一种针对未知变策略对手的博弈决策方法
文献发布时间:2024-04-18 20:01:30
技术领域
本发明涉及人工智能领域,具体涉及一种针对未知变策略对手的博弈决策方法。
背景技术
近年来,涵盖两人德州扑克等单对手游戏及Google足球等多对手游戏的多智能体游戏引起了广泛关注。在这些游戏中,一个核心问题就是如何设计有效的博弈决策方法以提升我方智能体的收益。现有博弈决策方法都假设对手策略已知且在博弈过程中保持不变,从而我方智能体可以训练出固定策略以应对对手的所有策略,确保我方预期收益下限;或者我方智能体可以训练出针对策略以应对对手的某些策略,从而获取最大收益。然而现实中,我方智能体经常会遇到未知变策略对手,其特征体现在:一、对手具有策略库而非单一策略,且我方仅了解对手策略库中的一部分策略;二、对手在游戏过程中会改变策略,且我方难以知晓对手策略的变化。
当博弈过程中对手策略未知或者发生变化时,如果我方采取固定策略,则能够保证博弈过程中的预期收益下限,但却有可能丧失最优奖励。另一方面,如果我方采取针对策略,则有可能获取高于预期收益下限的最大收益,但也面临无法确保收益下限的风险。因此,针对未知变策略对手,现有方法则缺乏有效的应对手段,仅能实现收益下限或者最大收益这样的单一优化目标。因此,需要提出一种有效的博弈决策方法,能够在确保我方预期收益下限的同时,实现我方收益的最大化。
发明内容
本发明技术解决问题:克服现有方法面对未知变策略对手时仅能实现收益下限或者最大收益这样单一优化目标的问题,提供一种针对未知变策略对手的博弈决策方法;可以证明,该方法能够在确保我方预期收益下限的同时,实现我方收益的最大化。通过该方法训练得到的我方智能体具自适应决策能力,在实际使用时不需要对手策略库的全部先验知识,并且能够快速适应对手的策略变化。
本发明的技术方案为:一种针对未知变策略对手的博弈决策方法,包括博弈前预训练和在线博弈两阶段:
博弈前预训练阶段包括步骤S1-步骤S6:
步骤S1:设置对手策略集合Π
步骤S2:初始化概率编码器q
步骤S3:从对手策略集合Π
步骤S4:对于H步推出步长,使用针对策略π
步骤S5:使用缓冲区B中的数据更新针对策略π
步骤S6:使用热编码向量w和缓冲区B中的数据更新概率编码器q
重复步骤S3-步骤S6,直至针对策略π
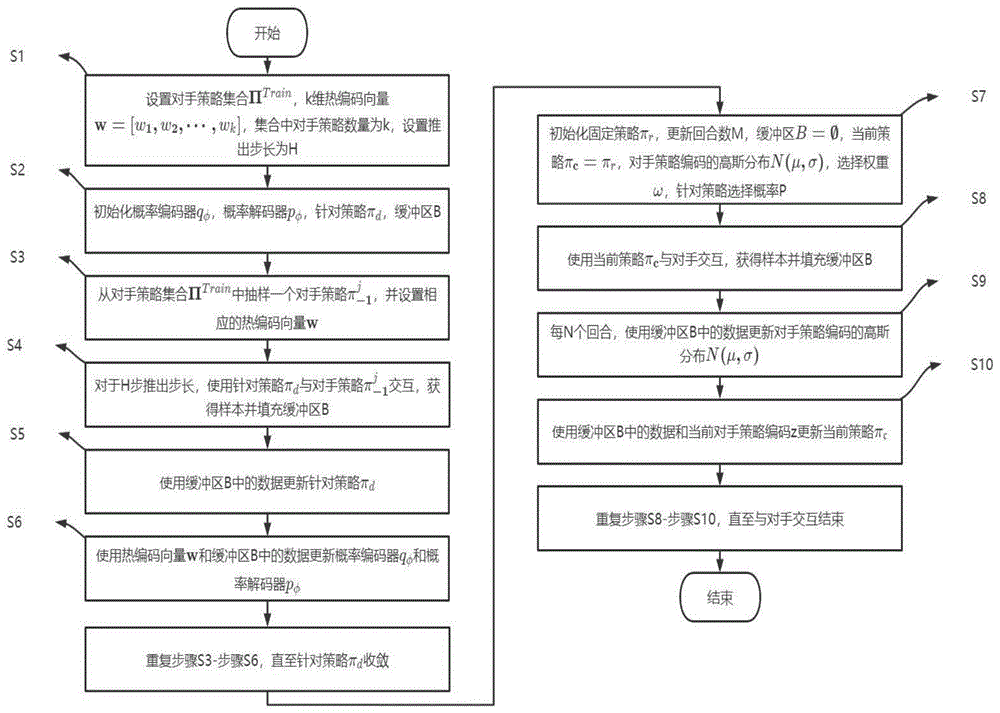
在线博弈阶段包括步骤S7-步骤S10:
步骤S7:初始化固定策略π
步骤S8:使用当前策略π
步骤S9:每N个回合,使用缓冲区B中的数据更新对手策略编码的高斯分布N(μ,σ);
步骤S10:使用缓冲区B中的数据和当前对手策略编码z更新当前策略π
重复步骤S8-步骤S10,直至与对手交互结束。
进一步的,所述步骤S2中,具体包括:
S21:初始化概率编码器q
S22:初始化针对策略π
进一步的,所述步骤S3中,具体包括:
S31:从对手策略集合Π
进一步的,所述步骤S4中,具体包括:
S41:将热编码向量w输入概率编码器中得到对手策略编码的高斯分布μ,σ~q
S42:计算对手策略编码z=μ+σ⊙∈,其中
S43:使用对手策略编码z和当前的环境状态s
S44:执行动作a
S45:将样本存储到缓冲区B中,B←B∪(s
重复步骤S41-S45 H步。
进一步的,所述步骤S5中,具体包括:
S51:从缓冲区B中采样样本;
S52:使用采样样本,通过随机梯度下降依次更新Critic网络和Actor网络参数,实现针对策略π
进一步的,所述步骤S6中,具体包括:
S61:从缓冲区B中采样样本(s
S62:使用采样得到的环境状态s
S63:使用式(1)更新概率编码器q
进一步的,所述步骤S7中,具体包括:
S71:初始化固定策略π
S72:初始化对手策略编码的高斯分布N(μ,σ),其中μ代表高斯分布的均值,初始化为0,σ代表高斯分布的方差,初始化为1;
S73:初始化选择权重
S74:初始化针对策略选择概率
进一步的,所述步骤S8中,具体包括:
S81:计算对手策略编码z=μ+σ⊙∈,其中
S82:使用对手策略编码z和当前的环境状态s
S83:执行动作a
S84:将样本存储到缓冲区B中,B←B∪(s
进一步的,所述步骤S9中,具体包括:
S91:从缓冲区B中采样样本(s
S92:使用采样样本和当前对手策略编码的高斯分布,通过式(2)更新对手策略编码的高斯分布N(μ,σ),其中,D
进一步的,所述步骤S10中,具体包括:
S101:从缓冲区B中采样样本(s
S102:使用采样样本,通过公式(3)更新选择权重ω,其中η和α为超参数,T为交互回合数;
S103:通过式(4)更新针对策略选择概率;
S104:当前策略π
本发明与现有技术相比,具有以下优点∶
(1)本发明基于条件变分自编码器来学习对手的策略嵌入,然后调用条件强化学习来训练得到针对策略,实现对未知对手的近似最佳反应。与针对特定对手策略的单一最佳反应相比,本发明更适于推广到未知变策略对手场景;
(2)本发明基于对抗性双臂老虎机原理进行自适应的博弈决策,通过迭代计算决策权重在固定策略和针对策略之间进行有效选择,从而适应对手的策略改变。可以证明,本发明在确保我方预期收益下限的同时,实现我方收益的最大化;
(3)本发明公开的一种针对未知变策略对手的博弈决策方法,能够和现有的任意强化学习算法相结合,具有很强的普适性。
附图说明
图1为本发明实施例中一种针对未知变策略对手的博弈决策方法;
图2为本发明提供的训练方法的流程示意图。
具体实施方式
现有博弈决策方法都假设对手策略已知且在博弈过程中保持不变,从而我方智能体可以训练出固定策略以应对对手的所有策略,确保我方预期收益下限;或者我方智能体可以训练出针对策略以应对对手的某些策略,从而获取最大收益。然而现实中,我方智能体经常会遇到未知变策略对手,此时现有方法仅能实现收益下限或者最大收益这样的单一优化目标。本发明提供一种针对未知变策略对手的博弈决策方法,在预训练阶段基于条件变分自编码器来学习对手的策略嵌入,并调用条件强化学习来训练得到针对策略。在在线博弈阶段,基于对抗性双臂老虎机原理进行自适应的博弈决策。可以证明,该方法能够在确保我方预期收益下限的同时,实现我方收益的最大化。
为了使本发明的目的、技术方案及优点更加清楚,以下通过具体实施,并结合附图,对本发明进一步详细说明。
如图1所示,本发明实施例提供一种针对未知变策略对手的博弈决策方法包括博弈前预训练和在线博弈两阶段:
博弈前预训练阶段包括步骤S1-步骤S6:
步骤S1:设置对手策略集合Π
步骤S2:初始化概率编码器q
步骤S3:从对手策略集合Π
步骤S4:对于H步推出步长,使用针对策略π
步骤S5:使用缓冲区B中的数据更新针对策略π
步骤S6:使用热编码向量w和缓冲区B中的数据更新概率编码器q
重复步骤S3-步骤S6,直至针对策略π
在线博弈阶段包括步骤S7-步骤S10:
步骤S7:初始化固定策略π
步骤S8:使用当前策略π
步骤S9:每N个回合,使用缓冲区B中的数据更新对手策略编码的高斯分布N(μ,σ);
步骤S10:使用缓冲区B中的数据和当前对手策略编码z更新当前策略π
重复步骤S8-步骤S10,直至与对手交互结束。
本发明提出的一种针对未知变策略对手的博弈决策方法可以与任何强化学习算法相结合进行策略的学习。
步骤S1:设置对手策略集合Π
步骤S2:初始化概率编码器q
S21:初始化概率编码器q
S22:初始化针对策略π
步骤S3:从对手策略集合Π
S31:从对手策略集合Π
步骤S4:对于H步推出步长,使用针对策略π
S41:将热编码向量w输入概率编码器中得到对手策略编码的高斯分布μ,σ~q
S42:计算对手策略编码z=μ+σ⊙∈,其中
S43:使用对手策略编码z和当前的环境状态s
S44:执行动作a
S45:将样本存储到缓冲区B中,B←B∪(s
重复步骤S41-S44 H步。
步骤S5:使用缓冲区B中的数据更新针对策略π
S51:从缓冲区B中采样样本;
S52:使用采样样本,通过随机梯度下降依次更新Critic网络和Actor网络参数,实现针对策略π
步骤S6:使用热编码向量w和缓冲区B中的数据更新概率编码器q
S61:从缓冲区B中采样样本(s
S62:使用采样得到的环境状态s
S63:使用式(1)更新概率编码器q
重复步骤S3-步骤S6,直至针对策略π
步骤S7:初始化固定策略π
S71:初始化固定策略π
S72:初始化对手策略编码的高斯分布N(μ,σ),其中μ代表高斯分布的均值,初始化为0,σ代表高斯分布的方差,初始化为1;
S73:初始化选择权重
S74:初始化针对策略选择概率
步骤S8:使用当前策略π
S81:计算对手策略编码z=μ+σ⊙∈,其中
S82:使用对手策略编码z和当前的环境状态s
S83:执行动作a
S84:将样本存储到缓冲区B中,B←B∪(s
步骤S9:每N个回合,使用缓冲区B中的数据更新对手策略编码的高斯分布N(μ,σ),具体包括:
S91:从缓冲区B中采样样本(s
S92:使用采样样本和当前对手策略编码的高斯分布,通过式(2)更新对手策略编码的高斯分布N(μ,σ),其中D
步骤S10:使用缓冲区B中的数据和当前对手策略编码z更新当前策略π
S101:从缓冲区B中采样样本(s
S102:使用采样样本,通过公式(3)更新选择权重ω,其中η和α为超参数,T为交互回合数;
S103:通过式(4)更新针对策略选择概率;
S104:当前策略π
重复步骤S8-步骤S10,直至与对手交互结束。
如图2所示,本发明提供方法的博弈前预训练阶段,包括下述步骤1-步骤9:
步骤1:设置对手策略集合Π
步骤2:初始化概率编码器q
步骤3:从对手策略集合Π
步骤4:将热编码向量w输入概率编码器中得到对手策略编码的高斯分布μ,σ~q
步骤5:计算对手策略编码z=μ+σ⊙∈,其中
步骤6:使用对手策略编码z和当前的环境状态s
步骤7:执行动作a
重复步骤4-步骤7H次。
步骤8:使用缓冲区B中的数据更新针对策略π
步骤9:使用热编码向量w和缓冲区B中的数据更新概率编码器q
重复步骤3-步骤9,直至针对策略π
在线博弈阶段包括步骤10-步骤15:
步骤10:初始化固定策略π
步骤11:计算对手策略编码z=μ+σ⊙∈,其中
步骤12:使用对手策略编码z和环境状态s
步骤13:执行动作a
步骤14:每N个回合,使用缓冲区B中的数据更新对手策略编码的高斯分布N(μ,σ);
步骤15:使用缓冲区B中的数据和当前对手策略嵌入z更新当前策略π
重复步骤11-步骤15,直至与对手交互结束。
综上所述,本发明提供一种针对未知变策略对手的博弈决策方法,在预训练阶段基于条件变分自编码器来学习对手的策略嵌入,并调用条件强化学习来训练得到针对策略。在在线博弈阶段,基于对抗性双臂老虎机原理进行自适应的博弈决策,通过迭代计算决策权重实现固定策略和针对策略之间的有效抉择。该方法能够在面对未知变策略对手时确保我方预期收益下限,并实现我方收益的最大化。
提供以上实施例仅仅是为了描述本发明的目的,而并非要限制本发明的范围。本发明的范围由所附权利要求限定。不脱离本发明的精神和原理而做出的各种等同替换和修改,均应涵盖在本发明的范围之内。
- 一种手持便携式雷达目标散射特性检测方法
- 一种手持便携式雷达目标散射特性检测方法