基于二进制蜻蜓算法的近红外模型传递标样集挑选方法
文献发布时间:2023-06-19 19:28:50
技术领域
本发明属于近红外模型传递标样集优选方法技术领域,具体涉及一种基于二进制蜻蜓算法的近红外模型传递标样集挑选方法。
背景技术
现代近红外光谱分析技术是一种绿色、高效、低成本的无损快速分析技术,经过半个多世纪的发展,目前已达到较为成熟的水平,被广泛地应用于农业、食品、医药和石化等领域。利用蛋白质分子中的C-H、N-H、O-H、C-O等化学键的泛频振动或转动对近红外光的吸收特性,近红外光谱分析技术在小麦粉蛋白质含量测定方面已取得一定成效。然而在实际应用中,由于样品状态、仪器性能或环境背景的差异,一台近红外光谱仪器上建立的模型往往不能直接应用于另一台仪器,进而影响了近红外光谱预测模型的准确性和通用性。因此,模型传递对于近红外光谱分析技术的实际应用具有重要意义。
近红外光谱的模型传递又称近红外光谱仪器的标准化,主要是用数学运算相关知识求解出两台或两台以上光谱仪测得的光谱数据之间的转换矩阵,进而实现不同仪器上测得的光谱数据的标准化。实现模型传递的方法主要分为有标样和无标样两类。其中,有标样法需要在主、从仪器上测得的光谱数据中选择一定数量的标样集,通过其建立主、从仪器之间光谱转换的数学模型,主要包括直接校正(Direct Standardization,DS)、分段直接校正(Piecewise Direct Standardization,PDS)、Slop/Bias、典型相关分析(CanonicalCorrelation Analysis,CCA)以及Shenk’s等算法。无标样法则不需要标样集,主要包括有限脉冲响应算法(Finite Impulse Response,FIR)等。
在有标样模型传递方法中,标样集的挑选很大程度上影响模型传递的效果,常用的标样集挑选方法有Kennard/Stone(K/S)法、杠杆点算法(Lev)和Maximizes theSmallest Inter-point Distance算法(MSID)。尽管这些常规的方法可以基于光谱特征挑选出具有一定代表性的样品,但Lev法对样品的不同组份浓度分布比较敏感,当预测集样品超出标样集的空间时会出现奇异噪声;MSID法算法复杂,计算时间长,对模型传递的效率有一定影响;相较而言,K/S方法使用光谱间的欧氏距离或主成分之间的距离来选择代表性样品,不易受干扰且计算量较少,被广泛应用于模型传递实验中。然而,K/S算法挑选样品集时本身具有在特征空间中均匀取样和首选极值的特性,因此进行挑选标样集时,会将某些极端值样品选进标样集,一定程度上影响模型传递效果,具有一定的局限性。
发明内容
有鉴于此,本发明提供一种基于二进制蜻蜓算法的近红外模型传递标样集挑选方法,该方法与传统的K/S方法挑选标样集的模型传递方法相比,挑选的标样集规模更小,其所包含的信息能更充分表征仪器间的光谱差异,用于模型传递后预测精度有所提高。
本发明提供了一种基于二进制蜻蜓算法的近红外模型传递标样集挑选方法,采用的技术方案为:
一种基于二进制蜻蜓算法的近红外模型传递标样集的挑选方法,将近红外模型传递标样集的挑选抽象为二进制优化问题,利用蜻蜓算法进行求解,并引入策略来保证优化的全局性和收敛速度,筛选出最优的标样集。
将近红外模型传递标样集的挑选抽象为二进制优化问题包括:
标样集的挑选,将校正集划分为k个子集,k为校正集的样品个数;
构造一个长度为k的二进制序列M=[m
蜻蜓算法包括:
S1:初始化蜻蜓种群;
S2:蜻蜓个体适应度函数值评价;
S3:记录个体历史最优位置;
S4:记录全局历史最优位置;
S5:根据策略更新蜻蜓个体的位置,产生新的群体;
S6:判断是否满足停止条件,若满足,则结束并输出近红外模型传递标样集挑选优化结果;若不满足,则返回蜻蜓个体适应度函数值评价,进行循环计算,直至满足停止条件。
进一步的,S1所述的初始化蜻蜓种群为随机初始化,随机产生N个二进制序列的蜻蜓个体,组成初始种群S
进一步的,S2所述的适应度函数值为预测标准偏差(RMSEP),根据已经建立好的主仪器校正模型对从仪器的验证集经直接校正算法传递后的光谱矩阵X
(1)计算转换矩阵F
F
其中,X
(2)计算传递后的光谱矩阵X
X
其中,X
(3)用已经建立好的主仪器校正模型对X
进一步的,S3所述的计算个体历史最优位置,是将种群中的所有蜻蜓个体按照适应度函数值大小进行排序,适应度函数值最优的蜻蜓个体的位置作为个体历史最优位置。
进一步的,S5所述的根据策略更新蜻蜓个体的位置是指,若蜻蜓个体M
(1)分离:
(2)结队:
(3)聚集:
(4)觅食:F
(5)避敌:E
在连续的搜索空间中,蜻蜓算法的搜索代理通过在位置向量上添加步进向量来更新种群个体的位置,而在离散搜索空间中,位置向量只能赋值为0或1,利用传递函数将蜻蜓算法从连续域转换到离散域,再将传递函数接收的速度值作为输入并输出一个0或1的数字,表示位置变化的概率。V型传递函数如下:
用传递函数得出位置变化率后使用位置公式更新蜻蜓在空间中的搜索位置:
其中,r为[0,1]之间的随机数,负号表示逻辑取反运算。
进一步的,S2~S5中主仪器模型的评价指标为决定系数(R
其中,y
其中,y
其中,y
进一步的,S6所述的停止条件为最大迭代次数。
有益效果
与传统的K/S方法挑选近红外模型传递标样集相比,本方法以标样集自身作为决策变量,经模型传递后从机验证集的RMSEP为适应度函数值,直接在校正集样本空间中全局优化最优标样集,克服了K/S算法挑选的标样集是基于样品的差异而不能集中反映仪器之间的差异、挑选时具有在特征空间中均匀取样和首选极值的不足;与粒子群算法、遗传算法等群智能优化算法相比,二进制蜻蜓算法在实施中需要分离、结队、聚集、觅食、避敌等因子在一定范围内能自动随机取值并收敛,减少了人为干预,从而可为小麦粉近红外模型传递标样集挑选过程提供方便、可靠和有效的方法;此外,基于二进制蜻蜓算法经过多次迭代所挑选的标样集少而精干,不仅降低了模型传递的复杂度,也提高了主机模型对从机光谱数据的预测精度。
附图说明
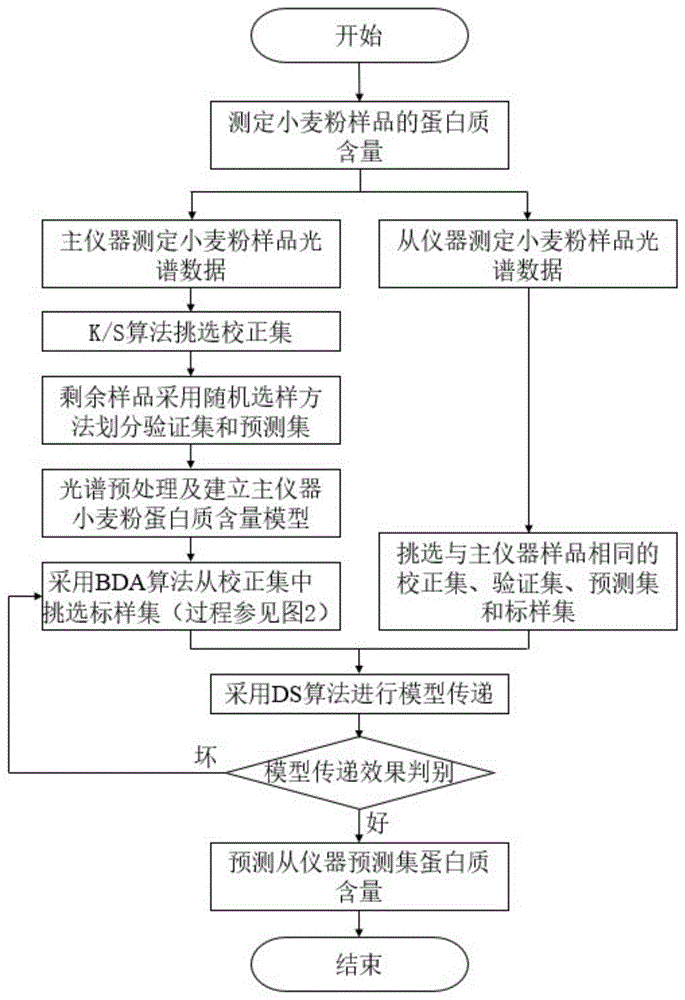
图1是本发明实施例的流程图;
图2是采用BDA算法从校正集中挑选标样集的流程图;
图3是BDA-DS算法迭代过程中验证集RMSEP值变化图;
图4是K/S-DS方法预测集RMSEP值随标样集样品个数变化图;
图5是10次BDA-DS实验中入选标样集的样品出现频次图;
图6是标样集主成分分布图。
具体实施方式
为了便于本领域普通技术人员理解和实施本发明,下面结合附图及实施例对本发明作进一步的详细描述,应当理解,此处所描述的实例仅用于说明和解释本发明,并不限定于本发明。
请见图1,本发明提供的一种基于二进制蜻蜓算法的近红外模型传递标样集挑选方法,具体实施案例如下:
首先,主仪器和从仪器分别采集相同样品的近红外光谱数据,同时测定样品待测指标的化学值。本实施例采集从超市购买的不同品牌以及不同批次的126个小麦粉样品。使用棱光S450(主仪器)和NeoSpectra Micro(从仪器)两台近红外光谱仪进行小麦粉光谱采集,两台仪器的主要参数如表1所示。将面粉样品常温保存,并在室温(20~23℃)环境下不做任何前处理,分别采用棱光S450型和NeoSpectra Micro型近红外光谱仪采集小麦粉的近红外光谱。采集光谱时,面粉样品铺平样品池,按120°间隔采集得到三条不同检测点的光谱,取它们的平均作为该样品的最终采集光谱。本实施例按照GB 5009.5-2016食品安全国家标准中食品中蛋白质的测定的标准测定小麦粉的蛋白质含量。表2显示了本次样本小麦粉蛋白质含量的统计特征。
表1两台近红外光谱分析仪主要参数
表2样本小麦粉蛋白质含量的统计特征
然后,将收集到的光谱数据和化学值对应整理,将样品划分为校正集、验证集和预测集。本实施例先从主仪器全部样品集中用K/S方法挑选出76个样品作为校正集,再采用随机选样的方法把剩下的50个样品划分成验证集(30个)和预测集(20个)。从仪器的校正集、验证集和预测集的构建与主仪器一致。各样品集划分及其化学值分布如表3所示。校正集用来建立主仪器校正模型以及从中挑选标样集;验证集用于对采用BDA算法所挑选出的某一标样集的模型传递效果以适应度函数予以评价;预测集用来评估最终优选的标样集的模型传递性能和模型的泛化能力。
表3各样品集样品数量及其化学值分布
接着,对主仪器的校正集先进行光谱预处理,再用偏最小二乘回归(PLSR)法建立主仪器的小麦粉蛋白质含量校正模型,经留一法交叉验证确定最佳主成分数为8,模型交互验证决定系数为0.9743,RMSECV为0.3110。本实施例比较了均值中心化、标准化、归一化、Savitaky-Golay卷积平滑(S-G平滑)、一阶导数、二阶导数、标准正态变量变换(SNV)、去趋势、多元散射校正(MSC)及多种组合的预处理方法,最终选择的预处理方法为S-G平滑+SNV+去趋势的组合,以减少甚至消除无关的信息和噪声,后续利用该模型预测小麦粉蛋白质含量时,被预测的样品应先进行与主机校正集方法一致的预处理。
最后,使用二进制蜻蜓算法(Binary Dragonfly Algorithm,BDA)从校正集中优选标样集,并结合直接校正算法(Direct Standardization,DS)对从仪器样品进行模型传递,带入主仪器校正模型,得到从仪器样品预测集的预测结果。挑选标样集的流程请见图2,本实施例设置迭代次数50次,种群数1000,标样集样品数量最小为5,最大为30。由于BDA算法的优化过程及结果具有一定的随机性,不能保证每次都收敛到最优解,本实施例进行了10次BDA-DS实验(序号记为B1~B10),以便通过多次计算验证BDA-DS方法选择标样集的可行性。迭代过程中验证集RMSEP值变化如图3所示,每次实验迭代约40次后,算法收敛到当次寻优的最优解,此时标样集数量约8个左右,最多10个,最少6个,RMSEP均小于0.26,平均值为0.2407。
本实施例对比了BDA与K/S算法挑选标样集的模型传递方法,K/S法选择标样集样品数n分别取n=5,7,9,…,N(N最大取73),模型传递后预测集RMSEP如图4所示,当标样集个数为39时,模型传递预测效果最好(实验序号记为K11),R
表4 AE-BDA与K/S挑选标样集结合DS方法模型传递与预测效果比较
校正集样品在10次BDA-DS实验中入选标样集的样品出现频次如图5所示,其中,入选标样集超过6次的样品有3个,编号分别为94(6次)、96(8次)和127(7次),其中样品96和127也被实验K11(K/S-DS方法)挑选进标样集。从K11实验标样集中剔除这两个样本后用剩余标样集进行模型传递,得到对从仪器预测集的预测结果R
图6为实验B1和实验K11前两个主成分(PCA)分布图,使用PCA结合马氏距离对主仪器校正集进行异常样品识别,发现样品91为光谱残差界外异常样品。剔除实验K11标样集的样品91再进行模型传递,主仪器模型对从仪器预测集预测评价参数R
综合表4、图6得出,本发明提出的基于二进制蜻蜓算法的近红外模型传递标样集的挑选方法可以挑选出更少、更具有代表性的标样集,降低了模型传递的复杂度,提高了模型传递后预测结果的精度。应当理解的是,本说明书未详细阐述的部分均属于现有技术。应当理解的是,以上所述仅为本发明的较佳实施例而已,并非用于限定本发明的保护范围。凡在本发明的精神和原则之内,所做的任何修改、等同替换、变形等,均落入本发明的保护范围之内。