一种基于深度学习的地面无人平台人员跟踪方法
文献发布时间:2023-06-19 11:32:36
技术领域
本发明属于地面无人平台感知决策技术领域,具体涉及一种基于深度学习的地面无人平台人员跟踪方法。
背景技术
地面无人平台的一大优势在于其负重能够远远超过普通人类。为利用这一优势,常常要求地面无人平台能够跟踪引导人员,穿越各种地面环境,这要求目标跟踪算法能够长时间跟踪移动目标。而人员作为移动目标,其型变和尺度变化较大,遮挡较多,目标跟踪算法需要极高的鲁棒性,以及跟丢目标后的纠错能力。
现有目标追踪技术,包括基于纯视觉和基于点云两种方法,但是基于视觉的算法容易目标漂移以致目标丢失,在长时间跟踪过程中,目标的遮挡型变容易出现目标漂移的问题,导致最终目标丢失,地面无人平台失去跟踪目标,只能人工检测目标是否丢失,并重新初始化开始跟踪。此外,而基于点云的算法缺乏灵活性,点云的人员目标跟踪一般无法区别人员,需要佩戴或穿着特殊的制品,这导致在实际应用中缺乏灵活性,当跟踪目标种类变更,特殊制品需要被更换,跟踪算法也需要被重新设计,并且如果多个特殊制品出现在视野范围内,点云不能对其进行有效的识别区分。
发明内容
(一)要解决的技术问题
本发明提出一种融合视觉和点云优势的基于深度学习的地面无人平台人员跟踪方法,以解决既如何提高目标跟踪算法的鲁棒性,又能免除点云中对于特殊穿戴物和手动设计特征依赖的技术问题。
(二)技术方案
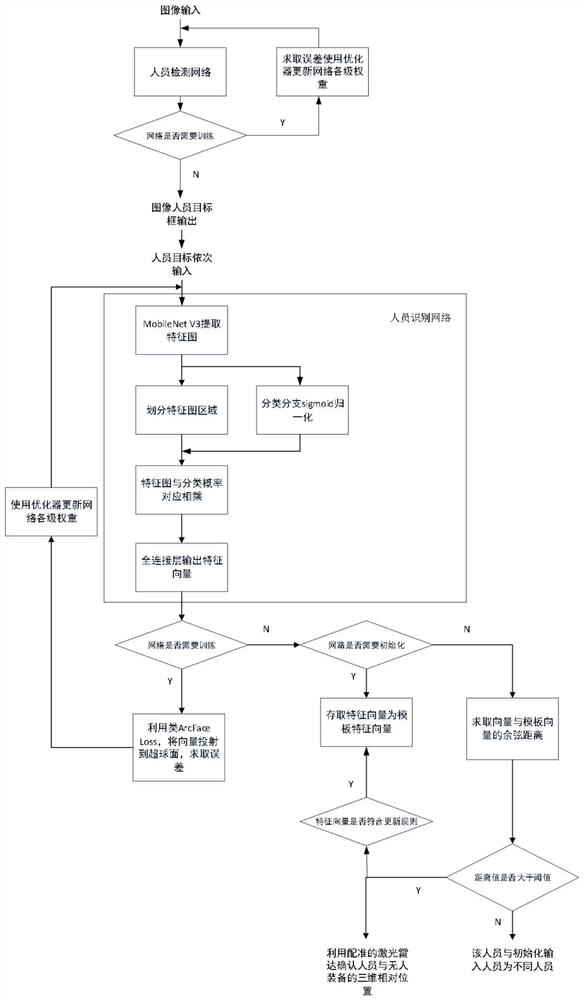
为了解决上述技术问题,本发明提出一种基于深度学习的地面无人平台人员跟踪方法,该跟踪方法包括以下步骤:
步骤S1、对摄像头采集的图像进行人员目标检测,输出图片内各个人员的像素坐标位置;
步骤S2、将图片内每个识别出的人员目标作为甄别对象,依次输入人员识别网络,通过骨干网络提取得到特征图,再针对确定的人员目标种类,对特征图进行区域划分;在将特征图进行全连层输出前,在特征图上添加分类分支,利用分类分支给每一部分的表征能力打分,对分数归一化后得到分类概率,输出的分类概率作为注意力权值与对应特征相乘得到最终具有高区分度的特征向量;
步骤S3、对跟踪方法进行初始化,以确认待跟踪的人员目标;初始化时,确保图像画面内只有待跟踪目标一人,由人员检测网络检测出人员的像素位置,再将由人员识别网络得到的特征向量存为模板向量;
步骤S4、初始化完成后,对之后视频的每一帧图像进行人员检测和人员识别,提取出各人员的特征向量,与模板向量进行余弦距离计算,将距离值小于阈值的特征向量作为待跟踪人员的特征向量,并以如公式2、3所示的更新规则,更新模板向量:
其中,T
步骤S5、根据待跟踪人员的特征向量,反推出待跟踪人员的图像像素坐标,利用联合标定的激光雷达与摄像头的感知系统,将待跟踪人员的图像像素坐标转换为与激光雷达的三维相对位置,经过坐标转换后最终确定识别目标与地面无人平台的三维相对位置,从而实现对特定人员目标的三维位置跟踪。
进一步地,步骤S1中,人员目标检测网络使用通用目标检测网络作为基准网络;以收集标注好的人员目标图片作为训练数据,对基准网络进行训练;在去除基准网络的分类通道后重新训练,根据标注信息与网络输出求取误差,利用优化器更新网络各级权重,直至网络误差收敛。
进一步地,步骤S2中,通过骨干网络MobileNetV3提取得到压缩步长为32x的特征图。
进一步地,步骤S2中,将特征图分为6份,并平均池化分为三部分,从上往下的第一部分表征头部,第二和第三部分表征躯干,剩下部分表征下肢。
进一步地,步骤S2中,对分数使用sigmoid归一后得到分类概率。
进一步地,步骤S2中,在使用识别网络输出的特征向量前,首先对识别网络进行训练,利用如公式1所示的类ArcFaceLoss的误差设计求取误差,将特征向量投射到高维超球面,剔除高维特征向量的模长影响,不同种的向量差距由余弦距离进行表示:
其中,Loss为识别误差输出,n为数据库中人员个体的总数,θ为权重与输入之间的夹角,s为用于保持误差数值稳定的常数。
(三)有益效果
本发明提出一种基于深度学习的地面无人平台人员跟踪方法,包括行人目标检测、人员识别以及图像与激光雷达的匹配方法。其中,行人目标检测提取出图像中包含人员的包围框,人员识别则是从提取的包围框中识别出特定的引导人员,图像与激光雷达的匹配方法则是计算出特定引导人员与地面无人平台的相对距离,为之后的底盘跟踪速度生成提供数据。本发明能够实现无人平台对人员的跟踪,不需要人员穿戴特殊制品的前提下,解决了传统视觉目标跟踪易导致的目标漂移问题,提高了算法的鲁棒性,同时不损失算法使用的灵活性。
附图说明
图1为本发明实施例的方法流程图;
图2为本发明实施例中特征图池化示意图:(a)人员特征图;(b)特征图分为6份;(c)分为6份的特征图池化分为三部分。
具体实施方式
为使本发明的目的、内容和优点更加清楚,下面结合附图和实施例,对本发明的具体实施方式作进一步详细描述。
本实施例提出一种基于深度学习的地面无人平台人员跟踪方法,主要流程如图1所示,该方法包括以下步骤:
步骤S1、对摄像头采集的图像进行人员目标检测,输出图片内各个人员的像素坐标位置。
人员目标检测网络使用高检测精度、高鲁棒性、高检测速率的通用目标检测网络作为基准网络。基准网络需要经过训练才能正确检测人员目标,收集标注好的人员目标图片作为训练数据,在去除基准网络的分类通道后重新训练,根据标注信息与网络输出求取误差,利用优化器更新网络各级权重,直至网络误差收敛。
步骤S2、将图片内每个识别出的人员目标作为甄别对象,依次输入人员识别网络,首先通过骨干网络MobileNetV3提取得到压缩步长为32x的特征图,再针对确定的人员目标种类,对特征图进行区域划分,包括:将特征图分为6份,并依试验经验值平均池化分为三部分,从上往下的第一部分表征头部,第二和第三部分表征躯干,剩下部分表征下肢,如图2所示。在将特征图进行全连层输出前,在特征图上添加分类分支,利用分类分支给每一部分的表征能力打分,对分数使用sigmoid归一后得到分类概率,输出的分类概率作为注意力权值与对应特征相乘得到最终具有高区分度的特征向量。
在使用识别网络输出的特征向量前,首先对识别网络进行训练,利用类ArcFaceLoss的误差设计(如公式1所示)求取误差,将特征向量投射到高维超球面,从而剔除高维特征向量的模长影响,不同种的向量差距可以由余弦距离进行表示。
其中,Loss为识别误差输出,n为数据库中人员个体的总数,θ为权重与输入之间的夹角,s为用于保持误差数值稳定的常数。
步骤S3、对跟踪方法进行初始化,以确认待跟踪的人员目标。初始化时,确保图像画面内只有待跟踪目标一人,由人员检测网络检测出人员的像素位置,再将由人员识别网络得到的特征向量存为模板向量。
步骤S4、初始化完成后,对之后视频的每一帧图像进行人员检测和人员识别,提取出各人员的特征向量,与模板向量进行余弦距离计算,将距离值小于阈值的特征向量作为待跟踪人员的特征向量,并以一定更新规则(如公式2、3所示)更新模板向量。
其中,T
步骤S5、根据待跟踪人员的特征向量,反推出待跟踪人员的图像像素坐标,利用联合标定的激光雷达(可提供三维坐标)与摄像头(可提供像素坐标)的感知系统,将待跟踪人员的图像像素坐标转换为与激光雷达的三维相对位置,经过坐标转换后最终确定识别目标与地面无人平台的三维相对位置,从而实现对特定人员目标的三维位置跟踪。
本发明的地面无人平台人员跟踪方法包括目标检测、目标识别和点云图像配准。其中,目标检测与目标识别组合可以有效地解决视觉目标跟踪易造成的目标框漂移问题,同时因为目标检测检测种类的多样和视觉图像包含的丰富信息,能够摆脱点云目标跟踪算法对特殊穿戴品依赖。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明技术原理的前提下,还可以做出若干改进和变形,这些改进和变形也应视为本发明的保护范围。
- 一种基于深度学习的地面无人平台人员跟踪方法
- 一种基于深度学习检测跟踪的地面无人平台自主跟随系统