一种利用社交软件大数据找寻潜在客户的方法
文献发布时间:2023-06-19 10:38:35
技术领域
本发明涉及一种利用社交软件大数据找寻潜在客户的方法。
背景技术
开发新客户是业务发展最重要的因素之一。但是,寻找新客户是一个非常困难的过程,它需要大量时间和金钱的投资,而且仍然不能保证新客户的顺利开发。
市场上有很多付费软件可以提供潜在客户的信息,这些信息基于几个条件(地理位置,行业等),之后你可以尝试通过电话、电子邮件等联系这些潜在客户。电话销售或发送电子邮件是开发新客户的传统方法,但通常效果不大,转化率很低。因为没有针对真正有需要的潜在客户进行发送,因而大部分的状况是,对方根本不回复或不接你的电话,因而目前我们迫切需要一种利用社交软件大数据快捷准确筛选出有需要的潜在客户的方法。
发明内容
为了克服现有技术的不足,本发明提供一种建立社交软件大数据找寻潜在客户的方法。
本发明解决其技术问题所采用的技术方案是:
一种利用社交软件大数据找寻潜在客户的方法,其特征在于:包括以下步骤:
S1,依据历史客户的信息作为数据创建筛选模型一和筛选模型二,
S2,对筛选模型一设置筛选条件,筛选条件包括教育背景、教育领域、目前就职公司、任职年限、出任职务、是否使用任何3D或CAD软件,筛选模型一依据筛选条件自动在网络上搜寻符合筛选条件的新客户,
S3,经过筛选模型一搜寻的新客户的信息输入筛选模型二同时附加行业及公司规模做为筛选模型二的筛选条件再次筛选,
S4,符合条件则发送定制信息联系该新客户。
所述筛选模型一和筛选模型二的创建包括以下步骤:
S1.1,数据收集,从历史客户中挑选一定数量的客户并收集这些客户的信息作为数据,客户包括下过订单的客户和给我司发送询价但最终没有下订单的客户,信息包括教育背景、教育领域、目前就职公司、任职年限、出任职务、是否使用任何3D或CAD软件,
S1.2,数据清洗,丢弃无法复制数据的行,
S1.3,数据分析,寻找各种特征之间的相关性,
S1.4,特征工程,将部分特征分类为变量,并将变量转换为数值。
S1.5,模型创建,创建多个随机森林模型,
S1.6,模型评估一,通过检查混淆矩阵、召回结果和特异性来评估随机森林,选出准确性最高的作为筛选模型一,
S1.7,模型测试一,在社交网站中随机选取一定数量的客户作为测试,通过成功率判断筛选模型一的效果,
S1.8,创建筛选模型二,筛选模型二为一个与筛选模型一相同的随机森林模型,将筛选模型一的输出数据作为筛选模型二的输入数据并且附加行业及公司规模做为特征,
S1.9,模型评估二,检测筛选模型二的精度,
S1.10,模型测试二,通过超参数调整提高筛选模型二的精度并完成模型的建立。
所述数据分析还包括分析所有变量和创建图表解析数据,并且依据数据建立机器学习模型找出各种特征之间的相关性。
所述图表包括职务列表、目前就职公司规模列表、学历领域列表。
本发明的有益效果是:筛选模型一能够自动按照设置的筛选条件搜寻符合条件的潜在客户,再通过筛选模型二的进一步筛选后发送定制信息给该客户可以筛选出成功率比较高的客户,相比之前人工筛选和联系,我们的方法工作效率高、转化率高、节省时间,从而避免浪费时间在不适合的联系人,将时间和精力投入更适合的潜在客户。
附图说明
下面结合附图和实施例对本发明进一步说明。
图1是职位类型的分析图;
图2是学历类型的分析图;
图3是公司规模的分析图;
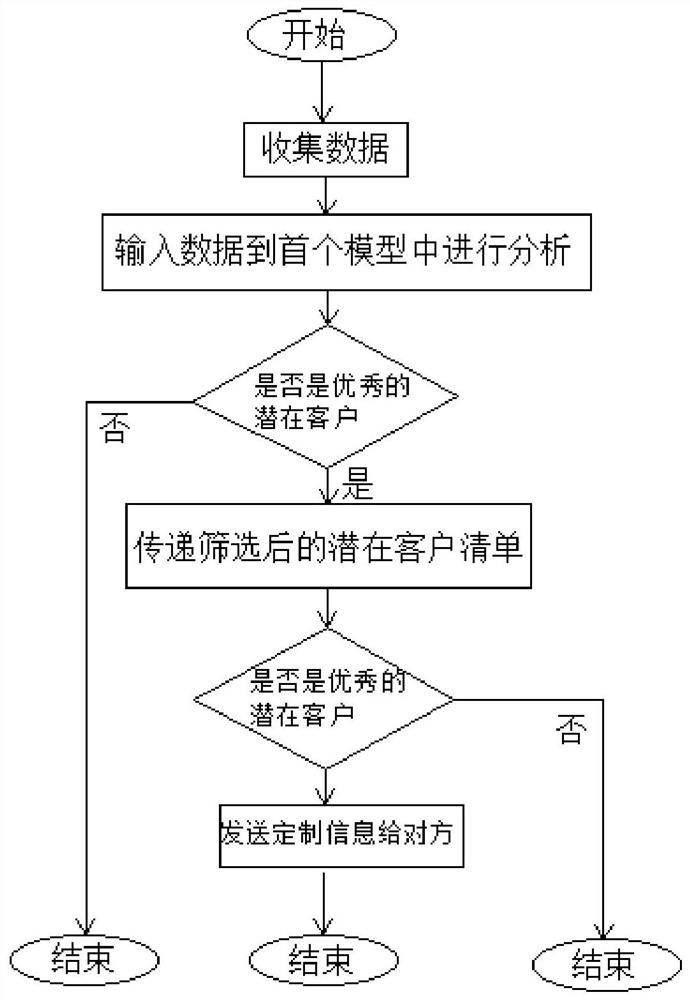
图4是本发明的流程图。
具体实施方式
参照图1至图4,本发明公开了一种利用社交软件大数据找寻潜在客户的方法,包括以下步骤:
S1,依据历史客户的信息作为数据创建筛选模型一和筛选模型二,
S2,对筛选模型一设置筛选条件,筛选条件包括教育背景、教育领域、目前就职公司、任职年限、出任职务、是否使用任何3D或CAD软件,筛选模型一依据筛选条件自动在网络上搜寻符合筛选条件的新客户,如筛选条件可以是本科以上、机械专业、美的集团、工作三年以上、管理层、使用3D或CAD软件其中的一种,这样根据上述条件我们能够初步筛选出所需要的客户,
S3,经过筛选模型一搜寻的新客户的信息输入筛选模型二同时附加行业及公司规模做为筛选模型二的筛选条件再次筛选,筛选条件为家电行业、公司营收超一千万或公司人数超一百人等,
S4,符合条件则发送定制信息联系该新客户。
所述筛选模型一和筛选模型二的创建包括以下步骤:
S1.1,数据收集,挑选2000名历史客户并收集这些历史客户的信息作为数据,历史客户包括下过订单的客户和给我司发送询价但最终没有下订单的客户,信息包括教育背景、教育领域、目前就职公司、任职年限、出任职务、是否使用任何3D或CAD软件,我们将这些客户的信息混合在数据库里,然后我们收集了他们在社交软件上公开的信息,
S1.2,数据清洗,因为收集到的数据是混乱的,因此,我们在适当的使用了插补方法清理数据,并丢弃了几行无法复制数据的行,
S1.3,数据分析,在此过程中,我们对整个数据进行分析,并寻找各种特征之间的相关性,确定哪些特征是重要变量,确定各种数据、目标变量的分布,
分析过程包括分析所有变量和创建图表解析数据,采用数据构建了机器学习模型,这些数据背后都包含不同的特征,因此,通过这些图表我们获得了更多数据,帮助我们确定目标变量的分布和变量之间的关系。例如,它告诉我们下订单的客户的联系人中有多少人是工程师或采购(如附图1所示,横坐标表示职位,纵坐标表示该职位对应的人数);多少客户的联系人的学历是硕士或博士(如附图2所示,横坐标表示学历,纵坐标表示该学历对应的人数);多少客户的规模有多大(如附图3所示,横坐标表示数量范围,纵坐标表示该数量范围对应的营收)等。然后我们对数据进行了分析,为了找出这些特征,我们检查了这些特征与目标变量的相关性,我们使用内置的导入变量功能,构建了一个基本模型并绘制出一个相关的图表,这个图表可以告诉我们哪些变量最重要,我将这些变量按升序进行排列,
目标变量可以区分下过订单与未下订单的客户。此变量的分布约为49%至51%。数据库中49%的客户下过订单,51%的人客户未下过订单,
S1.4,特征工程,部分特征都被分类为变量,这些变量格式各不相同。要使用这些变量,使用了独热编码技术将它们转换为数值,
S1.5,模型创建,创建多个随机森林模型,模型创建首先需要训练集,之后是测试集,通过训练集训练随机森林模型和通过测试集测试随机森林模型,我们可以用60:40,70:30或80:20的比率,优选了70:30,这些数据足够进行模型测试,根据数据的总量,按照比率随机分成两组,数据集被随机划分,两个集合中包含了各种变量。将数据按照70-30比率划分后,我们创建了随机森林模型。
随机森林模型以随机的方式分配数据,并建造出很多决策树,随后以民主方式采取所有决策树的平均值。随机森林所需的计算能力较少,它易于部署,完全可以满足我们的要求。
S1.6,模型评估一,通过检查混淆矩阵、召回结果和特异性来评估随机森林,选出准确性最高的作为筛选模型一,
S1.7,模型测试一,在社交网站中随机选取一定数量的客户作为测试,通过成功率判断筛选模型一的效果,我们使用领英网站中约500人的原始信息进行测试。筛选模型一在运行这些数据后,为我们筛选了140名潜在客户,然后我们在领英中发送建立联系的邀请给这些客户,以前人工筛选的邀请的接受率在20%左右,但现在达到了80%左右,因此,我们看到模型即时提升了转换率,帮助我们从原始数据中找出更适合的潜在客户。
S1.8,创建筛选模型二,筛选模型二为一个与筛选模型一相同的随机森林模型,将筛选模型一的输出数据作为筛选模型二的输入数据并且附加行业及公司规模做为特征,筛选模型一的整体精度约为82%。但召回是(1,0---62,98)。这意味着模型在筛除不适合人员时准确率达到98%,但在选择匹配客户时的准确率只有62%。在此基础上建立筛选模型二,筛选模型二将筛除更多不太可能向我们下订单的人员,在筛选模型二中,我们需要更具体的特征,将潜在客户与非客户分开,因此,我们决定使用行业及公司规模这两个特征,作为一家加工制造型企业,某些行业和公司规模非常适合我们,因此,第二个模型的目的就是从第一个模型的输出中,再次过滤掉其余不适合的人员,
S1.9,模型评估二,检测筛选模型二的精度,通过检查混淆矩阵、召回结果和特异性来评估筛选模型二的精度,筛选模型二的精度达到了85%,比第一个模型有显著的提高,
S1.10,模型测试二,通过超参数调整提高筛选模型二的精度并完成模型的建立,最终将模型的准确度提升到了89%。
综上所述,依据本方法原理建成的人工智能客源筛选器是一款销售效率软件,可以和领英、瞩目信息(美国B2B营销智能化服务公司)、行网(德国商务社交网站)等任何类型的市场开发工具匹配使用,通过更为精准的客源筛选,显著减少公司销售和市场部门产生的垃圾邮件。
以上对本发明实施例所提供的一种利用社交软件大数据找寻潜在客户的方法进行了详细介绍,本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处,综上所述,本说明书内容不应理解为对本发明的限制。
- 一种利用社交软件大数据找寻潜在客户的方法
- 一种基于大数据的停车场找寻方法