基于Bert与全连接神经网络融合的中文文本意图识别方法
文献发布时间:2023-06-19 12:10:19
技术领域
本发明属于自然语言处理技术领域,尤其是一种基于Bert与全连接神经网络融合的中文文本意图识别方法。
背景技术
随着互联网与人工智能的高速发展,由机器代替人类工作已逐步成为现实,其中以对话商务发展较为迅速。人们喜欢用自然语言表达他们的感受和需求,对话商务技术使企业可以在客户喜欢的平台上与客户交谈,优化表达能力、相关性和个性化。在人机交互已经从图形窗口交互方式转向对话窗口交互方式的浪潮下,自然语言处理技术已经成为人机交互的关键要素。然而,机器与人类交流以完成特定任务仍是亟待解决的挑战,其中一个亟待克服的困难是让机器识别使用者的对话意图。
传统的意图识别方法采用非动态字向量或词向量作为语义特征,且上下文信息量比较单一,采用的特征提取模型大多是深度学习中的CNN、RNN模型,对语料特征提取能力不足。本发明采用一种基于Bert与全连接神经网络融合的中文文本意图识别方法加强了特征提取效果,有效提高了意图识别的准确度。
发明内容
传统意图识别技术对语义特征提取能力不足导致识别效果较差,为了克服现有技术上的不足,本发明提供一种基于Bert预训练模型与全连接神经网络融合的中文文本意图识别方法,其中将Bert作为意图文本特征提取器,全连接神经网络模型作为识别模型识别中文文本意图,有效提高现有意图识别技术能力。
为了解决上述技术问题,本发明采用如下的技术方案:
一种基于Bert与全连接神经网络融合的中文文本意图识别方法,包括以下步骤:
S1:获取原始中文意图文本数据集T,其中,T={t
S2:对T'中的每条意图文本以字为单位进行分词,从字向量表中找到对应字的向量表达并将每个字初始化为维度为[vocab_size,embedding_dimension]的向量,其中vocab_size为总共的字库数量,embedding_dimension为字向量的维度,也就是每个字的数学表达,其中所述字向量表是依据历史训练过程进行构建的,获得词向量特征后利用Bert预训练模型分别提取每个意图文本的句子嵌入特征以及位置嵌入特征;
其中,句子嵌入通过在模型训练过程中自动习得句子向量的取值,用于刻画文本的全局语义信息,并与词嵌入所得的语义信息相融合;
其中,位置嵌入利用对不同位置的字分别附加不同的向量以获得位置信息,位置嵌入的维度为[max_sequence_length,embedding_dimension],嵌入的维度同词向量的维度,max_sequence_length属于超参数,指的是限定的最大单个句子长度,其中Bert初始化一个位置嵌入值,然后通过预训练过程学习得到最优位置嵌入值;
S3:将词嵌入,句子嵌入和位置嵌入三者所得的向量一起作为Bert双向Transformer编码器的输入,Transformer编码器采用多头注意力机制对提取的特征向量进行拼接,得到含有语义特征的序列向量,其中,采用多头注意力机制对所提取的特征向量进行拼接的计算公式如下:
MultiHead(Q,K,V)=Concat(head
其中,Q=V=K,均是attention机制的输入矩阵,Concat()目的是实现矩阵进行行向量的拼接,W
head
W
经Transformer编码器输出字向量序列S,其中S={s
S4:将字向量序列S中的字向量输入到全连接神经网络模型中进行特征提取,得到特征向量F
S5:将全连接神经网络的输出结果输入到SoftMax层进行概率计算,使得输入向量中的每个实数被映射为0到1之间的实数,并且输出向量中所有实数之和为1,这些实数表示相应意图种类的概率大小,得到的输出为概率预测向量P={p
S6:根据分类结果,计算全连接神经网络模型的损失函数;
S7:采用Adam算法对损失函数进行优化,指标为准确度,对全连接神经网络模型反向传播训练,更新优化各层神经元的参数值以及权重;
S8:将意图文本测试集输入到识别模型中,确定模型参数的最佳值,使误差值达到最小,完成意图识别模型的训练;
S9:将待识别的意图文本输入到训练好的意图识别模型中,得到识别结果。
进一步,所述步骤S1中,预处理操作包括去标点、符号和停用词。
再进一步,所述步骤S2中,Transformer编码器的核心部件是一个多头注意力机制,由8个self-attention机制组成。
更进一步,所述步骤S2中,利用Bert模型提取每个序列的嵌入层包括使用了词嵌入,段嵌入和位置嵌入来抽取序列特征,使用多头注意力机制和全连接层增强语义向量。
更进一步,所述步骤S2中,限定最大单个意图文本长度为50。
更进一步,所述步骤S6中,所述的损失函数为categorical_crossentropy。
本发明的有益效果为:
本发明基于Bert与全连接神经网络融合的中文文本意图识别方法,解决了意图识别过程中传统意图识别方法提取的语义特征比较单一导致意图识别准确度不足的问题,实现了利用Bert为意图文本特征提取器,利用全连接神经网络模型作为识别模型识别中文文本意图的过程。克服了传统意图识别方法下准确度不足甚至无法正确识别文本意图的不足。从而可以用于解决在文本意图识别中遇到的语义特征比较单一导致识别精度下降问题。
附图说明
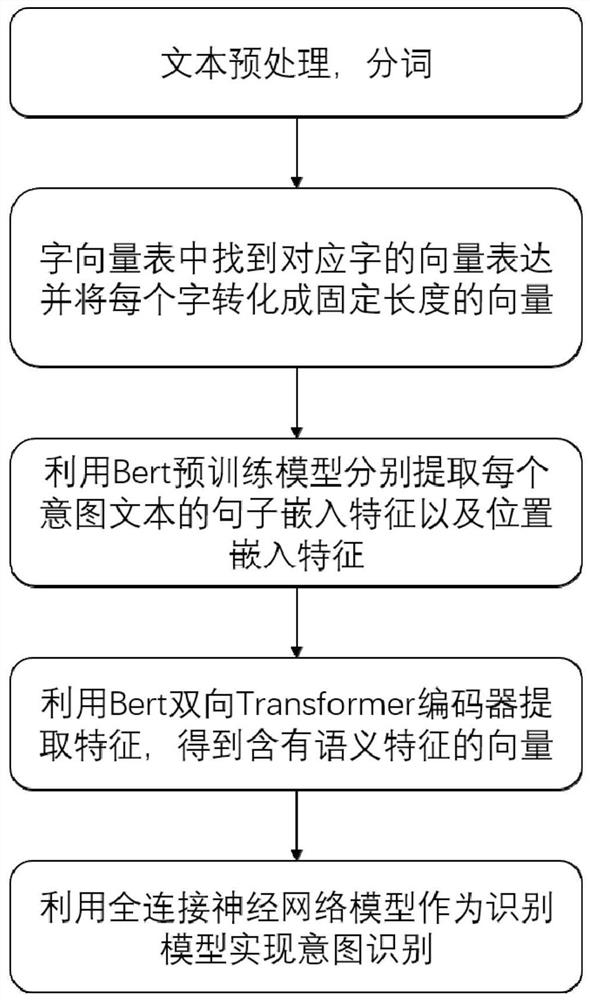
图1是本发明的一种基于Bert与全连接神经网络融合的中文文本意图识别方法的流程示意图。
图2是本发明的一种基于Bert与全连接神经网络融合的中文文本意图识别方法的又一流程示意图。
具体实施方式
下面结合具体实施方式,进一步阐述本发明。应理解,这些实施例仅用于说明本发明而不用于限制本发明的范围。此外应理解,在阅读了本发明讲授的内容之后,本领域技术人员可以对本发明作各种改动或修改,这些等价形式同样落于本申请所附权利要求书所限定的范围。
参照图1和图2,一种基于Bert与全连接神经网络融合的中文文本意图识别方法,包括以下步骤:
S1:获取原始中文意图文本数据集T,其中,T={t
S2:对T'中的每条意图文本以字为单位进行分词,从字向量表中找到对应字的向量表达并将每个字初始化为维度为[vocab_size,embedding_dimension]的向量,其中vocab_size为总共的字库数量,embedding_dimension为字向量的维度,也就是每个字的数学表达,其中所述字向量表是依据历史训练过程进行构建的,获得词向量特征后利用Bert预训练模型分别提取每个意图文本的句子嵌入特征以及位置嵌入特征;
其中,句子嵌入通过在模型训练过程中自动习得句子向量的取值,用于刻画文本的全局语义信息,并与词嵌入所得的语义信息相融合;
其中,位置嵌入利用对不同位置的字分别附加不同的向量以获得位置信息,位置嵌入的维度为[max_sequence_length,embedding_dimension],嵌入的维度同词向量的维度,max_sequence_length属于超参数,指的是限定的最大单个句子长度,其中Bert初始化一个位置嵌入值,然后通过预训练过程学习得到最优位置嵌入值;
Transformer编码器的核心部件是一个多头注意力机制,由8个self-attention机制组成。利用Bert模型提取每个序列的嵌入层包括使用了词嵌入,段嵌入和位置嵌入来抽取序列特征,使用多头注意力机制和全连接层增强语义向量;限定最大单个意图文本长度为50。
S3:将词嵌入,句子嵌入和位置嵌入三者所得的向量一起作为Bert双向Transformer编码器的输入,Transformer编码器采用多头注意力机制对提取的特征向量进行拼接,得到含有语义特征的序列向量,其中,采用多头注意力机制对所提取的特征向量进行拼接的计算公式如下:
MultiHead(Q,K,V)=Concat(head
其中,Q=V=K,均是attention机制的输入矩阵,Concat()目的是实现矩阵进行行向量的拼接,W
head
W
经Transformer编码器输出字向量序列S,其中S={s
S4:将字向量序列S中的字向量输入到全连接神经网络模型中进行特征提取,得到特征向量F
S5:将全连接神经网络的输出结果输入到SoftMax层进行概率计算,使得输入向量中的每个实数被映射为0到1之间的实数,并且输出向量中所有实数之和为1,这些实数表示相应意图种类的概率大小,得到的输出为概率预测向量P={p
S6:根据分类结果,计算全连接神经网络模型的损失函数,所述的损失函数为categorical_crossentropy;
S7:采用Adam算法对损失函数进行优化,指标为准确度,对全连接神经网络模型反向传播训练,更新优化各层神经元的参数值以及权重;
S8:将意图文本测试集输入到识别模型中,确定模型参数的最佳值,使误差值达到最小,完成意图识别模型的训练;
S9:将待识别的意图文本输入到训练好的意图识别模型中,得到识别结果。
本实施例的方案解决了传统意图识别方法提取的语义特征比较单一而导致识别准确度不足的问题,实现了利用Bert作为意图文本特征提取器,利用全连接神经网络模型作为识别模型识别中文文本意图的过程,从而可以用于解决在文本意图识别中遇到的语义特征比较单一导致识别精度下降问题。
本说明书的实施例所述的内容仅仅是对发明构思的实现形式的列举,仅作说明用途。本发明的保护范围不应当被视为仅限于本实施例所陈述的具体形式,本发明的保护范围也及于本领域的普通技术人员根据本发明构思所能想到的等同技术手段。
- 基于Bert与全连接神经网络融合的中文文本意图识别方法
- 一种基于多粒度融合与Bert筛选的中文文本自动校对方法