一种任务监控方法、装置、设备及存储介质
文献发布时间:2023-06-19 13:29:16
技术领域
本发明涉及信息处理技术领域,更具体地说,涉及一种任务监控方法、装置、设备及存储介质。
背景技术
当使用Flink作为处理引擎,编写一个Flink任务来处理数据时,一般会从多个数据来源抽取数据,同时对于某一个数据源,也会设置多个并行度来提高从当前数据源获取数据的速度。在这种情况下,不同的Flink任务基本是分布在不同实体机的不同JVM中的;而Flink本身提供的度量统计数据是算子的单个并行任务的数据,当想要了解整个任务接收或者输出了多少数据等情况的时候,则是没有办法进行相应的统计分析等。
发明内容
本发明的目的是提供一种任务监控方法、装置、设备及存储介质,能够对Flink任务运行过程中的情况进行监控,便于需要了解整个Flink任务情况时进行相应的统计分析等操作。
为了实现上述目的,本发明提供如下技术方案:
一种任务监控方法,包括:
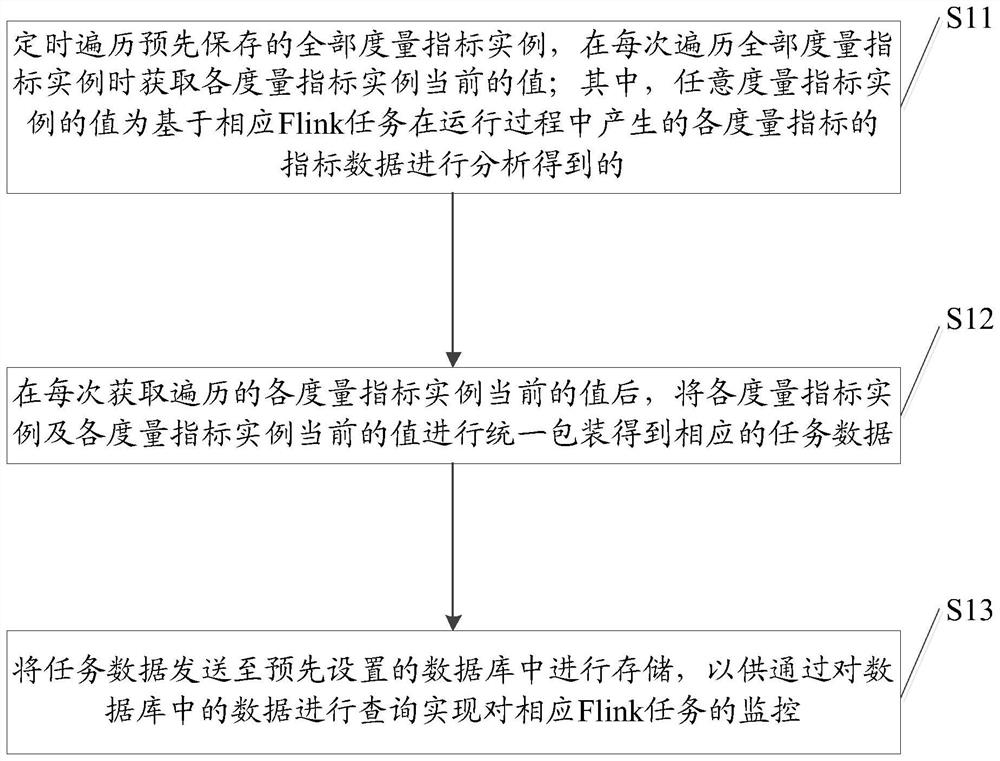
定时遍历预先保存的全部度量指标实例,并在每次遍历全部度量指标实例时获取各度量指标实例当前的值;其中,任意度量指标实例的值为基于相应Flink任务在运行过程中产生的各度量指标的指标数据进行分析得到的;
在每次获取遍历的各度量指标实例当前的值后,将各度量指标实例及各度量指标实例当前的值进行统一包装得到相应的任务数据;
将所述任务数据发送至预先设置的数据库中进行存储,以供通过对所述数据库中的数据进行查询实现对相应Flink任务的监控。
优选的,预先保存所述度量指标实例,包括:
确定任意Flink任务在运行过程中需要获取相应指标数据的各度量指标;
基于该任意Flink任务对应的各度量指标构建并保存相应的度量指标实例;其中,同一度量指标实例对应的各度量指标按照被检索的可能性越大越靠前的方式排列。
优选的,构建度量指标实例,包括:
构建与各Flink任务中任意Flink任务的各度量指标对应的度量指标实例,将各度量指标实例以一一对应的关系分别映射到同种类的不同javabean中,并在各javabean中存储所映射的度量指标实例对应的各度量指标。
优选的,将各度量指标实例及各度量指标实例当前的值进行统一包装得到相应的任务数据,包括:
确定各度量指标实例为当前实例,将当前时间、当前实例对应各度量指标及当前实例当前的值统一包装成相应任务数据。
优选的,将所述任务数据发送至预先设置的数据库中进行存储,包括:
将所述任务数据发送至Kafka中的对应主题下,以供DruidIO对所述Kafka中相应主题下的任务数据进行获取。
优选的,定时遍历预先保存的全部度量指标实例,包括:
使用Scheduled定时器定时遍历预先保存的全部度量指标实例。
优选的,还包括:
所述DruidIO接收查询请求,并将查询请求对应的任务数据进行绘制后显示;其中,所述查询请求为以SQL方式构建的请求。
一种任务监控装置,包括:
获取模块,用于:定时遍历预先保存的全部度量指标实例,并在每次遍历全部度量指标实例时获取各度量指标实例当前的值;其中,任意度量指标实例的值为基于相应Flink任务在运行过程中产生的各度量指标的指标数据进行分析得到的;
包装模块,用于:在每次获取各度量指标实例当前的值后,将各度量指标实例及各度量指标实例当前的值进行统一包装得到相应的任务数据;
存储模块,用于:将所述任务数据发送至预先设置的数据库中进行存储,以供通过对所述数据库中的数据进行查询实现对相应Flink任务的监控。
一种任务监控设备,包括:
存储器,用于存储计算机程序;
处理器,用于执行所述计算机程序时实现如上任一项所述任务监控方法的步骤。
一种计算机可读存储介质,所述计算机可读存储介质上存储有计算机程序,所述计算机程序被处理器执行时实现如上任一项任务监控方法的步骤。
本发明提供了一种任务监控方法、装置、设备及存储介质,该方法包括:定时遍历预先保存的全部度量指标实例,并在每次遍历全部度量指标实例时获取各度量指标实例当前的值;在每次获取遍历的各度量指标实例当前的值后,将各度量指标实例及各度量指标实例当前的值进行统一包装得到相应的任务数据;将所述任务数据发送至预先设置的数据库中进行存储,以供通过对所述数据库中的数据进行查询实现对相应Flink任务的监控;任意度量指标实例的值为基于相应Flink任务在运行过程中产生的各度量指标的指标数据进行分析得到的。本申请通过定时遍历获取各Flink任务对应度量指标实例的值,得到各Flink任务在运行过程中产生各度量指标的指标数据分析所得结果,进而将这些结果统一包装后存储至数据库中,以供对各Flink任务运行过程的情况进行统计分析等操作。可见,本申请能够对Flink任务运行过程中的情况进行监控,便于需要了解整个Flink任务情况时进行相应的统计分析等操作。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。
图1为本发明实施例提供的一种任务监控方法的流程图;
图2为本发明实施例提供的一种任务监控方法中数据处理流程示意图;
图3为本发明实施例提供的一种任务监控装置的结构示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
请参阅图1,其示出了本发明实施例提供的一种任务监控方法的流程图,具体可以包括:
S11:定时遍历预先保存的全部度量指标实例,在每次遍历全部度量指标实例时获取各度量指标实例当前的值;其中,任意度量指标实例的值为基于相应Flink任务在运行过程中产生的各度量指标的指标数据进行分析得到的。
需要说明的是,Flink是一款分布式实时流式处理引擎,其是通过Dataflow流式计算模式实现低延迟、高吞吐、高性能兼具的实时流式计算框架,同时Flink支持高度容错的状态管理,防止状态在计算过程中因为系统异常而出现丢失。Flink周期性的通过分布式快照技术Checkpoints实现状态的持久化维护,使得即使在系统停机或者异常的情况下都能计算出正确的结果。
本申请实施例中使用Flink作为处理引擎,编写Flink任务来实现相应的数据处理;并且,本申请实施例在Flink中设置自定义的Reporter,进而基于该自定义的Reporter实现任务监控方案。具体来说,本申请可以预先设置度量指标实例,在任意Flink任务运行的过程中,可以实时或者定时获取该任意Flink任务运行过程中产生的各度量指标的指标数据,进而基于获取的该任意Flink任务运行过程中产生的指标数据进行统计分析,得到该任意Flink任务对应度量指标实例的值;其中,度量指标为表示Flink任务运行过程中各项情况的指标,如可以包括来源种类、运行主机、来源种类名称、来源种类ID、并行度ID等,指标数据则为获取的度量指标的值,而度量指标实例的值则为通过对指标数据进行分析可得到的值,如可以包括接收数据量、发送数据量及系统负载等。
S12:在每次获取遍历的各度量指标实例当前的值后,将各度量指标实例及各度量指标实例当前的值进行统一包装得到相应的任务数据。
为了便于对数据的统计分析,本申请实施例在每次遍历到各度量指标实例当前的值后,可以将当前次遍历得到的各度量指标实例当前的值进行统一包装得到相应的任务数据;而对各度量指标实例当前的值进行统一包装的具体方式可以根据实际需要进行确定,如将其均转换为统一的格式等,均在本发明的保护范围之内。
S13:将任务数据发送至预先设置的数据库中进行存储,以供通过对数据库中的数据进行查询实现对相应Flink任务的监控。
在每次统一包装得到相应的任务数据后,则可以将任务数据发送至预先设置的数据库中进行存储,从而使得相关人员能够从数据库中查询任务数据并进行相应的统计分析等操作。
本申请通过定时遍历获取各Flink任务对应度量指标实例的值,得到各Flink任务在运行过程中产生各度量指标的指标数据分析所得结果,进而将这些结果统一包装后存储至数据库中,以供对各Flink任务运行过程的情况进行统计分析等操作。可见,本申请能够对Flink任务运行过程中的情况进行监控,便于需要了解整个Flink任务情况时进行相应的统计分析等操作。
本发明实施例提供的一种任务监控方法,预先保存度量指标实例,具体可以包括:
确定任意Flink任务在运行过程中需要获取相应指标数据的各度量指标;
基于该任意Flink任务对应的各度量指标构建并保存相应的度量指标实例;其中,同一度量指标实例对应的各度量指标按照被检索的可能性越大越靠前的方式排列;
其中,构建度量指标实例,可以包括:
构建与各Flink任务中任意Flink任务的各度量指标对应的度量指标实例,将各度量指标实例以一一对应的关系分别映射到同种类的不同javabean中,并在各javabean中存储所映射的度量指标实例对应的各度量指标;
而定时遍历预先保存的全部度量指标实例,可以包括:
使用Scheduled定时器定时遍历预先保存的全部度量指标实例。
需要说明的是,本申请实施例设置Reporter中度量名称的组合方式,具体来说,Flink中度量指标的具体名称的是比较复杂的,其会根据来源种类、运行主机、来源种类名称、来源种类ID、并行度ID等确定;并且度量指标会根据来源种类进行分组,来源种类包括JobManager、TaskManager、算子等。为便于在查询时实现度量名称的过滤识别,本申请实施例可以按照被检索可能性越大越靠前的方式对度量名称进行相应的排列,从而在自定义时在Flink的主要配置文件(flink-conf.yaml)中,添加自主组合方式,修改算子的度量指标名称格式为:
metrics.scope.operator:
其中,尖括号内的属性均为度量指标,其会在相应Flink任务运行时依据实际情况自动进行填充,这样将度量指标进行排序,能够在度量指标名称比较奇怪或者含有大量不确定字符时被放到最后,进而方便的对前面的较为清晰的、明确的度量指标名称(也即最可能被检索的名称)进行获取。然后将度量指标的组合方式作为参数告知自定义的Reporter,方便在程序中对度量指标进行分隔处理:
metrics.reporter.Kafka.metrics.scope.operator:
本申请实施例还可以在自定义Reporter中进行数据标准化,主要通过实现MetricReporter构建自定义的Fafka Reporter,同时实现Scheduled定时器以便定期将度量指标的指标数据推送出去;具体来说,本申请实施例可以在内存中保存着不同类型的度量指标实例,比如Counters(计数)、Gauges(测量)、Histograms(统计)以及Meters(速率)等,在监听到度量指标实例的数量修改时,同步调整度量指标实例的映射关系,进而将不同的度量实例分别映射到相同种类的不同JavaBean中。另外,本申请实施例在构建JavaBean时,在JavaBean定义所关心的字段(即度量指标),比如主机名(host)、任务ID(jobID)、任务名(jobName)、任务运行的子程序序号(subtaskIndex)、算子ID(operatorID)、算子名称(operatorName)、度量名称(key)以及数据表名称(tableName)等,进而在做映射生成JavaBean时,根据上述定义的格式实现度量指标的组合;如可以拿出算子名称(operatorName),如果它是以“Source:”为开头,那么就可以确定该JavaBean是一个数据源算子,在进行标注后,就可以将相关数据进行赋值保存。
本发明实施例提供的一种任务监控方法,将任务数据发送至预先设置的数据库中进行存储,可以包括:
将任务数据发送至Kafka中的对应主题下,以供DruidIO对Kafka中相应主题下的任务数据进行获取;
其中,另外,将各度量指标实例及各度量指标实例当前的值进行统一包装得到相应的任务数据,可以包括:
确定各度量指标实例为当前实例,将当前时间、当前实例对应各度量指标及当前实例当前的值统一包装成相应任务数据;
另外,本发明实施例提供的一种任务监控方法,还可以包括:
DruidIO接收查询请求,并将查询请求对应的任务数据进行绘制后显示;其中,查询请求为以SQL方式构建的请求。
本申请实施例在实现标准化数据入库时,可以依据上述定制的度量指标实例与JavaBean的映射关系,以及定时器的Scheduled接口,可以配置每隔3秒钟将真实度量指标的指标数据发送出去一次。具体来说,在定时执行的方法中遍历所有保存的度量指标实例,对于每一个度量指标实例,因为都有一个JavaBean与之关联,并且该JavaBean中保存了该度量指标实例的基本信息(也即该度量指标实例对应的各项度量指标),因此可以构建统一的发送数据格式,即包含三个部分:1:当前时间,2:JavaBean基本信息,3:度量实例的当前值;进而将所有当前时间的度量信息统一包装好。
本申请实施例可以构建Kafka数据发送器,将准备好的数据通过Kafka发送器发送到预先Kafka下创建好并指定的主题中,该主题统一接收所有Flink集群的指标数据,且使用json数据格式实现所接收数据的存储。本申请实施例还可以搭建DruidIO,通过DruidIO内置的Kafka插件,对Kafka下上述主题中的数据进行获取。同时定义用于存储任务数据的表格,并定义任务数据的转换方式,对抽取到的任务数据进行字段关系映射,将json格式的数据映射成单层的列。DruidIO对外统一提供“time”(时间)、“host”(主机名)、“jobID”(任务ID)、“operatorID”(算子ID)、“tableName”(数据表名)、“sourceOperator”(是否为数据来源算子)、“key”(度量名称)、“value”(度量值)等可供查询的字段,且DruidIO提供以SQL的方式查询存储的表,但是需要使用http请求封装一次。具体来说,可以根据业务需要,对且DruidIO进行数据聚合查询,比如:需要查询某个任务在某段时间内的数据输入总量趋势图,那么可以构建SQL查询思路——过滤任务ID为关心的任务ID,过滤度量指标名称为关注的“numRecords”,过滤数据为数据来源算子,过滤时间为指定时间段。最后通过聚合函数,统计出不同时间点上各数据来源接收到的数据总量值,示例SQL可以如下:
对于上述SQL查询出来的是不同的时间点对应的输入数据的总值(按不同输入表划分),示例可以如下:
[
{time:1,value:100,tableName:t1},
{time:1,value:50,tableName:t2},
{time:1,value:200,tableName:t3},
{time:2,value:200,tableName:t1},
{time:2,value:100,tableName:t2},
{time:2,value:400,tableName:t3},
{time:3,value:300,tableName:t1},
{time:3,value:150,tableName:t2},
{time:3,value:800,tableName:t3}
]
将上述数据绘制出来,即可查看不同时间点的数据总量,同时也能查看具体不同来源表的总量,通过这种方式,来获取更加值得关注的各种度量指标的数据。另外,本申请实施例还可以在获取到任务数据后直接将任务数据存储至clickhouse、mySQL等,均在本发明的保护范围之内。
本申请的数据流程处理示意图可以如图2所示,具体来说,本申请首先自定义Flink Reporter,在Reporter中对Flink任务的各种度量指标进行分类标准化,并将度量指标相关数据存入数据库,最后使用聚合查询,统计出Flink任务的整体流量。本申请能够在Reporter中对度量指标相关数据按特定的方式进行拆分、重组,并额外增加一些特定的数据及标识信息,来完成各种度量指标的标准化,在数据推送到特定的中间件或存储中后,可以增加从Flink任务整体角度对Flink任务度量指标的分析与展现。从而可以通过比较简单的方式对整个任务进行度量指标统计查询,且支持对过往度量指标数据进行查询。
本发明实施例还提供了一种任务监控装置,如图3所示,可以包括:
获取模块11,用于:定时遍历预先保存的全部度量指标实例,并在每次遍历全部度量指标实例时获取各度量指标实例当前的值;其中,任意度量指标实例的值为基于相应Flink任务在运行过程中产生的各度量指标的指标数据进行分析得到的;
包装模块12,用于:在每次获取各度量指标实例当前的值后,将各度量指标实例及各度量指标实例当前的值进行统一包装得到相应的任务数据;
存储模块13,用于:将任务数据发送至预先设置的数据库中进行存储,以供通过对数据库中的数据进行查询实现对相应Flink任务的监控。
本发明实施例还提供了一种任务监控设备,可以包括:
存储器,用于存储计算机程序;
处理器,用于执行计算机程序时实现如上任一项任务监控方法的步骤。
本发明实施例还提供了一种计算机可读存储介质,计算机可读存储介质上存储有计算机程序,计算机程序被处理器执行时可以实现如上任一项任务监控方法的步骤。
需要说明的是,本发明实施例提供的一种任务监控装置、设备及存储介质中相关部分的说明请参见本发明实施例提供的一种任务监控方法中对应部分的详细说明,在此不再赘述。另外本发明实施例提供的上述技术方案中与现有技术中对应技术方案实现原理一致的部分并未详细说明,以免过多赘述。
对所公开的实施例的上述说明,使本领域技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
- 一种任务监控方法、装置、设备以及存储介质
- 分布式任务监控方法、装置、终端设备及存储介质