案情文本中智能提取文本摘要的方法、系统及电子设备
文献发布时间:2023-06-19 11:19:16
技术领域
本发明属于文本及自然语言处理技术领域,尤其涉及一种案情文本中智能提取文本摘要的方法、系统及电子设备。
背景技术
对文本进行自动摘要的提取,属于自然语言处理,提取摘要的一个好处是可以让阅读者通过最少的信息判断出这个文章对自己是否有意义或者价值,是否需要进行更加详细的阅读,并且可以让文章与文章之间产生关联,同时也可以让读者快速定位到相关的文章内容。
传统文本摘要的提取方法分为:1、抽取式自动文摘方法,通过提取文档中已存在的关键词形成摘要;2、生成式自动文摘方法,通过建立抽象的语意表示,使用自然语言生成技术,形成摘要。
上述传统的方法均无法提取结构化的文本摘要,使得提取到的文本摘要无法用数据或统一的结构加以表示,这样的文本摘要不利于案情文本的检索和对比,而对于案情文本来说,检索和对比尤为重要。
发明内容
基于此,针对上述技术问题,提供一种案情文本中智能提取文本摘要的方法、系统及电子设备。
为解决上述技术问题,本发明采用如下技术方案:
一方面,本发明提供一种案情文本中智能提取文本摘要的方法,包括:
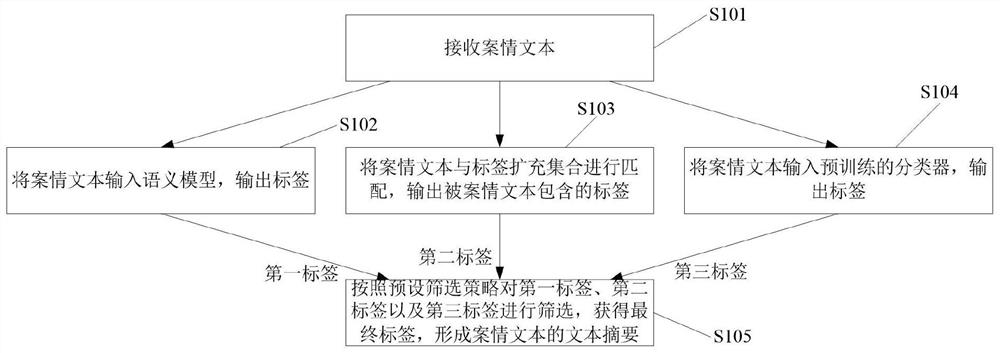
S101、接收案情文本;
S102、将所述案情文本输入语义模型,输出标签,所述语义模型被构建为:
将预先建立的标签集合中每个标签的说明描述和样本举例作为字符串1,将输入的案情文本作为字符串2,遍历每个标签对应的字符串1,计算字符串2与字符串1的相似度,输出相似度得分大于第一阈值的字符串1对应的标签;
所述标签集合中的标签用于形成案情文本的文本摘要,每个标签分别具有说明描述和样本举例;
S103、将所述案情文本与标签扩充集合进行匹配,输出被所述案情文本包含的标签,所述标签扩充集合由对所述标签集合进行同义词扩充后获得;
S104、将所述案情文本输入预训练的分类器,输出标签,用于训练所述分类器的训练样本为根据所述标签集合进行标注后的历史案情文本,且每种标签的历史案情文本的数量不小于第二阈值;
另一方面,本发明提供一种案情文本中智能提取文本摘要的系统,包括存储模块,所述存储模块包括由处理器加载并执行的指令,所述指令在被执行时使所述处理器执行上述的一种案情文本中智能提取文本摘要的方法。
再一方面,本发明提供一种电子设备,该设备具有上述的一种案情文本中智能提取文本摘要的系统。
本发明通过将案情文本输入语义模型、分类器以及与标签扩充集合进行匹配,分别得到标签,进而通过预设的融合策略将三种方式获得的标签进行融合,最终形成文本摘要,由于上述三种方式获得的标签均基于统一的定义,故本发明可以从案情文本中智能提取结构化的文本摘要,有利于案情文本的检索和对比。
附图说明
下面结合附图和具体实施方式本发明进行详细说明:
图1为本发明的流程图。
具体实施方式
如图1所示,本说明书实施例提供一种案情文本中智能提取文本摘要的方法,包括:
S101、接收案情文本。
S102、将案情文本输入语义模型,输出标签。
其中,语义模型被构建为:
将预先建立的标签集合中每个标签的说明描述和样本举例作为字符串1,将输入的案情文本作为字符串2,遍历每个标签对应的字符串1,计算字符串2与字符串1的相似度,输出相似度得分大于第一阈值的字符串1对应的标签,第一阈值可以选用0.5。
在本实施例中,语义模型采用的相似度得分函数为
其中,x
可以使用gensim工具包和公开的中文语料训练的词嵌入文件将字符串转换为数据向量(如(0.1,0.3,0.12,...)),也可以使用其它的词嵌入工具,比如fasttext工具包/bert等。
标签集合中的标签用于形成案情文本的文本摘要,每个标签分别具有说明描述和样本举例,具体地,标签集合建立过程如下:
1、收集案情维度信息,案情维度信息包括案件信息、案件大小、时间信息以及空间信息。案情维度信息为案情的核心维度信息,警官进行案情描述的时候,都会重点记录这些信息。
2、为每个案情维度信息定义对应的小颗粒度的标签,每个标签分别具有说明描述和样本举例,形成标签集合。
以丢失物品的案情为例,案情维度信息如下:
丢失物品(现金/电脑/首饰/手机/家电/纪念品),案件大小(团伙/单人),时间信息(工作日/休息日/清晨/上午/中午/下午/傍晚/上半夜/下半夜),空间信息(城区/乡镇/村庄),括号中为多个小颗粒度的标签。
现金标签的说明描述:人民币,美金等其他现钞与钞票,样本举例:杨某回家后,窗户被打开,并且发现床头柜里面一万人民币遗失。
S103、将案情文本与标签扩充集合进行匹配,输出被案情文本包含的标签。
其中,标签扩充集合由对标签集合进行同义词扩充后获得,如现金标签可以扩充的同义词为:现钞/纸币/人民币/美元/英镑/欧元/日元/韩币/钞票,在匹配时,如果案情文本中含有现金或者其同义词,则输出的标签为现金。
S104、将案情文本输入预训练的分类器,输出标签,用于训练分类器的训练样本为根据标签集合进行标注后的历史案情文本,且每种标签的历史案情文本的数量不小于第二阈值,如含有现金标签的历史案情文本的数量不小于第二阈值,第二阈值可以选用10000。
其中,分类器可以采用bert分类器,训练时采用的GPU型号为2080ti,操作系统为linux。
需要指出的是,步骤S102、S103以及S104不分先后顺序。
S105、将步骤S102输出的标签作为第一标签,将步骤S103输出的标签作为第二标签,将步骤S104输出的标签作为第三标签,按照预设融合策略对第一标签、第二标签以及第三标签进行融合,获得最终标签,形成案情文本的文本摘要。这样,可以将弱分类器和弱模型进行融合形成强模型,从而得到较好的精度,弱模型/分类器在数据不够大的情况下会形成统计学偏见、偏执、过拟合等情况,强模型可以缺避免这种情况。
在本实施例中,融合策略为:
1、保留第一标签与第三标签中相同的标签。
第一标签基于语义模型,分类器的训练也是基于文本的语义嵌入,故第三标签也基于语义模型。语义模型是基于统计与概率等的计算产物,大概率的计算结果是准确的,所以也会存在小概率的计算结果是错误的,第一标签与第三标签的交集可以很好地减少这个小概率的错误结果发生,从而达到性能的最优。
2、保留剩余第三标签中相应的样本数大于第三阈值的标签(阈值可以选为50000),随机保留剩余第一标签中预设比例的标签(可以选为50%)。
其中,第三标签是通过分类模型计算得到的,而模型训练的准确率很大程度由样本数据质量决定的,某一个标签的样本数据质量越好,则训练出来对该标签判断的准确率越高,样本数据的数量对其质量起到很重要的作用,所以阈值设置为50000。
而第一标签交集外的部分,如果全部丢弃,很大程度会遗漏一些正确的标签,所以这里保留50%。
3、保留所有第二标签,第二标签纯粹基于人工定义的规则,由于它是靠人工精选的扩充词库来匹配,所以准确率是可以得到保障,因此全部选取。
基于同一发明构思,本说明书实施例还提供一种案情文本中智能提取文本摘要的系统,包括存储模块,存储模块包括由处理器加载并执行的指令(程序代码),指令在被执行时使处理器执行本说明书上述一种案情文本中智能提取文本摘要的方法部分中描述的根据本发明各种示例性实施方式的步骤。
其中,存储模块可以包括易失性存储单元形式的可读介质,例如随机存取存储单元(RAM)和/或高速缓存存储单元,还可以进一步包括只读存储单元(ROM)。
可以以一种或多种程序设计语言的任意组合来编写用于执行本发明操作的程序代码,程序设计语言包括面向对象的程序设计语言—诸如Java、C++等,还包括常规的过程式程序设计语言—诸如“C”语言或类似的程序设计语言。程序代码可以完全地在用户计算设备上执行、部分地在用户设备上执行、作为一个独立的软件包执行、部分在用户计算设备上部分在远程计算设备上执行、或者完全在远程计算设备或服务器上执行。在涉及远程计算设备的情形中,远程计算设备可以通过任意种类的网络,包括局域网(LAN)或广域网(WAN),连接到用户计算设备,或者,可以连接到外部计算设备(例如利用因特网服务提供商来通过因特网连接)。
基于同一发明构思,本说明书实施例还提供一种电子设备,该电子设备具有本说明书上述的一种案情文本中智能提取文本摘要的系统,此处不再具体赘述。
但是,本技术领域中的普通技术人员应当认识到,以上的实施例仅是用来说明本发明,而并非用作为对本发明的限定,只要在本发明的实质精神范围内,对以上所述实施例的变化、变型都将落在本发明的权利要求书范围内。
- 案情文本中智能提取文本摘要的方法、系统及电子设备
- 文本提取方法、文本提取系统、电子设备和存储装置