基于深度神经网络和图卷积网络的视频行人识别方法
文献发布时间:2023-06-19 09:27:35
技术领域
本发明属于计算机视觉的技术领域,具体涉及基于深度神经网络和图卷积网络的视频行人识别方法。
背景技术
随着世界范围内对社会公共安全需求的日益增长,成千上万的监控摄像头被安装在各式各样的公众聚集场所,如公园、体育场馆、大型广场、学校、医院、商业街、住宅小区等,并由此产生了海量的监控图像和视频数据。同时,硬件存储能力的提升以及互联网云计算、云存储的崛起也加速了视频技术的发展和更新。
如何自动地对这些海量图像、视频数据进行有效的管理、解释和利用,实现对数据语义的理解,已引起众多科研工作者和厂商的广泛关注,视频语义挖掘技术应运而生。视频语义挖掘,就是从海量视频中探索蕴含的高层结构,提取潜在的、引起人们兴趣的、相互关联的、可以理解的语义信息和模式知识的过程。
行人属性是人类可以直接予以描述的行人特征,例如“性别”、“发型”、“穿衣风格”和“携带物”等等,可以同时被机器和人所理解。行人属性作为视觉属性,因其在智能监控系统中得到广泛应用而引起了极大的关注。该算法可用于检索行人并协助完成其他计算机视觉任务,例如行人检测,行人重新识别等。
现有的行人属性分析算法大致非为两大类,一类是基于传统方法,一类是基于深度学习方法。对于传统机器学习方法,起初的行人属性识别算法依赖手工设计的特征,例如方向梯度直方图特征,结合数据增广技术在MIT公共数据集上识别人的性别属性。或使用颜色和纹理特征,并结合支持向量机和马尔科夫随机场等对属性进行识别等等。近年来,深度学习的兴起使得研究者们大都采用深度神经网络构建行人属性识别模型,基于神经网络学习到的特征显著提升了属性识别的能力。
目前大多数的行人属性识别方法都是基于静态图像的。他们在每个实例仅包含一张图像的数据集上进行训练和评估。但是,在实际监控中,我们获得的是连续的图像序列。对于特定属性,行人的单个镜头不一定是最具代表性的。
在过去的十几年中,很多人在行人属性识别领域已经做出了很多努力。最近,由于深度学习的快速发展,许多人开始利用基于卷积神经网络(CNN)的方法,例如联合训练的整体CNN模型。尽管基于深度学习模型的方法表现出良好的性能,目前大多数的行人属性识别方法都是基于静态图像的。但是,在实际监控中,获得的是连续的图像序列。连续的数据可以提供强有力的时间线索,且在视频数据在处理某些特殊情况和质量问题方面也显示出明显的优势。而且目前的行人属性识别还没有去挖掘属性标签间的依赖关系,捕获标签依赖关系是多标签图像识别的关键问题之一。
发明内容
本发明的目的在于:针对现有技术的不足,提供基于深度神经网络和图卷积网络的视频行人识别方法,本发明能利用视频的时序特征,提高了行人属性识别的准确率。
为了实现上述目的,本发明采用如下技术方案:
基于深度神经网络和图卷积网络的视频行人识别方法,包括如下步骤:
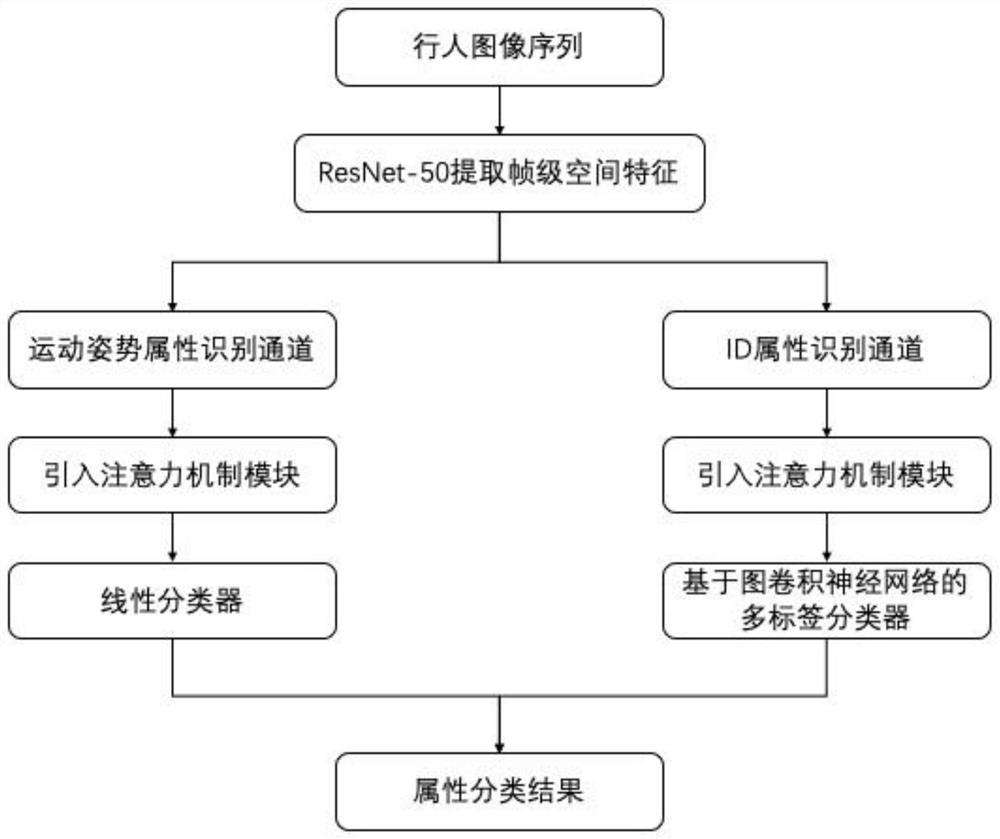
步骤一、输入行人图像序列;
步骤二、选择ResNet-50作为骨干模型,提取帧级空间特征;
步骤三、识别是否为运动姿态属性或ID属性,若是运动姿态属性,则进行步骤四;若是ID属性,则进行步骤五;
步骤四、将空间特征向量作为每个属性分类器中的时间注意模块的输入,并生成时间注意向量,然后,将时间注意力向量加权每个帧的空间特征,并且将生成用于识别特定属性的图像序列的最终特征向量,最后,将最终特征向量馈入全连接层以实现属性分类结果。
步骤五、将空间特征向量作为每个属性分类器中的时间注意模块的输入,并生成大小为n×1的时间注意向量,然后,将时间注意力向量加权每个帧的空间特征,并且将生成用于识别特定属性的图像序列的最终特征向量,最后,将图卷积网络引入到属性分类器中,以执行半监督分类。
作为本发明所述的基于深度神经网络和图卷积网络的视频行人识别方法的一种改进,使用空间特征提取器,每个帧由大小为2048×4×7的张量表示,然后,空间特征向量通过两个通道中的卷积和合并单元分别处理,采用全局最大池化来获得图像级特征;
通过属性分类器处理合并空间特征向量。
作为本发明所述的基于深度神经网络和图卷积网络的视频行人识别方法的一种改进,所述步骤五中,将图卷积网络引入到属性分类器中,以执行半监督分类,包括:
将每个图卷积网络节点的最终输出设计为属性识别任务中相应标签的分类器;
基于图卷积网络的分类器学习,通过基于图卷积网络的映射函数从标签表示中学习相互依赖的对象分类器;
通过将学习到的分类器应用于图像表示,得到预测分数。
作为本发明所述的基于深度神经网络和图卷积网络的视频行人识别方法的一种改进,所述图卷积网络通过基于相关矩阵在节点之间传播信息来工作,通过数据驱动的方式构建此相关矩阵,通过在数据集中挖掘标签的共现模式来定义标签之间的相关性,以条件概率的形式对标签相关性依赖性进行建模。
作为本发明所述的基于深度神经网络和图卷积网络的视频行人识别方法的一种改进,所述相关矩阵为非对称结构。
作为本发明所述的基于深度神经网络和图卷积网络的视频行人识别方法的一种改进,所述相关矩阵的构造方法,包括:
对训练集中的标签对的出现进行计数;
通过使用这个标签共现矩阵,得到条件概率矩阵
P
其中,M
对相关性P进行二值化。
作为本发明所述的基于深度神经网络和图卷积网络的视频行人识别方法的一种改进,对相关性P进行二值化,包括:
使用阈值τ过滤噪声边缘,重新加权,即
其中,A′是重新加权的二进制相关矩阵,而p确定分配给节点本身和其他相关节点的权重。
作为本发明所述的基于深度神经网络和图卷积网络的视频行人识别方法的一种改进,在图卷积网络之后,节点的特征为其自身特征与相邻节点的特征的加权总和。
本发明的有益效果在于,本发明包括基于常规神经网络和图卷积网络神经网络的新型多任务模型,用于行人属性识别;通过端到端可训练多标签图像识别框架,该框架采用图卷积网络将标签表示形式映射到相互依赖的对象分类器,通过图卷积网络中的相关系数矩阵,并重新构建了相关系数矩阵;并通过重新加权方法,同时缓解了过度拟合和过度平滑的问题,此外,本发明对于运动姿势分类部分,采用了时间注意力机制,从而达到更好地分类效果;还将行人属性识别与深度学习相结合,基于视频的行人属性识别方法与传统方法相比,准确新高、特征利用率高,具有一定的市场价值和推广意义。本发明基于视频的行人属性识别方法,并在分类器里引入了图卷积网络的模型,以从先前的标签表示中学习相互依赖的对象分类器,从而提高了行人属性识别的准确率并利用了视频的时序特征。
附图说明
下面将参考附图来描述本发明示例性实施方式的特征、优点和技术效果。
图1为本发明的步骤流程图。
图2为本发明的模型结构图。
具体实施方式
如在说明书及权利要求当中使用了某些词汇来指称特定组件。本领域技术人员应可理解,硬件制造商可能会用不同名词来称呼同一个组件。本说明书及权利要求并不以名称的差异来作为区分组件的方式,而是以组件在功能上的差异来作为区分的准则。如在通篇说明书及权利要求当中所提及的“包含”为一开放式用语,故应解释成“包含但不限定于”。“大致”是指在可接受的误差范围内,本领域技术人员能够在一定误差范围内解决技术问题,基本达到技术效果。
此外,术语“第一”、“第二”等仅用于描述目的,而不能理解为指示或暗示相对重要性。
在发明中,除非另有明确的规定和限定,术语“安装”、“相连”、“连接”、“固定”等术语应做广义理解,例如,可以是固定连接,也可以是可拆卸连接,或一体地连接;可以是机械连接,也可以是电连接;可以是直接相连,也可以通过中间媒介间接相连,可以是两个元件内部的连通。对于本领域的普通技术人员而言,可以根据具体情况理解上述术语在本发明中的具体含义。
以下结合附图1~2对本发明作进一步详细说明,但不作为对本发明的限定。
连续的数据还可以提供强有力的时序关联性。而且,视频数据在处理某些特殊情况和质量问题方面也显示出明显的优势。
对于行人属性识别这种多标签的分类任务,本发明引入了一种图卷积网络的模型来捕获多标签图像识别的标签相关性。这种模型将对象分类器视为要学习的一组独立参数向量,通过基于图卷积网络的映射函数从先前的标签表示中学习相互依赖的对象分类器。接下来,将生成的分类器应用于另一个子网生成的图像表示,以实现端到端训练。由于嵌入到分类器的映射参数在所有分类之间共享,因此所有分类器的梯度都会影响基于图卷积网络的分类器生成功能。
在网络的开始,本发明选择ResNet-50作为骨干模型,最后平坦层的输出用作帧级空间特征,然后将网络分为两个通道:分别是运动姿势通道和与ID相关的通道。之所以将分类器分为两个通道,是因为运动姿势属性与ID不相关,并且与ID相关的属性相比,其分类器将专注于空间特征的不同部分。因此在所有ID中直接共享相同的空间特征与id不相关和与id相关的属性分类器将导致功能竞争情况,这意味着与id不相关的分类器和与id相关的分类器都将在训练进度上相互制约。
令I={I
x=f
其中θ
然后由属性分类器处理合并的空间特征向量。对于运动姿势通道,将空间特征向量作为每个属性分类器中的时间注意模块的输入,并生成大小为n×1的时间注意向量A,该向量表示每个帧的重要性。然后,将时间注意力向量用于加权每个帧的空间特征,并且将生成用于识别特定属性的图像序列的最终特征向量D=A
对于与ID相关的通道,与运动姿势通道相同,同样引入时间注意力机制模块,生成用于识别特定属性的图像序列的最终特征向量D,然后在此将图卷积网络(GCN)引入到属性分类器中,以执行半监督分类。基本思想是通过在节点之间传播信息来更新节点表示。GCN的目标是学习图G上的函数f(·,·),该图具有特征描述H
H
采用卷积运算后,f(·,·)表示为
其中W
最后将每个GCN节点的最终输出设计为属性识别任务中相应标签的分类器。然后基于GCN的分类器学习通过基于GCN的映射函数从标签表示中学习相互依赖的对象分类器,即
假设图像的真实标签为y∈R
其中σ(·)是S形函数。
GCN通过基于相关矩阵在节点之间传播信息来工作。通过数据驱动的方式构建此相关矩阵,即通过在数据集中挖掘标签的共现模式来定义标签之间的相关性。以条件概率的形式对标签相关性依赖性进行建模,即P(L
P
其中N
然后对相关性P进行二值化。具体来说,使用阈值τ过滤噪声边缘。在GCN之后,节点的特征将为其自身特征与相邻节点的特征的加权总和。为缓解节点功能过于平滑的问题,提出重新加权方案的方法,即
其中,A′是重新加权的二进制相关矩阵,而p确定分配给节点本身和其他相关节点的权重。这样,在更新节点特征时,考虑节点本身具有固定的权重,而相关节点的权重将由邻域分布确定。当p趋于1时,将不考虑节点本身的特征。另一方面,当p趋于0时,而不考虑邻域信息。
根据上述说明书的揭示和教导,本发明所属领域的技术人员还能够对上述实施方式进行变更和修改。因此,本发明并不局限于上述的具体实施方式,凡是本领域技术人员在本发明的基础上所作出的任何显而易见的改进、替换或变型均属于本发明的保护范围。此外,尽管本说明书中使用了一些特定的术语,但这些术语只是为了方便说明,并不对本发明构成任何限制。