一种基于大数据的论文相似度检测方法和装置
文献发布时间:2023-06-19 11:54:11
技术领域
本发明涉及一种基于大数据的论文相似度检测方法和装置。
背景技术
通过论文相似度检测方法对两篇论文的相似度进行检测,以确定是否存在抄袭的情况。目前的论文相似度检测方法为:将两篇论文划分为多个词组,然后依次对比两篇论文中的各个词组,根据词组是否相同确定相似度。通常而言,词组仅仅是一个具有两个、三个或者四个单字的词语。
现有的论文相似度检测方法只通过词组是否相同来确定两个论文的相似度,准确性较差。
发明内容
本发明提供一种基于大数据的论文相似度检测方法和装置,用于解决现有的论文相似度检测方法的准确性较差的技术问题。
一种基于大数据的论文相似度检测方法,包括如下步骤:
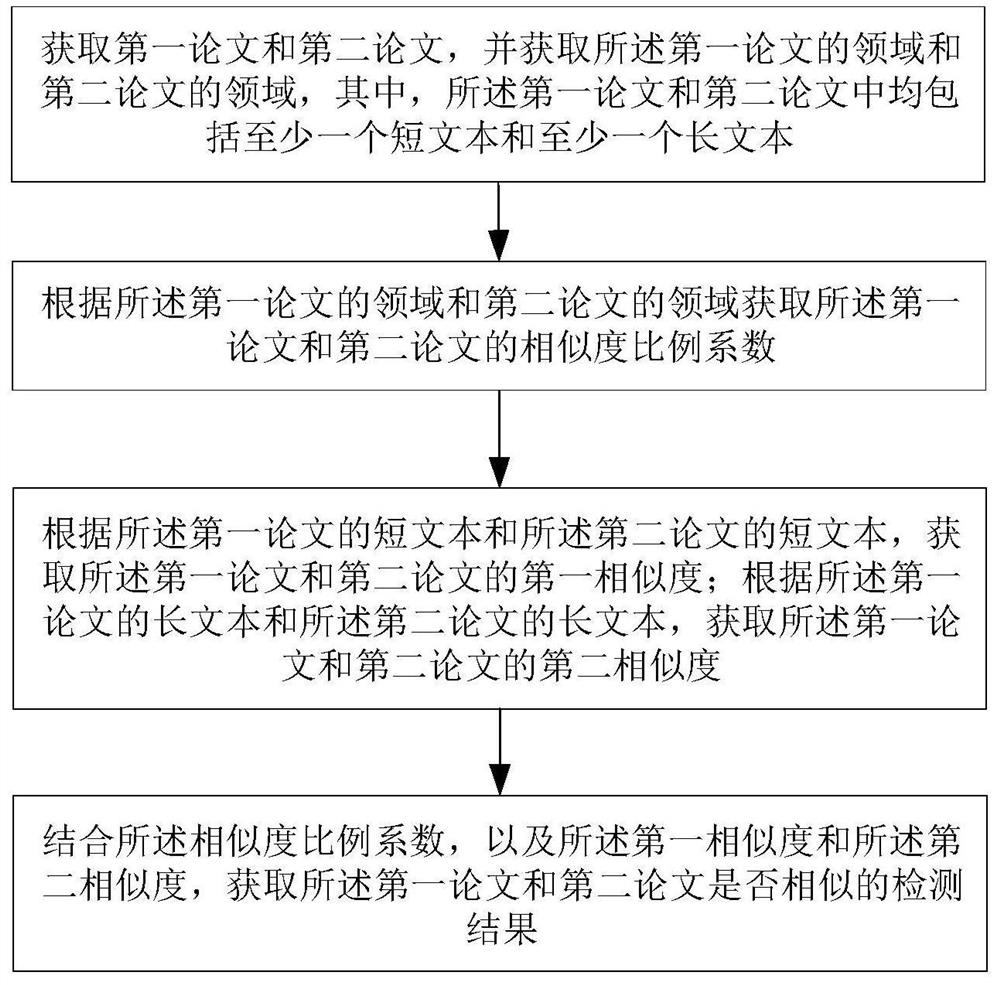
获取第一论文和第二论文,并获取所述第一论文的领域和第二论文的领域,其中,所述第一论文和第二论文中均包括至少一个短文本和至少一个长文本;
根据所述第一论文的领域和第二论文的领域获取所述第一论文和第二论文的相似度比例系数;
根据所述第一论文的短文本和所述第二论文的短文本,获取所述第一论文和第二论文的第一相似度;根据所述第一论文的长文本和所述第二论文的长文本,获取所述第一论文和第二论文的第二相似度;
结合所述相似度比例系数,以及所述第一相似度和所述第二相似度,获取所述第一论文和第二论文是否相似的检测结果。
具体地,所述根据所述第一论文的领域和第二论文的领域获取所述第一论文和第二论文的相似度比例系数具体为:
若所述第一论文的领域和第二论文的领域相同,则所述相似度比例系数为一个大于1的数值,若所述第一论文的领域和第二论文的领域不同,则所述相似度比例系数为1。
具体地,所述根据所述第一论文的领域和第二论文的领域获取所述第一论文和第二论文的相似度比例系数具体为:
将所述第一论文的领域和第二论文的领域输入至预设的领域知识图谱中,确定所述第一论文的领域和第二论文的领域是否相同或者相关;
若所述第一论文的领域和第二论文的领域相同或者相关,则所述相似度比例系数为一个大于1的数值,若所述第一论文的领域和第二论文的领域不同且不相关,则所述相似度比例系数为1。
具体地,所述结合所述相似度比例系数,以及所述第一相似度和所述第二相似度,获取所述第一论文和第二论文是否相似的检测结果具体为:
计算所述第一相似度和所述第二相似度的平均值,并计算所述平均值与所述相似度比例系数的乘积,得到所述第一论文和第二论文的最终相似度;
将所述最终相似度与预设相似度阈值进行比对,若所述最终相似度大于或者等于所述预设相似度阈值,则所述检测结果为所述第一论文和第二论文相似;若所述最终相似度小于所述预设相似度阈值,则所述检测结果为所述第一论文和第二论文不相似。
具体地,所述根据所述第一论文的短文本和所述第二论文的短文本,获取所述第一论文和第二论文的第一相似度具体为:
根据所述第一论文的短文本和所述第二论文的短文本,计算所述第一论文的和第二论文的杰卡德距离。
具体地,所述根据所述第一论文的短文本和所述第二论文的短文本,计算所述第一论文的和第二论文的杰卡德距离具体为:
获取所述第一论文的短文本和所述第二论文的短文本中的相同词组;
计算每个相同词组在短文本中的权重;
根据所述权重计算所述第一论文的和第二论文的杰卡德距离。
具体地,所述根据所述第一论文的长文本和所述第二论文的长文本,获取所述第一论文和第二论文的第二相似度具体为:
根据所述第一论文的长文本和所述第二论文的长文本,获取所述第一论文和第二论文的余弦相似度。
具体地,所述根据所述第一论文的长文本和所述第二论文的长文本,获取所述第一论文和第二论文的余弦相似度具体为:
对所述第一论文的长文本中的每个词组进行处理,得到第一词向量,并根据所述第一词向量计算所述第一论文的长文本中每个语句的第一句向量;
对所述第二论文的长文本中的每个词组进行处理,得到第二词向量,并根据所述第二词向量计算所述第二论文的长文本中每个语句的第二句向量;
根据所述第一句向量和所述第二句向量计算所述第一论文和第二论文的余弦相似度。
具体地,所述根据所述第一词向量计算所述第一论文的长文本中每个语句的第一句向量具体为:
通过如下计算公式计算第一论文的长文本中每个语句的初始向量A:
其中,T为所述语句中词组的个数,v
根据计算出的初始向量A,得到向量集合,并计算所述向量集合的主成分向量;
将每个语句的初始向量A中的所述主成分向量去除,得到所述第一论文的长文本中每个语句的第一句向量。
一种基于大数据的论文相似度检测装置,包括存储器、处理器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现如上述的基于大数据的论文相似度检测方法的步骤。
本发明的技术效果包括:根据两个论文的领域获取第一论文和第二论文的相似度比例系数,然后,对第一论文中的短文本和第二论文中的短文本进行处理,得到第一论文和第二论文的第一相似度,对第一论文的长文本和第二论文的长文本进行处理,得到第一论文和第二论文的第二相似度,最后结合相似度比例系数以及第一相似度和第二相似度,获取第一论文和第二论文是否相似的检测结果。首先将第一论文和第二论文的领域参与到论文是否相似的检测中,根据两个论文的领域满足的相关条件获取相似度比例系数,相似度比例系数为判定论文是否相似的其中一个因素,能够提升检测准确性,而且,对第一论文和第二论文的不同长短的文本分别进行处理,得到对应的相似度,相较于只通过固定大小且长度比较短的词组是否相同来确定两个论文的相似度,能够提升检测准确性。
附图说明
图1是本发明提供的一种基于大数据的论文相似度检测方法的流程图。
具体实施方式
基于大数据的论文相似度检测方法实施例:
本实施例提供一种基于大数据的论文相似度检测方法,该基于大数据的论文相似度检测方法可以应用于服务器、计算机设备、智能移动终端等等。如图1所示,基于大数据的论文相似度检测方法包括以下步骤:
(1)获取第一论文和第二论文,并获取所述第一论文的领域和第二论文的领域,其中,所述第一论文和第二论文中均包括至少一个短文本和至少一个长文本:
获取第一论文和第二论文,第一论文和第二论文为相似度检测对象。应当理解,获取到的第一论文和第二论文为论文正文。并得到第一论文的领域和第二论文的领域。其中,第一论文的领域和第二论文的领域可以由论文题目的关键字得到,或者第一论文的领域和第二论文的领域是事先确定好的,在得到第一论文和第二论文之后,直接就可以获取到第一论文的领域和第二论文的领域。
第一论文和第二论文中均包括多个文本,各文本的划分由实际情况进行具体设置。其中,第一论文和第二论文中均包括至少一个短文本和至少一个长文本。短文本为字数较少的文本,长文本为字数较多的文本,本实施例中,可以设置一个字数阈值,对于任意一个文本,若该文本的字数大于或者等于字数阈值,则确定该文本为长文本,若该文本的字数小于字数阈值,则确定该文本为短文本。
应当理解,短文本和长文本中,均包括多个词组,词组可以为常规的、由两个单字、三个单字或者四个单字构成的词语。
(2)根据所述第一论文的领域和第二论文的领域获取所述第一论文和第二论文的相似度比例系数:
根据第一论文的领域和第二论文的领域,获取第一论文和第二论文的相似度比例系数。其中,相似度比例系数的大小与第一论文的领域和第二论文的领域相关。
本实施例中,根据第一论文的领域和第二论文的领域获取第一论文和第二论文的相似度比例系数具体为:若第一论文的领域和第二论文的领域相同,则需要更加趋向于第一论文和第二论文相似这一可能性,那么,相似度比例系数为一个大于1的数值(应当理解,相似度比例系数的具体数值由实际需要进行设置,比如1.2);若第一论文的领域和第二论文的领域不同,则相似度比例系数为1。
作为另外的一个实施方式,根据第一论文的领域和第二论文的领域获取第一论文和第二论文的相似度比例系数具体为:预设一个领域知识图谱,该领域知识图谱包括目前已知所有的论文涉及到的领域,以及各论文领域之间的关系,从该领域知识图谱中,就可以获取到任意两个领域之间的关系,即是否相同或者相关。那么,将第一论文的领域和第二论文的领域输入至该领域知识图谱中,确定第一论文的领域和第二论文的领域是否相同或者相关;若第一论文的领域和第二论文的领域相同或者相关(相关可以指相近),则相似度比例系数为一个大于1的数值(应当理解,相似度比例系数的具体数值由实际需要进行设置,比如1.2),若第一论文的领域和第二论文的领域不同且不相关,即第一论文的领域和第二论文的领域毫无关系,则相似度比例系数为1。
(3)根据所述第一论文的短文本和所述第二论文的短文本,获取所述第一论文和第二论文的第一相似度;根据所述第一论文的长文本和所述第二论文的长文本,获取所述第一论文和第二论文的第二相似度:
该步骤包括两部分,分别是根据第一论文的短文本和第二论文的短文本,获取第一论文和第二论文的第一相似度,以及根据第一论文的长文本和第二论文的长文本,获取第一论文和第二论文的第二相似度,以下分别进行说明。
本实施例中,根据第一论文的短文本和第二论文的短文本,获取第一论文和第二论文的第一相似度具体为:根据第一论文的短文本和第二论文的短文本,计算第一论文的和第二论文的杰卡德距离,即第一相似度为杰卡德距离。
杰卡德距离(Jaccard Distance)是用来衡量两个集合差异性的一种指标,它是杰卡德相似系数的补集,被定义为1减去Jaccard相似系数,而杰卡德相似系数(Jaccardsimilarity coefficient),也称杰卡德指数(Jaccard Index),是用来衡量两个集合相似度的一种指标。
作为一个具体实施方式,以下给出根据第一论文的短文本和第二论文的短文本,计算第一论文的和第二论文的杰卡德距离的一种具体算法过程:
由于第一论文的短文本和第二论文的短文本中均包括多个词组,那么,获取第一论文的短文本和第二论文的短文本中的相同的词组,即相同的词组定义为相同词组。
计算每个相同词组在短文本中的权重。本实施例采用tf-idf技术进行权重计算,其中,tf表示词频,指某个词在某份文件中出现的频率,计算公式如下:
其中,j表示文本,i表示文本j中的第i个词,那么,n
idf表示逆文件频率指数,指文件集中包含文件的总份数除以包含该词的文件的份数,计算公式如下:
其中,|D|表示文件集中的文件总份数,|{j:t
将得到的tf和idf相乘,乘积为tf-idf权重。那么,每个相同词组在短文本中的权重的计算方式可以为:1、先计算每个相同词组在其各自所在的短文本中的tf-idf权重,然后计算所有tf-idf权重的和值,得到的和值为每个相同词组在短文本中的权重;2、直接计算每个相同词组在所有短文本中的tf-idf权重,得到每个相同词组在短文本中的权重。
根据权重计算第一论文的和第二论文的杰卡德距离,作为一个具体实施方式,采用如下计算公式计算杰卡德距离J:
其中,R为相同词组的个数,a
本实施例中,根据第一论文的长文本和第二论文的长文本,获取第一论文和第二论文的第二相似度具体为根据第一论文的长文本和第二论文的长文本,获取第一论文和第二论文的余弦相似度,即第二相似度为余弦相似度。
作为一个具体实施方式,以下给出根据第一论文的长文本和第二论文的长文本,获取第一论文和第二论文的余弦相似度的具体算法过程:
对第一论文的长文本中的每个词组进行处理,得到第一词向量,并根据第一词向量计算第一论文的长文本中每个语句的第一句向量。作为一个具体实施方式,可以将第一论文的长文本中的每个词组输入到预设的词向量数据库中,生成第一词向量,其中,词向量数据库包括多个词组,以及与各词组对应的词向量。下述第二词向量的获取过程与上述同理。
以下给出第一论文的长文本中每个语句的第一句向量的计算过程:通过如下计算公式计算第一论文的长文本中每个语句的初始向量A:
其中,T为语句中词组的个数,v
根据计算出的初始向量A,得到向量集合,向量集合由计算出的各初始向量A组成,并计算向量集合的主成分向量。主成分向量可以用于表示向量集合的两两不相关、且具有最大方差的标准化线性组合。主成分向量中每个元素对应向量集合的一个特征值。
将每个语句的初始向量A中的主成分向量去除,即对于第一论文的长文本中的任意一个语句而言,该语句的初始向量A减去主成分向量,得到该语句的第一句向量。从而得到第一论文的长文本中每个语句的第一句向量。
对第二论文的长文本中的每个词组进行处理,得到第二词向量,并根据第二词向量计算第二论文的长文本中每个语句的第二句向量。同理,采用上述过程得到第二论文的长文本中每个语句的第二句向量。
根据第一句向量和第二句向量计算第一论文和第二论文的余弦相似度。作为一个具体实施方式,以下给出余弦相似度的具体算法过程:将所有的第一句向量生成第一矩阵,将所有的第二句向量生成第二矩阵,利用如下计算公式计算余弦相似度:
其中,A
(4)结合所述相似度比例系数,以及所述第一相似度和所述第二相似度,获取所述第一论文和第二论文是否相似的检测结果:
得到相似度比例系数、第一相似度和第二相似度之后,根据相似度比例系数、第一相似度和第二相似度,对第一论文和第二论文是否相似进行判断,具体为:
先计算第一相似度和第二相似度的平均值,然后计算平均值与相似度比例系数的乘积,得到第一论文和第二论文的最终相似度。
然后,将最终相似度与预设相似度阈值进行比对,预设相似度阈值由实际需要进行设定。其中,若最终相似度大于或者等于预设相似度阈值,表示最终相似度数值较大,则检测结果为第一论文和第二论文相似;若最终相似度小于预设相似度阈值,表示最终相似度数值较小,则检测结果为第一论文和第二论文不相似。
基于大数据的论文相似度检测装置实施例:
本实施例提供一种基于大数据的论文相似度检测装置,包括存储器和处理器,以及存储在存储器上并在处理器上运行的计算机程序,处理器与存储器相耦合,处理器执行计算机程序时实现上文中的基于大数据的论文相似度检测方法,由于该基于大数据的论文相似度检测方法在上文已给出了详细说明,不再赘述。
- 一种基于大数据的论文相似度检测方法和装置
- 一种基于信息相似度的睡眠呼吸暂停检测方法及装置