一种基于深度学习的图像关键信息提取系统
文献发布时间:2023-06-19 12:05:39
技术领域
本发明涉及计算机深度学习领域,尤其涉及一种基于深度学习的图像关键信息提取系统。
背景技术
关于光学字符识别(O批cal Character Recognition,下面都简称OCR),是指将图像上的文字转化为计算机可编辑的文字内容;在金融领域的应用则更加广泛,对于上市公司发布的公告、财报、研报等不可编辑的pdf文档,需要做结构化处理并抽取还原,提取关键信息供需要的用户参考。
但是该领域仍然存在着很多问题有待解决。例如文本检测存在着文本框识别不全、文本框识别不准确等问题。文本识别部分存在着文字识别精度过低、无法适应复杂的债券的背景等问题。
随着智能化检测识别技术的不断优化,减轻人工检测识别的劳动强度,提高债券文本检测、识别的效率和准确率显得尤为重要。因此一个实用的、能适应复杂背景的债券文本检测识别系统有着广阔的市场和应用环境。
近年来人工智能等新技术飞速发展,在各行各业的应用越来越广泛,利用深度学习在图像文本位置检测、文本内容识别中的应用,可以显著提高图像文本检测、文本内容识别的精度和效率,大大的解放了人的生产力。通过文本检测模型和文本识别模型能够快速精确的识别出债券上文本的位置和对应位置中文本的内容。
为了能够快速识别文本,目前采用的主要方法有Textboxes算法、改进的TestBoxes++算法、CPTN算法和SEGLINK算法。之后的研究主要针对这几种算法进行改进,改进的TestBoxes++算法有类似SSD的多尺度结构,结构简单,运行速度快,并且算法可以直接在在feature map上进行分类和回归,可以回归到四边形或者带角度的矩形,这样就可以支持多尺度的文本检测。CPTN算法将CNN与RNN结合,同时学习空间特征和序列特征,空间特征用来描述CPTN检测到的小的文字片段,序列特征可以学习小的文字片段之间的关联性。SEGLINK算法结合了CPTN算法的局部片段预测与SSD算法的多尺度预测,可同时预测不同scale下的segment和link,以学习的方式连接文本,可以处理多方向任意长度的文本。对于传统算法无法检测较大的文本、无法检测形变或曲线的文本以及针对横向文本两端位置定位精度较低的问题。基于此提出了一种基于深度学习的图像关键信息提取系统。
发明内容
本发明的目的是解决对于传统算法无法检测较大的文本、无法检测形变或曲线的文本以及针对横向文本两端位置定位精度较低的问题,而提出一种基于深度学习的图像关键信息提取系统。
为了实现上述目的,本发明技术方案如下:
本系统的设计主要分为如下几个部分:首先是文本检测(AdvancedEast)模块,文本检测算法从CTPN提出以来已经取得了长足的发展。以前的文本检测方法比如Fast-RCNN等已经在不同的基准上取得了很好的性能。然而,在处理具有挑战性的复杂场景时,有的准确度不足,有的速度偏慢。并且都存在着一些问题,比如多数模型在长文本检测方面表现得不够优秀、有的模型不能识别有角度倾斜的文本等。因此我们采用了AdvancedEast作为文本检测算法的基础模型,该模型在长文本检测方面表现优良,且可以检测带倾斜角度的文本,并且我们对该模型的特征提取模块做了改进;大部分现有的AdvancedEast模型采用VGG16作为特征提取模块,然而在此次的文本检测任务中,VGG16表现得并不好,因此我们采用了Mobilenet-v3large作为特征提取模块。在此次识别的场景之下,相比于VGG16而言,Mobilenet-v3 large版本的advancedeast模型不仅仅更加轻量,识别的速度更快,而且识别的效果也更好。
然后是文本识别模块(CRNN+CTC)。CRNN(卷积循环神经网络)为CNN+RNN的组合,模型既有CNN强大的提取特征的能力,又有与RNN相同的性质,能够产生一系列序列化标签。CRNN模型分为三个部分:卷积层、循环层、转录层。
卷积层:提取特征(32*280*1)。
循环层:使用深层双向RNN,预测从卷积层获取的特征序列的标签(真实值)分布(64*512)。
转录层:使用CTC,代替softmax,训练样本无需对齐。
附图说明
图1为详细技术路线图;
图2为软件架构图;
图3为CRNN+CTC原理图;
图4为文本识别模型流程图;
具体实施方式
整个方法的具体实施方案主要分为两个重要部分:文本检测模型、文本识别模型。
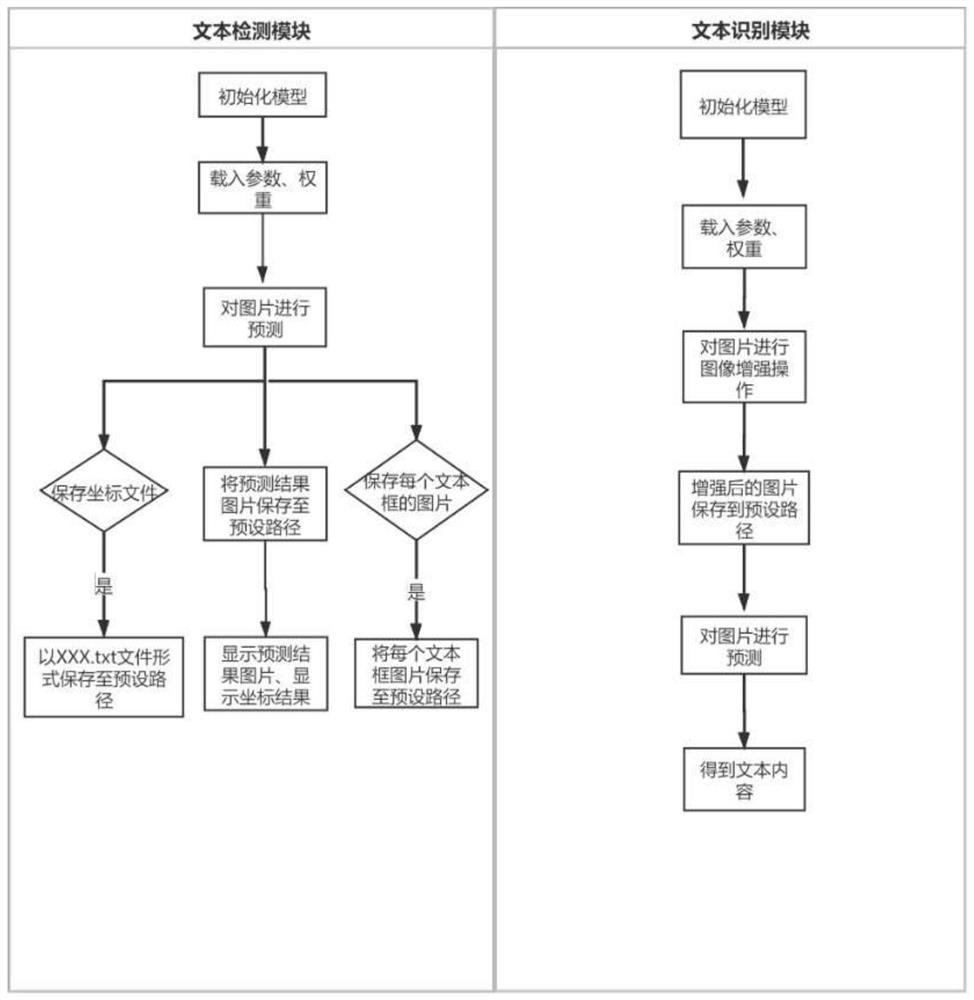
文本检测模型:在软件界面上,点击“选择文件”按钮,用户输入待检测的图片,点击识别按钮,向后端发送请求,后端响应请求并保存图片至预设路径;接着到“文本检测模块”,程序初始化模型并载入权重和相关参数,对已经保存的图片进行识别预测,若选择保存坐标文件,则会自动生成后缀为.txt的文件,保存至指定路径,预测结果图片保存至路径后,最终在前端界面显示,文本框的坐标信息同时也会显示在前端界面上,若选择保存每个文本框的图片,则会将每个部分文本框图片保存至路径。最终,界面左边显示待预测的图片,界面右侧上方显示预测图片的结果,界面右侧下方显示坐标信息。
文本检测模型具体实现方式:
(1)数据集收集:采用了阿里天池ICPR MTWI 2018网络挑战赛数据和一些自行制作的债券文本数据组合为混合数据集来作为最终的训练集;在增加模型的背景复杂性的同时,也加入我们本次检测任务的识别背景;这不仅减小了其过拟合的风险,也在一定程度上增强了模型的泛化性。对于每一张图像,都会有一个相应的文本文件(.txt)(UTF-8编码与名称:[图像文件名].txt)。文本文件是一个逗号分隔的文件,其中每行对应于图像中的一个文本串,并具有以下格式:
X1,Y1,X2,Y2,X3,Y3,X4,Y4,“文本”
其中X1,Y1,Y2,X2,X3,X4,Y3,Y4分别代表文本的外接四边形四个顶点坐标。而“文本”是四边形包含的实际文本内容。
(2)数据集预处理:在训练之前,我们分别对图片和标签进行了处理,并且按照9:1的概率划分了训练集和验证集。我们直接采用了最大的736*736的图片大小。并用AdvancedEast的识别方法进行了图片的标注。
(3)标签预处理:对标签进行预处理,转化为.npy的标签文件,便于训练,并进一步的转为,_gt.npy的文件。在转化过程中,对标签进行了标签平滑处理。最终我们把数据集转化为LMDB的数据集的形式,便于训练。
(4)实现Precision、recall相关指标:因为模型本身比较特殊,pytorch的评估函数自带的训练函数和其中的评估指标并不能实现我们需要的评估指标,因此我们在AdvancedEast模型的基础上添加了评估类eval_pre_rec_f1,适配AdvancedEast模型在训练中实时的输出这三个指标,并且重写了训练函数,用自定的训练函数进行训练。
(5)开始训练以及评估:我们使用的1mdb格式的数据集进行训练,将模型转化为train模式,用我们得出结果后计算一次损失值,用优化器进行优化,train_loss_list存储每一个batchsize的训练损失,每一个epoch输出最后一次计算的train_loss值。我们设定每一个epoch结束就评估一次,在评估部分输出meanPrecision,meanRecall,meanF1-score:(在IOU=0.5的情况下计算,TP:正确预判的正例数,FP:错误预判的负例数,FN:错误预判的负例数)。
评估的时候,先将模型的模式设置为评估:eval模式,这里的ValInterval=1。每次输入一个bach_size的图片集合,得到结果后,将对应的标签和预测结果输入到eval_p_r_f.add()中,计算出对应的指标值。
我们最终保存的模型是f1-score值最高的模型。
文本识别模块:在软件界面上,点击“选择文件”按钮,初始化模型,载入权重参数后,对输入的图片进行图像增强操作,之后模型对增强后的图片进行预测,得到文本内容,并把文本内容返回并显示到前端的界面上。
最终,界面左边显示待预测的图片,界面右侧显示预测出的文本内容。
文本识别模块具体实现方式:
(1)数据集搜集:训练集使用的是混合数据集,使用360万中文数据部分,每张图片由10个字符组成,里面加入了模糊、锐化、轻微旋转等一系列的干扰因素,一方面数据量庞大,保证了模型的泛化性与精度,另一方面按照10∶1的比例加入我们需要的特征,同时又能兼顾精度。
(2)训练数据预处理:首先在训练之前就用opencv的函数库将图片转化为(280,32)的大小,防止后面在自行转化的时候出现失真的状况,影响识别的效果。这里采用cv2.INTER_CUBIC(立方插值)的方法。
(3)将处理后的训练数据转化为LMDB数据集。
(4)开始训练:采用pytorch的官方函数进行训练,最终保存验证时val_acc最高的值的训练模型。
本发明未尽事宜为公知技术。
上述实施例只为说明本发明的技术构思及特点,其目的在于让熟悉此项技术的人士能够了解本发明的内容并据以实施,并不能以此限制本发明的保护范围。凡根据本发明精神实质所作的等效变化或修饰,都应涵盖在本发明的保护范围之内。
- 一种基于深度学习的图像关键信息提取系统
- 一种基于深度学习的小肠核磁共振影像图像识别和生理学信息提取系统及方法