适用于金融业务的多框架微服务应用的云配置方法及系统
文献发布时间:2023-06-19 10:29:05
技术领域
本发明涉及软件技术领域,尤其涉及一种适用于金融业务的多框架微服务应用的云配置方法及系统。
背景技术
微服务是当前互联网应用的主要实现形式,而众多微服务通常部署在云计算基础设施中。各种各样的微服务应用在由多个框架组成的计算生态系统中执行,这些框架以类似图形的结构连接在一起,形成计算集群。部署这些计算集群的常见方式是在云环境中获取资源,并在需要重复执行任务时按需获取资源。在云中执行任务时,确保分配正确的资源至关重要,这是为了满足任务完成时间的严格服务质量和成本效益需要。因此,在云中部署计算集群需要解决云配置问题,确定使用多少个实例,以及使用哪种类型的实例。选择正确的配置是至关重要的,因为当这样的决策失误时,任务不能满足其截止日期或执行成本成倍增加。
选择云配置的现有方法(CherryPick:Adaptively Unearthing the Best CloudConfigurations for Big Data Analytics.In the Proceedings of the 14th USENIXSymposium onNetworked Systems Design and Implementation,2017.)不考虑计算集群中多个框架的存在,而是专注于配置单个框架。在面向多框架计算集群的环境中,已有方法都具有局限性。第一种方法(Micky:A cheaper alternative for selecting cloudinstances.In the Proceedings of 11th IEEE International Conference on CloudComputing,pages 409–416.IEEE,2018.)单独优化每个框架,然而不同框架之间的耦合性和不合理的资源预分配导致难以整体上提高性能。第二种方法(Arrow:Low-LevelAugmented Bayesian Optimization forFinding the Best Cloud VM.In theProceedings of 38th IEEE International Conference on Distributed ComputingSystems,pages 660–670.IEEE,2018.)将整个计算集群视为一个“单一大系统”,同时修改所有框架的配置,这种方法支持联合优化,但会随着框架数量的增加而成倍增加配置搜索空间的大小。探索更大的空间自然需要更长的时间,导致用户在生产中部署他们的集群之前的昂贵延迟。
发明内容
为了解决现有技术的问题,本发明提供了一种适用于金融业务的多框架微服务应用的云配置方法及系统,面向部署在云计算环境中的采用多框架的微服务应用选择优化的云配置,从而提高为服务应用执行的性能,即减少请求处理时间,并且提高云资源利用率。所述技术方案如下:
一方面,本发明提供了一种适用于金融业务的多框架微服务应用的云配置方法,包括以下步骤:
S1、接受任务的处理请求,并计算请求中的任务与已知任务之间的相似度;
S2、根据相似度计算结果,判断请求中的任务类型属于已知任务类型、相似任务类型或未知任务类型,若属于已知任务类型,则执行S31和S4,若属于相似任务类型,则执行S32和S4,若属于未知任务类型,则执行S33和S4;
S31、对于已知任务类型,使用匹配的已知初始模型并在线优化,生成新的任务模型;
S32、对于相似任务类型,在线优化器加载最相似任务的初始模型,并使用迁移学习来引导建立新任务的新的任务模型;
S33、对于未知任务类型,基于基准测试构建新的任务模型;
S4、利用所述新的任务模型,丢弃预测执行时间与当前最佳配置的最佳预测执行时间相比更长的配置,构建配置候选集合,在其中选择一个配置用于下一次执行,并从其余的候选中选择模型预测的最佳云配置。
进一步地,步骤S31包括以下三个阶段:
初始化阶段:优化器首先使用预先指定的配置执行分析任务,以获得初始性能样本;
资源增加阶段:分析运行顺序,分配给每个框架的实例数量的数量根据监测的CPU和内存利用率而增加;若CPU的平均利用率和内存利用率之和超过阈值,则实例数量增加一倍,否则实例数量增加一个常数;当以上两种情况中的任何一种出现时,优化器检查是否找到多个有效的配置,若是,则通过返回具有最佳执行时间的配置来终止,否则优化器进入细粒度的资源调整阶段;
资源调整阶段:若CPU并且内存使用率小于阈值,则实例数量减半;若CPU和内存使用率大于阈值,则实例数量翻倍;其他情况下,实例数量减去一个常数;若利用率指标超出预设的高临界值,则将实例数量减半,若利用率指标低于预设的低临界值,则将实例数量加倍。
进一步地,步骤S33进一步包括:
选择先前执行的配置作为质心,将执行时间在当前最低执行时间的范围内的有效配置作为相邻配置,使用评分函数将选择扩展到满足执行时间约束的先前执行的配置,并根据其执行成本表示优化选择。
进一步地,步骤S33进一步包括:
与不满足成本约束的配置相比,为满足成本约束的配置分配较高的分数,所分配的分数与超出约束的数量成比例,使得在满足时间约束的配置中,优先搜索具有较低执行时间的有效配置的邻域。
进一步地,针对未知任务类型,步骤S4中的构建配置候选集合包括:
基于质心集合,形成一组未经测试的候选配置,该集合从每个质心的邻域并通过当前最佳配置的实例类型变化绘制的配置;对于每个质心,选择距质心距离d内的每个配置,基于CPU和内存容量的差异来定义距离度量。
进一步地,步骤S32进一步包括:
当新的任务到达时,在初始配置上执行,并根据与以前执行任务的相似性进行评分;如果该任务与现有任务相似度达到预设的相似度阈值,则将该任务传递给在线优化器,并在线优化器加载最相似任务的性能模型,并使用迁移学习来引导建立新任务的性能模型,该模型作为在线优化器的初始状态以搜索新任务的适当配置。
进一步地,步骤S1中两个任务之间的相似度为对应两个配置向量小于CPU数量且内存总量大于两个任务之间的向量距离。
另一方面,本发明提供了一种适用于金融业务的多框架微服务应用的云配置系统,包括以下模块:
任务相似度计算模块,用于接受任务的处理请求,并计算请求中的任务与已知任务之间的相似度;
已知任务类型配置模块,用于响应于请求中的任务类型属于已知任务类型,则使用匹配的已知初始模型并在线优化,生成新的任务模型;
相似任务类型配置模块,用于响应于请求中的任务类型属于相似任务类型,则在线优化器加载最相似任务的初始模型,并使用迁移学习来引导建立新任务的新的任务模型;
未知任务类型配置模块,用于响应于请求中的任务类型属于未知任务类型,则基于基准测试构建新的任务模型;
最佳最佳云配置模块,用于利用新的任务模型,丢弃预测执行时间与当前最佳配置的最佳预测执行时间相比更长的配置,构建配置候选集合,在其中选择一个配置用于下一次执行,并从其余的候选中选择模型预测的最佳云配置。
进一步地,所述系统基于在线随机森林方法构建性能模型来微调配置,该模型随着重复任务的每次连续运行而不断更新。
本发明提供的技术方案带来的有益效果如下:
a.通过分析任务之间的相似性,使用迁移学习重用以前任务中的知识,可以提高基准测试运行,减少在初始阶段找到较优配置的时间;
b.通过基于在线随机森林方法构建性能模型来微调配置,可以不断更新以逐步搜索到优化配置,从而解决了多框架大搜索空间的低效问题。
附图说明
为了更清楚地说明本发明实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
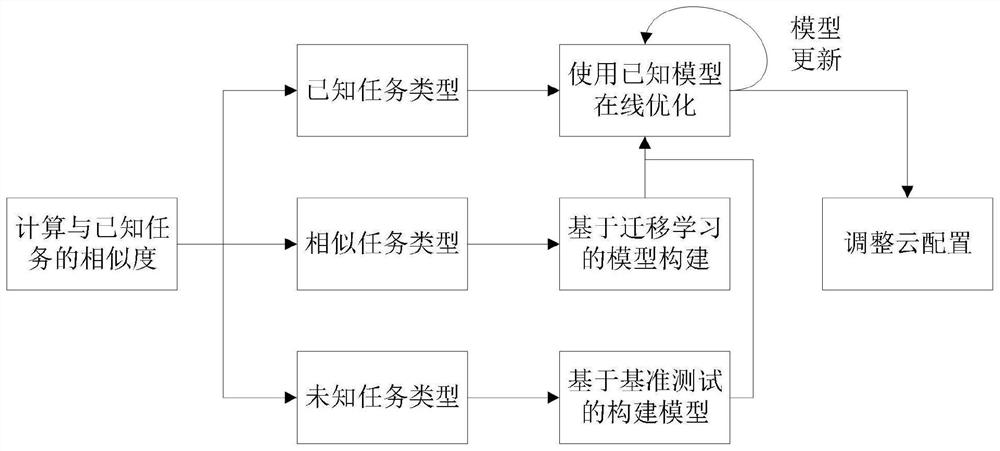
图1是本发明实施例提供的适用于金融业务的多框架微服务应用的云配置方法流程图。
具体实施方式
为了使本技术领域的人员更好地理解本发明方案,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分的实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都应当属于本发明保护的范围。
需要说明的是,本发明的说明书和权利要求书及上述附图中的术语“第一”、“第二”等是用于区别类似的对象,而不必用于描述特定的顺序或先后次序。应该理解这样使用的数据在适当情况下可以互换,以便这里描述的本发明的实施例能够以除了在这里图示或描述的那些以外的顺序实施。此外,术语“包括”和“具有”以及他们的任何变形,意图在于覆盖不排他的包含,例如,包含了一系列步骤或单元的过程、方法、装置、产品或设备不必限于清楚地列出的那些步骤或单元,而是可包括没有清楚地列出的或对于这些过程、方法、产品或设备固有的其他步骤或单元。
发明涉及一种离在线优化相结合的多框架微服务应用的云配置方法。在基准测试阶段,使用基于指标的优化器来快速确定初始配置。在这个阶段,分析任务之间的相似性,使用迁移学习重用以前任务中的知识。然后,基于在线随机森林方法构建性能模型来微调配置,该模型随着重复任务的每次连续运行而不断更新以逐步改善配置,以解决在大搜索空间内进行快速基准搜索的性能限制,从而提升搜索优化云配置的效率。
在本发明的一个实施例中,提供了一种适用于金融业务的多框架微服务应用的云配置方法,如图1所示,所述云配置方法包括以下步骤:
S1、接受任务的处理请求,并计算请求中的任务与已知任务之间的相似度;
S2、根据相似度计算结果,判断请求中的任务类型属于已知任务类型、相似任务类型或未知任务类型,若属于已知任务类型,则执行S31和S4,若属于相似任务类型,则执行S32和S4,若属于未知任务类型,则执行S33和S4;
S31、对于已知任务类型,使用匹配的已知初始模型并在线优化,生成新的任务模型;
S32、对于相似任务类型,在线优化器加载最相似任务的初始模型,并使用迁移学习来引导建立新任务的新的任务模型;
S33、对于未知任务类型,基于基准测试构建新的任务模型;
S4、利用所述新的任务模型,丢弃预测执行时间与当前最佳配置的最佳预测执行时间相比更长的配置,构建配置候选集合,在其中选择一个配置用于下一次执行,并从其余的候选中选择模型预测的最佳云配置。
本发明的原理:在基准测试阶段快速找到足够好的配置,并在执行期间随着任务的重复增量式优化该配置。具体而言,在基准测试阶段,使用基于指标的优化器来快速确定初始配置。在这个阶段,分析任务之间的相似性,使用迁移学习重用以前任务中的知识。然后,为了解决在大搜索空间内进行快速基准搜索的性能限制,基于在线随机森林方法构建性能模型来微调配置,该模型随着重复任务的每次连续运行而不断更新以逐步改善配置。
在本发明的一个实施例中,离在线优化相结合的多框架微服务应用的云配置方法的实现步骤如下:
第一步,计算与已知任务的相似度,判断任务类型属于已知、相似还是未知。相似度是两个配置
每当任务请求到达时,分为以下三种情况:已知任务类型是该任务与先前执行的任务相同;相似任务类型是以前没有遇到的新任务但与以前执行的任务类似;未知任务类型是以前没有遇到的新任务并且与以前执行的任何任务都不相似。
第二步,对于已知任务类型,使用初始模型并在线优化,生成任务模型。该步骤分为初始化、资源增加和资源调整等三个阶段。
初始化阶段:优化器首先使用预先指定的配置执行分析任务,以获得初始性能样本。
资源增加阶段:分析运行顺序,分配给每个框架的实例数量的数量根据监测的CPU和内存利用率而增加。如果CPU的平均利用率和内存利用率之和超过阈值,则实例数量增加一倍。否则,较低的CPU和内存利用率总和表明资源翻倍将是过度分配。在这种情况下,每次分析运行时,实例数量都会增加一个常数。由于搜索空间界限对特定大小的实例数量施加了限制,如果实例数量达到该限制,将会达到更大的实例大小。如果当前配置的执行时间与先前配置的执行时间相比变慢,或者先前配置有效,但当前配置无效。当这两种情况中的任何一种出现时,优化器都会检查它是否找到了多个有效的配置。如果是这种情况,将通过返回具有最佳执行时间的配置来终止。否则,优化器会进入细粒度的资源调整阶段,以找到更好的配置。
资源调整阶段:优化器通过减少资源来降低整体执行成本,从而找到有效的配置。在分析运行期间,当任何CPU和内存利用率不超过特定阈值,框架会减少其资源分配。当前配置无效而此前配置有效时,此操作终止。实例数量的调整如下:当CPU并且内存使用率小于阈值,则实例数量减半;当CPU并且内存使用率大于阈值,则实例数量翻倍;其他情况下,实例数量减去一个常数。当利用率指标过高或过低时,进行调整,将实例数量减半或加倍。否则,启用细粒度调整,增量或减量到实例数量,以避免过度或分配资源不足。
第三步,对于未知任务类型,基于基准测试构建初始模型;对于相似任务类型,基于迁移学习构建初始模型,在线优化以生成任务模型。选择先前执行的配置作为质心,将执行时间在当前最低执行时间的∈内的有效配置作为相邻配置,以提供更好的可能配置,使用评分函数将选择扩展到满足执行时间约束的先前执行的配置,并根据其执行成本表示优化选择。为满足成本约束的配置分配较高的分数,为不满足成本约束的配置分配较低的分数,与超出约束的数量成比例。确保了在满足时间约束的配置中,优先搜索具有较低执行时间的有效配置的邻域。候选集选择:基于质心集合,形成一组未经测试的候选配置,该集合从每个质心的邻域并通过当前最佳配置的实例类型变化绘制的配置。对于每个质心,选择距质心距离d内的每个配置,基于CPU和内存容量的差异来定义距离度量。
第四步,根据生成的任务模型,生成云配置。使用候选集合,在其中选择一个配置用于下一次执行。过滤候选集,丢弃预测执行时间与当前最佳配置的最佳预测执行时间相比过高的配置,从剩余的候选中选择模型预测的最佳配置。
本发明实施例离在线优化相结合的多框架微服务应用的云配置方法流程分为两个阶段:
第一个阶段,基于快速优化的基准测试阶段,使用离线优化器,运行基准测试以确定足够好的初始配置。
第二个阶段,在生产优化阶段,使用在线优化器,每次运行都是实际执行,用于增量更新性能模型,以改进下一次迭代任务的配置。
每当任务请求到达时,区分以下三种情况:已知任务类型,该任务与先前执行的任务相同;相似任务类型,以前没有遇到的新任务,但与以前执行的任务类似;类似任务类型,以前没有遇到的新任务,并且与以前执行的任何任务都不相似。
对于已知任务类型:再次循环请求的运行任务,直接传递给在线优化器。在线优化器使用此任务的性能模型来选择新的云配置进行测试,运行结束后,更新性能模型。
对于类似任务类型:当新的任务到达时,在初始配置上执行,并根据与以前执行任务的相似性进行评分。如果该任务与现有任务有足够的相似度,则将该任务传递给在线优化器。在线优化器加载最相似任务的性能模型,并使用迁移学习来引导建立新任务的性能模型。该模型作为在线优化器的初始状态以搜索新任务的适当配置。
对于未知任务类型:当新任务不满足相似性过滤规则时,任务请求传递给离线优化器。优化器找到满足用户约束的足够好的配置,然后使用该配置启动执行,后续提交的该任务使用在线优化器进行优化。
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 适用于金融业务的多框架微服务应用的云配置方法及系统
- 云部署微服务应用系统及其数据传输方法、装置和设备