字幕生成装置、方法以及存储介质
文献发布时间:2023-06-19 19:33:46
本申请以日本专利申请2021-178498(申请日:2021年11月1日)为基础,从该申请享受优先的权益。本申请通过参考该申请而包含该申请的全部内容。
技术领域
实施方式涉及字幕生成装置、方法以及存储介质。
背景技术
在电视节目等的字幕制作中,有活用声音辨识技术来自动地生成字幕的技术。近年来,随着深度学习技术的发展,声音辨识的精度快速地提高,但由于包含背景音、言语错误、术语的发声等,声音辨识有可能出现错误。因此,在实际的字幕制作时,并非通过声音辨识来制作所有的字幕,而是在大部分的情况下,人工地确认声音辨识结果的字幕来修正错误,制作最终的字幕。
另外,在如新闻节目等那样实时地根据声音辨识结果生成字幕的情况下,希望确保人工的修正时间,所以期望提早地得到声音辨识结果。作为其有效的方法,有提早确定这样的技术。提早确定是指在包括声音辨识的模式辨识中当搜索空间的候选变少时结束搜索并在该时间点输出辨识结果的技术,适用于实时地利用声音辨识的应用。然而,在使用了提早确定的情况下,在发声结束前结束搜索,所以声音辨识结果被缩短,或者有时相反地搜索空间未被缩小而声音辨识结果变长。因此,在将提早确定的技术用于字幕生成的情况下,为了使人易于阅读字幕,对声音辨识结果进行结合或者分割这样的修正的负担大。
如以上那样,在以往的字幕生成装置中,在实时地根据声音辨识结果生成字幕时,用于使字幕变得易于阅读的修正的负担大。
发明内容
本发明要解决的课题在于,提供一种在实时地根据声音辨识结果生成字幕时能够降低用于使字幕变得易于阅读的修正的负担的字幕生成装置、方法以及存储介质。
实施方式所涉及的字幕生成装置具备取得部、历史部、生成部、历史更新部以及提示部。所述取得部逐次地取得声音辨识结果的文本。所述历史部将所述文本保存为历史数据。所述生成部根据所述保存的一个以上的所述历史数据推测所述文本的分割位置以及结合位置,并基于所述分割位置以及所述结合位置,根据一个以上的所述历史数据生成字幕文本。所述历史更新部根据所述分割位置以及所述结合位置来更新所述历史数据。所述提示部提示所述字幕文本。
附图说明
图1是示出第1实施方式所涉及的字幕生成装置的一个例子的框图。
图2是用于说明第1实施方式所涉及的历史数据的示意图。
图3是用于说明第1实施方式中的动作的一个例子的流程图。
图4是用于说明第1实施方式中的动作的一个例子的示意图。
图5是示出第2实施方式所涉及的字幕生成装置的一个例子的框图。
图6是用于说明第2实施方式中的动作的一个例子的流程图。
图7是用于说明第2实施方式中的动作的一个例子的示意图。
图8是示出第3实施方式所涉及的字幕生成装置的一个例子的框图。
图9是用于说明第3实施方式中的动作的一个例子的流程图。
图10是用于说明第3实施方式中的动作的一个例子的示意图。
图11是例示第4实施方式所涉及的字幕生成装置的硬件结构的图。
(符号的说明)
10:声音辨识部;20:字幕生成装置;21:历史部;21a:历史数据;22:取得部;23:历史更新部;24:字幕处理部;24a:生成部;24b:重新生成部;24c:修正候选生成部;25:用户接口部;26:修正期望接收部;201:CPU;202:RAM;203:程序存储器;204:辅助存储装置;205:输入输出接口;UA1:斜拖动作;UA2:滑动动作;UA3:指示动作。
具体实施方式
以下,参考附图,说明各实施方式。各实施方式所涉及的字幕生成装置例如用于在电视的新闻节目等的字幕制作中在实时地辨识声音之后人工地进行确认和修正的系统等。此外,各实施方式中的实时并非是指瞬间或同时,而包括由于数据处理、通信而引起的延迟。另外,字幕生成装置也可以适当地改成自动字幕生成装置等这样的任意的名称。
<第1实施方式>
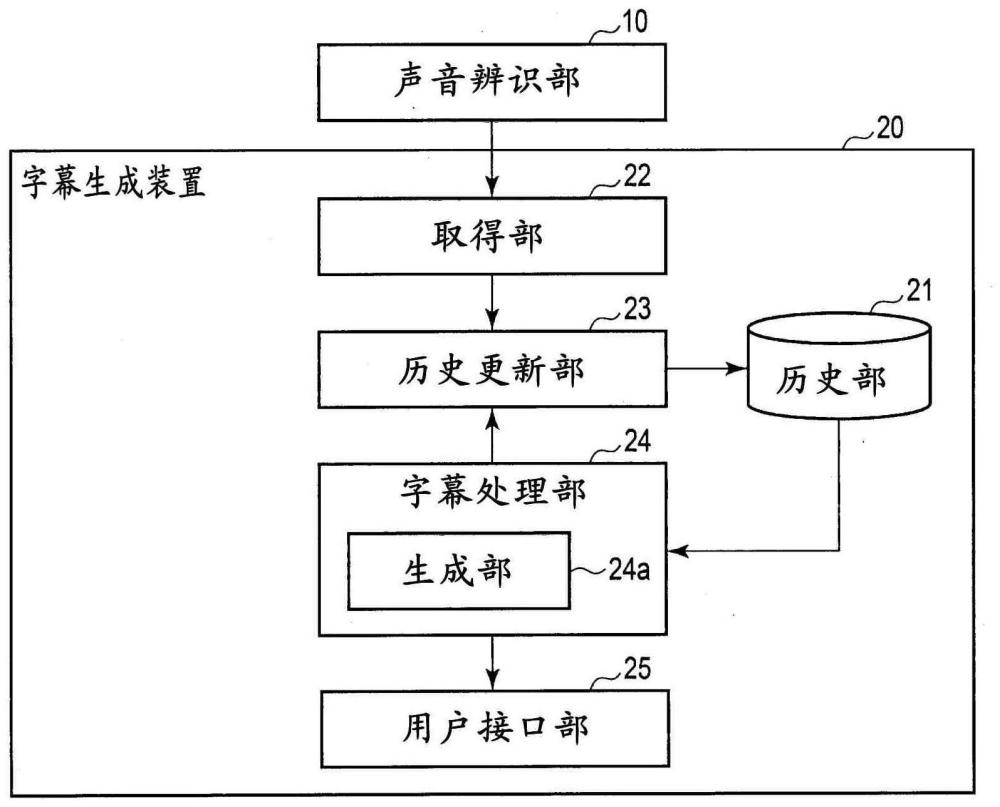
图1是示出第1实施方式所涉及的字幕生成装置的框图。在图1中,声音辨识部10与字幕生成装置20连接。字幕生成装置20具备历史部21、取得部22、历史更新部23、字幕处理部24以及用户接口部25。字幕处理部24包括生成部24a。
在此,声音辨识部10连续地取得声音数据,针对取得的声音数据进行声音辨识,生成声音辨识结果的文本。
历史部21是可从历史更新部23以及生成部24a进行读出/写入的存储器。历史部21例如保存与取得的声音辨识结果的文本有关的历史数据、以及与基于历史数据的字幕文本的生成有关的数据。历史数据21a如图2所示是将被取得部22逐次地取得的声音辨识结果的文本、和作为与生成部24a生成的字幕文本有关的信息的已输出字符数及分割字符位置对应起来的信息。此外,作为历史数据21a,也可以针对声音辨识结果的每个文本,除了已输出字符数以及分割字符位置以外,还包括识别ID、取得时刻(取得日期时间)、字符串长度(字符数)等。
识别ID是对逐次地取得的各个文本进行识别的信息。
取得时刻是取得各个文本的时刻,包括未图示的取得日。即,取得时刻是取得日期时间的一个例子。
文本是表示逐次地取得的声音辨识结果的字符串。例如,“新型コロナウイルスワクチンの大規模接種センターの予約が今日からスタートしました”这样的日文文章在日语中发音为“shingata-korona-uirusu-wakuchin-no-daikibo-sessyu-sentaa-no-yoyaku-ga-kyoo-kara-sutaato-shimashita”,中文含义是“新型冠状病毒疫苗接种的大规模接种中心的预约从今天开始”。关于该文章,逐次地取得“新型コロナウイルスワクチン”(utterance;shingata-korona-uirusu-wakuchin:meaning;新型コロナウイルスワクチン)、“の大規模接種”(no-daikibo-sessyu:の大規模接種)、“センターの”(sentaa-no:センターの)、“予約が今日”(yoyaku-ga-kyoo:予約が今日)、“からスタートしました”(kara-sutaato-shimashita:からスタートしました)。另外,“東京会場となる合同庁舎”这样的日文文章的一部分在日语中发音为“tookyoo-kaijyoo-tonaru-goodoochoosya”,中文含义是“成为东京会场的综合政府大楼”。该文章的一部分被逐次地取得为“東京会場”(tookyoo-kaijyoo:東京会場)、“となる合同庁舎”(tonaru-goodoochoosya:となる合同庁舎)。
字符串长度是文本的字符串的长度,换言之是文本的字符数。
已输出字符数是文本之中的从生成部24a向用户接口部25已输出的文本的字符数。在图2的例子中,已输出字符为“新型コロナウイルスワクチンの大規模接種センターの予約が”(shingata-korona-uirusu-wakuchin-no-daikibo-sessyu-sentaa-no-yoyaku-ga:新型コロナウイルスワクチンの大規模接種センターの予約が)。
分割字符位置是结合了文本时的对该文本进行分割(换行)的字符的位置。
作为与字幕文本的生成有关的数据,可适当使用后述的显示候选的当前位置CSI、显示候选排列、连结文本的字符串长度、最大字符数、单词识别WID、特征向量(featurevector)、更新信息、分割推测评分、单词分割位置SWI等。
取得部22从声音辨识部10逐次地取得声音辨识结果的文本。此外,字幕生成装置20也可以代替声音辨识部10以及取得部22,而具备连续地取得声音数据并针对所取得的声音数据进行声音辨识,逐次地将声音辨识结果的文本发送给历史更新部23的声音辨识部。
历史更新部23将取得部22取得的声音辨识结果的文本作为历史数据21a而保存到历史部21。另外,历史更新部23根据与生成部24a生成的字幕文本有关的信息,更新历史部21的历史数据21a。
生成部24a根据保存于历史部21的一个以上的历史数据21a来推测文本的分割位置和结合位置,并基于所推测的分割位置和结合位置,根据历史数据21a生成字幕文本。在此,生成部24a也可以以直至结合文本而得到的连结文本的字符数成为阈值字符数(最大字符数)以上为止结合历史数据的文本的方式,推测结合位置。另外,生成部24a也可以针对结合文本而得到的连结文本执行词素解析以及依存解析(dependency parsing)中的某一方或者两方,并根据该执行结果来生成各单词的特征向量。在该情况下,生成部24a使用特征向量来计算各单词的分割推测评分,并根据分割推测评分推测分割位置。
用户接口部25向用户提示生成部24a生成的字幕文本。作为用户接口部25,例如既可以为对字幕文本进行显示的显示器,也可以为兼具该显示器和输入功能的触摸面板等。另外,作为用户接口部25,也可以除了该显示器以外还具备作为输入功能的键盘以及鼠标等。该输入功能可适当地使用于字幕文本的分割位置、结合位置、声音辨识错误等的修正。用户接口部25是提示部的一个例子。
接下来,使用图3的流程图以及图4的示意图,说明如以上那样构成的字幕生成装置的动作。
(步骤ST1)
取得部22逐次地取得声音辨识结果的文本。具体而言,声音辨识部10针对连续地接收到的声音数据进行声音辨识,如图4所示生成声音辨识结果的文本。取得部22从声音辨识部10逐次地取得声音辨识结果的文本。此外,关于取得的文本,根据时滞(time lag)少的观点,优选为利用了上述提早确定技术的声音辨识结果的文本。但是,不限于此,取得的文本也可以是利用了一般的发声区间推测技术时的声音辨识结果的文本。
此外,在图4中,“新型コロナウイルスワクチンの大規模接種センターの予約が今日からスタートしました”的日文文章如上所述。另外,在图4中,“東京会場となる千代田区の大手町合同庁舎では接種に当たる自衛官のいかんや看護官らが編成完結式を行いました”的日文文章发音为“tookyoo-kaijyoo-tonaru-chiyodaku-no-ootemachi-goodoochoosya-dewa-sessyu-ni-ataru-jieitai-no-ikan-ya-kangokan-ra-ga-hensei-kanketsushiki-o-okonaimashita”,中文含义是“在成为东京会场的千代田区的大手巷综合政府大楼中进行接种的自卫队员的医疗官、护士们进行了编组完成仪式”。
(步骤ST2)
历史更新部23将取得的声音辨识结果的文本作为历史数据21a而保存到历史部21。在图2所示的例子中,针对“新型コロナウイルスワクチンの大規模接種センターの予約が今日からスタートしました。東京会場となる合同庁舎”(shingata-korona-uirusu-wakuchin-no-daikibo-sessyu-sentaa-no-yoyaku-ga-kyoo-kara-sutaato-shimashita.tookyoo-kaijyoo-tonaru-goodoochoosya)这样的发声,将“新型コロナウイルスワクチン”(shingata-korona-uirusu-wakuchin)、“の大規模接種”(no-daikibo-sessyu)、“センターの”(sentaa-no)等分别逐次地取得的声音辨识结果的文本保存为历史数据21a。在历史数据21a中,与声音辨识结果文本一起至少保持对历史数据21a进行识别的识别ID、已输出的字符数、分割字符位置。历史更新部23在取得了声音辨识文本的情况下,与声音辨识结果文本一起,新制作新的识别ID、已输出字符数为0、无分割字符位置的数据,并作为历史数据21a而保存到历史部21。以上的步骤ST1~ST2与接下来的步骤ST3以后的处理并行地反复执行。
(步骤ST3)
生成部24a抽出历史部21内的历史数据21a之中的未作为字幕文本提示的1个以上的历史数据21a。
例如,将历史部21内的历史数据21a的排列作为历史数据排列。具体而言,例如历史数据排列具有包括用识别ID=0~6来识别的各文本的7个历史数据21a。各历史数据21a例如是{识别ID=0和“新型コロナウイルスワクチン”(shingata-korona-uirusu-wakuchin)}、{识别ID=1和“の大規模接種”(no-daikibo-sessyu)}、{识别ID=2和“センターの”(sentaa-no)}、{识别ID=3和“予約が今日”(yoyaku-ga-kyoo)}、{识别ID=4和“からスタートしました”(kara-sutaato-shimashita)}、{识别ID=5和“東京会場”(tookyoo-kaijyoo)}、{识别ID=6和“となる合同庁舎”(tonaru-goodoochoosya)}。另外,设为将生成的字幕文本的最大字符数预先决定为30字符。
首先,生成部24a将历史数据排列中的显示候选的当前位置CSI、保持历史数据排列中的1个以上的历史数据21a的显示候选排列、以及连结显示候选排列中的历史数据21a的文本而得到的连结文本的字符串长度进行初始化。
另外,生成部24a在历史数据排列的大小大于显示候选的当前位置CSI的情况、即在历史数据排列中有未被显示为字幕文本的历史数据21a的情况下,将以下进行重复。
首先,生成部24a在从历史数据排列中取得第CSI的历史数据21a时,使显示候选的当前位置CSI增加1,并将历史数据21a追加到显示候选排列。
接下来,生成部24a将从历史数据21a的声音辨识结果的文本的字符串长度减去历史数据21a的已输出字符数而得到的值,追加到连结文本的字符串长度。在此,生成部24a在连结文本的字符串长度大于生成的字幕文本的最大字符数的情况下,为了使连结文本易于阅读,转移到步骤ST4。
例如,在显示候选的当前位置CSI=0的情况下,从历史数据排列中取得第0(识别ID=0)的历史数据21a的“新型コロナウイルスワクチン”(shingata-korona-uirusu-wakuchin),并将取得的历史数据21a追加到显示候选排列。此时,识别ID=0的历史数据21a的字符串长度是13,已输出字符数是0,所以连结文本的字符串长度成为13。以下,使显示候选的当前位置CSI增加1,同样地取得第CSI的历史数据21a并追加到显示候选排列。由此,在连结文本的字符串长度大于最大字符数(30字符)时,在显示候选排列中追加有识别ID=0~4的历史数据21a。此外,识别ID=0~4的各历史数据21a的文本是“新型コロナウイルスワクチン”(shingata-korona-uirusu-wakuchin)、“の大規模接種”(no-daikibo-sessyu)、“センターの”(sentaa-no)、“予約が今日”(yoyaku-ga-kyoo)、“からスタートしました”(kara-sutaato-shimashita)。因此,在这个例子中,连结文本的字符串长度为39(=13+6+5+5+10)。
(步骤ST4)
生成部24a根据抽出的历史数据21a的文本,推测结合位置和分割位置。例如,生成部24a以直至结合文本而得到的连结文本的字符数成为最大字符数(阈值字符数)以上为止结合历史数据21a的文本的方式,推测结合位置。另外,例如生成部24a根据显示候选排列来推测分割位置,并转移到步骤ST5。具体而言,例如根据前后的上下文来推测分割位置。
首先,生成部24a将连结显示候选排列内的文本而得到的连结文本、以及历史数据21a的更新信息进行初始化。
接下来,生成部24a针对显示候选排列内的各历史数据21a,将各历史数据的识别ID和文本开始位置对应起来保存到更新信息,并且直至成为最大字符数以上为止将文本进行连结来制作连结文本。
例如,设为识别ID=0~4的历史数据21a的文本是“新型コロナウイルスワクチン”(shingata-korona-uirusu-wakuchin)、“の大規模接種”(no-daikibo-sessyu)、“センターの”(sentaa-no)、“予約が今日”(yoyaku-ga-kyoo)、“からスタートしました”(kara-sutaato-shimashita)。在该情况下,在更新信息中保存{识别ID=0和文本开始位置“0”}、{识别ID=1和文本开始位置“13”}、{识别ID=2和文本开始位置“19”}、{识别ID=3和文本开始位置“24”}、{识别ID=4和文本开始位置“29”}。此外,文本开始位置相当于连结文本内的各文本之前的字符串长度。另外,制作连结文本“新型コロナウイルスワクチンの大規模接種センターの予約が今日からスタートしました”(shingata-korona-uirusu-wakuchin-no-daikibo-sessyu-sentaa-no-yoyaku-ga-kyoo-kara-sutaato-shimashita)。如上所述,该连结文本的字符串长度是39,直至成为作为最大字符数的30字符以上为止连结声音辨识结果的文本。
接下来,生成部24a针对结合文本而得到的连结文本,执行词素解析以及依存解析中的某一方或者两方,并根据该执行结果而生成各单词的特征向量。另外,生成部24a使用特征向量来计算各单词的分割推测评分,根据分割推测评分来推测分割位置。
具体而言,例如生成部24a针对连结文本进行词素解析,根据词素解析的结果而生成将各单词和单词识别WID关联起来的单词排列。例如,作为单词排列而生成{单词识别WID=0和“新型コロナウイルス”(shingata-korona-uirusu:新型コロナウイルス)}、{单词识别WID=1和“ワクチン”(wakuchin:ワクチン)}、{单词识别WID=2和“の”(no:の)}、{单词识别WID=3和“大規模”(daikibo:大規模)}、{单词识别WID=4和“接種”(sessyu:接種)}、{单词识别WID=5和“センター”(sentaa:センター)}、{单词识别WID=6和“の”(no:の)}、{单词识别WID=7和“予約”(yoyaku:予約)}、{单词识别WID=8和“が”(ga:が)}、{单词识别WID=9和“今日”(kyoo:今日)}、{单词识别WID=10和“から”(kara:から)}、{单词识别WID=11和“スタート”(sutaato:スタート)}、{单词识别WID=12和“し”(shi:し)}、{单词识别WID=13和“まし”(mashi:まし)}、{单词识别WID=14和“た”(ta:た)}。
接下来,生成部24a针对单词排列,使用保持于更新信息的文本开始位置,将各历史数据21a的识别ID和单词识别WID对应起来而保存到更新信息。
例如,在识别ID=0~4的历史数据21a(“新型コロナウイルスワクチン”(shingata-korona-uirusu)、“の大規模接種”(no-daikibo-sessyu)、“センターの”(sentaa-no)、“予約が今日”(yoyaku-ga-kyoo)、“からスタートしました”(kara-sutaato-shimashita))的情况下,在更新信息中以下被保存。{识别ID=0和“新型コロナウイルス(shingata-korona-uirusu)(WID=0)”、“ワクチン(wakuchin)(WID=1)”}、{识别ID=1和“の(no)(WID=2)”、“大規模(daikibo)(WID=3)”、“接種(sessyu)(WID=4)”}、{识别ID=2和“予約(yoyaku)(WID=7)”、“が(ga)(WID=8)”、“今日(kyoo)(WID=9)”}、{识别ID=3和“センター(sentaa)(WID=5)”、“の(no)(WID=6)”}、{识别ID=4和“から(kara)(WID=10)”、“スタート(sutaato)(WID=11)”、“し(shi)(WID=12)”、“まし(mashi)(WID=13)”、“た(ta)(WID=14)”}。
接下来,生成部24a针对单词排列,生成各单词的特征向量。在此,作为在特征向量中利用的特征,例如可适当地利用各单词的从文章开头起的单词索引、字符长、词类、依存解析结果等。
接下来,生成部24a根据所生成的特征向量,通过学习完毕模型来计算是否在各单词之前进行分割的分割推测评分。在此,作为学习完毕模型,例如可适当地使用深度学习模型。作为深度学习模型,例如也可以使用N-gram方式的深度神经网络(DNN)模型。在该情况下,生成部24a也可以将各单词的前后N个单词的特征向量作为一个向量,将该向量输入到DNN模型,通过该DNN模型来计算各单词的分割推测评分。
接下来,生成部24a根据分割推测评分,决定要分割的单词的位置即单词分割位置SWI。例如,将分割推测评分最大的单词之前设为单词分割位置SWI。或者,将阈值以上的上位几个单词之前设为单词分割位置SWI。
具体而言,例如设为单词分割位置SWI=[3,9]。在该情况下,表示单词分割位置SWI是单词识别WID=3的单词“大規模”(daikibo)之前和单词识别WID=9的单词“今日”(kyoo)之前进行分割的位置。补充地讲,单词分割位置SWI=[3,9]中的SWI=[3]表示单词识别WID=2的单词“の”(no)与单词识别WID=3的单词“大規模接種センター”之间。同样地,SWI=[3,9]中的SWI=[9]表示单词识别WID=8的单词“が”(ga)与单词识别WID=9的单词“今日”(kyoo)之间。
接下来,在得到单词排列和单词分割位置SWI时,转移到生成字幕文本的步骤ST5。
(步骤ST5)
生成部24a根据所抽出的历史数据21a和所推测的结合位置及分割位置,生成字幕文本。另外,生成部24a制作各历史数据21a的更新所需的更新信息。例如,生成部24a通过从各单词的单词索引和更新信息的历史数据21a的单词开始位置抽出各单词出现的更新信息,并将输出字符数追加到相应的更新信息,从而制作更新信息。
例如,设为上述单词分割位置SWI=[3,9]。生成部24a根据包括识别ID=0~4的历史数据21a的显示候选排列,制作保持字幕文本“新型コロナウイルスワクチンの¥n大規模接種センターの予約が”(shingata-korona-uirusu-wakuchin-no(¥n)daikibo-sessyu-sentaa-no-yoyaku-ga)和各历史数据21a的识别ID及输出字符数的更新信息。此外,“¥n”表示分割位置处的换行。此外,音标内的(¥n)不发音,但与字幕文本的换行对应地进行了记载。更新信息例如包括{识别ID=0和已输出字符数13}、{识别ID=1和已输出字符数6}、{识别ID=2和已输出字符数4}、{识别ID=3和已输出字符数3}、{识别ID=4和已输出字符数0}。
(步骤ST6)
用户接口部25向用户提示所生成的字幕文本。例如,用户接口部25如图4所示,依次显示2行以内的字幕文本。另外,生成部24a将显示候选排列和连结文本的字符串长度进行初始化。
(步骤ST7)
历史更新部23根据所生成的字幕文本,更新保存于历史部21的历史数据21a。例如,历史更新部23根据历史数据21a的更新信息,更新历史数据排列。另外,历史更新部23根据更新信息,将显示候选的当前位置CSI更新为有未显示的历史数据21a的位置。
例如,关于显示候选的当前位置CSI,在步骤ST5中叙述的更新信息的情况下,在识别ID=3的历史数据21a中由于文本的字符串长度“5”和已输出字符数“3”不一致所以被更新。
(步骤ST9)
生成部24a判定是否有未提示的历史数据21a,在有未提示的历史数据21a的情况下,反复执行步骤ST3至ST9的处理。另一方面,判定的结果,在没有未提示的历史数据21a的情况下结束处理。
如上所述根据第1实施方式,取得部22逐次地取得声音辨识结果的文本。历史部21将该文本保存为历史数据21a。生成部24a根据保存的一个以上的历史数据21a来推测文本的分割位置以及结合位置。另外,生成部24a基于分割位置以及结合位置,根据该一个以上的历史数据21a而生成字幕文本。历史更新部23根据分割位置以及结合位置来更新历史数据21a。作为提示部的用户接口部25提示字幕文本。因此,在实时地根据声音辨识结果生成字幕时,能够降低用于使字幕变得易于阅读的修正的负担。
补充地讲,在活用了声音辨识技术的实时的字幕制作中,能够自动生成考虑了易读性的字幕文本,所以能够削减字幕制作者的修正成本。另外,在使用利用了提早确定技术的声音辨识结果的情况下,能够将更多的时间用于修正。
此外,说明针对这样的第1实施方式的比较例(1)~(3)。
(1)第1比较例是为了提高字幕的易读性而针对已开始写的文本推测换行位置的技术。在第1比较例的技术中,为了使演讲的字幕易于阅读,针对已开始写的演讲文本,利用作为深度学习技术的循环神经网络(RNN),推测在文本的各短语之前是否插入换行。然而,在第1比较例中,全部根据已开始写的演讲文本来推测换行位置,所以不适合实时地生成字幕。具体而言,第1比较例的技术不适合逐次地取得辨识结果并显示且人工地进行修正,所以难以应用于新闻节目等的实时的字幕制作。
(2)第2比较例是为了制作字幕而根据声音辨识结果的文本的字符数来调整声音数据的输出再生的技术。这样的第2比较例与所制作的字幕的易读性没有关系。因此,在第2比较例中,需要人工地修正为考虑了易读性的字幕,所以基于人工的修正成本大。
(3)第3比较例是关于声音辨识结果的修正而利用触摸面板等来指定修正部位并再次重现讲话的技术。然而,第3比较例并非是逐次地连续进行修正的结构,所以无法应用于实时的字幕制作。
这样,不论是哪个比较例(1)~(3),都不适合于易于阅读的字幕的实时生成,所以无法得到上述第1实施方式的效果。
另外,根据第1实施方式,生成部24a以直至结合文本而得到的连结文本的字符数成为阈值字符数(最大字符数)以上为止结合历史数据的文本的方式,推测结合位置。因此,除了上述效果以外,由于根据稍微超过阈值字符数的字符数的连结文本来推测分割位置,所以还能够期待生成与阈值字符数相近的字符数的字幕文本。即,能够在可显示的范围中生成大量的字幕文本,并且能够期待字幕显示的延迟时间的缩短。
另外,根据第1实施方式,生成部24a针对结合文本而得到的连结文本,执行词素解析以及依存解析中的某一方或者两方,并根据该执行结果而生成各单词的特征向量。另外,生成部24a使用特征向量来计算各单词的分割推测评分,并根据分割推测评分来推测分割位置。因此,除了上述效果以外,由于不需要人工而能够根据连结文本来推测分割位置,所以能够进一步降低用于使字幕变得易于阅读的修正的负担。
(第1实施方式的变形例)
第1实施方式也可以如以下的变形例那样实施。该变形例还能够同样地应用于以下的各实施方式。
即,在第1实施方式中使用了特征向量,但不限定于此。例如,也可以代替特征向量,而使用利用了单词嵌入方法的单词向量。在该情况下,生成部24a针对结合文本而得到的连结文本,执行词素解析以及依存解析中的某一方或者两方,并根据该执行结果而生成各单词的嵌入向量,使用嵌入向量来计算各单词的分割推测评分,根据分割推测评分来推测分割位置。这样也能够得到与第1实施方式同样的效果。
接下来,在第1实施方式中使用了N-gram方式的DNN模型,但不限定于此。例如,也可以代替N-gram方式的DNN模型,而使用循环神经网络(RNN)模型。在该情况下,使用将各单词的特征向量作为输入来计算各单词的分割推测评分的RNN模型即可。另外,RNN模型既可以是考虑关注单词的单侧的上下文的单向的结构,也可以是考虑两侧的上下文的双向的结构。具体而言,例如生成部24a也可以在计算各单词的分割推测评分的情况下,使用考虑该各单词之前的上下文、该各单词之后的上下文、或者该各单词的前后的上下文的LSTM模型,计算该分割推测评分。此外,LSTM是“Long Short-Term Memory”(长短期存储)的简称。
另外,在第1实施方式中,作为生成字幕文本的处理而设为单词单位的处理,但不限定于此。例如,也可以代替单词单位的处理,而将汇总单词得到的短语作为处理单位,使用按照短语单位进行汇总得到的特征向量。在该情况下,生成部24a针对结合文本而得到的连结文本,执行词素解析以及依存解析中的某一方或者两方,按短语单位来汇总该执行结果而生成各短语的特征向量,使用特征向量来计算各短语的分割推测评分,并根据分割推测评分来推测分割位置。这样也能够得到与第1实施方式同样的效果。
另外,在第1实施方式中,在生成字幕文本时未删除不需要的填充符或记号等词类、特定的字符串这样的不需要的单词,但不限定于此。即,也可以构成为在生成字幕文本时删除该不需要的单词。在该情况下,生成部24a在词素解析之后进行删除不需要的单词的处理,使该删除的单词的文本内的位置包含于更新数据,在历史更新时反映到各历史数据。
另外,在第1实施方式中,在生成字幕文本的处理中计算分割推测评分,并根据分割推测评分来推测分割位置,但不限定于此。例如,也可以构成为在生成字幕文本的处理中,事先决定分割位置,并在该事先决定的固定的分割位置进行分割。
另外,在第1实施方式中,生成部24a以直至结合文本而得到的连结文本的字符数成为阈值字符数(最大字符数)以上为止结合历史数据21a的文本的方式推测结合位置,但不限定于此。例如,生成部24a也可以针对结合文本而得到的连结文本,根据与该阈值字符数不同的固定字符数来推测分割位置。固定字符数例如是比最大字符数小的任意的字符数。
另外,在第1实施方式中,与在历史数据排列中未显示的历史数据的数量无关地推测分割位置,但不限定于此。即,也可以根据在历史数据排列中未显示的历史数据的数量,变更对分割位置进行推测的模型、处理。补充地讲,生成部24a例如在历史数据21a的数量增加的情况下,优选为尽早地提示给用户,所以根据计算量少的固定字符数来推测分割位置。即,生成部24a在保存于历史部21的历史数据21a中的、包括未作为字幕文本提示的文本的历史数据21a的数据数量是阈值以上的情况下,根据固定字符数来推测分割位置。另一方面,生成部24a在历史数据21a的数量成为一定以下的情况下,虽然计算量大,但使用具有高精度的分割推测模型来计算分割推测评分。即,生成部24a在保存于历史部21的历史数据21a中的、包括未作为字幕文本提示的文本的历史数据21a的数据数量小于阈值的情况下,通过计算分割推测评分来推测分割位置。
另外,在第1实施方式中,在推测分割位置时,也可以在比显示于1个画面的范围长且包括前后的范围中推测分割位置。具体而言,例如在向显示候选排列追加历史数据21a的判定中,直至连结的文本的字符数成为对显示于1个画面的最大字符数相加几个字符(+α字符)得到的字符数以上为止,使显示候选排列包含历史数据21a,与上述同样地推测分割位置。在该情况下,在生成字幕文本时,以使在开头的字符串中过去显示的部分和在末尾的字符串中超过最大字符数的部分不包含于字幕文本的方式推测分割位置即可。
另外,在第1实施方式中,作为向显示候选排列追加历史数据21a的判定,示出利用显示于1个画面的最大字符数进行判定的方法,但不限定于此。例如,也可以代替利用最大字符数进行判定的方法,而使用如下方法:将声音辨识结果的文本的取得日期时间与该文本关联起来保存到历史部21,将即使从取得日期时间起经过一定时间也不会显示的历史数据追加到显示候选排列。在该情况下,历史数据21a包括声音辨识结果的文本和该文本的取得日期时间。生成部24a以结合即使从该取得日期时间起经过一定时间也不会显示的历史数据21a的文本的方式,推测结合位置。一定时间例如是10秒。但是,不限于此,作为一定时间,例如可适当使用1秒至10秒的范围内的任意的时间。
<第2实施方式>
第2实施方式相比于第1实施方式,附加有如下结构:用于根据用户针对显示于用户接口部25的字幕文本部分的动作(操作),校正字幕文本的分割位置和结合位置。此外,也可以将动作称为操作。
图5是示出第2实施方式所涉及的字幕生成装置的框图,对于与图1同样的构成要素附加同一符号,省略其详细的说明,在此主要说明不同的部分。以下的各实施方式也同样地省略重复的说明。
图5所示的字幕生成装置20相比于图1所示的结构,字幕处理部24还包括重新生成部24b,在重新生成部24b与用户接口部25之间还具备修正期望接收部26。
与此相伴地,用户接口部25除了上述结构以外,还检测用户针对所提示的字幕文本的一部分进行的动作,生成动作数据。该用户接口部25是检测部的一个例子。
修正期望接收部26根据该动作数据,判定字幕文本的修正对象范围、和针对字幕文本的分割及结合中的任意方的期望类型。在此,修正期望接收部26例如在接收到作为修正期望的动作数据时,执行该判定。该修正期望接收部26是判定部的一个例子。
重新生成部24b根据修正对象范围、期望类型以及历史数据21a,重新推测字幕文本的分割位置或者结合位置,并根据重新推测结果来重新生成字幕文本。
使用图6的流程图以及图7的示意图,说明如以上那样构成的字幕生成装置的动作。此外,本实施方式的动作被执行为上述步骤ST7与步骤ST9之间的步骤ST8。步骤ST8被执行为以下的步骤ST8-1~ST8-6。
(步骤ST8-1)
用户接口部25在用户针对在步骤ST6中显示的字幕文本的一部分进行了动作的情况下,检测动作,并生成动作数据。具体而言,设为针对显示中的字幕文本进行了光标的移动、点击、拖动、轻拂(flick)、或者滑动等的动作。在该情况下,用户接口部25生成进行了动作的画面内的开始位置、结束位置等的信息作为动作数据。
(步骤ST8-2)
用户接口部25向修正期望接收部26通知动作数据。修正期望接收部26接收该动作数据。
(步骤ST8-3)
接下来,修正期望接收部26根据动作数据,判定字幕文本的修正对象范围、以及是面向字幕文本的分割及结合中的哪一方的期望类型。
(步骤ST8-4)
重新生成部24b根据字幕文本的修正对象范围、和期望类型以及历史数据21a,重新推测字幕文本的分割位置或者结合位置,并根据重新推测结果来重新生成字幕文本。
(步骤ST8-5)
用户接口部25对用户提示重新生成的字幕文本。
(步骤ST8-6)
历史更新部23根据重新生成的字幕文本,更新保存于历史部21的历史数据21a。由此,字幕生成装置20结束由步骤ST8-1~ST8-6构成的步骤ST8,转移到上述步骤ST9。
接下来,关于以上那样的动作,参考图7的示意图来说明针对字幕文本的分割以及结合各自的期望类型的具体例。在以下的说明中,将用户接口部25设为触摸面板来安装,但不限定于此。这在以下的各实施方式中也是同样的。另外,示出分割为时刻t1~t3的例子,示出结合为时刻t4~t6的例子。
(时刻t1)
在时刻t1,用户接口部25在画面上显示2行的字幕文本“新型コロナウイルスワクチンの¥n大規模接種センターの予約が今日から”(shingata-korona-uirusu-wakuchin-no(¥n)daikibo-sessyu-sentaa-no-yoyaku-ga-kyoo-kara)。此时,设为针对显示中的字幕文本的一部分“今日から”(kyoo-kara),用户进行了在用手指触摸的状态下从右上向左下拖动的斜拖动作UA1。
用户接口部25检测该斜拖动作UA1,取得斜拖动作UA1的开始位置和结束位置,生成包括该开始位置和结束位置的动作数据(步骤ST8-1)。然后,用户接口部25向修正期望接收部26通知动作数据。
修正期望接收部26接收动作数据(步骤ST8-2),根据动作数据的开始位置和结束位置来判定是否为斜拖动作(步骤ST8-3)。具体而言,在动作数据的开始位置处于右上、且结束位置处于左下的情况下判定为斜拖动作。
在判定为斜拖动作的情况下,修正期望接收部26根据字幕文本的显示位置、以及动作数据的开始位置和结束位置的周边,决定字幕文本的修正对象范围。例如,修正期望接收部26根据动作数据的开始位置和结束位置来计算中心位置,求出与该中心位置最接近的字幕文本的字符位置,将该字符位置的前后几个字符设为修正对象范围。另外,修正期望接收部26在判定为斜拖动作的情况下,将期望类型设为分割类型,将期望类型以及修正对象范围发送给重新生成部24b。
重新生成部24b在期望类型是分割类型的情况下,根据所取得的修正对象范围以及历史数据21a,在修正对象范围中推测合理的分割位置,重新生成字幕文本(步骤ST8-4)。
具体而言,重新生成部24b针对所取得的修正对象范围“の予約が今日から”(no-yoyaku-ga-kyoo-kara),与上述同样地计算各单词的分割推测评分,在修正对象范围中,将在除去当前分割的位置之后分割推测评分最高的位置推测为分割位置。在这个例子中,字幕文本“今日から”(kyoo-kara)之前被推测为分割位置。此外,重新生成部24b在分割后的行数(3行)超过在1个画面中可显示的行数(2行)的情况下,从该显示中的字幕文本删除超过的部分(第3行的“今日から”(kyoo-kara)),并且制作历史数据21a的更新信息。另外,虽然并非是这个例子,但重新生成部24b在分割后的字符数超过在1行中可显示的字符数的情况下,从该1行删除超过的部分,并且制作历史数据21a的更新信息。例如,在显示中的2行的字幕文本之中,在第1行的字幕文本的一部分被分割而转移到第2行时,有时第2行的字幕文本超过在1行中可显示的字符数。在这样的情况下,能够从该第2行的字幕文本删除超过的部分。
另外,重新生成部24b基于所推测的分割位置(“今日から”(kyoo-kara)之前),根据与显示中的字幕文本“新型コロナウイルスワクチンの¥n大規模接種センターの予約が今日から”(shingata-korona-uirusu-wakuchin-no(¥n)daikibo-sessyu-sentaa-no-yoyaku-ga-kyoo-kara)对应的历史数据21a而重新生成字幕文本。在该情况下,重新生成部24b重新生成字幕文本“新型コロナウイルスワクチンの¥n大規模接種センターの予約が”(shingata-korona-uirusu-wakuchin-no(¥n)daikibo-sessyu-sentaa-no-yoyaku-ga)。
(时刻t2)
然后,用户接口部25对用户提示重新生成的字幕文本“新型コロナウイルスワクチンの¥n大規模接種センターの予約が”(shingata-korona-uirusu-wakuchin-no(¥n)daikibo-sessyu-sentaa-no-yoyaku-ga)(步骤ST8-5)。
历史更新部23根据重新生成的字幕文本,更新保存于历史部21的历史数据21a(步骤ST8-6)。例如,历史更新部23根据历史数据21a的更新信息,更新历史数据排列。
(时刻t3)
在时刻t2显示的字幕文本的显示结束后,用户接口部25对用户提示新生成的字幕文本“今日からスタートしました”(kyoo-kara-sutaato-shimashita)。在时刻t3所示的字幕文本中,在开头包括伴随时刻t1的斜拖动作UA1而被删除的字幕文本“今日から”(kyoo-kara)。此外,在假设将没有斜拖动作UA1的情况设为时刻t3p时,在时刻t3p会提示不包括该开头的字幕文本“今日から”(kyoo-kara)的字幕文本“スタートしました”(sutaato-shimashita)。
以上是在时刻t1~t3分割字幕文本的例子。接下来,说明在时刻t4~t6结合字幕文本的例子。
(时刻t4)
在时刻t4,用户接口部25在画面上显示2行的字幕文本“東京会場となる千代田区の¥n大手町合同庁舎では接種に当たる”(tookyoo-kaijyoo-tonaru-chiyodaku-no(¥n)ootemachi-goodoochoosya-dewa-sessyu-ni-ataru)。此时,设为在显示中的字幕文本的一部分“···千代田区の”(chiyodaku-no)的右侧的空白区域中,用户进行了在用手指触摸的状态下从右向左滑动的滑动动作UA2。
用户接口部25检测该滑动动作UA2,取得滑动动作UA2的开始位置和结束位置,生成包括该开始位置和结束位置的动作数据(步骤ST8-1)。然后,用户接口部25向修正期望接收部26通知动作数据。
修正期望接收部26接收动作数据(步骤ST8-2),根据动作数据的开始位置和结束位置来判定是否为滑动动作(步骤ST8-3)。具体而言,在动作数据的开始位置的高度和结束位置的高度大致相同、且开始位置比结束位置靠右的情况下,判定为滑动动作。
在判定为滑动动作的情况下,修正期望接收部26根据字幕文本的显示位置和动作数据的开始位置,决定字幕文本的修正对象范围。例如,修正期望接收部26将与动作数据的开始位置最接近的字幕文本的字符位置的前后几个字符设为修正对象范围。另外,修正期望接收部26在判定为滑动动作的情况下,将期望类型设为结合类型,并与修正对象范围一起通知给重新生成部24b。
重新生成部24b在期望类型是结合类型的情况下,根据所取得的修正对象范围和历史数据21a来推测结合位置和结合后的分割位置,重新生成字幕文本(步骤ST8-4)。
具体而言,重新生成部24b将与所取得的修正对象范围“場となる千代田区の大手町合同庁舎では”(jyoo-tonaru-chiyodaku-no-ootemachi-goodoochoosya-dewa)对应的历史数据21a中包含的当前的分割位置重新推测为结合位置。另外,重新生成部24b针对修正对象范围“場となる千代田区の大手町合同庁舎では”(jyoo-tonaru-chiyodaku-no-ootemachi-goodoochoosya-dewa),与上述同样地计算各单词的分割推测评分,在修正对象范围中将在除去当前的分割位置之后分割推测评分最高的位置重新推测为结合后的分割位置。在这个例子中,字幕文本“では”(dewa)之前被重新推测为分割位置。此外,虽然并非是这个例子,但在分割后的字符数超过在1行中可显示的字符数的情况下,从该1行删除超过的部分,并且制作历史数据21a的更新信息。例如,设为显示中的2行的字幕文本之中的第1行的字幕文本的字符数接近在1行中可显示的字符数。在该情况下,在根据针对第1行的字幕文本的结合类型的期望来计算修正对象范围内的各单词的分割推测评分时,在推测的分割位置处有时第1行的字幕文本的字符数超过在1行中可显示的字符数。在这样的情况下,能够将超过的部分从该第1行的字幕文本中删除而移动到第2行的字幕文本。
然后,重新生成部24b基于重新推测的结合位置,根据与当前显示中的字幕文本“東京会場となる千代田区の¥n大手町合同庁舎では接種に当たる”(tookyoo-kaijyoo-tonaru-chiyodaku-no(¥n)ootemachi-goodoochoosya-dewa-sessyu-ni-ataru)对应的历史数据21a来结合字幕文本。
接下来,重新生成部24b基于重新推测的分割位置(“では”(dewa)之前),根据与结合后的字幕文本“東京会場となる千代田区の大手町合同庁舎では接種に当たる”(tookyoo-kaijyoo-tonaru-chiyodaku-no-ootemachi-goodoochoosya-dewa-sessyu-ni-ataru)对应的历史数据21a来重新生成字幕文本。在该情况下,重新生成部24b重新生成字幕文本“東京会場となる千代田区の大手町合同庁舎¥nでは接種に当たる”(tookyoo-kaijyoo-tonaru-chiyodaku-no-ootemachi-goodoochoosya(¥n)dewa-sessyu-ni-ataru)。
(时刻t5)
然后,用户接口部25对用户提示重新生成的字幕文本“東京会場となる千代田区の大手町合同庁舎¥nでは接種に当たる”(tookyoo-kaijyoo-tonaru-chiyodaku-no-ootemachi-goodoochoosya(¥n)dewa-sessyu-ni-ataru)(步骤ST8-5)。
历史更新部23根据重新生成的字幕文本,更新保存于历史部21的历史数据21a(步骤ST8-6)。例如,历史更新部23根据历史数据21a的更新信息,更新历史数据排列。
(时刻t6)
在时刻t5所显示的字幕文本的显示结束后,用户接口部25对用户提示新生成的字幕文本“自衛隊のいかんや看護官らが¥n編成完結式を行ないました”(jieitai-no-ikan-ya-kangokan-ra-ga(¥n)hensei-kanketsushiki-o-okonaimashita:自卫队的医疗官、护士们进行了编组完成仪式)。
以上是在时刻t4~t6结合字幕文本的例子。这样,能够根据用户的动作来分割或者结合字幕文本。
如上所述根据第2实施方式,作为检测部的用户接口部25检测用户针对所提示的字幕文本的一部分进行的动作,生成动作数据。作为判定部的修正期望接收部26根据该动作数据来判定字幕文本的修正对象范围、以及针对字幕文本的分割以及结合中的任意方的期望类型。重新生成部24b根据修正对象范围、期望类型以及历史数据来重新推测字幕文本的分割位置或者结合位置,并根据重新推测结果来重新生成字幕文本。因此,除了第1实施方式的效果以外,还能够根据用户的动作而容易地修正所提示的字幕文本的分割位置、结合位置。
(第2实施方式的变形例)
此外,在第2实施方式中,将从右上向左下拖动的操作检测为斜拖动作UA1,但不限定于此。例如,也可以将从左上向右下拖动的操作检测为斜拖动作UA1。另外,例如也可以将从上向下笔直地拖动的操作检测为斜拖动作UA1。即,如果是表示分割位置的动作,则能够将任意的动作设为斜拖动作UA1来使用。另外,如果是表示分割位置的动作,则也可以代替斜拖动作这样的用词,而使用其他用词。
另外,在第2实施方式中,将从右向左滑动的操作检测为滑动动作UA2,但不限定于此。例如,也可以将从右向左拨弄的操作(轻拂)检测为滑动动作UA2。另外,例如也可以将使向左右展开的2根手指在触摸的状态下收窄的操作(捏合)检测为滑动动作UA2。即,如果是表示结合位置的动作,则能够将任意的动作作为滑动动作UA2来使用。另外,如果是表示结合位置的动作,则也可以代替滑动动作这样的用词,而使用其他用词。
(第3实施方式)
第3实施方式相比于第2实施方式,附加有如下结构:用于根据用户针对显示于用户接口部25的字幕文本部分的动作,提示字幕文本的修正候选。但是,第3实施方式不限于此,也可以对第1实施方式附加该结构。
图8是示出第3实施方式所涉及的字幕生成装置的框图。
图8所示的字幕生成装置20相比于图5所示的结构,字幕处理部24还具备修正候选生成部24c。
与此相伴地,用户接口部25与上述同样地检测用户针对所提示的字幕文本的一部分进行的动作,生成动作数据。该用户接口部25是检测部的一个例子。
修正期望接收部26根据该动作数据,决定字幕文本的修正对象范围。在此,修正期望接收部26例如在接收到作为修正期望的动作数据时,执行该决定。该修正期望接收部26是决定部的一个例子。
修正候选生成部24c根据修正对象范围以及历史数据21a而生成该修正对象范围的修正候选,推测包括该修正候选的字幕文本的分割位置。
使用图9的流程图以及图10的示意图,说明如以上那样构成的字幕生成装置的动作。此外,本实施方式的动作作为上述步骤ST7与步骤ST9之间的步骤ST8A而被执行。步骤ST8A作为以下的步骤ST8A-1~ST8A-7、ST8-3~ST8-6而被执行。
(步骤ST8A-1~ST8-2)
步骤ST8A-1~ST8A-2与上述步骤ST8-1~ST8-2同样地执行。即,用户接口部25检测用户针对所显示的字幕文本的一部分进行的动作,生成动作数据。修正期望接收部26从用户接口部25接收该动作数据。
(步骤ST8A-2-1)
修正期望接收部26根据动作数据,判定该动作数据是否是提示修正候选的指示。在否的情况下,执行在第2实施方式中叙述的步骤ST8-3~ST8-6而结束步骤ST8A,转移到步骤ST9。另一方面,在提示修正候选的指示的情况下,转移到步骤ST8A-3。此外,该步骤ST8A-2-1在无法执行第2实施方式的处理的情况下被省略。
(步骤ST8A-3)
接下来,修正期望接收部26根据动作数据来决定字幕文本的修正对象范围,对修正候选生成部24c通知该修正对象范围。
(步骤ST8A-4)
修正候选生成部24c根据字幕文本的修正对象范围和历史数据21a,生成修正对象范围的修正候选。
(步骤ST8A-5)
修正候选生成部24c针对所生成的每个修正候选,推测选择了修正候选时的字幕文本的分割位置和结合位置,根据分割位置和结合位置而生成候选字幕文本。然后,修正候选生成部24c将修正候选以及候选字幕文本发送给用户接口部25。此时,发送1个以上的修正候选以及与各修正候选对应的候选字幕文本。
(步骤ST8A-6)
用户接口部25对用户提示所生成的1个以上的修正候选。
(步骤ST8A-7)
用户接口部25在根据用户的动作而选择了修正候选中的任意候选的情况下,对用户提示与该选择的修正候选对应的候选字幕文本。然后,历史更新部23根据所提示的候选字幕文本,更新保存于历史部21的历史数据21a。由此,字幕生成装置20结束步骤ST8A,转移到上述步骤ST9。
接下来,关于如以上那样的动作,参考图10的示意图来说明针对字幕文本的修正候选的提示和修正的具体例。在以下的说明中,示出在时刻t6~t8修正字幕文本的例子。
(时刻t6)
在时刻t6,用户接口部25在画面上显示2行的字幕文本“自衛隊のいかんや看護官らが¥n編成完結式を行ないました”(jieitai-no-ikan-ya-kangokan-ra-ga(¥n)hensei-kanketsushiki-o-okonaimashita)。此时,设为用户针对显示中的字幕文本的一部分“の”(no)进行了用手指按下后松开的指示动作UA3。
用户接口部25检测该指示动作UA3,取得指示动作UA3在画面内的指示位置,生成包括该指示位置的动作数据(步骤ST8A-1)。然后,用户接口部25对修正期望接收部26通知动作数据。
修正期望接收部26接收动作数据(步骤ST8A-2),根据动作数据的指示位置来判定是否是提示修正候选的指示(指示动作)(步骤ST8A-2-1)。具体而言,动作数据的指示位置是一个点,所以判定为指示动作。换言之,动作数据的开始位置和结束位置相同,所以判定为指示动作。
在判定为指示动作的情况下,修正期望接收部26根据动作数据来决定字幕文本的修正对象范围,对修正候选生成部24c通知该修正对象范围。
例如,修正期望接收部26在对“の”(no)进行指示的指示位置的周边,推测错误率最大的区间,将该区间的字符串“のいかんや”(no-ikan-ya)设为修正对象范围(步骤ST8A-3)。但是,不限于此,修正期望接收部26也可以将指示位置的最近处显示的字幕文本的字符位置的前后几个字符设为修正对象范围。另外,修正期望接收部26在判定为指示动作的情况下,将修正对象范围“のいかんや”(no-ikan-ya)发送给修正候选生成部24c。
接下来,修正候选生成部24c从历史部21取得与显示中的字幕文本对应的历史数据21a。另外,修正候选生成部24c从显示中的字幕文本屏蔽成为修正对象范围的部分,之后使用事先学习模型BERT来推测(生成)修正对象范围的候选字符串(修正候选)(步骤ST8A-4)。在此,BERT是“Bidirectional Encoder Representations from Transformer”(来自transformer的双向编码器表示)的简称。在这个例子中,在修正候选生成部24c中,作为修正对象范围“のいかんや”(no-ikan-ya)的修正候选,推测“の医官や”(no-ikan-ya)(置换为日文“医官”(ikan:医疗官))、“の”(no)(删除“いかんや”)、“の、いかんや”(no,ikan-ya)(“、”的插入)。此外,日语的“、”与英语的“,”(comma,逗号)同样地不发音,在1个句子的内部表示分隔符。另外,修正候选生成部24c推测包括3个修正候选的字幕文本“自衛隊の医官や看護官らが編成完結式を行ないました”(jieitai-no-ikan-ya-kangokan-ra-ga-hensei-kanketsushiki-o-okonaim ashita:自卫队的医疗官、护士们进行了编组完成仪式)、“自衛隊の看護官らが編成完結式を行ないました”(jieitai-no-kangokan-ra-ga-hensei-kanketsushiki-o-okonaimashita:自卫队的护士们进行了编组完成仪式)、“自衛隊の、いかんや看護官らが編成完結式を行ないました”(jieitai-no,ikan-ya-kangokan-ra-ga-hensei-kanketsushiki-o-okonaimashita:自卫队的、医疗官、护士们进行了编组完成仪式)的分割位置。在该情况下,分割位置是“編成完結式”(hensei-kanketsushiki:编组完成仪式)之前,与修正前相同。
接下来,修正候选生成部24c根据3个修正候选以及分割位置,生成第1至第3候选字幕文本(步骤ST8A-5)。第1候选字幕文本是“自衛隊の医官や看護官らが¥n編成完結式を行ないました”(jieitai-no-ikan-ya-kangokan-ra-ga(¥n)hensei-kanketsushiki-o-okonaimashita)。第2候选字幕文本是“自衛隊の看護官らが¥n編成完結式を行ないました”(jieitai-no-kangokan-ra-ga(¥n)hensei-kanketsushiki-o-okonaimashita)。第3候选字幕文本是“自衛隊の、いかんや看護官らが¥n編成完結式を行ないました”(jieitai-no,ikan-ya-kangokan-ra-ga(¥n)hensei-kanketsushiki-o-okonaimashita)。另外,修正候选生成部24c将修正候选以及候选字幕文本发送给用户接口部25。
(时刻t7)
用户接口部25对用户提示所生成的3个修正候选(步骤ST8A-6)。
(时刻t8)
用户接口部25在根据用户的动作来选择修正候选“の医官や”(no-ikan-ya)(置换为日文“医官”(ikan:医疗官))时,对用户提示与该修正候选对应的候选字幕文本。在这个例子中,显示第1候选字幕文本“自衛隊の医官や看護官らが¥n編成完結式を行ないました”(jieitai-no-ikan-ya-kangokan-ra-ga(¥n)hensei-kanketsushiki-o-okonaimashita)。
以上是在时刻t6~t8修正字幕文本的例子。这样,能够根据用户的动作来修正字幕文本。
如上所述根据第3实施方式,作为检测部的用户接口部25检测用户针对所提示的字幕文本的一部分进行的动作,生成动作数据。作为决定部的修正期望接收部26根据该动作数据,决定字幕文本的修正对象范围。修正候选生成部根据修正对象范围以及历史数据21a而生成该修正对象范围的修正候选,推测包含该修正候选的字幕文本的分割位置。因此,除了第1实施方式的效果以外,还能够根据用户的动作而容易地生成所提示的字幕文本的修正候选。另外,通过根据用户的动作来选择修正候选,能够容易地修正字幕文本。
<第4实施方式>
图11是例示第4实施方式所涉及的字幕生成装置的硬件结构的框图。第4实施方式是第1至第3实施方式的具体例,成为通过计算机来实现字幕生成装置20的形态。
在字幕生成装置20中,作为硬件而具备CPU(Central Processing Unit,中央处理单元)201、RAM(Random Access Memory,随机存取存储器)202、程序存储器203、辅助存储装置204以及输入输出接口205。CPU201经由总线而与RAM202、程序存储器203、辅助存储装置204以及输入输出接口205进行通信。即,本实施方式的字幕生成装置20通过这样的硬件结构的计算机来实现。
CPU201是通用处理器的一个例子。CPU201将RAM202用作工作存储器。RAM202包括SDRAM(Synchronous Dynamic Random Access Memory,同步动态随机存取存储器)等易失性存储器。RAM202也可以用作存储历史数据的历史部21。程序存储器203存储用于实现与各实施方式对应的各部分的字幕生成程序。该字幕生成程序例如也可以是用于使计算机作为上述的历史部21、取得部22、历史更新部23及字幕处理部24、用户接口部25这样的各单元发挥功能的程序。另外,作为程序存储器203,例如使用ROM(Read-Only Memory,只读存储器)、辅助存储装置204的一部分、或者其组合。辅助存储装置204以非临时的方式存储数据。辅助存储装置204包括HDD(hard disc drive,硬盘驱动器)或者SSD(Solid State Drive,固态驱动器)等非易失性存储器。此外,RAM202、程序存储器203以及辅助存储装置204各自不限于内置于计算机的结构,也可以是外置于计算机的结构。
输入输出接口205是用于与其他设备连接的接口。输入输出接口205例如被用于与键盘、鼠标以及显示器的连接。
存储于程序存储器203的字幕生成程序包括计算机可执行命令。字幕生成程序(计算机可执行命令)在被作为处理电路的CPU201执行时,使CPU201执行预定的处理。例如,字幕生成程序在被CPU201执行时,使CPU201执行关于图1、图5以及图8的各部分进行了说明的一连串的处理。例如,包含于字幕生成程序的计算机可执行命令在被CPU201执行时,使CPU201执行字幕生成方法。字幕生成方法也可以包括与上述的历史部21、取得部22、历史更新部23、字幕处理部24、生成部24a、用户接口部25的各功能对应的各步骤。在此,字幕处理部24也可以除了生成部24a以外,还包括重新生成部24b以及修正候选生成部24c。另外,字幕生成方法也可以还包括与修正期望接收部26的各功能对应的各步骤。另外,字幕生成方法也可以适当地包括图3、图6、图9所示的各步骤。
字幕生成程序也可以以存储于计算机可读取的存储介质的状态而被提供给作为计算机的字幕生成装置20。在该情况下,例如字幕生成装置20还具备从存储介质读出数据的驱动器(未图示),从存储介质取得字幕生成程序。作为存储介质,例如可适当地使用磁盘、光盘(CD-ROM、CD-R、CD-RW、DVD-RAM、DVD-ROM、DVD-R等)、光磁盘(MO等)、半导体存储器等。存储介质也可以称为非临时性的计算机可读取的存储介质(non-transitory computerreadable storage medium)。另外,也可以将字幕生成程序储存到通信网络上的服务器,字幕生成装置20使用输入输出接口205从服务器下载字幕生成程序。
执行字幕生成程序的处理电路不限于CPU201等通用硬件处理器,也可以使用ASIC(Application Specific Integrated Circuit,专用集成电路)等专用硬件处理器。处理电路(处理部)这样的用词包括至少1个通用硬件处理器、至少1个专用硬件处理器、或者至少1个通用硬件处理器和至少1个专用硬件处理器的组合。在图11所示的例子中,CPU201、RAM202以及程序存储器203与处理电路相当。
根据以上叙述的至少一个实施方式,在实时地根据声音辨识结果生成字幕时,能够降低用于使字幕变得易于阅读的修正的负担。
此外,虽然说明了本发明的几个实施方式,但这些实施方式是作为例子来提示的,并非意图限定发明的范围。这些实施方式能够以其他各种方式来实施,能够在不脱离发明的要旨的范围中进行各种省略、置换、变更。这些实施方式及其变形包含于发明的范围、要旨,并且同样地包含于权利要求书记载的发明及其均等的范围。
此外,能够将上述实施方式总结为以下的技术方案。
技术方案1
一种字幕生成装置,具备:
取得部,逐次地取得声音辨识结果的文本;
历史部,将所述文本保存为历史数据;
生成部,根据所述保存的一个以上的所述历史数据来推测所述文本的分割位置以及结合位置,并基于所述分割位置以及所述结合位置,根据一个以上的所述历史数据来生成字幕文本;
历史更新部,根据所述分割位置以及所述结合位置来更新所述历史数据;以及
提示部,提示所述字幕文本。
技术方案2
根据上述技术方案1,其中,所述生成部以直至结合所述文本而得到的连结文本的字符数成为阈值字符数以上为止结合所述历史数据的文本的方式,推测所述结合位置。
技术方案3
根据上述技术方案1,其中,
所述历史数据包括所述文本和该文本的取得日期时间,
所述生成部以结合即使从所述取得日期时间起经过一定时间也不会显示的历史数据的文本的方式,推测所述结合位置。
技术方案4
根据上述技术方案2或者3,其中,所述生成部针对结合所述文本而得到的连结文本,执行词素解析以及依存解析中的某一方或者两方,根据该执行的结果来生成各单词的特征向量,使用所述特征向量来计算各单词的分割推测评分,根据所述分割推测评分来推测所述分割位置。
技术方案5
根据上述技术方案2或者3,其中,所述生成部针对结合所述文本而得到的连结文本,执行词素解析以及依存解析中的某一方或者两方,按短语单位来汇总该执行的结果而生成各短语的特征向量,使用所述特征向量来计算各短语的分割推测评分,根据所述分割推测评分来推测分割位置。
技术方案6
根据上述技术方案2或者3,其中,所述生成部针对结合所述文本而得到的连结文本,执行词素解析以及依存解析中的某一方或者两方,根据该执行的结果来生成各单词的嵌入向量,使用所述嵌入向量来计算各单词的分割推测评分,根据所述分割推测评分来推测所述分割位置。
技术方案7
根据上述技术方案4或者6,其中,所述生成部在计算各单词的所述分割推测评分的情况下,使用考虑该各单词之前的上下文、该各单词之后的上下文或者该各单词的前后的上下文的LSTM模型来计算该分割推测评分。
技术方案8
根据上述技术方案4至7中的任意一个,其中,所述生成部在保存于所述历史部的历史数据之中的包括未作为所述字幕文本提示的文本的历史数据的数据数量小于阈值的情况下,通过计算所述分割推测评分来推测所述分割位置。
技术方案9
根据上述技术方案2,其中,所述生成部针对结合所述文本而得到的连结文本,根据与所述阈值字符数不同的固定字符数来推测所述分割位置。
技术方案10
根据上述技术方案9,其中,所述生成部在保存于所述历史部的历史数据之中的包括未作为所述字幕文本提示的文本的历史数据的数据数量是阈值以上的情况下,根据所述固定字符数来推测所述分割位置。
技术方案11
根据上述技术方案1至10中的任意一个,其中,
字幕生成装置还具备:
检测部,检测用户针对所提示的所述字幕文本的一部分进行的动作,生成动作数据;
判定部,根据所述动作数据,判定所述字幕文本的修正对象范围、和针对所述字幕文本的分割以及结合中的任意方的期望类型;以及
重新生成部,根据所述修正对象范围、所述期望类型以及所述历史数据来重新推测所述字幕文本的分割位置或者结合位置,并根据重新推测结果来重新生成字幕文本。
技术方案12
根据上述技术方案1至10中的任意一个,其中,
字幕生成装置还具备:
用户接口部,将用户针对所提示的所述字幕文本的一部分进行的动作生成为动作数据;
决定部,根据所述动作数据来决定所述字幕文本的修正对象范围;以及
修正候选生成部,根据所述修正对象范围以及所述历史数据来生成该修正对象范围的修正候选,推测包含该修正候选的字幕文本的分割位置。
技术方案13
一种字幕生成方法,具备:
逐次地取得声音辨识结果的文本;
将所述文本保存为历史数据;
根据所述保存的一个以上的所述历史数据来推测所述文本的分割位置以及结合位置,并基于所述分割位置以及所述结合位置,根据一个以上的所述历史数据来生成字幕文本;
根据所述分割位置以及所述结合位置来更新所述历史数据;以及
提示所述字幕文本。
技术方案14
一种存储介质,存储有字幕生成程序,该字幕生成程序用于使计算机作为如下单元发挥功能:
逐次地取得声音辨识结果的文本的单元;
将所述文本保存为历史数据的单元;
根据所述保存的一个以上的所述历史数据来推测所述文本的分割位置以及结合位置,并基于所述分割位置以及所述结合位置,根据一个以上的所述历史数据来生成字幕文本的单元;
根据所述分割位置以及所述结合位置来更新所述历史数据的单元;
提示所述字幕文本的单元。