口语文本翻译的检测方法、翻译方法、装置及其存储介质
文献发布时间:2023-06-19 19:30:30
技术领域
本发明涉及自然语言处理、机器翻译技术领域,具体涉及一种口语文本翻译的检测方法、翻译方法、装置及其存储介质。
背景技术
神经机器翻译近年来取得了突飞猛进的发展,在书面语文本上可以获得可读性较好的翻译结果。但是在包含不流利现象的口语领域,由于机器翻译模型通常使用规范的书面语文本进行训练,当面对含有大量不流利噪声的口语文本时,训练数据和测试数据间的不匹配会造成翻译性能出现明显下降。这一问题限制了机器翻译在真实口语场景下的使用。这里所述的不流利现象是口语中特有的一种语言现象,是指说话人在表达交流过程中由于思考或被打断,使用与所述内容无关的内容,包括填充词(如:嗯、这个)、重复、修正(对前面的话进行自我修正)等成分。例如,“啊下面呢是我们呃我们现在的一些啊开放的就是我们的一些联系我们的联系方式”是一句包含不流利现象的口语表达,其实际想表达的内容是“下面是我们的一些联系方式”。如果翻译模型不加区分地对给定文本进行翻译就会翻译出大量不相关的内容甚至出现翻译错误。
目前处理不流利口语翻译的常用方法是在翻译之前对口语文本进行前处理操作,以减小口语文本与书面语文本之间的差别。其中,前处理方法通常采用不流利检测,即首先通过不流利检测模型识别并剔除句中的不流利成分,然后将得到的流利句子输入至机器翻译系统。不流利检测方法又可以分为四类:基于噪声信道模型的方法、基于依存分析的方法、基于序列标注的方法和基于编码器-解码器框架的方法。
然而使用不流利检测再进行机器翻译的级联方法,存在错误传递问题,并且不流利检测任务仍需要大量的数据训练额外的前处理模型,增加了计算开销和时间延迟。因此,如何在不增加前处理模块的基础上实现不流利口语的检测是需要解决的技术问题;另外如何提升机器翻译模型在不流利口语翻译场景下的翻译效果也是现有技术需要解决的技术问题。
发明内容
本发明的目的在于克服上述技术不足,提供一种口语文本翻译的检测方法、翻译方法、装置及其存储介质,解决现有技术中如何在不增加前处理模块的基础上实现不流利口语的检测的技术问题。
为达到上述技术目的,本发明的技术方案提供一种口语文本翻译的检测方法,包括以下步骤:
在模型编码器中,将包含不流利成分的口语文本输入模型编码器,进行不流利成分检测任务训练,得到不流利检测任务的损失函数。
进一步地,所述不流利成分检测任务训练包括:
输入包含不流利成分的口语文本,经过编码器编码得到每个输入口语文本中的词语对应的隐层表示,通过参数矩阵将隐层表示映射到不流利标签输出空间,预测出不流利标签序列,即预测每一个输入单词是否属于不流利成分。
进一步地,所述不流利成分的标签包括重复、修正、重新开始以及填充词。
进一步地,所述不流利检测任务的训练的数据集为
此外,本发明还提出一种口语文本翻译方法,包括以下步骤:
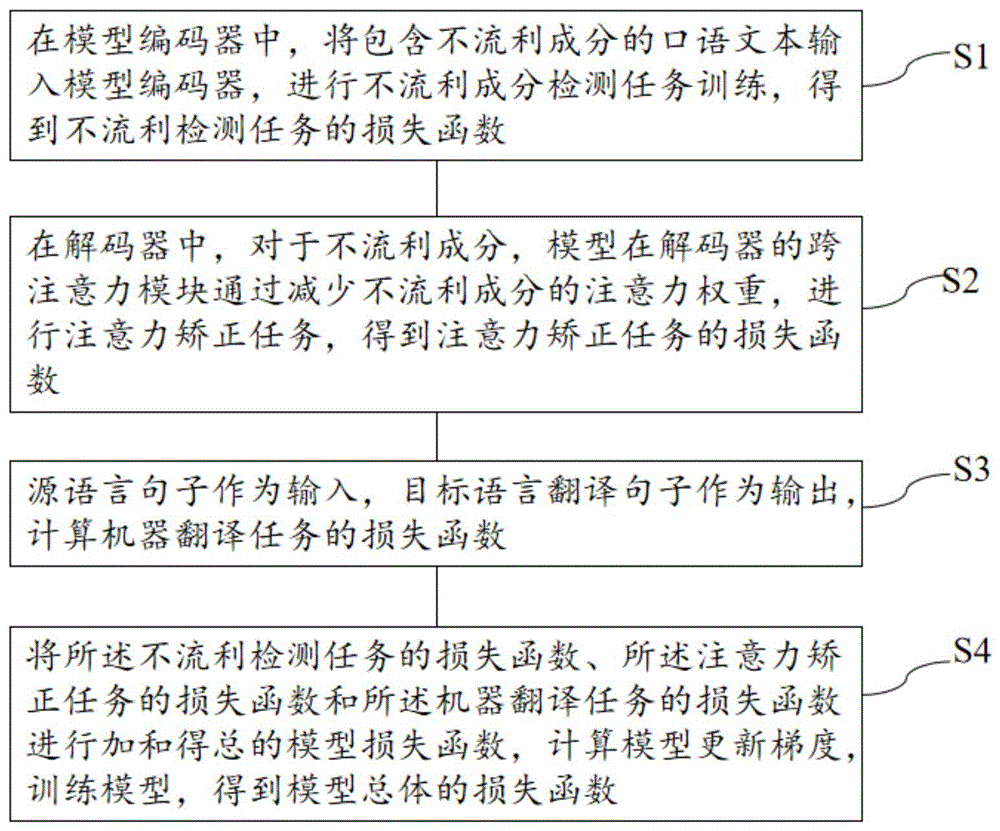
S1、在模型编码器中,将包含不流利成分的口语文本输入模型编码器,进行不流利成分检测任务训练,得到不流利检测任务的损失函数;
S2、在解码器中,对于不流利成分,模型在解码器的跨注意力模块通过减少不流利成分的注意力权重,进行注意力矫正任务,得到注意力矫正任务的损失函数;
S3、源语言句子作为输入,目标语言翻译句子作为输出,计算机器翻译任务的损失函数;
S4、将所述不流利检测任务的损失函数、所述注意力矫正任务的损失函数和所述机器翻译任务的损失函数进行加和得总的模型损失函数,计算模型更新梯度,训练模型,得到模型总体的损失函数。
进一步地,在步骤S2中,所述注意力矫正任务的损失函数为:
其中attn(y
进一步地,在步骤S2中,在获得所述注意力矫正任务的损失函数之前还包括:获得不流利成分的注意力权重之和,并将其作为损失函数,该损失函数为:
进一步地,在步骤S3中,所述机器翻译任务的损失函数为
此外,本发明还提出一种口语文本翻译装置,包括:
检测单元,用于在模型编码器中,将包含不流利成分的口语文本输入模型编码器,进行不流利成分检测任务训练,得到不流利检测任务的损失函数;
矫正单元,用于在解码器中,对于不流利成分,模型在解码器的跨注意力模块通过减少不流利成分的注意力权重,进行注意力矫正任务,得到注意力矫正任务的损失函数;
翻译任务损失单元,用于以源语言句子作为输入,目标语言翻译句子作为输出,计算机器翻译任务的损失函数;
加和单元,用于将所述不流利检测任务的损失函数、所述注意力矫正任务的损失函数和所述机器翻译任务的损失函数进行加和得总的模型损失函数,计算模型更新梯度,训练模型,得到模型总体的损失函数。
此外,本发明还提出一种存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现如上述所述的口语文本翻译的步骤。
与现有技术相比,本发明的有益效果包括:本发明提出的口语文本翻译的检测方法中,在模型编码器中,将包含不流利成分的口语文本输入模型编码器,进行不流利成分检测任务训练,得到不流利检测任务的损失函数,通过在模型编码器中预测不流利词语的位置和类别,辅助模型学习句子中流利成分和不流利成分之间的区别,在不增加前处理模块的基础上实现了不流利口语的检测,同时增强了编码器判别能力。
附图说明
图1是本发明本具体实施方式中的口语文本翻译方法的流程图。
图2是本发明本具体实施方式中的口语文本翻译装置的结构示意图。
具体实施方式
本具体实施方式提供一种口语文本翻译的检测方法,包括以下步骤:
在模型编码器中,将包含不流利成分的口语文本输入模型编码器,进行不流利成分检测任务训练,得到不流利检测任务的损失函数;所述不流利成分检测任务训练包括:
输入包含不流利成分的口语文本,经过编码器编码得到每个输入口语文本中的词语对应的隐层表示,通过参数矩阵将隐层表示映射到不流利标签输出空间,预测出不流利标签序列,即预测每一个输入单词是否属于不流利成分;所述不流利成分的标签包括重复、修正、重新开始以及填充词;所述不流利检测任务的训练的数据集为
结合图1,本具体实施方式还提出一种口语文本翻译方法,包括以下步骤:
S1、在模型编码器中,将包含不流利成分的口语文本输入模型编码器,进行不流利成分检测任务训练,得到不流利检测任务的损失函数;
S2、在解码器中,对于不流利成分,模型在解码器的跨注意力模块通过减少不流利成分的注意力权重,进行注意力矫正任务,得到注意力矫正任务的损失函数;所述注意力矫正任务的损失函数为:
其中attn(y
S3、源语言句子作为输入,目标语言翻译句子作为输出,计算机器翻译任务的损失函数;所述机器翻译任务的损失函数为
S4、将所述不流利检测任务的损失函数、所述注意力矫正任务的损失函数和所述机器翻译任务的损失函数进行加和得总的模型损失函数,计算模型更新梯度,训练模型,得到模型总体的损失函数;模型总体的损失函数为:L=L
此外,结合图2,本具体实施方式还提出一种口语文本翻译装置,包括:
检测单元,用于在模型编码器中,将包含不流利成分的口语文本输入模型编码器,进行不流利成分检测任务训练,得到不流利检测任务的损失函数;
矫正单元,用于在解码器中,对于不流利成分,模型在解码器的跨注意力模块通过减少不流利成分的注意力权重,进行注意力矫正任务,得到注意力矫正任务的损失函数;
翻译任务损失单元,用于以源语言句子作为输入,目标语言翻译句子作为输出,计算机器翻译任务的损失函数;
加和单元,用于将所述不流利检测任务的损失函数、所述注意力矫正任务的损失函数和所述机器翻译任务的损失函数进行加和得总的模型损失函数,计算模型更新梯度,训练模型,得到模型总体的损失函数。
另外,本具体实施方式还提出一种存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现上述口语文本翻译的步骤。
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
实施例1
为了提升神经机器翻译模型对于不流利口语文本的翻译质量,本实施例提出了一种基于多任务学习的不流利口语文本的翻译方法。整个模型基于Transformer模型模块(包含词嵌入层EmbeddingLayer、注意力机制Attention、前馈神经网络FFN),模型在训练过程中包含三个子任务,分别是不流利检测任务、注意力矫正任务和机器翻译任务。
步骤S1:在模型编码阶段,将包含不流利成分的口语文本输入模型编码器,进行不流利检测任务训练;
不流利检测任务采用序列标注的方式,输入包含不流利成分的文本x,经其中过编码器Enc编码得到Enc每个输入词语对应的隐层表示h
h
其中,不流利成分与标签对应关系为:RP一重复、RP一修正、RS一重新开始、FL一填充词,标签O表示非不流利成分,即句子正常表述的内容。这里对不同类型的不流利成分分配不同的标签,可以帮助模型学习不同类别的不流利成分之间的区别,例如“嗯”,“这个”等填充类现象应更加关注于该词本身,而修正类现象需要模型结合整句话的语义加以判断,两类现象具有不同的特点。
在整个不流利检测任务的训练数据集
步骤S2:在解码器中,对于不流利成分,模型在解码器进行跨注意力阶段(Cross-Attention)时,减少对其关注程度,进行注意力矫正任务。
由于源语言中的不流利成分不应出现在目标语言译文中,即源端不流利成分不对应任何译文片段,但这种连续词语的不对齐现象阻碍了翻译任务的学习,影响模型训练的速度。为此,本发明提出了一种针对不流利标签的注意力矫正机制。
在Transformer解码器中的编码器-编码器在跨注意力阶段,对于源语言句子中的每一个单词分配一个注意力权重,用于衡量翻译当前单词对于源端单词的关注程度。对于包含不流利成分的口语翻译,在翻译时应当给予源端不流利成分更低的注意力权重,避免其对译文产生影响。
对于注意力矫正任务,输入为包含不流利成分的源语言句子x=(x
Enc编码得到隐层向量
计算目标序列y中每个时刻t对于源语言句子x中每个不流利成分的注意力权重之和,将其作为损失函数,
其中使用
最终,在包含源语言句子、不流利标签和目标语言句子的数据集
步骤S3:输入为源语言句子,输出为目标语言翻译句子,计算机器翻译任务的损失;对于翻译任务,在整个翻译任务数据集
步骤S4:将上述三个步骤的损失的加和作为总的模型损失函数,计算模型更新梯度,训练模型;
L=L
神经机器翻译在通用书面语场景可以取得较好的翻译效果,但是在包含不流利现象的口语领域中,翻译性能往往会出现显著下降。在口语翻译场景中,神经机器翻译模型存在两个问题:编码器无法判别源语言文本中的不流利成分,将其统一编码为一种表示;解码器的注意力机制也难以对句子中的流利和不流利成分加以区分。为此本发明提出了一种融合不流利检测任务的神经机器翻译方法,通过引入不流利检测任务辅助模型识别句子中的不流利成分,并通过一个注意力矫正任务,引入额外的损失函数降低注意力机制对于不流利词语的关注程度,以此增强编码器和解码器在不流利口语文本上的建模能力。
本发明在口语翻译模型中引入了一种针对不流利文本翻译的辅助任务,并通过对注意力机制进行约束,提高了编码器和注意力模块对不流利现象的鲁棒性在中英真实口语翻译任务上的实验结果表明,所提方法可以有效提高神经机器翻译模型在不流利口语文本上的翻译质量。
以上所述本发明的具体实施方式,并不构成对本发明保护范围的限定。任何根据本发明的技术构思所做出的各种其他相应的改变与变形,均应包含在本发明权利要求的保护范围内。