融合多源数据的Telegram中文群组检索方法、装置及设备
文献发布时间:2023-06-19 18:37:28
技术领域
本发明涉及信息检索技术领域,特别涉及一种融合多源数据的Telegram中文群组检索方法、装置及设备。
背景技术
Telegram是一款在国际范围有着巨大用户量的即时通讯软件,用户可以根据自己的兴趣爱好创建或加入不同的群组,其中,公开群组的聊天信息可被任意用户查看,而无需加入。但是,由于该软件宽松的监管,其中包含着大量涉及违法犯罪的群组,仍然在该软件上进行违法活动。如何准确的定位群组,并及时的掌握违法犯罪信息,对于制止犯罪、打击犯罪有着重要的意义。然而,Telegram官方只提供了英文检索功能,特定主题词相关的中文群组,仍然难以有效的检索。有的开发者通过给Telegram机器人积累群组与标题知识,利用关键词去与知识库中的群组标题匹配,从而实现中文群组检索功能。这种方法虽然可以实现中文检索功能,但这种做法存在几个缺点:
1)这类方法需要机器人事先遍历大量的群组,积累广泛的知识库;
2)Telegram群组标题允许随意更改,如果要维持检索的准确性,需频繁的遍历和更新知识库;
3)当群组标题无法匹配检索词,但是群组的内容却与检索词相关时,此类群组难以被检索到。
发明内容
本发明实施例的目的在于提供一种融合多源数据的Telegram中文群组检索方法、装置及设备,该方法着重于解决Telegram中文群组检索困难,检索结果少,检索结果不准确等问题。
为实现上述目的,本发明的技术方案如下:
根据本公开实施例的第一方面,提供一种融合多源数据的Telegram中文群组检索方法,包括:
获取检索词,并对所述检索词进行Telegram中文群组检索,生成多源融合群组;
分析所述多源融合群组对应的群聊记录集合,得到特征词集合,并基于所述特征词集合筛选所述多源融合群组,得到符合特征群组V
基于符合特征群组V
对所述关联群组R
基于所述特征词筛选所述关联群组R
在所述符合特征群组V
在所述符合特征群组V
进一步地,所述对所述检索词进行Telegram中文群组检索,生成多源融合群组,包括:
利用多种数据源对检索词进行Telegram中文群组检索,得到多源数据检索群组。
进一步地,基于Telegram所提供的英文群组检索接口,对所述检索词的拼音以及与检索词拼音近似的拼音进行Telegram中文群组搜索,得到检索词联想群组;
合并所述多源数据检索群组与检索词联想群组,并进行去重,以得到多源融合群组。
进一步地,所述多种数据源包括:谷歌数据源、推特数据源和其他第三方Telegram群组信息检索服务数据源;
所述利用多种数据源对检索词进行Telegram中文群组检索,得到多源数据检索群组,包括:
采用自定义搜索模式定向检索telegram.org范围内的所述检索词,得到谷歌数据源对应的检索结果;
利用爬虫技术对推特数据定向搜索检索词,并筛选其中包含telegram群组字段的数据,得到推特数据源对应的检索结果;
通过所述其他第三方Telegram检索服务中Telegram robot账户的问答式服务,搜索所述检索词,得到其他第三方Telegram群组信息检索服务数据源对应的检索结果;
合并所述谷歌数据源对应的检索结果、所述推特数据源对应的检索结果、以及所述其他第三方Telegram群组信息检索服务数据源对应的检索结果,并进行去重,以得到多源数据检索群组。
进一步地,所述基于Telegram所提供的英文群组检索接口,对所述检索词的拼音以及与检索词拼音近似的拼音进行Telegram中文群组搜索,得到检索词联想群组;
计算所述检索词的拼音;
生成与检索词拼音近似的拼音;
基于Telegram所提供的英文群组检索接口,并使用所述检索词的拼音、所述与检索词拼音近似的拼音对群组username进行检索,得到第一联想检索结果;
基于Telegram所提供的英文群组检索接口,并使用所述检索词的拼音对群组title进行检索,得到第二联想检索结果;
合并所述第一联想检索结果与第二联想检索结果,并进行去重,以得到检索词联想群组。
进一步地,所述分析所述多源融合群组对应的群聊记录集合,得到特征词集合,包括:
针对所述多源融合群组,利用切词技术对每一Telegram中文群组的群聊记录进行分词,并基于所述关键词在对话中的顺序,生成关键词对;
将分词结果中的高频词作为关键词;
构建关键词关系图;其中,所述关键词关系图中的节点为所述关键词,所述关键词关系图中的边表示所述关键词对的关联,所述节点的权重为所述关键词出现的次数,所述边的权重为所述关键词对出现的次数;
基于所述节点的权重筛选所述关键词,得到主特征词集合;
根据所述主特征词与连接所述主特征词的边的权重,得到辅特征词集合;
合并所述主特征词集合与所述辅特征词集合,得到特征词集合。
进一步地,所述对所述关联群组R
获取所述关联群组R
生成与所述群组名相似的近似群组名,并得到所述近似群组名的拼音;
基于所述进行多种数据源的Telegram中文群组搜索,和/或基于Telegram所提供的英文群组检索接口对所述近似群组名的拼音进行Telegram中文群组检索,以得到关联联想群组L
根据本公开实施例的第二方面,提供一种融合多源数据的Telegram中文群组检索装置,包括:
数据收集模块,用于获取检索词,并对所述检索词进行Telegram中文群组检索,生成多源融合群组;
特征计算模块,用于分析所述多源融合群组对应的群聊记录集合,得到特征词集合,并基于所述特征词集合筛选所述多源融合群组,得到符合特征群组V
关联联想模块,用于基于符合特征群组V
结果生成模块,用于在所述符合特征群组V
根据本公开实施例的第三方面,提供一种电子设备,其特征在于,包括:
处理器;
用于存储所述处理器可执行指令的存储器;
所述处理器,用于从所述存储器中读取所述可执行指令,并执行所述指令以实现所述上述任一所述的融合多源数据的Telegram中文群组检索方法。
根据本公开实施例的第四方面,提供一种计算机可读存储介质,其上存储有计算机程序指令,其特征在于,该程序指令被处理器执行时,以实现上述任一所述的融合多源数据的Telegram中文群组检索方法。
本发明提出的方法具有以下的优点及效果:
1)能够有效利用已有的网络资源,提供更加全面的中文群组检索能力。
2)能够对标题无关,但是群聊相关的群组有效检索。
3)无需对群组进行广泛搜索以及频繁的更新。
附图说明
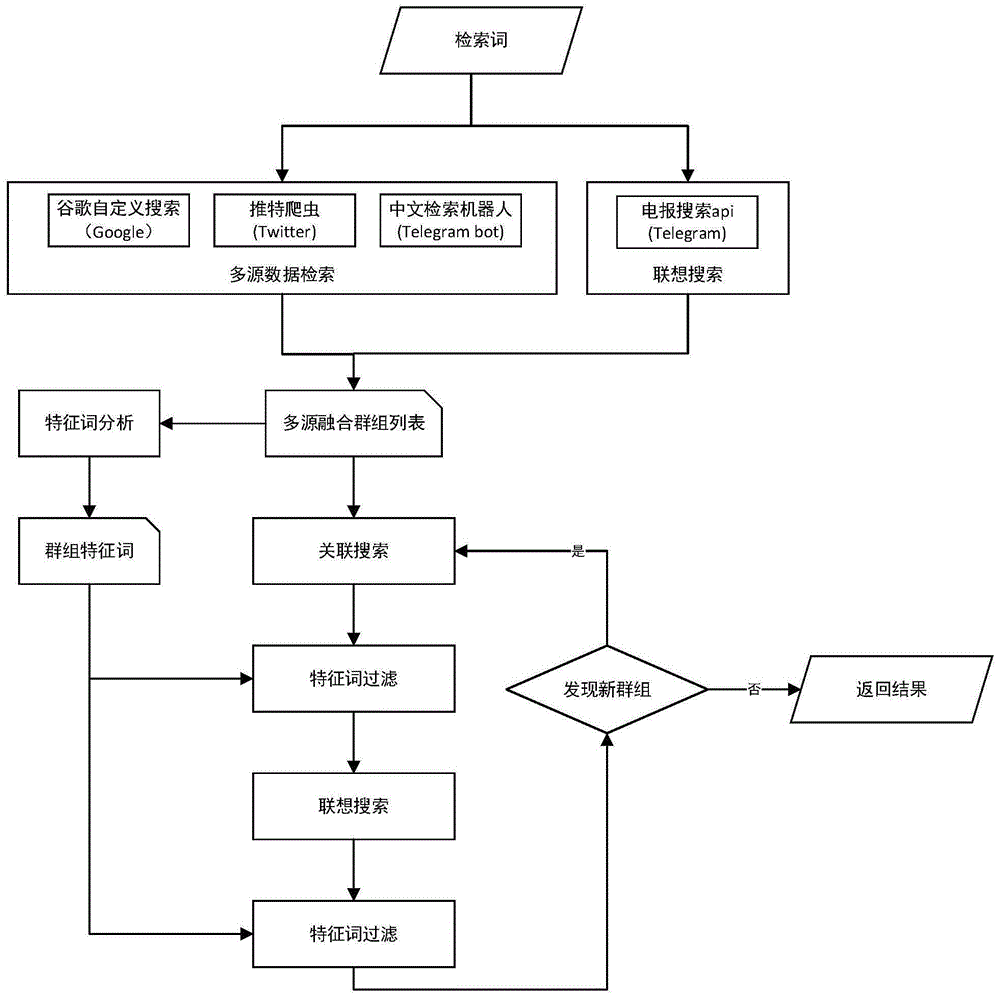
图1是本发明实施例提供的一种融合多源数据的Telegram群体检索的整体流程图。
具体实施方式
为使本发明技术方案更明显易懂,特举实施例并结合附图详细说明如下。
本实施例公开一种融合多源数据的Telegram群体检索方法及系统,具体说明如下:
系统整体架构的整体流程如图1所示,本实施例包括以下步骤:
步骤一:利用多种数据源对检索词进行多源数据检索,综合多数据源所获得的群组,并对集合中的群组进行去重处理。
所述的多种数据源搜索包括:谷歌搜索、推特定向数据爬虫、利用telegram中文检索机器人进行群组搜索。
其中,使用谷歌自定义搜索时,优先设定数据的检索范围为telegram.org,并结合搜索词进行检索,以此获得谷歌数据源中符合条件的结果;
其中,使用推特定向数据爬虫,即使用爬虫技术定向的搜索推特网中包含关键词且包含Telegram群组链接的推文,并对Telegram群组数据进行抓取。此处,Telegram群聊链接的特征字段为:“
其中,利用Telegram中文检索机器人进行群组检索,即利用Telegram提供的收发消息接口,向Telegram中文检索机器人提问要查询的关键词,并利用接收接口监听telegram中文检索机器人的结果,提取结果中的群组ID。此处,Telegram中文检索机器人问答是不同开发者通过各自的技术手段,将其实现的中文检索功能通过Telegram robot账户为其他用户提供问答式的检索服务。
步骤二:利用Telegram接口,对检索词进行联想检索。
所述的联想检索,即采用基于Telegram所提供的英文群组检索接口,对检索词的拼音进行搜索,得到检索词联想群组列表,以实现对群组名称、群组id与检索词拼音结构的群组进行有效的联想扩展检索。该群组列表包括群组username等于检索拼音的群组,以及群组username与检索词拼音近似的群组列表,或群组title包含检索词拼音的群组列表。
在另一示例中,在检索的过程中不止限于对用户输入的检索词的进行检索,而是结合已获得的多源数据检索结果,进行全面的检索。
步骤三:合并多源数据检索结果与联想检索结果,并对合并后的群组列表去重,得到第一阶段多源融合群组列表。
步骤四:对检索群组的聊天记录进行特征词分析。
所述的分析群组聊天的特征词,即利用群聊中出现的关键词及关键词在对话中的顺序构建关键词图,通过关键词链接强度,筛选出特征词。
所述的关键词图,即对每个群组都从聊天记录中提取关键词,关键词作为节点,同时出现的关键词之间做边,所有群组的关键词最终构成统一的图结构,得到特征词关系图。具体来说,所述的特征词关系图,即利用群聊中出现的关键词以及关键词在对话中的顺序构建关键词关联图;其中关键词是首先利用切词技术对群聊数据进行切词处理,并利用词频统计技术所得到的群聊高频词;关联图的构建为利用关键词及关键词在对话中的顺序构建的关键词关系图,反映词之间的指向关系与关键词之间的链接性强弱。
图结构的构造中,相同的关键词重复出现时,增加其节点的计数,相同关键词对重复出现时,增加节点间边的计数。
最终,选取图结构中节点计数较高的关键词及他们关联度较高的节点作为特征词。
其中,群聊信息由Telegram开源包中所给出的iter_messages接口进行获取,通过该接口可以用于对特定群组聊天内容进行遍历查询,查询群聊的群组是多源融合群组列表中所包含的全部群组。
步骤五:利用特征词过滤无关群组。
即利用步骤四从群聊信息中所得到群组的特征词,反向对第一阶段多源群组列表群组的群聊内容进行校验,根据群聊关键词与特征词的匹配程度,过滤掉群聊内容不符合特征的群组,只保留群聊内容与特征词匹配的群组。此处,得到特征词过滤处理后的多源融合群组列表。
所述的匹配程度,即根据群组聊天关键词中包含特征词的个数得到的,匹配特征词个数越多,匹配程度越高。
步骤六:对符合特征的群组进行关联搜索。
从群聊信息中筛选所有分享群组,视作群组的关联群组列表。去除关联列表自身的重复项,以及关联列表与多源融合列表中的重复项。
所述的关联搜索,即利用群组聊天记录中涉及的群聊分享,发现当前群组所关联的其他群组,所有被分享的群组构成当前群组的分享群组列表。
完成所有群组的关联搜索后,对总体的关联群组进行去重操作,去重时包括各群组关联群组的重复项,也包括关联群组与多源融合列表的重复项。
步骤七:对关联结果进行联想搜索。
对步骤六获得的关联群组逐一进行联想搜索,并将联想后新获得的群组并入关联群组列表。群组联想搜索完成后,再对更新后的关联群组列表进行去重操作。
一示例中,所述的关联群组发现,在关联发现过程中不止检索分析群聊中所包含的关联群组,而是同时对每个关联的群组进行联想扩展搜索,完成完整的联想扩展搜索后,再对获取的群组进行特征词分析,过滤群聊特征词不满足特征词关系图的列表;新获取的关联群组,将重复执行该关联发现过程,直到没有新的符合群聊特征词特点的关联群组被发现。
步骤八:利用特征词过滤步骤七的关联联想列表中的无关群组。
利用群聊信息检索接口,对关联群组列表中的群组,进行群聊信息获取。并结合步骤四所获得的特征词,对关联列表中的群组进行过滤,将群聊内容不符合特征的群组过滤,并将群聊内容符合特征的群组保留,得到符合特征的关联群组列表。
步骤九:重复步骤六到八。
继续对得到的关联群组列表进行步骤六、步骤七涉及的关联搜索,并由步骤八筛选出群聊内容符合特征的群组。重复进行这三个步骤,不断扩大关联搜索范围,直到所获取的关联群组中新出现的群组,群聊内容不再符合特征为止。
步骤十:合并所有结果。
将步骤三所获取的多源融合群组列表与最终的关联群组列表合并,得到完整的检索列表。
以上实施例仅用以说明发明的技术方案而非对其进行限制,本领域普通技术人员可以对发明的技术方案进行修改或者等同替换,本发明的保护范围以权利要求所述为准。