一种为命名实体识别模型自动生成训练数据的方法和装置
文献发布时间:2024-01-17 01:14:25
技术领域
本发明涉及一种文本信息抽取和结构化技术,特别是涉及一种命名实体识别(Named Entity Recognition,NER)技术。
背景技术
非结构化文本是指不方便用数据库二维逻辑表来表现的文本数据,例如各种图书、文章等。结构化文本是指方便用数据库二维逻辑表来表现的文本数据,例如特定形式的表格等。半结构化文本则是介于两者之间。从非结构化文本、半结构化文本中提取出特定的信息例如时间、地点、人物等,称作文本信息抽取和结构化。
自然语言处理(Natural Language Processing,NLP)是一种让计算机处理和分析大量自然语言数据的技术。命名实体识别技术是自然语言处理技术中的一种。命名实体识别是指识别文本中可以用专有名词标识的事物(称为命名实体),包括人名、地名、机构名、专有名词、时间、数量、货币、比例数值等。命名实体识别技术能用于从非结构化文本中提取目标信息(称为命名实体)从而得到结构化文本。
目前,命名实体识别的实现通常采用机器学习方式。通过将训练数据输入到深度学习模型中,经过一定轮次的训练,训练完成后就得到一个能够识别非结构化文本中的命名实体的模型。深度学习模型的训练过程需要有足够量的训练数据才可以开展,而训练数据需要耗费大量的人力和时间进行人工标注。
发明内容
本发明所要解决的技术问题是提供一种为命名实体识别模型自动生成训练数据的方法,使得训练数据不再需要人工标注。
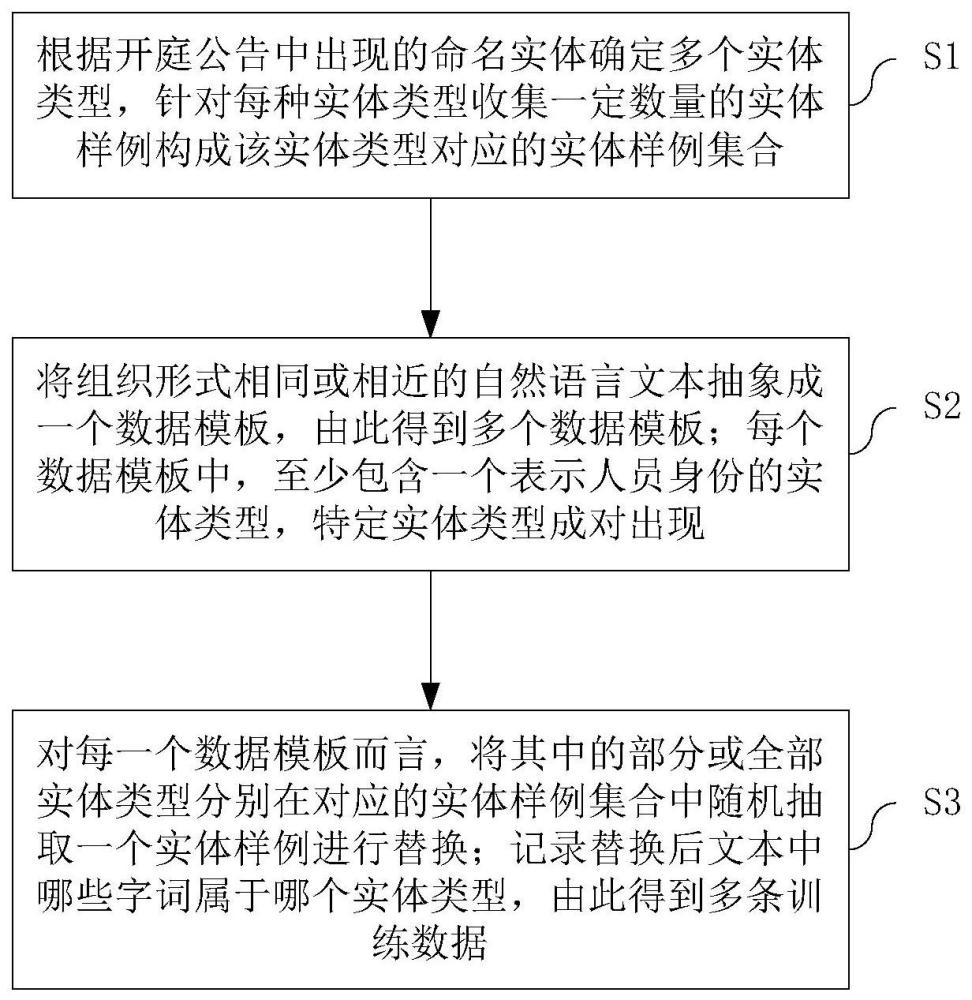
为解决上述技术问题,本发明提出了一种为命名实体识别模型自动生成训练数据的方法,包括如下步骤。步骤S1:根据开庭公告中出现的命名实体确定多个实体类型,针对每种实体类型收集一定数量的实体样例构成该实体类型对应的实体样例集合。步骤S2:将组织形式相同或相近的自然语言文本抽象成一个数据模板,由此得到多个数据模板;每个数据模板由一个或多个实体类型、以及无法归入任何实体类型的字词和标点符号构成;每个数据模板中,至少包含一个表示人员身份的实体类型,表示人员身份的部分实体类型成对出现。步骤S3:对每一个数据模板而言,将其中的部分或全部实体类型分别在对应的实体样例集合中随机抽取一个实体样例进行替换;记录替换后文本中哪些字词属于哪个实体类型,以及这些字词的位置,由此得到多条训练数据。
进一步地,所述步骤S2中,每个数据模板是从自然语言文本中将所有需要识别的实体抽象为对应的实体类型、从而使得后续可以使用相同实体类型的实体样例填充进去的一段自然语言文本框架。
可选地,所述步骤S2中,表示人员身份的部分实体类型重复出现,重复出现的次数在1到10之间。
优选地,所述步骤S2中,所述表示人员身份的实体类型包括原告和被告、上诉人和被上诉人、申请人和被申请人。
进一步地,所述步骤S2中,至少部分数据模板中包含一个或多个可删除的实体类型。所述步骤S3中,对于数据模板中的可删除的实体类型,在该实体类型对应的实体样例集合中随机选择一个实体样例替换该实体类型、或删除该实体类型。
进一步地,所述步骤S2中,将无法归入任何实体类型的字词和标点符号按照在文本中的功能分别构成一个或多个备选集合。所述步骤S3中,还将其中的部分或全部的无法归入任何实体类型的字词和标点符号在对应的备选集合中随机抽取一个进行替换。
进一步地,所述步骤S3中,将数据模板中的表示人员身份的实体类型用实体样例进行替换时,将所述特定实体类型的名称与一个实体样例组合后进行替换。
进一步地,所述步骤S3中,按照数据模板生成数据时,改变该数据模板中的实体类型之间的顺序、位置,得到多个不同的训练数据。
进一步地,所述步骤S3中,按照该数据模板生成数据时,通过在文本的开头、结尾以及句中的部分位置增加冗余文本,得到多个不同的训练数据。
本发明还提出了一种为命名实体识别模型自动生成训练数据的装置,包括收集单元、抽象单元和生成单元。所述收集单元用于根据开庭公告中出现的命名实体确定多个实体类型,针对每种实体类型收集一定数量的实体样例构成该实体类型对应的实体样例集合。所述抽象单元用于将组织形式相同或相近的自然语言文本抽象成一个数据模板,由此得到多个数据模板;每个数据模板由一个或多个实体类型、以及无法归入任何实体类型的字词和标点符号构成;每个数据模板中,至少包含一个表示人员身份的实体类型,表示人员身份的部分实体类型成对出现。所述生成单元用于对每一个数据模板,将其中的部分或全部实体类型分别在对应的实体样例集合中随机抽取一个实体样例进行替换;记录替换后文本中哪些字词属于哪个实体类型,以及这些字词的位置,由此得到多条训练数据。
本发明取得的技术效果是:通过构造模板、嵌入样例的方法为命名实体识别模型自动生成训练数据,无需人工标注形成训练数据,节省了大量的人力资源,极大地提高了开发效率。
附图说明
图1是本申请提出的为命名实体识别模型自动生成训练数据的方法的流程示意图。
图2是本申请提出的为命名实体识别模型自动生成训练数据的装置的结构示意图。
图中附图标记说明:1为收集单元、2为抽象单元、3为生成单元。
具体实施方式
本申请采用基于深度学习的命名实体识别技术来实现开庭公告文本数据的结构化。开庭公告是指法院在互联网公布的关于将要开庭审理的案件信息,包括当事人、案号、案由、开庭时间、开庭地点等信息,这些信息以非结构化文本或半结构化文本的形式发布在数千家法院的网站上。
请参阅图1,本申请提出的为命名实体识别模型自动生成训练数据的方法包括如下步骤。
步骤S1:根据开庭公告中出现的命名实体确定多个实体类型,针对每种实体类型收集一定数量的实体样例构成该实体类型对应的实体样例集合。不同实体样例的收集尽可能特征多样化,以提高训练出来的命名实体识别模型的泛化能力。以下是一些示例,方括号内为实体类型,方括号后为该实体类型的一些实体样例。
【法院名称】:北京市高级人民法院、江苏省高级人民法院、苏州市中级人民法院、苏州市姑苏区人民法院、海安县人民法院等。
【时间】:二〇一六年九月二十八日11:00到12:00、二〇二〇年十月十二日上午九时三十分、2020年10月12日上午9时30分、2016-9-28 11:00、2023/10/30 11:24等。
【开庭地点]:第十二法庭、第十三审判庭、互联网二十五庭、第二办公区16号法庭、大安二庭等。
【案号】:(2019)沪0104民初25682号、(2019)苏0830民初4604号、(2019)渝0108民特146号、(2019)豫0823民初5863号、管劳人仲案字〔2022〕1196号、浙杭萧山劳人仲案(2022)2468号等。
【当事人】:廖**、张**、王**、南充**型材有限公司、重庆**文化传播有限责任公司、**(北京)网络科技有限公司、北京**超市有限责任公司一分公司等。在本文件中以*号进行示意的内容,在具体实现时均为正常字词。
【案由】:帮助信息网络犯罪活动罪、侵害作品展览权纠纷、侵害经营秘密纠纷、与公司有关的纠纷、福利待遇纠纷、买卖合同纠纷等。法院公布的开庭公告数据存在大量并非标准化案由的数据,不过这并不影响命名实体识别模型以标准化案由学习到的特征来提取非标准化案由的效果。
步骤S2:将组织形式相同或相近的自然语言文本抽象成一个数据模板,由此得到多个数据模板。每个数据模板是从自然语言文本中将所有需要识别的实体抽象为对应的实体类型、从而使得后续可以使用相同实体类型的实体样例填充进去的一段自然语言文本框架。每个数据模板由一个或多个实体类型和少数无法归入任何实体类型的字词和标点符号按照某一特定表达方式构成。部分或全部的无法归入任何实体类型的字词和标点符号按照器在文本中的功能分别构成一个或多个备选集合,例如表示连接关系的备选集合包括“与”、“和”、半角逗号、全角逗号、半角分号、全角分号、顿号等。每个数据模板中,至少包含一个或多个表示人员身份的实体类型,否则生成的开庭信息训练数据无意义。部分数据模板中可能还包含一个或多个可删除的实体类型。由于自然语言表达的多样性,同一业务——例如开庭公告文本数据的结构化——一般存在多种数据模板,需要尽可能的抽象出所有数据模板才能使命名实体识别模型达到较好的效果。在不同的业务中,数据模板需要重新生成。
例一:开庭公告中经常有这样的表述:张三与李四合同纠纷。这里的张三与李四均可以抽象为“当事人”实体类型,合同纠纷抽象为“案由”实体类型,那么就得到数据模板:【当事人】与【当事人】【案由】。其中的“与”字无法归入任何实体类型,属于表示连接关系的备选集合。这里的当事人并非指司法案件中的所有相关的人或组织,而是指在无法得知该人或组织的具体角色时由本申请赋予的一种实体类型。
例二:开庭公告中经常有这样的表述:我院定于二〇二一年一月二十五日下午十五时十分,在北京法院云法庭依法公开开庭审理(2016)渝0107民初8137号*局第五综合服务保障中心与朱**供用热力合同纠纷一案。与这段话的语言组织形式相同或接近的文本可抽象成如下数据模板:【本院|我院|法院名称】定于【时间】【,|,】在【我院|本院|法院名称】【开庭地点】【依法】【公开】【开庭】【审理】【案号】【当事人1】(,|,|、)【当事人2】(,|,|、)(与|和|,|,|、)【当事人3】(,|,|、)【当事人4】【案由】【一|二|三|四】案。该数据模板中,每个方括号内的字词表示一个实体类型。如果方括号内有竖线,则表示被竖线分隔的多个实体类型是多选一的关系。如果方括号内无竖线时,表示该方括号中的实体类型是可选项。无括号或圆括号内的字词或标点符号无法归入任何实体类型,其中圆括号内的字词或标点符号属于表示连接关系的备选集合。表示人员身份的部分实体类型可以重复出现,例如原告、被告、上诉人、被上诉人、申请人、被申请人等。在开庭公告中可能会出现多名原告,因此数据模板中允许此类实体类型重复出现。数据模板中的这些表示人员身份的部分实体类型如果重复出现时,其数量通常大于或等于1,且小于或等于10。
所述步骤S2中,抽象出来的数据模板要保证特定实体类型成对出现,且不能随意搭配。这是由开庭公告数据的独特性决定的。这里的特定实体类型例如是指原告和被告、上诉人和被上诉人、申请人和被申请人等表示人员身份的部分实体类型,这些特定实体类型必须成对出现。例如,不能将原告和上诉人组合到一起,“原告张三与上诉人李四合同纠纷”就不合常理。也有一些表示人员身份的实体类型可以单独出现,例如第三人。
步骤S3:对每一个数据模板而言,将其中的部分或全部实体类型分别在对应的实体样例集合中随机抽取一个实体样例进行替换,还将其中的部分或全部“无法归入任何实体类型的字词和标点符号”在对应的备选集合中随机抽取一个进行替换(可选);记录替换后文本中哪些字词属于哪个实体类型,以及这些字词的位置(即实体索引),由此得到多条训练数据。对于数据模板中的可删除的实体类型,在该实体类型对应的实体样例集合中随机选择一个实体样例替换该实体类型、或删除该实体类型。例如,按照某一数据模板生成训练数据时,是按照该数据模板的实体类型组织框架从头开始生成文本。当遇到实体类型时,从该实体类型的实体样例集合中随机抽取一个实体样例,替换该实体类型。当遇到非实体类型的字词或符号时,可选地从对应的备选集合中随机抽取一个字词或符号进行替换。生成文本完毕后,记录所生成文本中的实体样例、所属的实体类型以及其在文本中的位置(开始和结束的索引)。
针对例一获取的数据模板【当事人】与【当事人】【案由】,在按照该数据模板生成训练数据时,首先定义一个待生成文本字符串,初始值为空。其次从“当事人”实体类型对应的实体样例集合中随机抽取一个实体样例“王小虎”拼接到待生成文本末尾。接着例如从“与”对应的表示连接关系的备选集合中随机抽取“和”到待生成文本末尾。最后再从“当事人”实体类型对应的实体样例集合中随机抽取一个实体样例“张小兰”拼接到待生成文本的末尾。假设不用实体样例替换“案由”实体类型,就得到一条训练数据,例如:王小虎和张小兰合同纠纷。该段描述仅为一个具体示例。
所述步骤S3中,在按照数据模板生成训练数据时,增加表示人员身份的实体类型时,必须将所述特定实体类型的名称(作为指示实体类型的标志词)与一个或多个实体样例同时增加到待生成文本末尾。假设某一个数据模板是:【原告】与【被告】【案由】。在不同的案件中,张三既可以是原告,也可以是被告,如果只将“张三”这一实体添加到当前【原告】实体位置,而不是同时增加“原告张三”,会导致模型学习效果差。所以这里需要在增加实体样例“张三”的同时在前面增加实体类型的名称“原告”,例如得到一条训练数据:原告张三与被告李四合同纠纷。这里的特定实体类型是指例如原告、被告、上诉人、被上诉人、申请人、被申请人等表示人员身份的实体类型。该段描述仅为一个具体示例。
所述训练数据后续将用于对一个命名实体识别模型进行训练,来实现开庭公告文本数据的结构化。所述命名实体识别模型优选采用Transformer(变换器)+CRF(Conditional Random Fields,条件随机场)的模型结构。
优选地,所述步骤S3中,当根据某个数据模板生成训练数据时,故意改变该数据模板中的实体类型之间的顺序、位置,使实体类型的位置不再固定,而是可能出现在数据模板中的不同位置,得到多个不同的训练数据。
例三:原始文本是“苏州市中级人民法院定于二〇一七年四月二十七日上午九时三十分,在本院12法庭依法公开开庭审理原告梁**与被告**集团有限公司、江苏***造船集团股份有限公司合同纠纷一案”。初始得到的数据模板例如是按照法院名称、时间、开庭地点、当事人、案由的顺序来排列实体类型,按照这一模板生成一定量的训练数据对命名实体识别模型进行训练之后,当给出测试数据“我院定于二〇一七年四月二十七日上午九时三十分,在本院12法庭依法公开开庭审理原告梁**与被告**集团有限公司、江苏***造船集团股份有限公司合同纠纷一案。苏州市中级人民法院”时,模型就存在无法将“苏州市中级人民法院”识别出来的可能。
例四:如果在各种数据模板中原告总是被告的前面,当给出测试数据“审理被告**集团有限公司、江苏***造船集团股份有限公司与原告梁**合同纠纷一案”时,模型会给出错误的实体类型,即将“**集团有限公司和江苏***造船集团股份有限公司”识别为原告,“梁**”识别为被告。
基于特定领域或业务的文本形式,抽象出的数据模板会有一定的局限性,即实体类型的顺序往往较为固定,从而导致训练出来的命名实体识别模型的模型的泛化能力不强,容易被实体位置影响。本申请在生成训练数据时,通过改变数据模板中的实体类型之间的顺序、位置,能够大幅度增强训练出来的命名实体识别模型的泛化能力,提高识别准确率。
优选地,所述步骤S3中,当根据某个数据模板生成训练数据时,故意在该所生成文本的开头、结尾或者句中特定位置增加冗余文本,得到多个不同的训练数据。所述冗余文本不属于任何实体类型,也与任何实体样例都不重复,否则会对模型的精度造成影响。所述冗余文本可以是与开庭公告完全无关的文本,也可以是具体业务中可能出现的文本。
例五:测试数据是“(2016)渝0116民初7329号本院定于二〇一六年八月二十九日14:00到17:30在第十五审判法庭开庭审理(2016)渝0116民初7329号原告陈**诉被告王**,何**企业出售合同纠纷一案。江津区人民法院承办人:文**”。其中,“承办人:文学清”是增加的额外的文本。模型针对该测试数据,有可能会把文**识别为一个人,并且尝试基于现有的命名实体类型进行分类,比如认为其所属的实体类型为被告人,这显然是错误的。
数据模板是为了让命名实体识别模型学习各类实体的特征,从而学会识别它们。但是这一过程并没有教模型学习如何排除哪些不是实体,所以一旦在测试数据中增加额外的文本,模型也会尝试将增加的信息进行实体识别。本申请中在训练数据的开头、结尾以及中间的某些特定位置增加冗余文本,有效地提升了训练出来的命名实体识别模型的抗干扰能力。
请参阅图2,本申请提出的为命名实体识别模型自动生成训练数据的装置包括收集单元1、抽象单元2和生成单元3。图2所示装置对应于图1所示方法。
所述收集单元1用于根据开庭公告中出现的命名实体确定多个实体类型,针对每种实体类型收集一定数量的实体样例构成该实体类型对应的实体样例集合。
所述抽象单元2用于将组织形式相同或相近的自然语言文本抽象成一个数据模板,由此得到多个数据模板。每个数据模板由一个或多个实体类型、以及无法归入任何实体类型的字词和标点符号构成。每个数据模板中,至少包含一个表示人员身份的实体类型,表示人员身份的部分实体类型成对出现。
所述生成单元3用于对每一个数据模板,将其中的部分或全部实体类型分别在对应的实体样例集合中随机抽取一个实体样例进行替换;记录替换后文本中哪些字词属于哪个实体类型,以及这些字词的位置,由此得到多条训练数据。
与现有技术相比,本发明提出的为命名实体识别模型自动生成训练数据的方法具有如下有益效果。
第一,本发明采用的命名实体识别模型共生成26000条训练数据,其中训练集20800条,验证集2600条,测试集2600条。如果采用人工标注形成训练数据的方式,经粗略测试,人工每人每日可标注数据300条,需要约86个工作日完成。本发明采用构造模板、嵌入样例自动生成训练数据的方式,从收集实体样例(例如通过爬虫抓取网络数据)到生成训练数据,约为10个工作日。所以本发明与现有技术相比在数据生成这一环节整体效率提升8.6倍。
第二,本发明进一步通过改变该数据模板中的实体类型的位置、在训练数据的任意位置增加冗余文本等方式,提升了训练数据的质量。根据以前的业务经验,基于规则的方法得到的模型识别准确率在90.7%左右。经过在真实数据集上面的测试,本发明的训练数据得到的命名实体识别模型准确率达到98.4%。
第三,根据平时业务开发统计,开发一个数据源(网站)平均用时2小时。本发明无需额外开发规则去结构化数据,开发一个数据源平均用时1小时,开发效率提升1倍。
以上仅为本发明的优选实施例,并不用于限定本发明。对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。