一种基于flex与bison语法分析的多输出编译方法及系统
文献发布时间:2023-06-29 06:30:04
技术领域
本发明涉及工业自动控制的技术领域,尤其涉及一种基于flex与bison语法分析的多输出编译方法及系统。
背景技术
工业控制环境下常使用IEC61131-3标准来作为PLC、DCS编程系统的标准。用此标准编写的高级编程语言ST语言在硬件中运行需要将其转为机器能够识别的机器码才能运行。通常这一转换过程我们称之为编译。而转换的工具称之为编译器。编译器在对高级编程语言进行转译的时候,需要读取用户编写的文本文件,识别文本文件当中用户编写高级语言的关键字和标识符,识别这些元素之间的关系,将其组合识别为语法。当前多数情况下,开发公司会自行开发词法分析器和语法分析器来做语法分析或直接使用国外既存的编译器。
Flex和Bison是用来生成词法分析器和语法分析器源程序的工具,他们所生成的程序能够处理结构化的输入。其中,词法分析就是将输入分隔为一个个有意义的词块,称之为记号(Token)。语法分析器是确定这些记号是如何关联的。
在工业控制系统前期设计阶段,设计师需要对工业控制程序进行调试校验,很多时候,编译的程序需要运行在硬件上,调配硬件资源流程复杂时间长。本发明提出一种基于Flex和Bison语法分析的多语言编译器。一般情况下,一个编译器只负责将一种语言转译为另一种语言。本发明利用Flex和Bison工具快速建立起ST语言的语法树,然后利用语法转译配置文件将语法树同时转为PLC、DSC系统运行在硬件上的机器码与运行在个人计算机(PC)上的高级语言代码(本文中使用的是C++语言)。对应的PLC、DSC机器码作为硬件输出的调试程序源,个人计算机上的高级语言代码,通过配合相应的仿真系统可以在个人计算机上实现快速调试,达到一次输入,多种应用的效果。
发明内容
针对上述问题,本发明的目的在于提供一种基于flex与bison语法分析的多输出编译方法及系统,利用flex和bison工具,只需要编写ST语言语法描述文件,即可生成词法分析器与语法分析器。再利用其处理流程生成语法树,通过读取语法转译配置文件,将输入的语法树,转译为多种语言。
本发明的上述发明目的是通过以下技术方案得以实现的:
一种基于flex与bison语法分析的多输出编译方法,包括以下步骤:
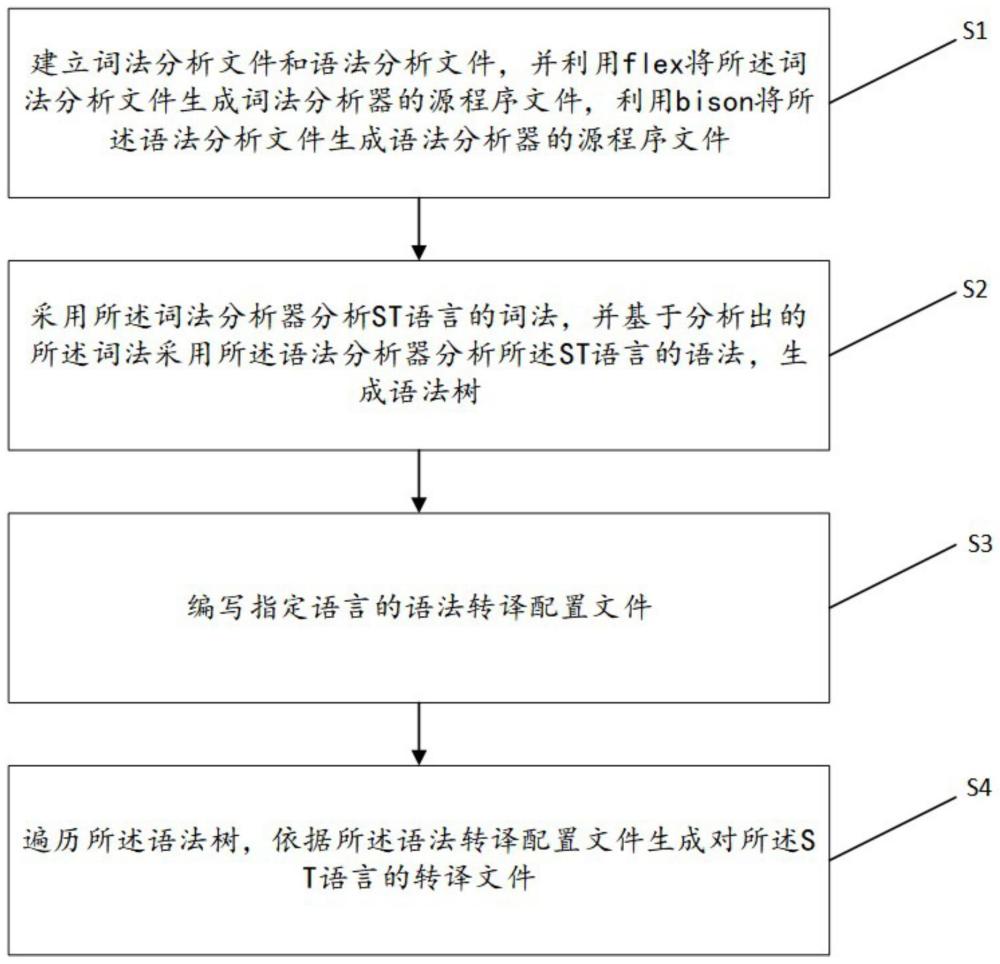
S1:建立词法分析文件和语法分析文件,并利用flex将所述词法分析文件生成词法分析器的源程序文件,利用bison将所述语法分析文件生成语法分析器的源程序文件;
S2:采用所述词法分析器分析ST语言的词法,并基于分析出的所述词法采用所述语法分析器分析所述ST语言的语法,生成语法树;
S3:编写指定语言的语法转译配置文件;
S4:遍历所述语法树,依据所述语法转译配置文件生成对所述ST语言的转译文件。
进一步地,在步骤S1中,所述词法分析文件,具体为:
根据IEC61131-3标准,依次定义所述ST语言中的包括关键字、分界符、数据类型在内的可识别字符串为记号值。
进一步地,在步骤S1中,所述语法分析文件,具体为:
定义接收由所述词法分析器返回的所述记号值,依次接收所述ST语言中的所述关键字、所述分界符、所述数据类型;
依次按照定义标识符表达式关系、语句语法描述、基于所述标识符表达式关系和所述语法语句描述依赖语句的嵌套层级生成结构化的数据的步骤定义所述语法分析文件;
其中,在基于所述标识符表达式关系和所述语法语句描述依赖语句的嵌套层级生成结构化的数据中,将标识符定义为一个类,所述标识符的内容作为对象,将不同的表达式定义为不同的类,所述标识符作为成员,将不同的所述语句语法定义为一个类,所述表达式与所述标识符作为成员,根据所述语句语法的嵌套层级使用指针指向目标保存。
进一步地,在步骤S2中,还包括:
对所述语法树进行包括声明与定义、标识符类型、控制流、唯一性在内语法错误的检查,具体为:
所述声明与定义检查,具体包括:
建立所述语法树的符号表,用于存放字符串形式的所述标识符,以及所述标识符对应的数据类型;
逐层遍历所述语法树,若遇到所述标识符的定义语句,将所述标识符存入所述符号表再向下层遍历,下层遍历结束后,在所述符号表中删除所述标识符;
若遇到包含所述标识符的非定义语句,判断所述标识符是否在所述符号表中,当不在所述符号表中时,则所述标识符未定义;
所述标识符类型检查,具体包括:
计算所述语法树的每一个叶子节点的返回类型,依据IEC61131-3的类型标准判断所述表达式中所述标识符的类型与所述符号表中保存的类型是否兼容;
所述控制流检查,具体包括:
检查退出语句EXIT或跳出语句BREAK的叶子节点以上是否允许退出或跳出;
所述唯一性检查,具体包括:
检查多分支语句CASE中的整形变量是否重复。
进一步地,在步骤S3中,编写指定语言的所述语法转译配置文件,具体为:
获取所述语句语法描述中的语法类型标识;
将所述语法类型标识下方的语句依据所述指定语言的编码要求转换为所述指定语言的编码格式的语句语法,生成所述指定语言的所述语法转译配置文件。
进一步地,在步骤S4中,遍历所述语法树,依据所述语法转译配置文件生成对所述ST语言的所述转译文件,具体为:
遍历所述语法树,每遍历一个叶子节点,若当前叶子节点的语法类型在所述语法转译配置文件中存在配置信息时,则取出所述配置信息,将子树的转译结果按照所述配置信息中的配置生成转译文本;
所述语法树遍历完成后,所述转译文本组成所述转译文件。
一种用于执行如上述的基于flex与bison语法分析的多输出编译方法的基于flex与bison语法分析的多输出编译系统,包括:
分析器建立模块,用于建立词法分析文件和语法分析文件,并利用flex将所述词法分析文件生成词法分析器的源程序文件,利用bison将所述语法分析文件生成语法分析器的源程序文件;
语法树生成模块,用于采用所述词法分析器分析ST语言的词法,并基于分析出的所述词法采用所述语法分析器分析所述ST语言的语法,生成语法树;
配置文件编写模块,用于编写指定语言的语法转译配置文件;
转译文件生成模块,用于遍历所述语法树,依据所述语法转译配置文件生成对所述ST语言的转译文件。
一种计算机设备,包括存储器和一个或多个处理器,所述存储器中存储有计算机代码,所述计算机代码被所述一个或多个处理器执行时,使得所述一个或多个处理器执行如上述的方法。
一种计算机可读存储介质,所述计算机可读存储介质存储有计算机代码,当所述计算机代码被执行时,如上述的方法被执行。
与现有技术相比,本发明包括以下有益效果是:
通过提供一种基于flex与bison语法分析的多输出编译方法,包括以下步骤:S1:建立词法分析文件和语法分析文件,并利用flex将所述词法分析文件生成词法分析器的源程序文件,利用bison将所述语法分析文件生成语法分析器的源程序文件;S2:采用所述词法分析器分析ST语言的词法,并基于分析出的所述词法采用所述语法分析器分析所述ST语言的语法,生成语法树;S3:编写指定语言的语法转译配置文件;S4:遍历所述语法树,依据所述语法转译配置文件生成对所述ST语言的转译文件。采用上述技术方案,可以在不用编写复杂的逻辑情况下,即可生成语法树。同时通过对不同的语言编写指定的语法转译配置文件,可以将语法树转换为多种不同的语言,利用多种不同的转译语言可以实现在不同场景下的应用。
附图说明
图1为本发明基于flex与bison语法分析的多输出编译方法的整体流程图;
图2为本发明语句语法描述编写示意图;
图3为本发明生成的语法树示意图;
图4为本发明转译为C++语言的语法转译配置文件示意图;
图5为本发明转译为C++语言的转译文件示意图;
图6为本发明转译为Python语言的语法转译配置文件示意图;
图7为本发明转译为Python语言的转译文件示意图;
图8为本发明基于flex与bison语法分析的多输出编译系统的整体结构图。
具体实施方式
为使本申请实施例的目的、技术方案和优点更加清楚,下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本申请一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。
本技术领域技术人员可以理解,除非特意声明,这里使用的单数形式“一”、“一个”、“所述”和“该”也可包括复数形式。应该进一步理解的是,本发明的说明书中使用的措辞“包括”是指存在所述特征、整数、步骤、操作、元件和/或组件,但是并不排除存在或添加一个或多个其他特征、整数、步骤、操作、元件、组件和/或它们的组。
本发明涉及的术语解释:
(1)IEC61131-3标准:一种工业化标准;
(2)ST语言:使用IEC61131-3标准开发的计算机语言;
(3)Flex与Bison:用来生成进行词法分析器和语法分析器的工具;
(4)语法分析:分析语句的组成结构;
(5)编译器:将一种计算机语言翻译为另一种计算机语言的工具;
(6)语法树:是编译原理中的概念,其作用是将抽象的语法结构用树状形式表现出来,书上的每个非叶子节点都是抽象语法中的一个运算符,叶子节点代表抽象语法树的具体对象;
(7)叶子:每一个节点都是叶子节点;
(8)标识符:标识符包含了关键字、分界符、用户定义字符串等;
(9)类:高级编程语言中对一种数据结构的定义;
(10)对象:计算机中类生成的实际存储内容(是一段内存空间);
(11)成员:类中的数据元素;
(12)指针:指向计算机内容空间的地址标识;
(13)语法:语句应该以什么样的格式排布词汇;
(14)语义:语句的含义。
本发明提供了一种基于flex与bison语法分析的多输出编译方法及系统,利用flex和bison工具,只需要编写ST语言语法描述文件,即可生成词法分析器与语法分析器。再利用其处理流程生成语法树,通过读取语法树配置文件,将输入的语法树,转译为多种语言。
通过本发明的技术方案可以解决如下问题:
(1)工业ST语言的词法分析与语法分析;
(2)能够快速对ST语言语法进行扩展;
(3)能够将ST语言通过配置文件转为多个不同的对应语言文本;
本发明的计算方案具体分为两个部分,第一个部分先利用flex和bison工具生成语法树,并对语法树进行检验。第二个部分是通过读取指定语言的语法转译配置文件,将语法树转译为与语法转译配置文件相对应的任意语言。具体通过以下实施例进行说明:
第一实施例
如图1所示,本实施例提供了一种基于flex与bison语法分析的多输出编译方法,包括以下步骤:
S1:建立词法分析文件和语法分析文件,并利用flex将所述词法分析文件生成词法分析器的源程序文件,利用bison将所述语法分析文件生成语法分析器的源程序文件。
步骤S1具体包括以下具体步骤:
S11:编写词法分析文件。词法分析文件中说明了flex在读取ST语言对应的文件时应该将文件中的字符串识别为什么样的记号。根据IEC61131-3标准,依次定义所述ST语言中的包括关键字(IF、THEN、ELSE、END_IF、FOR等等)、分界符(+、-、*、/、#等等)、数据类型(BOOL、SINT、INT等)在内的可识别字符串为记号值。利用flex提供的操作,将这些记号向下层返回结果标识值。
S12:编写语法分析文件。语法分析文件中说明了bison在读取到记号时应该按照什么样的规则将记号组合起来,形成什么关系。
S13:编写语法分析文件需要先定义接收由所述词法分析器返回的所述记号值,依次接收所述ST语言中的所述关键字、所述分界符、所述数据类型;
S14:编写语法分析文件接着定义标识符表达式关系,例如:“A+B”,数据A与B跟分界符B的关系是一组运算关系,那么这段描述即是一个(加法)表达式。再例如:“A>B”,数据A与B跟分界符是一组比较关系,那么这段描述即是一个(大于)表达式。以此类推直到编写完所有的表达式。
S15:编写语法分析文件接着定义语句语法描述。例如:“C:=A+B;”,其中“A+B”在步骤4中识别为一个表达式,将这个表达式的值传递给C,那么这段描述即是一个(赋值)语句。再例如:“IF A>B THEN C:=A+B;END_IF;”,A>B作为了一个条件,当条件满足时执行赋值语句(C:=A+B;),那么这段描述即是(条件)语句。
一个语句语法描述形如图2(以IF条件语句为例):左上方的“if_state ment”是当前语法的标识,该语句有三种表现形式,分别在语法标识下面三行书写并以“|”分隔。第一个描述是由“IF关键字标识符条件表达式THEN关键字标识符语句列表END_IF关键字”组成的,当该语法与输入文件匹配后,“{}”大括号内是对该语法的处理(“$$代表当前叶子”,“$2”代表以空格分割的第2个元素即or_expr),示例中是构造语法树的过程,创建了叶子节点,并把数据存储进去了。对应例子“IF A>B THEN C:=A+B;END_IF;”中:“IF关键字标识符”<=对应=>“IF”;“条件表达式”<=对应=>“A>B”;“THEN关键字标识符”<=对应=>“THEN”;“语句列表”<=对应=>“C:=A+B;”;“END_IF关键字标识符”<=对应=>“END_IF”。
S16:在基于所述标识符表达式关系和所述语法语句描述依赖语句的嵌套层级生成结构化的数据中,将标识符定义为一个类,所述标识符的内容作为对象,将不同的表达式定义为不同的类,所述标识符作为成员,将不同的所述语句语法定义为一个类,所述表达式与所述标识符作为成员,根据所述语句语法的嵌套层级使用指针指向目标保存,具体的:
Bison在读取语法分析文件后生成的语法分析器在通过步骤S13、步骤S14与步骤S15的处理后,已经能够将一个文本文件识别为若干个语句(由子语句、表达式、标识符组成)。接着需要将其转化为结构化的数据方便后期处理。利用Bison提供的操作,将标识符定义为一个类(标识符内容作为其对象),不同的表达式定义为不同的类(标识符作为其成员),不同的语句定义为一个类(表达式与标识符作为其成员)。根据语句的嵌套层级使用指针指向目标保存。例如图3是步骤S15中条件语句的语法树(自顶向下看,箭头代表指针,框代表对象):该条件语句语法具有一条比较表达式和当前条件所具有的处理语句列表标明了当达到某个条件后执行某些功能。所以顶部的IF语句类具有两个成员,一个比较表达式成员跟一个语句列表成员。左边子树比较表达式中有三个成员:A标识符、B标识符、‘>’标识符代表了“A>B”的条件。右侧子树是一个处理语句列表,可以包含多条语句,当前步骤S15示例只有一条处理语句即赋值语句;赋值语句是将一个加法表达式的值赋给C标识符,而这个加法表达式就是“A+B”。所以右子树就代表了“C:=A+B;”。
S17:使用Flex对步骤S11中的词法分析文件进行生成,直接生成词法分析器的源程序文件。
S18:使用Bison对步骤S12(经历过步骤S13、步骤S14、步骤S15、步骤S16补充)中的语法文件进行生成,直接生成语法分析器源程序文件。此时通过上述步骤S17、步骤S18生成出来的源程序文件通过编译后能够生成ST语言词法分析器跟语法分析器。
S2:采用所述词法分析器分析ST语言的词法,并基于分析出的所述词法采用所述语法分析器分析所述ST语言的语法,生成语法树。
具体的,语法分析器处理ST语言的文本文件时会通过词法分析器分析词法,再自身分析语法,最后生成语法树(如图3)。
进一步地,在语法分析器分析过程中存在的语法错误会直接报出,还需要对语法树进行包括声明与定义、标识符类型、控制流、唯一性在内语法错误的检查,并具体包括:
(1)所述声明与定义检查,具体包括:
建立所述语法树的空的符号表,符号表是一个表格形式的存储结构,用于存放字符串形式的所述标识符,以及所述标识符对应的数据类型;从语法树由上至下逐层遍历所述语法树,若遇到所述标识符的定义语句,将所述标识符存入所述符号表再向下层遍历,下层遍历结束后,在所述符号表中删除所述标识符;若遇到包含所述标识符的非定义语句,判断所述标识符是否在所述符号表中,当不在所述符号表中时,则所述标识符未定义。
(2)所述标识符类型检查,具体包括:
与(1)相同,利用符号表的手段,计算所述语法树的每一个叶子节点的返回类型,依据IEC61131-3的类型标准判断所述表达式中所述标识符的类型与所述符号表中保存的类型是否兼容。
(3)所述控制流检查,具体包括:
检查退出语句EXIT或跳出语句BREAK的叶子节点以上是否允许退出或跳出。
(4)所述唯一性检查,具体包括:
检查多分支语句CASE中的整形变量是否重复。
通过以上四个步骤的检查,若存在错误则反馈给用户界面,若没有错误则进行下一步。
S3:编写指定语言的语法转译配置文件。
具体的,获取所述语句语法描述中的语法类型标识;将所述语法类型标识下方的语句依据所述指定语言的编码要求转换为所述指定语言的编码格式的语句语法,生成所述指定语言的所述语法转译配置文件。
例如图4是ST语言IF条件语句转译为C++语言的语法转译配置文件。结合图2与图4:语法转译配置文件先以语法描述文件中的“if_statement”标识语法,共有三种表现形式,分别在语法标识下面分三行书写并以“|”分隔,ST语言的第一个描述形式“IF关键字标识符条件表达式THEN关键字标识符语句列表END_IF关键字”对应到C++语言中是“if关键字标识符‘(’左括号标识符条件表达式条件表达式‘)’右括号标识符‘{’左大括号标识符语句列表‘}’右大括号标识符”。
S4:遍历所述语法树,依据所述语法转译配置文件生成对所述ST语言的转译文件。
具体的,读取语法转译配置文件,将每一条语法的配置按照语法类型读取保存下来。后续遍历所述语法树,每遍历一个叶子节点,若当前叶子节点的语法类型在所述语法转译配置文件中存在配置信息时,则取出所述配置信息,将子树的转译结果按照所述配置信息中的配置生成转译文本;所述语法树遍历完成后,所述转译文本组成所述转译文件。
例如,如图3中的根节点“IF语句”节点,先遍历左子树获取左子树的转译结果“A>B”,再遍历右子树获取右子树的转译结果“C:=A+B;\n”。在图4的语法配置文件中存在此语句的语法转译配置,则取出转译形式为“if($2)\n{\n$4\n}\n”;其中“$2”在生成语法树时已存储类型为比较表达式即左子树,将“$2”替换为左子树的转译结果,此时转译结果为:“if(A>B)\n{\n$4\n}\n”;其中“$4”在生成语法树时已存储类型为处理语句列表即右子树,将“$4”替换为右子树的专辑结果,次数转译结果为:“if(A>B)\n{\n C:=A+B;\n\n}\n”;此时转译结束,生成的转译文件如图5所示。
进一步地,若需要转换为新的语言,只需要设置匹配的语法转译配置文件,按照相同的步骤S3和S4执行即可。如图6所示为转译为Python语言的语法转译配置文件,如图7所示,生成的Python的转译文件。
第二实施例
如图8所示,本实施例提供一种用于执行如第一实施例中的基于flex与bison语法分析的多输出编译方法的基于flex与bison语法分析的多输出编译系统,包括:
分析器建立模块1,用于建立词法分析文件和语法分析文件,并利用flex将所述词法分析文件生成词法分析器的源程序文件,利用bison将所述语法分析文件生成语法分析器的源程序文件;
语法树生成模块2,用于采用所述词法分析器分析ST语言的词法,并基于分析出的所述词法采用所述语法分析器分析所述ST语言的语法,生成语法树;
配置文件编写模块3,用于编写指定语言的语法转译配置文件;
转译文件生成模块4,用于遍历所述语法树,依据所述语法转译配置文件生成对所述ST语言的转译文件。
一种计算机可读存储介质,计算机可读存储介质存储有计算机代码,当计算机代码被执行时,如上述方法被执行。本领域普通技术人员可以理解上述实施例的各种方法中的全部或部分步骤是可以通过程序来指令相关的硬件来完成,该程序可以存储于一计算机可读存储介质中,存储介质可以包括:只读存储器(ROM,Read Only Memory)、随机存取存储器(RAM,Random Access Memory)、磁盘或光盘等。
以上所述仅是本发明的优选实施方式,本发明的保护范围并不仅局限于上述实施例,凡属于本发明思路下的技术方案均属于本发明的保护范围。应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理前提下的若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
以上所述实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
应当说明的是,上述实施例均可根据需要自由组合。以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。