一种汉语发展性阅读障碍预测系统及其预测方法
文献发布时间:2023-06-19 09:55:50
技术领域
本发明涉及阅读障碍识别技术领域,具体涉及一种汉语发展性阅读障碍预测系统及其预测方法。
背景技术
现有的汉语发展性阅读障碍的预测技术是以儿童的行为测验成绩为基础,使用传统的Logistic回归模型进行模拟,得到最终的预测评估模型(例如:Shu,McBride-Chang,Wu,&Liu,2006;Li,Shu,McBride-Chang,Liu,&Xue,2009;董琼,李虹,伍新春,潘敬儿,张玉平,阮氏芳,2012;Tong,Tong,&King Yiu,2018)。但是,当前针对汉语儿童发展性阅读障碍的预测评估模型存在以下缺陷:
1)Logistic回归方法模拟数据时需要满足数据线性、独立、正态分布以及方差齐性(Lyu&Zhang,2019),但是阅读障碍儿童属于特殊群体,并且在测试成绩上很难满足上述要求,这会导致获得的预测评估模型的预测结果不准确或预测偏差较大(Lyu&Zhang,2019)。
2)发展性阅读障碍是由多种因素相互影响、共同作用的结果(Morris et al.,1998),其影响因素之间的复杂关系也很难通过Logistic回归这样简单的数学模式精确表征,由Logistic回归方法得到的预测评估模型总体预测准确率并不高(<82%)。
3)现有的预测评估模型在构建时模拟数据的样本量过少(n<150),很难有效地反映客观规律,造成模型预测准确率偏低。
4)现有的预测评估模型仅作为实证研究的一种技术手段,并没有被制作为可以大规模临床、科研应用的检测系统。
发明内容
本发明针对现有汉语发展性阅读障碍的预测评估模型数据拟合方式、训练样本较小以及尚未应用于实际等不足,提供一种汉语发展性阅读障碍预测系统及其预测方法,通过使用经遗传算法优化的误差反向传递神经网络技术训练大量已有诊断数据,最后以训练、验证完毕的神经网络为核心进行图形用户界面程序设计,并封装为可在Windows 64位系统中安装和运行,能够对汉语发展性阅读障碍进行预测的评估系统。
本发明采用如下技术方案:
一方面,本发明提供了一种汉语发展性阅读障碍预测系统,其特征在于,所述系统包括计算机和内嵌于所述计算机中运行的经训练完毕的神经网络模型,所述神经网络模型包括数据信号传输的输入层神经元模块、隐含层神经元模块和输出层神经元模块,所述输入层神经元模块、隐含层神经元模块和输出层神经元模块间数据信号与各个神经元的权重值和偏置加权求和并通过模块间的传递函数由左到右依次传播;所述输入层神经元模块和输出层神经元模块分别与所述计算机主界面上所设置的输入模块和预测模块进行数据传输,所述输入层神经元模块中包括用于输入被试的人口统计学信息、参加语音意识测验的类型和阅读相关认知测验信息的若干个神经元节点,所述隐含层神经元模块中包含若干个隐含层神经元节点,所述输出层神经元模块用于输出是否患有发展性阅读障碍的预测结果。
所述输入层神经元模块中包括14个神经元节点,其依次为被试的性别、年级、年龄、参加语音意识测验的类型以及阅读流畅性、阅读准确性、语素意识、语音意识、图片快速命名、数字快速命名、判断假字正确率、判断非字正确率、判断假字反应时和判断非字反应时成绩;所述隐含层神经元模块中包含12个隐含层神经元节点。
所述输入模块包括个体预测模块和团体预测模块,所述个体预测模块用于录入被试的人口统计学信息、参加语音意识测验的类型和阅读相关认知测验信息,并对输入的个体数据进行汉语发展性阅读障碍预测;所述团体预测模块用于导入团体数据,并对导入的团体数据进行汉语发展性阅读障碍预测。
所述神经网络模型中采用trainlm函数作为训练函数,所述隐含层神经元模块采用的传递函数为S型tangent函数,所述输出层神经元模块采用的传递函数为S型logarithmic函数。
进一步地,所述神经网络模型为经遗传算法对其初始权重值和偏置进行优化的神经网络模型,优化的神经网络模型经训练后,将所得最优解的神经网络模型进行保存,用于对被试进行阅读障碍预测。
另一方面,本发明还提供了一种基于汉语发展性阅读障碍预测系统的预测方法,
步骤1、收集儿童的人口学和测试数据;
步骤2、对性别、年级、被试参加语音意识测试的类型进行重新编码,被试年龄以及各项阅读相关技能变量用原始数据直接编码;
步骤3、将需测试的被试数据经计算机主界面上的输入模块输入;
步骤4、系统将调用原始数据集与输入数据进行合并,并归一化;
步骤5、系统以归一化后的输入数据作为输入层神经元模块的输入层,经调用“sim”函数并使用训练完毕的神经网络模型进行汉语发展性阅读障碍预测计算;
步骤6、预测结果直接由计算机主界面上显示。
所述步骤5中神经网络模型的构建方法是:
步骤5.1、收集发展性阅读障碍儿童和正常儿童的原始筛查数据,训练前将原始数据随机分为训练集和测试集两个集合;
步骤5.2、使用trainlm函数作为训练函数,设置期望误差为1×10
步骤5.3、将所得原始数据归一化;
步骤5.4、利用公式
步骤5.5、使用遗传算法对构建的神经网络模型进行优化,将最优的初始权重值和偏置赋值给构建的神经网络模型,使用原始数据中的训练集数据对所构建的神经网络模型进行训练并保存最终的神经网络模型;
步骤5.6、通过调用sim函数并使用训练完毕的神经网络模型对原始数据中的测试集进行测试,得到神经网络模型的预测结果。
所构建的神经网络模型为包含14个神经元节点的输入层神经元模块、包含12个隐含层神经元节点的隐含层神经元模块和包含有1个输出层神经元节点的输出层神经元模块。
其中步骤5.5中遗传算法对构建的神经网络模型进行优化的具体方法是:
步骤5.5.1、使用ones函数将所构建的14-12-1型神经网络模型的初始权重值和偏置作为“基因”编码为“染色体”,设置种群规模为50,使用initializega函数使“染色体”形成初始种群;
步骤5.5.2、将所建初始种群中的每个构成“染色体”的权重值和偏置放入神经网络模型中进行训练和测试,与实际结果相减后得到测试误差;
步骤5.5.3、以测试结果与实际结果的误差平方和的倒数作为适应度(fitness)指标,将步骤5.5.2所得测试误差与期望误差进行比较,若所得测试误差不满足期望误差,将选择适应度高的“染色体”进行复制(设置选择算子selection operator为0.09),通过对“染色体”上“基因”进行交叉(设置交叉算子crossover operator为2)和变异(设置变异算子mutation operator为[2 100 3])得到新的种群,并重复训练和测试的步骤;
步骤5.5.4、若所得测试误差达到期望误差时,将“染色体”解码为最优权重值和偏置并赋给神经网络模型。
其中原始数据中所包含的训练集样本与测试集样本之比为7:3,比如原始数据中的训练集中可以包含280个样本,测试集中包含119个样本。
本发明技术方案,具有如下优点:
A.本发明使用机器学习领域能够拟合任意复杂、模糊数据关系的误差反向传递神经网络技术,利用遗传算法优化神经网络模型参数,最后以经过大量数据样本训练与验证后获得的神经网络模型作为核心结合实际应用要求制作成图形用户界面,能够高效、准确预测汉语发展性阅读障碍。
B.本发明很好地解决了先前汉语儿童发展性阅读障碍预测模型存在的缺馅,并将总体预测准确性提高至94.1%,其中对阅读障碍儿童的预测准确性为91.4%,对正常儿童的预测准确性为96.2%。
附图说明
为了更清楚地说明本发明具体实施方式,下面将对具体实施方式中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施方式,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
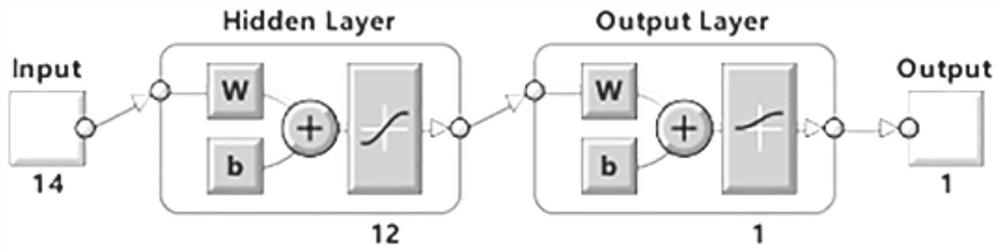
图1本发明所提供的预测评估系统中神经网络模型结构原理图;
图2是本发明所提供的预测评估系统主界面;
图3是本发明所提供的预测评估系统的个体预测界面;
图4是本发明所提供的预测评估系统的团体预测界面;
图5是本发明所提供的遗传算法优化神经网络模型的过程框图;
图6是本发明分别利用神经网络模型与经遗传算法优化后的神经网络模型预测结果对比图示;
图7是本发明所提供的预测方法流程框图。
具体实施方式
下面将结合附图对本发明的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
在本发明的描述中,需要说明的是,术语“中心”、“上”、“下”、“左”、“右”、“竖直”、“水平”、“内”、“外”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。此外,术语“第一”、“第二”、“第三”仅用于描述目的,而不能理解为指示或暗示相对重要性。
在本发明的描述中,需要说明的是,除非另有明确的规定和限定,术语“安装”、“相连”、“连接”应做广义理解,例如,可以是固定连接,也可以是可拆卸连接,或一体地连接;可以是机械连接,也可以是电性连接;可以是直接相连,也可以通过中间媒介间接相连,可以是两个元件内部的连通。对于本领域的普通技术人员而言,可以具体情况理解上述术语在本发明中的具体含义。
如图1所示,本发明提供了一种汉语发展性阅读障碍预测系统,包括计算机和内嵌于所述计算机中运行的经训练完毕的神经网络模型,神经网络模型包括输入层神经元模块、隐含层神经元模块和输出层神经元模块,输入层神经元模块、隐含层神经元模块和输出层神经元模块间数据信号与各个神经元的权重值和偏置加权求和并通过模块间的传递函数由左到右依次传播;输入层神经元模块和输出层神经元模块分别与计算机主界面上所设置的输入模块和预测模块进行数据传输,输入层神经元模块中包括用于输入被试的人口统计学信息、参加语音意识测验的类型和阅读相关认知测验信息的若干个神经元节点,隐含层神经元模块中包含若干个隐含层神经元节点,输出层神经元模块用于输出是否患有发展性阅读障碍的预测结果。
神经网络模型中的模块与模块之间神经元的连接是完全的,同一模块的神经元之间不存在相互连接。训练时模块与模块之间存在两种传递信号,一种是工作信号,从输入层神经网络模型向前传递,直到在输出层神经元模块产生实际输出的信号;另一种是误差信号,即实际输出值与期望值之间的差值,由输出层神经元模块开始逐层向后传递至输入层神经元模块。如果输出层神经元模块不能得到期望的输出,误差信号沿原来的路径返回,逐步调整网络各层的权重值和偏置,直至到达输入层神经元模块,再重复先前的正向传递。
这里的输入层神经元模块中优选包括14个神经元节点,其依次为被试的性别、年级、年龄、参加语音意识测验的类型以及阅读流畅性、阅读准确性、语素意识、语音意识、图片快速命名、数字快速命名、判断假字正确率、判断非字正确率、判断假字反应时和判断非字反应时成绩,通过测验获得每个被试的原始数据;隐含层神经元模块中包含12个隐含层神经元节点。其中的神经网络模型中优选采用trainlm函数作为训练函数,隐含层神经元模块优选采用的传递函数为S型tangent函数,输出层神经元模块优选采用的传递函数为S型logarithmic函数。
原始数据中的测量方式如下:
A.阅读流畅性测验:测验共包含160个中高频汉字,要求儿童在一分钟之内又快又准地读出这些汉字。记录儿童读对汉字的个数作为最终成绩。
B.阅读准确性测验:该测验共包含172个字频由高到低排列的汉字,要求儿童将认识的汉字准确地读出来(不限时间)。记录儿童读对的汉字个数作为最终成绩。
C.语素意识测验:该测验共包含20题,要求儿童判断一对双字词中相同汉字的意思是否相同。例如“信封”和“信任”的“信”字是否意思相同。记录儿童答对的题目总数作为最终成绩。
D.语音意识测验:
测验共有两种形式
①使用oddball范式要求儿童判断按顺序呈现的三个汉字的字音中哪个在声母、韵母或声调上不同于另外两个的字音(各10题)。
②采用oddball范式,共30题。测验将声母、韵母和声调辨别拆分成3个子测验,每个子测验各10题。两种测验均计算儿童答对的题目总数作为最终成绩。
E.快速自动命名测验:
测验包含两个子测验
①图片快速命名:材料为花、书、狗、手、鞋五幅图片,随机排列成六行五列,要求儿童按照顺序又快又准地读出图片的名称并记录用时。
②数字快速命名:将刺激材料改为2、4、6、7、9这几个数字,过程与快速图片命名相同。每个子测验均进行两次,取平均值作为最终成绩。
F.正字法意识测验:该测验为真、假、非字判断任务。刺激材料共包括40个真字、20个假字(比如:扌同)与20个非字(比如:者纟)。程序使用E-prime2.0呈现,首先呈现500毫秒注视点,随后呈现刺激,要求儿童判断看到的刺激是否是真实存在的汉字。记录儿童对假字和非字的反应时及正确率。
本系统中包括两种类型的预测,分别在计算机主界面上呈现个体预测模块和团体预测模块。个体预测模块用于录入被试的人口统计学信息、参加语音意识测验的类型和阅读相关认知测验信息,并对输入的个体数据进行汉语发展性阅读障碍预测;团体预测模块用于导入团体数据,并对导入的团体数据进行汉语发展性阅读障碍预测。
系统进一步地采用遗传算法对所构建的神经网络模型的初始权重值和偏置进行优化,对优化后的神经网络模型进行训练后,将所得最优解的神经网络模型进行保存,用于对被试进行阅读障碍预测。
本发明针对现有汉语发展性阅读障碍的预测评估模型数据拟合方式、训练样本较小以及尚未应用于实际等不足,使用经遗传算法优化的误差反向传递神经网络技术训练大量已有诊断数据,最后以训练、验证完毕的神经网络为核心进行图形用户界面程序设计,并封装为可在Windows 64位系统中安装和运行,能够对汉语发展性阅读障碍进行预测的评估系统。
本预测评估系统的核心神经网络模型的结构为14-12-1,如图1所示。包含14个输入层神经元(14个变量分别为儿童的性别、年级、年龄、参加语音意识测验的类型以及阅读流畅性、阅读准确性、语素意识、语音意识、图片快速命名、数字快速命名、判断假字正确率、判断非字正确率、判断假字反应时和判断非字反应时成绩),12个隐含层神经元和1个输出层神经元(是否为发展性阅读障碍)。
本预测评估系统的主界面主要包含两个模块:“个体预测”和“团体预测”,如图2所示。
“个体预测”模块用于对单个被试进行预测,如图3所示。在该模块中,主试需要输入被试的人口统计学信息(包括:姓名、性别、年级、年龄)、参加语音意识测验的类型和阅读相关认知测验信息(包括:阅读流畅性、阅读准确性、语素意识、语音意识、图片快速命名、数字快速命名、判断假字正确率、判断非字正确率、判断假字反应时和判断非字反应时)。点击“预测”按钮后,系统将调用原始数据集与输入的数据进行合并,并归一化。接着,系统以归一化后的输入数据作为输入层,调用“sim”函数并使用训练完毕的神经网络模型进行计算。最后,系统根据所得结果弹出对话框提示被试是否患有发展性阅读障碍。
“团体预测”模块用于对两个或两个以上被试同时预测,如图4所示。在该模块中,主试首先需要根据软件界面上的“数据录入示例”在Excel中录入所有被试的数据信息。接着,选择需要预测的数据文件并指定预测结果文件的输出位置。点击“预测”按钮后,系统将调用原始数据集与输入的数据集进行合并,并归一化。接着,系统以归一化后的输入数据集作为输入层,调用“sim”函数并使用训练完毕的神经网络模型进行计算。最后,系统根据所得结果判断团体中的每个个体是否患有发展性阅读障碍,并将结果输出到指定位置。
如图7所示,具体的汉语发展性阅读障碍预测方法如下:
1)数据收集:收集儿童的人口学和测验数据,导出性别、年级、年龄、参加语音意识测验的类型以及阅读流畅性、阅读准确性、语素意识、语音意识、图片快速命名、数字快速命名、判断假字正确率、判断非字正确率、判断假字反应时和判断非字反应时成绩共计14项数据。
2)数据编码:对性别、年级、被试参加语音意识测试的类型进行重新编码。性别被重新编码为“1=男”,“2=女”。年级被重新编码为“3=3年级”,“4=4年级”,“5=5年级”,“6=6年级”。被试参加语音意识测试的类型被重新编码为“1=参加第一种测验”,“2=参加第二种测验”。被试年龄以及各项阅读相关技能变量用原始数据直接编码。
3)将需测试的被试数据经计算机主界面上的输入模块输入;
其中基础参数的设置如下:
A.设置输入层神经元节点数14(包括被试性别、年级、年龄、语音意识测验类型以及10个阅读相关技能成绩);设置隐含层层数为1,具有12个神经元节点;设置输出层神经元节点数1(是否患有阅读障碍)。
B.隐含层传递函数设置为S型tangent函数,输出层传递函数设置为S型logarithmic函数。
4)系统将调用原始数据集与输入数据进行合并,并归一化;
5)系统以归一化后的输入数据作为输入层神经元模块的输入层,调用“sim”函数并使用训练完毕的神经网络模型进行汉语发展性阅读障碍预测计算;
6)预测结果直接有计算机主界面上显示。
其中步骤5中的神经网络模型的构建方法如下:
A)收集发展性阅读障碍儿童和正常儿童的原始筛查数据,训练前将原始数据随机分为训练集和测试集两个集合,比如,训练集包含280个样本(70%),测试集包含119个样本(30%);
B)使用trainlm函数作为训练函数,设置期望误差为1×10
C)原始数据归一化。
D)确定隐含层神经元节点的个数:根据经验公式
E)遗传算法优化:由于基础神经网络模型易陷入局部最优解,对构建完成的结构为14-12-1的神经网络模型的初始权重值和偏置使用遗传算法进行优化(如图5所示),将最优的初始权重值和偏置赋值给构建的神经网络模型,使用原始数据中的训练集数据对所构建的神经网络模型进行训练并保存最终的神经网络模型。
遗传算法优化神经网络模型的步骤:
①使用ones函数将所构建的14-12-1型神经网络模型的初始权重值和偏置作为“基因”编码为“染色体”,设置种群规模为50,使用initializega函数使“染色体”形成初始种群;
②将所建初始种群中的每个构成“染色体”的权重值和偏置放入神经网络模型中进行训练和测试,与实际结果相减后得到测试误差;
③以测试结果与实际结果的误差平方和的倒数作为适应度(fitness)指标,将步骤②所得测试误差与期望误差进行比较,若所得测试误差不满足期望误差,将选择适应度高的“染色体”进行复制(设置选择算子selection operator为0.09),通过对“染色体”上“基因”进行交叉(设置交叉算子crossover operator为2)和变异(设置变异算子mutationoperator为[2 100 3])得到新的种群,并重复训练和测试的步骤;其中的复制、交叉和变异过程通过调用GOAT工具箱实现的。
④若所得测试误差达到期望误差时,将“染色体”解码为最优权重值和偏置并赋给神经网络模型。
F)通过调用sim函数并使用训练完毕的神经网络模型对原始数据中的测试集进行测试,得到神经网络模型的预测结果。
如图2所示,汉语发展性阅读障碍预测系统在计算机中构建:
A.计算机主界面放置三个按钮,“个体预测”按钮指向“个体预测”,“团体预测”按钮指向“团体预测”界面,“退出系统”按钮作用为退出程序。
B.“个体预测”界面放置20个输入文本框/按钮用于录入被试各项数据。另放置三个功能按钮,“预测”按钮用于对输入的个体数据进行预测,“重置”按钮用于清除输入文本框/按钮中的所有数据,“返回”按钮指向主界面,如图3所示。
C.“团体预测”界面放置数据录入示例图片和说明文本框,另放置五个功能按钮。“请选择数据(Excel)”按钮用于导入团体数据,“请选择结果保存位置”按钮用于设置预测结果文件保存路径及文件名,“预测”按钮用于对输入的团体数据进行预测,“重置”按钮用于清除输入的团体数据和保存路径,“返回”按钮指向主界面,如图4所示。
图6是采用所构建的基础神经网络模型(Basic BPNN)和经遗传算法优化后的神经网络模型(GA-BPNN)以及传统Logistic回归方法的实验结果对照,具体预测结果如下表所示。
从上表可以看出,本发明很好地解决了先前汉语儿童发展性阅读障碍预测评估模型存在的缺馅,并将总体预测准确性提高至94.1%,其中对阅读障碍儿童的预测准确性为91.4%,对正常儿童的预测准确性为96.2%。
本发明提供了一个可以对汉语发展性阅读障碍进行预测评估的神经网络模型,并将其以图形用户界面的形式呈现。故本发明中包含的神经网络模型、软件的结构、可实现的功能及所做的等效变化和装饰应包括在本专利所保护的范围中,未述之处适用于现有技术。
显然,上述实施例仅仅是为清楚地说明所作的举例,而并非对实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。而由此所引伸出的显而易见的变化或变动仍处于本发明的保护范围之中。
- 一种汉语发展性阅读障碍预测系统及其预测方法
- 汉语韵律层级结构预测系统