训练预测模型以及预测资源使用量的方法及装置
文献发布时间:2023-06-19 18:37:28
技术领域
本说明书一个或多个实施例涉及数据库和人工智能,尤其涉及一种训练预测模型以及预测资源使用量的方法及装置。
背景技术
目前多种主流的数据库都采用分布式存储的方式,将租户数据存储于集群中。租户数据可以包括该租户中大量用户的个人数据、隐私数据等,这些数据可以以数据表的形式,存储于数据库集群中。
为了更高的可靠性和可用性,以及容灾的考虑,一些数据库开始支持多副本的部署方案。也就是,每个数据表的分区都包括多个副本,不同副本分布在集群的不同服务器中,从而能够容许单机故障、数据中心故障以及城市级别的故障。例如,在OceanBase(OB)数据库中,支持一主多备共5种副本的部署方式,除主副本外,备副本包括以下副本类型:全能型副本、日志型副本、只读型副本、备份型副本。
数据库系统中多类型的副本部署结构,在实现数据库高可用的情况下也对副本类型的运维带来了挑战。例如,在OceanBase(OB)数据库运维场景中,缺乏有效的方式获取租户副本粒度的处理资源使用指标,例如CPU使用指标cpu_uti l,而这些使用指标的精准刻画,对于扩缩容策略、限流自适应、分时调度等实现都是至关重要的基石。因此,迫切需要改进的技术手段,有效而精准地刻画租户副本粒度的处理资源使用指标,从而促进数据库的部署和性能提升。
发明内容
鉴于上述问题,本说明书提供了一种训练预测模型,以及通过该模型预测资源使用量的方法,通过拟合租户对其数据副本的访问流量与资源使用量之间的关系,有效而精准地刻画租户副本粒度的处理资源使用指标,促进数据库的资源部署和性能提升。
根据第一方面,提供一种训练预测模型的方法,包括:
获取服务器集群中目标服务器在历史时段中对处理资源的目标使用量,以及多个数据副本对应的多条流量数据,所述多个数据副本是所述目标服务器中存储的租户数据副本;其中任意数据副本对应的流量数据包括,对应租户在所述历史时段中访问与该数据副本对应的数据而产生的流量信息;
将各条流量数据输入预测模型,得到各个数据副本对所述处理资源的预测使用量;
将各个预测使用量之和,作为预测总使用量,根据所述目标使用量和所述预测总使用量,确定预测损失;
以预测损失最小化为目标,更新所述预测模型。
典型的,上述处理资源为CPU资源。
根据一种实施方式,预测模型可以包括,第一模型和第二模型;所述多个数据副本包括第一数据副本。相应的,将各条流量数据输入预测模型,得到各个数据副本对所述处理资源的预测使用量,具体包括:将所述第一数据副本对应的第一流量数据输入所述预测模型,通过所述第一模型预测,处理所述第一数据副本自身导致的对所述处理资源的第一使用量,通过所述第二模型预测,与所述第一数据副本相关的服务器间通信导致的对所述处理资源的第二使用量;将所述第一使用量和第二使用量之和,确定为所述第一数据副本的预测使用量。
进一步的,在一个实施例中,第一模型可以包括与预设的多个租户组对应的多个模型版本;在这样的情况下,将第一数据副本对应的第一流量数据输入所述预测模型,具体包括:确定所述第一数据副本所属的第一租户在所述预设的多个租户组中所归属的目标租户组;将所述第一流量数据输入目标版本的第一模型,所述目标版本是所述多个模型版本中与所述目标租户组对应的模型版本。
在一个示例中,上述第一流量数据可以包括:每秒查询数QPS,每秒事务数TPS,逻辑读,IO通信量。
根据一个实施例,第一流量数据至少包括:第一数据副本对应的主副本的第一流量指标,并且所述第二模型包括与多个副本类型相对应的多个子模型。在这样的情况下,将第一数据副本对应的第一流量数据输入所述预测模型,具体包括:将所述第一流量指标输入目标子模型,所述目标子模型是所述多个子模型中与所述第一数据副本的副本类型对应的子模型。
根据一个示例,上述多个副本类型可以包括:主副本,只读副本,日志副本。
根据一个具体示例,上述与主副本类型对应的主副本子模型具有与预设的多个租户组对应的多个子模型版本;相应的,将第一流量指标输入目标子模型,包括:当所述目标子模型为主副本子模型时,确定所述第一数据副本所属的第一租户在所述预设的多个租户组中所归属的目标租户组;将所述第一流量指标输入目标子模型版本的主副本子模型,所述目标子模型版本是所述多个子模型版本中与所述目标租户组对应的版本。
根据第二方面,提供了一种预测服务器的资源使用量的方法,包括:
获取根据第一方面的方法训练得到的预测模型;
获取待评估的目标数据副本对应的目标流量数据,其中,所述目标数据副本存储于服务器集群中的某一服务器中,所述目标流量数据包括,目标租户在待评估的当前时段中访问与该目标数据副本对应的数据而产生的流量信息;
将所述目标流量数据输入所述预测模型,得到所述目标数据副本对所述某一服务器的处理资源的预测使用量。
根据第三方面,提供了一种训练预测模型的装置,包括:
数据获取单元,配置为获取服务器集群中目标服务器在历史时段中对处理资源的目标使用量,以及多个数据副本对应的多条流量数据,所述多个数据副本是所述目标服务器中存储的租户数据副本;其中任意数据副本对应的流量数据包括,对应租户在所述历史时段中访问与该数据副本对应的数据而产生的流量信息;
预测输入单元,配置为将各条流量数据输入预测模型,得到各个数据副本对所述处理资源的预测使用量;
损失确定单元,配置为将各个预测使用量之和,作为预测总使用量,根据所述目标使用量和所述预测总使用量,确定预测损失;
模型更新单元,配置为以预测损失最小化为目标,更新所述预测模型。
根据第四方面,提供了一种预测服务器的资源使用量的装置,包括:
模型获取单元,配置为获取根据第三方面的装置训练得到的预测模型;
数据获取单元,配置为获取待评估的目标数据副本对应的目标流量数据,其中,所述目标数据副本存储于服务器集群中的某一服务器中,所述目标流量数据包括,目标租户在待评估的当前时段中访问与该目标数据副本对应的数据而产生的流量信息;
预测单元,配置为将所述目标流量数据输入所述预测模型,得到所述目标数据副本对所述某一服务器的处理资源的预测使用量。
根据第五方面,提供了一种计算机可读存储介质,其上存储有计算机程序,当所述计算机程序在计算机中执行时,令计算机执行第一方面或第二方面所述的方法。
根据第六方面,提供了一种计算设备,包括存储器和处理器,其特征在于,所述存储器中存储有可执行代码,所述处理器执行所述可执行代码时,实现第一方面或第二方面所述的方法。
在本说明书实施例中,通过多元回归的方式充分拟合租户对其数据副本的访问流量与资源使用量之间的关系,得到用于预测资源使用量的预测模型。基于该预测模型,可以准确地评估出租户副本粒度的资源使用情况。
附图说明
为了更清楚地说明本发明实施例的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其它的附图。
图1示出服务器集群的数据存储示意图;
图2示出根据一个实施例训练预测模型的方法流程图;
图3示出根据一个实施例训练预测模型的过程示意图;
图4示出根据一个实施例的预测模型的结构和预测过程示意图;
图5示出根据一个实施例服务器的资源使用量的方法流程图;
图6示出根据一个实施例训练预测模型的装置示意图;
图7示出根据一个实施例预测服务器的资源使用量的装置示意图。
具体实施方式
下面结合附图,对本说明书提供的方案进行描述。
图1示出服务器集群的数据存储示意图。如图所示,多个服务器(server)形成一个服务器集群,作为数据库的存储空间。具体地,图1中的服务器集群包括m个服务器:{S1,S2,…,Sm},其中任意服务器Si可以理解为单台设备或机器。一个服务器上可以有多个租户的数据,该多个租户表示为t1,t2,…tn。每个租户的数据具有多个数据副本,多个数据副本分布在不同服务器中。实践中,常常将数据副本称为un it,则每个租户具有多个un its。例如,租户t1的数据具有数据副本u11,u12,u13,分别部署在服务器S1,S2,Sm中,租户t2的数据具有数据副本u21,u22,u23,分别部署在服务器S1,S2,S3中,等等。在图1中,还以不同的背景示出不同的副本类型,例如白色块表示主副本,灰色块表示从副本/只读副本,斜线阴影块表示日志副本。
可以理解,在图1中,以横向表示租户维度,以纵向表示服务器维度,简要示出服务器、租户、副本之间的拓扑结构。实践中,数据副本在服务器集群中的分布存储可以更加复杂。例如,在一种典型的数据库中,租户数据具有5个数据副本,集群中服务器的数量m可以是几十或几百数量级,而租户数量n可以是几十万的量级。取决于各个服务器的存储能力,单个服务器上通常不会存储所有租户的数据副本;单个租户的k个数据副本根据部署需要,存储于k个服务器中。
根据图1所示,一个服务器中存储有多个租户的多个数据副本。如果直接对服务器的资源使用情况进行监测,例如监测其CPU使用量,内存使用量,对磁盘的读写等,得到的指标结果是该服务器的总体资源使用量,是其上所有租户副本共同作用的结果,而无法获知单个副本的资源使用情况。
在一种相关技术中,对于单个服务器,通过统计一段时间内针对某个租户副本分配的线程运行时间的占比,来评估该租户副本对该单个服务器的CPU消耗。然而,线程粒度的CPU资源监测对于租户副本的CPU使用情况的评估还不够准确。对于租户副本粒度的资源使用情况的精准刻画,仍是亟待解决的技术难题。
为此,发明人经过研究和分析,在本说明书中提出一种改进方案,通过多元回归的方式充分拟合租户对其数据副本的访问流量与资源使用量之间的关系,得到用于预测资源使用量的预测模型。基于该预测模型,可以在线地评估出租户副本粒度的资源使用情况。下面详细描述该改进方案的实施方式。
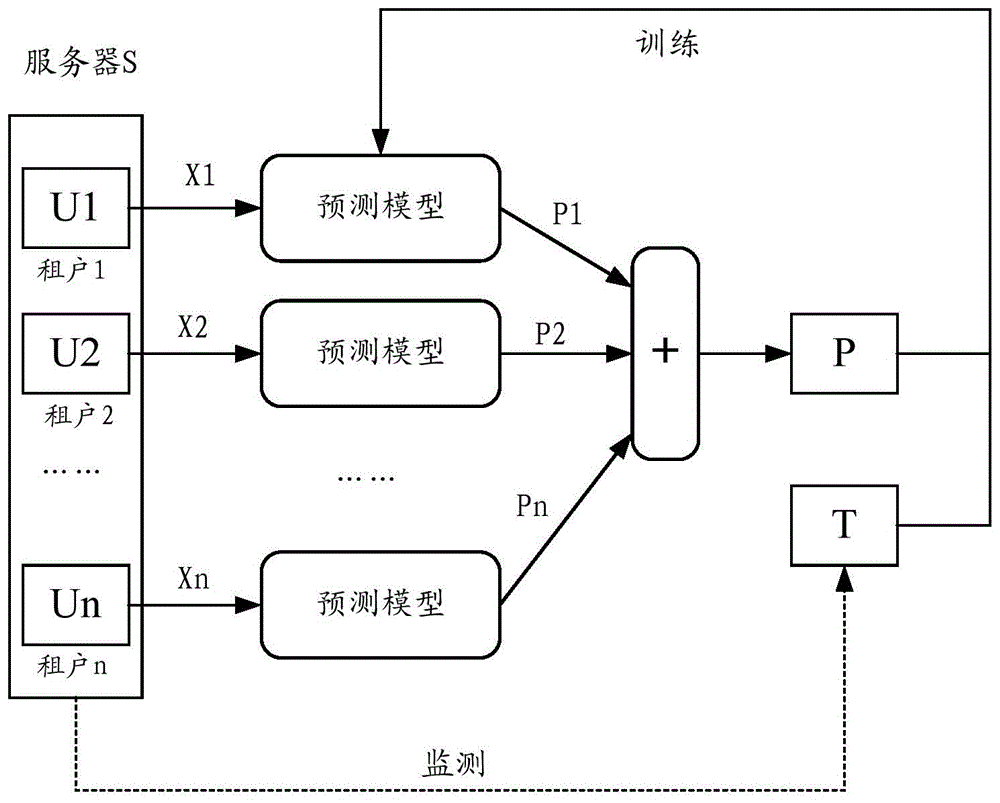
图2示出根据一个实施例训练预测模型的方法流程图。该方法可以通过任何具有计算、处理能力的计算单元、平台、服务器、设备等执行。图3示出根据一个实施例训练预测模型的过程示意图。下面结合图2和图3,描述上述训练方法的具体步骤。
首先,在步骤21,获取服务器集群中目标服务器在历史时段中对处理资源的目标使用量,以及多个数据副本对应的多条流量数据,其中多个数据副本是所述目标服务器中存储的租户数据副本;其中任意数据副本对应的流量数据包括,对应租户在所述历史时段中访问与该数据副本对应的数据而产生的流量信息。
需理解,上述服务器集群可以是如图1所示的形成分布式数据库的集群,目标服务器可以是该服务器集群中任意一个服务器。在图3中,将该目标服务器表示为服务器S。可以通过常规监测手段,监测获得该目标服务器S在指定历史时段中对处理资源的使用量,即目标使用量T。具体的,历史时段可以是分钟级别。该目标使用量T可以是CPU资源的使用量,内存资源的使用量,等等。后续的实施例主要结合CPU使用量的例子进行描述。但是需理解,处理资源也可以推广至其他与副本处理和部署有关的服务器资源。
上述步骤21中的多个数据副本是目标服务器S中存储的租户数据副本。在图3的示例中,该多个数据副本即为,租户1的数据副本U1,租户2的数据副本U2,…,租户n的数据副本Un。可以通过监测各个租户在前述历史时段中对服务器集群的访问,获得任意数据副本Ui对应的流量数据Xi,其中该流量数据Xi包括,对应的租户t i在前述历史时段中访问与该数据副本Ui对应的数据而产生的流量信息,这些流量信息可以包括每秒查询数QPS(Queries Per Second),每秒事务数TPS(Transact ions Per Second),逻辑读,IO通信量,等等。
接着,在步骤22,将各条流量数据输入预测模型,得到各个数据副本对处理资源的预测使用量。
具体的,如图3所示,可以将任意数据副本Ui对应的流量数据Xi输入预测模型,通过该预测模型输出,对应数据副本Ui对处理资源的预测使用量Pi。于是,得到数据副本U1,U2…Un分别对应的预测使用量P1,P2,…Pn。
于是,在步骤23,确定各个预测使用量之和,作为预测总使用量,并根据目标使用量和预测总使用量,确定预测损失。
如图3所示,将各个数据副本分别对应的预测使用量P1,P2,…Pn求和,得到预测总使用量P。该预测总使用量P是通过预测模型预测的各个数据副本的资源使用量之和,因此可以表征对目标服务器在历史时段中使用处理资源的预测使用量。而目标使用量T是通过监测目标服务器的资源使用情况得到的真实使用量。将预测使用量P与目标使用量T相比较,可以得到预测损失,其反映模型预测结果与真实情况的差距。
从而可以在步骤24,以预测损失最小化为目标,更新预测模型。
可以理解,通过监测和统计大量历史时段中各个服务器的真实资源使用量,以及监测和统计对应历史时段中租户访问其副本数据的流量数据信息,可以获得大量的统计数据作为训练样本。利用这些训练样本,按照上述步骤21-24,可以反复训练、更新预测模型,直到达到一定停止条件(例如,预测损失足够小,迭代轮次足够多,等等),此时获得训练好的预测模型。
以上预测模型,可以拟合租户访问其副本的流量数据与该副本的资源使用量之间的关系。从模型结构或算法上,上述预测模型可以通过多种方式实现。
在一个实施例中,上述预测模型通过深度神经网络DNN实现,该深度神经网络通过其输入层接收租户副本Ui对应的流量数据Xi,通过中间隐藏层对流量数据进行多层处理,通过输出层输出一个回归值,作为对副本的资源使用量的预测值Pi。
在另一实施例中,考虑到租户数据副本的处理特点以及模型的可解释性,通过两个子模型,共同构成上述预测模型。这两个子模型在下文中称为第一模型和第二模型,其中第一模型用于预测,处理单个数据副本自身导致的对处理资源的使用量,第二模型用于预测,租户访问引起的集群内服务器间通信导致的处理资源的使用量。下面结合图4描述预测模型的结构和对流量数据的处理。
图4示出根据一个实施例的预测模型的结构和预测过程示意图。如图所示,预测模型包括第一模型401和第二模型402。当将租户副本Ui对应的流量数据Xi输入该预测模型,第一模型401输出处理该数据副本Ui自身导致的对处理资源的第一使用量Y1,第二模型402输出,与数据副本Ui相关的服务器间通信导致的对处理资源的第二使用量Y2。将第一使用量Y1和第二使用量Y2求和,作为预测模型的输出,即该数据副本Ui的预测使用量Pi。
下面分别描述第一模型和第二模型的处理特点。
如前所述,第一模型401用于预测处理数据副本自身导致的资源使用量,即第一使用量。实践中,该资源使用量通常与租户所属的不同租户组相关,因此,该第一模型401又可以称为租户组模型。租户组模型可以具有与预设的多个租户组对应的多个模型版本,一个模型版本对应一套模型参数。例如,若服务器集群针对其服务的租户划分为3个租户组A,B,C,则该租户组模型401具有对应于租户组A,B,C的3个模型版本a,b,c。
对于当前待评估的租户副本Ui,可以首先确定该数据副本Ui的租户t i在预设的多个租户组中所归属的目标租户组;然后,将租户副本Ui对应的流量数据Xi输入与目标租户组对应版本的租户组模型。例如,若租户t i属于租户组B,则将流量数据Xi输入与租户组B对应版本的租户组模型,即版本b的租户组模型。
输入租户组模型的流量数据Xi可以包括对应租户t i访问其副本数据的多维流量指标,具体例如包括,每秒查询数QPS(Quer ies Per Second),每秒事务数TPS(Transactions Per Second),逻辑读,IO通信量,等等。在一些实施例中,输入第一模型的流量数据也可以包括以上列举的指标的一部分。对应版本的租户组模型对输入其中的多维流量指标进行模型处理,输出第一使用量Y1,其指示租户t i的数据副本Ui自身对处理资源的使用量。
第二模型402用于预测,与数据副本Ui相关的服务器间通信导致的处理资源的使用量,即第二使用量。第二使用量的产生,是由不同副本类型之间的数据同步需求导致的,与待评估的数据副本的副本类型相关,因此,该第二模型402又可以称为副本类型模型。
本领域技术人员可以理解的是,不同类型的数据副本处理的任务不完全一致。例如,日志副本用来记录数据库表的增、删、改等操作,一般情况下不处理流量请求。只读副本只处理QPS查询流量(例如,sq l_se lect_count),不处理TPS流量。TPS流量例如包括以下sq l请求/操作:sq l_de lete_count,sq l_de lete_rt,sq l_update_count,sq l_update_rt,sq l_insert_count,sq l_insert_rt。而存储主副本的主节点则可以处理TPS和QPS流量。换而言之,只有主副本可以处理TPS流量。在租户请求访问其租户数据时,取决于租户所请求的处理操作以及被路由到的服务器,存储不同类型数据副本的不同服务器之间往往需要进行数据同步和通信,租户的非主副本类型的数据副本会受主副本的TPS流量影响。
基于以上考虑,为了评估第二使用量,可以获取当前有待评估的数据副本Ui所对应的主副本的流量指标X-pr i,该流量指标可以是主副本独有的流量指标,例如TPS指标,将该流量指标X-pr i作为第二模型402的输入。需要理解的是,在服务器集群中,各个服务器在存储数据副本的同时,还会记录有该数据副本的元数据,其中包括,数据副本Ui所属的租户t i,对应的租户组,Ui的副本类型等等。因此,服务器集群可以容易地确定出属于同一租户t i的不同副本类型的各个数据副本在服务器中的存储分布。通过监测同一时段中各个服务器的流量数据,可以获知同一租户t i的各个副本类型各自的流量数据,其中包括,数据副本Ui(其本身可能是主副本,也可能是其他类型的数据副本)所对应的主副本的TPS流量指标。
进一步地,第二模型402被设置为,具有与多个副本类型相对应的多个子模型。如图4所示,第二模型(即副本类型模型)402具有3个子模型,分别对应于日志型副本,主副本,只读型副本。需要理解的是,上述副本类型可以基于不同副本执行的任务特点根据需要进行划分,而不限于图4所示的划分示例。例如,在OB数据库具有5个数据副本的部署方式下,可以直接将5个数据副本作为5种副本类型。其他数据库也可以具有其对应的副本类型划分方式。
如此,在利用第二模型402进行预测时,首先确定待评估的数据副本Ui的副本类型,将前述的模型输入数据,即数据副本Ui所对应的主副本的流量指标X-pr i,输入目标子模型中,该目标子模型是第二模型的多个子模型中与数据副本Ui的副本类型对应的子模型。例如,当数据副本Ui为日志型副本,则将上述主副本的TPS流量数据输入日志副本子模型中;当数据副本Ui为只读型副本,则将上述主副本的TPS流量数据输入只读副本子模型中;当数据副本Ui为主副本,则将上述主副本的TPS流量数据输入主副本子模型中。
进一步的,在一个实施例中,在第二模型的多个子模型中,与主副本类型对应的主副本子模型可以具有与预设的多个租户组对应的多个子模型版本,每个版本对应一套子模型参数。在这样的情况下,当有待评估的数据副本Ui是主副本时,在将主副本的TPS流量数据输入该主副本子模型前,还需先确定要使用的主副本子模型的版本。即,确定该数据副本Ui所属的租户t i在预设的多个租户组中所归属的目标租户组,然后,将主副本的流量指标X-pr i输入与该目标租户组对应版本的主副本子模型中。例如,若预设的租户组包括A,B,C三个组,则第二模型402的主副本子模型具有对应的3个子模型版本a’,b’,c’。若当前待评估的租户副本Ui是主副本类型,而对应的租户t i属于租户组B,则将主副本的流量指标X-pr i输入与租户组B对应版本的主副本子模型中,即版本b’的主副本子模型。
因此,对于第二模型(副本类型模型)402而言,其输入数据为待评估的数据副本Ui对应的主副本的流量指标X-pr i;数据副本Ui本身的副本类型用于确定采用第二模型402的哪个子模型;租户组信息用于在采用主副本子模型的情况下,确定所使用的子模型版本。通过副本类型信息以及租户组信息,确定出所采用的具体子模型,利用该具体子模型处理输入的主副本流量指标X-pr i,得到第二使用量Y2,其指示与数据副本Ui相关的服务器间通信导致的处理资源使用量。
如前所述,第一使用量Y1和第二使用量Y2之和,可以作为该数据副本Ui对处理资源的预测使用量Pi。
需要理解,以上单个数据副本Ui的第一使用量Y1、第二使用量Y2甚至预测使用量Pi都没有各自单独对应的标签数据(即对应的真实使用量);可以监测获得的真实使用量只有服务器整体的目标使用量T。因此,如图3所示,通过将服务器中各个数据副本的预测使用量之和与目标使用量进行对比,来训练整个预测模型,即对第一模型401和第二模型402进行联合训练。这里对第一模型401和第二模型402内部的结构和算法不做限定。
在通过以上方式完成对预测模型的训练之后,可以存储对应的模型文件,以供在线预测服务调用。如此,在在线阶段,可以基于以上训练好的预测模型,提供租户副本的资源使用预测服务。下面描述利用预测模型进行资源使用情况预测的过程。
图5示出根据一个实施例服务器的资源使用量的方法流程图。该方法可以通过任何具有计算、处理能力的计算单元、平台、服务器、设备等执行。如图5所示,该预测方法包括以下步骤。
在步骤51,获取根据前述方式训练得到的预测模型。具体的,在该步骤,可以读取和加载已经训练好的预测模型的模型文件。
在步骤52,获取待评估的目标数据副本Ux对应的目标流量数据X,其中,该目标数据副本Ux存储于服务器集群中的某一服务器中,对应的目标流量数据X包括,目标租户tx在待评估的当前时段中访问与该目标数据副本Ux对应的数据而产生的流量信息。在一个具体示例中,目标流量数据X包括:每秒查询数QPS,每秒事务数TPS,逻辑读,IO通信量等。
然后,在步骤53,将上述目标流量数据X输入获取的预测模型,得到该目标数据副本Ux对所在服务器的处理资源的预测使用量Px。典型的,该处理资源为CPU资源。
在一种实施方式中,预测模型实现为深度神经网络DNN。在这样的情况下,通过输入层将目标流量数据X输入深度神经网络,DNN通过其中间隐藏层对流量数据进行多层处理,直接输出对目标数据副本Ux的资源使用量的预测值Px。
在另一种实施方式中,预测模型包括第一模型和第二模型;在这样的情况下,将目标流量数据X输入所述预测模型,通过第一模型预测得到,处理该目标数据副本Ux自身导致的对处理资源的第一使用量Y1,通过第二模型预测得到,与目标数据副本Ux相关的服务器间通信导致的对处理资源的第二使用量Y2。于是,可以将第一使用量Y1和第二使用量Y2之和,确定为预测使用量Px。
更具体的,在一个实施例中,第一模型包括与预设的多个租户组对应的多个模型版本。在这样的情况下,可以确定目标租户tx在预设的多个租户组中所归属的目标租户组;从而将目标流量数据X输入与该目标租户组对应版本的第一模型中。
在一个实施例中,目标流量数据包括:目标数据副本Ux对应的主副本的流量指标。并且,所述第二模型包括与多个副本类型相对应的多个子模型。该多个副本类型例如包括:主副本,只读副本,日志副本。此时,利用第二模型对目标流量数据的处理可以包括:将上述主副本的流量指标输入目标子模型,该目标子模型是所述多个子模型中与目标数据副本Ux的副本类型对应的子模型。
进一步的,在一个实施例中,与主副本类型对应的主副本子模型可以具有与预设的多个租户组对应的多个子模型版本。在这样的情况下,当目标数据副本Ux为主副本时,还需确定目标租户tx在预设的多个租户组中所归属的目标租户组;从而将主副本的流量指标输入与所述目标租户组对应版本的主副本子模型中。
第一模型和第二模型对目标流量数据X的处理过程,与结合图4描述的训练阶段的处理过程相似,在此不复赘述。
如此,通过训练好的预测模型,可以根据数据副本的流量信息,准确评估出副本粒度的资源使用情况。由此,可以便于服务器集群对处理资源的扩缩容、调度、部署等工作,提升数据库性能。
根据另一方面的实施例,与图2所示的训练方法相对应的,本说明书还提供一种训练预测模型的装置,该装置可以部署在任何具有计算、处理能力的计算单元、平台、服务器、设备中。图6示出根据一个实施例训练预测模型的装置示意图。如图6所示,该装置600包括:
数据获取单元61,配置为获取服务器集群中目标服务器在历史时段中对处理资源的目标使用量,以及多个数据副本对应的多条流量数据,所述多个数据副本是所述目标服务器中存储的租户数据副本;其中任意数据副本对应的流量数据包括,对应租户在所述历史时段中访问与该数据副本对应的数据而产生的流量信息;
预测输入单元62,配置为将各条流量数据输入预测模型,得到各个数据副本对所述处理资源的预测使用量;
损失确定单元63,配置为将各个预测使用量之和,作为预测总使用量,根据所述目标使用量和所述预测总使用量,确定预测损失;
模型更新单元54,配置为以预测损失最小化为目标,更新所述预测模型。
以上装置的各个单元,可以配置用来执行图2的方法步骤,具体执行过程可以参照之前结合图2的描述,不复赘述。
根据又一方面的实施例,与图5所示的预测方法相对应的,本说明书还提供一种预测服务器的资源使用量的装置,该装置可以部署在任何具有计算、处理能力的计算单元、平台、服务器、设备中。图7示出根据一个实施例预测服务器的资源使用量的装置示意图。如图7所示,该装置700包括:
模型获取单元71,配置为获取根据前述装置训练得到的预测模型;
数据获取单元72,配置为获取待评估的目标数据副本对应的目标流量数据,其中,所述目标数据副本存储于服务器集群中的某一服务器中,所述目标流量数据包括,目标租户在待评估的当前时段中访问与该目标数据副本对应的数据而产生的流量信息;
预测单元73,配置为将所述目标流量数据输入所述预测模型,得到所述目标数据副本对所述某一服务器的处理资源的预测使用量。
以上装置的各个单元,可以配置用来执行图5的方法步骤,具体执行过程可以参照之前结合图5的描述,不复赘述。
根据其他方面的实施例,还提供一种计算机可读存储介质,其上存储有计算机程序,当所述计算机程序在计算机中执行时,令计算机执行前述结合图2或图5描述的方法。
根据再一方面的实施例,还提供一种计算设备,包括存储器和处理器,该存储器中存储有可执行代码,所述处理器执行所述可执行代码时,实现前述结合图2或图5描述的方法。
本领域技术人员应该可以意识到,在上述一个或多个示例中,本发明所描述的功能可以用硬件、软件、固件或它们的任意组合来实现。当使用软件实现时,可以将这些功能存储在计算机可读介质中或者作为计算机可读介质上的一个或多个指令或代码进行传输。
以上所述的具体实施方式,对本发明的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本发明的具体实施方式而已,并不用于限定本发明的保护范围,凡在本发明的技术方案的基础之上,所做的任何修改、等同替换、改进等,均应包括在本发明的保护范围之内。