基于深度学习的船牌识别方法及系统
文献发布时间:2023-06-19 09:26:02
技术领域
本发明涉及深度学习、自然环境文字识别领域,具体地,涉及一种基于深度学 习的船牌识别方法及系统。
背景技术
我国水运资源丰富,水路运输具有运能大、占地少、能耗低、污染小等特点,一直是客货运输的一种极为重要的方式,在我国综合交通运输体系中具有举足轻重的地位和作用。近年来,我国的船运行业更是愈加发达,各类型船舶穿梭于大江大河以及各大海 港之间。船只通常采取关闭AIS等已有检测设备的方式,避开监管系统。虽然现在的港 口和岸边拥有很多监控和雷达设备,但是全凭人工识别去发现和跟踪非法船只难度较大。 随着大数据和人工智能的发展,以人工智能代替人工识别来提高监管效率必将是未来的 发展方向。但是在这个过程中,如何高效准确的识别出这些船只的船牌,就成了这项技 术的一个关键技术难点。
公开号为CN110245613A的专利文献“基于深度学习特征对比的船牌识别方法” 公开了一种采用深度学习卷积神经网络技术构建船只船牌检测模型及船牌字符识 别模型,解决的是将待识别船牌字符的数字识别和汉字识别分开处理,保证训练效 率和收敛速度的问题,与本发明要解决的问题并不一致。
发明内容
针对现有技术中的缺陷,本发明的目的是提供一种基于深度学习的船牌识别方法及系统。
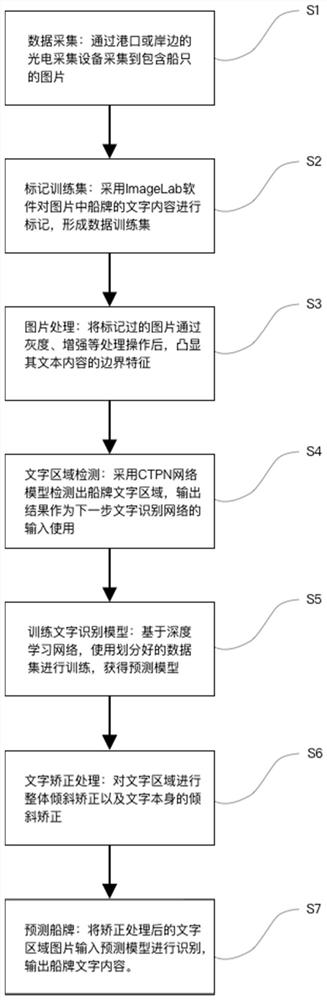
根据本发明的一个方面,提供的一种基于深度学习的船牌识别方法,包括如下步骤:
数据采集步骤:通过光电采集设备采集包含船只的船舶图片;
标记训练集步骤:对船舶图片中船牌的文字内容进行标记,形成数据训练集;
图片处理步骤:将标记过的船舶图片通过灰度、增强等处理操作后,凸显文本内容的边界特征;
文字区域检测步骤:对经过图片处理步骤处理过的船舶图片,采用CTPN文字检测网络模型检测出船舶图片中的船牌文字区域,检测结果作为训练文字识别模型步骤的输入使用;
训练文字识别模型步骤:基于深度学习网络,使用检测结果进行训练,获得文字识别预测模型;
文字矫正处理步骤:对待识别船舶图片中的船牌文字区域进行整体倾斜矫正以及文 字本身的字体倾斜矫正;
预测船牌步骤:将文字矫正处理后的检测结果输入文字识别预测模型进行识别,输 出船牌文字内容。
优选地,所述数据采集步骤中,所述船舶图片包括两部分,一部分是直接使用带有抓拍功能的成像设备抓拍所得的照片,另一部分是光电视频采集设备获取的视频,从中 截取出包含船只的帧图片。
优选地,所述从中截取出包含船只的帧图片,包括采用三帧差分算法,记获取视频序列中某第n-1帧、第n帧和第n+1帧图片对应为f
优选地,所述标记训练集步骤中,使用ImageLab标记软件,对上一步收集到的船舶图片进行人工标注,标注出船牌的文字内容,标注结果输出至XML文件中保存,一张 船舶图片对应与一个XML文件建立联系。
优选地,所述图片处理步骤中,包括:
图片灰度处理子步骤:对图片进行一次预处理,将图片灰度化,仅由一个分量表示出来,采用平均值灰度法,公式为Gray(x,y)=(R(x,y)+G(x,y)+B(x,y))/3,将彩色 图片中的三分量亮度求平均得到一个灰度值,最终得到灰度后的图片,所述x表示像素 点的横坐标,所述y表示像素点的纵坐标,所述R是红色分量,所述G是绿色分量,所 述B是蓝色分量;
图片增强处理子步骤:将图片灰度处理子步骤处理得到的灰度图片进行增强处理, 采用灰度直方图均衡化算法实现细节增强,包括:
首先,统计原始图像各灰度级的像素数目n
然后,图像中灰度为i的像素的出现概率是:
接着,p
最后,直方图均衡化计算公式
优选地,所述文字区域检测步骤中,所述采用CTPN文字检测网络模型检测出船舶图片中的船牌文字区域,包括文字区域检测采用成熟的CTPN文字检测算法实现,将标 记过船牌文字内容的训练集图片输入准备好的CTPN文字检测模型中,得到船牌文字内 容的坐标位置信息,并输入所述船舶图片对应的XML文件中作为训练集数据保存。
优选地,所述训练文字识别模型步骤包括:
预处理子步骤:所述训练集数据在输入船牌识别网络进行训练之前,需要进行一次 预处理,依据所述船舶图片对应XML文件中存储的文字区域信息进行图片截取,设截取的图片宽为W,高为H,再对截取出的图片进行统一高度的缩放处理,使高度缩放到32, 宽度等比缩放至W*H/32尺寸,形成高度统一宽度不定的训练集数据,把训练集数据输 入船牌训练网络进行训练;
文字识别网络结构搭建子步骤:船牌识别网络结构包括7个Conv层、4个 Max-Pooling层、2个Bn层、2个双向LSTM网络和CTC loss转录层;其中CNN卷积层, 使用深度CNN,对输入图像提取特征,得到特征图;其中RNN循环层,使用双向RNN, 包含BLSTM,对特征序列进行预测,对序列中的每个特征向量进行学习,并输出预测标 签包含真实值分布;所述的CTC loss转录层,使用CTC损失,把RNN循环层获取的一 系列标签分布转换成最终的标签序列;
接入relu函数子步骤:所述的Conv层,在每一层卷积层后面都接入了relu函数,解决梯度消失问题,使网络具有稀疏性;
引入BatchNormalization模块子步骤:在第Conv5和Conv6卷积层后面引入了BatchNormalization模块,用于加速模型的收敛,缩短训练过程;
池化层尺寸选取子步骤:所述的Max-Pooling层,窗口尺寸选取2*2,适合整体方正的汉字对象识别;
CNN处理子步骤:输入预处理子步骤得到的训练集数据,图片通过CNN后,高度由32变为1,所以CNN的输入数据尺寸为(channel,height,width)=(1,32,width), CNN的输出尺寸为(512,1,width/4),CNN最后得到的是512个特征图;
RNN处理子步骤:将CNN得到的特征图输入到RNN进行训练,在此之前,需要先从CNN产生的特征图中提取特征向量序列,每一个特征向量在特征图上按列从左到右生成,每一列包含512维特征,第i个特征向量是所有的特征图第i列像素的连接,这些特征 向量就构成了一个特征向量序列,这些特征向量序列,就作为RNN循环层的输入,每个 特征向量作为RNN在一个时间步,也就是time step的输入;
LSTM处理子步骤:RNN中存在梯度消失的问题,不能获取更多的上下文信息,船 牌识别网络使用的是LSTM来解决这个问题,LSTM的特殊设计允许它捕获长距离依赖; 这里采用的是两层各256单元的双向LSTM网络,经过RNN处理子步骤,得到了t个特 征向量,每个特征向量长度为512,LSTM中一个时间步就传入一个特征向量行分类, 即t个时间步;根据输入的特征向量来进行预测,每个时间步都会有一个输入特征向量 X
CTC loss转录层处理子步骤:LSTM处理子步骤的结果输入CTC loss转录层进行训练,将RNN对每个特征向量所做的预测转换成标签序列,即找到具有最高概率组合 的标签序列;因为训练样本是统一高度32,长度不固定的图片,而CTC是一种不需要 对齐的Loss计算方法,用CTC代替Softmax Loss,解决了训练样本不对齐的问题;对 于LSTM处理子步骤中,RNN训练给出的概率分布为Y={Y
输出子步骤:经过整个船牌识别网络的训练输出,得到最终的识别文本,将识别出的结果保存进之前存储的XML文件中,根据之前保存的包含位置信息的XML文本,可编 写程序在原图的对应位置画框标记,并添加识别出的文本信息,并最终可视化输出。
优选地,所述文字矫正处理步骤包括:
文字区域的整体倾斜矫正子步骤,包括:目标图片在输入船牌识别网络预测模型之 前需要做一次文字区域的矫正处理;根据所述文字区域检测步骤中获取的文字区域,其左下角坐标为(x
文字区域的文字本身倾斜矫正子步骤,包括:
首先,将文字图片进行滤波和二值化处理;
然后,使用图像模糊算法对其进行水平模糊,从而将文字图像上长度小于某一域值 的连续黑点转为白点,图像上距离相近的连通成份将会形成为一较大的连通区域;
接着,使用水平投影算法对连通区域进行图像垂直投影,根据垂直投影的测角原理 计算出倾斜字体的角度;
最后,根据倾斜角对文本区域的原图进行像素坐标的空间转换,并采用双线性插值 来降低转换过程中的失真问题,并对校正后的图像进行平滑处理,以消除插值带来的毛刺点。
优选地,所述预测船牌步骤包括:经过训练文字识别模型步骤中神经网络的反复训 练,获取并保存最终的训练模型结果作为预测模型,组合图片处理步骤、文字区域检测步骤、训练文字识别模型步骤中的预处理子步骤、文字矫正处理步骤,将矫正后的文字 区域图输入预测模型,形成一个需输入图片能够输出船牌的识别系统,将包含船牌的船 只图片输入识别系统,能够识别并输出船牌的内容。
根据本发明的另一个方面,提供一种基于深度学习的船牌识别系统,包括以下模块:
数据采集模块:通过光电采集设备采集包含船只的船舶图片;
标记训练集模块:对船舶图片中船牌的文字内容进行标记,形成数据训练集;
图片处理模块:将标记过的船舶图片通过灰度、增强处理操作,凸显出文本内容的边界特征;
文字区域检测模块:对经过图片处理模块处理过的船舶图片,采用CTPN文字检测网络模型检测出船舶图片中的船牌文字区域,检测结果作为训练文字识别模型模块的输入使用;
训练文字识别模型模块:基于深度学习网络,使用检测结果进行训练,获得文字识别预测模型;
文字矫正处理模块:对待识别船舶图片中的船牌文字区域进行整体倾斜矫正以及文 字本身的字体倾斜矫正;
预测船牌模块:将文字矫正处理后的检测结果输入文字识别预测模型进行识别,输 出船牌文字内容。
与现有技术相比,本发明具有如下的有益效果:
1.本发明通过对船舶图片的处理,检测文字区域并进行文字识别训练,最终实现船 牌内容识别;
2.本发明针对船牌识别设计深度学习网络,通过对训练图片的预处理以及对船牌文 字区域的矫正操作,降低了训练任务量也提高了预测模型识别船牌的正确率。
附图说明
通过阅读参照以下附图对非限制性实施例所作的详细描述,本发明的其它特征、目的和优点将会变得更明显:
图1为本发明的方法逻辑图;
图2为本发明的船牌识别网络部分网络结构图;
图3为灰度化后的图片;
图4为增强后的图片;
图5为输入船牌识别网络高度为32的训练图。
具体实施方式
下面结合具体实施例对本发明进行详细说明。以下实施例将有助于本领域的技术人 员进一步理解本发明,但不以任何形式限制本发明。应当指出的是,对本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变化和改进。这些都属于 本发明的保护范围。
在本实施例中,基于深度学习的船牌识别方法流程图如图1所示,包括如下步骤:
数据采集步骤:通过港口的光电采集设备采集到包含船只的船舶图片;标记训练集 步骤:采用ImageLab软件对船舶图片中船牌的文字内容进行标记,形成数据训练集; 图片处理步骤:将标记过的船舶图片通过灰度、增强等处理操作后,凸显文本内容的边 界特征;文字区域检测步骤:对经过图片处理步骤处理过的船舶图片,采用CTPN文字 检测网络模型检测出船舶图片中的船牌文字区域,检测结果作为下一步训练文字识别模 型步骤的输入使用;训练文字识别模型步骤:基于深度学习网络,使用检测结果进行训 练,获得文字识别预测模型;文字矫正处理步骤:对待识别船舶图片中的船牌文字区域 进行整体倾斜矫正以及文字本身的字体倾斜矫正;预测船牌步骤:将文字矫正处理后的 检测结果输入文字识别预测模型进行识别,输出船牌文字内容。
在数据采集步骤中,本实施例中采用直接使用带有抓拍功能的成像设备抓拍所得的 照片。
在标记训练集步骤中,采用ImageLab软件对船舶图片中船牌的文字内容进行标记, 形成数据训练集,包括使用ImageLab标记软件,对上一步收集到的船舶图片进行人工标注,标注出船牌的文字内容,标注结果输出至XML文件中保存,一张船舶图片对应与 一个XML文件建立联系。
在图片处理步骤中,包括:图片灰度处理子步骤:由于所获取的图片为彩色图片,包含RGB三色通道,对于计算机来说,彩色图片包含的信息量较大,在处理图像时,需 要分别对RGB三种分量进行处理,直接使用彩色图片进行训练会加大训练难度和任务量, 实际上RGB并不能反映图像的形态特征,只是从光学原理上进行颜色调配,因此对图片 进行一次预处理,将图片灰度化,仅由一个分量表示出来,这极大的减小了任务量,采 用平均值灰度法,公式为Gray(x,y)=(R(x,y)+G(x,y)+B(x,y))/3,将彩色图片中的 三分量亮度求平均得到一个灰度值,最终得到灰度后的图片,如图3所示, 所述x表示像素点的横坐标,所述y表示像素点的纵坐标,R是红色分量,G是绿色分量, B是蓝色分量;图片增强处理子步骤:将图片灰度处理子步骤处理得到的灰度图片进行 增强处理,采用灰度直方图均衡化算法实现细节增强,包括:首先,统计原始图像各灰 度级的像素数目n
在文字区域检测步骤中,采用CTPN文字检测网络模型检测出船舶图片中的船牌文字区域,包括文字区域检测采用成熟的CTPN文字检测算法实现,将标记过船牌文字内 容的训练集图片输入准备好的CTPN文字检测模型中,得到船牌文字内容的坐标位置信 息,并输入船舶图片对应的XML文件中作为训练集数据保存。
在训练文字识别模型步骤中,首先进行预处理操作:训练集数据在输入船牌识别网 络进行训练之前,需要进行一次预处理,依据船舶图片对应XML文件中存储的文字区域信息进行图片截取,设截取的图片宽为W,高为H,再对截取出的图片进行统一高度的 缩放处理,使高度缩放到32,宽度等比缩放至W*H/32尺寸,形成高度统一宽度不定的 训练集数据,把训练集数据输入船牌训练网络进行训练,截取并缩放处理后的文字图片 如图5所示;然后搭建文字识别网络结构:如图2所示,船牌识别网络结构包括7个Conv 层、4个Max-Pooling层、2个Bn层、2个双向LSTM网络和CTC loss转录层;其中CNN 卷积层,使用深度CNN,对输入图像提取特征,得到特征图;其中RNN循环层,使用双 向RNN,包含BLSTM,对特征序列进行预测,对序列中的每个特征向量进行学习,并输 出预测标签包含真实值分布;的CTCloss转录层,使用CTC损失,把RNN循环层获取 的一系列标签分布转换成最终的标签序列;接入relu函数子步骤:的Conv层,在每一 层卷积层后面都接入了relu函数,解决梯度消失问题,使网络具有稀疏性;引入 BatchNormalization模块子步骤:在第Conv5和Conv6卷积层后面引入了 BatchNormalization模块,用于加速模型的收敛,缩短训练过程;池化层尺寸选取子步 骤:的Max-Pooling层,窗口尺寸选取2*2,适合整体方正的汉字对象识别;CNN处理 子步骤:输入预处理子步骤得到的训练集数据,图片通过CNN后,高度由32变为1,所以CNN的输入数据尺寸为(channel,height,width)=(1,32,width),CNN的输出 尺寸为(512,1,width/4),CNN最后得到的是512个特征图;RNN处理子步骤:将CNN 得到的特征图输入到RNN进行训练,在此之前,需要先从CNN产生的特征图中提取特征 向量序列,每一个特征向量在特征图上按列从左到右生成,每一列包含512维特征,第 i个特征向量是所有的特征图第i列像素的连接,这些特征向量就构成了一个特征向量 序列,这些特征向量序列,就作为RNN循环层的输入,每个特征向量作为RNN在一个时 间步,也就是time step的输入;LSTM处理子步骤:因为RNN中存在梯度消失的问 题,不能获取更多的上下文信息,所以船牌识别网络使用的是LSTM,LSTM的特殊设 计允许它捕获长距离依赖;这里采用的是两层各256单元的双向LSTM网络,经过RNN 处理子步骤,得到了t个特征向量,每个特征向量长度为512,LSTM中一个时间步就 传入一个特征向量行分类,即t个时间步;根据输入的特征向量来进行预测,每个时间 步都会有一个输入特征向量X
在文字矫正处理步骤中,先执行文字区域的整体倾斜矫正子步骤,由于水面上环境 复杂,波浪抬高因素以及各种船只的朝向不确定,所捕捉到的图片中的船牌通常具有一定的倾斜度,因此文字区域检测步骤中获取的船牌区域坐标框存在一定的倾斜角度,为 了使训练好的船牌识别网络模型能够更加精确的识别出船牌内容,目标图片在输入船牌 识别网络预测模型之前需要做一次文字区域的矫正处理;根据文字区域检测步骤中获取 的文字区域,其左下角坐标为(x
最后,经过训练文字识别模型步骤中神经网络的反复训练,获取并保存最终的训练 模型结果作为预测模型,组合图片处理步骤、文字区域检测步骤、训练文字识别模型步骤中的预处理子步骤、文字矫正处理步骤,将矫正后的文字区域图输入预测模型,形成 一个需输入图片能够输出船牌的识别系统,将包含船牌的船只图片输入识别系统,能够 识别并输出船牌的内容。
本发明还提供了一种基于深度学习的船牌识别系统,包括以下模块:
数据采集模块:通过光电采集设备采集包含船只的船舶图片;
标记训练集模块:对船舶图片中船牌的文字内容进行标记,形成数据训练集;
图片处理模块:将标记过的船舶图片通过灰度、增强处理操作,凸显出文本内容的边界特征;
文字区域检测模块:对经过图片处理模块处理过的船舶图片,采用CTPN文字检测网络模型检测出船舶图片中的船牌文字区域,检测结果作为训练文字识别模型模块的输入使用;
训练文字识别模型模块:基于深度学习网络,使用检测结果进行训练,获得文字识别预测模型;
文字矫正处理模块:对待识别船舶图片中的船牌文字区域进行整体倾斜矫正以及文 字本身的字体倾斜矫正;
预测船牌模块:将文字矫正处理后的检测结果输入文字识别预测模型进行识别,输 出船牌文字内容。
本领域技术人员知道,除了以纯计算机可读程序代码方式实现本发明提供的系统及 其各个装置、模块、单元以外,完全可以通过将方法步骤进行逻辑编程来使得本发明提供的系统及其各个装置、模块、单元以逻辑门、开关、专用集成电路、可编程逻辑控制 器以及嵌入式微控制器等的形式来实现相同功能。所以,本发明提供的系统及其各项装 置、模块、单元可以被认为是一种硬件部件,而对其内包括的用于实现各种功能的装置、 模块、单元也可以视为硬件部件内的结构;也可以将用于实现各种功能的装置、模块、 单元视为既可以是实现方法的软件模块又可以是硬件部件内的结构。
以上对本发明的具体实施例进行了描述。需要理解的是,本发明并不局限于上 述特定实施方式,本领域技术人员可以在权利要求的范围内做出各种变化或修改, 这并不影响本发明的实质内容。在不冲突的情况下,本申请的实施例和实施例中的 特征可以任意相互组合。