一种使用语义标注的中文地址RoBERTa-BiLSTM-CRF耦合解析方法
文献发布时间:2023-06-19 10:24:22
技术领域
本发明涉及自然语言处理中的中文分词领域,尤其是涉及一种使用语义标注的中文地址RoBERTa-BiLSTM-CRF耦合解析方法。
背景技术
随着外卖、快递等行业的发展,基于地址匹配的位置服务扮演着越来越重要的角色,同时也对地址匹配的准确性提出了越来越高的要求。地址解析是地址匹配的重要组成部分,其对地址匹配的准确性有着重要影响。但是,由于定位系统的误差,导致经常使用的百度地图导航、高德地图导航、腾讯地图导航等无法解决最后几十米的导航问题。为了更加准确的对某一位置进行描述,经常在地址中加入距离、方位等空间关系关键词。另外,中文地址作为一种空间数据基础设施,由于不同的需求,会造成地址描述方式的不一致。比如,公安部门要求地址精确到房间号,而工商教育部门一般要求地址精确到楼栋号或门牌号。这些都增加了地址解析的难度。因此,对这些地址进行高效的解析成为了一个急需解决的问题。
地址解析就是把地址中的地址元素以及地址标志结构抽取出来,即结合空间关系地址模型对中文地址进行分词,并标注地址元素的层级及空间关系,为下一阶段的地址标准化和匹配做准备。目前,很多研究者提出了中文地址分词算法。程昌秀等、张雪英等提出了基于规则和词尾特征的中文分词,但是由于地址用字的自由性,该方法分词准确率不高。后来随着统计语言模型的兴起,基于统计模型的地址分词受到了越来越多的关注。应申等提出了基于决策树的城市地址集分词,该方法统计城市地址集的分布特征构建决策树进行地址元素提取,无法解决数据稀疏及过分割问题。蒋文明等提出了基于条件随机场的地址元素提取方法,该方法需要设计复杂的特征。李伟等提出了基于规则和统计的混合方法进行中文地址分词,该方法需要提取词尾特征集,在一定程度上缓解了数据稀疏的问题,仍存在过分割的问题。随着机器学习、特别是深度学习的技术在自然语言处理领域取得了重大突破。李鹏鹏等使用BiGRU进行中文地址分割,该方法只考虑了使用兴趣点地址进行分词,没有考虑地址元素之间的约束关系,无法对地址进行标准化等操作。程博等使用BiLSTM-CRF对中文地址进行分词,该方法提取了地址元素词尾特征以增强地址切分的准确性,并且对地址元素所处的层级进行了标注,但是没有考虑地址中的楼层号、距离关系等。
针对地址分词存在的不足,提出一种使用语义标注的中文地址RoBERTa-BiLSTM-CRF耦合解析方法。该方法不需要依赖外部特征,采用基于自然语言理解的深度学习方法学习地址模型特征和上下文信息。
发明内容
本发明针对地址分词存在的不足,提出一种使用语义标注的中文地址RoBERTa-BiLSTM-CRF耦合解析方法。
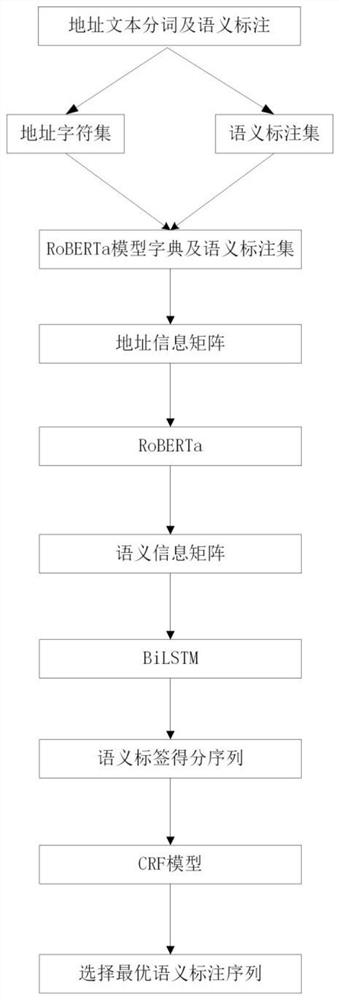
本发明的目的是通过以下技术方法来实现的:一种使用语义标注的中文地址RoBERTa-BiLSTM-CRF耦合解析方法,包括以下步骤:
步骤1、将多条地址文本依次进行分词,对分词后的字符进行人工语义标注。处理得到分词后地址字符集合及语义标注集合,将多条分词后地址字符集合及语义标注集合进行拼接,得到分词后去重的字符集及语义标注集;
步骤2、将得到分词后去重的字符集通过RoBERTa模型词典转化为字符信息向量,依据字符信息向量将地址文本转化为地址文本信息矩阵;依据语义标注集将地址文本对应的语义标注转化为语义标注信息矩阵。
步骤3、根据地址文本中字符的位置,采用RoBERTa模型中的三角函数位置编码方式计算地址文本中每个字符的位置信息向量,根据每个字符的位置信息向量将地址文本转化为位置信息矩阵;
步骤4、将地址文本信息矩阵和位置信息矩阵相加,进一步与语义标注信息矩阵拼接得到地址信息矩阵;
步骤5、将地址信息矩阵输入到RoBERTa神经网络,得到地址的语义信息矩阵。
步骤6、将地址的语义信息矩阵输入到BiLSTM,使用前向传播算法和后向传播算法对BiLSTM进行训练,通过门控机制对上下文语义信息进行删减,得到标签的得分序列。
步骤7、将标签的得分序列作为输入,利用条件随机场构建标签之间的约束关系,得到中文地址分词的最优标注序列。
作为优选,步骤1所述的分词后地址字符集合及标注集合定义为:
j∈[1,M]
其中,address
步骤1所述分别将多条分词后的地址字符集合及语义标注集合进行拼接为:
{address
步骤1所述通过去重处理分别得到地址分词后的字符集及语义标注集为将{address
word={word
tag={tag
其中,word
作为优选,步骤2所述将分词后去重的字符集通过查找RoBERTa模型词典转化为字符信息向量为:
其中,α
步骤2所述依据字符信息向量将地址文本转化为地址文本信息矩阵为:
将每条地址中包含的字符通过步骤1得到分词后去重的字符集转化为one-hot向量为:
β
其中,β
限制地址文本长度为L,对于小于L的地址使用零向量进行补充,对于大于L的地址进行截断,零向量定义为:
γ={0,0,...,0,…,0}
其中,γ为零向量,所有位置的值为0,γ的维数为word中字符集的个数,即N。
则把一条地址文本η=[word
B
通过字符矩阵
把
τ
其中,τ
步骤2所述依据语义标注集将地址文本对应的语义标注转化为语义标注信息矩阵为:
D
作为优选,步骤3所述计算地址文本中每个字符的位置信息向量为:
PE(pos,2i)=sin(pos/100002i/d
PE(pos,2i+1)=cos(pos/100002i/d
其中,PE(pos,2i)、PE(pos,2i+1)分别表示地址文本
步骤3所述地址文本中第i个字符的位置信息向量为:
其中,z
步骤3所述将地址文本转化为位置信息矩阵为:
作为优选,所述步骤4将地址文本信息矩阵和位置信息矩阵相加为:
进一步与语义标注信息矩阵拼接得到地址信息矩阵为
作为优选,所述步骤5包括:
将步骤4得到的地址信息矩阵
其中,W
由于RoBERTa模型是利用多头注意力机制捕获地址语义信息,多头注意力机制就是把每个head的计算结果拼接起来得到地址的语义信息矩阵,具体计算公式如下
其中head
作为优选,所述步骤6包括:
将上下文语义信息矩阵输入到BiLSTM模型,通过遗忘门、记忆门、输出门对上下文语义信息进行删减,对于t时刻门控制单元的计算过程如下:
f
i
c
o
h
其中,h
把前向信息、后向信息拼接,得到地址的上下文语义信息v=[m,n]。
把得到地址的上下文语义信息通过全连接神经网络转化为标签得分序列X={x
X=v×E
其中,E为初始化的转换矩阵;
进一步,所述步骤7包括:
将步骤6得到的标签得分序列X={x
式中,Z(X)为归一化因子,t
采用维特比算法选取概率最大的Y为最优标注序列。
本发明优点在于:
采用语义标注,能够识别地址中地址元素的层级及空间关系;
能够从非标准地址提取标准地址,解决未登录词问题、并剔除非标准和错误地址元素,根据地址中的空间关系实现空间推理。
附图说明
图1:RoBERTa-BiLSTM-CRF神经网络结构示意图。
图2:本发明方法流程图。
图3:分词后地址语义标注。
图4:注意力机制计算过程。
图5:BiLSTM前后向信息计算过程。
具体实施方式
下面结合附图和实施例,对本发明的具体实施方式作进一步详细描述,以下实施例用于说明本发明,但不用来限制本发明的范围。
本发明提供的一种使用语义标注的中文地址RoBERTa-BiLSTM-CRF耦合解析方法,其结构见图1。
下面结合图1至图5介绍本发明的具体实施方式为一种使用语义标注的中文地址RoBERTa-BiLSTM-CRF耦合解析方法,方法流程图见图2。具体包括以下步骤:
步骤1、将多条地址文本依次进行分词,对分词后的字符进行人工语义标注,语义标注如表1所示。处理得到分词后地址字符集合及语义标注集合,将多条分词后地址字符集合及语义标注集合进行拼接,得到分词后去重的字符集及语义标注集;
步骤1所述的分词后地址字符集合及标注集合定义为:
j∈[1,M]
其中,address
步骤1所述分别将多条分词后的地址字符集合及语义标注集合进行拼接为:
{address
步骤1所述通过去重处理分别得到地址分词后的字符集及语义标注集为将{address
word={word
tag={tag
其中,word
表1:语义标注
步骤2、将步骤1得到的分词后去重的字符集通过RoBERTa模型词典转化为字符信息向量,依据字符信息向量将步骤1地址文本转化为地址文本信息矩阵;依据步骤1得到的语义标注集将步骤1地址文本对应的语义标注转化为语义标注信息矩阵。
步骤2所述将分词后去重的字符集通过查找RoBERTa模型词典转化为字符信息向量为:
其中,α
步骤2所述依据字符信息向量将步骤1地址文本转化为地址文本信息矩阵为:
将每条地址中包含的字符通过步骤1得到word字符集转化为one-hot向量为:
β
其中,β
限制地址文本长度为L,对于小于L的地址使用零向量进行补充,对于大于L的地址进行截断,零向量定义为:
γ={0,0,...,0,…,0}
其中,γ为零向量,所有位置的值为0,γ的维数为word中字符集的个数,即N。
则把一条地址文本η=[word
B
通过字符矩阵
把
τ
其中,τ
步骤2所述依据步骤1得到的语义标注集将步骤1地址文本对应的语义标注转化为语义标注信息矩阵为:
D
步骤3、根据地址文本η中字符的位置,采用RoBERTa模型中的三角函数位置编码方式计算地址文本中每个字符的位置信息向量,根据每个字符的位置信息向量将地址文本η转化为位置信息矩阵;
步骤3所述计算地址文本中每个字符的位置信息向量为:
PE(pos,2i)=sin(pos/100002i/d
PE(pos,2i+1)=cos(pos/100002i/d
其中,PE(pos,2i)、PE(pos,2i+1)分别表示地址文本
步骤3所述地址文本η中第i个字符的位置信息向量为:
其中,z
步骤4、将步骤2所述的地址文本信息矩阵和步骤3所述的位置信息矩阵相加,进一步与语义标注信息矩阵拼接得到地址信息矩阵;
进一步,所述步骤4包括:
将将步骤2所述的地址文本信息矩阵和步骤3所述的位置信息矩阵相加为
进一步与语义标注信息矩阵拼接得到地址信息矩阵为
步骤5、将步骤4得到的地址信息矩阵输入到RoBERTa神经网络,得到地址的语义信息矩阵。
进一步,所述步骤5包括:
将步骤4得到的地址信息矩阵
其中,W
由于RoBERTa模型是利用多头注意力机制捕获地址语义信息,多头注意力机制就是把每个head的计算结果拼接起来得到地址的语义信息矩阵,具体计算公式如下
其中head
步骤6、将步骤5得到的上文语义信息矩阵输入到BiLSTM,使用前向传播算法和后向传播算法对BiLSTM进行训练,通过门控机制对上下文语义信息进行删减,得到标签的得分序列。
进一步,所述步骤6包括:
将上下文语义信息矩阵输入到BiLSTM模型,通过遗忘门、记忆门、输出门对上下文语义信息进行删减,对于t时刻门控制单元的计算过程如下:
f
i
c
o
h
其中,h
把前向信息、后向信息拼接,得到地址的上下文语义信息v=[m,n],BiLSTM前后向信息计算过程见图5。
把得到地址的上下文语义信息通过全连接神经网络转化为标签得分序列X={x
X=v×E
其中,E为初始化的转换矩阵;
步骤7、将步骤6标签的得分序列作为输入,利用条件随机场构建标签之间的约束关系,得到中文地址分词的最优标注序列。
进一步,所述步骤7包括:
将步骤6得到的标签得分序列X={x
式中,Z(X)为归一化因子,t
采用维特比算法选取概率最大的Y为最优标注序列。
应当理解的是,本申请书未详细阐述的部分均属于现有技术。
应当理解的是,上述针对较佳实施例的描述较为详细,并不能因此而认为是对本申请专利保护范围的限制,本领域的普通技术人员在本发明的启示下,在不脱离本申请权利要求所保护的范围情况下,还可以做出替换或变形,均落入本申请的保护范围之内,本申请的请求保护范围应以所附权利要求为准。
- 一种使用语义标注的中文地址RoBERTa-BiLSTM-CRF耦合解析方法
- 一种基于贝叶斯分词算法的中文地址语义标注方法