中的需求预测的情形。在该情况下,在第二区段中不存在实绩数据,所以考虑挪用利用在第一区段中发生的实绩数据构筑的预测模型。
但是,该预测模型具有的参数(权重)是专门用于使用与第一区段对应的特征量生成的类别的参数,所以即使仅挪用预测模型,也无法得到期望的结果。其原因为,在进行需求预测时生成的类别(使用与第二区段对应的特征量生成的类别)未必与在学习时使用的类别(使用与第一区段对应的特征量生成的类别)一致。在类别之间产生偏差的情况下,应用了不适合的参数,所以无法正确地进行需求预测。
以下,说明用于解决该问题的信息处理装置100。
图2是概略地示出使用机械学习算法进行需求的预测的信息处理装置100的结构的一个例子的框图。
信息处理装置100构成为包括存储部101、控制部102、输入输出部103。信息处理装置100由具有处理器以及存储器的一般的计算机构成。
存储部101是存储为了进行需求的预测而所需的数据的单元。具体而言,构成为包括存储机械学习模型的模型存储部101A、和存储用于进行机械学习的数据的数据存储部101B。此外,在存储部101中,还能够存储由后述控制部102执行的程序、该程序利用的数据等。存储部101由RAM、磁盘、闪存存储器等存储介质构成。
模型存储部101A存储机械学习模型。
在本实施方式中,作为机械学习模型,使用分类模型和预测模型。
分类模型是将成为需求预测的背景的信息分类为多个类别的模型。类别分类例如能够根据与区段数据对应的特征量、和与一般数据对应的特征量来进行。分类模型例如生成“关于在天气条件为X、时间段为Y时满足Z这样的地理上的条件的网格,分类为类别A”这样的分类基准。
另外,预测模型是关于被分类出的类别的各个,赋予针对多个说明变量的权重的模型。这些模型从初始状态启动,经由学习阶段随时更新。
模型的详细的学习方法以后叙述。
数据存储部101B是存储实绩数据、区段数据、一般数据的数据库。通过由处理器执行的数据库管理系统(DBMS)的程序管理存储于存储装置的数据,构筑这些数据库。在本实施方式中利用的数据库是例如关系数据库。
作为用于进行机械学习的数据,有如上述那样的、实绩数据、区段数据、一般数据。这些数据也可以从装置的外部经由存储介质、网络取得。
实绩数据是表示在对象区段中提供商品或者服务的实绩的数据。图3(A)是实绩数据的例子。实绩数据例如是表示商品、服务的内容、个数的数据,在服务是提供移动的例子的情况下,是表示人数、货物的个数、移动区间、销售额金额等的数据。
区段数据是表示关于包含于对象区段的多个网格的特征的数据。图3(B)是区段数据的例子。区段数据例如是通过数值表示在网格内存在的设施、建筑物的数量、类别(例如学校、商业设施、医院、车站等)、可停留人数(例如在设施是医院的情况下病床数、在是学校的情况下学生数、在是娱乐设施的情况下容纳人数等)等的数据。在本实施方式中,设为对象区段被预先分割为多个网格。
一般数据是通过数值表示日期、星期、时间段、天气等的数据。图3(C)是一般数据的例子。一般数据是与商品、服务的内容无关且通常可获得的数据。
此外,在以后的说明中,将变换实绩数据而得到的特征量称为实绩特征量,将变换区段数据而得到的特征量称为区段特征量,将变换一般数据而得到的特征量称为一般特征量。
控制部102是掌控信息处理装置100具有的功能的运算装置。控制部102能够通过CPU(Central Processing Unit,中央处理单元)等运算处理装置实现。
控制部102构成为具有学习部1021、预测部1022、导出部1023、导入部1024这四个功能模块。各功能模块也可以通过由CPU执行存储于存储部101的程序来实现。
学习部1021使用在第一区段中收集并存储到数据存储部101B的数据组,构筑分类模型以及预测模型。
预测部1022使用构筑的分类模型以及预测模型,进行需求预测。
导出部1023将已构筑的分类模型以及预测模型保持的参数保存为外部数据。
导入部1024取入由导出部1023保存的参数,反映到分类模型以及预测模型。
通过能够保存并取入各模型的特征,不经由学习过程也能够构筑模型,能够开始需求的预测。
说明各功能模块进行的处理的具体的内容。
首先,参照图4,说明学习部1021进行的模型的构筑方法。在此,在第一区段中,有提供商品或者服务的实绩,关联的数据(实绩数据、区段数据、一般数据)存储于数据存储部101B。
第一学习阶段(图4(A))是构筑分类模型的阶段。在第一学习阶段中,使用与第一区段对应的区段数据和一般数据来构筑分类模型。具体而言,将与在第一区段中发生的需求对应的所有区段数据变换为区段特征量。另外,将与在第一区段中发生的需求对应的所有一般数据变换为一般特征量。
区段特征量例如包括处于对应的网格内的建筑物的数量、类别、规模、容纳人员数、道路的类别、规模、总延伸、是否为城市化区域、其他网格的特征等。另外,一般特征量例如包括天气、日期、星期、时间段等。
接下来,使用区段特征量以及一般特征量,构筑分类模型。分类例如也可以通过聚类进行。聚类例如也可以用矢量表示区段特征量以及一般特征量,通过矢量之间的距离来进行。
通过上述处理,生成用于将处于特定的条件下的网格分类为类别的分类基准。
第二学习阶段(图4(B))是构筑预测模型的阶段。在第二学习阶段中,使用区段特征量、实绩特征量、一般特征量,进行预测模型的学习。
具体而言,将第一区段中的实绩数据抽出一个,将与其对应的区段特征量和一般特征量,输入到已构筑的分类模型。由此,输出决定的类别。接下来,将对象的实绩数据变换为特征量,与类别信息一起输入到预测模型,从而进行预测模型的学习。
通过将其针对所有实绩数据的记录项反复进行,针对每个类别,更新说明变量针对目的变量的权重。
接下来,参照图5,说明预测部1022进行的需求预测的方法。在此,设为与进行需求的预测的对象网格(预测对象网格)对应的区段数据、和与预测条件对应的一般数据存储于数据存储部101B。
预测部1022首先针对构筑的分类模型,输入与预测对象网格对应的区段特征量、和与预测条件对应的一般特征量,作为输出得到类别。接下来,将得到的类别输入到预测模型,取得所得到的输出,作为与预测的需求有关的数据。
接下来,说明导出部1023的功能。导出部1023将构筑的分类模型具有的分类基准、即表示“在被输入怎样的特征量的情况下,对应起来怎样的类别”的数据,保存为分类基准数据。另外,将构筑的预测模型具有的权重的组(即按照类别生成的针对说明变量的系数的组),保存为参数数据。
接下来,说明导入部1024的功能。导入部1024取入被保存的分类基准数据,应用于初始状态的分类模型。由此,能够得到与刚刚执行第一学习阶段之后的分类模型等效的模型。另外,导入部1024取入被保存的参数数据,应用于初始状态的预测模型。由此,能够得到与刚刚执行第二学习阶段之后的预测模型等效的模型。
通过能够针对分类模型以及预测模型实现数据的导出/导入,能够复制利用在第一区段中发生的数据学习而得的模型。
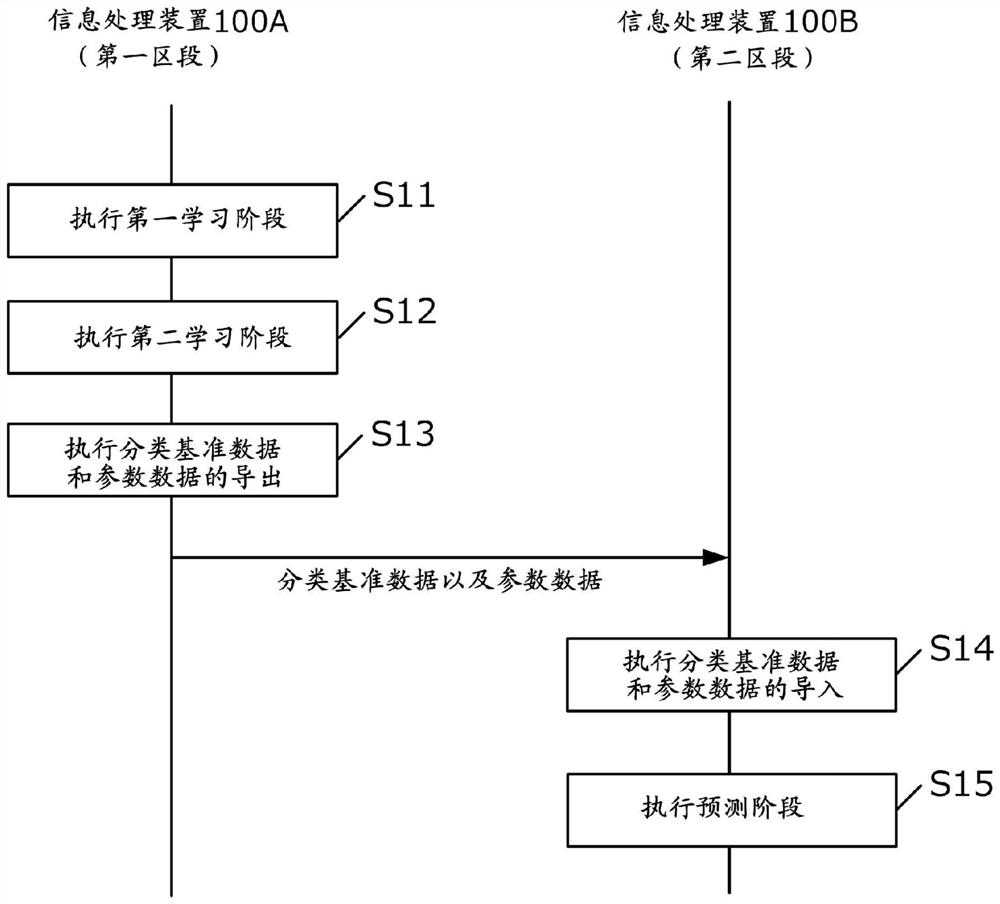
接下来,参照作为处理流程图的图6,说明直至根据在第一区段中发生的实绩数据在不存在实绩数据的第二区段中进行需求的预测为止的处理。图6所示的信息处理装置100A是将第一区段作为对象进行需求预测的装置,信息处理装置100B是将第二区段作为对象进行需求预测的装置。双方的装置既可以在地理上离开地设置,也可以通过网络等可通信地连接。
步骤S11~S13的处理由信息处理装置100A执行。
首先,在步骤S11中,学习部1021执行第一学习阶段。由此,构筑分类模型。
接下来,在步骤S12中,学习部1021执行第二学习阶段。由此,构筑预测模型。
接下来,在步骤S13中,导出部1023输出分类基准数据以及参数数据。如上所述,分类基准数据是表示分类模型具有的分类基准的数据。另外,参数数据是预测模型具有的表示每个类别的权重的组的数据。
输出的分类基准数据以及参数数据被传送给信息处理装置100B。
步骤S14~S15的处理由信息处理装置100B执行。
首先,在步骤S14中,导入部1024将接收到的分类基准数据应用于初始状态的分类模型。由此,信息处理装置100B利用的分类模型能够通过与信息处理装置100A利用的分类模型相同的基准,执行类别分类。
另外,导入部1024将接收到的参数数据应用于初始状态的预测模型。由此,信息处理装置100B利用的预测模型能够通过与信息处理装置100A利用的预测模型相同的参数(系数),进行针对说明变量的加权。
接下来,在步骤S15中,预测部1022使用构筑的分类模型以及预测模型,执行预测阶段。
根据以上说明的结构,能够使在信息处理装置100A进行类别分类时利用的基准、和在信息处理装置100B进行类别分类时利用的基准一致。预测模型是针对每个类别生成参数(权重组)的模型,所以仅通过从信息处理装置100A向信息处理装置100B拷贝作为学习结果的参数,无法正确地进行需求的预测。但是,根据本实施方式,能够使分类基准一致,所以即使在无实绩数据的第二区段中,也能够高精度地进行需求的预测。
(第二实施方式)
在第一实施方式中,信息处理装置100B使用从信息处理装置100A取得的参数数据,构筑预测模型。另一方面,在第二区段中开始服务之后,在第二区段中发生实绩数据,所以能够利用该实绩数据,构筑预测模型。
第二实施方式是除了在第一实施方式中生成的预测模型以外,还使用在第二区段中发生的实绩数据来生成新的预测模型,并切换双方的实施方式。
以下,将信息处理装置100A在步骤S12中生成的预测模型称为第一预测模型,将信息处理装置100B在步骤S14中生成的预测模型称为第二预测模型。另外,在本实施方式中,将信息处理装置100B生成的新的预测模型称为第三预测模型。实施方式中的第一~第三预测模型与本发明中的第一~第三需求预测模型对应。
图7是概略地示出第二实施方式中的信息处理装置100的结构的一个例子的框图。第二实施方式所涉及的信息处理装置100构成为模型存储部101A能够存储第一预测模型、第二预测模型、第三预测模型。
另外,在第二实施方式中,学习部1021A除了通过导入生成的第二预测模型以外,根据实绩数据,生成第三预测模型。
进而,预测部1022A根据积蓄的实绩数据的量,切换使用第二预测模型来进行需求预测、或者使用第三预测模型来进行需求预测。
在第二区段中积蓄的实绩数据少的情况下,相比于第三预测模型,使用第二预测模型能够进行精度良好的预测。另一方面,在第二区段中积蓄的实绩数据充分的情况下,认为相比于基于第一区段中的实绩数据的第二预测模型,使用基于在实地积蓄的实绩数据的第三预测模型能够进行精度更良好的预测。
因此,在第二实施方式中,在第二区段中积蓄的实绩数据的量低于阈值的情况、即第三预测模型的学习的程度低于预定值的情况下,预测部1022A使用第二预测模型来进行需求预测。另外,在第二区段中积蓄的实绩数据的量超过阈值的情况、即第三预测模型的学习的程度超过预定值的情况下,预测部1022A使用第三预测模型来进行需求预测。
图8(A)是学习部1021A进行的处理的流程图。该处理由学习部1021A周期性地执行。
首先,在步骤S21中,判定学习周期是否到来。关于学习周期,例如,以从上次的学习经过预定的时间新得到预定量的实绩数据等为触发判定,但不限于此。
在学习周期到来的情况下,在步骤S22中,使用积蓄的实绩数据(在第二区段中发生的实绩数据)来执行第二学习阶段,更新第三预测模型。此外,不进行分类模型的更新。
图8(B)是预测部1022A进行的处理的流程图。由预测部1022在进行需求预测的定时执行该处理。
首先,在步骤S31中,判定在数据存储部101B中是否积蓄有预定量以上的实绩数据(在第二区段中发生的实绩数据)。例如,能够通过与在第二区段内发生的实绩对应的记录项的数量,判定实绩数据的积蓄量。
在步骤S31中成为否定判定的情况下,处理转移到步骤S32,使用第二预测模型来实施需求预测。
在步骤S32中成为肯定判定的情况下,处理转移到步骤S33,使用第三预测模型来实施需求预测。
此外,在本例子中,在步骤S31中,通过实绩数据的量进行判定,但也可以根据利用在第二区段中发生的实绩数据进行学习的程度(学习次数等)是否为预定值以上,进行判定。
根据上述结构,能够使用在第二区段中发生的实绩数据,进一步提高需求预测的精度。
(第二实施方式的变形例)
在第二实施方式中,使用阈值,决定利用第二预测模型或者利用第三预测模型,但也可以并用双方的模型来进行需求预测。例如,也可以如图9所示,根据在第二区段中收集的实绩数据的量,动态地变更第二预测模型和第三预测模型的利用比率。
(变形例)
上述实施方式只不过是一个例子,本发明能够在不脱离其要旨的范围内适宜地变更而实施。
例如,在本公开中说明的处理、单元只要不产生技术上的矛盾,就能够自由地组合实施。
另外,说明由1个装置进行的处理也可以由多个装置分担执行。或者,说明由不同的装置进行的处理也可以由1个装置执行。在计算机系统中,能够灵活地变更通过怎样的硬件结构(服务器结构)实现各功能。
本发明还能通过将安装有在上述实施方式中说明的功能的计算机程序供给给计算机而该计算机具有的1个以上的处理器读出并执行程序来实现。这样的计算机程序既可以通过能够连接到计算机的系统总线的非临时性的计算机可读存储介质提供给计算机,也可以经由网络提供给计算机。非临时性的计算机可读存储介质例如包括磁盘(软盘(注册商标)、硬盘驱动器(HDD)等)、光盘(CD-ROM、DVD盘·蓝光盘等)等任意类型的盘、只读存储器(ROM)、随机存取存储器(RAM)、EPROM、EEPROM、磁卡、闪存存储器、光学式卡、适合于储存电子的命令的任意类型的介质。
- 信息处理方法、用于使计算机实施该信息处理方法的程序、实施该信息处理方法的信息处理装置及信息处理系统
- 位置确定处理装置、位置确定处理方法、位置确定处理程序、移动信息处理装置、移动信息处理方法、移动信息处理程序和存储介质