一种分布式多机器人目标搜索方法
文献发布时间:2023-06-19 11:06:50
技术领域
本发明属于人工智能技术领域,尤其涉及一种分布式多机器人目标搜索方法。
背景技术
现阶段多智能体的环境感知技术主要是被动地完成环境探测、目标识别与跟踪、实时定位与地图构建等,所涉及的智能体数目也大多为单个。此外,机器人群体的研究领域大多集中在机器人的群体集中式编队、机器人之间的通信机制、机器人之间的任务资源分配等方面,在机器人群体的协同目标搜索方面很少有研究,而移动目标搜索更是稀少。随着深度学习算法的飞速发展,热门的深度学习主要关注于文本、图像、视频等数据的处理,但是这一过程耗时长、数据收集成本高无法应用于实际的多机器人系统以及实时区域态势感知当中。在复杂大规模动态环境中,机器人需要与环境交互的信息量较多,不能很好地通过深度学习方法来进行主动目标感知。
现有的机器人目标搜索研究成果大部分集中于已知的静态环境,大多借助环境离散化,采用传统搜索算法,得到起点和终点之间的路径,比如:A*算法,蚁群算法,遗传算法,粒子群算法等。这些算法搜索速度慢,计算量大,在多约束条件下很难找到机器人群体的最优轨迹,且上述算法研究多集中于单个机器人应用,很少涉及群体机器人的协同搜索和感知。而且当区域环境未知且发生变化的时候,上述算法无法适应环境变化,必须重新计算,在区域态势感知、移动目标搜索方面有很大的局限性。
蒙特卡洛树搜索算法是一种利用蒙特卡洛方法作为评估的博弈树搜索算法,不需要引入过多的领域知识的同时,具有非常大的可扩展性,其采用的上限置信区间策略可以极大提升计算机博弈引擎水平,目前该算法多用于如围棋一类的博弈类游戏的开发,少数研究将蒙特卡洛算法应用于单个机器人在线规划,在机器人群体的目标搜索领域很少有研究成果。
发明内容
本发明的目的是提出一种分布式多机器人目标搜索方法,以克服现有技术中的不足,针对大规模且未知的非结构化复杂环境,引入专家知识,实时更新区域奖励值,并且利用蒙特卡洛树搜索算法解决多约束下群体机器人区域性系统快速轨迹规划和移动目标搜索。
本发明提出的分布式多机器人目标搜索方法,该方法根据已知目标,带入搜索目标之间的关联性,实时更新区域追踪奖励与探索奖励,基于分布式蒙特卡洛树搜索确定机器人协同搜索过程中的动作序列,对上限置信区间进行改进,同时利用利帕雷托最优策略实现多目标优化,采用梯度下降法优化机器人动作序列概率分布,与其他机器人通信,更新机器人动作序列概率分布,完成分布式多机器人的目标搜索。
本发明提出的一种分布式多机器人目标搜索方法,其优点是:
1、本发明的分布式多机器人目标搜索方法,是一种群体协同主动感知方法,其中引入专家知识或已知目标,在搜索到敌方目标的时候根据专家知识推测其他目标可能出现的区域并且更新奖励。
2、本发明方法中设置独特的奖励机制,在机器人搜索到目标后同时生成追踪奖励地图和探索奖励地图。使得奖励地图能够随时间实时变化,从而使得机器人群体能够适应环境变化继续作出优化决策,并且在追踪和探索中保持平衡,不需要重新开始计算。
3、本发明方法,能够首先由多机器人分布式同时群体协同搜索,在预算时间足够的情况下,能够演进学习,随着迭代次数增多搜索效果逐渐提高。本发明方法解决了机器人群体在未知、动态环境下的群体协同目标搜索问题。
附图说明
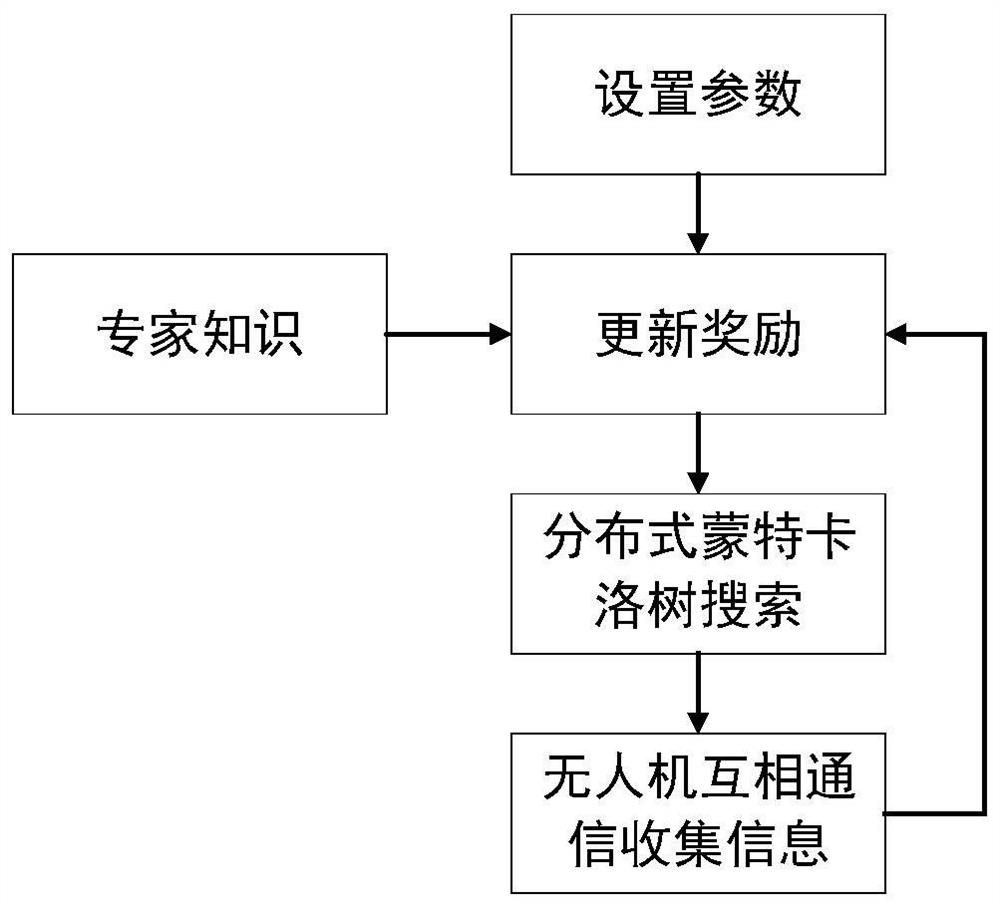
图1是本发明提出的一种分布式多机器人目标搜索方法的流程框图。
图2是本发明方法的一个实施例中涉及的蒙特卡洛搜索树的示意图。
具体实施方式
本发明提出的分布式多机器人目标搜索方法,根据已知目标,带入搜索目标之间的关联性,实时更新区域追踪奖励与探索奖励,基于分布式蒙特卡洛树搜索确定机器人协同搜索过程中的动作序列,对上限置信区间进行改进,同时利用利帕雷托最优策略实现多目标优化,采用梯度下降法优化机器人动作序列概率分布,与其他机器人通信,更新机器人动作序列概率分布,完成分布式多机器人的目标搜索。
本发明的分布式多机器人目标搜索方法的一个实施例中,其流程框图如图1所示,包括以下步骤:
(1)设定分布式多机器人中有R台机器人,机器人群{1,2,…,R},每台机器人独立规划自己的计划动作序列x
设定各机器人的监视半径,当目标出现在机器人监视半径内时,视为搜索到目标。每台机器人都搭载有必要光学传感器来搜索区域内的目标。
将每台机器人的行动用可能动作序列集合χ
(2)设定一个蒙特卡洛树搜索奖励地图的更新方法,具体包括如下步骤:
(2-1)将待搜索目标的出现区域网格化,每个网格设置不同奖励值,形成追踪奖励地图
(2-2)设置一个待优化的蒙特卡洛树搜索全局目标函数g(x),该全局目标函数g(x)为一个由步骤(1)中的所有机器人动作序列集合x构成的函数,g(x)=(g
其中,pose为机器人在步骤(2-1)中的追踪奖励地图
(2-3)定义局部目标函数f
(3)设定分布式多机器人中的每个机器人的初始位置,每个机器人的动作有三种选择,分别为以-45°、0°、45°为转向角向前前进一格,各机器人基于蒙特卡洛树搜索方法以并行的方式得到计划动作序列x
(3-1)每个机器人以初始位置作为根节点,由于机器人有三个动作,所以每个节点可以扩展出最多三个子节点。在蒙特卡洛树搜索方法中,从蒙特卡洛树的根节点开始搜索,根据帕雷托最优原则,每次选择子节点中上限区间分数相量帕雷托最优的节点作为下一个访问节点,向搜索树下方搜索,直到访问到一个存在未扩展子节点的节点,每个节点表示机器人所在的地图坐标,链接节点的箭头表示机器人做出的动作,第t次迭代时,子节点j的上限区间向量计算公式如下:
其中:
上述公式是一种折扣上限区间公式,其中,
t
(3-2)利用(3-1)中上限区间公式选择子节点,在搜索树中向下访问直到拥有未扩展子节点的节点,在该节点处随机扩展一个子节点j,如图2所示的子节点j;
(3-3)设置机器人模拟随机移动上限值N
(3-4)采用反向传播方式,将第t次迭代的模拟奖励值F
(3-5)设置迭代次数上限值N
(4)从步骤(3-5)的蒙特卡洛搜索树选取奖励值最高的N条通路作为机器人可能动作序列集合
(5)分布式多机器人中的所有机器人向其他机器人发送本机器人的可能动作序列集合
对于
(5-1)计算步骤(2-3)中的奖励差值f
其中,Π为连乘运算符;
(5-2)采用梯度下降法,利用下式优化可能动作序列集合
其中,参数α为梯度下降固定步长,参数α取值范围为(0,0.1),本发明中取值为0.01,β为常数,β的取值范围为(0,1),H(q
(6)从步骤(5)的
(7)根据分布式机器人目标搜索的要求时间,设置机器人动作次数上限N
- 一种分布式多机器人目标搜索方法
- 一种多无人机分布式协同目标搜索方法