基于隐式神经表示的低剂量稀疏视图SPECT重建和图像去噪方法
文献发布时间:2024-04-18 19:44:28
技术领域
本发明属于生物医学图像重建技术领域,具体涉及一种基于隐式神经表示的低剂量稀疏视图SPECT重建和图像去噪方法。
背景技术
单光子发射计算机断层成像技术(Single-Photon Emission ComputedTomography,SPECT))是一种常用的核医学成像技术,用于检测和诊断多种疾病。SPECT通过测量从患者体内放射出来的gamma射线来获取关于组织和器官功能的信息。然而,由于SPECT成像过程中存在的噪声(图像可能存在泊松噪声)、散射和有限角度采样等问题,重建出准确的三维图像一直是一个具有挑战性的任务。
传统的SPECT重建方法可以分为三类:解析方法、迭代方法和基于学习的方法。解析方法通过解决Radon变换及其逆问题来估计放射性核素的分布。其中,经典的FDK算法在理想情况下表现良好,但在稀疏视图等不完备数据情况下的重建效果较差。迭代方法是另一类常用的重建方法,它将重建问题建模为最小化过程。这些方法采用优化框架结合正则化模块进行重建。虽然迭代方法在处理不完备数据问题时表现较好,但需要较长的计算时间和大量的内存。随着人工智能的兴起,基于学习的方法在SPECT重建中变得越来越流行。这些方法利用深度神经网络来实现预测和外推投影数据,通过类似数据回归估计放射性核素的分布使重建过程可微分。其中,大多数方法需要大规模的数据集进行网络训练,并且依赖于神经网络记忆SPECT图像的特征。
发明内容
为了解决背景技术问题,本发明提出了一种基于隐式神经表示的低剂量稀疏视图SPECT重建和图像去噪方法,该方法首先对低剂量且噪声较高的稀疏视图通过隐式神经表示来生成密集的视图,将训练的稀疏视图和生成的密集视图相结合,通过PreconditionedAlternating Projection Algorithms重建算法来获得对应的SPECT重建图像。然后通过对更深层权重的增长进行惩罚,最大化隐式神经表示固有的去噪能力,对有噪声的SPECT图像进行去噪,实现高质量的SPECT图像重建。
本发明的一种基于隐式神经表示的低剂量稀疏视图SPECT重建和图像去噪方法,包括如下步骤:
S1:将低剂量、噪声高的稀疏视图SPECT的三维坐标通过小波级数映射为高频特征,并进行频率正则化;
S2:将经过小波级数映射和频率正则化的稀疏视图输入到全连接多层感知器(MLP)中,在低维问题域中学习高频函数;
S3:通过最小化真实投影和合成投影之间的误差来训练网络,预测时生成不包含训练视图的密集的视图;
S4:将训练时的稀疏视图和生成的密集视图相结合,通过PreconditionedAlternating ProjectionAlgorithms重建算法实现低剂量高噪声稀疏视图的SPECT重建;
S5:利用去噪算法,通过惩罚更深层权重的增长来最大化隐式神经表示(INR)的固有去噪能力,实现高质量的SPECT图像的去噪。
进一步地,所述步骤S1中的稀疏视图SPECT的三维坐标是指假设K张稀疏视图SPECT投影,那么每张投影中的二维坐标x’=(u,v)经过一个旋转矩阵R∈R
其中L表示是控制最大编码频率的超参数。当L等于6时,k有32种情况,分别为0,1...31。将输入点输入到小波函数中,
其中haar小波函数表达公式为:
将x’=[x,γ
在给定x’=[x,γ
γ
其中
其中α
进一步地,所述步骤S2中全连接多层感知器网络包括8个全连接层,其中所述全连接多层感知器网络的第1层和第4层具有不同于全连接多层感知器网络的其他层的神经元数量,并且所述全连接多层感知器网络的其他层每层有256个神经元,除了最后一层外,每个完全连接层后面都有周期性sin激活函数,这个周期性sin激活函数,非常适合表示复杂的自然信号及其导数。
进一步地,所述步骤S3中的真实投影I
其中,投影I可以用
进一步地,所述步骤S4中通过Preconditioned AlternatingProjectionAlgorithms重建算法得到其对应的SPECT图像;
进一步地,所述步骤S5中的去噪算法,其中使用了第一阶段的全连接多层感知器权重参数,作为当前的网络的预训练权重,当训练时通过全连接多层感知器生成的图像与目标噪声图像之间的均方误差(MSE)小于目标图像估计的噪声水平时停止训练。其中均方误差的表示为:
其中C为噪声图像中所有像素坐标对c=(x,y)∈R
其中,每对表示像素的中心坐标。
当
时就停止训练。
该停止准则的设计考虑了理想情况,其中隐式神经表示偏置提供了图像和噪声拟合的完美时间分离(即,在拟合噪声之前拟合底层干净信号)。实际上,如果全连接多层感知器生成的图像与干净图像完全相同,则停止准则将满足相等。此外,为了加强隐式神经表示偏差,在最后两层的全连接感知器上选择性地应用权重衰减。观察发现,隐式神经表达的后层比前一层对拟合噪声信号的贡献更大。更具体地说,前层神经元主要代表低频模式,而后层神经元产生细粒度细节。完全训练和早期停止的模型之间的一个显著区别是后一层神经元的行为。特别是,与最佳早期停止时期的隐式神经表示(INR)相比,训练到收敛的隐式神经表示(INR)主要在其后一层神经元输出上有所不同;后一层的许多输出丢失了语义信息并收敛为噪声。另一方面,早期层的输出几乎没有变化
本发明的有益效果:
本发明提供了一种基于隐式神经表示的低剂量稀疏视图SPECT重建和图像去噪方法,具有以下有益效果:首先,通过采用隐式神经表示和小波级数映射,能够在低剂量和高噪声条件下实现稀疏视图的三维重建。该方法能够有效地提取和学习高频特征,并通过频率正则化实现重建过程的优化。其次,通过使用预训练的多层感知器权重参数,结合Preconditioned Alternating Projection Algorithms重建算法,实现了低剂量高噪声稀疏视图的SPECT重建,从而提供了高质量的重建结果。最后,在图像去噪方面,利用隐式神经表示固有的去噪能力,通过使用先前训练的权重参数,实现了对有噪声的SPECT图像的有效去噪,进一步提高了重建图像的质量。因此,本发明的有益效果在于实现了低剂量稀疏视图SPECT重建和图像去噪的高质量结果,相比于传统的深度学习方法,能够进一步提高SPECT重建图像的质量。
附图说明
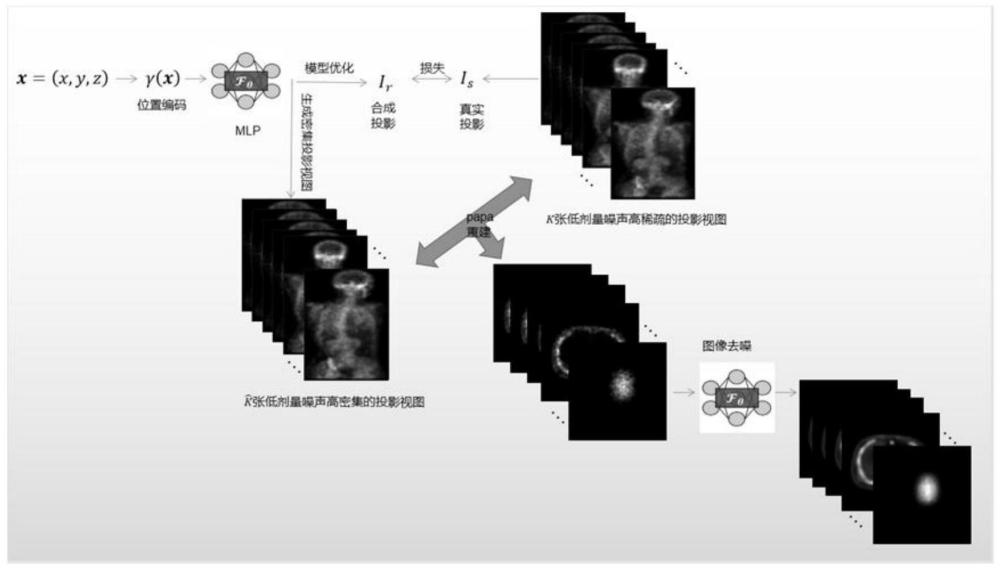
图1为整体模型框架示意图
图2为基于隐式神经表示的低剂量稀疏视图SPECT重建和图像去噪方法的流程图
图3为第一阶段的全连接多层感知器的架构
图4为第二阶段去噪时的全连接多层感知器的架构
具体实施方式
需要说明的是,在不冲突的情况下,本申请中的实施例及实施例中的特征可以相互结合,下面结合附图和具体实施例对本发明作进一步详细说明。
本发明基于隐式神经表示的低剂量稀疏视图SPECT重建和图像去噪方法,具体实施如下:
搭建好的隐式神经表示结构如图1所示,以及整体模型框架示意图如图2所示。
本文中使用的实验数据是通过蒙特卡罗模拟软件Simind获得的,且每张低剂量视图的大小都是128×128。在360度扫描内一共有120张投影视图,其中的训练集为每间隔6度取1张,也就是选取20张视图为训练集,然后渲染生成剩余所有的100张投影视图。那么每张训练集投影视图中的二维坐标x’=(u,v)经过一个旋转矩阵R∈R
其中L表示是控制最大编码频率的超参数。当L等于6时,k有32种情况,分别为0,1...31。将输入点输入到小波函数中,
其中haar小波函数表达公式为:
将x’=[x,γ
将x’=[x,γ
在给定x’=[x,γ
γ’
其中
其中α
第一阶段的全连接多层感知器的架构如附图3所示,全连接多层感知器网络包括8个全连接层,其中所述全连接多层感知器网络的第1层和第4层具有不同于全连接多层感知器网络的其他层的神经元数量,并且所述全连接多层感知器网络的其他层每层有256个神经元。除了最后一层外,每个完全连接层后面都有周期性sin激活函数。由于频谱偏置,标准的ReLU MLP无法在这些复杂的低维信号中充分表示细节,并通过用正弦sin函数代替ReLU激活,使基于坐标的MLP能够从拟合类别内许多信号的过程中学习,从而可以使用更少的步骤和更少的观察值快速优化以拟合任何新信号。所以这个周期性sin激活函数,非常适合表示复杂的自然信号及其导数。
附图1中的真实投影I
其中,投影I可以用
附图4表示了第二阶段去噪时的全连接多层感知器的架构。其中使用了第一阶段的全连接多层感知器权重参数,作为当前的网络的预训练权重,当训练时通过全连接多层感知器生成的图像与目标噪声图像之间的均方误差(MSE)小于目标图像估计的噪声水平时停止训练。其中均方误差的表示为:
其中C为噪声图像中所有像素坐标对c=(x,y)∈R
其中,每对表示像素的中心坐标。
当
时就停止训练。
该停止准则的设计考虑了理想情况,其中隐式神经表示偏置提供了图像和噪声拟合的完美时间分离(即,在拟合噪声之前拟合底层干净信号)。实际上,如果全连接多层感知器生成的图像与干净图像完全相同,则停止准则将满足相等。此外,为了加强隐式神经表示(INR)偏差,在最后两层的全连接感知器上选择性地应用权重衰减。观察发现,隐式神经表达的后层比前一层对拟合噪声信号的贡献更大。更具体地说,前层神经元主要代表低频模式,而后层神经元产生细粒度细节。完全训练和早期停止的模型之间的一个显著区别是后一层神经元的行为。特别是,与最佳早期停止时期的隐式神经表示(INR)相比,训练到收敛的隐式神经表示(INR)主要在其后一层神经元输出上有所不同;后一层的许多输出丢失了语义信息并收敛为噪声。另一方面,早期层的输出几乎没有变化。
本实施方式整个算法在Ubuntu 16.04.1(64位)系统中测试,其中cpu为IntelXeon Silver 4210R(2.4GHz),显卡型号为GeForce RTX 3090(8GB显存)。在编程中,采用Pytorch 1.8.0平台来进行网络模型的搭建。
上述的对实施例的描述是为便于本技术领域的普通技术人员能理解和应用本发明。熟悉本领域技术的人员显然可以容易地对上述实施例做出各种修改,并把在此说明的一般原理应用到其他实施例中而不必经过创造性的劳动。因此,本发明不限于上述实施例,本领域技术人员根据本发明的揭示,对于本发明做出的改进和修改都应该在本发明的保护范围之内。