一种基于多频段融合与时空Transformer的脑电信号分析方法
文献发布时间:2023-06-19 19:30:30
技术领域
本发明属于脑电分析技术领域,具体涉及一种脑电信号分析方法。
背景技术
脑电图(Electroencephalography,EEG)是使用最广泛且价格低廉的神经成像技术之一,它需要先进而强大的学习算法来建模和分析。根据EEG信号的多尺度性质,将多频段概念引入对EEG信号建模的Transformer架构的设计中至关重要。现有的工作基于传统的信号处理方法和深度学习方法对EEG信号的多频段融合已经进行了广泛的研究,例如,通过使用不同频率范围的滤波器处理信号并在特征空间融合滤波后的信号频段。然而,神经网络模型的训练过程通常缓慢而复杂,再加上模型引入的噪声限制,难以有效融合脑电信号的所有频段。并且,以往的深度学习模型大多属于后期融合策略,在融合之前,那些有意义的、有区分性的特征仍然用单频段来表示,这导致了模型的冗余以及整体信息的丢失。
发明内容
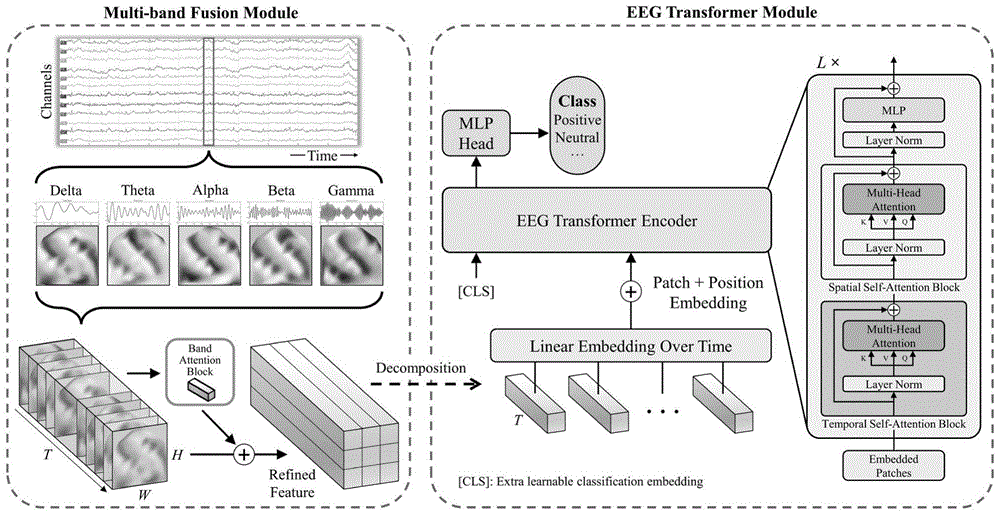
为了克服现有技术的不足,本发明提出了一种基于多频段融合与时空Transformer的脑电信号分析方法(Multi-band EEG Transformer,MEET),首先将预处理后的脑电信号转化为对应时间长度的多频段图像,并尽可能保留采样通道之间的三维空间信息;然后采用频段注意力模块融合特征,用于计算堆叠的多频段图像的注意力图并推断出经过融合的特征图;接着使用时间/空间自注意力模块提取时空特征,用于表征和区分多帧多区域的动态大脑状态;最终通过多层感知机学习特征的类别信息。训练得到的MEET模型,可以表示和分析人脑脑电信号的多尺度时间序列。本发明能有效提高脑电信号分类的准确度,一定程度上解决了脑电信号的分类任务。
本发明解决其技术问题所采用的技术方案包括如下步骤:
步骤1:将脑电信号预处理成多频段图像;
将时间长度为T的脑电信号下采样到200Hz,并分解为五个频段:Delta(1-4Hz)、Theta(4-8Hz)、Alpha(8-14Hz)、Beta(14-31Hz)和Gamma(31-50Hz);采用微分熵作为特征提取器,对五个频段中的每一个频段上的每个EEG通道独立执行微分熵特征提取,随后使用AEP法将三维电极坐标映射到二维平面,因此一维微分熵特征向量被重组为二维散点图。然后使用C-T法对散点图进行插值,以生成分辨率为32×32的特征图;五个频段上的特征图是堆叠在一起的;
输入的EEG数据表示为四维特征张量x
步骤2:多频段特征融合;
三维多频段特征张量
然后将F
M
=σ(W
其中σ表示激活函数,x
步骤3:时序/空间特征提取;
采用基于多频段融合与时空Transformer模型MEET学习复杂EEG信号的时序依赖性和空间关系,其中时间自注意力模块学习不同帧之间的时序依赖,空间自注意力模块学习同一帧中不同位置之间的空间关系;计算公式如下:
采用基于多频段融合与时空Transformer模型MEET学习复杂EEG信号的时序依赖性和空间关系,其中时间自注意力模块学习不同帧之间的时序依赖,空间自注意力模块学习同一帧中不同位置之间的空间关系;时间自注意力模块中,在连续t帧中相同空间位置处的张量块被分组,每组中的张量块被矢量化,作为query/key/value来计算多头自注意力;两种自注意力权重α在query(p,t)上的计算公式如下:
式中,l和a分别表示编码器的层数和多头自注意力模块的序列号,p和t分别表示查询块的位置序号和时间序号,SM为softmax激活函数,q/k表示query/key,相应的,每个注意头的维度为D
步骤4:将数据集通过步骤1预处理后输入步骤2和步骤3,得到最终的模型输出,即为最终的分类结果。
优选地,所述基于多频段融合与时空Transformer模型MEET的深度为3,隐藏层维度为768,多层感知机维度为3072。
优选地,所述基于多频段融合与时空Transformer模型MEET的深度为6,隐藏层维度为768,多层感知机维度为3072。
优选地,所述基于多频段融合与时空Transformer模型MEET的深度为12,隐藏层维度为1024,多层感知机维度为4096。
本发明的有益效果如下:
1、本发明对于脑电信号分析具有重要意义,使用Transformer作为骨干网络可以有效地对脑电信号进行建模以区分大脑状态,更重要的是,MEET的多频段融合策略可以显著提高分类性能,同时与其他先进方法相比,消耗的训练资源显著减少。
2、脑电信号分类技术在脑电图分析、BCI和神经科学技术领域具有重要的作用。对于BCI的应用,脑状态的实时分析是关键,MEET具有预训练和微调策略,在有限的时间消耗和资源成本下实现在线脑状态推理的潜力很大。
附图说明
图1为本发明的MEET模型网络结构示意图。
图2为本发明提出的频段注意力模块和时间/空间自注意力模块示意图。
具体实施方式
下面结合附图和实施例对本发明进一步说明。
本发明提供了一种基于多频段融合与时空Transformer的脑电信号分析方法,提出用基于深度自注意力变换网络的模型,融合频段注意力模块、时间/空间自注意力模块,去学习潜在的特征信息。
如图1所示,一种基于多频段融合与时空Transformer的脑电信号分析方法,包括以下步骤:
步骤1:将脑电信号预处理成相应时间长度的多频段图像;
如图1左侧所示,在为输入脑电信号的每一段提取多频段特征后,多频段融合模块使用频段注意块推导出多频段的线性组合带可学习权重的特征。将时间长度为T的脑电信号下采样到200Hz,并分解为五个频段:Delta(1-4Hz)、Theta(4-8Hz)、Alpha(8-14Hz)、Beta(14-31Hz)和Gamma(31-50Hz)。采用脑电图分析中广泛使用的微分熵作为特征提取器,对五个频段中的每一个频段上的每个EEG通道独立执行微分熵特征提取后,使用AEP(AzimuthalEquidistant Projection)法将三维电极坐标映射到二维平面。因此,一维微分熵特征向量被重组为二维散点图。然后我们使用C-T方案对散点图进行插值,以生成分辨率为32×32的特征图。五个频段上的特征图是堆叠在一起的。经过以上步骤,输入的EEG数据表示为四维特征张量
步骤2:多频段特征融合;
三维多频段特征张量
M
=σ(W
其中σ表示激活函数,x
步骤3:时序/空间特征提取;
采用基于多频段融合与时空Transformer模型MEET学习复杂EEG信号的时序依赖性和空间关系,其中时间自注意力模块学习不同帧之间的时序依赖,空间自注意力模块学习同一帧中不同位置之间的空间关系;时间自注意力模块中,在连续t帧中相同空间位置处的张量块被分组,每组中的张量块被矢量化,作为query/key/value来计算多头自注意力,空间自注意力模块和ViT模型(Vision Transformer)类似。两种自注意力权重α在query(p,t)上的计算公式如下:
式中,l和a分别表示编码器的层数和多头自注意力模块的序列号,p和t分别表示查询块(query patch)的位置序号和时间序号,SM为softmax激活函数,q/k表示query/key,相应的,每个注意头的维度为D
步骤4:将数据集通过步骤1预处理后输入步骤2和步骤3,得到最终的模型输出,即为最终的分类结果。
为了应对不同规模的任务,设计了三种MEET模型变体。如下表1所示,“深度”表示EEG Transformer编码器(包括时间自注意力模块和空间自注意力模块)的层数。“时间”表示在一个任务上训练模型100次所需的时间。在接下来的内容中,MEET-Small因其训练速度快且准确率没有明显衰减而被用于大量基础评估(包括个体内和跨个体实验);MEET-Base用于对比实验,确认模型的结构和参数;MEET-Large用于探索模型学习能力的上限。
表1
具体实施例:
1、将脑电信号预处理成相应时间长度的多频段图像;
如图1左侧所示,在为输入脑电信号的每一段提取多频段特征后,多频段融合模块使用频段注意块推导出多频段的线性组合带可学习权重的特征。将时间长度为T的脑电信号下采样到200Hz,并分解为五个频段:Delta(1-4Hz)、Theta(4-8Hz)、Alpha(8-14Hz)、Beta(14-31Hz)和Gamma(31-50Hz)。采用脑电图分析中广泛使用的微分熵作为特征提取器,对五个频段中的每一个频段上的每个EEG通道独立执行微分熵特征提取后,使用AEP(AzimuthalEquidistant Projection)法将三维电极坐标映射到二维平面。因此,一维微分熵特征向量被重组为二维散点图。然后我们使用C-T方案对散点图进行插值,以生成分辨率为32×32的特征图。五个频段上的特征图是堆叠在一起的。经过以上步骤,输入的EEG数据表示为四维特征张量
2、多频段特征融合
三维多频段特征张量
M
=σ(W
其中σ表示激活函数,x
3、时间/空间特征提取
采用基于多频段融合与时空Transformer模型MEET学习复杂EEG信号的时序依赖性和空间关系,其中时间自注意力模块学习不同帧之间的时序依赖,空间自注意力模块学习同一帧中不同位置之间的空间关系;时间自注意力模块中,在连续t帧中相同空间位置处的张量块被分组,每组中的张量块被矢量化,作为query/key/value来计算多头自注意力,空间自注意力模块和ViT模型(Vision Transformer)类似。两种自注意力权重α在query(p,t)上的计算公式如下:
式中,l和a分别表示编码器的层数和多头自注意力模块的序列号,p和t分别表示查询块(query patch)的位置序号和时间序号,SM为softmax激活函数,q/k表示query/key,相应的,每个注意头的维度为D
4、测试阶段
将数据集通过步骤1预处理后输入步骤2和步骤3得到最终的模型输出,即为最终的分类结果。使用两个公开的EEG数据集来评估MEET的性能:SEED(三分类任务)和SEED-IV(四分类任务)。对于SEED,MEET-Small在每个个体上都取得了出色的分类结果(平均准确率为99.30%)。并且,对于难度更大的SEED-IV数据集依然获得了很高的准确率(平均准确率为96.02%)。统计了各种分类方法的测试性能,与目前最先进的模型4D-aNN相比。在SEED实验中,MEET-Small将平均准确率提高了3.05%;SEED-IV的提升幅度更大,平均准确率提升了9.25%。同时,所提出的MEET模型的标准差也是最小的,这有力地证明了MEET的稳定性和鲁棒性。
本发明提出了一种基于多频段融合与时空Transformer的脑电信号分析方法,证明使用Transformer作为骨干网络可以有效地对脑电信号进行建模以区分大脑状态,更重要的是,MEET的多频段融合策略可以显著提高分类性能。与大多数使用RNN或基于RNN框架结合CNN/GNN的算法相比,MEET-Small取得了最好的结果,同时训练所需的计算资源要少得多。这在很大程度上要归功于提出的时间/空间自注意力模块,它通过模拟双向网络来学习EEG信号的时序信息。并行计算的时间复杂度远低于RNN所用的串行计算方法。与此同时,MEET证明5频段融合是更好的融合策略,基于其独特的自注意机制可以解释相关的有意义的大脑注意力区域。此外,为了进一步提高大脑状态分类能力,MEET设计了预训练策略并进行评估,以检查预训练的有效性,结果表明,与从头开始训练相比,得到了0.87%和0.64%的提升,证明了经过预训练的MEET可以显著提高模型的预测能力。在使用EEG的BCI中,MEET可以提供有效的表征学习架构,具有更高的大脑状态区分能力,同时花费更少的训练资源。对于脑控机器人的应用,脑状态的实时分析是关键,MEET具有预训练和微调策略,在有限的时间消耗和资源成本下实现在线脑状态推理的潜力很大。对于使用EEG进行脑部疾病诊断的应用,例如注意力缺陷多动障碍(ADHD),MEET可以模拟脑电波并帮助分析注意力缺陷的机制。此外,MEET还可以对异常和正常大脑注意区域之间的相互作用进行建模和研究,这将为大脑的康复提供很大的支持。