基于GPU集群的雷达探测空间目标并行信号处理系统
文献发布时间:2024-04-18 20:02:40
技术领域
本发明涉及雷达信号处理技术领域,具体涉及一种基于GPU集群的雷达探测空间目标并行信号处理系统。
背景技术
空间目标的探测设备主要可分为光学设备与雷达设备两类。相比于光学设备,雷达具备全天时、全天候的工作能力且可获得高精度的目标径向距离与径向速度测量。对于相控阵雷达,因其独特的波束捷变能力,从而具备不同空域多目标的搜索、跟踪能力。
受限于雷达设备的发射功率及天线增益,当探测远超过单脉冲作用距离的目标时,通常采用信号处理的方法对多脉冲回波信号进行长时间相参积累以实现目标探测。对于空间目标,可利用其轨道约束,对多个回波进行运动补偿处理,从而完成能量的有效积累。然而,当目标轨道误差大或无先验轨道信息时,长时间相参积累处理需遍历搜索目标所有可能的轨道参数空间,该处理过程运算量巨大,信号处理时间长,导致测量数据率大幅降低。
一种提高数据率的方法是滑窗处理,滑窗处理时,相邻处理帧之间的数据部分重叠,由历史数据和新的回波数据组成新的处理窗。滑窗数越大,数据处理间隔越短,数据率越高。然而,滑窗处理方式对信号处理系统的处理时间提出了更高的要求,需要处理系统具备更强的运算能力。
如何设计空间目标的信号处理系统使其能够适应滑窗处理的方式,是目前亟待解决的问题。
发明内容
有鉴于此,本发明提供了一种基于GPU集群的雷达探测空间目标并行信号处理系统,能够针对雷达探测空间目标的应用场景,解决采用滑窗方式进行长时间相参积累处理时,由于运算量巨大,现有的信号处理机无法满足实时处理的问题。
为达到上述目的,本发明的技术方案为:基于GPU集群的雷达探测空间目标并行信号处理系统,该系统包括光纤数据接收转发模块、光纤数据分发模块、多个GPU处理节点及综合处理模块。
光纤数据接收转发模块与光纤数据分发模块间、光纤数据分发模块与多个GPU处理节点间通过光纤连接;多个处理节点与综合处理模块通过以太网连接;
光纤数据接收转发模块用于进行多路雷达回波光纤数据的接收与合并,合并后的回波数据转发给光纤数据分发模块。
光纤数据分发模块解析合并后的回波数据中的控制信息,从数据流提取发射脉冲调制类型、发射脉宽以及信号带宽信息,对合并后的回波数据进行筛选,将筛选出的回波数据转发至对应的GPU处理节点。
GPU处理节点通过DMA方式获取筛选出的回波数据,解析回波数据控制信息附带的回波标识,根据分配的节点ID筛选需要处理的数据范围,完成信号的距离对齐、相位补偿、脉冲压缩、相参积累、恒虚警检测CFAR和参数测量。
综合处理模块接收各个GPU处理节点的状态信息,完成各GPU处理节点的管理与GPU处理节点间数据级的整合,得到最终的检测和参数测量结果。
进一步地,光纤数据接收转发模块包含至少一块光纤数传处理板。
光纤数据分发模块包含至少一块光纤数传处理板;其中光纤数据分发模块中的每一块光纤数传处理板对应连接一个GPU处理节点。
光纤数传处理板上至少搭载1片FPGA芯片。
进一步地,光纤数传处理板上还搭载有1片DSP芯片和2片SDRAM芯片,同时外挂DDR存储芯片;光纤数传处理板安装于标准CPCI机箱。
进一步地,每个GPU处理节点的主体为带有PCIe接口的通用服务器,搭载一块PCIe接口的光纤数据接收处理板与4块GPU计算卡,其中光纤数据接收处理板搭载了1片FPGA并可外挂两条DDR3内存用于收发缓存,通过PCIe接口与服务器连接,以DMA方式完成数据的高速传输。
进一步地,综合处理模块为通用服务器,各GPU处理节点与综合处理模块间通过以太网连接。
进一步地,每个GPU处理节点上均设置有节点处理程序,节点处理程序申请一段连续的内存空间后与光纤数据接收处理板通过DMA方式完成数据的传输;节点处理程序解析回波数据控制信息附带的回波标识,根据分配的节点ID,选取滑窗处理过程中分配给该节点ID的积累窗范围,完成信号的距离对齐、相位补偿、脉冲压缩、相参积累、恒虚警检测CFAR和参数测量,并将该积累窗的处理结果上报给综合处理模块。
进一步地,综合处理模块上设置有综合处理程序,综合处理程序通过以太网络接收各个节点上报的系统状态,并根据当前的积累脉冲数和设置的滑窗数分配不同的节点ID给节点处理程序;其中积累脉冲数为N,滑窗数为m,则对于节点数等于滑窗数的情况,节点0的处理范围为第1~N个脉冲,节点1的处理范围为
进一步地,多GPU处理节点间数据的传输、同步由底层板卡实现,GPU处理节点的具体计算任务由综合处理模块分配、管理,各GPU处理节点只负责完成计算任务。
有益效果:
1、本发明完成了基于GPU集群的雷达探测空间目标并行信号滑窗处理的任务,光纤数据接收转发模块完成了对雷达端原始信号的接收,并按信号处理系统内部格式拼接转发;光纤数据分发模块将原始数据分发至每个GPU处理节点,完成了不同节点间数据的同步;GPU处理节点与综合处理模块交互,完成滑窗处理方式下信号的距离对齐、相位补偿、脉冲压缩、相参积累、恒虚警检测(CFAR)和参数测量;综合处理模块完成各个处理节点数据级的整合,得到最终的处理结果。
2、本发明采用综合处理模块与多个GPU处理节点间的主从结构。综合处理模块根据实时监测获得的处理节点个数,完成运算任务的动态分配及负载均衡;每个GPU处理节点则最大限度的利用GPU自身单指令流多数据流的并行处理架构,选取综合处理模块分配的处理数据,完成波门截取、相位补偿和脉冲压缩处理后,在全参数空间并行搜索目标运动参数,利用搜索到目标运动参数对多个脉冲压缩结果进行相参积累,并完成空间目标的恒虚警检测和参数测量;综合处理模块汇总各节点处理结果。
3、光纤数据接收转发模块、光纤数据分发模块利用FPGA灵活的数据输入输出接口和强实时控制能力,通过光纤接口及PCIe总线完成处理数据在多个节点间转发与同步,避免了现有GPU集群处理过程中数据在各节点间传输过程受限于各节点间传输带宽的情况,能够满足需要强实时控制以及超高速运算能力下的空间目标探测要求。
4、该架构可以通过增加光纤数据接收转发模块、光纤数据分发模块完成GPU处理节点的扩展,后续可以在不改变原有处理方式的基础上增加处理节点以提高算力,扩展现有处理算法,进一步提高信号处理能力。
附图说明
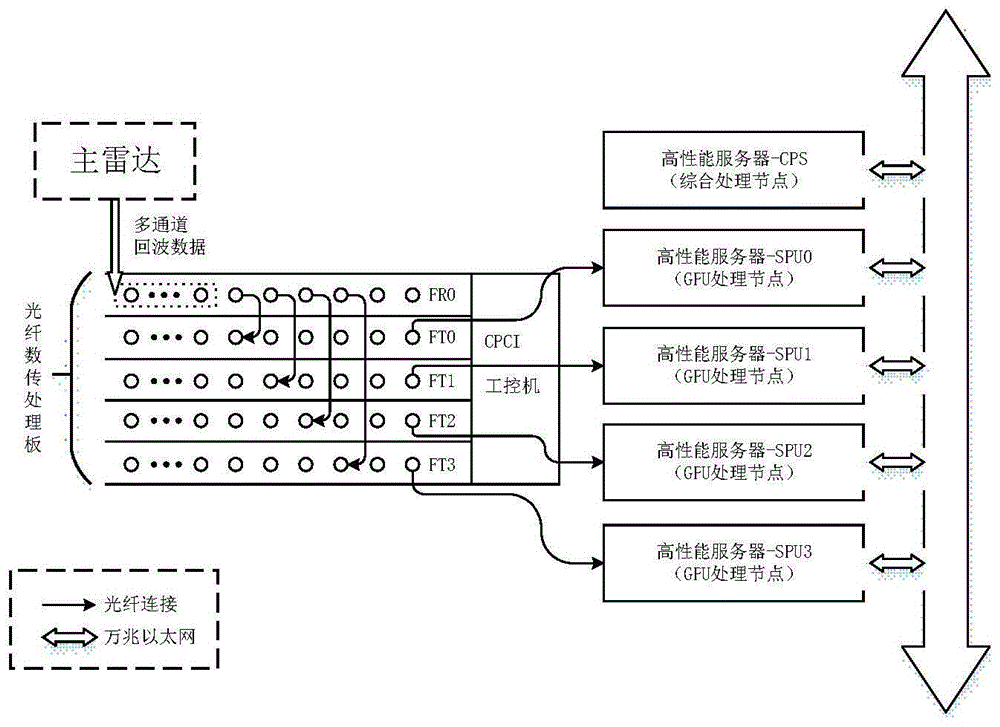
图1本发明的基于GPU集群的雷达探测空间目标并行信号处理系统硬件配置图;
图2本发明的基于GPU集群的雷达探测空间目标并行信号处理系统硬件架构图;
图3本发明的光纤数传处理板(475T)结构框图;
图4本发明的光纤数传处理板(130T)结构框图;
图5本发明的光纤数据接收处理板结构框图;
图6本发明的处理流程图;
图7本发明的处理节点资源分配示意图。
具体实施方式
下面结合附图并举实施例,对本发明进行详细描述。
本发明提供了基于GPU集群的雷达探测空间目标并行信号处理系统,该系统包括光纤数据接收转发模块、光纤数据分发模块、多个GPU处理节点及综合处理模块。
光纤数据接收转发模块与光纤数据分发模块间、光纤数据分发模块与多个GPU处理节点间通过光纤连接;多个处理节点与综合处理模块通过以太网连接;
光纤数据接收转发模块用于进行多路雷达回波光纤数据的接收与合并,合并后的回波数据转发给光纤数据分发模块。
光纤数据分发模块解析合并后的回波数据中的控制信息,从数据流提取发射脉冲调制类型、发射脉宽以及信号带宽信息,对合并后的回波数据进行筛选,将筛选出的回波数据转发至对应的GPU处理节点。
本发明实施例中,光纤数据接收转发模块包含至少一块光纤数传处理板;光纤数据分发模块包含至少一块光纤数传处理板;其中光纤数据分发模块中的每一块光纤数传处理板对应连接一个GPU处理节点;光纤数传处理板上至少搭载1片FPGA芯片。光纤数传处理板上还搭载有1片DSP芯片和2片SDRAM芯片,同时外挂DDR存储芯片;光纤数传处理板安装于标准CPCI机箱。本发明实施例提供了两种光纤数传处理板的形式分别如图3和图4所示。图3为本发明的光纤数传处理板(475T)结构框图;图4为本发明的光纤数传处理板(130T)结构框图。
GPU处理节点通过DMA方式获取筛选出的回波数据,解析回波数据控制信息附带的回波标识,根据分配的节点ID筛选需要处理的数据范围,完成信号的距离对齐、相位补偿、脉冲压缩、相参积累、恒虚警检测CFAR和参数测量。
本发明实施例中,每个GPU处理节点的主体为带有PCIe接口的通用服务器,搭载一块PCIe接口的光纤数据接收处理板与4块GPU计算卡,其中光纤数据接收处理板搭载了1片FPGA并可外挂两条DDR3内存用于收发缓存,通过PCIe接口与服务器连接,以DMA方式完成数据的高速传输。
本发明实施例中,每个GPU处理节点上均设置有节点处理程序,节点处理程序申请一段连续的内存空间后与光纤数据接收处理板通过DMA方式完成数据的传输;节点处理程序解析回波数据控制信息附带的回波标识,根据分配的节点ID,选取滑窗处理过程中分配给该节点ID的积累窗范围,完成信号的距离对齐、相位补偿、脉冲压缩、相参积累、恒虚警检测CFAR和参数测量,并将该积累窗的处理结果上报给综合处理模块。
综合处理模块接收各个GPU处理节点的状态信息,完成各GPU处理节点的管理与GPU处理节点间数据级的整合,得到最终的检测和参数测量结果。
本发明实施例中,综合处理模块为通用服务器,各GPU处理节点与综合处理模块间通过以太网连接。
本发明实施例中,综合处理模块上设置有综合处理程序,综合处理程序通过以太网络接收各个节点上报的系统状态,并根据当前的积累脉冲数和设置的滑窗数分配不同的节点ID给节点处理程序;其中积累脉冲数为N,滑窗数为m,则对于节点数等于滑窗数的情况,节点0的处理范围为第1~N个脉冲,节点1的处理范围为
多GPU处理节点间数据的传输、同步由底层板卡实现,GPU处理节点的具体计算任务由综合处理模块分配、管理,各GPU处理节点只负责完成计算任务。
下面以某空间目标雷达探测GPU集群并行信号处理系统样机为例,结合附图对本发明进行详细说明。
某空间目标雷达探测GPU集群并行信号处理系统样机主要包括:1个6槽的CPCI机箱,5块光纤数传处理板(编号FR0、FT0、FT1、FT2、FT3),5台高性能服务器(编号CPS、SPU0、SPU1、SPU2、SPU3)组成,其中四台服务器各自搭载4块通用图形处理器GPU和一块光纤数据接收处理板,设备的硬件配置如图1所示。硬件架构及连接关系如图2所示。
光纤数传处理板(475T)FR0采用FPGA+DSP架构,可插于CPCI工控机箱。板上FPGA的型号为XC6VLX475T,片上含有可编程逻辑块CLB达77400个以及2016个乘法器DSP48E单元,内部存储单元BRAM可达38304Kb,其板载DDR3存储容量最高可达4GB,以及4组光纤数据收发通道最高速率可达5Gbps,板上具备丰富的时钟资源具有50MHz、150Mhz晶振可供FPGA内部编程使用,以及150MHz的差分晶振,作为高速接口的参考时钟。板卡结构如图3所示。
光纤数传处理板(130T)FT0-FT3采用R9-DSPEED-DTIO-LX130T,是一块FPGA+DSP架构的硬件板卡,其FPGA为Xilinx公司的XC6VLX130T-1FFG1156,LXT子系列具有丰富的逻辑资源,逻辑资源CLBs达到20000Slices,乘法器DSP48E1有481Slices,存储器BRAM有9504KB,其主要用于高性能的逻辑控制及高速数据传输,拥有高速串行传输的吉比特收发器GTX达20个,DSP为TI公司的TMS320C6455BZTZ,其工作频率1GHz,峰值运算能力3200MIPS,该DSP拥有4MB的SRAM存储器,并挂载2片512MB的DDR II SDRAM。此外,为了兼容光纤传输,该板卡上具有四个光模块AFBR-57D7APZ,该光模块支持LC接口全双工传输,光纤通道FC-4和FC-2协议传输,支持8.5GBd/4.25GBd/2.215GBd的速率,最远传输距离分别为150m/380m/500m,SFP封装支持热拔插,使用更加灵活方便。板卡结构如图4所示。
光纤数据接收处理板R9-PCIe-FIBRE-Q4000板上FPGA为XC6VLX240T-2FFG1156,其速度等级较130T高,板上逻辑资源更加丰富,Slices资源达到130T的两倍,存储器BRAM14976KB,拥有24个GTX,此外其拥有PCI Express接口两个,更加方便的实现PCIExpress协议,PCI Express侧通过金手指与主机直接连接,拥有四个光纤模块,此外板上还有用于收发缓存的DDR3内存条MT4JSF12864HY-1G4两条,需1.5v供电,数据位宽64bit,容量1GB。板卡结构如图5所示。
通用图形处理器GPU选择NVIDIA Tesla A100,单精度浮点运算能力可达19.5万亿次/秒,四台高性能处理器共16块GPU卡,可完成单精度浮点312万亿次/秒的计算。
下面结合图6对GPU集群处理样机的处理流程进行详细介绍:
光纤数传处理板FR0主要实现3路雷达回波光纤数据的接收且合并为一路并分发给4块光纤数传处理板FT0-FT3。高速串口GTX_rx1至GTX_rx3和光模块完成3路光纤数据的接收,同时使用3个FIFO实现三路回波数据的合并与同步。因为接收数据的瞬时速率高于发送数据瞬时速率,因此使用FPGA外挂的DDR3模块进行缓存。因DDR3控制器的时钟为与前后模块间为异步时钟且数据位宽不一致,使用异步非对称FIFO_1、FIFO_2对数据进行跨时钟域处理和位宽转换。
光纤数传处理板FT0-FT3接收FR0发送的合并后的雷达回波数据,并对数据进行筛选并转发至GPU处理节点。回波数据选取模块使用筛选控制状态机基于两级FIFO完成,通过雷达控制信息中的发射脉冲调制类型、发射脉宽、信号带宽参数综合判断。因此使用第一级同步FIFO先缓存雷达控制信息,并对其中发射脉冲调制类型、发射脉宽、信号带宽信息进行解包判断。若不是处理节点需要的回波数据,则将同步FIFO清空,且不再接收这一包的回波数据。若为处理节点需要的回波数据,读取同步FIFO_1的数据至异步FIFO_2,其中异步FIFO_2完成GTX用户时钟至Aurora用户时钟的跨时钟域要求。至此完成回波数据预筛选功能。
GPU处理节点上的光纤数据通过Aurora接收后缓存至板载DDR芯片中。节点处理程序申请一段连续的内存空间后等待接收光纤数据接收处理板发送的中断,并告知所申请内存的物理地址和空间大小,启动DMA;光纤数据接收处理板FPGA上的DMA控制器自动填充处理层数据包逐一的增加地址,直到达到节点处理程序设定的长度,然后发送一个中断;节点处理程序接收到中断后将物理内存中的数据拷贝到想要存储的空间内完成一次数据的传输。节点处理程序解析回波数据控制信息附带的回波标识,根据分配的节点ID筛选需要处理的数据范围,完成信号的距离对齐、相位补偿、脉冲压缩、相参积累、恒虚警检测(CFAR)和参数测量。这里的数据分配逻辑如图7所示,如进行128的脉冲的相参积累,并对脉冲进行编号,则ID=0的节点需对编号1-128和65-192脉冲的分别进行相参积累处理,ID=1的节点需对编号17-144和81-208脉冲的分别进行相参积累处理,ID=2的节点需对编号33-160和97-224脉冲的分别进行相参积累处理,ID=3的节点需对编号,49-176和113-240脉冲的分别进行相参积累处理。
综合处理程序首先通过以太网络接收各个GPU处理节点发送的状态信息,并为每个节点分配唯一的节点ID;当检测到一个或多个GPU处理节点状态异常时,综合处理程序会尝试进行软件复位操作,如无法恢复,则自适应的修改处理参数以适应运算能力的下降。当接收到各个节点的处理结果后,综合处理程序对测量结果进行融合处理,以完成后续目标跟踪及特性测量的相关处理。
从上述本发明的具体实施方案可以看出,本发明采用标准化、模块化的CPCI板卡来构建多通道的数字接收转发系统,以完成GPU集群各个节点内数据的同步;综合处理节点通过主从模式灵活地分配各个处理节点的计算任务。系统充分利用了FPGA灵活的数据输入输出接口、强的控制能力及GPU超高速的运算能力,结构规整,能够满足需要强实时控制以及超高速运算能力下的空间目标探测要求。同时,该处理架构具有扩展性,通过增加光纤数据接收转发模块、光纤数据分发模块的数量,可进一步增加GPU处理节点的数量以满足不同处理任务的需要。
综上所述,以上仅为本发明的较佳实施例而已,并非用于限定本发明的保护范围。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 基于GPU的信号级雷达目标探测系统及探测方法
- 一种基于雷达信号的多目标生命探测方法及探测雷达