一种文本并行数据挖掘系统及方法
文献发布时间:2023-06-19 11:35:49
技术领域
本发明涉及数据挖掘技术领域,更具体的说是涉及一种文本并行数据挖掘系统及方法。
背景技术
目前,数据挖掘是人工智能和数据库领域研究的热点问题,所谓数据挖掘是指从数据库的大量数据中揭示出隐含的、先前未知的并有潜在价值的信息的过程。而随着互联网的发展,网页上的文本信息增长快速,如何索引、检索、管理、挖掘网页上的海量文本信息已成为计算机科学领域所面临的一个巨大挑战。
但是,现有的文本数据挖掘架构大多采用复杂的数据算法,而且很少有数据挖掘系统中的数据挖掘算法实现了并行的方式,当数据量特别大的时候,这种模式会导致处理效率较低且处理过程较为繁琐。
因此,如何提供一种能够解决上述问题的文本数据挖掘系统是本领域技术人员亟需解决的问题。
发明内容
有鉴于此,本发明提供了一种文本并行数据挖掘系统及方法,并行数据挖掘架构扩展了数据挖掘的应用范围,同时可根据需要优先处理出现频率较高的文本集。
为了实现上述目的,本发明采用如下技术方案:
一种文本并行数据挖掘系统,包括:
数据获取模块,所述数据获取模块用于获取多个原始文本数据集;
数据清洗模块,所述数据清洗模块用于对所述原始文本数据集进行预处理,以得到对应的多个关键词条集;
中央处理模块,所述中央处理模块用于根据所述关键词条集的数量进行解析,得到解析结果;
线程配置模块,所述线程配置模块根据所述解析结果配置线程进行处理;
数据存储模块,所述数据存储模块用于实时存储处理结果。
优选的,还包括:远程通讯服务器,所述远程通讯服务器用于当所述处理结果出现敏感词汇时远程发送提示信息。
优选的,所述中央处理模块包括:
解析单元,所述解析单元用于分析多个所述关键词条集得到对应的文件大小,以及出现相同关键词的概率;
调度单元,所述调度单元根据出现相同关键词概率按照由大到小的顺序排序,并综合分析所述关键词条集的文件大小对每个所述关键词条集权重分配,得到对应的排序结果。
优选的,所述线程配置模块包括:
线程负载获取单元,所述线程负载获取单元用于获取当前各个线程对应的负载大小;
线程分配单元,所述线程分配单元用于根据所述线程的负载大小以及所述调度单元的所述排序结果对分配任务,并计算是否存在任务剩余量;
线程设置单元,所述线程设置单元用于根据所述任务剩余量大小判断是否需要建立新线程。
优选的,本发明还提供一种文本并行数据挖掘方法,包括:
步骤S1:利用所述数据获取模块得到多个原始文本数据集;
步骤S2:利用数据清洗模块对所述原始文本数据集进行预处理,以得到对应的多个关键词条集;
步骤S3:利用所述中央处理模块对多个所述关键词条集进行处理,并将处理结果发送至所述线程配置模块;
步骤S4:所述线程配置模块根据各挖掘线程当前的数据挖掘任务负载情况,将当前数据挖掘任务分配给数据挖掘任务负载较少的挖掘代理线程,并将结果发送至所述数据存储模块进行存储。
优选的,还包括:所述步骤S2中:当所述关键词条集中出现敏感词汇超过设定阈值时,通过所述远程通讯服务器发送提示信息至工作人员。
优选的,所述步骤S3还包括:
步骤S31:利用所述解析单元分析多个所述关键词条集得到对应的文件大小,以及出现相同关键词的概率;
步骤S32:所述调度单元根据出现相同关键词概率按照由大到小的顺序排序,并综合分析所述关键词条集的文件大小对每个所述关键词条集权重分配,得到对应的排序结果。
优选的,所述步骤S4还包括:
步骤S41:利用所述线程负载获取单元获取当前各个线程对应的负载大小;
步骤S42:利用所述线程分配单元用于根据所述线程的负载大小以及所述调度单元的所述排序结果对分配任务,并计算是否存在任务剩余量。
经由上述的技术方案可知,与现有技术相比,本发明公开提供了一种文本并行数据挖掘系统及方法,并行数据挖掘架构扩展了数据挖掘的应用范围,且可以动态增加挖掘节点,扩展计算能力,实现对海量数据的高速有效地处理,解决了传统数据挖掘软件处理数据量小,运行速度慢的问题,大大提高了数据挖掘算法处理海量数据的效率和数据承载能力
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。
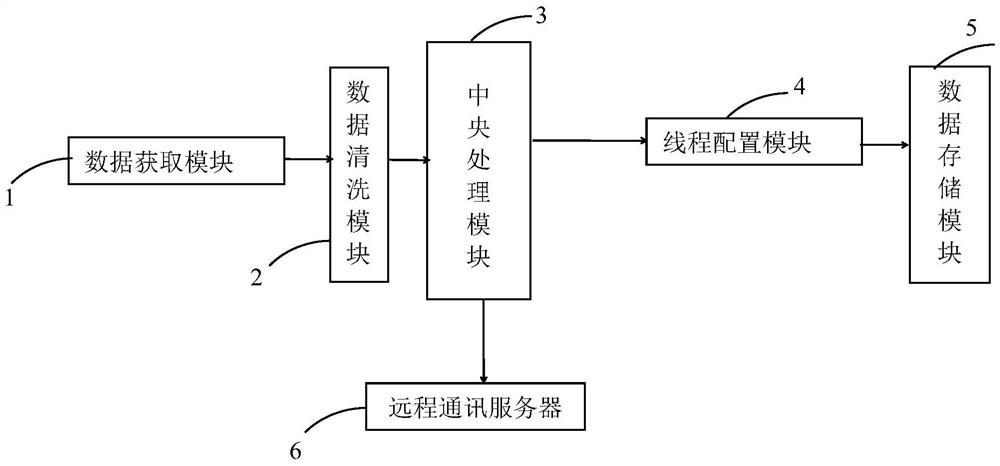
图1附图为本发明提供的一种文本并行数据挖掘系统的结构原理框图;
图2附图为本发明提供的中央处理模块的结构原理框图;
图3附图为本发明提供的线程配置模块的结构原理框图;
图4附图为本发明提供的一种文本并行数据挖掘方法的执行流程图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
实施例1
参见附图1所示,本发明实施例公开了一种文本并行数据挖掘系统,包括:
数据获取模块1,数据获取模块1用于获取多个原始文本数据集;
数据清洗模块2,数据清洗模块2用于对原始文本数据集进行预处理,以得到对应的多个关键词条集;
中央处理模块3,中央处理模块3用于根据关键词条集的数量进行解析,得到解析结果;
线程配置模块4,线程配置模块4根据解析结果配置线程进行处理;
数据存储模块5,数据存储模块5用于实时存储处理结果。
在一个具体的实施例中,还包括:远程通讯服务器6,远程通讯服务器6用于当处理结果出现敏感词汇时远程发送提示信息。
参见附图2所示,在一个具体的实施例中,中央处理模块3包括:
解析单元31,解析单元31用于分析多个关键词条集得到对应的文件大小,以及出现相同关键词的概率;
调度单元32,调度单元32根据出现相同关键词概率按照由大到小的顺序排序,并综合分析关键词条集的文件大小对每个关键词条集权重分配,得到对应的排序结果。
参见附图3所示,在一个具体的实施例中,线程配置模块4包括:
线程负载获取单元41,线程负载获取单元41用于获取当前各个线程对应的负载大小;
线程分配单元42,线程分配单元42用于根据线程的负载大小以及调度单元32的排序结果对分配任务,并计算是否存在任务剩余量;
线程设置单元43,线程设置单元43用于根据任务剩余量大小判断是否需要建立新线程。
实施例2
参见附图4所示,本发明实施例2提供一种文本并行数据挖掘方法,包括:
步骤S1:利用数据获取模块1得到多个原始文本数据集;
步骤S2:利用数据清洗模块2对原始文本数据集进行预处理,以得到对应的多个关键词条集;
步骤S3:利用中央处理模块3对多个关键词条集进行处理,并将处理结果发送至线程配置模块4;
步骤S4:线程配置模块4根据各挖掘线程当前的数据挖掘任务负载情况,将当前数据挖掘任务分配给数据挖掘任务负载较少的挖掘代理线程,并将结果发送至数据存储模块5进行存储。
在一个具体的实施例中,步骤S2中还包括:当关键词条集中出现敏感词汇超过设定阈值时,通过远程通讯服务器6发送提示信息至工作人员。
在一个具体的实施例中,步骤S3还包括:
步骤S31:利用解析单元31分析多个关键词条集得到对应的文件大小,以及出现相同关键词的概率;
步骤S32:调度单元32根据出现相同关键词概率按照由大到小的顺序排序,并综合分析关键词条集的文件大小对每个关键词条集权重分配,得到对应的排序结果。
具体的,调度单元32内部预先存储有相关概率阈值,当该词条集出现的概率超过该值时,则赋予较高的权重,优先进行挖掘处理。
具体的,当关键词条集数量较大、文件较多时,可以通过层次聚类方法对关键词条集进行聚类处理,以提高处理效率。
在一个具体的实施例中,步骤S4还包括:
步骤S41:利用线程负载获取单元41获取当前各个线程对应的负载大小;
步骤S42:利用线程分配单元42用于根据线程的负载大小以及调度单元32的排序结果对分配任务,并计算是否存在任务剩余量。
具体的,当当前线程的计算能力无法满足需要时,可以通过线程设置单元43重新设置新的线程进行处理。
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例公开的装置而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
- 一种文本并行数据挖掘系统及方法
- 一种基于层次的中文文本并行数据挖掘方法