基于文本对抗生成网络的无监督图像描述生成方法
文献发布时间:2023-06-19 19:27:02
技术领域
本发明属于计算机视觉和自然语言处理技术领域,具体的说是一种基于文本对抗生成网络的无监督图像描述生成方法。
背景技术
图像描述生成是计算机视觉和自然语言处理领域的重要课题,在图像索引,人机交互及视障人士的生活辅助等方面具有广泛的应用。传统的图像描述生成是有监督的,依赖人工标注的图像-描述对,然而大规模,高质量的标注数据受到成本因素限制而难以获取。因此,研究者们提出了无监督的图像描述生成方法。传统的无监督图像描述生成方法大致可以分为以下三类:基于目标检测器,基于场景图生成器,基于中介语言图像描述器的方法。基于目标检测器的方法首先训练模型利用文本库中的实体名称生成文本,然后检测图像中出现的实体,最后将实体作为模型输入进行图像描述。基于场景图生成器的方法首先训练模型从文本中建立的场景图重建文本,然后生成图像对应的场景图,最后将场景图作为模型输入进行图像描述。基于中介语言图像描述器的方法首先利用中介语言图像描述器生成中介描述,然后再利用翻译器翻译到指定的语言。然而,基于目标检测器和场景图生成的方法需要图像信息提取或中间结果预测,如目标检测和场景图生成,而且中间结果不够准确和全面,带来误差累积。而基于中介语言图像描述器的方法需要假定已经存在一个中介语言图像描述器,这大大限制了该方法的使用场景。
近年来,随着语言-图像对比学习预训练技术的兴起,显示出优异的语言-图像对齐性能。研究者们将语言-图像对比学习预训练模型CLIP应用到图像文字描述领域中,然而目前CLIP的应用局限于使用CLIP的图像编码器提取图像特征或使用CLIP筛选高质量的伪标签,没有对CLIP进行充分的挖掘和利用。总体而言,如何实现无需复杂图像信息提取和能够充分利用语言-图像对比学习预训练模型CLIP的无监督图像描述生成还是一个未解决的问题。
发明内容
本发明是为了解决上述现有技术存在的不足之处,提出一种基于文本对抗生成网络的无监督图像描述生成方法,以期能克服现有方法的图像处理复杂,误差累积和场景局限等问题,并能充分利用语言-图像对比学习预训练模型CLIP的能力实现图像的信息提取,从而能显著提升无监督图像描述生成质量。
本发明为达到上述发明目的,采用如下技术方案:
本发明一种基于文本对抗生成网络的无监督图像描述生成方法的特点在于,是按如下步骤进行:
步骤1、获取训练数据,包括:图像集和辅助文本库;
利用语言-图像对比学习预训练模型CLIP中的图像特征提取器CLIP-ImageEncoder对所述图像集中的
对所述辅助文本库中的
步骤2、构建图像描述生成器
K
步骤3、利用语言-图像对比学习预训练模型CLIP中的文本特征提取器CLIP-TextEncoder对第
步骤4、构建文本-图像特征转换器,包括
所述文本-图像特征转换器对文本特征
步骤5、由文本特征
步骤6、构建文本判别器
所述基于RoBERTa语言理解模型的文本特征提取器将第
步骤7、使用自批判的强化学习方式训练预热后的图像描述生成器
本发明所述的基于文本对抗生成网络的无监督图像描述生成方法的特点在于,所述步骤5包括:
步骤5.1、领域适应学习策略:
从图像特征集合{
从文本库{
(1)
式(1)中,
步骤5.2、语义约束学习策略:
利用式(2)构建语义约束损失
(2)
步骤5.3、文本重建学习策略:
构造伪标签对(
(3)
式(3)中,
步骤5.4、利用式(4)构造预热损失函数
L
式(4)中,
步骤5.5、最小化所述预热损失函数
所述步骤7包括:
步骤7.1、自批判强化学习策略:
步骤7.1.1、所述预热后的图像描述生成器
将文字描述
步骤7.2.2、激励函数计算:
将文字描述
(5)
式(5)中,
将采样文字描述
步骤7.2.3、利用式(6)计算自批判强化学习策略梯度
(6)
式(6)中,
(7)
式(7)中,
步骤7.2、二分类文本判别策略:
步骤7.2.1、将采样文字描述
步骤7.2.2、根据式(8)构建文本判别器
(8)
式(7)中,
步骤7.3、交替优化训练策略:
步骤7.3.1、定义当前迭代步数为step,并初始化step=1;定义学习率为γ;
步骤7.3.2、在当前第step步训练时先对二分类损失
(9)
步骤7.3.3、step+1赋值给step后,判断step>step_max是否成立,若成立,则停止对抗训练,并从step_max步中选择最优图像描述生成器
与现有技术相比,本发明的有益效果在于:
1、本发明提出了一种基于预训练模型的文本对抗生成网络模型,该模型包括图像描述生成器,文本判别器和激励函数;其中,图像描述生成器利用了先进的语言生成预训练模型,文本判别器利用了先进的语言理解预训练模型,激励函数利用了先进的语言-图像对比学习预训练模型;从而使得文本对抗生成网络模型的训练难度大大降低,提升了图像描述生成的质量。
2、本发明提出了一种无监督图像描述生成器的预热方法,是通过训练图像描述生成器从文本特征和虚拟图像特征重建文本,使得图像描述生成器初步学习根据图像特征进行文字描述。除了文本重建学习策略之外,该方法还使用领域适应学习策略和语义约束学习策略对虚拟图像特征进行进一步的约束,使得生成的虚拟图像特征一方面适应图像领域,另一方面保持和文本尽可能一致的语义;使得虚拟图像特征更加真实,强化预热阶段的效果。预热之后的图像描述生成器用于初始化对抗训练阶段的图像描述生成器,可以进一步提升对抗训练效果。
3、本发明提出了一种兼顾真实度和语义匹配的自批判强化学习策略,是通过激励来引导图像描述生成器学习,估计策略梯度来优化生成器,将模型的推断时argmax解码的激励值作为基线,计算采样策略解码的激励值与之相减作为自批判后的激励值。其中,激励值是真实度和语义匹配度的加权和,使得图像描述生成器兼顾描述的真实性和语义一致性。自批判策略的使用使得训练和推理阶段的差距缩小,有利于达到最优效果。
附图说明
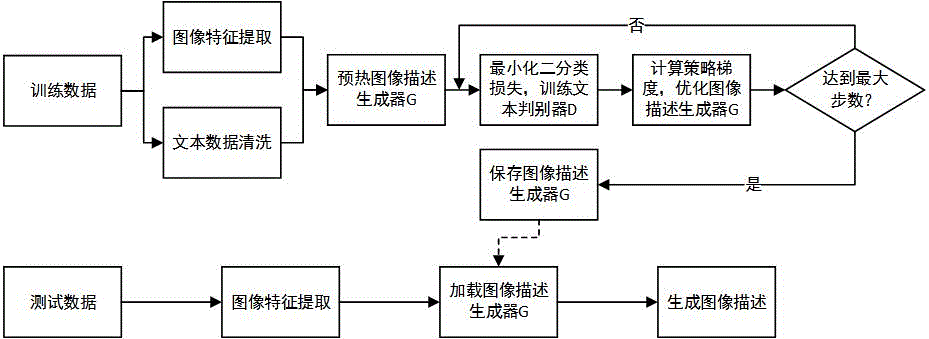
图1为本发明方法的流程示意图;
图2为本发明对抗学习阶段模型结构示意图;
图3为本发明预热阶段模型结构示意图。
具体实施方式
本实施例中,如图1所示,一种基于文本对抗生成网络的无监督图像描述生成方法是按如下步骤进行:
步骤1、获取训练数据,包括:图像集和辅助文本库;
利用语言-图像对比学习预训练模型CLIP中的图像特征提取器CLIP-ImageEncoder对图像集中的
对辅助文本库中的
步骤2、构建图像描述生成器
K
步骤3、利用语言-图像对比学习预训练模型CLIP中的文本特征提取器CLIP-TextEncoder对第
步骤4、构建文本-图像特征转换器,包括
文本-图像特征转换器对文本特征
步骤5、如图3所示,由文本特征
步骤5.1、领域适应学习策略:
步骤4中进行特征转换后的虚拟图像特征
从图像特征集合{
从文本库{
(1)
式(1)中,
步骤5.2、语义约束学习策略:
步骤4中进行特征转换后的虚拟图像特征
利用式(2)构建语义约束损失
(2)
步骤5.3、文本重建学习策略:
根据步骤4到5.2,实际上构造了伪标签对(
(3)
式(3)中,
步骤5.4、利用式(4)构造预热损失函数
L
式(4)中,
步骤5.5、最小化预热损失函数
步骤6、构建文本判别器
基于RoBERTa语言理解模型的文本特征提取器将第
步骤7、如图2所示,使用自批判的强化学习方式训练预热后的图像描述生成器
步骤7.1、自批判强化学习策略:
步骤7.1.1、预热后的图像描述生成器
将文字描述
步骤7.2.2、激励函数计算:
在激励计算步骤,需要兼顾生成的描述文本的真实度和语义匹配度,前者要求生成的描述文本和人类自然语言相似,用文本判别器输出的真实度来衡量;后者要求生成的描述文本忠实于图像的内容,用图像-文本基于CLIP的特征相似度来衡量。在本实施例中,使用权重因子来加权两部分的激励。将文字描述
(5)
式(5)中,
将采样文字描述
步骤7.2.3、利用式(6)计算自批判强化学习策略梯度
(6)
式(6)中,
(7)
式(7)中,
步骤7.2、二分类文本判别策略:
步骤7.2.1、将采样文字描述
步骤7.2.2、根据式(8)构建文本判别器
(8)
式(7)中,
步骤7.3、交替优化训练策略:
步骤7.3.1、定义当前迭代步数为step,并初始化step=1;定义学习率为γ;
步骤7.3.2、在当前第step步训练时先对二分类损失
(9)
步骤7.3.3、step+1赋值给step后,判断step>step_max是否成立,若成立,则停止对抗训练,并从step_max步中选择最优图像描述生成器
结合下列图表进一步描述本发明的测试结果,表格中的MSCOCO和ShutterStock均为使用的数据集名称,在MSCOCO数据集的公开测试集上进行测试,METEOR(Metric forEvaluation of Translation with Explicit ORdering),CIDEr(Consensus-based ImageDescription Evaluation)和SPICE(Semantic Propositional Image CaptionEvaluation)均为图像描述领域的常用指标:
为了验证本发明图像描述生成器预热阶段各个学习策略对最终生成效果的贡献,进行了消融实验,包含三个预热阶段方法:(1)只使用文本重建学习策略;(2)结合文本重建学习策略和领域适应学习策略;(3) 结合文本重建学习策略,领域适应学习策略和语义约束学习策略,即使用所有学习策略。实验结果如表1所示。
表 1
为了验证本发明对抗训练中不同的激励函数和是否使用图像描述生成器预热操作对最终生成效果的贡献,进行了消融实验,包含四个训练阶段方法:(1)激励函数只使用图像-文本基于CLIP的特征相似度,图像描述生成器不使用预热操作;(2) 激励函数只使用文本判别器输出的真实度,图像描述生成器不使用预热操作;(3)使用完整的激励函数,图像描述生成器不使用预热操作;(4)使用完整的激励函数,图像描述生成器使用预热操作。实验结果如表2所示。
表 2
通过分析表1的结果,说明预热阶段的各个学习策略是有效的,随着策略的加入,实验结果有明显的提升;通过分析表2的结果,对抗训练中的激励函数组合和图像描述生成器预热操作均带来生成效果的提升。
表3将本发明与传统的无监督方法UIC-GAN(Unsupervised image captioning),R2M(Recurrent relational memory network for unsupervised image captioning),IGGAN(Interactions guided generative adversarial network for unsupervisedimage captioning)和TSGAN(Triple sequence generative adversarial nets forunsupervised image captioning)以及利用CLIP进行伪标签筛选的方法PL-UIC(Prompt-based learning for unpaired image captioning)进行对比。
表 3
通过分析表3中的结果,说明本发明提出的方法不但显著超越了传统的无监督图像描述方法,而且比PL-UIC(Prompt-based learning for unpaired image captioning)利用CLIP的方式更加的有效,从而达到了更好的效果。