虚拟形象驱动方法、装置、电子设备和可读存储介质
文献发布时间:2023-06-19 12:21:13
技术领域
本申请涉及网络直播技术领域,具体而言,涉及一种虚拟形象驱动方法、装置、电子设备和可读存储介质。
背景技术
随着网络直播的发展,网络直播形式也越发多样。为了增加网络直播的趣味性,在直播界面上渲染虚拟形象的直播方式受到大众喜爱。在这种直播方式中,对于虚拟形象的驱动控制目前常采用的方式是采集主播的视频信息,基于视频信息中主播的肢体状态相应地控制虚拟形象进行随动。
目前采用的这种驱动控制方式可以便捷地实现对虚拟形象地控制,但是,在很多主播场景下,主播在直播过程中可能并未开启摄像头,因此,并不能采集到主播的视频信息。目前采用的驱动控制方式难以应用于缺乏主播的视频信息的应用场景下的虚拟形象控制。
发明内容
本申请的目的包括,例如,提供了一种虚拟形象驱动方法、装置、电子设备和可读存储介质,其能够基于流式音频数据实现虚拟形象的控制,可以满足对虚拟形象实时控制的需求。
本申请的实施例可以这样实现:
第一方面,本申请提供一种虚拟形象驱动方法,所述方法包括:
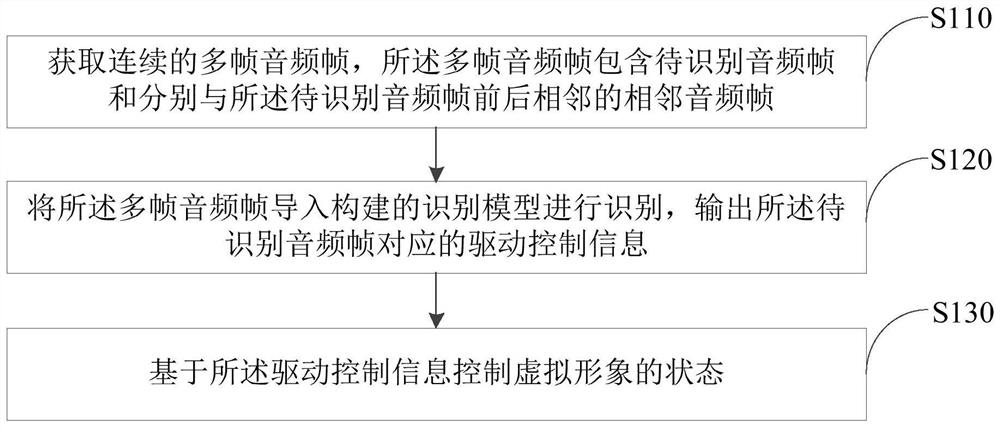
获取连续的多帧音频帧,所述多帧音频帧包含待识别音频帧和分别与所述待识别音频帧前后相邻的相邻音频帧;
将所述多帧音频帧导入构建的识别模型进行识别,输出所述待识别音频帧对应的驱动控制信息;
基于所述驱动控制信息控制虚拟形象的状态。
在可选的实施方式中,所述基于所述驱动控制信息控制虚拟形象的状态的步骤,包括:
获得所述驱动控制信息所指向的所述虚拟形象包含的多个关节中的目标关节;
基于所述驱动控制信息对所述目标关节进行姿态控制,以使所述虚拟形象的目标关节按所述待识别音频帧的语义指令进行姿态变化。
在可选的实施方式中,所述基于所述驱动控制信息对所述目标关节进行姿态控制的步骤,包括:
将所述驱动控制信息转换为三维空间中的旋转矩阵;
将所述旋转矩阵转换为四元数驱动信号;
基于所述四元数驱动信号在渲染引擎中对所述虚拟形象的目标关节进行姿态控制。
在可选的实施方式中,所述基于所述驱动控制信息控制虚拟形象的状态的步骤,包括:
基于所述驱动控制信息控制虚拟形象的嘴部特征的状态并播放所述待识别音频帧,以使所述嘴部特征的状态与朗读所述待识别音频帧的语音时的状态一致。
在可选的实施方式中,所述方法还包括:
获取从预先设置的多种形象风格中选择的目标形象风格;
获得所述目标形象风格对应的驱动信息,所述驱动信息为针对所述虚拟形象的肢体状态的信息;
根据所述驱动信息对所述虚拟形象的肢体状态进行驱动控制。
在可选的实施方式中,所述将所述多帧音频帧导入构建的识别模型进行识别的步骤,包括:
对各所述音频帧进行特征提取,获得各所述音频帧的MFCC特征;
将各所述音频帧的MFCC特征导入构建的识别模型进行识别。
在可选的实施方式中,所述将各所述音频帧的MFCC特征导入构建的识别模型进行识别的步骤,包括:
对获得的多帧音频帧的MFCC特征进行归一化处理,以使各所述音频帧的MFCC特征处于预设范围内;
将归一化处理后的各所述音频帧的MFCC特征导入构建的识别模型进行识别。
在可选的实施方式中,所述识别模型包括依次连接的长短期记忆网络层组和全连接层组;
所述将所述多帧音频帧导入构建的识别模型进行识别,输出所述待识别音频帧对应的驱动控制信息的步骤,包括:
将所述多帧音频帧导入构建的识别模型包含的长短期记忆网络层组,输出各所述音频帧的高维特征向量;
将各所述音频帧的高维特征向量输入所述识别模型包含的全连接层组,输出所述待识别音频帧对应的驱动控制信息。
在可选的实施方式中,所述长短期记忆网络层组包括依次连接的第一长短期记忆网络层和第二长短期记忆网络层;
所述将所述多帧音频帧导入构建的识别模型包含的长短期记忆网络组,输出各所述音频帧的高维特征向量的步骤,包括:
针对所述多帧音频帧中的每个音频帧,利用所述第一长短期记忆网络层并根据所述音频帧和所述音频帧的上一个音频帧的中间状态,得到所述音频帧的中间状态;
利用所述第二长短期记忆网络层并根据所述音频帧的中间状态和所述上一个音频帧的中间状态,得到所述音频帧的高维特征向量。
第二方面,本申请提供一种虚拟形象驱动装置,所述装置包括:
获取模块,用于获取连续的多帧音频帧,所述多帧音频帧包含待识别音频帧和与所述待识别音频帧相邻的相邻音频帧;
识别模块,用于将所述多帧音频帧导入构建的识别模型进行识别,输出所述待识别音频帧对应的驱动控制信息;
控制模块,用于基于所述驱动控制信息控制虚拟形象的状态。
第三方面,本申请提供一种电子设备,包括一个或多个存储介质和一个或多个与存储介质通信的处理器,一个或多个存储介质存储有处理器可执行的机器可执行指令,当电子设备运行时,处理器执行所述机器可执行指令,以执行前述实施方式中任意一项所述的方法步骤。
第四方面,本申请提供一种计算机可读存储介质,所述计算机可读存储介质存储有机器可执行指令,所述机器可执行指令被执行时实现前述实施方式中任意一项所述的方法步骤。
本申请实施例的有益效果包括,例如:
本申请提供一种虚拟形象驱动方法、装置、电子设备和可读存储介质,通过采集连续的包含待识别音频帧和与待识别音频帧相邻的相邻音频帧的多帧音频帧,并将多帧音频帧导入构建的识别模型进行识别,输出待识别音频帧对应的驱动控制信息,再基于驱动控制信息控制虚拟形象的状态。本方案中,采用基于音频帧得到驱动控制信息以驱动虚拟形象的方式,可以避免在无法获取视频信息的应用场景下难以驱动虚拟形象的缺陷,并且,本方案中可以基于流式音频数据实现虚拟形象的控制,可以满足对虚拟形象实时控制的需求。
附图说明
为了更清楚地说明本申请实施例的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,应当理解,以下附图仅示出了本申请的某些实施例,因此不应被看作是对范围的限定,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他相关的附图。
图1为本申请实施例提供的虚拟形象驱动方法的应用场景示意图;
图2为本申请实施例提供的虚拟形象驱动方法的流程图;
图3为本申请实施例提供的流式音频数据的示意图;
图4为图2中步骤S120包含的子步骤的流程图;
图5为本申请实施例提供的识别模型的网络结构示意图;
图6为图2中步骤S120包含的子步骤的另一流程图;
图7为本申请实施例提供的长短期记忆网络层的处理流程示意图;
图8为图2中步骤S130包含的子步骤的流程图;
图9为本申请实施例提供的电子设备的结构框图;
图10为本申请实施例提供的虚拟形象驱动装置的功能模块框图。
图标:100-直播提供终端;110-存储介质;120-处理器;130-虚拟形象驱动装置;131-获取模块;132-识别模块;133-控制模块;140-通信接口;200-直播服务器;300-直播接收终端。
具体实施方式
为使本申请实施例的目的、技术方案和优点更加清楚,下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本申请一部分实施例,而不是全部的实施例。通常在此处附图中描述和示出的本申请实施例的组件可以以各种不同的配置来布置和设计。
因此,以下对在附图中提供的本申请的实施例的详细描述并非旨在限制要求保护的本申请的范围,而是仅仅表示本申请的选定实施例。基于本申请中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。
应注意到:相似的标号和字母在下面的附图中表示类似项,因此,一旦某一项在一个附图中被定义,则在随后的附图中不需要对其进行进一步定义和解释。
在本申请的描述中,需要说明的是,在不冲突的情况下,本申请的实施例中的特征可以相互结合。
请参阅图1,为本申请实施例提供的虚拟形象驱动方法的应用场景示意图,该应用场景中包括直播提供终端100、直播服务器200、直播接收终端300。直播服务器200分别与直播提供终端100和直播接收终端300通信连接,用于为直播提供终端100以及直播接收终端300提供直播服务。例如,直播提供终端100可以将直播流发送给直播服务器200,观众可以通过直播接收终端300访问直播服务器200以观看直播视频、收听直播音频。其中,直播服务器200推送的直播流可以是当前正在直播平台中直播的直播流或者直播完成后形成的完整直播流。
可以理解,图1所示的应用场景结构仅为一种可行的示例,在其它可行的实施例中,该应用场景中也可以仅包括图1所示组成部分的其中一部分或者还可以包括其它的组成部分。
在一些实施场景中,直播提供终端100和直播接收终端300可以互换使用。例如,直播提供终端100的主播可以使用直播提供终端100来为观众提供直播视频服务,或者作为观众查看其它主播提供的直播视频。又例如,直播接收终端300的观众也可以使用直播接收终端300观看所关注的主播提供的直播视频,或者作为主播为其它观众提供直播视频服务。
本实施例中,直播提供终端100和直播接收终端300可以是,但不限于,智能手机、个人数字助理、平板电脑、个人计算机、笔记本电脑、虚拟现实终端设备、增强现实终端设备等。其中,直播提供终端100和直播接收终端300中可以安装用于提供互联网直播服务的互联网产品,例如,互联网产品可以是计算机或智能手机中使用的与互联网直播服务相关的应用程序APP、Web网页、小程序等。
本实施例中,在该应用场景中还可以包括用于采集主播的音频信息的音频采集设备。音频采集设备可以直接安装或集成于直播提供终端100。例如,音频采集设备可以是配置在直播提供终端100上的麦克风,直播提供终端100中的其他模块或组件可以经由内部总线接收从音频采集设备采集到的音频数据。或者,音频采集设备也可以独立于直播提供终端100,两者之间通过有线或无线的方式进行通信。
图2示出了本申请实施例提供的虚拟形象驱动方法的流程示意图,该虚拟形象驱动方法可由图1中所示的直播提供终端100执行。应当理解,在其它实施例中,本实施例的驱动方法其中部分步骤的顺序可以根据实际需要相互交换,或者其中的部分步骤也可以省略或删除。该驱动方法的详细步骤介绍如下。
步骤S110,获取连续的多帧音频帧,所述多帧音频帧包含待识别音频帧和分别与所述待识别音频帧前后相邻的相邻音频帧。
步骤S120,将所述多帧音频帧导入构建的识别模型进行识别,输出所述待识别音频帧对应的驱动控制信息。
步骤S130,基于所述驱动控制信息控制虚拟形象的状态。
本实施例中,可以针对流式音频数据进行处理,流式音频数据即为一组顺序、大量、快速、连续到达的数据序列。在网络直播应用场景中,主播发出的语音数据即为流式音频数据,此外,一段预先录制好的、较长的音频数据,例如一节小说的音频数据,也为流式音频数据。因此,本实施例提供的驱动方法可以应用于直播应用场景下基于主播语音实现虚拟形象的驱动,也可以适用于基于预先录制好的一段音频数据实现虚拟形象的驱动的应用场景。
而现有技术中通常采用的虚拟形象的控制方法往往仅适应于一段完整的音频序列,也即,在获得一段完整的音频序列后,再基于获得的完整的音频序列对应的驱动信息,基于驱动信息实现虚拟形象的驱动。
现有技术中所采用的方式,由于需要基于完整的音频序列进行分析处理,因此,在虚拟形象控制的实时性上不佳,并且,由于在如网络直播应用场景下,往往难以获得完整的音频序列,而是在直播过程中持续产生流式音频数据。因此,现有技术中的方式无法应用于如直播应用场景下基于主播语音的虚拟形象驱动。
在一种实施方式中,本实施例中,可以将流式音频数据中的每25ms的音频数据片段作为一帧音频帧,也即获得的是连续的以25ms音频数据为一个单位的音频数据。
针对流式音频数据进行处理,由于流式音频数据的前后音频帧之间存在语义关联,因此,本实施例中,在针对待识别音频帧进行识别处理时,需要获得待识别音频帧以及分别与待识别音频帧前后相邻的相邻音频帧。
请结合图3所示,假设当前时刻为t,待识别音频帧可以为t-1时刻的音频帧,获得的相邻音频帧可以是t-2时刻的音频帧和t时刻的音频帧。本实施例中,结合待识别音频帧的前一帧音频帧和后一帧音频帧,以获得待识别音频帧对应的驱动控制信息。如此,可以结合前后音频帧的上下文信息来提高待识别音频帧的识别准确性。
并且,本实施例中,在获得t时刻的音频帧时,再输出t-1时刻音频帧对应的驱动控制信息,也即网络模型输出有一个单位音频数据的延迟。采用延迟输出的方式,可以进一步提高得到的待识别音频数据的准确性。而现有技术中由于是需要基于一段完整的音频序列来得到驱动信息,因此,在输出延迟上较大,对于用户侧而言,实时性差。本实施例中对于流式音频数据,仅具有一个单位音频数据的延迟,对用户来说其实是无感的,不影响用户体验。
本实施例中,可以将得到的待识别音频帧和相邻音频帧导入构建的识别模型,基于识别模型的分析处理输出待识别音频帧对应的驱动控制信息。其中,识别模型可以是预先基于训练音频以及与训练音频对应的真实驱动控制信息对网络模型进行训练获得。
本实施例中,识别模型可以是轻量化的长短期记忆网络(Long Short-TermMemory,LSTM)模型。由于直播提供终端100这类终端设备在处理性能上的局限,本实施例中,采用轻量化的LSTM模型进处理,可以使方案成功应用于性能较差的终端设备上。避免了现有技术中常采用的结构复杂的网络模型而难以应用于计算性能较弱的终端设备的缺陷。
在获得待识别音频帧对应的驱动控制信息后,可以将驱动控制信息导入到渲染引擎中以实现控制虚拟形象的状态。其中,虚拟形象可以是为增加直播趣味性所设计的模型,例如可以是动物模型、萝莉模型等不限。对于虚拟形象的控制可以是对虚拟形象的面部表情、肢体关节、面部特征等进行控制。
本实施例中,采用基于音频信息实现对虚拟形象的控制,可以适用于无法获得视频信息的场景下的控制,且本实施例方案可以针对流式音频数据进行处理进而实现虚拟形象控制,一方面使得方案可以适用于如直播应用场景下采集的音频特征的处理,另一方面可以提高对虚拟形象控制的实时性。
本实施例中,获得的音频帧的格式可为单通道格式,可以采用设置的采样率进行音频采样,例如16k。由于不同帧之间的音频数据可能在音频信息上存在较大差异,因此,本实施例中,可以预先对采集到的音频帧进行归一化处理,从而将各个音频帧的音频信息转化至一定范围内,以避免由于音频信息数据上相差太大而影响后续处理的问题。
本实施例中,为了提高音频帧的鲁棒性,更符合人耳的听觉特征,在利用识别模型对音频帧进行识别处理之前,还可预先对各个音频帧进行以下处理,请结合参阅图4:
步骤S121,对各所述音频帧进行特征提取,获得各所述音频帧的MFCC特征。
步骤S122,将各所述音频帧的MFCC特征导入构建的识别模型进行识别。
MFCC特征即为梅尔频率倒谱系数(Mel-frequency cepstral coefficients)特征。这种特征不依赖于信号的性质,对输入信号不作任何的假设和限制,且又利用了听觉模型的研究成果。因此,采用MFCC特征作为识别模型的输入,相比目前常用的LPCC特征而言,可以具有更好的鲁棒性,且更符合人耳的听觉特性,并且,当信噪比降低时仍然具有较好的识别性能。
本实施例中,对各音频帧进行特征提取得到各音频帧的MFCC特征的过程中,首先,可以将各音频帧通过一个设置的高通滤波器,以提升高频部分,使得信号的频谱变得平坦,保持在低频到高频的整个频带中。再将每一帧音频帧乘以设置的汉明窗,从而增加帧左端和帧右端的连续性。
由于信号在时域上的变换通常很难看出信号的特性,因此,在上述基础上,对音频帧进行快速傅里叶变换,以得到各个音频帧的频谱。再将转换后的音频帧通过一组三角形滤波器组,从而对频谱进行平滑处理,消除谐波,凸显原有语音的共振峰。计算出每个三角形滤波器输出的对数能量,基于对数能量进行离散余弦变化即可得到对应的MFCC特征。
本实施例中,将最终得到的各帧音频帧的MFCC特征导入到识别模型中,输出其中待识别音频帧对应的驱动控制信息。
考虑到不同音频帧转换后的MFCC特征之间可能也存在较大差异,因此,本实施例中可对获得的多帧音频帧的MFCC特征进行归一化处理,以使各音频帧的MFCC特征处于预设范围内,再将归一化处理后的各音频帧的MFCC特征导入构建的识别模型进行识别。
请结合参阅图5,本实施例所采用的识别模型为轻量型的LSTM模型,该识别模型包括依次连接的长短期记忆网络层组和全连接层组。将长短期记忆网络层组部署在识别模型的网络层的前列,可以首先对音频帧进行结合上下文信息的识别处理,能够结合上下文信息提高待识别音频帧的识别效果。
请参阅图6,在本实施例中,识别模型可以采用如下方式对多帧音频帧进行识别处理。
步骤S123,将所述多帧音频帧导入构建的识别模型包含的长短期记忆网络层组,输出各所述音频帧的高维特征向量。
步骤S124,将各所述音频帧的高维特征向量输入所述识别模型包含的全连接层组,输出所述待识别音频帧对应的驱动控制信息。
本实施例中,可将多帧音频帧导入到长短期记忆网络层组进行处理,其中,每帧音频帧的维度可为20维,以上述为例,针对待识别音频帧,可以将待识别音频帧、前一帧和后一帧一共三帧导入到识别模型中,因此,导入的信息为3*20维的特征信息。
长短期记忆网络层组包括依次连接的第一长短期记忆网络层和第二长短期记忆网络层。针对多帧音频帧中的每个音频帧,可利用第一长短期记忆网络层并根据音频帧和音频帧的上一个音频帧的中间状态,得到音频帧的中间状态,再利用第二长短期记忆网络层并根据音频帧的中间状态和上一个音频帧的中间状态,得到音频帧的高维特征向量。
第一长短期记忆网络层的输入为20维的特征向量、输出为256维的特征向量,而第二长短期记忆网络层的输入为256维的特征向量、输出为512维的特征向量。每一个长短期记忆网络层会输入上一时刻音频帧的中间状态,并输出当前时刻音频帧的中间状态。
其中,结合图7中所示,第一长短期记忆网络层的输出为两组256维的特征向量,第二长短期记忆网络层的输出为两组512维的特征向量。其中,该两组中间状态分别标识为特征ht和特征Ct,分别为长短期记忆网络层的记忆门特征和遗忘门特征。利用长短期记忆网络层对音频帧进行处理,可以使处理过程具有长期的记忆能力。最后由长短期记忆网络层组所输出的高维特征向量,为带有时序信息的特征向量。
本实施例中,将长短期记忆网络层组所输出的高维特征向量输入到全连接层组中,输出待识别音频帧对应的驱动控制信息。全连接层组的核心操作是矩阵向量乘积,可以通过对全连接层组进行训练,以不断调整网络层中矩阵参数的设置,从而使得到的乘积结果不断接近真实的驱动信息。全连接层组的输入和输出都是向量,其保存的参数是网络层矩阵,实际操作可以简化为利用网络层存的矩阵乘以输入的向量,得到输出结果。
本实施例中,全连接层组可包括依次连接的第一全连接层和第二全连接层。其中,第一全连接层可为单层结构,长短期记忆网络层组所输出的512维的高维特征向量输入至第一全连接层,第一全连接层可输出512维的抽象音频特征。第二全连接层可包含三层子网络层,如第一全连接子层、第二全连接子层和第三全连接子层。第一全连接子层可对输入的512维的抽象音频特征进行处理,输出同样为512维。第二全连接子层可将输入的512维的向量转化为256维的向量并输出,而第三全连接子层可将256维的向量转化为144维并输出。
需要说明的是,本实施例中,是以输入至识别模型的特征向量为20维为例进行的以上说明,实际实施时,具体应当以实际输入至识别模型的特征向量为准。
作为一种可能的实施方式,本实施例提供的虚拟形象驱动方法可以应用在基于用户的语音表征的指令控制虚拟形象活动的应用场景下。请参阅图8,在此情形下,可以通过以下方式基于驱动控制信息控制虚拟形象的状态。
步骤S131,获得所述驱动控制信息所指向的所述虚拟形象包含的多个关节中的目标关节。
步骤S132,基于所述驱动控制信息对所述目标关节进行姿态控制,以使所述虚拟形象的目标关节按所述待识别音频帧的语义指令进行姿态变化。
本实施例中,虚拟形象包含多个关节,例如四肢、躯干、头部等部位的多个关节。要控制虚拟形象进行如抬高手、翘脚等动作,则需要通过控制相应的关节予以实现。
在该应用场景下,得到的音频帧可以是在直播过程中主播所发出的语音,基于主播的语音对虚拟形象进行控制。在此情形下,可以获得识别模型所输出的驱动控制信息所指向的目标关节,进而基于驱动控制信息对目标关节进行姿态控制。
例如,主播可发出表征一定语义指令的语音信息,如表征抬手的语音信息、表征翘脚的语音信息等。如此,可以基于主播的语音信息相应地控制直播间内的虚拟形象的状态为抬手状态或翘脚状态等。
在对虚拟形象的关节进行驱动控制的应用中,采用合适格式的驱动控制信息将大大提高驱动效果。
假设需要连续地描述一维的角度0-360,若只用一维信号进行控制,控制效果其实是不连续的,如0度和360度表示的是同一个旋转方向,1度和359度旋转方向实际上很近,但是在数值上相差358度。因此,采用一维信号将大大降低控制的连续性。若采用两维信号进行控制,那么在一个单位圆上的坐标序列就可以连续地表示一个角。
基于上述分析,映射到三维空间时,本实施例中,利用6D信号形式的驱动控制信息进行虚拟形象的控制。在识别模型输出6D形式的驱动控制信息后,可以将驱动控制信息转换为三维空间中的旋转矩阵,再将旋转矩阵转换为四元数驱动信号,基于四元数驱动信号在渲染引擎中对虚拟形象的目标关节进行姿态控制。
此外,在另一种可能的实施方式下,本实施例提供的虚拟形象驱动方法还可以应用在控制虚拟形象嘴部特征的状态以使虚拟形象类似朗读相应的语音的场景下。在此情形下,可以通过以下方式基于驱动控制信息控制虚拟形象的状态。
基于驱动控制信息控制虚拟形象的嘴部特征的状态并播放待识别音频帧,以使嘴部特征的状态与朗读待识别音频帧的语音时的状态一致。
在该应用场景下,获得的音频帧可以是采集到的主播直播时的音频帧,也可以是预先存储在直播提供终端100的音频帧,例如一段小说的音频。驱动控制信息可以是需要朗读出相应的音频帧时,虚拟形象的嘴部特征应当具有的状态的控制信息。
例如,针对一段预先存储的小说,可以获得可控制虚拟形象的嘴部形状类似于在朗读该段小说的驱动控制信息。如此,对于一段小说类的音频帧,可在实际播放该段音频的同时,通过虚拟形象的嘴部特征的状态控制以类似朗读该段音频。
此外,在该种应用场景下,除了可以让虚拟形象形式上朗读音频帧,还可以对虚拟形象的肢体进行控制,从而使虚拟形象的状态更加自然。对于虚拟形象的肢体控制可以通过以下方式实现:
获取从预先设置的多种形象风格中选择的目标形象风格,获得目标形象风格对应的驱动信息,根据驱动信息对虚拟形象的肢体状态进行驱动控制。
本实施例中,预先可以得到多种形象风格对应的驱动信息并存储,所述的形象风格可以是根据音频信息的类型进行设置。例如,针对一段小说,若该小说为武侠类小说,相应的形象风格可为飘逸风格,驱动信息可以是如驱动虚拟形象的肢体轻微晃动的信息。若该小说为动漫类小说,相应的形象风格可为可爱风格,驱动信息可以是如驱动虚拟形象作为一些可爱肢体动作的信息。
本实施例中,预先可以设置多种不同的形象风格并与对应的驱动信息进行关联。实际应用时,用户可以基于所针对的音频帧,选择所需的目标形象风格。根据用户选择的目标形象风格可基于预先的关联信息获得对应的驱动信息,并基于驱动信息控制虚拟形象的肢体。
如此,虚拟形象可以通过嘴部活动以类似朗读音频帧,如小说,同时虚拟形象的肢体可相应活动,以使朗读状态看着更加自然。
在采用上述任意一种方式实现虚拟形象控制后,直播提供终端100将得到的直播流上传至直播服务器200,各个进入到相应直播间的直播接收终端300登录至直播服务器200,接收直播服务器200推送的直播流。
请参阅图9,为本申请实施例提供的电子设备的示例性组件示意图,该电子设备可为图1中所示的直播提供终端100,直播提供终端100可包括存储介质110、处理器120、虚拟形象驱动装置130、通信接口140。本实施例中,存储介质110与处理器120均位于直播提供终端100中且二者分离设置。然而,应当理解的是,存储介质110也可以是独立于直播提供终端100之外,且可以由处理器120通过总线接口来访问。可替换地,存储介质110也可以集成到处理器120中,例如,可以是高速缓存和/或通用寄存器。
虚拟形象驱动装置130可以理解为上述直播提供终端100,或直播提供终端100的处理器120,也可以理解为独立于上述直播提供终端100或处理器120之外的在直播提供终端100控制下实现上述虚拟形象驱动方法的软件功能模块。
如图10所示,上述虚拟形象驱动装置130可以包括获取模块131、识别模块132和控制模块133,下面分别对该虚拟形象驱动装置130的各个功能模块的功能进行详细阐述。
获取模块131,用于获取连续的多帧音频帧,所述多帧音频帧包含待识别音频帧和与所述待识别音频帧相邻的相邻音频帧。
可以理解,该获取模块131可以用于执行上述步骤S110,关于该获取模块131的详细实现方式可以参照上述对步骤S110有关的内容。
识别模块132,用于将所述多帧音频帧导入构建的识别模型进行识别,输出所述待识别音频帧对应的驱动控制信息。
可以理解,该识别模块132可以用于执行上述步骤S120,关于该识别模块132的详细实现方式可以参照上述对步骤S120有关的内容。
控制模块133,用于基于所述驱动控制信息控制虚拟形象的状态。
可以理解,该控制模块133可以用于执行上述步骤S130,关于该控制模块133的详细实现方式可以参照上述对步骤S130有关的内容。
在一种可能的实现方式中,前述控制模块133具体可以用于:
获得所述驱动控制信息所指向的所述虚拟形象包含的多个关节中的目标关节;
基于所述驱动控制信息对所述目标关节进行姿态控制,以使所述虚拟形象的目标关节按所述待识别音频帧的语义指令进行姿态变化。
在一种可能的实现方式中,前述控制模块133具体可以用于:
将所述驱动控制信息转换为三维空间中的旋转矩阵;
将所述旋转矩阵转换为四元数驱动信号;
基于所述四元数驱动信号在渲染引擎中对所述虚拟形象的目标关节进行姿态控制。
在一种可能的实现方式中,前述控制模块133具体可以用于:
基于所述驱动控制信息控制虚拟形象的嘴部特征的状态并播放所述待识别音频帧,以使所述嘴部特征的状态与朗读所述待识别音频帧的语音时的状态一致。
在一种可能的实现方式中,所述虚拟形象驱动装置130还包括驱动模块,该驱动模块可以用于:
获取从预先设置的多种形象风格中选择的目标形象风格;
获得所述目标形象风格对应的驱动信息,所述驱动信息为针对所述虚拟形象的肢体状态的信息;
根据所述驱动信息对所述虚拟形象的肢体状态进行驱动控制。
在一种可能的实现方式中,前述识别模块132可以用于:
对各所述音频帧进行特征提取,获得各所述音频帧的MFCC特征;
将各所述音频帧的MFCC特征导入构建的识别模型进行识别。
在一种可能的实现方式中,前述识别模块132可以用于:
对获得的多帧音频帧的MFCC特征进行归一化处理,以使各所述音频帧的MFCC特征处于预设范围内;
将归一化处理后的各所述音频帧的MFCC特征导入构建的识别模型进行识别。
在一种可能的实现方式中,所述识别模型包括依次连接的长短期记忆网络层组和全连接层组,前述识别模块132具体可以用于:
将所述多帧音频帧导入构建的识别模型包含的长短期记忆网络层组,输出各所述音频帧的高维特征向量;
将各所述音频帧的高维特征向量输入所述识别模型包含的全连接层组,输出所述待识别音频帧对应的驱动控制信息。
在一种可能的实现方式中,所述长短期记忆网络层组包括依次连接的第一长短期记忆网络层和第二长短期记忆网络层,前述识别模块132具体可以用于:
针对所述多帧音频帧中的每个音频帧,利用所述第一长短期记忆网络层并根据所述音频帧和所述音频帧的上一个音频帧的中间状态,得到所述音频帧的中间状态;
利用所述第二长短期记忆网络层并根据所述音频帧的中间状态和所述上一个音频帧的中间状态,得到所述音频帧的高维特征向量。
关于装置中的各模块的处理流程、以及各模块之间的交互流程的描述可以参照上述方法实施例中的相关说明,这里不再详述。
进一步地,本申请实施例还提供一种计算机可读存储介质,计算机可读存储介质存储有机器可执行指令,机器可执行指令被执行时实现上述实施例提供的虚拟形象驱动方法。
具体地,该计算机可读存储介质能够为通用的存储介质,如移动磁盘、硬盘等,该计算机可读存储介质上的计算机程序被运行时,能够执行上述虚拟形象驱动方法。关于计算机可读存储介质中的及其可执行指令被运行时,所涉及的过程,可以参照上述方法实施例中的相关说明,这里不再详述。
综上所述,本申请实施例提供的虚拟形象驱动方法、装置、电子设备和可读存储介质,通过采集连续的包含待识别音频帧和与待识别音频帧相邻的相邻音频帧的多帧音频帧,并将多帧音频帧导入构建的识别模型进行识别,输出待识别音频帧对应的驱动控制信息,再基于驱动控制信息控制虚拟形象的状态。本方案中,采用基于音频帧得到驱动控制信息以驱动虚拟形象的方式,可以避免在无法获取视频信息的应用场景下难以驱动虚拟形象的缺陷,并且,本方案中可以基于流式音频数据实现虚拟形象的控制,可以满足对虚拟形象实时控制的需求。
以上所述,仅为本申请的具体实施方式,但本申请的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本申请揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本申请的保护范围之内。因此,本申请的保护范围应以所述权利要求的保护范围为准。
- 虚拟形象驱动方法、装置、电子设备和可读存储介质
- 虚拟形象生成方法、装置、电子设备和计算机可读存储介质