用于井优化的自主故障预测和泵控制
文献发布时间:2023-06-19 13:46:35
相关申请的交叉引用
本专利申请要求2019年4月5日提交的题为“Autonomous Failure Predictionand Pump Control for Well Optimization”的美国临时申请第62/829,834号的优先权和2020年1月29日提交的题为“Well Site Edge Analytics”的美国临时申请第62/967,492号的优先权,并通过引用将其并入本文。
技术领域
本公开涉及监测和控制油气井以确保井的正确操作,并且更具体地,涉及使用井场边缘分析来检测异常事件和操作条件的发生以实时监测和控制井操作的方法和系统。
背景技术
石油和天然气井通常用于从地下地层中提取碳氢化合物。典型的井场包括已经钻入地层的井眼和在井眼内胶合就位以稳定和保护井眼的管道或套管部分。套管在井眼的某个目标深度被穿孔,以允许石油、天然气和其他流体从地层流入套管。油管沿着套管向下延伸,为石油和天然气提供管道以向上流动到它们被收集的地面。如果地层中有足够的压力,则石油和天然气可以自然地沿油管向上流动,但通常在井场需要泵送装备将流体带到地面。
由于石油和天然气井位于偏远地区,它们通常在无人值守的情况下操作延长的时间间隔。在这些时间间隔期间,许多环境和其他因素会影响井的操作。当出现问题时,现场人员通常需要前往井场,对装备进行物理检查,并进行任何必要的维修。这可能是成本高且耗时的工作,导致井的所有者和操作员的生产力和盈利能力下降,并且对现场人员也是危险的。
因此,尽管在石油和天然气生产领域已经取得了许多进步,但是很容易理解,仍然需要不断的改进。
发明内容
本公开涉及使用边缘分析进行在井场实时监测和控制井操作的系统和方法。该系统和方法直接在井场的边缘设备上部署基于机器学习(machine learning,ML)的分析,以检测异常事件和操作条件的可能发生,并自动响应这些事件。事件检测可以基于在从实时井操作中获取的操作参数数据中识别的趋势。趋势可以通过分析数据的变化率来识别,也可以通过对数据使用统计相关技术来识别。在检测到异常事件可能正在发生或将要发生时,边缘设备可以发出关于该事件的警示,并采取预定义的步骤来减少由该事件导致的潜在损害。这有助于减少停机时间,最大限度地降低生产力和成本损失,并降低现场人员的健康和安全风险。
总的来说,在一个方面,本公开的实施例涉及安装在井场并可操作来监测井场操作的边缘设备。边缘设备尤其包括处理器和存储设备,存储设备耦合到处理器并在其上存储用于井场监测和控制应用的计算机可读指令。井场监测和控制应用使得边缘设备尤其从井场处的远程可编程自动化(remote programmable automation,PAC)控制器接收井场数据,井场数据表示与井场操作相关的一个或多个操作参数。井场监测和控制应用还使得边缘设备使用来自PAC的井场数据在井场处执行基于机器学习(ML)的分析。井场监测和控制应用还使得边缘设备根据基于ML的分析检测与井场操作相关的事件的发生,并基于一个或多个事件在边缘设备上发起响应动作。
根据前述实施例中的任何一个或多个,井场操作包括由井场处的ESP(电动半潜泵)执行的泵操作,并且井场数据包括与井场处的ESP执行的泵操作相关的数据。
根据前述实施例中的任何一个或多个,井场监测和控制应用还使得边缘设备将井场数据实时地流式传输到一个或多个ML模型中,该一个或多个ML模型包括执行基于相关性的检测和基于示意图的检测中的一个的模型,通过将线段拟合到井场数据并确定线段的斜率来执行基于示意图的检测,和/或通过将线段的斜率与预定斜率阈值进行比较来执行事件的检测。
根据前述实施例中的任何一个或多个,井场监测和控制应用还使得边缘设备允许操作员修改其预定义斜率阈值中的斜率阈值和与之对应的事件,基于ML的分析是使用预定义时间窗口逐步执行的,和/或预定义时间窗口包括基于被检测事件的优先级而具有不同持续时间的时间窗口。
总的来说,在另一方面,本公开的实施例涉及一种监测井场操作的方法。该方法尤其包括从井场处的远程可编程自动化(PAC)控制器接收井场数据,井场数据表示与井场操作相关的一个或多个操作参数。该方法还包括使用来自PAC的井场数据在井场处的边缘设备上执行基于机器学习(ML)的分析。该方法还包括根据基于ML的分析在边缘设备上检测与井场操作相关的事件的发生,并基于一个或多个事件在边缘设备上启动响应动作。
根据前述实施例中的任何一个或多个,井场操作包括由井场处的ESP执行的泵操作,并且井场数据包括与井场处的ESP的泵操作相关的数据。
根据前述实施例中的任何一个或多个,执行基于ML的分析包括将井场数据实时地流式传输到一个或多个ML模型中,该一个或多个ML模型包括执行基于相关性的检测和基于示意图的检测中的一个的模型,通过将线段拟合到井场数据并确定线段的斜率来执行基于示意图的检测,和/或通过将线段的斜率与预定义的斜率阈值进行比较来执行事件的检测。
根据前述实施例中的任何一个或多个,该方法还包括允许操作员修改斜率阈值和在其预定义斜率阈值中与其对应的事件,基于ML的分析是使用预定义时间窗口逐步执行的,和/或预定义时间窗口包括基于被检测事件的优先级而具有不同持续时间的时间窗口。
总的来说,在又一方面,本公开涉及包含程序逻辑的非暂时性计算机可读介质,当该程序逻辑被一个或多个计算机处理器的操作执行时,根据本文公开的任何一个或多个实施例执行井场监测操作。
附图说明
通过参考各种实施例,可以获得上文简要概述的本公开的更详细描述,其中一些实施例在附图中示出。虽然附图图示了本公开的选定实施例,但是这些附图不应被认为是对其范围的限制,因为本公开可以允许其他同等有效的实施例。
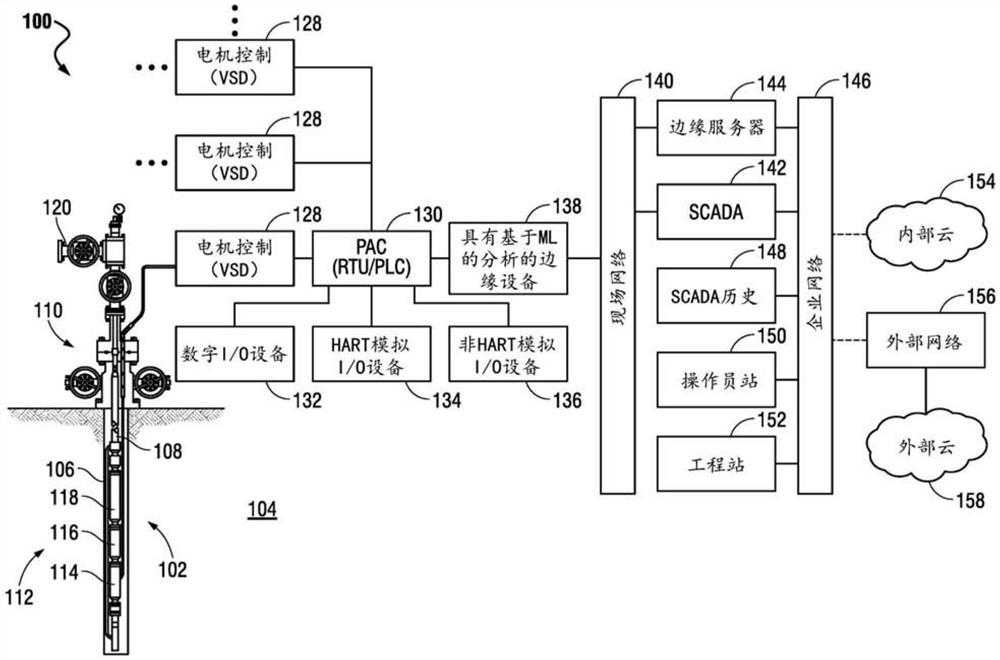
图1是根据本公开实施例的在井场处的基于ML的分析的示例性实施方式的示意图;
图2是根据本公开实施例的能够在井场处执行基于ML的分析的示例性边缘设备的框图;
图3是根据本公开实施例的用于将基于ML的分析部署到井场边缘设备的示例性软件架构的框图;
图4是示出根据本公开实施例的在井场边缘设备处的基于ML的分析的示例性操作阶段的图;
图5是举例说明根据本公开实施例的2-变量异常值检测的数据曲线图;
图6是示出根据本公开实施例的系统从稳定正常操作到异常事件的演变的概率曲线图;
图7是描绘根据本公开实施例的多变量概率确定的概率曲线图阵列;
图8是示出根据本公开实施例的用于井场边缘设备处的基于相关性的事件检测的示例性数据库的一部分的表;
图9是描绘根据本公开实施例的井场边缘设备处的基于示意图的事件检测的示例性操作阶段的流程图;
图10是示出根据本公开实施例的在井场边缘设备处使用时间窗口的示例性事件检测的图;
图11是示出根据本公开实施例的在井场边缘设备处的示例性基于示意图的事件检测的图;
图12是示出根据本公开实施例的在井场边缘设备处的基于示意图的事件检测的示例性斜率的表;
图13是示出根据本公开实施例的在井场边缘设备处使用多个时间窗口的示例性事件检测的图;
图14A-图14H是示出根据本公开实施例的在井场边缘设备处的用于监测事件检测的示例性用户界面的屏幕截图;
图15是示出根据本公开的在井场边缘设备处的用于监测事件检测的示例性用户界面的另一屏幕截图;和
图16是示出根据本公开实施例的在井场边缘设备处的事件检测的概率图的另一屏幕截图。
在可能的情况下,使用相同的附图标记来表示附图中相同的元件。然而,在一个实施例中公开的元件可以有益地用于其他实施例,而无需具体叙述。
具体实施方式
该描述和附图说明了本公开的示例性实施例,并且不应该被认为是限制性的,权利要求限定了本公开的范围,包括等同物。在不脱离本说明书和权利要求书的范围(包括等同物)的情况下,可以进行各种机械、组成、结构、电气和操作上的改变。在一些情况下,没有详细示出或描述众所周知的结构和技术,以免混淆本公开。此外,只要可行,参考一个实施例详细描述的元件及其相关方面可以包括在没有具体示出或描述它们的其他实施例中。例如,如果参考一个实施例详细描述了元件,而没有参考第二实施例描述该元件,则该元件仍然可以被声明为包括在第二实施例中。
注意,如在本说明书和所附权利要求中所使用的,单数形式的“一”和“该”以及任何单词的任何单数形式使用包括复数引用,除非明确且毫不含糊地限于一个引用。如本文所使用的,术语“包括”及其语法变体旨在是非限制性的,使得列表中项目的列举不排除可以被替换或添加到所列项目的其他类似项目。
在高水平上,本公开的实施例提供了用于在井场处使用基于机器学习(ML)的分析来实时监测和控制井操作的系统和方法。本文使用的术语“分析”通常指的是数据分析以及数据中有意义模式的识别和检测。所公开的系统和方法直接在井场处的边缘设备上部署基于ML的分析,以检测异常事件和异常操作条件,并自动对其做出响应。本文使用的术语“边缘设备”指的是被设计为提供对网络的访问或进入的设备,例如局域网(local areanetwork,LAN)、广域网(wide area network,WAN)、城域网(metropolitan area network,MAN)等。能够在边缘设备上执行基于ML的分析提供了许多益处,特别是对于位于远程的井场,在那里ML建模通常需要的计算资源可能不可用。在这种情况下(以及其他情况下),在边缘设备上执行ML建模允许操作员主动管理远程井场。具体而言,配备基于ML的分析的边缘设备可以自动检测可能指示非最佳生产和可能的装备故障的事件和操作条件,发出关于事件的警示,并采取预定义步骤来减少由此导致的潜在损害。这种边缘分析平台(edgeanalytics platform,EAP)有助于减少停机时间,从而最大限度地降低生产力和成本损失,并降低人员的健康和安全风险,否则他们可能不得不进行计划外的井场经历(即,减少“通勤时间”)。
当EAP在井场实施时,结合朝向所谓的工业物联网(Industrial Internet ofThings,IIoT)的广泛移动,上述益处变得更加明显。在IIoT环境中,井场操作员越来越多地使用互连的传感器和设备直接在井场收集和存储大量数据。然后,这些数据可以在井场处由配备有ML建模的边缘设备进行处理,以监测和控制井操作。考虑从井眼使用电动半潜泵(electric semisubmersible pump,ESP)产石油的井场。在ESP的操作期间,通常会收集大量原始数据,包括井口压力、泵排放压力、泵吸入压力、泵吸入温度、泵流速、电机温度等。配备ML建模的边缘设备可以实时处理数据,并识别数据中可能导致ESP故障的模式。然后,边缘设备可以生成警报,执行应急操作,并根据需要将处理的结果存储在本地服务器和/或云中。本地生成的数据一旦被加标签和处理,就可以用于更新和进一步训练ML模型,调试新的边缘设备,并通常改进井场操作。
本文的ESP的示例性实施例可以基于从地面和地面以下传感器收集的实时数据自主地控制井场处的ESP操作。这些实施例可以包括构建基于事件的ML模型的系统和方法,以识别时间序列数据和其他数据源中的模式,并对这些模式采取行动以改进/减轻井的性能。在这点上,多变量时间序列数据是从附接到例如变速驱动器(variable speed drives,VSD)、井下仪表和来自各种岸上井场和离岸平台的地面仪器的传感器接收的。对于后者,数据通常可以在岸上控制室获得,这是边缘分析解决方案所部署的地方。
本文讨论的ESP可以捕获高频数据,并应用模式识别算法,提供异常ESP性能的早期指示。然后,捕获和验证的模式可用于减少计划外停机时间、管理钻机活动、提高产量和增强操作员经验。本公开的技术的其他优点包括ESP的能够基于从地面和地面以下传感器捕获的高频数据来近乎实时地检测异常ESP性能模式的能力;ML模型的预测异常事件和基于预定工作流来通知和/或采取纠正措施的能力;EAP的提高ESP性能的能力,该ESP性能通过跟踪由运营和生产约束设定的关键绩效指标(key performance indicators,KPI)被转化为生产优化;以及EAP的在一时间段内迭代ML模型的能力,在该时间段内,通过操作员反馈、捕获的知识和真实世界的经验来提高模型精度,从而提高预测精度。后者可以通过迁移学习技术来提高模型精度。各种类型的分析算法可以应用于原始高频数据,以识别在确定的时间段内出现的数据趋势。该趋势可以是在一组数据输入中观察到的行为模式,这些数据输入在确定的时间段内是一致的。预训练的ML模型用于预测任何异常行为,无论是ESP还是与生产相关的行为,并且可以采取纠正措施,例如,通过VSD速度控制来改进/减轻井性能。这种校正动作可以是可配置模板的形式,该模板根据预测的异常行为指示要采取的动作类型,例如加速泵以清除泵中的沙子等。例如,EAP可以发送控制命令以在确定的时间段内加速泵,以避免异常行为的发生。
简言之,本公开的实施例提供了用于在IIoT环境中开发和部署稳健的ML建模的方法和系统,以直接在井场处自动检测异常事件和非最佳操作,并且还通过基于ML的分析确保预测的高水平准确性,从而产生增加的操作员信心。这种异常事件和非最佳操作在下文中简称为“事件”,并且可以包括例如泵断轴、油管中的孔、泵吸入处的堵塞、含水率的增加(即井内流体中的水量)、地面的关井(即关闭的井)、泵级中的堵塞、储层压力的增加、泵吸入处的游离气体的增加、泵级处的磨损、电机振动的增加、打开的节流器等。还应当理解,术语“检测”和“预测”在本文中可互换使用,指的是EAP的基于对底层数据中的模式的检测来预测事件的能力。
现在参考图1,根据本公开的实施例示出了井场100处的示例性EAP实施方式的示意图。可以看出,井眼102已经钻入井场100处的地下地层104中,并且套管106已经胶合到井眼102中。管道108从井口110通过套管106沿井眼102向下延伸,以从地层104接收和输送石油(或其他流体)。该示例中的地层104不再具有足够的地层压力来自然产石油,因此经由安装在井场100处的ESP 112提供人工提升。ESP 112通常包括如图所示连接的电机114、密封件116和泵118。ESP 112的操作对于本领域技术人员来说是众所周知的,因此为了经济起见,这里省略了其他常见部件,例如电机跨接底座、接地故障测量仪等。排放管线120将从井眼102产出的石油(或其他流体)运送到一个或多个储存罐(未明确示出),用于在地面储存和处理。
在地面上,通常为变速驱动器(variable speed drive,VSD)的电机控制单元128向ESP 112提供动力(即电流和电压)并调节其操作速度。电机控制单元128又由可编程自动化控制器(programmable automation controller,PAC)130控制,该控制器可以提供与远程终端单元(remote terminal unit,RTU)、可编程逻辑控制器(programmable logiccontroller,PLC)或其他类似的可编程控制器类似的控制功能。PAC 130从电机控制单元128接收关于ESP操作的数据,包括电机速度和负载,并从井眼102收集关于其他操作参数的数据,例如流速、压力、温度等。该数据可以由位于井眼102周围和内部的各种无线和有线I/O设备提供,包括数字I/O设备132、HART模拟I/O设备134和非HART模拟I/O设备136。I/O设备的示例包括温度传感器、压力传感器、流速传感器、接近传感器、电流/电压传感器、振动传感器、各种致动器等。根据所获取的数据,PAC 130可以根据其编程来监测和控制ESP 112的操作和井眼102处的其他操作。
电机控制单元128可以是几个电机控制单元128中的一个,每个电机控制单元控制相应井的相应ESP(未示出),它们连接到PAC 130并由PAC 130控制。PAC 130从每个电机控制单元128接收关于ESP操作的数据,以及由每个ESP的井处的无线和有线I/O设备提供的关于其他井操作参数的数据。边缘设备138为PAC 130提供到现场网络140的访问或入口点,现场网络140允许PAC 130将收集的数据传送到控制系统,例如监测和数据采集(supervisorycontrol and data acquisition,SCADA)系统142。任何类型的边缘设备或电器都可以用作边缘设备138,只要该设备对于本文讨论的目的具有足够的处理能力。合适的边缘设备的例子包括网关、路由器、路由交换机、集成接入设备(integrated access device,IAD)以及各种MAN和WAN接入设备。
在一些实施例中,还可以提供将现场网络140连接到企业网络146的边缘服务器144。从那里,数据可以被转发到企业内的其他系统,例如SCADA历史148、一个或多个操作员站150、一个或多个工程站152等。在一些实施例中,数据还可以被传送到私有企业云,例如内部云(on-premise cloud,OPC)154,以根据需要进行进一步处理。可选地,对于不太关心严格数据安全性的应用,数据也可以被传送到外部网络156,如因特网,并且随后被传送到外部云158,以便根据需要进一步处理。根据本公开的实施例,如下所述,边缘设备138具有对关于井眼102处的ESP操作和其他操作的数据执行基于ML分析的能力。
图2是示出根据本公开实施例的边缘设备138的示例性硬件架构200的框图。这里所示的边缘设备138是网关。在一个实施例中,边缘网关138包括用于在网关内传送信息的总线202或其他通信路径,以及与总线202耦合用于处理信息的CPU 204,例如ARM微处理器。边缘网关138还可以包括主存储器206,例如耦合到总线202的随机存取存储器(RAM)或其他动态存储设备,用于存储将由CPU 204执行的计算机可读指令。主存储器206还可以用于在由CPU 204执行的指令的执行期间存储临时变量或其他中间信息。
边缘网关138还可以包括耦合到总线202的只读存储器(ROM)208或其他静态存储设备,以用于为CPU 204存储静态信息和指令。计算机可读存储设备210,例如非易失性存储器(例如闪存)驱动器或磁盘,可以耦合到总线202,以用于为CPU 204存储信息和指令。CPU204还可以经由总线202耦合到诸如触摸屏接口的人机接口(human-machine interface,HMI)212,以用于向用户显示信息并允许用户与边缘网关138交互。PAC接口214可以耦合到总线202,以用于允许边缘网关138与PAC 130或类似的可编程控制器通信。可以提供网络或通信接口216以允许边缘网关138与诸如SCADA系统140和/或网络142的外部系统通信。
上面使用的术语“计算机可读指令”是指可以由CPU 204和/或其他组件执行的任何指令。类似地,术语“计算机可读介质”是指可用于存储计算机可读指令的任何存储介质。这种介质可以采取许多形式,包括但不限于非易失性介质、易失性介质和传输介质。非易失性介质可以包括例如光盘或磁盘,例如存储设备210。易失性介质可以包括动态存储器,例如主存储器206。传输介质可以包括同轴电缆、铜线和光纤,包括总线202的电线。传输本身可以采取电磁波、声波或光波的形式,例如在射频和红外数据通信过程中生成的电磁波、声波或光波。计算机可读介质的常见形式可以包括,例如,磁性介质、光学介质、存储芯片以及计算机可以从中读取的任何其他介质。
井场监测和控制应用220,或者更确切地说,其计算机可读指令,也可以驻留在存储设备210上或者下载到存储设备210。井场监测和控制应用220可以由CPU 204和/或边缘网关138的其他组件执行,以对来自PAC 130的数据执行基于ML的分析,从而自动检测事件并生成响应。这种监测和控制应用220可以用本领域技术人员已知的任何合适的计算机编程语言编写,使用已知的任何合适的软件开发环境。合适的编程语言的例子可以包括C、C++、C#、Python、Java、Perl等。
根据示例性实施例,井场监测和控制应用220可以包括数据预处理模块222、一个或多个ML算法或模型224以及响应动作模块226。顾名思义,数据预处理模块222对从PAC130接收的数据执行预处理(例如,滤波、平滑、放大等),以用于监测和控制应用220。监测和控制应用220将经预处理的数据输入到一个或多个ML模型224进行处理,以确定数据是否匹配或类似于一个或多个已知的数据模式。在优选实施例中,监测和控制应用220采用集合建模,其中多个不同的ML模型224被组合以获得更精确的结果。因此,集合模型有时被称为元模型。基于ML模型处理的结果,响应动作模块226采取适当的响应动作,范围从记录发生的日期和时间,到向SCADA系统142和/或授权人员发送警报消息,到指示PAC 130切断ESP 112的电源。注意,尽管主要讨论了ML模型,但是本领域普通技术人员将理解,除了ML模型之外或者代替ML模型,还可以使用经验模型来用于本文的目的。
图3示出了可用于在边缘网关138上部署ML模型224(和相关联的模块)的示例性架构300。该示例中的边缘架构300使用微软IoT边缘302,其在Ubuntu核306之上分解Docker容器304之间的本地处理,以支持嵌入式约束。这种基于容器的架构简化了部署,但需要能够运行Linux OS变量的基于Linux的网关,以及与众所周知的树莓派(Raspberry Pi)硬件相似的最小计算资源(即CPU、内存)。在该示例中,用于预测的容器304包括MODBUS,其使得能够在PAC 130和边缘网关138之间进行Modbus通信。还包括AzureML和EdgeAgent,AzureML有助于Azure上的机器学习,EdgeAgent检查硬件完整性,并确保所有必要的进程无缝运行。EdgeHub容器支持使用发布/订阅方法与云平台通信(例如,经由MQTT协议)。云连接允许出于维护目而远程监测和管理边缘网关138,以及跟踪ML模型224的有效性和准确性,并且还可以远程触发迁移学习(Transfer Learning),这是本领域技术人员已知的过程,由此在解决问题时获得的知识被应用于不同但相关的问题。简言之,图3中描绘的ML模型部署架构300适用于满足最低硬件要求的任何边缘网关,并且使用容器304来部署ML模型和其他相关联的组件,使得与不同硬件平台的互操作性更加无缝并且更容易管理。本领域普通技术人员将理解,本发明不限于容器的这种特定选择和布置,并且在本公开的范围内可以使用附加的和/或替代的容器。
在部署在边缘设备138上之前,首先需要训练该一个或多个ML模型224来检测预期在现场发生的各种类型的事件。通常而言,本公开的实施例考虑两种类型的事件检测技术,图诊断技术和多元相关技术。图诊断技术通常基于滑动时间窗口内代表各种井操作参数(包括ESP参数)的数据的时间变化率或斜率来检测事件。将具有特定斜率的参数的组合与各种事件的参数斜率的已知组合进行比较。例如,如果流速、井口压力和电流都在降低,而泵的排放压力在增加,那么ESP很可能正在经历或即将经历断轴等等。多元相关技术通常基于给定时间窗内各种井操作参数的斜率之间的统计相关性来检测事件。任何技术都可以单独用于本文的事件检测,并且优选地,两种技术并行使用以相互补充。不管使用哪种技术,或者两者都使用,ML模型224首先需要经历训练,然后它们才能以足够的精度检测事件,如图4中通常描绘的。
在图4中,图表400示出了几条图表线,每条线表示井操作参数(例如,流速、压力、温度、电压、电流等)的数据点。图表400和本文类似的图表有时被称为数据图。如图表400所示,ML模型224通常有两个操作阶段,训练阶段402和预测阶段404,在训练阶段402期间,使用历史数据集来训练模型以识别不同的事件,在预测阶段404中,训练的模型用于从实时获取的数据推断不同的事件。
历史数据集通常包含在ESP 112和/或其他ESP的先前操作期间获取的各种操作参数的测量值(例如,来自I/O设备132-136)。这些参数可以包括电机电流、电机电压、电机负载、泄漏电流、电机温度、电机输出功率、泵吸入压力、泵排放压力、井口压力、流速等。优选地,历史数据集专用于特定的ESP 112,以便相对于该ESP定制(初始通用的)ML模型224的性能。在任一情况下,训练教导ML模型124识别数据中的模式,如果未被纠正的话,该模式暗示事件当前正在发生或将在一定时间内发生。
在一些实施例中,可以使用自监督学习方法来进行训练,在监督学习方法中,将加标签的历史数据作为输入应用于ML模型。加标签是指标注或描述数据以及为数据创建标签或标记的过程。训练可以在场外(例如,在OPC154上)或在井场100处进行,并且可以包括使用商业上可获得的ML训练工具来开发和验证ML模型。在OPC 154或一些其他计算集群平台上开发ML模型具有额外的溢出,即其上的增强硬件资源的可用性提供了高计算能力,这在训练阶段期间被证明是有用的。数据预处理和准备是这个过程的关键部分,因为需要正确加标签的数据来产生高度精确的ML模型。
然后,被标记或被加标签的历史数据被用于训练一般的ML模型,该模型开始时相对于ESP类型是中性的,以便将经训练的模型的能力扩展到由任何类型的ESP产生的广义数据。可以被训练的通用ML模型的例子包括卷积神经网络(Convolutional Neural Network,CNN)、暹罗神经网络、支持向量机(Support Vector Machine,SVN)、自动编码器神经网络等。模型预测可以可选地使用集成建模技术来聚集,集成建模技术基于模型对于给定问题类别的准确性来给予模型更多的权重。经训练的ML模型224然后对照另一个训练数据集进行评估,该另一个训练数据集在初始模型训练阶段没有用于验证目的。根据所需的预测精度水平(即服务质量),训练阶段可以重复,直到实现满意的结果。模型性能可以通过改进数据预处理技术(如要求使用高分辨率数据)、增加数据集的数量等来提高。
在图4的示例中,历史数据集帮助ML模型224认识到当某个参数或参数组合(例如,电机泄漏电流、电机温度等)表现出特定的行为406时,例如在给定的时间窗口内超过特定相关性阈值的斜率或斜率的某个组合时,如果没有采取纠正措施,通常在某个时间量408内或在事件发生时间内发生事件1(例如,泵断轴)。类似地,历史数据集可以帮助ML模型224认识到当另一个参数或参数组合(例如,泵吸入压力、泵排放压力等)表现出另一种行为410时,如果没有采取纠正措施,通常在特定事件发生时间412内发生事件2(例如,堵塞的泵吸入)。模式识别训练(以及随后的推断)可以针对数据点逐步进行,例如在1分钟窗口、10分钟窗口、30分钟窗口或一些其他选择的时间增量内。
在从学习阶段实现令人满意的结果之后,经训练和验证的ML模型224可以被部署到边缘网关138。在一些实施例中,当边缘网关138连接到PAC130时(即,不连接到云),模型随着边缘网关138的试运转而部署。尽管边缘网关相对于典型的PAC通常具有更高的处理能力,但是应该考虑能够在每种类型的边缘网关138上有效操作的ML模型的类型,以帮助提供用于预测或推断目的的令人满意的响应时间。这有助于确保ML模型的响应时间足够快,以便及时识别任何异常数据,从而自动或由操作员采取有效措施。
一旦ML模型224及其支持组件被部署在边缘网关138上,实时预测或推断可以从网关从PAC 130接收数据开始。边缘网关138实时接收来自PAC130的数据作为反映各种参数的测量的原始数据点,然后使用监测和控制应用220的预处理模块222来预处理(例如,滤波、平滑、放大等)数据点。然后,部署在边缘网关138上的ML模型224处理数据点以从中推断各种事件,并输出关于任何推断事件的信息。响应动作模块226接收该输出,并基于该输出采取某些选定的动作,包括向SCADA系统142发出立即标志。在一些实施例中,来自ML模型224的输出也作为反馈提供给PAC 130,以采取经编程的校正动作,例如调节ESP 112的电机速度或切断ESP的电源。
在一些实施例中,ML模型224的使用多元相关性从数据中准确推断各种事件的能力是基于成对概率计算技术对多个参数的扩展,如图5-图8所示和所描述的。
现在转到图5,作为背景,示出了反映两个参数的数据点的示例性数据曲线图500,变量1(例如,排放压力)和变量2(例如,流动),其中一个参数依赖于另一个参数或与另一个参数相关。沿着变量1的典型或统计上可能的数据点的分布在502处被指示,其中统计上不太可能的异常值在504处被指示,而沿着变量2的典型或统计上可能的数据点的分布在506处被指示,其中统计上不太可能的异常值在508处被指示。区域510定义了曲线图500内统计上可能的数据点的分布。通过分析随着时间推移收集的各种参数的数据点的分布,可以使用统计上可能的数据点分布,基于参数的时间变化率或斜率来开发模型。
图6是示例性概率曲线图600,其示出了来自图5的参数具有基于参数的数据点的分布的给定斜率的可能性(即,从稳定的正常操作到异常操作的演变)。在该图中,椭圆602表示在正常操作条件下,在2-西格玛置信水平内(即,在95%置信范围内),参数的斜率可能被发现的区域。换句话说,在该区域602内具有斜率的参数指示ESP可能是稳定的或正常操作的。相反,圆圈604指示参数的斜率不太可能被发现的区域。在该区域604内具有斜率的参数指示ESP可能不稳定或操作异常(例如,由于地面关井)。
上述概率可以通过以本领域技术人员已知的方式计算数据的Mahalanobis距离d来确定,如下所示:
d=(x-μ)∑
在等式(1)中,x是表示给定参数的斜率的状态向量,μ是状态向量的平均值。在给定区域内找到斜率的概率P可以由等式(2)确定:
P=1-χ
当相关性被扩展到两个以上的参数,然后在数学上进行组合(例如,平均)时,已经观察到更好的建模性能,如图7中以图表形式所示。在该图中,示出了曲线图的阵列700,其中一个以702指示,示出了几对参数的数据点分布,包括流动、井口压力、泵排放压力和泵吸入压力。与其他参数之一相关的每个参数的概率斜率由Pn,m表示。例如,流速斜率与井口压力相关的概率由P1,2表示,而流速斜率与泵排放压力相关的概率由P1,3表示,以此类推。然后,合成概率P可以通过对组成概率取平均或者数学组合来确定,通常由等式3表示:
P= 然后可以设置初始阈值,如图8所示,以允许基于相关性的ML模型224检测反映当前发生或将在一定时间内发生的事件的斜率(基于历史数据)。在图8中,示出了初始相关性数据库800(或其一部分),其包含多个井操作参数(列)的以度为大内的阈值斜率802(行)。基于上面讨论的统计相关性,这些阈值斜率802被认为强烈指示或关联于井场的某些类型的已知事件(原因)804,并且可以是取决于特定参数的最小或最大阈值。可能有多行斜率对应于相同类型的事件(原因)804。如果从数据中导出的斜率足够接近数据库中的条目,则该相关性数据库800可以用于从输入数据中自动识别事件。数据库800可以随着时间推移自动地和经由手动的用户反馈来更新和丰富,这允许对已知类型的事件进行较少的人工干预。 用户可以根据需要不时地修改一个或多个阈值斜率802,例如,基于真实世界的经验或观察。由斜率反映的事件804的类型也可以由用户根据需要不时地定义(和重新定义)。例如,根据数据的新检测到的(未分配的)事件可以基于指定的斜率差参数与现有事件相关联。因此,可以基于新检测到的事件的每个信号的斜率与相关性数据库800中已经存在的事件的相应信号的斜率之间的差异程度,来做出将新检测到的(且尚未分配的)事件与数据库800中已经存在的事件类型相关联的决定。在未分配事件可以被识别为与数据库800中的事件类型相同之前所需的差异程度可以根据需要通过调整例如每个信号的指定斜率差异参数来调整。 图9是根据本公开的实施例更详细地示出图4的ML模型224的操作阶段的流程图900。这里,训练阶段402和预测阶段404以功能框示出,训练阶段402被分解成几个更小的步骤,包括初始设置步骤902、可视化步骤904、用户反馈和修改步骤906以及模型训练步骤908。预测阶段404主要包括运行ML模型224以提供对事件的实时分析和检测或预测(即,故障预测)的步骤910。 初始设置步骤902主要包括对训练数据集的预处理,包括加标签,该训练数据集将用于训练用于事件检测或预测的ML模型224。该初始设置通过使用来自一个或多个历史数据集的基于示意图的斜率阈值912的默认集合作为起点而开始。在一些实施例中,初始斜率阈值存储在类似于图12所描绘的表中。这种表有时通俗地称为“诊断示意图”,因为表中的斜率是(或可以是)从用于以图表方式示出各种井操作参数(包括ESP参数)的图表中得出的。在一些实施例中,用户可以在训练开始之前在初始设置期间修改阈值并添加或移除事件。得到的阈值914然后被存储为对表或诊断示意图的更新。反映来自先前检测的异常事件916和停机918的专用阈值也可以在此时被添加到相关性数据库。 接下来,在可视化步骤904,为数据集的一部分或某个固定长度生成诊断示意图920,该数据集可以是整个数据集,显示检测到的事件和停机检测。在一些实施例中,阈值事件(即,对应于阈值的事件)、异常事件和停机可以用不同的颜色显示。 在用户反馈步骤906,用户可以对阈值加标签,并在用户认为合适时修改诊断示意图上的任何阈值,从而产生修改的诊断示意图922。例如,用户可以通过点击事件并修改事件(包括为事件提供新的标签)来添加或移除事件,例如移除误报。添加的任何异常事件916和停机918都可以在此时被加标签。然后,用户点击“应用”按钮(如果适用)来应用修改,这也将为存储数据的文件添加时间戳。否则,用户可以简单地重启监测和控制应用,以使用户提供的修改被应用。 一旦训练数据集被加标签,模型训练步骤908就开始。在该步骤中,被加标签的训练数据集用于关于如何以上面参考图4详细描述的方式执行事件检测和预测来训练ML模型224。一旦ML模型224被训练并被验证,模型运行步骤910可以通过将ML模型224部署到边缘网关138以进行实时的事件检测或预测来执行,如图10所示。 图10图示地描绘了使用滑动时间窗口的方法,其中井场处的边缘网关138可以执行该滑动时间窗口来检测或预测事件。该方法包括边缘网关138实时接收来自ESP 112或关于ESP 112的数据,这里以示意图1000的形式实时示出。在一些实施例中,数据可以被实时流式传输到边缘网关138,或者它可以在预先安排的基础上提供给边缘网关138。在示意图1000中示出了几条示例性的图表,每条图表线表示与ESP相关的操作参数,包括井口压力1002、泵排放压力1004、流体流速1006和电机泄漏电流1008。在接收时,边缘网关138将这些图表线,或者更确切地说图表线下面的数据输入到ML模型224。然后,ML模型224处理数据以从其中的数据模式中检测事件。如前所述,检测事件的一种方法是检查给定操作参数的斜率或操作参数的组合的斜率是否匹配诊断示意图中的任何斜率或斜率组合。图表线的斜率可以通过使用曲线拟合技术将线段拟合到图表线,然后确定线段的斜率来确定。框1010示出了已经拟合到图表线1008的一部分的线段1012的示例。线段1012的斜率可以用度数(例如-52.2度)来表示,或者用垂直距离与水平距离之比来表示。之后,ML模型224检查来自每个图表线或图表线的组合的斜率,以识别指示事件(例如,固体/沙子吸入、气体吸入、泵磨损、管道中的孔、电机/电缆退化、打开的节流器等)当前发生或在一定时间内发生的模式。 在一些实施例中,事件检测或预测针对数据逐步地执行,如前所述。这可以从开始于时间t的时间窗口1014、开始于时间t+1的第二时间窗口1016等形式看出。然后可以在每个窗口的基础上为每个图表线执行斜率确定(即,每个窗口一个斜率确定),或者可以为给定窗口内的给定图表线确定多个斜率,然后根据数据变化的频率进行数学上的组合(例如,平均)。时间窗口优选地具有统一的尺寸(由标签“窗口”指示),并且优选地以统一的步长递增(由标签“步幅”指示)。窗口尺寸和递增步长可以根据特定应用的需要进行选择,并且可以是秒、分钟、小时或天的数量级。在一些实施例中,也可以使用基于一定数量的数据点(例如,对于低分辨率数据)而不是时间间隔的窗口尺寸和递增步长。 图11是另一个示意图1100,其更详细地以图表方式描绘了由边缘设备138使用ML模型224执行的实时事件检测或预测方法。在该视图中有几个时间窗口,如1102、1104和1106所示。对于每个窗口内的每个图表线,由ML模型224确定的斜率由线段表示,线段之一在1108处指示。然后将每个窗口1102、1104和1106的不同斜率或斜率的组合与诊断示意图中的阈值进行比较(参见例如图12),以执行事件检测或预测。例如,在第一窗口1102中,每个图表线的斜率相对平坦,因此不满足或超过诊断示意图中的任何阈值。另一方面,第二窗口1104中的斜率的组合指示事件1(例如,打开的节流器)将在给定时间量内发生的高概率,而第三窗口1106中的斜率组合指示事件2(例如,堵塞的泵排放)将在给定时间量内发生的高概率。 图12是示出根据一些实施例的示例性示意图诊断阈值(或其一部分)的表1200,该示例性示意图诊断阈值可以被输入(参见图9中的914)并被基于示意图的ML模型224用来执行事件检测或预测。基于先前在该场中所做的工作和/或先前从真实世界井场数据中公布的结果,这些阈值斜率(例如列1202所示的阈值斜率)被认为强烈指示已知事件或与某些类型的已知事件(例如列1204中所列的已知事件)相关联。在一些情况下,表1200中的一个或多个斜率阈值可能与来自图8中的相关性数据库800的一个或多个斜率阈值一致或重叠,这是可能的,并且可能是预期的。这些斜率阈值1202可以根据用户的需要不时进行修改。 该示例中的表1200还包括时间窗口列1206,其示出了事件被优选地检测或预测的时间窗口,以及与事件检测或预测相关的操作参数。因此,例如,断轴事件优选在6小时窗口或12小时窗口内预测。该示例中的操作参数包括流速1208、井口压力1210、泵排放压力1212、泵吸入压力1214和电机速度1216。其他参数当然可以包括在本公开的范围内。在该示例中,如果底层数据的斜率在6小时或12小时的时间窗口内超过了操作参数1208-1216(例如-20、-20、-20、20和0)或其某些组合中列出的(最小或最大)斜率,则ML模型224将检测到断轴事件。在一些实施例中,不是使用斜率的专用数值(例如,度数、比率等),而可能使用斜率的范围,例如-10到-20,或者对斜率应用描述性类别,例如“稳定”、“略微减小”、“略微增大”、“步长增大变化”等。 图13是根据一些实施例的以图表方式示出检测事件的方法的图1300,在该方法中,基于相关性和/或基于示意图的ML模型224使用几个时间窗口,每个时间窗口具有不同的持续时间。不同的持续时间允许检测或预测具有不同优先级或紧急程度的事件。例如,ML模型224可以使用具有更短持续时间(例如,1分钟)的时间窗口1302来检测或预测高优先级事件或可能导致近期故障的事件。相反,ML模型224可以使用具有中等持续时间(例如,15分钟)的第二时间窗口1304来检测或预测中等优先级事件或可能导致长期故障的事件。ML模型224还可以使用具有更长持续时间(例如,一小时)的第三时间窗口1304来检测或预测所有其他事件。 图14A-图14H示出了根据本公开的实施例的可以与运行在边缘设备138上的监测和控制应用220一起使用的示例性用户界面1400。用户界面1400允许操作员基于实时流传送到边缘设备138的井操作参数来实时监测井场。用户界面1400还可以通过将历史数据集输入到边缘设备130并让ML算法224利用操作员反馈和对通过用户界面提供的数据的调整从数据中学习来用于模型训练目的。 首先参考图14A,在1402,由边缘设备138接收(或能够接收)的井操作参数(包括ESP参数)按类型列出。在一些实施例中,操作参数1402可以是彩色编码的,或者以其他方式视觉区分,以允许操作员单独识别每个参数。当然应该理解,除了1402所示的参数之外,也可以使用本领域技术人员已知的其他参数。然后,在1404,用户界面1400以图表方式再现或显示这些操作参数。在这个例子中显示的时间尺度是以天为单位的,但是不同的时间尺度(例如,分钟、小时、周等)肯定可能会用到。在1406处指示的一组选项允许用户选择要显示的专用类型的数据,例如生产数据、电气数据等,并隐藏未选择的数据。事件过滤器选项1408允许用户指定要显示的事件类型。在该示例中,用户可以从经由手动用户反馈、基于相关性的事件、基于示意图的事件和跳转检测到的事件中进行选择。选择基于相关性的事件使得用户界面1400显示使用相关性检测到的事件,如图14B所示。 在图14B中,用户界面1400显示了由边缘设备138的监测和控制应用220从数据中检测到的两个基于相关性的事件,如1410和1411所示。还示出了事件1410和1411的时间窗口1412和1413。在这个例子中,监测和控制应用220中负责(被训练用于)检测基于相关性的事件的ML模型224已经从时间窗口内的数据中检测到异常或不寻常的行为,但是还没有将该行为与相关性数据库中的已知事件积极匹配,因此事件1410和1411已经被指定为“未分配”。 图14C示出了操作员另外从事件过滤器1408中选择基于示意图的事件的示例。如可以看到的,用户界面1400现在显示两个基于示意图的事件1414和1415以及来自上图的两个基于相关性的事件1410和1411。当基于示意图和基于相关性的模型在相同或重叠的时间窗口内检测到事件时,这指示该事件很有可能是真实的(即,不是误报)。监测和控制应用中负责(被训练用于)检测基于示意图的事件的ML模型224已经从数据中肯定地识别出相同的异常或异常行为是穿孔堵塞(即,管道中的穿孔被堵塞,因此阻止流体自由地移动通过孔)。注意,点击任何事件或将光标悬停在任何事件上都会弹出一个弹出框1416,该框1416显示关于事件的附加细节,例如开始和结束日期/时间、数据源、用于检测事件的ML模型等。 图14D示出了操作员附加选择通过用户反馈识别的事件的例子。在1418处显示一个这样的事件以及该事件的时间窗口1420。在一些实施例中,每个时间窗口可以具有不同的颜色,或者在视觉上与其他时间窗口不同,以便于参考。创建事件按钮1422允许操作员手动创建事件。当操作员通过视觉检查数据(例如,基于以前的经验等)知道或强烈怀疑事件已经或将要发生但基于相关性的ML模型和基于示意图的ML模型都没有检测到该事件时,该选项特别有用。在这种情况下,操作员可以点击创建事件按钮1422来添加事件,如图14E所示。 在图14E中,操作员已经在图表线中的一条图表线上选择了数据点1424,其中该条图表线表示操作员认为指示事件的操作参数。选择事件类型选项1426允许操作员选择事件类型,例如电气事件。选择持续时间选项1428允许操作员选择事件的时间窗口,例如3小时、6小时、12小时等等。选择添加事件选项1430使得用户界面1400添加所选数据点1424作为用户反馈事件,如图14F所示。 在图14F中,用户界面1400现在将所选择的数据点1424显示为具有6小时时间窗口1432的电气事件1424,如操作员所选择的。用户界面1400还自动将该用户创建的事件1424添加到数据库中,以用于基于相关性的模型和基于示意图的模型,这些模型将用于未来的模式识别。除了添加事件之外,操作员还可以通过选择该事件并为该事件选择事件类型来修改任何事件,如图14G所示。 在图14G的例子中,操作员已经选择了由基于相关性的模型识别的“未分配”事件之一(1410和1411)。根据以前的经验,操作员知道或强烈怀疑该事件下的数据反映了地面关井事件(即,井已在地面关闭)。因此,操作员可以为该事件选择地面关井类型,以为该事件分配一个事件类型。此后,用户界面1400使该事件的事件类型改变为所选择的类型,并且还更新ML模型的数据库,以反映底层数据表示地面关井事件。这样,操作员可以帮助提高模型的识别精度。 用户界面1400还可以显示“跳转”类型的事件。从图14A回想,事件过滤器选项1408允许用户指定显示哪种或哪些类型的事件,包括经由手动用户反馈检测到的事件、基于相关性的事件、基于示意图的事件和跳转。跳转基本上是时间序列数据中的时间步长之间的变化,像表示各种井操作参数1402的数据。用于检测跳转的技术对于本领域技术人员来说是众所周知的,并且可以包括例如可从美国德克萨斯州休斯顿的Arundo Analytics分析公司获得的开源库。这种跳转可以由用户界面1400可视化为堆叠的柱状图。 再次参考图14G,在1436处示出了一组堆叠的柱状图,表示井操作参数1402的时间序列数据的跳转。在本例中,每个柱状图表示在给定日期的选择的时间序列数据集中看到的跳转的次数。如果用户选择一组不同的时间序列数据,则用户界面1400更新柱状图1436以反映所选数据中看到的跳转次数。通常来说,跳转次数越多,检测到的事件为真实事件的概率就越大。选择(例如,通过双击、点击等)柱状图之一使得用户界面1400放大由所选择的柱状图反映的数据部分,如图14H所示。 在图14H的示例中,用户界面1400放大了所选择的柱状图的数据(例如,像图14G所示的柱状图),如更小的时间刻度1438(即,小时而不是天)所示。从该视图中,用户可以看到所选择的跳转包含三个独立的跳转,如1436a-c所示,它们一个堆叠在另一个之上。用户界面1400还显示以图表方式表示数据中的跳转的跳转线1440。点击或者将光标悬停在线上的任何点上使得用户界面1400显示弹出框1442,该弹出框1442包含跳转背后的细节,例如日期/时间、数据类型等。 图15是边缘网关138的监测和控制应用220的可选用户界面1500,其可以显示给操作员。该用户界面1500再次向操作员呈现从ESP 112流出或围绕ESP 112流式传输的数据1502的图表可视化。用户界面1500还显示概率线1504,该概率线指示由监测和控制应用220中的ML模型检测到的任何事件或故障的可能性。通常,概率线1504越高,事件发生的概率越大。 在图15的示例中,ML模型224已经检测到流式传输的数据1502中的斜率或斜率的组合,其反映了大约两天内的沙吸入事件的发生。该事件由概率线1504中的峰值1506指示,伴随有指出该事件的警示1508。该事件也在用户界面1500中显示为阴影区域1510。ML模型224还检测到流式传输的数据1502中反映大约两天半内故障事件发生的斜率或斜率的组合。该事件由概率线1504中的峰值1512指示,伴随有指出该事件的警告1514。该事件也在用户界面1500中显示为阴影区域1516。然后,操作员可以选择这些事件或其警示和警报中的任一个来查看事件的细节(例如,底层数据、斜率等),如图16所示。 在图16中,操作员已经选择了1506处指示的事件,这使得用户界面1500调出该事件的故障概率图1600。该故障概率图1600向用户呈现了关于由ML模型224检测到的事件1506的事件发生时间的故障概率的图表可视化,如线1602所示。从该图表1600,用户可以看到故障概率随着时间推移的分布的细节。因此,在该示例中,在接下来的10至20小时内,故障概率最高,此后逐渐降低。 根据前述,可以理解的是,本文讨论的具有基于ML的分析的边缘网关可以以多种方式部署,包括作为独立的内部解决方案,其中边缘网关没有到云平台的连接。这种独立的解决方案与现有或新的SCADA系统无缝集成,其中,来自边缘网关的反馈可以以集中方式使用,以支持有助于提高运营效率的实时决策。在广域网连接有限或没有广域网连接的情况下,或者在运营商出于数据安全目的不愿通过公共互联网连接在云平台上公开数据的情况下,内部解决方案更为可取。 可替换地,具有基于ML的分析的边缘网关可以利用完全的云连接,其中多个这样的网关可以通过云平台来维护和管理。此选项允许从多个边缘网关收集的实时数据用于重新训练ML模型,从而在边缘处实现更精确的应用。只要模型精度达到预定义水平,这种重新训练过程就可以自动化,并且重新训练的模型可以基于预设的时间表部署到多个网关。 在前面的讨论中,参考了各种实施例。然而,本公开的范围不限于专用的描述实施例。相反,所描述的特征和元素的任何组合,无论是否与不同的实施例相关,都被预期来实现和实践预期的实施例。此外,尽管实施例可以实现优于其他可能的解决方案或现有技术的优点,但是特定的优点是否由给定的实施例实现并不限制本公开的范围。因此,前面的各方面、特征、实施例和优点仅仅是说明性的,并且不被认为是所附权利要求的要素或限制,除非在权利要求中明确陈述。 本文公开的各种实施例可以实现为系统、方法或计算机程序产品。因此,各方面可以采取完全硬件实施例、完全软件实施例(包括固件、常驻软件、微代码等)的形式或结合软件和硬件方面的实施例,这些方面通常都被称为“电路”、“模块”或“系统”此外,各方面可以采取包含在一个或多个计算机可读介质中的计算机程序产品的形式,该计算机可读介质具有包含在其上的计算机可读程序代码。 可以利用一个或多个计算机可读介质的任何组合。计算机可读介质可以是非暂时性计算机可读介质。非暂时性计算机可读介质可以是,例如但不限于,电子、磁、光、电磁、红外或半导体系统、装置或设备,或前述的任何合适的组合。非暂时性计算机可读介质的更具体的例子(非穷举列表)可以包括以下:具有一条或多条导线的电连接、便携式计算机磁盘、硬盘、随机存取存储器(RAM)、只读存储器(ROM)、可擦除可编程只读存储器(EPROM或闪存)、光纤、便携式光盘只读存储器(CD-ROM)、光存储设备、磁存储设备或上述的任何合适的组合。包含在计算机可读介质上的程序代码可以使用任何适当的介质来传输,包括但不限于无线、有线、光纤电缆、射频等、或前述的任何合适的组合。 用于执行本公开各方面的操作的计算机程序代码可以用一种或多种编程语言的任意组合来编写。此外,这种计算机程序代码可以使用单个计算机系统或通过彼此通信的多个计算机系统(例如,使用专用局域网(PAN)、局域网(LAN)、广域网(WAN)、因特网等)来执行。尽管参考流程图和/或框图描述了前面的各种特征,但是本领域普通技术人员将理解,流程图和/或框图的每个框以及流程图和/或框图中的框的组合可以由计算机逻辑(例如,计算机程序指令、硬件逻辑、两者的组合等)来实现。通常,计算机程序指令可以被提供给通用计算机、专用计算机或其他可编程数据处理设备的处理器。此外,使用处理器执行这样的计算机程序指令产生了能够执行流程图和/或框图一个或多个框中指定的功能或动作的机器。 附图中的流程图和框图说明了本公开的各种实施例的可能实现的架构、功能和/或操作。在这点上,流程图或框图中的每个框可以代表模块、代码段或代码部分,其包括用于实现指定逻辑功能的一个或多个可执行指令。还应该注意的是,在一些替代实现中,框中提到的功能可以不按图中提到的顺序发生。例如,连续示出的两个框实际上可以基本上同时执行,或者这些框有时可以以相反的顺序执行,这取决于所涉及的功能。还将注意到,框图和/或流程图图示的每个框以及框图和/或流程图图示中的框的组合可以由执行指定功能或动作的基于专用硬件的系统或者专用硬件和计算机指令的组合来实现。 应当理解,以上描述旨在说明而非限制。在阅读和理解以上描述后,许多其他实施例是显而易见的。尽管本公开描述了具体示例,但是应当认识到,本公开的系统和方法不限于这里描述的示例,而是可以在所附权利要求的范围内进行修改来实施。因此,说明书和附图被认为是说明性的,而不是限制性的。因此,本公开的范围应当参考所附权利要求以及这些权利要求所赋予的等同物的全部范围来确定。