一种基于数据融合的电影票房预测方法、系统及电子设备
文献发布时间:2023-06-19 19:30:30
技术领域
本发明涉及计算机技术领域,特别是涉及一种基于数据融合的电影票房预测方法、系统及电子设备。
背景技术
随着人们生活水平、电影制作水平以及计算机技术的发展,越来越多的人通过看电影来丰富自己的生活,并且机器学习成为人工智能领域的研究热点,其理论和方法慢慢被广泛应用于解决工程应用和科学领域的复杂问题。电影创作融资往往要参考电影作品本身以及行业社会的发展情况,这就产生了电影数据、行业数据、社会数据等多源数据融合的需求。对于一部电影的成功与否,其电影票房是一项重要的评价指标,而如何通过数据融合来对电影票房进行合理、准确地预测,识别出更有价值的电影,成为电影行业从事与研究人员越来越关注的地方。
发明内容
本发明的目的是提供一种基于数据融合的电影票房预测方法、系统及电子设备,通过数据融合来对电影票房进行合理、准确地预测,识别出更有价值的电影。
为实现上述目的,本发明提供了如下方案:
一种基于数据融合的电影票房预测方法,包括:
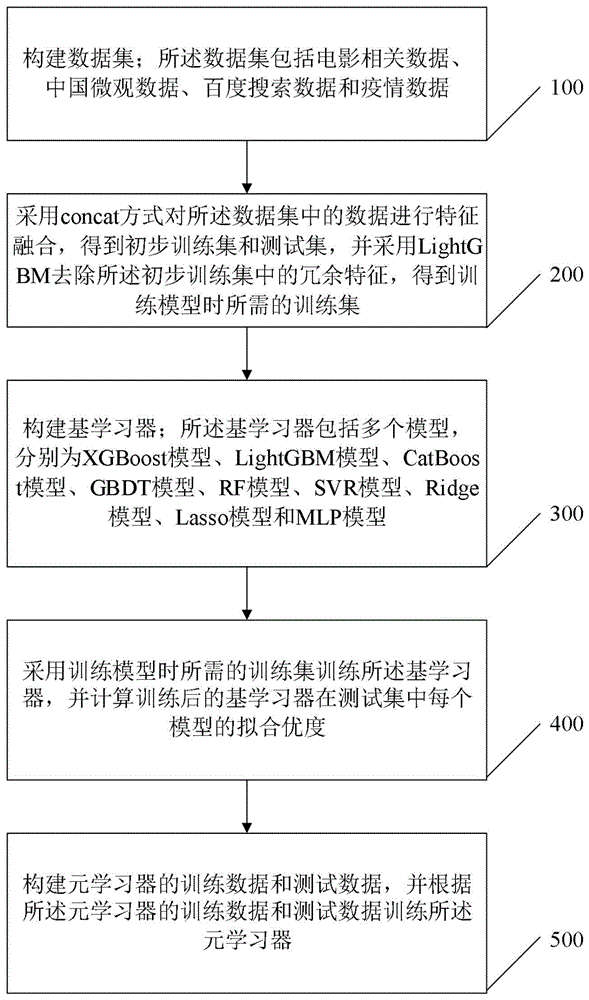
构建数据集;所述数据集包括电影相关数据、中国微观数据、百度搜索数据和疫情数据;
采用concat方式对所述数据集中的数据进行特征融合,得到初步训练集和测试集,并采用LightGBM去除所述初步训练集中的冗余特征,得到训练模型时所需的训练集;所述初步训练集和所述测试集均包括多个样本数据;所述样本数据包括输入数据和对应的标签数据;所述输入数据包括电影特征、国家微观数据特征、疫情数据特征和百度搜索指数特征;所述标签数据为电影总票房;
构建基学习器;所述基学习器包括多个模型,分别为XGBoost模型、LightGBM模型、CatBoost模型、GBDT模型、RF模型、SVR模型、Ridge模型、Lasso模型和MLP模型;
采用训练模型时所需的训练集训练所述基学习器,并计算训练后的基学习器在测试集中每个模型的拟合优度;
构建元学习器的训练数据和测试数据,并根据所述元学习器的训练数据和测试数据训练所述元学习器;所述元学习器的训练数据为将验证集中的数据输入至训练后的基学习器后得到的预测结果;所述元学习器的测试数据为采用拟合优度对训练后的基学习器得到的预测结果进行加权平均后得到的数据;训练后的元学习器用于预测电影票房;训练模型时所需的训练集分为5折,4折作为基学习器的训练集,1折作为基学习器的验证集。
第二方面,本发明提供了一种基于数据融合的电影票房预测系统,包括:
数据集构建模块,用于构建数据集;所述数据集包括电影相关数据、中国微观数据、百度搜索数据和疫情数据;
训练集和测试集确定模块,用于采用concat方式对所述数据集中的数据进行特征融合,得到初步训练集和测试集,并采用LightGBM去除所述初步训练集中的冗余特征,得到训练模型时所需的训练集;所述初步训练集和所述测试集均包括多个样本数据;所述样本数据包括输入数据和对应的标签数据;所述输入数据包括电影特征、国家微观数据特征、疫情数据特征和百度搜索指数特征;所述标签数据为电影总票房;
基学习器构建模块,用于构建基学习器;所述基学习器包括多个模型,分别为XGBoost模型、LightGBM模型、CatBoost模型、GBDT模型、RF模型、SVR模型、Ridge模型、Lasso模型和MLP模型;
拟合优度计算模块,用于采用训练模型时所需的训练集训练所述基学习器,并计算训练后的基学习器在测试集中每个模型的拟合优度;
元学习器训练模块,用于构建元学习器的训练数据和测试数据,并根据所述元学习器的训练数据和测试数据训练所述元学习器;所述元学习器的训练数据为将验证集中的数据输入至训练后的基学习器后得到的预测结果;所述元学习器的测试数据为采用拟合优度对训练后的基学习器得到的预测结果进行加权平均后得到的数据;训练后的元学习器用于预测电影票房;训练模型时所需的训练集分为5折,4折作为基学习器的训练集,1折作为基学习器的验证集。
第三方面,本发明提供了一种电子设备,包括存储器及处理器,所述存储器用于存储计算机程序,所述处理器运行所述计算机程序以使所述电子设备执行根据第一方面所述的一种基于数据融合的电影票房预测方法。
根据本发明提供的具体实施例,本发明公开了以下技术效果:
在电影本身特征基础上,引入多项国家微观数据、上映日期前后30天的电影名称百度搜索指数数据、新冠疫情数据等特征进行特征层融合。决策层融合采用Stacking方法,使用一种加权Stacking算法进行建模,影响因素较为全面、实验数据集较大,对于电影行业的发展有一定的意义。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
图1为本发明实施例提供的基于数据融合的电影票房预测方法的流程图;
图2为本发明实施例提供的基于数据融合的电影票房预测系统的结构图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明引入决策级融合机制,基于Stacking构建一种基于数据融合的电影票房预测方法、系统及电子设备,识别电影的价值,为电影制作与发行公司提供商业决策支撑与指导,促进电影行业的持续发展。
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本发明作进一步详细的说明。
针对现有技术中存在的缺陷,本发明实施例提供了一种基于数据融合的电影票房预测方法,如图1所示,该方法包括如下步骤。
步骤100:构建数据集;所述数据集包括电影相关数据、中国微观数据、百度搜索数据和疫情数据,具体为:
步骤101:采用网站下载方式、网络爬虫方式和人工标注方式获取电影相关数据、中国微观数据、百度搜索数据和疫情数据。
步骤102:根据所述电影相关数据、所述中国微观数据、所述百度搜索数据和所述疫情数据,构建数据集。
所述电影相关数据来自艺恩娱数网站,包括:影片名称、猫眼想看人数、淘票票想看人数、豆瓣想看人数、猫眼评分、淘票票评分、豆瓣评分、时长、演员、编剧、剧情简介、上映日期、年度场次、总场次、年度人次(万)、总人次(万)、首周票房(万)、平均票价、场均人次、影片英文名称、主类型、完整类型、导演、出品公司、制作公司、发行公司、影片制式、国别、投资规模、整合营销公司、新媒体营销公司、制片人、监制、出品人、影片属性、服务费(万)、总票房(万)。
所述中国微观数据来自EPS(Easy Professional Superior)数据平台,包括:全体居民消费水平(元)、农村居民消费水平(元)、城镇居民消费水平(元)、全体居民消费水平指数(1978年=100)、农村居民消费水平指数(1978年=100)、第三产业所占比重(国内生产总值=100)、国内生产总值(亿元)、居民人均可支配收入(元)、电影院线(条)、电影院线内银幕(块)、互联网上网人数(万人)、互联网宽带接入端口(万个)、互联网国际出口带宽(Mbps)、开通互联网宽带业务的行政村比重(%)、互联网普及率(%)、互联网宽带接入用户(万户)。
所述百度搜索数据为:根据电影名称与电影上映日期,爬取电影上映前30天到上映后30天的每一天百度搜索指数,所述百度搜索数据用于票房预测,所述百度搜索数据包括移动端百度搜索指数、PC端百度搜索指数、PC+移动端百度搜索指数。
所述疫情数据来自国家卫健委每日疫情通报新闻。
步骤200:采用concat方式对所述数据集中的数据进行特征融合,得到初步训练集和测试集,并采用LightGBM去除所述初步训练集中的冗余特征,得到训练模型时所需的训练集;所述初步训练集和所述测试集均包括多个样本数据;所述样本数据包括输入数据和对应的标签数据;所述输入数据包括电影特征、国家微观数据特征、疫情数据特征和百度搜索指数特征;所述标签数据为电影总票房。
采用concat方式对所述数据集中的数据进行特征融合,得到初步训练集和测试集,具体包括:
查看电影相关数据中各个数据特征的缺失情况,最终采用总票房排名前2000的电影相关数据构建模型;
查看总票房排名前2000的电影相关数据的票房分布数据,相比于正态分布,票房的分布更符合无界约翰逊分布,将电影票房的值进行log转换;
根据获取的中国微观数据进行多项式回归建模,用于预测电影上映时的中国微观数据,构造国家微观数据特征;
采用正则表达式对国家卫健委每日疫情通报进行数据提取,构造疫情特征;
根据电影上映前后30天的百度搜索指数数据,构造百度搜索指数特征;
根据每部电影的导演、演员、编剧、出品人、监制、制片人、出品公司、制作公司、发行公司、整合营销公司、新媒体营销公司、上映日期等电影属性,构造电影特征。
其中,对数值型特征使用均值填充缺失值;
对类别型特征使用OrdinalEncoder进行标签编码,对类别型特征的缺失值用众数填充;
最后按照9:1的比例,将数据集分为初步训练集和测试集。
所述采用LightGBM去除所述初步训练集和所述初步测试集中的冗余特征,得到训练模型时所需的训练集和测试集,具体包括:
采用LightGBM建立LightGBM模型;
计算所述初步训练集中的各特征在LightGBM模型中的重要性,删除特征重要性小于3的电影特征,保留国家微观数据特征、疫情数据特征、百度搜索指数特征。
步骤300:构建基学习器;所述基学习器包括多个模型,分别为XGBoost模型、LightGBM模型、CatBoost模型、GBDT模型、RF模型、SVR模型、Ridge模型、Lasso模型和MLP模型;其中,所述基学习器的决策层采用的方法为Stacking方法。
步骤400:采用训练模型时所需的训练集训练所述基学习器,并计算训练后的基学习器在测试集中每个模型的拟合优度。
步骤500:构建元学习器的训练数据和测试数据,并根据所述元学习器的训练数据和测试数据训练所述元学习器;所述元学习器的训练数据为将验证集中的数据输入至训练后的基学习器后得到的预测结果;所述元学习器的测试数据为采用拟合优度对训练后的基学习器得到的预测结果进行加权平均后得到的数据;训练后的元学习器用于预测电影票房;训练模型时所需的训练集分为5折,4折作为基学习器的训练集,1折作为基学习器的验证集。所述元学习器为使用多元线性回归模型构建的基于Stacking方法的模型。
其中,训练后的元学习器用于预测电影票房
所述采用训练模型时所需的训练集训练所述基学习器,并计算训练后的基学习器在测试集中每个模型的拟合优度,具体包括:
将训练集分为5折,采取5折交叉验证的方式进行训练,每次使用其中4折进行训练,另1折作为验证集进行测试,同时对测试集进行测试,得到每个基学习器预测测试集时的拟合优度(R
所述采用训练模型时所需的训练集训练所述基学习器,具体包括:
将训练模型时所需的训练集为5折,其中,4折作为基学习器的训练集,1折作为基学习器的验证集;
将训练集中的4折数据分别输入基学习器内的每个模型,进行训练,得到训练后的基学习器。
所述构建元学习器的训练数据和测试数据,具体包括:
将验证集中的数据分别输入至训练后的基学习器内的每个模型中,得到模型预测结果,并将所有模型预测结果进行拼接,得到训练数据。
将测试集中的数据分别输入至训练后的基学习器内的每个模型中,得到模型预测结果,然后采用测试集对应的拟合优度,对该测试集对应的模型预测结果进行加权平均,得到加权平均后的模型预测结果,最后将加权平均后的模型预测结果进行拼接,得到测试数据。
实施例二
为了执行上述实施例一对应的方法,以实现相应的功能和技术效果,下面提供一种基于数据融合的电影票房预测系统。
如图2所示,该基于数据融合的电影票房预测系统,包括:
数据集构建模块1,用于构建数据集;所述数据集包括电影相关数据、中国微观数据、百度搜索数据和疫情数据。
训练集和测试集确定模块2,用于采用concat方式对所述数据集中的数据进行特征融合,得到初步训练集和测试集,并采用LightGBM去除所述初步训练集中的冗余特征,得到训练模型时所需的训练集;所述初步训练集和所述测试集均包括多个样本数据;所述样本数据包括输入数据和对应的标签数据;所述输入数据包括电影特征、国家微观数据特征、疫情数据特征和百度搜索指数特征;所述标签数据为电影总票房。
基学习器构建模块3,用于构建基学习器;所述基学习器包括多个模型,分别为XGBoost模型、LightGBM模型、CatBoost模型、GBDT模型、RF模型、SVR模型、Ridge模型、Lasso模型和MLP模型。
拟合优度计算模块4,用于采用训练模型时所需的训练集训练所述基学习器,并计算训练后的基学习器在测试集中每个模型的拟合优度。
元学习器训练模块5,用于构建元学习器的训练数据和测试数据,并根据所述元学习器的训练数据和测试数据训练所述元学习器;所述元学习器的训练数据为将验证集中的数据输入至训练后的基学习器后得到的预测结果;所述元学习器的测试数据为采用拟合优度对训练后的基学习器得到的预测结果进行加权平均后得到的数据;训练后的元学习器用于预测电影票房;训练模型时所需的训练集分为5折,4折作为基学习器的训练集,1折作为基学习器的验证集。
实施例三
本发明实施例提供了一种基于数据融合的电影票房预测方法,包括如下步骤:
1.通过网站下载、网络爬虫、人工标注的方式收集电影相关数据、中国微观数据、百度搜索数据、疫情数据,以构建数据集;
1-1在艺恩娱数网站获取电影相关数据,数据特征包括:影片名称、猫眼想看人数、淘票票想看人数、豆瓣想看人数、猫眼评分、淘票票评分、豆瓣评分、时长、演员、编剧、剧情简介、上映日期、年度场次、总场次、年度人次(万)、总人次(万)、首周票房(万)、平均票价、场均人次、影片英文名称、主类型、完整类型、导演、出品公司、制作公司、发行公司、影片制式、国别、投资规模、整合营销公司、新媒体营销公司、制片人、监制、出品人、影片属性、服务费(万)、总票房(万)。
1-2在EPS(Easy Professional Superior)数据平台获取中国微观数据,数据特征包括:全体居民消费水平(元)、农村居民消费水平(元)、城镇居民消费水平(元)、全体居民消费水平指数(1978年=100)、农村居民消费水平指数(1978年=100)、第三产业所占比重(国内生产总值=100)、国内生产总值(亿元)、居民人均可支配收入(元)、电影院线(条)、电影院线内银幕(块)、互联网上网人数(万人)、互联网宽带接入端口(万个)、互联网国际出口带宽(Mbps)、开通互联网宽带业务的行政村比重(%)、互联网普及率(%)、互联网宽带接入用户(万户)。
1-3在百度搜索指数官网获取电影名称百度搜索数据,根据电影名称与电影上映日期,爬取电影上映前30天到上映后30天的每一天百度搜索指数,以用于票房预测,该指数包括移动端百度搜索指数、PC端百度搜索指数、PC+移动端百度搜索指数。
1-4在国家卫健委官方网站获取每日疫情通报新闻,进而获取疫情数据。
2.对数据集进行预处理;采用concat方式对数据集中的数据进行特征融合,组成训练集和测试集,并使用LightGBM去除训练集中的冗余特征,具体包括如下步骤:
2-1查看电影各个数据特征的缺失情况,最终采用总票房排名前2000的电影数据构建模型;
2-2查看电影票房的分布情况,相比于正态分布,票房的分布更符合无界约翰逊分布,将电影票房的值进行log变换;
2-3根据获取的中国微观数据进行多项式回归建模,用于预测电影上映时的中国微观数据,构造国家微观数据特征。从EPS网站获取了16种国家统计的微观数据,每一种数据均为年度数据。根据已有的数据对每一种数据使用多项式回归进行拟合,根据拟合后的多项式回归模型计算出每部电影上映时的微观数据。由于微观数据种类较多,以电影院线内银幕(块)数据为例说明如何使用多项式回归进行预测,具体预测过程如下:
2-3-1电影院线内银幕(块)为2006-2020年的数据,将年份转化为当年的最后一天日期,再将日期转换为数字(1900年1月1日为数字1,1900年1月2日为数字2,以此类推),转换示例如下表1所示:
表1转换示例表
2-3-2以日期数字作为自变量,电影院线内银幕(块)数作为因变量,使用python建立多项式回归模型,设置多项式的最高次幂为5,训练得到模型的拟合优度R
2-3-3以每部电影的上映日期为自变量,用2-3-2步骤中得到的多项式回归模型预测每部电影上映时的电影院线内银幕(块)。
2-4采用正则表达式对国家卫健委每日疫情通报进行数据提取,构造疫情特征;
2-4-1提取的数据特征包括:每一天的新增确诊病例、现有确诊病例、新增无症状感染者、累计治愈出院病例、累计死亡病例、累计报告确诊病例、现有疑似病例、累计追踪到密切接触者、尚在医学观察的密切接触者数量;
2-4-2根据疫情期间每天的疫情数据与电影上映日期,为每部电影数据增加疫情数据特征,包括上映当天新增确诊病例、上映当天现有确诊病例、上映当天新增无症状感染者、至上映当天累计治愈出院病例、至上映当天累计死亡病例、至上映当天累计报告确诊病例、至上映当天累计追踪到密切接触者、至上映当天尚在医学观察的密切接触者、上映前一周累计新增确诊病例、上映前30天累计新增确诊病例、上映后一周累计新增确诊病例、上映后30天累计新增确诊病例。
2-5根据电影上映前后30天的百度搜索指数数据,构造百度搜索指数特征;
2-5-1构造百度搜索指数特征包括:全端上映前30天平均搜索指数、全端上映前7天平均搜索指数、全端上映当天搜索指数、全端上映后7天平均搜索指数、全端上映后30天平均搜索指数、PC端上映前30天平均搜索指数、PC端上映前7天平均搜索指数、PC端上映当天搜索指数、PC端上映后7天平均搜索指数、PC端上映后30天平均搜索指数、智能端上映前30天平均搜索指数、智能端上映前7天平均搜索指数、智能端上映当天搜索指数、智能端上映后7天平均搜索指数、智能端上映后30天平均搜索指数、以及上映前后30天每天的百度搜索指数。全端搜索指数代表PC端与智能端搜索指数之和。
2-6根据每部电影的导演、演员、编剧、出品人、监制、制片人、出品公司、制作公司、发行公司、整合营销公司、新媒体营销公司、上映日期等电影属性,构造电影特征:
2-6-1将每部电影的演员的前三位设为主演,针对电影本身的特征如主演、编剧、导演、出品人、监制、制片人、出品公司、制作公司、发行公司、整合营销公司、新媒体营销公司,整理所有的电影数据,为每部电影数据增添电影的这些主体的人数、历史参与电影总数、历史总票房、历史平均票房;
2-6-2为每部电影的导演、编剧以及每位主演增添历史总猫眼想看人数、历史最高猫眼想看人数、历史平均猫眼想看人数、历史总淘票票想看人数、历史最高淘票票想看人数、历史平均淘票票想看人数、历史总豆瓣想看人数、历史最高豆瓣想看人数、历史平均豆瓣想看人数、历史总猫眼评分、历史最高猫眼评分、历史平均猫眼评分、历史总淘票票评分、历史最高淘票票评分、历史平均淘票票评分、历史总豆瓣评分、历史最高豆瓣评分、历史平均豆瓣评分的特征;
2-6-3为每部电影的数据增添第一导演(即排序第一的导演)、第一编剧、第一监制、第一制片人、第一出品公司、第一制作公司、第一发行公司的历史电影总数、历史总票房、历史平均票房、最近1年历史总票房、最近1年历史电影总数、最近1年平均票房、最近3年历史总票房、最近3年历史电影总数、最近3年平均票房、最近5年历史总票房、最近5年历史电影总数、最近5年平均票房;
2-6-4根据所有电影数据,计算所有演员、编剧、导演、出品人、监制、制片人、出品公司、制作公司、发行公司的参与电影次数,以参与电影次数排序前百分之一为门槛,确定劳模演员、劳模编剧、劳模导演、劳模出品人、劳模监制、劳模制片人、劳模出品公司、劳模制作公司、劳模发行公司名单。并且根据每部电影的工作人员,确定每部电影的劳模演员人数、劳模编剧人数、劳模导演人数、劳模出品人人数、劳模监制人数、劳模制片人人数、劳模出品公司数、劳模制作公司数、劳模发行公司数,将这些数据添加到电影票房预测数据特征中;
2-6-5根据电影上映日期,为每部电影数据增添年份、上映日期数字、上映日期周几的数据特征;
2-6-6为每部电影增加档期特征,有元旦档、春节档、情人节档、妇女节档、清明档、五一档、六一档、端午档、暑期档、七夕档、中秋档、国庆档、贺岁档,具体档期时间范围如下表所示:
表2档期时间范围表
2-6-7为每部电影增添影片名长度、剧情简介字数、电影类型个数的数据特征,将每个电影的完整类型分割为类型1、类型2、类型3,人工为电影增加电影是否是系列的特征。
2-7对数值型特征使用均值填充缺失值;
2-8对类别型特征使用OrdinalEncoder进行标签编码,对类别型特征的缺失值用众数填充;
2-9按照9:1的比例,将数据集分为训练集和测试集;
2-10用LightGBM建立模型,得出各个特征在LightGBM模型中的特征重要性,筛除特征重要性小于3的特征,保留国家微观数据特征、疫情数据特征、百度搜索指数特征。
3.决策层融合采用Stacking方法,使用XGBoost、LightGBM、CatBoost、GBDT、RF、SVR、Ridge、Lasso、MLP,构建Stacking算法的基学习器,训练基学习器并计算每个模型的拟合优度(R
3-1基于筛选后的特征建立XGBoost、LightGBM、CatBoost、GBDT、RF、SVR、Ridge、Lasso、MLP算法模型,使用参数搜索方法进行调参;
3-1-1本模型所用的XGBoost算法的超参数为:n_estimators=200,learning_rate=0.08,subsample=0.8,colsample_bytree=0.9,max_depth=5。
3-1-2所用的LightGBM算法的超参数为:boosting_type='gbdt',learning_rate=0.1,min_child_samples=20,n_estimators=200,num_leaves=31。
3-1-3所用的CatBoost算法的超参数为:iterations=200,loss_function='RMSE'。
3-1-4所用的GBDT算法的超参数为:n_estimators=200,subsample=0.8,learning_rate=0.1,max_depth=5。
3-1-5所用的RF算法的超参数为:n_estimators=200,bootstrap=True。
3-1-6所用的SVR算法的超参数为:kernel='rbf'。
3-1-7所用的Ridge算法的超参数为:alpha=1,fit_intercept=True,solver='auto',。
3-1-8所用的Lasso算法的超参数为:eps=0.001,n_alphas=100,alphas=None,cv=5。
3-1-9所用的MLP算法的超参数为:hidden_layer_sizes=(64,32,16,8,4,2),random_state=1,solver=’sgd'。
3-2将训练集分为5折,采取5折交叉验证的方式对基学习器进行训练,每次使用其中4折进行训练,另1折作为验证集进行测试,同时对测试集进行测试,得到每个基学习器预测测试集的拟合优度(R
4.使用多元线性回归模型构建基于Stacking算法的元学习器,根据基学习器的拟合效果R
4-1将每一类基学习器(即每个模型)对验证集的预测结果进行拼接,组成元学习器的训练集;
一个示例为:每一折数据都会作为一次验证集,然后将这5个验证集的预测结果并列起来,就是一类基学习器(比如XGBoost模型)对训练集(1800条)的预测结果。XGBoost模型对训练集生成1列预测结果,其他的基学习器,也照此对训练集生成1列预测结果,一共生成1800行9列的数据,作为元学习器的训练集的特征。
4-2根据每一类基学习器预测训练集的拟合优度(R
一个示例为:对于每一类基学习器,每次交叉验证时,(每一类基学习器交叉验证5次)每次拿训练集的其中4折数据进行训练,将训练出来的模型,对验证集进行预测,还要对测试集进行预测,然后记录对测试集的预测效果R
4-3采用多元线性回归模型作为元学习器,根据基学习器的训练结果产生的训练集进行训练。
实施例四
本发明实施例提供一种电子设备包括存储器及处理器,该存储器用于存储计算机程序,该处理器运行计算机程序以使电子设备执行实施例一的一种基于数据融合的电影票房预测方法。
可选地,上述电子设备可以是服务器。
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例公开的系统而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。
本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处。综上所述,本说明书内容不应理解为对本发明的限制。