用于头戴设备的语音方向识别系统及其方法
文献发布时间:2023-06-19 18:29:06
技术领域
本申请涉及一种语音方向识别,尤指一种用于头戴设备的语音方向识别系统及其方法。
背景技术
现有的消费性电子产品,头戴设备提供了通话以及娱乐等功能,例如:头戴耳机、真无线耳机(True Wireless Stereo,TWS)、扩充实境装置(Augmented Reality,AR)、虚拟现实装置(Virtual Reality,VR)以及声音信号眼镜,日渐成为人们必不可少的设备。
现有技术的头戴设备,为了提供更好的通话质量以及娱乐效果,以隔绝外部噪音信号进入用户的耳朵,通过头戴设备罩设人耳或直接入耳以后,以主动降噪以及通透功能的方式,以特定频率去抵销外部噪音信号,去除外部噪音信号的问题,以接收外部人声信号。
然而,现有技术的头戴设备在放大并播放人声信号时,将因为头戴设备皆包括双耳输出装置,而双耳输出装置将处理过的人声信号,通过两个紧挨人耳的输出装置播放出的声音会产生声音存在于使用者脑海中而非空间中的错觉(即「头中效应」),在使用者没有使用眼睛观察之前,很难清楚得知外部人声信号的传递方位,将造成使用者的不便利。
有鉴于此,现有技术确实有待进一步提供更佳改良方案的必要性。
发明内容
有鉴于上述现有技术的不足,本申请主要目的在于提供一种用于头戴设备的语音方向识别系统及其方法,通过辨识所述多个朝向不同方向的收音装置以及所述头部相关传输函数,当使用者在使用头戴设备时,不需要用眼睛观察,即可清楚得知所述语音信号的来源方向,达到提升使用头戴设备的便利性。
为达成上述目的所采取的主要技术手段是令前述语音方向识别系统包括:
多个朝向不同方向的收音装置,其分别接收信号;
头部相关传输函数数据库,其存储头部相关传输函数数据(Head RelatedTransfer Functions,HRTF);
信号处理装置,其与所述多个朝向不同方向的收音装置以及所述头部相关传输函数数据库连接;
其中,所述信号处理装置被配置为对所述信号撷取多个人声信号,且根据所述多个人声信号的时间信息以及响度信息,以获取挑选出的主要语音信号,并取得对应于所述挑选出的主要语音信号的位置信息,利用所述位置信息对应的所述头部相关传输函数数据对所述挑选出的主要语音信号进行信号处理,以产生语音方向识别信号。
较佳的,所述信号处理包括滤波处理。
较佳的,所述信号处理装置包括:
撷取模块,其与所述多个朝向不同方向的收音装置连接,且被配置为根据所述信号,撷取所述多个人声信号;
判断模块,其与所述撷取模块连接,且被配置为根据所述多个人声信号的所述时间信息以及所述响度信息,以取得所述挑选出的主要语音信号;
计算模块,其与所述头部相关传输函数数据库以及所述撷取模块连接,且被配置为根据所述多个朝向不同方向的收音装置的水平面上挑选出的两个延时最小且响度最大的收音装置所共同覆盖的方向确定所述挑选出的主要语音信号的方向区域和中心轴。
较佳的,所述计算模块还被配置为根据所述方向区域内的所述多个朝向不同方向的收音装置之间的所述时间信息以及距离信息,计算所述挑选出的主要语音信号与所述中心轴之间的方位角。
较佳的,所述信号处理装置还包括:
筛选模块,其与所述判断模块连接,且被配置为根据所述时间信息以及所述响度信息,由所述多个朝向不同方向的收音装置中取得至少两个挑选出的收音装置,所述时间信息包括所述至少两个挑选出的收音装置收到所述挑选出的主要语音信号的时间差,所述距离信息为所述至少两个挑选出的收音装置的距离差;
其中,所述计算模块还被配置为根据所述时间差与所述距离差,取得所述方位角。
较佳的,所述计算模块根据方程式θ=arcsin(△d/d
较佳的,所述计算模块根据所述方向区域内对应根据所述多个朝向不同方向的收音装置的一竖直平面上的所述多个收音装置之间的所述时间信息以及所述距离信息,计算所述挑选出的主要语音信号对应所述头部相关传输函数数据的坐标上的仰角。
较佳的,所述信号处理装置包括:
混频模块,其与所述判断模块以及所述计算模块连接,且被配置为根据所述头部相关传输函数数据与所述位置信息对所述挑选出的主要语音信号的时域进行卷积处理,以产生所述语音方向识别信号。
较佳的,所述信号处理装置包括:
混频模块,其与所述判断模块以及所述计算模块连接,且被配置为根据所述头部相关传输函数数据与所述位置信息对所述挑选出的主要语音信号的频域进行相乘处理,以产生所述语音方向识别信号。
较佳的,所述信号处理装置更包括:
混频模块,其与所述判断模块以及所述计算模块连接,且被配置为根据所述头部相关传输函数数据与所述位置信息对所述挑选出的主要语音信号进行信号处理,以产生所述语音方向识别信号;
增益调整模块,其与所述混频模块连接,且对所述语音方向识别信号进行音量增益调整,以产生音量增益信号。
较佳的,所述用于头戴设备的语音方向识别系统更包括:
混合器,其与所述增益调整模块连接,且根据所述音量增益信号与音频信号进行混合,以产生混音信号;
数字模拟转换器,其与所述混合器连接,且将混音信号进行数字模拟转换,以产生模拟混音信号;
音频输出装置,其与所述数字模拟转换器连接,在所述头戴设备中的相对应所述信号的虚拟位置输出所述模拟混音信号。
通过上述构造,所述信号处理装置通过撷取所述多个人声信号的所述时间信息以及所述响度信息,以获取所述挑选出的主要语音信号,并取得对应于所述挑选出的主要语音信号的位置信息,根据所述位置信息对应的所述头部相关传输函数数据以及所述位置信息对所述挑选出的主要语音信号进行信号处理,借由所述信号处理,以将符合所述头部相关传输函数数据以及所述位置信息的所述挑选出的主要语音信号进行提取,而产生所述语音方向识别信号,以排除其他不符合的语音信号,以提供用户可清楚识别所述语音信号的方向,如此一来,当使用者在使用头戴设备时,不需要用眼睛观察,即可清楚得知所述语音信号的来源方向,以提升了使用头戴设备的便利性。
为达成上述目的所采取的又一主要技术手段是令前述头戴设备的语音方向识别方法,应用在头戴设备的语音方向识别系统,其特征在于,所述语音方向识别系统包括多个朝向不同方向的收音装置、头部相关传输函数数据库以及信号处理装置,所述多个朝向不同方向的收音装置分别接收信号,所述头部相关传输函数数据库存储头部相关传输函数数据,且所述信号处理装置与所述多个朝向不同方向的收音装置以及所述头部相关传输函数数据库连接,并由所述信号处理装置执行以下步骤:
对所述多个朝向不同方向的收音装置接收到的信号,撷取多个人声信号;
根据所述多个人声信号的时间信息以及响度信息,以获取挑选出的主要语音信号;
取得对应于所述挑选出的主要语音信号的位置信息;
利用所述位置信息对应的所述头部相关传输函数数据对所述挑选出的主要语音信号进行信号处理,以产生语音方向识别信号。
较佳的,所述信号处理包括滤波处理。
较佳的,在执行前述方法至「取得对应于所述挑选出的主要语音信号的位置信息」的步骤,包括以下子步骤:
根据所述多个朝向不同方向的收音装置的一水平面上挑选出的两个延时最小且响度最大的收音装置所共同覆盖的方向确定所述挑选出的主要语音信号的方向区域和中心轴。
较佳的,在执行前述方法至「根据所述多个朝向不同方向的收音装置的一水平面上挑选出的两个延时最小且响度最大的收音装置所共同覆盖的方向确定所述挑选出的主要语音信号的方向区域和中心轴」的步骤,包括以下子步骤:
根据所述方向区域内的所述多个朝向不同方向的收音装置之间的所述时间信息以及距离信息,计算所述挑选出的主要语音信号与所述中心轴之间的方位角。
较佳的,在执行前述方法至「根据所述方向区域内的所述多个朝向不同方向的收音装置之间的所述时间信息以及距离信息,计算所述挑选出的主要语音信号与所述中心轴之间的所述方位角」的步骤以后,更由所述信号处理装置执行以下步骤:
根据所述时间信息以及所述响度信息,由所述多个朝向不同方向的收音装置中取得至少两个挑选出的收音装置,所述时间信息包括所述至少两个挑选出的收音装置收到所述挑选出的主要语音信号的时间差,所述距离信息为所述至少两个挑选出的收音装置的距离差,且根据所述时间差与所述距离差,取得所述方位角。
较佳的,在执行前述方法至「根据所述方向区域内的所述多个朝向不同方向的收音装置之间的所述时间信息以及距离信息,计算所述挑选出的主要语音信号与所述中心轴之间的方位角」的步骤,更包括以下子步骤:
所述计算模块根据方程式θ=arcsin(△d/d
较佳的,在执行前述方法至「取得对应于所述挑选出的主要语音信号的位置信息」的步骤,更包括以下子步骤:
根据所述方向区域内对应根据所述多个朝向不同方向的收音装置的一竖直平面上的所述多个朝向不同方向的收音装置之间的所述时间信息以及所述距离信息,计算所述挑选出的主要语音信号对应所述头部相关传输函数数据的坐标上的仰角。
较佳的,在「利用所述位置信息对应的所述头部相关传输函数数据对所述挑选出的主要语音信号进行信号处理,以产生语音方向识别信号」的步骤以后,包括以下步骤:
对所述语音方向识别信号进行音量增益调整,以产生音量增益信号。
较佳的,在「利用所述位置信息对应的所述头部相关传输函数数据对所述挑选出的主要语音信号进行信号处理,以产生语音方向识别信号」的步骤以后,包括以下步骤:
根据所述头部相关传输函数数据与所述位置信息对所述挑选出的主要语音信号的时域进行卷积处理,以产生所述语音方向识别信号。
较佳的,在「利用所述位置信息对应的所述头部相关传输函数数据对所述挑选出的主要语音信号进行信号处理,以产生语音方向识别信号」的步骤以后,包括以下步骤:
根据所述头部相关传输函数数据与所述位置信息对所述挑选出的主要语音信号的频域进行相乘处理,以产生所述语音方向识别信号。
较佳的,在「利用所述位置信息对应的所述头部相关传输函数数据对所述挑选出的主要语音信号进行信号处理,以产生语音方向识别信号」的步骤以后,包括以下步骤:
对所述语音方向识别信号进行音量增益调整,以产生音量增益信号。
较佳的,在「对所述语音方向识别信号进行音量增益调整,以产生音量增益信号」的步骤以后,包括以下步骤:
将所述音量增益信号与音频信号进行混合程序,以产生混音信号;
将所述混音信号进行数字模拟转换程序,以产生模拟混音信号;
在相对应的虚拟位置输出所述模拟混音信号。
通过上述方法,所述信号处理装置通过撷取所述多个人声信号的所述时间信息以及所述响度信息,以获取所述挑选出的主要语音信号,并取得对应于所述挑选出的主要语音信号的位置信息,根据所述位置信息对应的所述头部相关传输函数数据以及所述位置信息对所述挑选出的主要语音信号进行信号处理,借由所述信号处理,以将符合所述头部相关传输函数数据以及所述位置信息的所述挑选出的主要语音信号进行提取,而产生所述语音方向识别信号,以排除其他不符合的语音信号,提供用户可清楚识别所述语音信号的方向,如此一来,当使用者在使用头戴设备时,不需要用眼睛观察,即可清楚得知所述语音信号的来源方向,以提升了使用头戴设备的便利性。
附图说明
此处所说明的附图用来提供对本申请的进步理解,构成本申请的部分,本申请的示意性实施例及其说明用于解释本申请,并不构成对本申请的不当限定。在附图中:
图1是本申请的用于头戴设备的语音方向识别系统的装置方块图。
图2是本申请的用于头戴设备的语音方向识别系统的装置方块图。
图3是本申请的头戴设备的语音方向识别系统的方向方块图。
图4是本申请的头戴设备的语音方向识别方法的流程图。
图5是本申请的头戴设备的语音方向识别方法的又一流程图。
图6是本申请的头戴设备的语音方向识别方法的再一流程图。
图7是本申请的头戴设备的语音方向识别方法的另一流程图。
图8是本申请的头戴设备的语音方向识别方法的又一流程图。
图9A是本申请的头戴设备的语音方向识别方法的再一流程图。
图9B是本申请的头戴设备的语音方向识别方法的另一流程图。
图10是本申请的头戴设备的语音方向识别方法的再一流程图。
图11是本申请的头戴设备的语音方向识别方法的另一流程图。
具体实施方式
下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本申请部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。
关于本申请的头戴设备的语音方向识别系统10的较佳实施例,如图1所示,所述头戴设备的语音方向识别系统10包括多个朝向不同方向的收音装置11、头部相关传输函数数据库12以及信号处理装置13,所述多个朝向不同方向的收音装置11分别接收信号,以根据所述信号分别产生所述多个方向语音信号,所述头部相关传输函数数据库12存储头部相关传输函数数据,所述信号处理装置13与所述多个朝向不同方向的收音装置11以及所述头部相关传输函数数据库12连接。在本实施例中,所述多个朝向不同方向的收音装置11是设置在不同收音方向的麦克风(Microphone,mic),且麦克风是指向性,以接收所设置方向的语音信号,所述麦克风是模拟麦克风或是数字麦克风。
详细来说,所述多个朝向不同方向的收音装置11分别从不同方向接收同个说话者所发出的声源,而得到所述多个方向语音信号,也可以是所述多个朝向不同方向的收音装置11分别从不同方向接收到多个说话者分别发出的声源,而得到所述多个方向语音信号,接着,所述信号处理装置13被配置为对所述多个方向语音信号,分别撷取多个人声信号,且根据所述多个人声信号的时间信息以及响度信息,以获取所述多个人声信号中的其中一个人声信号是挑选出的主要语音信号,根据所述头部相关传输函数数据对应所述挑选出的主要语音信号,并取得对应于所述挑选出的主要语音信号的位置信息,利用所述位置信息对应的所述头部相关传输函数数据对所述挑选出的主要语音信号进行信号处理,以产生语音方向识别信号。在本实施例中,所述头部相关传输函数数据包括声音到达每只耳朵的时间差(Interaural Time Delay,ITD)、声音到达每只耳朵的水平差(Interaural AmplitudeDifference,IPD)。在本实施例中,在本实施例中,如果接收到同个说话者所发出的声源时,通过本申请可更为确认所述说话者与聆听者的相对方向,另外,如果接收到的是所述多个说话者所发出的声源,通过本申请可过滤掉其他人的声音。在本实施例中,所述信号处理包括滤波处理。
在本实施例中,如图2所示,所述信号处理装置13包括撷取模块130、判断模块131以及计算模块132,所述撷取模块130与所述多个朝向不同方向的收音装置11连接,所述判断模块131与所述撷取模块130连接,所述计算模块132与所述头部相关传输函数数据库12以及所述撷取模块130连接,且所述撷取模块130被配置为根据所述信号,撷取所述多个人声信号,所述判断模块131被配置为根据所述多个人声信号的所述时间信息以及所述响度信息,以取得所述挑选出的主要语音信号,所述计算模块132被配置为根据所述多个朝向不同方向的收音装置的一水平面上挑选出的两个延时最小且响度最大的所共同覆盖的方向确定主要语音信号的方向区域和中心轴。在本实施例中,所述判断模块131可根据所述多个人声信号的所述时间信息以及所述响度信息与所述头部相关传述函数信息中的所述声音到达每只耳朵的时间差以及所述声音到达每只耳朵的水平差进行比对,基于所述声音到达每只耳朵的时间差在不同方位对达不同耳朵的时间差有所不同,且所述声音到达每只耳朵的水平差是基于所述声音到达每只耳朵的水平差不同声音大小也将有所差异,故,根据所述声音到达每只耳朵的时间差以及所述声音每只耳朵的水平差进行比对后,以取得所述挑选出的主要语音信号。
在本实施例中,所述计算模块132还被配置为根据所述方向区域内的所述多个朝向不同方向的收音装置11之间的所述时间信息以及距离信息,计算所述挑选出的主要语音信号与所述中心轴之间的方位角。
在本实施例中,所述信号处理装置还包括筛选模块133,所述筛选模块133与所述判断模块131连接,且被配置为根据所述时间信息以及所述响度信息,由所述多个朝向不同方向的收音装置11中取得至少两个挑选出的收音装置11,所述时间信息包括所述多个朝向不同方向的收音装置11中的至少两个挑选出的收音装置收到所述挑选出的主要语音信号的时间差,所述距离信息为所述至少两个挑选出的收音装置11的距离差;其中,所述计算模块132还被配置为根据所述时间差与所述距离差,取得所述方位角。
在本实施例中,所述计算模块132根据方程式θ=arcsin(△d/d
在本实施例中,所述计算模块132根据所述方向区域内对应根据所述多个朝向不同方向的收音装置11的一竖直平面上的所述多个朝向不同方向的收音装置11之间的所述时间信息以及所述距离信息,计算所述挑选出的主要语音信号对应所述头部相关传输函数数据的坐标上的仰角。在本实施例中,根据所述方向区域内的所述多个收音装置之间的所述时间信息以及所述距离信息,取得所述方向区域的二个收音装置,在所述二个收音装置之间取得所述二个收音装置的所述中心轴。举例来说,如果以聆听者的头部正前方作为0°角,所述挑选出的主要语音信号的是从聆听者的头部正前方的右边以及左边而构成的所述方向区域中,找出接收到所述时间信息中延迟最小以及所述响度信息中响度最大的二个收音装置,所述二个收音装置分别在聆听者的头部正前方的-45°角的位置以及-135°角的位置,所述二个收音装置之间的所述中心轴则为(45°+135°)/2=90°。
在本实施例中,所述信号处理包括根据所述头部相关传输函数数据与所述位置信息对所挑选出的主要语音信号进行滤波处理。
在本实施例中,所述信号处理装置13包括混频模块134与所述判断模块131以及所述计算模块132连接,所述混频模块134被配置为根据所述头部相关传输函数数据与所述位置信息对所述挑选出的主要语音信号的时域进行卷积处理(Convolution),以产生所述语音方向识别信号。
在本实施例中,所述信号处理是所述混频模块134根据所述头部相关传输函数数据与所述位置信息对所述挑选出的主要语音信号的频域进行信号相乘处理,以产生所述语音方向识别信号,借由所述滤波处理,以将符合所述头部相关传输函数数据以及所述位置信息的所述挑选出的主要语音信号提取,而产生所述语音方向识别信号,以排除其他不符合的语音信号。
在一些实施例中,所述信号处理包括根据所述头部相关传输函数数据与所述位置信息对所述挑选出的主要语音信号的时域信号进行卷积处理与滤波处理;和/或,根据所述头部相关传输函数数据与所述位置信息对所述挑选出的主要语音信号的频域信号进行信号相乘处理与滤波处理。
在本实施例中,所述信号处理装置13更包括增益调整模块135,所述增益调整模块135与所述混频模块134连接,且对所述语音方向识别信号进行音量增益调整,以产生音量增益信号,使得所述语音方向识别信号的音量大小有所调整。
在本实施例中,所述用于头戴设备的语音方向识别系统10更包括混合器14、数字模拟转换器(Digital to Analog Converter,DAC)15以及音频输出装置16,所述混合器14与所述增益调整模块135连接,所述数字模拟转换器15与所述混合器14连接,且所述音频输出装置16与所述数字模拟转换器15转接,所述混合器14更与音频信号器17连接,所述混合器14根据所述音量增益信号与所述音频信号器17的音频信号进行混合,以产生混音信号,接着,所述数字模拟转换器15将混音信号进行数字模拟转换,以产生模拟混音信号,所述音频输出装置16在所述头戴设备中的相对应所述信号的虚拟位置输出所述模拟混音信号。在本实施例中,所述音频输出装置是扬声器。
详细来说,用于头戴设备的语音方向识别系统10在针对头罩式耳机、入耳式耳机等在佩戴时会将人耳与外界环境隔绝的头戴设备,可将外界有用的所述信号进行方向定位,以在头戴设备中相对所述信号的方向虚拟所述信号,用户能在佩戴头戴设备时,也能够快速的反应周围与自己交流的人的方向。
所述多个朝向不同方向的收音装置11具有指向性,仅接收对应方向的声音,摆放位置可根据实际产品形态(如:耳机或扩充实境装置)以及所述多个朝向不同方向的收音装置11的指向角度设置,使所述多个朝向不同方向的收音装置11可分别覆盖所述音频输出装置16的前、后、左、右等方向,基于每个朝向不同方向的收音装置11接收的信号大小有所差异,因此,通过在所述音频输出装置16的对称位置设置所述多个朝向不同方向的收音装置11(例如:在耳机的左、右声道各设置个收音装置),也可以在所述音频输出装置16的垂直方向设置所述多个朝向不同方向的收音装置11。若要达到提升定位精准度,则可在所述音频输出装置16的各角度设置所述多个朝向不同方向的收音装置11,使所述多个朝向不同方向的收音装置11的所能覆盖的角度越完整,如此一来,在定位上,也更为精准。
所述信号处理装置13可集成在系统芯片里,也可集成在单独数字信号处理(Digital Signal Processor,DSP)芯片里,当所述多个朝向不同方向的收音装置11接收到外部的所述信号直接或经过模拟数字转换后送入系统芯片或DSP芯片,进行声源定位处理。
所述多个朝向不同方向的收音装置11从所述头戴设备的外部接收所述信号,基于所述多个朝向不同方向的收音装置11设置在所述头戴设备的不同位置以及具有指向性的特性,使得所述多个朝向不同方向的收音装置11在接收到的所述信号之间在所述时间信息以及所述响度信息将有所差异。所述信号处理装置13将所述人声信号的所述时间信息和所述响度信息进行比对,根据各方向收音装置的所述时间信息(t1,t2…tn)以及所述响度信息(s1、s2…sn)进行分析,以找出所述时间信息中的延时最小min(t1,t2…tn)以及所述响度信息中的响度最大smain=max(s1、s2…sn)的作为所述挑选出的主要语音信号进行后续处理。
根据要使用的HRTF数据的方位角和仰角设定来设定人头水平方位角和仰角相对的坐标分布,以水平方向高度一致的麦克风高度作为0°水平面,人头正向作为0°方向,根据各通道人声信号之间的时间以及响度差异选出响度最大和延时最小的两个通道对应mic,确定所述方向区域范围和中心轴对应方位角。
举例来说,如图3所示,所述多个朝向不同方向的收音装置11包括左前的mic1、左后的mic2、右前的mic3以及右后的mic4、而延时最小且响度最大的两个通道对应麦克风为水平面上左前mic1、左后mic2,则声源方向应为两颗mic覆盖的交集区域,即左前到左后中间区域,对应中心轴为水平面正左(-90,0)。所述声源对应于所述挑选出的主要语音信号。
根据两通道的时延△t=t2-t1和两mic之间距离求出该声源与中心轴的夹角θ=arcsin(△d/d
若要增加竖直方向上角度位置信息,则利用有高度差的两颗mic进行同上述水平面计算方式处理,得到竖直方向上的仰角
根据计算得到的声源方位角和仰角,查找HRTF数据组中坐标相对最接近的数据组。
利用查找到的相对坐标的HRTF信息对挑选出的主要语音信号进行滤波处理。接着,根据所使用状态对声音大小进行自动增益调节,能够将靠近人耳的双扬声器发出的声音虚拟为在对应位置发出的响度适合的声音。
接着,用于头戴设备的语音方向识别系统10的头戴设备也可以增加通话mic正对使用者的嘴巴,以接收使用者的声音为主,在进行语音方向识别时,需要在进行语音方向识别的信号中滤去所述通话mic所接收到的信号,也就是说,用于头戴设备的语音方向识别系统仅针对外部周围的人声进行处理,不对使用者本人的声音进行处理。
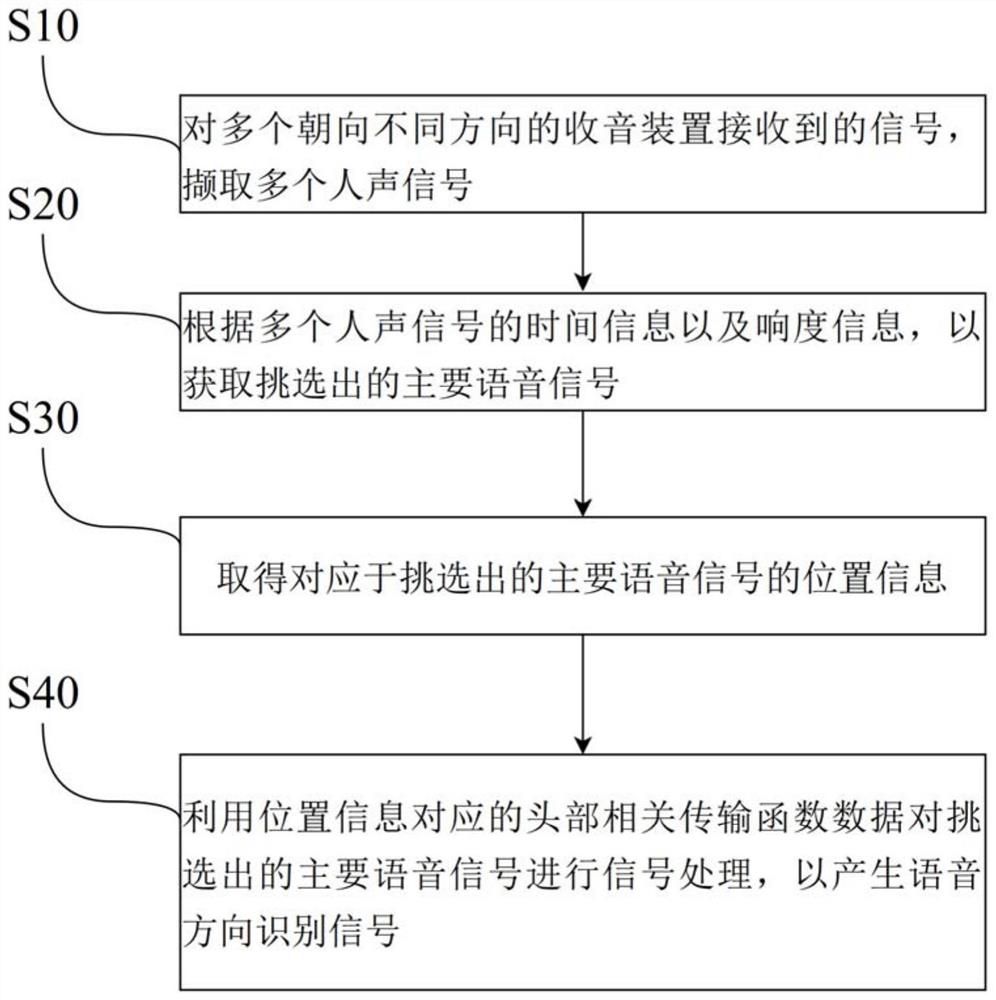
另外,关于本申请另一实施例的头戴设备的语音方向识别方法,如图4所示,应用在头戴设备的语音方向识别系统,其特征在于,所述语音方向识别系统包括多个方向收音装置、头部相关传输函数数据库以及信号处理装置,所述多个朝向不同方向的收音装置分别接收信号,所述头部相关传输函数数据库存储头部相关传输函数数据,且所述信号处理装置与所述多个方向收音装置以及所述头部相关传输函数数据库连接,并由所述信号处理装置执行以下步骤:
对所述多个朝向不同方向的收音装置接收到的信号,撷取多个人声信号(S10);
根据所述多个人声信号的时间信息以及响度信息,以获取挑选出的主要语音信号(S20);
取得对应于所述挑选出的主要语音信号的位置信息(S30);
利用所述位置信息对应的所述头部相关传输函数数据对所述挑选出的主要语音信号进行信号处理,以产生语音方向识别信号(S40)。在本实施例中,所述信号处理是一滤波处理。
在本实施例中,如图5所示,在执行前述方法至「取得对应于所述挑选出的主要语音信号的位置信息(S30)」的步骤,由所述信号处理装置执行以下子步骤:
根据所述多个朝向不同方向的收音装置的一水平面上挑选出的两个延时最小且响度最大的收音装置所共同覆盖的方向确定所述挑选出的主要语音信号的方向区域和中心轴(S31A)。
在本实施例中,如图6所示,在执行前述方法至「根据所述多个朝向不同方向的收音装置的一水平面上挑选出的两个延时最小且响度最大的收音装置所共同覆盖的方向确定所述挑选出的主要语音信号的方向区域和中心轴(S31A)」的步骤,由所述信号处理装置执行以下步骤:
根据所述方向区域内的所述多个朝向不同方向的收音装置之间的所述时间信息以及距离信息,计算所述挑选出的主要语音信号与所述中心轴之间的所述方位角(S32)。
在本实施例中,如图7所示,在执行前述方法至「根据所述方向区域内的所述多个朝向不同方向的收音装置之间的所述时间信息以及距离信息,计算所述挑选出的主要语音信号与所述中心轴之间的所述方位角(S32)」的步骤以后,由所述信号处理装置执行包括下步骤:
根据所述时间信息以及所述响度信息,由所述多个朝向不同方向的收音装置中取得所述至少两个挑选出的收音装置,所述时间信息包括所述至少两个挑选出的收音装置收到所述挑选出的主要语音信号的时间差,所述距离信息为所述至少两个挑选出的收音装置的距离差,且根据所述时间差与所述距离差,取得所述方位角(S320)。
在本实施例中,根据方程式θ=arcsin(△d/d
在本实施例中,如图8所示,在执行前述方法至「取得对应于所述挑选出的主要语音信号的位置信息(S30)」的步骤,由所述信号处理装置执行以下子步骤:
根据所述方向区域内对应根据所述多个朝向不同方向的收音装置的一竖直平面上的所述多个朝向不同方向的收音装置之间的所述时间信息以及所述距离信息,计算所述挑选出的主要语音信号对应所述头部相关传输函数数据的坐标上的仰角(S31B)。
在本实施例中,如图9A所示,在执行前述方法至「利用所述位置信息对应的所述头部相关传输函数数据对所述挑选出的主要语音信号进行信号处理,以产生语音方向识别信号(S40)」的步骤,由所述信号处理装置执行以下子步骤:
根据所述头部相关传输函数数据与所述位置信息对所述挑选出的主要语音信号的时域进行卷积处理,以产生所述语音方向识别信号(S41A)。
在本实施例中,如图9B所示,在执行前述方法至「利用所述位置信息对应的所述头部相关传输函数数据对所述挑选出的主要语音信号进行信号处理,以产生语音方向识别信号(S40)」的步骤,由所述信号处理装置执行以下子步骤:
根据所述头部相关传输函数数据与所述位置信息对所述挑选出的主要语音信号的频域进行信号相乘处理,以产生所述语音方向识别信号(S41B)。
在本实施例中,如图10所示,在执行前述方法至「利用所述位置信息对应的所述头部相关传输函数数据对所述挑选出的主要语音信号进行信号处理,以产生语音方向识别信号(S40)」的步骤以后,由所述信号处理装置执行以下步骤:
对所述语音方向识别信号进行音量增益调整,以产生音量增益信号(S50)。
在本实施例中,如图11所示,在执行前述方法至「对所述语音方向识别信号进行音量增益调整,以产生音量增益信号(S50)」的步骤以后,由所述信号处理装置执行以下步骤:
将所述音量增益信号与音频信号进行混合程序,以产生混音信号(S60);
将所述混音信号进行数字模拟转换程序,以产生模拟混音信号(S70);
在头戴设备中与所述信号相对应的虚拟位置输出所述模拟混音信号(S80)。
综上所述,所述信号处理装置通过撷取所述多个人声信号的所述时间信息以及所述响度信息,以获取所述挑选出的主要语音信号,并取得对应于所述挑选出的主要语音信号的位置信息,根据所述位置信息对应的所述头部相关传输函数数据以及所述位置信息对所述挑选出的主要语音信号进行信号处理,借由所述信号处理,以将符合所述头部相关传输函数数据以及所述位置信息的所述挑选出的主要语音信号进行提取,而产生所述语音方向识别信号,以排除其他不符合的语音信号,提供用户可清楚识别所述语音信号的方向,如此一来,当使用者在使用头戴设备时,使用者不需要在头中效应的影响下,而必须用眼睛在各方向进行寻找所述语音信号的来源方向,即可清楚得知所述语音信号的来源方向,以提升了使用头戴设备的便利性
需要说明的是,在本文中,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者装置不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者装置所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括该要素的过程、方法、物品或者装置中还存在另外的相同要素。
上面结合附图对本申请的实施例进行了描述,但是本申请并不局限于上述的具体实施方式,上述的具体实施方式仅仅是示意性的,而不是限制性的,本领域的普通技术人员在本申请的启示下,在不脱离本申请宗旨和权利要求所保护的范围情况下,还可做出很多形式,均属于本申请的保护范围。