自适应选择最优成矿预测要素的方法、终端及存储介质
文献发布时间:2023-06-19 11:02:01
技术领域
本申请涉及地质分析领域,具体而言,涉及一种自适应选择最优成矿预测要素的方法、终端及存储介质。
背景技术
在大数据背景技术及其相关配套环境的支持下,大数据为各个行业的发展及变革提供了契机、方向。在地球科学领域内的数学地质与成矿预测方向,其交叉学科的属性更面临海量多元数据及相关技术方法。在传统的成矿预测思路中,成矿预测要素的选择往往具有一定的主观性,单一性,也就丧失了一定程度的灵活性,即面对复杂多变的成矿系统背景,往往单一的成矿模式所确定的控矿要素层不能完全涵盖其成矿特征,从而造成了在成矿预测过程中成矿预测要素选择的不确定性、预测模型的泛化能力及准确性受限等问题,基于此,技术方法且是具有更加灵活的、智能的、科学合理的、确定最优控矿要素层的方法,是成矿预测准确性的方法保障,同时也提升相关技术方法在多维成矿预测平台下的科学性与逻辑的合理性。
在现有的海量的多元的数据之上,在三维平台下,利用高效准确的技术方法从中挖掘出具有成矿潜力的区域是成矿预测方向的关键技术要点。结合到具体的成矿预测过程,在外观层面表现下矿床的形成往往是多种控矿要素复合叠加产生的结果,在空间与时间上都有不同层次变化,在内部机理层面上,则是不同成矿方式导致的结果;进一步再具体到一个单一的矿床上,其成矿过程中往往是多期次多类型复合作用的结果,且随着不同的空间位置的变化而呈现不同的组合特征;结合段首所提的国家发展战略,以及进一步对矿山开采工作内容的深入挖掘,体现现有矿山的再生产价值,在三维平台下,结合多元数据的集成及数据挖掘的技术方法为深部及存在潜在未发掘有价值的矿产开发提供数据及技术上的支持,成为数学地质与成矿预测方向的技术环节中的一个要点。
发明内容
本申请的目的在于提供一种自适应选择最优成矿预测要素的方法、终端及存储介质,其能够通过更为合理的选择成矿预测要素,提高成矿预测的准确度,并且可以揭示三维空间各空间要素相互之间的关系以及组合特征。
本申请的实施例是这样实现的:
一种自适应选择最优成矿预测要素的方法,包括:
S1、集成所有参与评价的地质要素和矢量要素,并进行统一的空间数据库构建;
S2、在研究区三维空间内进行单元尺度的确定;
S3、沿预设方向以一定的移动间距逐步移动窗口;
S4、针对每一个窗口进行选择的数据进行Apriori运算,进行规则的提取;判断提取的结果是否包含矿点,在为是时,根据Apriori提取出形成矿的规则;在为否时,提取窗口内出现次数最多的规则;
S5、在当前窗口内含有矿点时,判断当前窗口中是否包含的矿点的数量是否超过预设数量,在为是时,采用Fisher判别系数方法判定当前空间点的类别归属;在为否时,采用层次聚类中的平均链接聚类方法判定当前空间点的类别归属;在当前窗口内不含有矿点时,根据已知的矿点确定的fisher和层次聚类方法判定和已知矿点是否为同一类别,进而根据已知矿点的属性和所属窗口来确定该点的成矿预测要素。
进一步地,所述地质要素包括:构造单元划分、地层、断裂、岩性单元、建造组合中的至少一种。
进一步地,所述矢量要素包括:遥感要素、地球化学数据、地球物理数据中的至少一种;其中,所述遥感要素包括光谱信息;所述地球化学数据包括预设元素的含量信息;所述地球物理数据包括重力勘探、磁法勘探、电法勘探、地震勘探。
进一步地,所述单元尺度的大小的确定包括:选择各类型数据中变为精细的数据为基准,且以该基准数据相邻数据点变化值参考正负一倍方差为标准确定单位格大小。
进一步地,选择Apriori确定的规则中置信度权重为0.5;提升度权重为0.3;支持度权重为0.2。
终端,包括:储存器和处理器,所述存储器储存有可在所述处理器上运行的计算机程序,所述处理器执行所述程序时实现上述的自适应选择最优成矿预测要素的方法中的步骤。
计算机可读存储介质,其上存储有计算机程序,所述计算机程序执行时实现上述的自适应选择最优成矿预测要素的方法中的步骤。
本申请实施例的包括:S1、集成所有参与评价的地质要素和矢量要素,并进行统一的空间数据库构建;S2、在研究区三维空间内进行单元尺度的确定;S3、沿预设方向以一定的移动间距逐步移动窗口;S4、针对每一个窗口进行选择的数据进行Apriori运算,进行规则的提取;判断提取的结果是否包含矿点,在为是时,根据Apriori提取出形成矿的规则;在为否时,提取窗口内出现次数最多的规则;S5、在当前窗口内含有矿点时,判断当前窗口中是否包含的矿点的数量是否超过预设数量,在为是时,采用Fisher判别系数方法判定当前空间点的类别归属;在为否时,采用层次聚类中的平均链接聚类方法判定当前空间点的类别归属;在当前窗口内不含有矿点时,根据已知的矿点确定的fisher和层次聚类方法判定和已知矿点是否为同一类别,进而根据已知矿点的属性和所属窗口来确定该点的成矿预测要素。利用移动窗口、Apriori算法、判别系数等组合技术方法,在客观的自然的真实三维空间内为成矿预测提供基础特征输入数据,即为成矿预测过程中的输入成矿预测要素层,提供因地制宜的选择,并根据Apriori算法的指标提升度、置信度、支持度等为成矿预测要素之间的相互关系给予量化指标,最终实现在成矿预测过程中,在选择输入成矿预测要素时因地制宜的智能的选择要素,从而提升预测精度,达到良好的预测效果;此外也可在各个空间区块内,揭示量化各个控矿要素之间的组合特征,为成矿预测过程中的决策提供参考依据。此组合技术方法相较于传统的成矿预测过程中,在确定输入特征要素时,该方法通过数据的关联规则可因地制宜的选择更符合该三维空间区域内的控矿要素,同时,该方法能够为该区域的各个要素的组合特征进行量化表达与揭示。综上所述,该组合技术方法有两个目的可以通过更为合理的选择成矿预测要素,成矿预测的准确度;还可以揭示三维空间各空间要素相互之间的关系以及组合特征。
附图说明
为了更清楚地说明本申请实施例的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,应当理解,以下附图仅示出了本申请的某些实施例,因此不应被看作是对范围的限定,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他相关的附图。
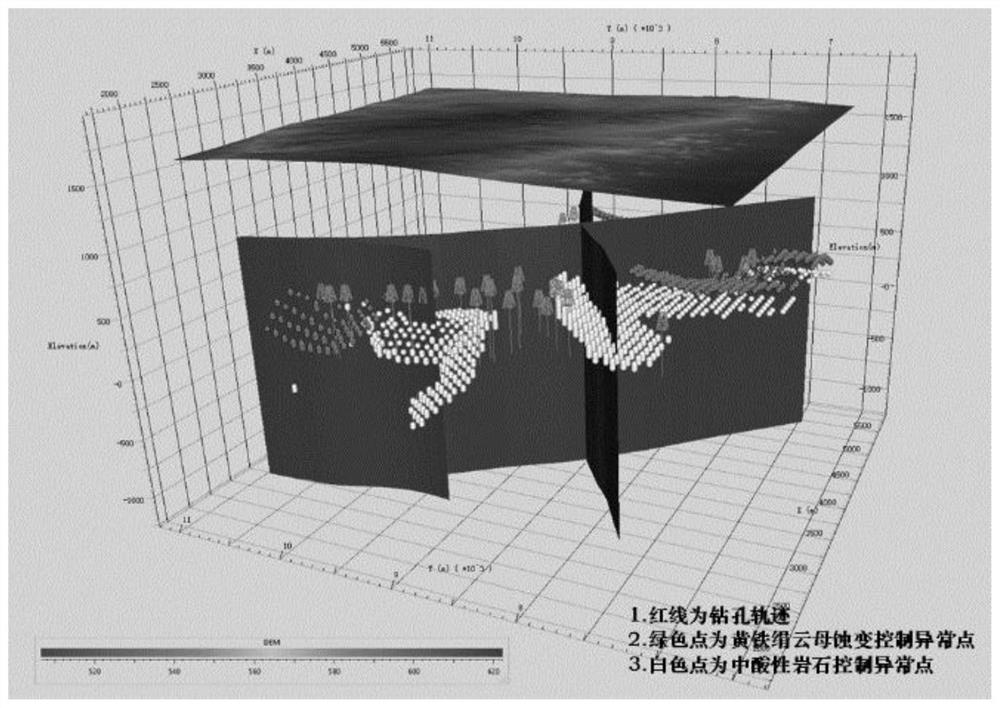
图1为本申请实施例提供的研究区空间数据初步分析与多元数据集成图;
图2为本申请实施例提供的空间单位格根据上述原则确定体元的大小为规则四方体X*Y*Z为25米*25*25示意图;
图3为本申请实施例提供的窗口移动方向为135度,仰角45度方向进行移动示意图;
图4为本申请实施例提供的Apriori规则的计算结果图;
图5为本申请实施例提供的研究区单元格的划分图;
图6为本申请实施例提供的窗口移动方位角与垂直平面内俯仰角示意图;
图7为本申请实施例提供的窗口滑动示意图;
图8为本申请实施例提供的层次聚类图。
具体实施方式
为使本申请实施例的目的、技术方案和优点更加清楚,下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本申请一部分实施例,而不是全部的实施例。通常在此处附图中描述和示出的本申请实施例的组件可以以各种不同的配置来布置和设计。
因此,以下对在附图中提供的本申请的实施例的详细描述并非旨在限制要求保护的本申请的范围,而是仅仅表示本申请的选定实施例。基于本申请中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。
本申请的实施例提供了一种自适应选择最优成矿预测要素的方法,包括如下步骤:
S1、研究区内,集成所有参与评价的地质要素,确保各个地质要素空间坐标系一致,空间范围一致,各矢量要素的空间拓扑关系正确,栅格数据类型及空间分辨率与各分析任务相适应,在完成以上步骤后,进行统一的空间数据库构建,其最终集成的数据应包括但不限于以下数据,在地质要素上应包括构造单元划分,地层,断裂,岩性单元,建造组合等;遥感要素方面以的光谱信息为主;地球化学数据则以各元素的含量信息为主,地球物理数据则包括重力勘探、磁法勘探、电法勘探、地震勘探四个方面,其对应的数据则以剩余密度数据,磁化率,极化率数据,电阻率数据等数据为主,将数据统一进行转换,类别划分,转变为统一的数据三维空间体元格式。
具体做法为:将不同的数据类型进行基础的分析工作,例如对矢量格式的线文件断裂进行距离分析或密度分析(视情况不同调整),并对其产生的连续性数据进行类别划分,每一类别代表特定的数据区间,同理对于遥感蚀变信息提取数据应同样进行类别的划分,类别划分标准以不同的蚀变类型为准,对于不存在蚀变信息应以编码信息进行表示,以示区别,对于极化率,电阻率数据等连续型数据依据数值大小进行类别划分及编码表达。
S2、在研究区三维空间内进行单元格尺度的确定,针对多元数据特征(连续性数据、离散型数据,文本数据)以及数据在三维空间内的差异性分布间距大小为依据划定单元格大小,划分的标准以能体现各类不同数据之间的差异性为准,此处的默认设置为选择各类型数据中变为精细的数据为基准,且以该基准数据相邻数据点变化值参考正负一倍方差为标准确定单位格大小。
S3、在以上工作的基础之上移动窗口的大小,并以一定的移动间距逐步移动窗口,在移动方向上以固定的原点为基础沿着X,Y,Z,且可沿某一固定方向进行平滑移动(若选择沿着某一方向进行移动,用户需指定方位角以及以原点为基准的俯、仰角,且该角度的变化在以原点和方位角所确定的垂直平面内所确定的),窗口的大小为10*10*10个空间立体像元为默认值(可根据实际情况进行调整)。
S4、针对每一个窗口进行选择的数据进行Apriori运算,进行规则的提取,对于含矿窗口要着重计算不同的项集对含矿这一项集的置信度与提升度指标,并以含矿的项集为右项集为前提条件,根据项集个数,支持度、置信度、提升度指标判断并确定利用成矿的要素组合也即成矿预测要素的确定过程,也即含矿窗口内的空间点即以Apriori所确定的规则为窗口内空间点的成矿要素对于不含矿窗口单元则应该计算不同项目集个数下,各个要素的组合规则,并根据置信度、提升度两个指标来判断不同项集个数下不同规则的组合特征,进而为选取成矿预测的控矿要素提供科学参考,同时开展下一步即第五步工作。
S5、此处判定空间点根据窗口中是否包含足够多的矿点(矿点的个数可以根据手动设置参数也可按照默认值20进行操作)进行不同方法的选择,若移动窗口内包含足够的矿点数采用的方法为Fisher判别系数方法,判定每一个空间点的类别归属,即是否采用已知矿点的属性作为空间点的成矿预测要素,若含矿点个数不够的情况下,采用层次聚类中的平均链接聚类方法,根据类别的异同来判定。
需额外说明的是对于大量不含已知矿点的数据也可采用上述的Fisher和层次聚类中的平均链接聚类方法来判定是否采用已知矿点的属性作为该空间点的成矿预测要素,并在此基础之上,需结合每一个移动窗口中的Apriori计算出的规则作为参考依据进行综合判断该空间点的成矿预测要素的选择,默认情况下在不含矿窗口内的空间点且中心点距离矿点的最近的矿点距离大于5000米时,选择Apriori确定的规则中置信度、提升度、支持度三者加权平均值最高的选项为判断依据置信度权重为0.5,提升度为0.3、支持度为0.2。
其中,Fisher线性判别法的基本思想(以两个总体为例)
(1)从两个总体中抽取具有p个观测指标的样品,所得数据集称为训练样本。
(2)构造判别函数
确定系数c
(3)将新样品的p个指标值带入判别函数,计算y值;
(4)判别准则:将新样品的y值与判别临界值进行比较,给出新样品类别归属的判别结果。
其中,聚类步骤流程如下:
1.将每一个元素单独定为一类;
2.重复:每一轮都合并指定距离(对指定距离的理解很重要)最小的类;
3.直到所有的元素都归为同一类;
依据对相似度(距离)的不同定义,将Agglomerative Clustering的聚类方法分为三种:Single-linkage,Complete-linkage、Group average.Single-linkage,其中Groupaverage:要比较的距离为类之间的平均距离(平均距离的定义与计算:假设有A,B两个类,A中有n个元素,B中有m个元素。在A与B中各取一个元素,可得到他们之间的距离。将nm个这样的距离相加,得到距离和。最后距离和除以nm得到A,B两个类的平均距离。)
其中,Apriori计算过程如下:
Apriori算法的基本定义中涉及的两个概念:
1)设定最小支持度的阈值,如果一个项集的支持度大于等于最小支持度,则其为频繁项集,如果一个项集的支持度小于最小支持度,则其为非频繁项集;
2)对于一个项集,如果它是频繁集,则它的子集均是频繁集;如果它是非频繁集,则它的父集都是非频繁集。这是因为一个项集的所有子集的支持度都大于等于它本身,一个项集的所有父集的支持度都小于等于它本身;
实施例1
基于以上的研究内容,将结果进行应用于卡拉塔格地区梅林南矿区,研究区位于哈密市西南260°方向约160千米处,行政区划隶属哈密市五堡乡管辖。矿床位于卡拉塔格矿区的东南端,为铜锌金多金属矿化主要与火山作用有关,位于区域上北西西-近东西向的卡拉塔格复背斜的中南部的南翼的次级向斜中;侵入岩发育一套形成于早古生代活动大陆边缘弧构造环境的英云闪长岩-花岗闪长岩;围岩蚀变矿区蚀变广泛发育,其中,安山岩以绿泥石化、绿帘石化、硅化及黄铁矿化;区内出露地层为上奥陶-下志留统荒草坡群大柳沟组(O3-S1Hd),其中Bi、Mo、Cu元素显示富集特征,浓集系数分别为39.25、4.72、1.44,变异系数分别为3.11、1.45、0.01。
表1梅岭南VMS铜锌矿床成矿概念模式
图1:研究区空间数据初步分析与多元数据集成;
图2:空间单位格根据上述原则确定体元的大小为规则四方体X*Y*Z为25米*25*25示意图;
图3:窗口移动方向为135度,仰角45度方向进行移动示意图;
图4:Apriori规则的计算结果图;
表2窗口1规则提取结果
窗口1规则代表的意义:代表距离黄铁绢英岩化北方向,且距离30米,同时距离侵入岩30米的位置有利于成矿,且在左项集存在的前提下产生矿体的概率为0.982(置信度),且该规则的支持度为0.953,根据提升度指标确定矿体与规则中控矿要素之间不存在相斥现象。
表2窗口1规则提取结果
窗口2表达的意义为距离在距离黄铁绢英岩化30米,方向为正上方时,断裂在空间单元的北东东方向有利于成矿,且在左项集存在的前提下产生矿体的概率为0.802(置信度)且该规则的支持度为0.902,同样根据提升度指标确定矿体与规则中控矿要素之间不存在相斥现象。
本申请还提供了一种终端,包括:储存器和处理器,储存器电连接于处理器,存储器储存有可在处理器上运行的计算机程序,处理器执行程序时实现上述的自适应选择最优成矿预测要素的方法中的步骤。
本申请还提供了一种计算机可读存储介质,其上存储有计算机程序,计算机程序执行时实现上述的自适应选择最优成矿预测要素的方法中的步骤。利用计算机读取该可读存储介质,计算机可以实现自适应选择最优成矿预测要素的方法的运行。
以上所述仅为本申请的优选实施例而已,并不用于限制本申请,对于本领域的技术人员来说,本申请可以有各种更改和变化。凡在本申请的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本申请的保护范围之内。
- 自适应选择最优成矿预测要素的方法、终端及存储介质
- 一种双向中继方案自适应选择方法、系统、存储介质及终端