基于双塔结构模型的文本匹配方法及装置
文献发布时间:2023-06-19 12:18:04
技术领域
本发明涉及自然语言处理技术领域,具体涉及一种基于双塔结构模型的文本匹配方法及装置。
背景技术
文本匹配是使用自然语言处理模型预测两份文本的语义相关性,可以应用于信息检索、问答系统、对话系统等技术领域,具有广泛的应用价值。近年来,人工智能与深度学习技术的兴起正在快速改变人类日常工作生活的固有习惯,基于深度学习的文本匹配方法也开始在文本匹配领域发挥其优势特长,具体来说,文本匹配有两种深度学习解决方案,一种是对目标文本与源文本的向量表示计算余弦相似度,另一种是融合目标文本与源文本的向量表示后,使用多层神经网络进行处理,将文本匹配变成分类问题来解决。双塔结构模型是第一种方法。
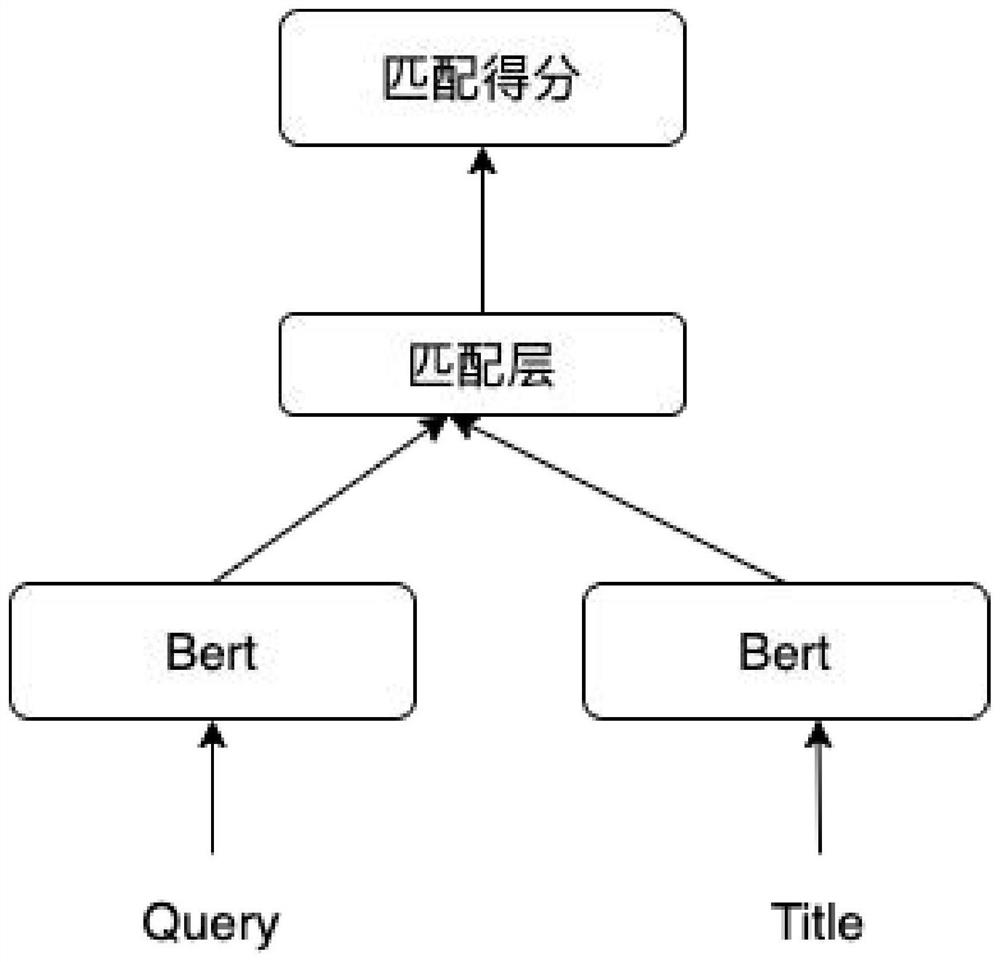
因为双塔结构模型的简便性,是使用深度学习方法解决文本匹配的主流方式。现有的双结构模型总体如图1,分为三个步骤:
Query与Title为文本匹配任务的两个输入,然后分别进入输入层,再分别接一个表示层进行特征提取,表示层输出特征提取后的特征向量,最后计算两个向量的相似度得到匹配得分。
输入层主要的作用就是把文本映射到低维向量空间转化成向量提供给深度学习网络,针对英文文本,一般使用n-gram方法,传统双塔结构模型一般使用3-gram方法;针对中文文本,因为中文的输入层处理方式与英文有很大不同,会在分词阶段引入误差,所以传统双塔结构模型采用字向量作为输入,向量空间约为1.5万维。
表示层为特征提取过程,使用卷积神经网络或者循环神经网络等特征提取模型输出特征向量。传统双塔模型使用两层300维度的隐藏层,最后统一输出128维度的向量。
匹配层计算Query和Title的语义相似性,使用两个语义向量(128维)的余弦距离来表示。最后根据匹配得分,判断Query与Title的语义相似性。
但是,传统的双塔结构模型在表示层中没有做到关注语序和上下文信息。然而,不考虑语序存在严重问题,因为语言作为连续性信息,其词语的前后顺序会显著影响语义,进而影响文本匹配的准确度。同时,没有考虑上下文信息,也会影响文本的整体语义理解,故而现有的文本匹配技术在使用中,尤其是针对复杂语义文本时,因为关注上下文信息与语序信息不足,文本匹配的效果不佳。
此外,中国专利申请CN110287494A公开了一种基于深度学习BERT算法的短文本相似匹配的方法,但该申请需对待匹配短文本进行分词处理,导致英文分词易存在冲突,中文的分词准确率不高,而且有时带来的偏差,对后续训练可能会产生影响。
发明内容
本发明目的是针对现有技术的缺陷,利用预处理语言模型,设计了一种基于双塔结构模型的文本匹配方法及装置,将现有双塔结构模型的输入层与表示层替换为预处理语言模型,实现效果更好的文本匹配技术。
为达到上述目的,本发明的技术方案包括:
一种基于双塔结构模型的文本匹配方法,其步骤包括:
1)将训练集中的一组待匹配文件与匹配文件,分别输入两个独立的预处理语言模型,得到待匹配文件语义向量与匹配文本语义向量;
2)将待匹配文件语义向量与匹配文本语义向量输入第一CNN层,进行降维,并利用第二CNN层,计算降维后的待匹配文件语义向量与匹配文本语义向量的相似度;
3)根据所述相似度,获取该组待匹配文件与匹配文件的匹配结果;
4)利用训练集中各组待匹配文件与匹配文件迭代训练第一CNN层与第二CNN层,并对预处理语言模型进行微调,得到改进后的双塔结构模型;
5)将待匹配文件与匹配文件输入改进后的双塔结构模型,得到匹配结果。
进一步地,语言模型包括:BERT模型、ELMO模型或GPT模型。
进一步地,待匹配文件语义向量与匹配文本语义向量的维度为256维。
进一步地,降维后的待匹配文件语义向量与匹配文本语义向量为128维。
进一步地,计算相似度的方法包括:计算降维后的待匹配文件语义向量与匹配文本语义向量的余弦距离。
进一步地,通过以下步骤获取该组待匹配文件与匹配文件的匹配结果:
1)利用多分类softmax函数,计算文本匹配概率;
2)根据文本匹配概率及一设定阈值,得到该组待匹配文件与匹配文件的匹配结果。
进一步地,文本匹配概率
进一步地,迭代训练第一CNN层与第二CNN层时,损失函数
一种存储介质,所述存储介质中存储有计算机程序,其中,所述计算机程序被设置为运行时执行上述所述的方法。
一种电子装置,包括存储器和处理器,所述存储器中存储有计算机程序,所述处理器被设置为运行所述计算机以执行上述所述的方法。
本发明的有益效果:
本发明研究目标是针对现有文本匹配技术在特征提取过程中关注复杂语义的不足,利用语言模型,尤其是BERT算法在复杂语义处理上的优越性,在传统的双塔结构模型上改进,设计了适用于复杂语义文本的文本匹配方法,从而为信息检索、搜索引擎、客服机器人等众多综合下游任务提供准确的文本匹配结果。
附图说明
图1现有的双结构模型框图。
图2本发明的双结构模型框图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述。基于本发明中的实施例,本领域技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明的双结构模型框图如图2,其使用BERT层代替基本模型中的输入层和表示层,BERT模型Bidirectional Encoder Representation from Transformers,是近年来模型的主要创新点是其预训练方法,使用Masked LM和Next Sentence Prediction两种方法分别捕捉词语和句子级别的representation。BERT算法的优越性在于不需要分词,避免了传统双塔结构模型在分词上出现的如下问题:英文的降维方法n-gram分的词存在冲突,中文的分词准确率不高,而且有时带来的偏差,对后续训练可能会产生影响。同时,BERT擅长处理各种复杂语义,而且不仅考虑从左向右的句子信息,也考虑到从右向左的句子信息,捕捉了上下文的语义信息。
具体来说:
1)BERT层
将待匹配文本Query和匹配文本Title分别输入到两个不同的BERT层,即Bert1和Bert2,两个Bert层分别输出256维向量。
2)匹配层
匹配层包括两个CNN层。将两个BERT层分别输出的256维向量,共512维向量共同输入到第一个CNN层,第一个CNN层经过卷积输出两个128维语义向量,然后输入到第二个CNN层。
第二个CNN层计算两个语义向量(128维)的余弦距离来计算相似度:
其中,Q为Query的128维特征向量,D为Title的128维特征向量,y
之后使用多分类softmax函数计算文本匹配对应的概率:
其中γ为softmax函数的平滑因子,D
文本匹配任务的损失函数:
其中,∧指迭代次数。损失函数即使得Query在正样本的情况,概率越大越好。
本发明将将训练样本输入到本发明的双结构模型中,Query输入待匹配文本,Title分别输入与待匹配同义语句和不同同义语句,使得同义语句,输出概率为1,不同语义语句,输出概率为0;迭代训练两个CNN层,并对两个Bert进行微调,直到神经网络模型收敛为止。
实验数据
本发明使用BQ Corpus(Bank Question Corpus),银行金融领域的问题匹配数据,包括了从一年的线上银行系统日志里抽取的问题pair对,是目前最大的银行领域问题匹配数据。将BQ Corpus数据集进行划分,包括训练集100000,验证集10000,测试集10000,分别对传统双塔模型,Bert,及本发明进行实验,正确率结果如下:
以上实施仅用以说明本发明的技术方案而非对其进行限制,本领域的普通技术人员可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明范围,本发明的保护范围应以权利要求书所述为准。
- 基于双塔结构模型的文本匹配方法及装置
- 一种基于文本分类和匹配融合模型的意图识别方法及装置