一种云计算资源弹性伸缩的方法和系统
文献发布时间:2023-06-19 09:32:16
技术领域
本发明涉及云计算技术领域,具体涉及一种云计算资源弹性伸缩的方法和系统。
背景技术
随着云计算技术的飞速发展,各地越来越重视云计算服务产业,纷纷将云计算服务作为国家软件产业快速发展的新机遇。云计算服务已成为我国国家发展战略之一,它为中国经济引擎带来了新的动力,同时,也带来了新的挑战。云计算平台作为一种新兴的资源使用平台,已形成了比较成熟的服务模式,更多的用户可以共享使用资源。
在云计算中,在业务不同时期对于资源的需求不同,云计算资源弹性伸缩可以根据业务需求和策略调整计算资源。云计算资源的容量需求随业务的变化而变化,计算资源需求量较大时,计算资源紧张,容量需要快速增加,简称扩容;计算资源需求量较小时,大量资源空闲,为了高效利用资源,容量需要快速减少,简称缩容。常见的弹性伸缩产品有云服务器,云数据库,云存储,不同的云计算产品使用不同的性能监测指标,例如,云服务器的CPU利用率、内存利用率等。
目前很多云计算产品都实现了弹性伸缩功能,但是实现的弹性伸缩基本都是规则简单,例如基于定时策略、周期策略和阙值策略,所述规则的粒度较粗,无法适应业务的稳定、消耗的成本、资源的使用率的需求,没有考虑到通过历史数据对弹性伸缩进行预测。
发明内容
针对现有技术中的上述技术问题,本发明提供一种云计算资源弹性伸缩的方法和系统,通过对历史性能数据的分析,建立预测模型,通过预测模型对当前性能数据进行分析,从而控制云计算资源的弹性伸缩,以维护业务的稳定性和提高资源使用率。
本发明公开了一种云计算资源弹性伸缩的方法,所述方法包括:
获取云计算的历史性能数据;
对所述历史性能数据进行数据清洗,获得第一样本集;
基于时间序列预测法对第一样本集进行训练,获得时间序列模型;
为第一样本集定义预测区间,并建立第二标签,获得第三样本集,所述第二标签包括扩容标签和缩容标签;
基于神经网络训练第三样本集,获得神经网络模型;
获取当前性能数据;
判断当前性能数据是否处于预测区间;
若是,基于时间序列模型分析当前性能数据,获得第一分析结果;
基于神经网络模型分析当前性能数据,获得第二分析结果;
根据第一分析结果对第二分析结果进行测试和评估,获得第三分析结果;
基于第三分析结果进行云计算资源扩容或缩容。
优选的,所述第一样本集的区间包括极低区间、极高区间和预测区间;
判断当前性能数据处于极低区间时,进行云计算资源缩容;
判断当前性能数据处于极高区间时,进行云计算资源扩容。
优选的,获得时间序列模型的方法包括:
根据第一样本集编制时间序列,根据时序序列绘成统计图;
基于时间序列预测法对时间序列或统计图进行训练,获得时间序列模型。
优选的,所述时间序列包括长期趋势、季节变动和不规则变动,所述时间序列模型包括以下模型之一或它们的组合:
根据长期趋势构建的长期时间序列模型、根据季节变动构建的季节变动时间序列模型和根据不规则变动构建的变动时间序列模型;
基于长期时间序列模型、季节变动时间序列模型和变动时间序列模型获取第一分析结果。
优选的,本发明还包括神经网络模型迭代的方法:
根据当前性能数据获取当前数据样本集;
将第三样本集和当前数据样本集输入所述神经网络模型,获取输出结果;
基于所述输出结果构造所述神经网络模型的损失函数;
利用所述损失函数对所述神经网络进行反向传播,以更新和迭代所述神经网络模型的参数。
优选的,根据第一分析结果对第二分析结果进行测试和评估的方法包括:
基于时间序列模型对当前性能数据进行预测,获取预测结果作为第一分析结果;
定义忙闲区间;
根据预测结果和忙闲区间,获取当前的忙闲状态;
根据忙闲状态,对第二分析结果进行测试和评估,获得第三分析结果。
优选的,进行云计算资源扩容或缩容的方法包括:
在OpenStack的Nova模块中添加hotplug插件;
对云计算主机的资源进行扩容或缩容,所述资源包括CPU或内存;
通过Libvirt模块的接口,修改Nova模块中XML文件的性能属性;
重启Nova模块。
本发明还提供一种云计算资源弹性伸缩的系统,用于实现上述的方法,所述系统包括:采集模块、预处理模块、时间序列分析模块、神经网络分析模块、预测模块、评估模块和控制模块;
所述采集模块用于获取云计算的历史性能数据;
所述预处理模块用于对所述历史性能数据进行数据清洗,获得第一样本集;
所述时间序列分析模块用于基于时间序列预测法对第一样本集进行训练,获得时间序列模型;
所述神经网络分析模块用于为第一样本集定义预测区间,并建立第二标签,获得第三样本集,所述第二标签包括扩容标签和缩容标签;
所述预测模块用于获取当前性能数据,判断当前性能数据处于预测区间时,基于时间序列模型分析当前性能数据,获得第一分析结果;
所述评估模块用于基于神经网络模型分析当前性能数据,获得第二分析结果,并根据第一分析结果对第二分析结果进行测试和评估,获得第三分析结果;
所述控制模块用于基于第三分析结果控制云计算资源进行扩容或缩容。
优选的,所述系统还还包括预选模块,
所述预选模块用于判断当前性能数据处于极低区间、极高区间或预测区间,
处于极低区间时,通过控制模块进行云计算资源缩容;
处于极高区间时,通过控制模块进行云计算资源扩容;
处于预测区间时,将当前性能数据转发时间序列分析模块和网络分析模块。
与现有技术相比,本发明的有益效果为:
通过定义预测区间,减少训练的样本数,便于提高获取神经网络模型的效率,同时防止神经网络模型过度拟合;通过时间序列模型分析的第一分析结果对神经网络模型的第二分析结果进行测试和评估,以提高第三分析结果的准确性和稳定性。
附图说明
图1是本发明的云计算资源弹性伸缩的方法流程图;
图2是获取时间序列模型的方法流程图;
图3是时间序列趋势图;
图4是神经网络模型迭代的方法流程图;
图5是根据第一分析结果对第二分析结果进行测试和评估的方法流程图;
图6是云计算进行扩容或缩容的方法流程图;
图7是本发明的云计算资源弹性伸缩的系统逻辑框图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明的一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。
下面结合附图对本发明做进一步的详细描述:
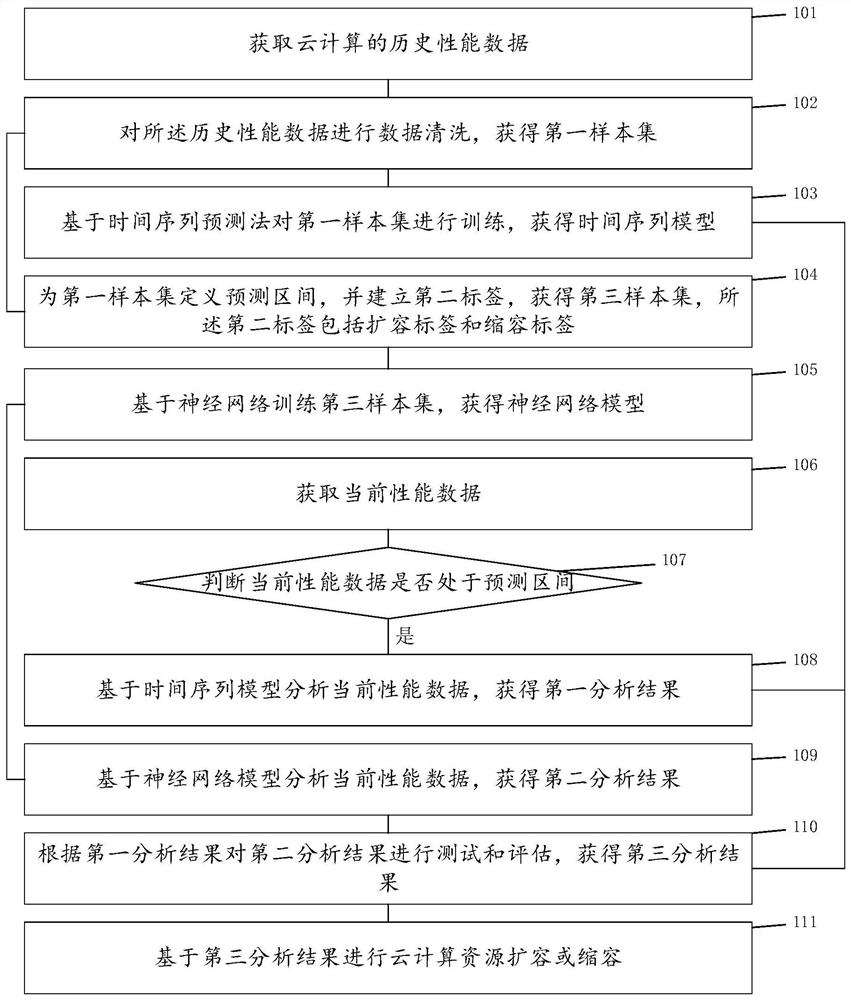
一种云计算资源弹性伸缩的方法,如图1所示,所述方法包括:
步骤101:获取云计算的历史性能数据。历史性能数据反映了业务变化的趋势,需要指出的是,不同的业务其历史性能数据的趋势不同。历史性能数据可以CPU总量、CPU使用量、CPU分配量、内存总量、内存使用量、内存分配量、存储总量、存储使用量、网络上行量和络下行量。
步骤102:对所述历史性能数据进行数据清洗,获得第一样本集。通过数据清洗,统一历史性能数据的粒度和格式,同时可以通过指标筛选历史性能数据,如按天计算CPU的平均使用率或按周计算CPU的平均使用率,指标可以包括CPU指标、内存指标、存储指标、网络指标和访问次数指标。
步骤103:基于时间序列预测法对第一样本集进行训练,获得时间序列模型。常见的时间序列预测法包括整合移动平均自回归法(ARIMA,Autoregressive IntegratedMoving Average)和指数平滑法(exponential smoothing或Holt-Winters),相应的,时间序列模型包括ARIMA模型和Holt-Winters模型。
步骤104:为第一样本集定义预测区间,并建立第二标签,获得第三样本集,所述第二标签包括扩容标签和缩容标签。第一样本集的区间可以包括:包括极低区间、极高区间和预测区间。需要指出的是,当前性能数据可以为当前一段时间性能数据的平均值,如将前1分钟的CPU平均使用率作为当前性能数据。
步骤105:基于神经网络训练第三样本集,获得神经网络模型。
步骤106:获取当前性能数据。
步骤107:判断当前性能数据是否处于预测区间。
若是,执行步骤108:基于时间序列模型分析当前性能数据,获得第一分析结果。在时间序列模型中输入当前性能数据,获利第一分析结果。不处于预测区间时,如处于极高区间或极低区间,适用简单的控制规则:当前性能数据处于极低区间时,进行云计算资源缩容;当前性能数据处于极高区间时,进行云计算资源扩容。如0-20%为极低区间,20-70%为预测区间,而70-100%为极高区间。
步骤109:基于神经网络模型分析当前性能数据,获得第二分析结果。在神经网络模型中输入当前性能数据,获得第二分析结果。
步骤110:根据第一分析结果对第二分析结果进行测试和评估,获得第三分析结果。结合第一分析结果对第二分析结果进行测试和评估,以提高第三分析结果的准备性和稳定性。
步骤111:基于第三分析结果进行云计算资源扩容或缩容。
通过定义预测区间,减少训练的样本数,便于提高获取神经网络模型的效率,同时防止神经网络模型过度拟合;通过时间序列模型分析的第一分析结果对神经网络模型的第二分析结果进行测试和评估,以提高第三分析结果的准备性和稳定性。
实施例1
如图2所示,本实施例提供了获得时间序列模型的方法:
步骤201:根据第一样本集编制时间序列,根据时间序列绘成统计图。可以选择样本集的一种指标编制时间序列,如CPU使用率、磁盘空间变化率或内在使用率;也可以为各指标分配权重,综合计算云计算的性能。
步骤202:基于时间序列预测法对时间序列或统计图进行训练,获得时间序列模型。
其中,对时间序列或统计图进行训练的方法包括:差分自回归移动平均法(ARIMA,Autoregressive Integrated Moving Average)和指数平滑法(exponential smoothing或Holt-Winters)。
其中,ARIMA(p,d,q)模型为差分自回归移动平均模型,AR是自回归,p为自回归项;MA为移动平均,q为移动平均项数,d为时间序列成为平稳时所做的差分次数。ARIMA模型,是指将非平稳时间序列转化为平稳时间序列,然后将因变量仅对它的滞后值以及随机误差项的现值和滞后值进行回归所建立的模型。ARIMA模型根据原序列是否平稳以及回归中所含部分的不同,包括移动平均过程(MA)、自回归过程(AR)、自回归移动平均过程(ARMA)以及ARIMA过程。
ARIMA模型预测的方法包括:
步骤301:根据时间序列的散点图、自相关函数和偏自相关函数图以ADF单位根检验其方差、趋势及其季节性变化规律,对序列的平稳性进行识别。步骤302:对非平稳序列进行平稳化处理。如果数据序列是非平稳的,并存在一定的增长或下降趋势,则需要对数据进行差分处理,如果数据存在异方差,则需对数据进行技术处理,直到处理后的数据的自相关函数值和偏相关函数值无显著地异于零。
步骤303:根据时间序列预测法的识别规则,建立ARIMA模型。若平稳序列的偏相关函数是截尾的,而自相关函数是拖尾的,可断定序列适合AR模型;若平稳序列的偏相关函数是拖尾的,而自相关函数是截尾的,则可断定序列适合MA模型;若平稳序列的偏相关函数和自相关函数均是拖尾的,则序列适合ARMA模型。其中,截尾是指时间序列的自相关函数(ACF)或偏自相关函数(PACF)在某阶后均为0的性质(比如AR的PACF);拖尾是ACF或PACF并不在某阶后均为0的性质(比如AR的ACF)。
步骤304:进行参数估计,检验是否具有统计意义。
步骤305:进行假设检验,诊断残差序列是否为白噪声。
步骤306:利用已通过检验的模型进行预测分析。
Holt-Winters预测法:
时间序列(time series)一系列有序的数据,一般具有趋势性与季节性。通常是等时间间隔的采样数据,如果不是等间隔,则一般会标注每个数据点的时间刻度。
分解时间序列需要将时间序列拆分成构成元件,时间序列包含长期趋势T和不规则变动I,如果是季节性时间序列,则还有一个季节变动S。可以分别根据长期趋势构建的长期时间序列模型、根据季节变动构建的季节变动时间序列模型和根据不规则变动构建的变动时间序列模型,分别对T、S、I进行预测。可以使用加法模式计算预测值Y:T+S+I=Y;也可以使用乘法模式计算预测值Y:T×S×I=Y。
具体的,可以通过R语言的函数包进行Holt-Winters预测。
也可以通过Excel的方式,根据历史性能参数构建时间序列和时间序列模型,以CPU使用率为例,如图3所示,横坐标为时间,单位为天;纵坐标为CPU使用率;时间序列模型为:
y=3E-05x
实施例2
本发明中可以采用的神经网络算法包括:BP(back propagation)神经网络和长短期记忆网络(LSTM,Long Short-Term Memory)。其中BP神经网络为按照误差逆向传播算法训练的多层前馈神经网络;LSTM是一种时间循环神经网络,是为了解决一般的RNN(循环神经网络)存在的长期依赖问题而专门设计出来的。
神经网络训练中,采用的参数包括:CPU使用率、内存用率和存储使用率,但不限于此,如也可以包括网络使用量。
第一样本集定义的预测区间为:CPU使用率:20-60%、内存使用量30-70%,但不限于此。第二标签可以包括以下两种或多种:扩容标签、缩容标签、维持标签、忙时标签、闲时标签、资源峰值、资源谷值和资源风险点。其中,扩容标签可以包括CPU扩容标签、内存扩容标签、磁盘扩容标签或网络扩容标签。
其中,通过第三样本集训练得到神经网络模型属于现有技术,不再赘述。
如图4所示,神经网络模型迭代的方法包括:
步骤501:获取当前数据样本集。当前数据样本集包括由当前性能数据清洗得到的当前样本。
步骤502:将第三样本集和当前数据样本集输入所述神经网络模型,获取输出结果。
步骤503:基于所述输出结果构造所述神经网络模型的损失函数。可以根据输出结果和标签的对比获取损失函数。
步骤504:利用所述损失函数对所述神经网络进行反向传播,以更新和迭代所述神经网络模型的参数。
实施例3
如图5所示,根据第一分析结果对第二分析结果进行测试和评估的方法包括:
步骤601:基于时间序列模型对当前性能数据进行预测,获取预测结果作为第一分析结果。如预测的CPU使用率为39%或63%。
步骤602:定义忙闲区间。如忙区间为:CPU使用率>=40%,闲区间为CPU使用率<40%。还可以定义谷值、峰值和危险值。
步骤603:根据预测结果和忙闲区间,获取当前的忙闲状态。如39%处于闲区间,而63%处于忙区间。
步骤604:根据忙闲状态,对第二分析结果进行测试和评估,获得第三分析结果。如,当前处于忙状态而第二分析结果为扩容,第三分析结果为忙状态和扩容,可以执行扩容;而当前处于闲状态而第二分析结果为扩容,第三分析结果为闲状态和扩容,可以将第三分析结果发送管理员进行确认。
实施例4
如图6所示,云计算进行扩容或缩容的方法包括:
步骤701:在OpenStack的Nova模块中添加hotplug插件。OpenStack是一个开源的云计算管理平台项目,是一系列软件开源项目的组合,Nova(OpenStack Compute Service)是OpenStack最核心的服务,负责维护和管理云环境的计算资源,同时管理虚拟机生命周期。hotplug插件允许用户在不关闭系统,不切断电源的情况下取出和更换设备。
步骤702:对云计算主机的资源进行扩容或缩容,所述资源包括CPU或内存。
步骤703:通过Libvirt模块的接口,修改Nova模块中XML文件的资源属性。所述属性可以包括:currentVCPU、totalVCPU和maxMemory。
步骤704:重启Nova,实现热扩容或缩容。
如,CPU热扩容的方法包括:
步骤801:如将CPU插入空闲的插口(socket)中。
步骤802:通过Hot Plug的接口初始化Hot Add的动作。
步骤803:Firmware/BIOS对插入的CPU进行初始化操作,如配置QPI总线的路由表、更新地址解码等。
步骤804:通过ACPI中断接口(SCI中断)向系统产生一个Hot Add的事件。
步骤805:系统通过ACPI的_OSI方法检测当前系统支持“Module Device”时,执行Hot Add操作。
步骤806:系统通过ACPI的_MAT方法得到MADT描述表,用来初始化Local APIC/SAPIC以及local NMI中断。
步骤807:系统对新增的CPU进行相关的电源管理配置。
步骤808:调用ACPI的_OST方法通知Firmware/BIOS本次Hot Add是否成功。CPU热缩容可以采用似的方法,不再赘述。
如,内存热扩容的方法:
步骤901:安装QEMU/KVM插件。QEMU-KVM是一个完整的模拟器,构建基于KVM上面的,提供了完整的网络和I/O支持。
步骤902:内存插入插槽中。
步骤903:QEMU所模拟的客户机发现内存。
步骤903:通过object_add来定义后端设备:memory-backend-ram。
步骤904:通过device_add添加前端的内存。此时可以通过info memory-device可以看到新添加的内存及其大小,是可以热插拔的(hotpluggable)。内存热缩容可以采用似的方法,不再赘述。
本发明还提供一种云计算资源弹性伸缩的系统,用于实现上述云计算资源弹性伸缩方法,如图7所示,所述系统包括:采集模块1、预处理模块2、时间序列分析模块3、神经网络分析模块4、预测模块5、评估模块6和控制模块7;
采集模块1用于获取云计算的历史性能数据;
预处理模块2用于对所述历史性能数据进行数据清洗,获得第一样本集;
时间序列分析模块3用于基于时间序列预测法对第一样本集进行训练,获得时间序列模型;
神经网络分析模块4用于为第一样本集定义预测区间,并建立第二标签,获得第三样本集,所述第二标签包括扩容标签和缩容标签;
预测模块5用于获取当前性能数据,判断当前性能数据处于预测区间时,基于时间序列模型分析当前性能数据,获得第一分析结果;
评估模块6用于基于神经网络模型分析当前性能数据,获得第二分析结果,并根据第一分析结果对第二分析结果进行测试和评估,获得第三分析结果;
控制模块7用于基于第三分析结果进行云计算资源扩容或缩容。
所述系统还可以包括预选模块8,
预选模块8用于判断当前性能数据处于极低区间、极高区间或预测区间:
处于极低区间时,通过控制模块进行云计算资源缩容;
处于极高区间时,通过控制模块进行云计算资源扩容;
处于预测区间时,将当前性能数据转发时间序列分析模块和网络分析模块。
以上仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。