具有降低的免疫原性的TRAIL组合物
文献发布时间:2023-06-19 19:30:30
关于联邦资助研究的声明
本发明是在美国国立卫生研究院(National Institutes of Health)授予的第4U44AA026111-03号拨款下,在政府支持下完成的。政府对本发明享有某些权利。
关于序列表
根据37C.F.R.§1.52(e)(5),于2021年6月4日提交的序列表,作为名为“THER_116_PCT_ST25.txt”的文本文件,创建于2021年6月4日,大小为60,827字节,特此通过引用并入。
技术领域
本发明笼统而言涉及含有肿瘤坏死因子相关的凋亡诱导配体(TRAIL)的融合多肽,该配体含有修饰的异亮氨酸拉链(miLZ)结构域。
背景技术
肿瘤坏死因子相关的凋亡诱导配体(TRAIL)是TNF-α超家族中的II型跨膜蛋白,与TNF和FasL具有序列同源性。TRAIL可以通过蛋白水解从细胞表面切下并以可溶形式释放。可溶性TRAIL本质上是同源三聚体,随后在结合后三聚化TRAIL受体。已在人类中鉴定出五种TRAIL受体,但只有TRAIL-R1/DR4和TRAIL-R2/DR5受体启动类似于Fas/FasL和TNF-R/TNF信号途径的细胞凋亡。TRAIL受体结合刺激与募集的衔接蛋白、具有死亡结构域的Fas相关蛋白(FADD)形成死亡诱导信号复合物(DISC)。FADD募集酶原(procaspase)8和酶原10,并且DISC允许自动激活这些半胱天冬酶(caspase)。该信号的下游是半胱天冬酶3/6/7的蛋白水解切割和激活,导致细胞凋亡。另一种细胞凋亡途径是诱导线粒体功能障碍和膜透化,导致激活半胱天冬酶9的细胞色素c释放,最后裂解半胱天冬酶3/7,导致细胞凋亡。TRAIL还可以与其诱饵受体TRAIL-R3/DcR1和TRAIL-R4/DcR2结合,但这些受体缺乏功能性死亡结构域,无法诱导细胞凋亡。
TRAIL与TNF超家族的其他成员(例如TNF和CD95L)之间的一个主要区别是TRAIL不能诱导正常组织的细胞死亡。已经尝试使用TNF和CD95L诱导细胞死亡的多种医学或药物应用。由于TNF和CD95L蛋白会诱导正常细胞以及癌细胞和过度激活的免疫细胞的死亡,因此它们的适用性有限。相比之下,TRAIL在广泛的癌细胞和过度激活的免疫细胞中诱导细胞凋亡,而对正常细胞几乎没有影响。这是由于细胞类型之间TRAIL受体的差异表达。
已鉴定出五种TRAIL受体。其中,DR4(TRAIL-R1)和DR5(TRAIL-R2)是代表性的细胞死亡相关受体。当TRAIL与DR4或DR5结合时,受体的细胞内死亡结构域被激活,从而通过各种信号转导途径转导细胞凋亡信号,导致凋亡性细胞死亡。TRAIL还可以结合不诱导细胞凋亡的DcR1、DcR2和骨保护素(osteoprotegerin,OPG)。细胞死亡诱导受体DR4和DR5在正常细胞和肿瘤细胞之间的表达水平没有明显差异。相比之下,其他三种不诱导细胞凋亡的受体在正常细胞中以高水平表达,但在肿瘤细胞中以低水平表达或根本不表达。因此,在正常细胞中,TRAIL主要结合不包含死亡结构域的DcR1、DcR2和OPG,因此不诱导细胞死亡。相反,在癌细胞和过度激活的免疫细胞中,细胞凋亡是由TRAIL与包含死亡结构域的DR4和DR5的结合诱导的。TRAIL的这种选择性细胞凋亡诱导在医学或制药应用中是一个特别有吸引力的特征。
已在包括结肠癌、神经胶质瘤、肺癌、前列腺癌、脑肿瘤和多发性骨髓瘤细胞的多种类型的癌细胞中观察到TRAIL介导的细胞凋亡。TRAIL已被证明在动物体内具有非常高的抗癌活性。通过单独使用TRAIL以及与其他抗癌药物,如紫杉醇和阿霉素(doxorubicin)和放疗组合使用,已经获得了TRAIL的好的抗癌功效。除癌症外,TRAIL还用于治疗关节炎(自身免疫性疾病),通过诱导过度激活的免疫细胞的死亡来缓解和治疗关节病。除了蛋白治疗外,还尝试通过递送TRAIL基因进行基因治疗。TRAIL还可用于治疗T细胞介导的自身免疫性疾病,例如狼疮、类风湿性关节炎和I型糖尿病。
然而,天然TRAIL作为治疗剂存在一些问题。主要问题是天然TRAIL的三聚体形成率低。TRAIL单体不与TRAIL受体结合,因此不会诱导细胞凋亡。在这方面,已经进行了许多研究,目的是改善TRAIL的三聚体结构和三聚体形成率。锌离子在天然TRAIL的三聚化中起关键作用。TRAIL的突变体是根据计算机分析结果开发出来的。对于TRAIL三聚体的形成,最有用的方法似乎是引入有利于三聚体折叠的氨基酸序列。此类序列包括亮氨酸拉链(LZ)基序和异亮氨酸拉链(iLZ)基序。Henning Walczak报道了三聚体TRAIL衍生物的抗癌功效,其中亮氨酸拉链基序被添加到天然TRAIL的N末端(Walczak et al.,Nature Medicine,5:157-163(1999))。Kim报道了一种含有异亮氨酸拉链基序并具有良好细胞凋亡活性的TRAIL衍生物(Kim et al.,BBRC,321:930-935(2004))。
TRAIL在不同物种中具有不同的半衰期。例如,据报道,TRAIL在啮齿类动物中的半衰期为几分钟,在类人猿中的半衰期约为30分钟(Xiang,et al.,Drug Metabolism andDisposition,32:1230-1238(2004))。大多数TRAIL通过肾脏迅速排泄掉。这种短的半衰期被认为是TRAIL药物用途的一个缺点,使得需要具有延长半衰期的TRAIL或其衍生物。其他需要解决的问题包括TRAIL的低溶解度和溶液稳定性。重组TRAIL的半衰期极短,不稳定并且在高浓度下聚集(aggregate)。因此,未修饰的TRAIL在体内药物开发中的用途有限。
TRAIL在临床应用中的另一个问题涉及对某些组织正常细胞的细胞毒性。大多数正常细胞对由各种TRAIL受体的表达引起的细胞毒性都有耐药性,但一些肝细胞和角质形成细胞对TRAIL介导的细胞毒性敏感(Yagita et al.,Cancer Sci.,95:777-783(2004);Joet al.,Nature Medicine,6:564-567(2000);Zheng et al.,J.Clin.Invest.,113:58-64(2004))。
仍然需要具有生物活性、高纯度的TRAIL组合物和TRAIL缀合物,它们保留天然TRAIL的生物活性,具有延长的血清半衰期、增加的溶解度,对健康细胞没有细胞毒性并且在宿主中是非免疫原性的。
因此,本发明的一个目的是提供具有延长的血清半衰期、高溶解度、高生物活性和对健康细胞低毒性的非免疫原性TRAIL组合物和TRAIL缀合物。
本发明的另一个目的是提供一种制备非免疫原性TRAIL组合物和TRAIL缀合物的方法。
本发明的另一个目的是提供使用非免疫原性TRAIL组合物和TRAIL缀合物的方法。
发明内容
具有修饰的多聚化结构域和TRAIL结构域的融合多肽具有高表达、溶解性和稳定性。与本领域具有未修饰的多聚化结构域的其他TRAIL多肽相比,融合多肽在宿主中通常具有低免疫原性。已经开发了融合多肽的缀合物、编码融合多肽的多核苷酸及它们的组合物。通常,融合多肽是重组融合多肽,其包含含有修饰的异亮氨酸拉链(miLZ)结构域的第一序列和第二序列。第一序列可包括SEQ ID NO:4-8中的任一项。第二序列通常是TRAIL结构域并且可以包括SEQ ID NO:9-26中的任一项。第一序列可以通过接头,例如氨基酸接头连接到第二序列。融合多肽可以包括在第一序列之前的表达序列。示例性融合多肽具有如SEQID NO:30所示的氨基酸序列。
融合多肽的修饰的异亮氨酸拉链(miLZ)结构域在本领域已知的异亮氨酸拉链(iLZ)的第17位具有异亮氨酸残基修饰并在26位具有赖氨酸残基修饰(含有SEQ ID NO:1所示序列的iLZ和含有SEQ ID NO:4-8所示序列的miLZ)。iLZ的这些修饰不影响融合多肽的多聚化,因此它们可用于产生稳定、可溶、体内半衰期延长且免疫原性降低的TRAIL三聚体。这与示出需要该位置的异亮氨酸残基(位于SEQ ID NO:2的位置20的Ile(对应于SEQ ID NO:1的位置17)并赋予TRAIL稳定的三聚体形成的技术相反(Harbury et al,Nature,371:80-83(1994);Rozanov et al.,Mol Cancer Ther,8:1515-1525(2009),公开了SEQ ID NO:3)。
多聚体形式例如三聚体形式的融合多肽,通常是高度可溶的,在生理缓冲液、生理pH和室温下的溶解度在约0.2mg/ml和100mg/ml之间。多聚体形式例如三聚体形式的融合多肽在体外具有显著低于含有未修饰的iLZ结构域的融合多肽的半数抑制浓度(halfmaximal inhibitory concentration,IC50)。融合多肽的IC50可以是含有未修饰的iLZ结构域的融合多肽的约1/10至约1/2,或低于1/10。融合多肽通常具有大于1小时,例如约1小时和约24小时之间、约1小时和约12小时之间或约1小时和约6小时之间的体内半衰期。
已经开发了稳定缀合至半衰期延长分子例如聚乙二醇(PEG)或其衍生物的融合多肽。通常,PEG或其衍生物的分子量介于约5,000Da(道尔顿)和约100,000Da之间。缀合物通常是高度可溶的,在生理浓度的盐的存在下具有至多约30mg/ml的溶解度,例如约25mg/ml。缀合物通常是高度稳定的并且不会随着重复冻融循环而显著降低溶解度和活性。缀合物通常具有长的体内半衰期,例如在非人灵长类动物中约20小时至约50小时的体内半衰期。缀合物的IC50可以是包含未修饰的iLZ结构域的约1/10至约1/2,或低于1/10。与含有未修饰的iLZ结构域的缀合物相比,该缀合物在哺乳动物宿主中的免疫原性通常要显著降低。
还开发了编码重组融合多肽的多核苷酸。多核苷酸可以在表达载体中。表达载体通常包括与多核苷酸可操作连接的启动子。启动子可以是任何启动子,包括组成型活性、诱导型、条件型或组织特异性启动子。该多核苷酸可用于在酵母(如毕赤酵母(Pichiapastoris))或大肠杆菌(E.coli)表达系统中表达。
药物组合物含有有效量的融合多肽、多核苷酸或缀合物。这些药物通常用于注射给药。
已经开发了制备融合多肽的方法。这样的方法包括用含有编码融合多肽的多核苷酸和可诱导启动子的表达载体转染表达宿主如大肠杆菌细胞。转染的大肠杆菌细胞用于接种培养基。培养基通常包括锌离子,例如氯化锌形式的锌离子。
在有需要的个体中治疗增殖性疾病、自身免疫性疾病或纤维化疾病的方法需要向个体施用融合多肽、缀合物、多核苷酸或其药物组合物。融合多肽、缀合物、多核苷酸或药物组合物在诱导癌症相关的成纤维细胞凋亡方面特别有效。在一些实施方案中,增殖性疾病是具有实体瘤的癌症。在一些实施方案中,增殖性疾病是肝细胞癌、胰腺导管腺癌、结肠癌、神经胶质瘤、肺癌、前列腺癌或多发性骨髓瘤。以有效诱导癌症相关成纤维细胞凋亡和/或减小肿瘤大小的量施用组合物。在一些实施方案中,该方法包括施用第二活性剂。在一些实施方案中,第二活性剂是化疗剂,例如DNA拓扑异构酶I抑制剂和DNA拓扑异构酶II抑制剂。在一些实施方案中,第二活性剂是免疫检查点抑制剂,例如PD-1拮抗剂、PD-1配体拮抗剂或CTLA4拮抗剂。在一些实施方案中,第二活性剂是阿霉素、依托泊苷(etoposide)、喜树碱(camptothecin)、伊立替康(irinotecan)、顺铂(cisplatin)、奥沙利铂(oxaliplatin)、多西紫杉醇(docetaxel)、环磷酰胺(cyclophosphamide)、5-氟尿嘧啶、卡铂(carboplatin)、氮芥(mechlorethamine)、索拉非尼(sorafenib)、苯丁酸氮芥(chlorambucil)、长春新碱(vincristine)、长春花碱(vinblastine)、长春瑞滨(vinorelbine)、长春地辛(vindesine)、紫杉醇及其衍生物、拓扑替康(topotecan)、安吖啶(amsacrine)、磷酸依托泊苷(etoposide phosphate)、替尼泊苷(teniposide)、表鬼臼毒素(epipodophyllotoxins)、曲妥珠单抗(trastuzumab)、西妥昔单抗(cetuximab)、利妥昔单抗(rituximab)、贝伐单抗(bevacizumab)、纳武单抗(nivolumab)、派姆单抗(pembrolizumab)、阿特朱单抗(atezolizumab)、阿维单抗(avelumab)、德瓦鲁单抗(durvalumab)、西米普利单抗(cemiplimab)、匹迪珠单抗(pidilizumab)、沃普利单抗(vopratelimab)、丹瓦特森(danvatirsen)、西妥利单抗(cetrelimab)或易普利姆玛(ipilimumab)。在一些实施方案中,该方法进一步包括向个体施用过继性T细胞疗法、癌症疫苗、手术和/或放射治疗。
附图说明
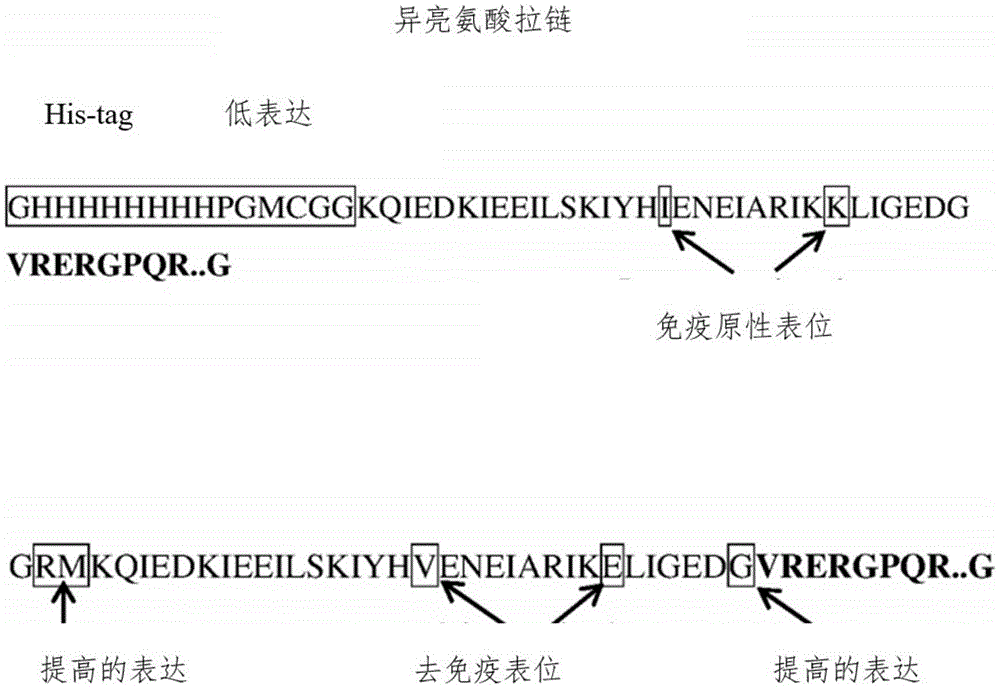
图1A-1C是示出已知融合多肽和修饰的融合多肽的序列的图。图1A是现有技术(Chae,et al.,Molecular cancer therapeutics 9(6):1719-29(2010))的含组氨酸标签的iLZ-TRAIL(His-iLZ-TRAIL)序列的图,重组人TRAIL(氨基酸114-281)之前是具有低表达序列和免疫原性表位的异亮氨酸拉链,其之前是组氨酸(His)标签;图1B示出miLZ-TRAIL—重组人TRAIL(氨基酸114-281)之前是异亮氨酸拉链,具有改善的表达序列、去免疫表位且没有组氨酸(His)标签(图1B);以及图1C示出图1B中的序列在N-末端用5kDa PEG聚乙二醇化。图ID示出TLY012的结构要素的图,三聚体的每个单体具有氨基酸序列SEQ ID NO:31。
图2A示出现有技术His-TRAIL和miLZ-TRAIL克隆#5的解链曲线(melting curve)(在温度范围(25-98℃)内的荧光变化)的图,其氨基酸序列如图1C所示。图2B示出在COLO205细胞上测试的现有技术His-iLZ-TRAIL和miLZ-TRAIL,克隆#5的生物活性(在一系列蛋白浓度(nM)内细胞活力的变化(%))的线图。
图3示出在静止HSC和激活HSC(肌成纤维细胞)上测试的TLY012的选择性细胞毒性(在一系列蛋白浓度(nM)内细胞活力的变化(%))的线图。示出了两种浓度的IC50(nM)。
图4示出在COLO-205结肠直肠癌细胞上测试的PEG化的His-iLZ-TRAIL(His-TRAIL-PEG,含有SEQ ID NO:3和SEQ ID NO:15,如在SEQ ID NO:32中)和聚乙二醇化的miIL-TRAIL(包含SEQ ID NO:4和SEQ ID NO:15,如在SEQ ID NO:31中)的细胞毒性(在蛋白浓度(nM)范围内的细胞活力变化(%))的线图。
图5A-5H示出含有SEQ ID NO:4的miLZ-TRAIL 1876(123V,K32E)(图5A和图5E);含有SEQ ID NO:3的iLZ-TRAIL 1877(图5B和5F);含有SEQ ID NO:6的miLZ-TRAIL 1878(K32E)(图5C和图5G);和含有SEQ ID NO:7的miLZ-TRAIL 1879(K32Q)(图5D和图5H)在30mMHepes、1M NaCl、5mM DTT(pH 8.0)中(图5A-5D)或在50mM MES、0.5M NaCl、5mM DTT(pH6.0)中(图5E-5H)的稳定性曲线在一定温度范围内(25-98℃)的荧光(-R*[T])变化的图。
图6是一个表,示出使用基于ProPred的算法对各种miLZ结构域进行的电子免疫原性分析的结果。该软件查询了广泛的人类MHC-II等位基因,以确定其结合蛋白序列中存在的潜在T细胞表位(线性九肽)的能力。潜在T细胞表位中的每个氨基酸都被分配了免疫原性评分。该评分与肽与特定MHC-II等位基因结合并触发T细胞免疫反应的可能性成正比。
图7A-7D示出静脉注射(IV,10mg/kg,图7A)或皮下注射(SC,2mg/kg或10mg/kg,图7B和7C)或50mg/kg(图7D)时,TLY012血清浓度随时间(小时)变化的图。
图8A示出组织提取物a-SMA、GRP78、DR4、DR5、PDGF-Rb和Cl.PARP-1的蛋白印迹分析(Western blot analysis)结果的柱状图。图8B-8D分别示出纤维化标记物Acta2、TGF-b和Pdgf-r的mRNA表达水平的柱状图。
图9A示出在有或没有PSC-CM的情况下生长并用TLY012和索拉非尼的组合处理的ASPC-1细胞的细胞活力(%)的柱状图。图9B示出来自用索拉非尼、TLY012或TLY012与索拉非尼的组合治疗的小鼠获得的ASPC-1/PSC异种移植物的肿瘤重量(mg)的量化数据的柱状图。
图10示出用不同剂量TLY012处理的胰腺CAF细胞中半胱天冬酶3/7活性(RLU)与用相同剂量TLY012处理的激活PSC中半胱天冬酶3/7活性(RLU)的柱状图。
图11示出用指定的各种细胞毒剂处理的胰腺CAF细胞中半胱天冬酶3/7活性(倍数(Fold))增加倍数的柱状图。
图12A示出用不同剂量(ng/ml)的TLY012处理的结肠CAF细胞中半胱天冬酶3/7活性(RLU)的柱状图。图12B示出用指定的各种细胞毒剂处理的结肠CAF细胞中半胱天冬酶3/7活性(倍数)增加倍数的柱状图。
图13A-13C示出与正常(静止)PSC相比,胰腺和结肠CAF中Dr4、DR5、Acta2、TGF-b、Colla2、PD-L1和PD-L2的mRNA表达水平的柱状图。
图14示出从用盐水或TLY012处理的小鼠中KPC细胞的原位胰腺异种移植物获得的肿瘤的肿瘤体积(mm
图15A是具有小鼠KPC细胞原位异种移植物,并用PBS、抗PD-L1抗体(B7-H1、抗小鼠PD-L1)、TLY012或抗PD-L1抗体和TLY012的组合处理的鼠肿瘤获得的生物发光活性(总计数)随时间(天)的线图。图15B是具有小鼠KPC细胞原位异种移植物,并用PBS、抗PD-L1抗体、TLY012或抗PD-L1抗体和TLY012的组合处理的鼠获得的肿瘤的肿瘤体积(mm
图16示出具有小鼠KPC细胞原位异种移植物并用PBS、抗PD-Ll抗体、TLY012或抗PD-Ll抗体和TLY012组合处理的鼠的组织中的天狼星红(Sirius Red)阳性面积(%)的图。
图17示出在静止HSC细胞(qHSC)、激活的肝星状细胞(hepatic stellate cells,HSC)和原发性肝癌相关成纤维细胞(肝CAF)中Acta2、Colla2、Col3al、PDGFR和CTGF标准化为GAPDH的mRNA表达水平的柱状图。
图18A和18B示出在用溶媒(Vehicle)或TLY012处理的高度TRAIL抗性HCC细胞(包括Huh-7细胞)(图18A)和Hep-G2细胞(图18B)中半胱天冬酶3/7活性(倍数)成倍增加(foldincrease)的柱状图。
具体实施方式
一、定义
如本文所用,术语“多肽(polypeptide)”包括蛋白及其片段。多肽在本文中作为氨基酸残基序列公开。这些序列按照从氨基到羧基末端的方向从左到右书写。根据标准命名法,氨基酸残基序列由三字母或单字母代码命名,如下所示:丙氨酸(Ala,A)、精氨酸(Arg,R)、天冬酰胺(Asn,N)、天冬氨酸(Asp,D)、半胱氨酸(Cys,C)、谷氨酰胺(Gin,Q)、谷氨酸(Glu,E)、甘氨酸(Gly,G)、组氨酸(His,H)、异亮氨酸(Ile,I)、亮氨酸(Leu,L)、赖氨酸(Lys,K)、甲硫氨酸(Met,M)、苯丙氨酸(Phe,F)、脯氨酸(Pro,P)、丝氨酸(Ser,S)、苏氨酸(Thr,T)、色氨酸(Trp,W)、酪氨酸(Tyr,Y)和缬氨酸(Val,V)。
如本文所用,术语“变体(variant)”是指不同于参考多肽或参考多核苷酸但保留基本特性的多肽或多核苷酸。多肽的典型变体在氨基酸序列上不同于另一个参考多肽。典型地,差异是有限的,因此参考多肽和变体的序列总体上非常相似,并且在许多区域中是相同的。变体和参考多肽的氨基酸序列可能因一处或多处修饰(例如,取代、添加和/或缺失)而不同。取代或插入的氨基酸残基可以是也可以不是遗传密码编码的氨基酸残基。多肽的变体可以是天然存在的,例如等位基因变体,或者它可以是未知的天然存在的变体。
可以在多肽的结构中进行修饰和改变,并且仍然获得具有与多肽相似特征的分子(例如,保守的氨基酸取代)。例如,某些氨基酸可以取代序列中的其他氨基酸而不会明显丧失活性。因为正是多肽的相互作用能力和性质决定了该多肽的生物学功能活性,所以可以在多肽序列中进行某些氨基酸序列取代,但仍然可以获得具有相似特性的多肽。
在进行这种改变时,可以考虑氨基酸的亲水指数。亲水氨基酸指数在赋予多肽相互作用的生物学功能方面的重要性在本领域中是普遍理解的。已知某些氨基酸可以替代具有相似亲水指数或得分的其他氨基酸,并且仍然产生具有相似生物活性的多肽。每种氨基酸都基于其疏水性和电荷特性指定了亲水指数。这些指数为:异亮氨酸(+4.5);缬氨酸(+4.2);亮氨酸(+3.8);苯丙氨酸(+2.8);半胱氨酸/半胱氨酸(+2.5);甲硫氨酸(+1.9);丙氨酸(+1.8);甘氨酸(0.4);苏氨酸(-0.7);丝氨酸(-0.8);色氨酸(-0.9);酪氨酸(-1.3);脯氨酸(1.6);组氨酸(-3.2);谷氨酸(-3.5);谷氨酰胺(-3.5);天冬氨酸(-3.5);天冬酰胺(-3.5);赖氨酸(-3.9);和精氨酸(-4.5)。
人们认为,氨基酸的相对亲水性决定了合成多肽的二级结构,而二级结构又决定了多肽与其他分子,如酶、底物、受体、抗体和抗原的相互作用。本领域已知,氨基酸可以被具有相似亲水指数的另一氨基酸取代,并且仍然获得功能等效的多肽。在这样的变化中,优选取代亲水指数在±2以内的氨基酸,特别优选那些在±1以内的氨基酸以及甚至更特别优选那些在±0.5以内的氨基酸。
类似氨基酸的取代也可以基于亲水性进行。氨基酸残基的亲水性值如下:精氨酸(+3.0);赖氨酸(+3.0);天冬氨酸(+3.0±1);谷氨酸(+3.0±1);丝氨酸(+0.3);天冬酰胺(+0.2);谷氨酰胺(glutamnine)(+0.2);甘氨酸(0);脯氨酸(-0.5±1);苏氨酸(-0.4);丙氨酸(-0.5);组氨酸(-0.5);半胱氨酸(1.0);甲硫氨酸(-1.3);缬氨酸(-1.5);亮氨酸(-1.8);异亮氨酸(-1.8);酪氨酸(2.3);苯丙氨酸(-2.5);色氨酸(-3.4)。应当理解,氨基酸可以被具有相似亲水性值的另一个氨基酸取代,并且仍然获得生物学等效的,特别是免疫等效的多肽。在这种变化中,优选取代亲水指数在±2以内的氨基酸,特别优选那些在±1以内的氨基酸以及甚至更特别优选那些在±0.5以内的氨基酸。
如上所述,氨基酸取代通常基于氨基酸侧链取代基的相对相似性,例如它们的疏水性、亲水性、电荷和大小。特别地,多肽的实施方案可以包括与感兴趣的多肽具有约50%、60%、70%、80%、90%和95%序列同一性的变体。
如本文所使用的,本领域已知的术语“同一性(identity)”是通过比较序列来确定的两个或多个多肽序列之间的关系。在本领域中,“同一性”还意味着由这些序列串之间的匹配确定的多肽之间的序列相关性程度。“同一性”也可以指多肽与参考多肽全长的序列相关性程度。“同一性”和“相似性(similarity)”可以通过已知方法容易地计算,包括但不限于(Computational Molecular Biology,Lesk,A.M.,Ed.,Oxford University Press,NewYork,1988;Biocomputing:Informatics and Genome Projects,Smith,D.W.,Ed.,Academic Press,New York,1993;Computer Analysis of Sequence Data,Part I,Griffin,A.M.,and Griffin,H.G.,Eds.,Humana Press,New Jersey,1994;SequenceAnalysis in Molecular Biology,von Heinje,G.,Academic Press,1987;SequenceAnalysis Primer,Gribskov,M.and Devereux,J.,Eds.,M Stockton Press,New York,1991;和Carillo,H.,and Lipman,D.,SIAM J Applied Math.,48:1073(1988)中描述的。
各种程序和比对算法描述于:Smith&Waterman,Adv Appl Math 2,482(1981);Needleman&Wunsch,J Mol Biol 48,443(1970);Pearson&Lipman,Proc Natl Acad SciUSA 85,2444(1988);Higgins&Sharp,Gene 73,237-244(1988);Higgins&Sharp,CABIOS 5,151-153(1989);Corpet et al,Nuc Acids Res 16,10881-10890(1988);Huang et al,Computer App Biosci 8,155-165(1992);和Pearson et al,Meth Mol Bio 24,307-331(1994)。此外,Altschul et al,J Mol Biol 215,403-410(1990),详细考虑了序列比对方法和同源性计算。
NCBI基本局部比对搜索工具(NCBI Basic Local Alignment Search Tool,BLAST)(上述Altschul et al,(1990))可从多个来源获得,包括国家生物信息中心(National Center for Biological Information,NCBI,国家医学图书馆,38A栋,8N805室,马里兰州贝塞斯达,20894)和互联网,用于与序列分析程序blastp、blastn、blastx、tblastn和tblastx结合使用。有关更多信息,请访问NCBI网站。BLASTN用于比较核酸序列,而BLASTP用于比较氨基酸序列。如果两个比较序列共享同源性,则指定的输出文件将这些同源性区域显示为对齐的序列(aligned sequence)。如果两个比较序列不共享同源性,则指定的输出文件将不会显示对齐的序列。
确定同一性的优选方法被设计为在所测试的序列之间提供最大匹配。确定同一性和相似性的方法被编入公开可用的计算机程序。两个序列之间的百分比同一性可以使用包含Needelman和Wunsch(J.Mol.Biol.,48:443-453,1970)算法(例如NBLAST和XBLAST)的分析软件(即,遗传计算机组(Genetics Computer Group)的序列分析软件包(SequenceAnalysis Software Package),Madison Wis.)来确定。默认参数用于确定多肽的同一性。
举例来说,多肽序列可以与参考序列相同,即100%相同,或者与参考序列相比,多肽序列可包括至多某整数个的氨基酸改变,使得百分比同一性小于100%。这种改变选自至少一个氨基酸缺失、取代(包括保守和非保守取代)或插入,其中所述改变可发生在参考多肽序列的氨基或羧基末端位置或这些末端位置之间的任何位置,其单独散布在参考序列中的氨基酸之间或在参考序列内的一个或多个相邻基团中。给定百分比同一性的氨基酸变化数通过将参考多肽中的氨基酸总数乘以相应百分比同一性的数值百分比(除以100),然后从参考多肽中的所述氨基酸总数中减去该乘积来确定。
术语“百分比(%)序列同一性”定义为候选序列中与参考核酸或多肽序列中核苷酸或氨基酸相同的核苷酸或氨基酸的百分比,在对齐序列并在必要时引入间隙后,以实现最大百分比序列同一性。用于确定百分比序列同一性的对齐(alignment)可以以本领域技术人员所掌握的各种方式实现,例如,使用公开可用的计算机软件,例如BLAST、BLAST-2、ALIGN、ALIGN-2或Megalign(DNASTAR)软件。可通过已知方法确定用于测量对齐的适当参数,包括在所比较序列的全长上实现最大对齐所需的任何算法。
如本文所用,术语“重组多核苷酸”通常指通过基因工程技术获得的多核苷酸。
如本文所用,术语“重组多核苷酸”通常指从重组多核苷酸获得的多肽。重组核酸或多肽是具有非天然存在的序列或具有由两个或多个以其他方式分离的序列片段的人工组合形成的序列的核酸或多肽。这种人工组合通常通过化学合成完成,或者更常见的是通过人工操作分离的核酸片段,例如通过基因工程技术完成。重组多肽也可以指使用重组核酸制备的多肽,包括转移到不是多肽天然来源的宿主生物体的重组核酸。
如本文所用,术语“纯化的”是指基本上不含(至少60%不含,优选75%不含,最优选90%不含)在天然环境中与分子或化合物通常相关的其他组分的形式的分子或化合物。
如本文所用,术语“融合多肽”是指通过在一条多肽的氨基末端和另一条多肽的羧基末端之间形成的肽键而连接的两条或更多条多肽,或通过氨基酸接头或氨基酸侧链之间的反应(例如每条多肽上半胱氨酸残基之间的二硫键)将一条多肽连接到另一条多肽,而形成的多肽。融合蛋白可以通过组成多肽的化学偶联形成,或者可以由编码单个连续融合蛋白的核酸序列表达为单个多肽。可以使用分子生物学中的常规技术来制备融合蛋白,以将两个基因在框架中连接成单个核酸序列,然后在表达融合蛋白的条件下在适当的宿主细胞中表达核酸。
如本文所用,术语“单体”是指单个融合多肽分子。如本文所用,术语“二聚体”、“三聚体”、“四聚体”或“多聚体”分别指两个、三个、四个或更多个单体形成一个多肽分子。二聚体、三聚体、四聚体或多聚体可以是形成二聚体、三聚体、四聚体或多聚体的单体中的每一个单体含有相同的氨基酸序列的同源二聚体、同源三聚体、同源四聚体或同源多聚体。二聚体、三聚体、四聚体或多聚体可以是形成二聚体或三聚体、四聚体或多聚体的单体中的每一个单体含有不同的氨基酸序列的异源二聚体,异源三聚体、异源四聚体或异源多聚体。
如本文所用,术语“溶解度”是指在生理pH和室温下,多肽或缀合物在生理缓冲液中的最大浓度,在该浓度下,多肽和缀合物基本上不会聚集。可通过色谱、凝胶电泳或熔融/聚集分析来检测溶解性和/或聚集性。
如本文所用,术语“体内半衰期”通常指多肽或缀合物在体内循环中保留的最长时间的一半。体内半衰期可以通过在从施用多肽或缀合物的个体以不同时间间隔获得血浆样品后,针对多肽或缀合物的活性测试来测量。体内半衰期可以通过检测在从施用多肽或缀合物的个体不同时间间隔获得的血浆样品中多肽或缀合物的存在的检测试验来测量。
如本文所用,术语“核酸”是指核苷酸和核苷的任何天然或合成的线性连续阵列(sequential array),例如DNA,包括互补DNA(cDNA)、复制RNA(repRNA)和信使RNA(mRNA)。术语“核酸”进一步包括修饰的或衍生的核苷酸和核苷,例如但不限于卤化核苷酸,例如5-溴尿嘧啶,以及衍生的核苷酸,例如生物素标记的核苷酸。
如本文所用,术语“多核苷酸”是指包括一个以上核酸分子的单个分子,其中每个核酸分子编码不同的蛋白和/或在表达载体中执行不同的功能。多核苷酸可以在表达载体中,例如在质粒、粘粒或病毒载体中。
如本文所用,术语“表达载体”是指具有一个以上分离的多核苷酸序列的重组遗传分子。用于宿主生物体中多核苷酸表达的表达载体包括5’-3’方向的启动子序列;编码感兴趣的多核苷酸的序列;以及终止序列。载体还可以包括用于表达的选择性标记基因和其他调节元件。该载体可适用于在原核细胞如大肠杆菌中表达,或在真核细胞如酵母细胞或哺乳动物细胞中表达。
如本文所用,术语“宿主”、“个体(subject)”或“患者”是指作为给药目标的任何个体(individual)。
如本文所用,在多肽、缀合物或组合物的上下文中,术语“免疫原性”是指能够诱导免疫反应并因此具有抗原性的多肽、缀合物或组合物。“免疫反应”是指免疫系统的任何反应。这些反应包括生物体免疫系统响应于多肽、多核苷酸、缀合物或其组合物的活性改变,并可涉及例如抗体产生、细胞介导的免疫的诱导、补体激活或免疫耐受的形成。
如本文所用,短语“显著较低的免疫原性”规定,相对于通过计算机模拟预测的在宿主中相应多肽或相应缀合物的免疫原性或离体(ex vivo)免疫细胞中相应多肽或相应缀合物的免疫原性,免疫原性得分的降低或抑制大于至少约25%、至少约20%、至少约15%、至少约12.5%、至少约10%或至少约5%。
如本文所用,术语“相应多肽”是指通常由与参考多肽相似的第一序列和/或相似的第二序列形成的多肽,但不具有参考多肽的修饰。
如本文所使用的,术语“相应缀合物”是指通常由与参考缀合物相同或相似的第一序列和/或相同或相似的第二序列形成的缀合物,但不具有参考缀合物的修饰。
如本文所用,术语“治疗”包括抑制、缓解、预防或消除与所治疗的疾病、病症(condition)或障碍(disorder)相关的一种或多种症状或副作用。
相对于对照(control),使用术语“降低”、“抑制”、“缓解”或“减少”。本领域技术人员将容易地确认用于每个实验的适当对照。例如,与对照进行比较,例如与未用多肽处理或未用相应多肽或相应缀合物处理的个体或细胞的应答进行比较,用多肽处理的个体或细胞中的反应降低。减少可以是活性、表达或症状的完全抑制或减少,或部分抑制或减少。抑制可以是与对照相比,活性、表达或症状减少1%、2%、3%、4%、5%、6%、7%、8%、9%、10%、11%、12%、13%、14%、15%、16%、17%、18%、19%、20%、21%、22%、23%、24%、25%、26%、27%、28%、29%、30%、31%、32%、33%、34%、35%、36%、37%、38%、39%、40%、41%、42%、43%、44%、45%、46%、47%、48%、49%、50%、51%、52%、53%、54%、55%、56%、57%、58%、59%、60%、61%、62%、63%、64%、65%、66%、67%、68%、69%、70%、71%、72%、73%、74%、75%、76%、77%、78%、79%、80%、81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%。
如本文所用,术语“有效量”或“治疗有效量”是指足以治疗、抑制或缓解正在治疗的疾病状态的一种或多种症状或以其他方式提供期望的药理学和/或生理学效果的剂量。精确剂量将根据多种因素,如个体相关变量(例如,年龄、免疫系统健康状况等)、疾病或病症以及正在进行的治疗而变化。有效量的效果可以是相对于对照的。这种对照在本领域中是已知的并在本文中讨论,并且可以是例如在药物或药物组合给药之前或不给药时个体的状况,或者在药物组合的情况下,可以将组合的效果与仅给药一种药物的效果进行比较。
如本文所用,术语“联合治疗”是指包括施用有效量的两种或多种化学剂或组分以治疗疾病或症状或产生生理变化,而治疗疾病或其症状,或实现期望的生理变化的方法,其中化学剂或组分一起施用,例如同一组合物的一部分,或在同一时间或不同时间单独和独立地施用(即,每个药剂或组分的施用彼此间隔有限的时间段)。
如本文所用,术语“给药方案(dosage regime)”是指多肽、多核苷酸、缀合物或它们组合物的施用方案、施用途径、剂量、施用间隔和治疗持续时间。
如本文所用,术语“显著地(substantially)”是指相对于对照的至少约25%、至少约20%、至少约15%、至少约12.5%、至少约10%或至少约5%的比较量度(comparativemeasurement)。
除非本文中另有说明,否则本文中对数值范围的记载仅旨在作为单独提及落在该范围内的每个单独值的速记方法,并且每个单独值被并入说明书中,如同其在本文中被单独记载一样。
术语“约”的使用旨在描述在约+/-10范围内高于或低于规定值的值。
二、组成(Compositions)
A、修饰的融合多肽
融合多肽包含修饰的多聚化结构域作为第一序列和感兴趣的蛋白作为第二序列。还描述了融合多肽的缀合物。缀合物通常包括融合多肽和半衰期延长分子。修饰的多聚化结构域为融合多肽提供高表达、溶解性、稳定性和低免疫原性。
与具有本领域多聚化结构域的TRAIL组合物相比,具有修饰的多聚化结构域的TRAIL组合物示出改善的物理化学和生物学特性。与具有本领域多聚化结构域的TRAIL组合物相比,TRAIL组合物也具有较低的免疫原性。
还描述了编码融合多肽的多核苷酸。多核苷酸可包含在表达载体中。通过在原核细胞或真核细胞中表达载体产生的融合多肽可以冷冻储存在细胞中,或从细胞中纯化以供进一步使用。
融合多肽通常包括第一序列和第二序列。第一序列是修饰的多聚化结构域的氨基酸序列,例如修饰的异亮氨酸拉链(miLZ)结构域。第二序列是具有二聚体、三聚体、四聚体或多聚体三级结构的蛋白或肽的氨基酸序列。示例性的蛋白或肽是TRAIL蛋白单体,其在其三级结构中是同源三聚体。
1.第一序列
典型地,第一氨基酸序列包括酵母GCN4 pII亮氨酸拉链(LZ)的修饰的多聚化序列。本领域认识到在某些氨基酸位置修饰以用异亮氨酸(Ile(I))取代亮氨酸(Leu(L))的GCN4-pII(Ile(I))(Harbury et al,Nature,371:80-83(1994);Rozanov et al.,MolCancer Ther,8:1515-1525(2009)),形成异亮氨酸拉链(iLZ)序列。本领域还认识到,这些修饰和这些拉链序列的使用在人类中是免疫原性的(US 2016/0280761)。
在本文所述的融合多肽中,第一序列通常包括在哺乳动物宿主中免疫原性降低的修饰的异亮氨酸拉链(miLZ)序列。修饰的异亮氨酸拉链序列如下所示,在本节中,在相对于以下序列的位置示出修饰的氨基酸:
1)核心序列(SEQ ID NO:1),
2)现有技术iLZ序列(SEQ ID NO:2;描述于Rozanov et al.,Mol Cancer Ther,8:1515-1525(2009));和
3)第二现有技术iLZ序列(SEQ ID NO:3)。
现有技术LZ和iLZ序列表示为:
KQIEDKIEEILSKIYHIENEIARIKKLIGE(SEQ ID NO:1,来自修饰的酵母GCN4-pII亮氨酸拉链(LZ)基序的片段,其在位置6、10、13、17、20、24、27和31处含有异亮氨酸取代(GRMKQIEDKIEEILSKIYHIENEIARIKKLIGER,SEQ ID NO:2,iLZ);Harbury et al,Nature,371:80-83(1994);Rozanov et al.,Mol Cancer Ther,8:1515-1525(2009)),或
PGMCGGKQIEDKIEEILSKIYHIENEIARIKKLIGEDGV(SEQ ID NO:3),iLZ)。
为了在本发明中保持一致,第一序列以其SEQ ID NO表示,修饰的氨基酸以相对于SEQ ID NO:1的位置表示。
包含miLZ的第一序列通常包括SEQ ID NO:4-8中的任一项作为miLZ的一部分:
KQIEDKIEEILSKIYHVENEIARIKELIGE(SEQ ID NO:4;I17V,K26E;或相对于SEQ IDNO:2,I20V,K29E,或相对于SEQ ID NO:3,I23V,K32E)
KQIEDKIEEILSKIYHVENEIARIKKLIGE(SEQ ID NO:5;I17V,或相对于SEQ ID NO:2,I20V,或相对于SEQ ID NO:3,I23V)
KQIEDKIEEILSKIYHIENEIARIKELIGE(SEQ ID NO:6;K26E,或相对于SEQ ID NO:2,K29E,或相对于SEQ ID NO:3,K32E)
KQIEDKIEEILSKIYHIENEIARIKQLIGE(SEQ ID NO:7;K26Q;相对于SEQ ID NO:2,K29Q,或相对于SEQ ID NO:3,K32Q)
KQIEDKIEEILSKVYHIENEIARIKELIGE(SEQ ID NO:8;I14V,K26E,或相对于SEQ IDNO:2,I17V;K29E,或相对于SEQ ID NO:3,I17V,K32E)。
融合多肽的miLZ结构域在本领域已知的iLZ中具有如下修饰:第17位异亮氨酸残基和第26位的赖氨酸残基(含有如SEQ ID NO:1所示的序列的iLZ,含有SEQ ID NO:4-8所示的序列的miLZ)。现有技术iLZ的这些修饰不影响融合多肽的多聚化,并产生稳定、可溶、体内半衰期增加、免疫原性降低的TRAIL三聚体。这与现有技术相反,现有技术表明需要这些位置的异亮氨酸残基(SEQ ID NO:2的位置20处的Ile(对应于SEQ ID NO:1中的位置17),并且它们赋予TRAIL稳定的三聚体形成(Harbury et al,Nature,371:80-83(1994);Rozanovet al.,Mol Cancer Ther,8:1515-1525(2009),公开了SEQ ID NO:3)。
2.第二序列
第二序列可以是蛋白或多肽的氨基酸序列,所述蛋白或多肽通常作为同源二聚体或异源二聚体、同源三聚体或异源三聚体、同源四聚体或异源四聚体或同源多聚体或异源多聚体发挥功能。示例性的第二序列是人TRAIL多肽的完整序列或片段、变体或同源物。
TRAIL/Apo2L(TNFSF10)最初在EST数据库中搜索与已知TNF超家族配体同源的基因时被鉴定(Benedict et al.,J.Exp.Med.,209(11):1903-1906(2012))。在人类中,TRAIL结合两种促凋亡死亡受体(DR),TRAIL-R1和TRAIL-R2(TNFRSF10A和TNFRSF10B),以及其他两种不诱导死亡反而充当死亡信号的诱饵的膜受体。TRAIL与其同源DR的结合诱导死亡诱导信号复合物的形成,最终导致半胱天冬酶激活和细胞凋亡的启动(Benedict et al.,J.Exp.Med.,209(11):1903-1906(2012))。
在一些实施方案中,第二序列包括TRAIL肽单体的氨基酸序列。
人TRAIL的核酸和氨基酸序列是本领域已知的。例如,人TRAIL的氨基酸序列是MAMMEVQGGPSLGQTCVLIVIFTVLLQSLCVAVTYVYFTNELKQMQDKYSKSGIACFLKEDDSYWDPNDEESMNSPCWQVKWQLRQLVRKMILRTSEETISTVQEKQQNISPLVRERGPQRVAAHITGTRGRSNTLSSPNSKNEKALGRKINSWESSRSGHSFLSNLHLRNGELVIHEKGFYYIYSQTYFRFQEEIKENTKNDKQMVQYIYKYTSYPDPILLMKSARNSCWSKDAEYGLYSIYQGGIFELKENDRIFVSVTNEHLIDMDHEASFFGAFLVG(SEQ ID NO:9,(UniProtKB数据库登录号P50591(TNF10_HUMAN))。在一些实施方案中,第二序列包括TRAIL肽,其包含或具有SEQ ID NO:10的氨基酸序列。
TRAIL同源物或变体可与SEQ ID NO:9具有至少50%、至少60%、至少70%、至少80%、至少90%、至少95%、至少98%、至少99%或100%的同一性。保守氨基酸取代是将一个氨基酸取代为结构相似的氨基酸。
优选地,TRAIL是可溶性TRAIL。内源性全长TRAIL包括胞质结构域、跨膜结构域和胞外结构域。典型地,可溶性TRAIL是全长TRAIL的不含胞质结构域和跨膜结构域的片段。因此,可溶性TRAIL可以是TRAIL的胞外结构域(例如,SEQ ID NO:9的胞外结构域)或其功能片段。SEQ ID NO:9的TRAIL的共有胞外结构域是SEQ ID NO:9的氨基酸39-281(SEQ ID NO:10)。因此,在一些实施方案中,第二序列包括TRAIL肽或其功能片段或变体,所述TRAIL肽包含或具有SEQ ID NO:9的氨基酸39-281(SEQ ID NO:10)、41-281(SEQ ID NO:11)、91-281(SEQ ID NO:12)、92-281(SEQ ID NO:13)、95-281(SEQ ID NO:14)和114-281(SIQ ID NO:15)。
在一些实施方案中,第二序列包括SEQ ID NO:7的功能性片段或变体,其可以通过TRAIL-R1和/或TRAIL-R2抑制信号传导。SEQ ID NO:9的片段或变体可以与SEQ ID NO:9具有50%、60%、70%、75%、80%、85%、90%、95%、96%、97%、98%、99%或大于99%的序列同一性。
优选地,功能性片段或其变体包括SEQ ID NO:9的胞外结构域或其功能性片段。人们认为TRAIL C端的150个氨基酸包括受体结合结构域。因此,在一些实施方案中,功能性片段包括SEQ ID NO:9的氨基酸132-281(SEQ ID NO:16)。在其他特定实施方案中,片段是SEQID NO:9的氨基酸95-281(SEQ ID NO:14)或SEQ ID NO:9的氨基酸114-281(SEQ ID NO:15)。
变体可以具有相对于SEQ ID NO:9-15的一个以上取代、缺失或添加,或其任何组合。在一些实施方案中,变体是一种自然发生的替代序列,拼接变体,或替换、添加或缺失变体,或胞外结构域或其功能性片段或替代序列、拼接变体,或替换、添加或缺失变体。UniProtKB数据库中登录号P50591(TNF10_HUMAN),版本140(2014年1月22日最后修改)公开了自然发生的替代序列和变体。
a、TRAIL类似物
TRAIL可以作为三聚体与其受体相互作用。在一些实施方案中,第二序列可以形成多聚体,优选三聚体。三聚体可以是同源三聚体或异源三聚体。
本文所述的所有TRAIL蛋白均可使用用于分离天然或重组蛋白的标准技术制备,并如本文所述进行化学修饰。
第二序列可以包括TRAIL类似物或其激动性(agonistic)TRAIL受体结合片段或变体。TRAIL类似物是本领域已知的。在优选实施方案中,与野生型或内源性TRAIL相比,类似物对一种或多种激动性TRAIL受体(例如TRAIL-R1(DR4)和/或TRAIL-R2(DR5))的亲和力或特异性增加,对一种或多种拮抗性或诱饵TRAIL受体(例如受体DcR1和DcR2)或其组合的亲和力或特异性降低。
在一些实施方案中,类似物是野生型TRAIL的DR4选择性突变体。DR-4选择性突变体是本领域已知的,并在例如Tur,J.Biological Chemistry,283(29):20560-8(2008)中描述。在特定实施方案中,类似物是具有D218H(SEQ ID NO:17)或D218Y(SEQ ID NO:18)取代的SEQ ID NO:9的变体,或其功能性片段(例如,胞外结构域)。
在一些实施方案中,类似物是野生型TRAIL的DR5选择性突变体。特定的DR-5选择性突变体包括具有D269H(SEQ ID NO:19)、D269H/E195R(SEQ ID NO:20)或D269H/T214R(SEQ ID NO:21)的SEQ ID NO:9变体及其功能性片段(例如,胞外结构域)。这些变体在vander Sloot,Proc.Nat.Acad.Sci.USA 103(23):8634-9(2006)中描述。
b、其他TRAIL类似物
在又进一步的实例中,第二序列包括对天然TRAIL序列SEQ ID NO:9进行的一个或多个稳定化(stabilizing)突变,如S133P(SEQ ID NO:22)、S156C(SEQ ID NO:23)、L196C(SEQ ID NO:24)、T127C(SEQ ID NO:25)或H270C(SEQ ID NO:26)。具有这种突变的序列的实例包括SEQ ID NO:11-26。
典型地,第二氨基酸序列包括SEQ ID NO:9-26中任一项的序列。
3、接头
在有或没有接头的情况下,第一序列可以与第二序列融合。
接头可以是氨基酸接头,例如长度为1至4或1至6个氨基酸的氨基酸接头。示例性氨基酸接头包括D、G、DG、KGSG(SEQ ID NO:27)、GSG、SG和RGSG(SEQ ID NO:28)。
4、表达序列
融合多肽可以包括在第一氨基酸序列之前的表达序列。表达序列的长度可以为2至6或2至8个氨基酸。示例性表达序列包括RM、GRM、CGG、PGMCGG(SEQ ID NO:29)。
5、示例性融合多肽
示例性融合多肽以SEQ ID NO:30呈现,并且包含SEQ ID NO:4作为第一氨基酸序列,SEQ ID NO:15作为第二氨基酸序列,通过DG接头(带下划线的)连接在一起,并且前面带有GRM表达序列(带下划线的):
GRM
另一个示例性序列是SEQ ID NO:31:
其示出了具有比现有技术中的iLZ序列更有利的特性的miLZ序列。其包含SEQID NO:4(粗体)和SEQ ID NO:15(斜体)。
一种示例性现有技术构建体是SEQ ID NO:32:
其包含分别作为iLZ和TRAIL序列的SEQ ID NO:30(粗体)和SEQ ID NO:15(斜体)。
其他示例性融合多肽包括含有序列SEQ ID NO:4-8中的任一项与SEQ ID NO:9-26中的任一项的组合的多肽。
融合多肽可以二聚化的、三聚化的或多聚化的。二聚化、三聚化或多聚化可以通过二聚化结构域、三聚化结构域或多聚化结构域发生在两个或更多个融合蛋白之间。或者,融合蛋白的二聚化、三聚化或多聚化可以通过化学交联发生。所形成的二聚体、三聚体或多聚体可以是同源二聚体/同源多聚体或异源二聚体/异源多聚体。
6.融合多肽的性质
相对于具有本领域多聚化结构域的TRAIL组合物,融合多肽显示出改善的物理化学和生物学性质。与具有本领域多聚化结构域的TRAIL组合物相比,该融合多肽也具有较低的免疫原性。
a、溶解性
典型地,融合多肽的溶解度在约0.2mg/ml和30mg/ml之间(在生理缓冲液、生理pH和室温下)。典型地,在含有浓度在0.2mg/ml和30mg/ml之间的融合多肽的溶液中没有观察到实质性或可检测的聚集。在含有浓度在约0.2mg/ml和30mg/ml之间、约0.5mg/ml和25mg/ml之间、约0.5mg/ml和20mg/ml之间、约0.5mg/ml和15mg/ml之间、约0.5mg/ml和10mg/ml之间,或约0.5mg/ml和5mg/ml之间的融合多肽的溶液中没有显示出实质性或可检测的多肽聚集。
b、稳定性和半衰期
典型地,融合多肽在4℃或冷冻储存时具有改善的稳定性。当在表达融合多肽的细胞(作为冷冻细胞块(cell mass))中冷冻储存时,融合多肽也具有改善的稳定性。表达细胞可以以每毫升细胞培养物约1g融合多肽的生产水平生产融合多肽。具有融合多肽的表达细胞可储存一、二、三、四、五、六、七、八、九、十、十一或十二个月以上的时间,而在解冻时可溶性融合多肽不会大量损失。典型地,在重复冻融循环时,融合多肽在表达细胞内保持稳定。
如以下实施例所示,与本领域中具有iLZ基序和His标签纯化序列的融合多肽相比(SEQ ID NO:3和SEQ ID NO:15;图2A),包含SEQ ID NO:4作为第一序列和SEQ ID NO:15作为第二序列的融合多肽在热转移试验(thermal shift assay)中具有统计学上更高的热力学稳定性。
融合多肽在体内的半衰期通常在约1小时至36小时之间。
c、生物活性
典型地,与本领域中具有iLZ基序的融合多肽相比,所述融合多肽具有改善的生物活性。通常,当在COLO 205细胞上测试时,所述融合多肽的体外半数抑制浓度(IC50)在约0.001nM至约0.1nM之间,优选在约0.001nm至约0.05nM之间。
典型地,当与本领域中具有iLZ基序的融合多肽相比时,所述融合多肽具有至少约1.5、至少约2、至少约3、至少约4、至少约5、至少约6、至少约7、至少约8、至少约9、至少约10以上倍数的生物活性(例如IC50)。
如以下实施例所示,与包含iLZ基序和His标签纯化序列的融合多肽相比,包含SEQID NO:4作为第一序列和SEQ ID NO:15作为第二序列的融合多肽在细胞活力测试中具有约5倍高(about 5-fold higher)的生物活性(SEQ ID NO:3和SEQ ID NO:15;图2B)。
d、低免疫原性
典型地,与宿主中携带iLZ的未修饰多肽的免疫原性相比,携带miLZ的修饰的融合多肽在同一宿主中具有较低的免疫原性。通常,宿主是哺乳动物,优选是人类。
与携带iLZ的未修饰的多肽相比,携带miLZ的修饰的融合多肽的较低免疫原性可以是较低的免疫原性得分。
对于治疗应用,人类个体的“免疫反应”尤其值得关注,因为它可能会导致毒性、改变或抵消治疗方式(如多肽)的治疗效果。为了预测iLZ-TRAIL融合多肽的免疫原性,已经使用了一级氨基酸序列的计算机模拟分析(in silico analysis)。该方法基于已成熟的PROPRED模型用于预测抗原蛋白序列中MHC II类结合区(Singh&Raghava,Bioinformatics,v17,N 12,p 1236;和Brison et al.,Biodrugs,v.24,N 1,p 1,2010)。作为比较具有修饰的多聚化结构域的融合多肽和具有本领域多聚化结构域的TRAIL组合物的免疫原性的下一步,正在使用由ABZENA(加利福尼亚州,圣地亚哥(San Diego,CA))提供的EPISCREENTMDC:T细胞试验进行原位测试。该试验使用源自外周血单核细胞(PBMC)的树突状细胞(DC),典型地,来自HLA-DR同种型(allotype)分布(覆盖率和频率)代表感兴趣的人群的50个单独供体。将DC分化成未成熟的DC表型并加载测试蛋白。一旦成熟,将DC与自体CD4+T细胞孵育,并测量T细胞激活标记物。
典型地,与通过EPISCREENTMDC:T细胞试验或等效试验检测到的携带iLZ的未修饰的多肽在宿主中产生的T细胞激活标记物的水平相比,携带miLZ修饰的融合多肽在同一宿主中产生最低或更低水平的T细胞激活标记物。
典型地,当与本领域中具有iLZ基序(如SEQ ID NO:3)的融合多肽相比时,所述融合多肽具有降低至少约15%、至少约30%、至少约50%的总免疫原性得分。
例如,Abzena使用预测算法iTope AI分析了两个感兴趣的蛋白序列,以识别与人类MHC II类结合和/或与已知T细胞表位具有同源性的肽。从该分析中,确定了SEQ ID NO:32(包含SEQ ID NO:3和SEQ ID NO:15)和SEQ ID NO:31(包含SEQ ID NO:4和SEQ ID NO:15)分别具有27和5的总得分,其中所述肽序列均不与来自TCED
如下所示,SEQ ID NO:31包含具有比SEQ ID NO:32中的iLZ序列更有利的性质的miLZ序列,并且具有显著更好的总得分(5相比于27),这与单克隆人抗体的最佳得分相匹配。
miLZ-TRAIL缀合物的低免疫原性通常与治疗性人蛋白(如单克隆人抗体)的免疫原性相当。因此,计算机模拟中miLZ-TRAIL(SEQ ID 4和SEQ ID 15)的总MHCII结合得分与典型人单克隆抗体的免疫原性相当或更好。与iLZ TRAIL相比,miLZ-TRAIL的免疫原性较低,在计算机模拟中MHCII结合的总得分降低了几倍(5相比于27)。典型地,修饰的融合多肽的免疫原性降低至少约1.5、2、3、4、5、6、7、8、9、10以上的倍数,优选约2和10倍之间。
B、融合肽缀合物
融合多肽可与一种以上半衰期延长分子偶联。典型地,缀合物是稳定的缀合物,不会在体内释放半衰期延长分子。
1.半衰期延长分子
亲水性聚合物如聚亚烷基氧化物或其共聚物如BASF出售的
在其他实施方案中,可使用生物聚合物或多肽通过已报道的方法,例如但不限于使用化学缀合的透明质酸(Yang et al.,Biomaterials,32(33):8722-8729(2011)、储库形成多肽(depot forming polypeptide)(Amiram et al.,Proc Natl Acad Sci USA,110(8):2792-2792(2013),美国公布申请号US 2013/0178416 A1)和与延长的重组多肽相连的融合多肽(美国公布申请号US 2010/0239554 A1),融合多肽可以衍生为具有延长的半衰期的长效多肽。
2、融合多肽-PEG缀合物
融合多肽可与一个以上的PEG分子稳定缀合。
研究表明,用PEG衍生的TRAIL类似物保持抗癌活性(如诱导癌细胞的凋亡),同时在血浆中表现出更高的代谢稳定性、延长的药代动力学特性(profile)和更大的循环半衰期(Chae,et al.,Molecular cancer therapeutics 9(6):1719-29(2010);Kim,et al.,Bioconjugate chemistry,22(8):1631-7(2011a);Kim,et al.,Journal ofpharmaceutical sciences 100(2):482-91(2011b);Kim,et al.,Journal of controlledrelease:official journal of the Controlled Release Society 150(1):639(2011c))。
因此,在一些实施方案中,用一个以上乙二醇(EG)单元、更优选2个以上EG单元(即聚乙二醇(PEG))或其衍生物衍生融合多肽。PEG的衍生物包括但不限于甲氧基聚乙二醇琥珀酰亚胺丙酸酯、甲氧基聚乙二醇N-羟基琥珀酰亚胺、甲氧基聚乙二醇醛、甲氧基聚乙二醇马来酰亚胺和多支链聚乙二醇。
EG或衍生物单元的精确数量取决于所需的活性、血浆稳定性和药代动力学特征(profile)。例如,Kim等人(Kim et al.,2011a)报道称,2K、5K、10K、20K和30K-PEG-TRAIL在小鼠中导致了较高的循环半衰期,分别为3.9小时、5.3小时、6.2小时、12.3小时和17.7小时,相对于此,TRAIL的循环半衰期为1.1小时。在一些实施方案中,PEG的分子量在约1和100kDa之间。例如,PEG可以具有“N”kDa的分子量,其中N是1到100之间的任何整数。PEG可以具有“N”Da的分子量,其中,N是1,000到1,000,000之间的任意整数。在特定实施方案中,PEG的分子量是“N”Da,其中,“N”在5,000到50,000之间,优选为5,000。
融合多肽可以与线性或支链PEG缀合。一些研究表明,与线性PEG蛋白相比,用支链PEG衍生的蛋白延长了体内循环半衰期,这被认为部分是由于支链PEG蛋白的流体动力学体积更大,Fee,et al.,Biotechnol Bioeng.,98(4):725-3(2007)。
肽配体可以使用本领域已知的方法在C端衍生,或优选在N端衍生。
缀合物可由下式描述:
X-L-(PEG)
其中
X表示TRAIL蛋白或TRAIL融合多肽,
L表示接头,
PEG表示直链或支链聚(乙二醇)链,并且
n是选自2、3、4、5、6、7或8的整数。
在某些实施方案中,n是2。
聚亚烷基氧化物(polyalkylene oxide)通过接头与蛋白结合。接头可以是聚亚烷基氧化物,并且优选将两种聚亚烷基氧化物聚合物连接到蛋白上。
在特定实施方案中,融合多肽缀合物是包含TRAIL结构域的PEG缀合物,所述TRAIL结构域包含截短形式的人TRAIL(例如人TRAIL全长形式(1-281)的精氨酸-114至甘氨酸-281),以及分子量在1,000和100,000道尔顿之间、优选在5,000和100,000道尔顿之间,例如在5,000和80,000道尔顿之间、在5,000和60,000道尔顿之间或在5,000和40,000道尔顿之间的PEG。
N-末端修饰的PEG-TRAIL缀合物可通过在还原剂存在下使TRAIL结构域的N-末端胺与PEG的醛基反应而获得。PEG和TRAIL可以以2至50,或优选5至7.5的摩尔比(PEG/TRAIL)反应。可以使用线性或支链PEG分子。
PEG链优选但不必要具有相等的分子量。每个PEG链的示例性分子量范围在约10kDa和60kDa之间,优选在约20kDa和40kDa之间。PEG40是支链PEG部分,其分子量为40kDa:20+20kDa(每个PEG链)。
三聚PEG部分可由连接至接头臂(linker arm)的支链PEG链组成。三聚体PEG部分的视觉描述如下。
支链PEG PEG接头臂
总分子量10-60kDa总分子量1-30kDa
优选20-40kDa优选2-20kDa
合成了以下三聚PEG:YPEG42、YPEG43.5、YPEG45、YPEG50和YPEG60。
YPEG42是一种三聚PEG部分,其分子量为42kDa:(20+20kDa)(支链PEG)+2kDa(接头臂)。
YPEG43.5是一种三聚PEG部分,其分子量为43.5kDa:(20+20kDa)(支链PEG)+3.5kDa(接头臂)。
YPEG45是一种三聚PEG部分,其分子量为45kDa:(20+20kDa)(支链PEG)+5kDa(接头臂)。
YPEG50是一种三聚PEG部分,其分子量为50kDa:(20+20kDa)(支链PEG)+10kDa(接头臂)。
YPEG60是一种三聚PEG部分,其分子量为60kDa:(20+20kDa)(支链PEG)+20kDa(接头臂)。
a、接头部分
融合多肽可以通过接头共价连接到PEG部分。接头是聚合物,通常具有至少800埃的原子长度(atomic length)。典型地,接头的原子长度为约800至约2,000埃,约800至1,500埃,约800至约1,000埃,或约900至约1,000埃。原子距离(atomic distance)是指完全伸展的聚合物,并且当处于固态或溶液中时,接头可以折叠或卷曲,使得支链PEG和蛋白或肽之间的实际距离小于上述原子长度。
在某些实施方案中,接头是分子量在约1kDa至30kDa之间,优选约2kDa至20kDa的聚(乙二醇)衍生物。接头的长度也可以是至少80个单元的天然或非天然氨基酸。
接头的PEG替代物可包括合成或天然水溶性生物相容性聚合物,如聚氧化乙烯、聚乙烯醇、聚丙烯酰胺、蛋白如透明质酸和硫酸软骨素(chondroitin sulfate)、纤维素如羟甲基纤维素、聚乙烯醇和(甲基)丙烯酸多羟烷基酯(polyhydroxyalkyl(meth)acrylate)。
可以使用常规化学方法将融合多肽共价结合到接头上。如在N末端或赖氨酸残基中存在的伯胺基团,将在还原条件下与醛及其等同物反应生成胺。(Molineux,Currentpharmaceutical design,10(11):1235-1244(2004))。如在半胱氨酸残基中存在的巯基(-SH)基团,可以与多种Michael受体,包括丙烯酸和甲基丙烯酸衍生物以及马来酰亚胺进行共轭加成(Gong et al.,British Journal of Pharmacology,163(2):399-412(2011))。在肽和蛋白中存在的其他合适的亲核基团包括融合多肽中的二硫键(Brocchini,et al.,Nature protocols,1:2241-2252(2006))和组氨酸残基(Cong,et al.,BioconjugateChemistry,23(2):248-263(2012))。
接头可以使用常规化学方法共价连接到蛋白或肽上。例如,接头聚合物可在一端用亲电基团如醛、环氧化物、卤素(氯、溴、碘)、磺酸酯(甲苯磺酸酯、甲磺酸酯)、Michael受体或激活的羧酸酯(carboxylate)衍化,然后与蛋白或肽中的亲核胺或巯基反应。合适的Michael受体包括丙烯酸和甲基丙烯酸衍生物,例如丙烯酰胺、甲基丙烯酰胺、丙烯酸酯和甲基丙烯酸酯以及马来酰亚胺。合适的激活的羧酸酯包括碳酸硝基苯基酯(nitrophenylcarbonate)和NHS(N-羟基琥珀酸)酯。在其他实施方案中,含有精氨酸残基的肽和蛋白可以与含有反应性1,3二酮官能团的接头共价连接。
缀合物可通过以下方式制备:首先将接头与融合多肽连接,然后将接头与支链聚(乙二醇)连接,或者首先将接头和支链聚(乙二醇)连接,然后将接头和融合多肽连接。键形成的最佳顺序由所涉及的特定化学转变决定。
3、缀合物的特性
与现有技术的具有iLZ结构域的缀合物相比,长效融合多肽-PEG缀合物具有较低的免疫原性。典型地,长效缀合物比现有技术的长效缀合体具有更高的溶解度、更低的免疫原性和显著提高的效力(potency)。
a、溶解性
典型地,缀合物的溶解度在约0.2mg/ml和50mg/ml之间(在生理缓冲液、生理pH和室温下)。典型地,在含有浓度在0.2mg/ml和50mg/ml之间的缀合物的溶液中没有观察到实质性或可检测的聚集。含有浓度在约0.2mg/ml和50mg/ml之间、约0.2mg/ml和40mg/ml之间、约0.2mg/ml和30mg/ml之间或约0.2mg/ml和25mg/ml之间的缀合物的溶液通常不显示缀合物实质性或可检测的聚集。
b、稳定性和半衰期
典型地,当在生理浓度的盐的存在下在4℃下储存时或冷冻时,缀合物的稳定性提高。典型地,缀合物在重复冻融循环中通常是稳定的,没有实质性的生物活性损失。
可通过测量可通过离心分离的可溶性物质与不溶性物质的比率来评价稳定性。储存材料的完整结构也可以通过IEX-HPLC(SP-NPR)和RP-HPLC(C4)确认。
如下面的实施例5所示,在21-22mg/ml的浓度下,包含SEQ ID NO:4作为第一序列和SEQ ID NO:15作为第二序列的示例性缀合物,在生物活性和HPLC分析中的表现方面均是耐多次冻融循环的。该实施例表明,示例性融合多肽-PEG缀合物是高度可溶的并且对于重复冻融循环是稳定的。
典型地,在非人灵长类动物中,融合多肽的体内半衰期通常在约20小时和约50小时之间,在非人灵长类动物中,约20小时和约40小时之间,或约25小时和约40小时之间。
注射到猴子体内的His-iLZ-TRAIL(包含SEQ ID 3和SEQ ID 15)的半衰期(t
c、生物活性
典型地,与本领域中具有iLZ基序的缀合物相比,所述缀合物具有改善的生物活性。通常,当在COLO 205细胞上测试时,缀合物的体外IC50在约0.001nM和约0.1nM之间,优选在约0.001nM和约0.05nM之间(图4)。当在激活的肝星状细胞(HSC)Colo-205细胞上测试时,miLZ缀合物的体外IC50在约0.01nM和约1nM之间(图2B)。
典型地,与具有iLZ基序的缀合物相比,所述缀合物具有至少约1.5、至少约2、至少约3、至少约4、至少约5、至少约6、至少约7、至少约8、至少约9、至少约10倍以上的生物活性(例如IC50)。生物活性通常表示为例如IC50(半数抑制浓度),其随着生物活性的增加而降低。
如以下实施例所示,含有SEQ ID NO:4作为第一序列和SEQ ID NO:15作为第二序列的TLY012缀合物在0.142nM的IC50下对激活的HSC具有细胞毒性,并且在高浓度(100nM)下对静止HSC没有影响(图3)。
d、低免疫原性
典型地,聚乙二醇化修饰的融合多肽的低免疫原性类似于修饰的融合多肽的低免疫原性。
典型地,与宿主中携带iLZ的未修饰多肽的免疫原性相比,携带miLZ的修饰的融合多肽在同一宿主中具有较低的免疫原性。通常,宿主是哺乳动物,优选人类。
与携带iLZ的未修饰多肽相比,携带miLZ的修饰的融合多肽的较低免疫原性可以是较低的免疫原性得分。如上所述。
miLZ-TRAIL缀合物的低免疫原性通常与治疗性人蛋白(如单克隆人抗体)的免疫原性相当。因此,计算机模拟的miLZ-TRAIL(SEQ ID 4和SEQ ID 15)的总MHCII结合得分与典型人单克隆抗体的免疫原性相当或更好。与iLZ-TRAIL相比,miLZ-TRAIL的较低免疫原性,是由计算机模拟的MHCII结合的总得分降低了几倍(5相比于27)所定义的。
例如,Abzena使用预测算法iTope-AI分析了两个感兴趣的蛋白序列,以识别与人类MHC II类结合和/或与已知T细胞表位具有同源性的肽。从该分析中,确定了SEQ ID NO:32(包含SEQ ID NO:3和SEQ ID NO:15)和SEQ ID NO:31(包含SEQ ID NO:4和SEQ ID NO:15)分别具有27和5的总得分,其中没有一个肽序列与来自TCED
SEQ ID NO:31包含具有比SEQ ID NO:32中的iLZ序列更有利的特性的miLZ序列,如下所示,并且具有显著更好的总得分(5相比于27),这与单克隆人抗体的最佳得分相匹配。
miLZ-TRAIL缀合物的低免疫原性通常与治疗性人蛋白(如单克隆人抗体)的免疫原性相当。因此,计算机模拟的miLZ-TRAIL(SEQ ID 4和SEQ ID 15)的总MHCII结合得分与典型人单克隆抗体的免疫原性相当或更好。与iLZ-TRAIL相比,miLZ-TRAIL的较低免疫原性,由计算机模拟的MHCII结合的总得分降低了几倍(5相比于27)。典型地,修饰的融合多肽的免疫原性降低至少约1.5、2、3、4、5、6、7、8、9、10倍以上,优选约2至10倍。
4、示例性融合多肽-PEG缀合物
PEG部分和TRAIL融合多肽的示例性缀合物是TLY012分子。它是重组人TRAIL(rhTRAIL)的聚乙二醇化形式,在N末端与有利于三聚体的形成的人源化卷曲螺旋异亮氨酸“拉链(zipper)”(iLZ)基因融合(图1D)。构建体的TRAIL部分是以V36开始的胞外结构域,如SEQ ID NO:31所示。miLZ“拉链”结构域源自一种称为GCN41的酵母蛋白。miLZ“拉链”包含在6、10、13、17、24、27和31位的异亮氨酸取代,以增强三聚体形成和两个氨基酸取代,并包含I20V和K29E(相对于SEQ ID NO:2显示的取代),以减少基于计算机模拟分析的免疫原性概率。可以添加残基以促进miLZ-TRAIL在大肠杆菌中的表达,例如初始G和/或氨基酸接头D或DG。
在聚乙二醇化之前,miLZ rhTRAIL是一种锌络合的同源三聚体,由三条相同的单链多肽组成,估计分子量为71.2kDa(71,175Da)。TLY012是几种miLZ-rhTRAIL形式的混合物,其以不同程度在不同位置聚乙二醇化,其中5kDa PEG-醛以单聚乙二醇化和双聚乙二醇化形式为主。TLY012中存在的miLZ-TRAIL的所有PEG化形式在基于细胞的生物测试中都具有功能活性(图3)。TLY012的氨基酸序列如下所示,在大肠杆菌中表达miLZ-TRAIL后处理N-末端甲硫氨酸:
GRMKQIEDKIEEILSKIYH
5、复合物(Complexes)
融合多肽可以与带负电的部分复合。在一些实施方案中,带负电的部分可有助于将融合多肽负载到纳米颗粒中,用于延长递送、持续递送或缓释递送。在一些实施方案中,带负电部分本身介导融合多肽的延长递送、持续递送或缓释递送。优选地,带负电部分不会实质性地降低融合多肽诱导或增强细胞凋亡的能力。
带正电的TRAIL和带负电的硫酸软骨素(CS)之间复合物(CS/TRAIL)的形成被证明有助于将TRAIL负载在聚(丙交酯-共-乙交酯)(PLGA)微球(MS)中,而不损害TRAIL的活性(Kim,et al.,Journal of Pharmacy and Pharmacology,65(1):11–21(2013))。在pH 5.0下,以2TRAIL与CS(TC2)的重量比形成了约200nm的纳米复合物(nanocomplex)。该复合物在通过多乳液方法制备的PLGA MS中的负载效率比天然TRAIL高>95%(>95%higher)。因此,在一些实施方案中,融合多肽或缀合物与硫酸软骨素复合,并任选地负载到微米颗粒或纳米颗粒中,例如基于PLGA的颗粒中。
在其他实施方案中,融合多肽或其缀合物与透明质酸(HA)复合。通过混合带正电荷的PEG-TRAIL和带负电荷的HA制备的PEG-TRAIL和HA的纳米复合物显示出在体内持续递送,与PEG-TRAIL相比,生物活性损失可忽略不计(Kim,et al.,Biomaterials,31(34):9057-64(2010))。通过施用在含1%HA的溶液中的纳米颗粒,进一步增强了递送。
C、编码融合多肽的多核苷酸
公开了编码重组融合多肽的多核苷酸。这种多核苷酸可以在表达载体中提供。典型地,表达载体包括与多核苷酸可操作连接的启动子。启动子可以是任何启动子,包括组成型活性、可诱导性、条件性或组织特异性启动子。该多核苷酸可适用于在酵母(如毕赤酵母(Pichia pastoris))或大肠杆菌表达系统中表达。
表达这些多核苷酸的方法是本领域已知的。这些方法包括用表达载体转染大肠杆菌细胞,前提是表达载体包括可诱导性启动子。转染的大肠杆菌细胞用于接种培养基。典型地,培养基包括锌离子,例如氯化锌形式的锌离子。
下面列出了编码融合多肽的核苷酸序列,方框中显示了感兴趣的密码子:
/>
/>
(SEQ ID NO:35);
/>
/>
/>
D.药物组合物
药物组合物包含有效量的融合多肽(或多核苷酸)或缀合物,以及任选的药学上可接受的载体。这些药物组合物可用于治疗增殖性、自身免疫性或纤维化疾病。
药物组合物可包括融合多肽(或多核苷酸)或缀合物作为第一治疗剂、预防剂或诊断剂,并包括第二治疗剂、预防剂或诊断剂,或更多治疗剂、预防剂或诊断剂。
典型地,典型的赋形剂包括通常注射给药配制用的无菌水、无菌盐水或无菌缓冲水或无菌缓冲盐水。
三、制备方法
A、融合多肽的制备方法
融合多肽可使用本领域已知的常规技术制造。分离的多肽可通过例如化学合成或在宿主细胞中重组生产获得。为了重组生产多肽,含有编码融合蛋白的核苷酸序列的核酸可用于转化、转导或转染细菌或真核宿主细胞(例如,昆虫、酵母或哺乳动物细胞)。通常,核酸构建体包括与编码多肽的核苷酸序列可操作地连接的调控序列。典型地,调控序列(本文中也称为表达控制序列)不编码基因产物,而是影响与它们可操作连接的核酸序列的表达。
用于表达和生产多肽的有用的原核系统和真核系统是本领域公知的,并且包括例如大肠杆菌菌株如BL-21和培养的哺乳动物细胞如CHO细胞。
糖蛋白在哺乳动物细胞中的表达通常导致哺乳动物型糖基化(mammalian-typeglycosylation)。对于人蛋白来说,这是理想的,然而一些细胞系添加了非人Galα1-3Gal表位和N-甘氨酰神经氨酸(NGNA)。昆虫表达系统增加了更短的N-聚糖,几乎没有唾液酸化。典型地,植物细胞包括含有额外海藻糖和木糖残基的聚糖。酵母表达系统具有与哺乳动物细胞非常不同的糖基化模式,只有含甘露糖的聚糖。通常,iLZ-TRAIL和miLZ不依赖于糖基化,因此细菌和哺乳动物细胞系可用于表达构建体。
在真核宿主细胞中,许多基于病毒的表达系统可用于表达多肽。基于病毒的表达系统是本领域公知的,并且包括但不限于杆状病毒、SV40、逆转录病毒或基于牛痘病毒的病毒载体。
稳定表达多肽的哺乳动物细胞系可以使用具有适当控制元件和选择性标记的表达载体来生产。例如,真核表达载体pCR3.1(Invitrogen Life Technologies)和p91023(B)(参见Wong et al.(1985)Science 228:810-815)适合于在例如中国仓鼠卵巢(CHO)细胞、COS-1细胞、人胚胎肾293细胞、NIH3T3细胞、BHK21细胞、MDCK细胞和人血管内皮细胞(HUVEC)中表达变体多肽。其他合适的表达系统包括可通过可从Lonza Group有限责任公司获得的GS基因表达系统
在通过电穿孔、脂质转染、磷酸钙或氯化钙共沉淀、DEAE-葡聚糖或其他合适的转染方法引入表达载体之后可以选择稳定的细胞系(例如,通过代谢选择或对G418、卡那霉素或潮霉素的抗生素抗性)。可以培养转染的细胞,以表达感兴趣的多肽,并且可以从例如细胞培养上清液或裂解的细胞中回收多肽。
多肽可以使用例如亲和色谱、离子交换色谱、疏水相互作用色谱、DEAE离子交换、凝胶过滤和羟基磷灰石色谱等色谱方法分离。在一些实施方案中,多肽可以被工程化以包含额外的含结构域的氨基酸序列,该氨基酸序列允许多肽被捕获到亲和基质上。例如,细胞培养上清液或细胞质提取物中的Fc-融合多肽可以使用蛋白A柱分离。标记(tag),如c-myc、血凝素、多组氨酸或FLAGTM(Kodak)可用于帮助多肽纯化。这种标记可以插入多肽内的任何地方,包括羧基末端或氨基末端。其他有用的融合包括有助于检测多肽的酶,如碱性磷酸酶。免疫亲和色谱也可用于纯化多肽。另外,多肽可以被工程化以包含分泌信号(如果没有分泌信号已经存在),该分泌信号导致多肽由产生多肽的细胞分泌。然后可以方便地从细胞培养基中分离分泌的多肽。
1、示例性方法
包含SEQ ID NO:4作为第一序列和SEQ ID NO:15作为第二序列的融合多肽可以根据以下方法。
使用pET23表达载体在大肠杆菌中产生表达盒中编码SEQ ID NO:4和SEQ ID NO:15的多核苷酸。在大肠杆菌中扩增后,使用异丙基L-硫代-B-D-吡喃半乳糖苷(isopropyl-L-thio-B-D-galactopyranoside)(0.02-1mmol/L,27℃下进行7小时)从可诱导性启动子诱导融合多肽的表达。然后收获细胞、裂解并通过亲和色谱(Zn-NTA)和HIC(C4)色谱纯化可溶性融合多肽。
B、缀合物的制备方法
PEG-融合多肽缀合物可通过在还原剂存在下使融合多肽的第一序列或第二序列的N-末端胺与PEG的醛基反应而获得。PEG和融合多肽可以以2至50、或优选5至7.5的摩尔比(PEG/miLZ-TRAIL)反应。
典型地,制备PEG-融合多肽缀合物的方法包括使融合多肽与PEG或其衍生物的醛基反应。PEG的示例性衍生物包括甲氧基聚乙二醇琥珀酰亚胺丙酸酯、甲氧基聚乙二醇N-羟基琥珀酰亚胺、甲氧基聚乙二醇醛、甲氧基聚乙二醇马来酰亚胺和多支链聚乙二醇。典型地,该反应在还原剂存在下发生。典型地,PEG或其衍生物具有通过SDS-PAGE和MALDI-TOF测定的在1,000和100,000之间的分子量。
在示例性方法中,PEG和融合多肽以2至10,优选5至7.5的摩尔比(PEG/融合多肽)反应。典型地,还原剂为NaCNBH
四、使用方法
典型地,将制剂用于预防或治疗疾病的一种或多种症状的方法中。所述方法通常包括将融合多肽、多核苷酸或缀合物的固体或液体组合物施用至需要其的个体。
含有有效量的融合多肽、多核苷酸或缀合物以治疗或缓解疾病或障碍(disorder)的一种或多种症状,以及任选的药学上可接受的载体的融合多肽、多核苷酸、缀合物或药物组合物,典型地,通过肠外施用,例如注射、局部(如手术期间)或施用至粘膜表面(直肠、阴道、口腔或肺)。这些药物可以以溶液、植入物或凝胶形式施用,或以干粉形式施用或再溶解或再悬浮后施用。
典型地,该方法包括单独或以组合物的形式使用融合多肽、多核苷酸或缀合物来治疗增殖性疾病,例如癌症、自身免疫性疾病,如类风湿性关节炎或纤维化疾病。
施用后,个体和治疗医生通常会监测疾病的状态、症状或临床表现。在优选实施方案中,与施用前症状的严重程度相比,制剂的施用部分地或完全降低了疾病的一种或多种症状或临床表现的严重程度。症状严重程度的这种降低在个体中减轻、改善、缓解相同或其他症状或特定疾病、障碍和/或病症、延迟个体的发病、抑制相同或其他症状或特定疾病、障碍和/或病症的进展、降低相同或其他症状或特定疾病、障碍和/或病症的严重程度和/或降低相同或其他症状或特定疾病、障碍和/或病症的的发生率。
融合多肽、多核苷酸或缀合物或其组合物可配制成各种制剂,用于临床应用时的肠外施用。向个体施用制剂将治疗有效量的融合多肽、多核苷酸或缀合物或其组合物递送至细胞和组织。
所需剂量可以每天递送一次或每天多次。例如,所需剂量可以每天递送三次、每天两次、每天一次、每周两次、每周一次或一周一次。在某些实施方案中,可以利用多次施用(例如,两次、三次、四次、五次、六次、七次、八次、九次、十次、十一次、十二次、十三次、十四次或更多次施用)来递送所需剂量。
特定患者的剂量将根据患者的体重、年龄、性别、健康状况和饮食、施用持续时间、施用途径、排泄率和疾病严重程度进行调整。通常,可以每一周到两周施用一次有效剂量。或者,该剂量可在每日有效剂量内以单剂量或分几剂服用。
典型地,融合多肽、多核苷酸或缀合物或其组合物以剂量单位形式配制,以便于施用和剂量的一致性(uniformity)。然而,应当理解,组合物的每日总用量将由主治医师在合理的医学判断范围内决定。任何特定个体的特定治疗有效剂量水平将取决于多种因素,包括所治疗的障碍以及该障碍的严重程度;所用特定活性剂的活性;所用的具体组分;个体的年龄、体重、一般健康状况、性别和饮食;所用特定活性剂的施用时间、施用途径和排泄率;治疗持续时间;与所用的特定活性剂组合或同时使用的药物;以及医学领域已知的类似因素。
在某些实施方案中,剂量单位含有每天约0.001mg/kg个体体重至约100mg/kg个体体重、约0.01mg/kg个体体重至约50mg/kg个体体重、约0.1mg/kg个体体重至约40mg/kg个体体重、约0.5mg/kg个体体重至约30mg/kg个体体重、约0.01mg/kg个体体重至约10mg/kg个体体重,约0.1mg/kg至约10mg/kg个体体重,或约1mg/kg至约25mg/kg个体体重的量的融合多肽、多核苷酸或缀合物或其组合物,每天一次或多次,以获得所需的治疗效果。所需剂量可以每天三次、每天两次、每天一次、两天一次、三天一次、每周一次、每两周一次、每三周一次或每四周一次递送。在某些实施方案中,可以使用多次施用(例如,两次、三次、四次、五次、六次、七次、八次、九次、十次、十一次、十二次、十三次、十四次以上施用)来递送所需剂量。
A、需要治疗的疾病
1.增殖性疾病,如癌症
融合多肽、多核苷酸、缀合物或它们的组合物,通过延迟或抑制个体中肿瘤的生长,减少肿瘤的生长或尺寸,抑制或减少肿瘤的转移,和/或抑制或减少与肿瘤发展或生长相关的症状,可用于治疗患有良性或恶性肿瘤或其他过度增殖疾病的个体。
可治疗的恶性肿瘤可根据肿瘤来源组织的胚胎起源进行分类。癌症是由内胚层或外胚层组织(如皮肤或内脏和腺体的上皮层)引起的肿瘤。肉瘤的发生频率较低,来源于中胚层结缔组织,如骨骼、脂肪和软骨。白血病和淋巴瘤是骨髓造血细胞的恶性肿瘤。白血病以单个细胞的形式增殖,而淋巴瘤则以肿瘤的形式生长。恶性肿瘤可出现在身体的许多器官或组织中,从而形成癌症。
增殖性疾病可以是癌症,其中原发性肿瘤起源于肝脏、胰腺、结肠、脑、乳腺、前列腺、肺、头和颈、胃、淋巴结和皮肤。肿瘤可以是原发性肿瘤或转移性肿瘤。肿瘤可能是实体瘤。
a、靶向癌症相关成纤维细胞
免疫疗法,或者更具体地说,使用单克隆抗体阻断抑制性免疫检查点分子以增强对肿瘤的免疫反应,在晚期实体瘤中显示出临床前景。此类疗法包括PD-1、PD-L1、CTLA-4、IDO通路阻断剂。肿瘤治疗取得了显著进展,包括基于检查点抑制剂的癌症免疫疗法的开发。然而,免疫疗法仅对黑素瘤和肺癌等选定癌症类型的患者有益,而针对实体癌(包括肝细胞癌(HCC)、胰腺导管腺癌(PDAC)或结肠癌(CRC))的有效免疫疗法的发展相对缓慢。目前已被广泛认为,免疫抑制肿瘤微环境(immunosuppressive tumor microenvironment,TME)是免疫疗法原发性耐药的主要组成之一。肿瘤微环境(TME)的建立不仅允许肿瘤发展,还允许其募集宿主免疫系统的组成部分。TME组成除了促进肿瘤生长外,还主要充当细胞屏障以防止抗肿瘤的免疫细胞的任何浸润(Weiner,Clinical Advances in Hematology&Oncology.;13(5):299-306(2015),Chiriva-Internati and Bot.International Reviewsof Immunology;34(2):101–103(2015))。围绕癌性肿块的基质层的形成建立了物理屏障,物理屏障的特征在于已知的促进癌症生长的几个特征,包括缺氧条件和异常肿瘤新生血管的形成(Klener et al.,Current Pharmaceutical Biotechnology;16(9):771–781(2015))。TME是由肿瘤细胞和纤维化基质细胞组成的异质细胞群。基质细胞最重要的来源是α-平滑肌肌动蛋白(α-SMA)+肌成纤维细胞(MFB,激活的成纤维细胞)和癌症相关成纤维细胞(CAF),已知它们有助于产生过量的胞外基质(ECM)沉积、肿瘤的启动和进展,以及实体癌中的强大免疫抑制特性。
当用于癌症治疗时,融合多肽和融合多肽缀合物靶向癌症相关的成纤维细胞并诱导癌症相关成纤维细胞凋亡。
本文证明了,融合多肽缀合物TLY012具有抗纤维化功能,并靶向具有癌症相关成纤维细胞的纤维化肿瘤,在没有治疗的情况下,由于纤维化细胞屏障,这些成纤维细胞对免疫疗法具有抗性。
2、自身免疫性疾病
融合多肽、多核苷酸、缀合物或其组合物可用于预防或治疗自身免疫性疾病的一种或多种症状。代表性自身免疫性疾病包括狼疮、类风湿性关节炎和I型糖尿病。
系统性红斑狼疮(SLE)是一种自身免疫性疾病,具有广泛的临床和免疫学异常。自身抗体,特别是针对双链DNA的自身抗体的存在,是该病的特征。SLE可影响不同的器官系统,包括皮肤、关节、中枢和外周神经系统、肾脏和肝脏。该病的病因尚不清楚。然而,越来越多的证据表明凋亡细胞的存在和积累在自身免疫中起作用(Hooge et al.,Ann RheumDis,64:854–858(2005))。
观察到SLE患者血清可溶性TRAIL浓度升高,发现其具有疾病特异性。非活动性疾病(inactive disease)患者的水平通常高于活动性疾病(active disease)的患者。
类风湿性关节炎(RA)是一种导致关节疼痛、肿胀、僵硬和功能丧失的关节炎。它可以影响任何关节,但常见于手腕和手指。患类风湿性关节炎的女性多于男性。这种疾病可能只存在很短的时间,或者症状可能会出现或消失。严重的形态(severe form)可以持续一生。
类风湿性关节炎与骨关节炎(OA)不同,骨关节炎是一种常见的关节炎,通常伴随着年龄的增长出现。RA会影响关节以外的身体部位,如眼睛、口腔和肺部。RA是一种自身免疫性疾病,这意味着关节炎是由免疫系统攻击身体自身组织引起的。
与骨关节炎(OA)患者相比,类风湿性关节炎(RA)患者的TRAIL表达升高。RA患者关节炎关节中的炎症环境似乎促进了成纤维细胞样滑膜细胞(FLS)中TRAIL的表达(Audo etal.,Arthritis and Rheumatism,63(4):904–913(2011))。
糖尿病(diabetes,diabetes mellitus)是由于胰腺不能产生足够的胰岛素,或者身体细胞对产生的胰岛素没有适当的反应。糖尿病主要有三种类型:
1型糖尿病是由于胰腺不能产生足够的胰岛素引起的。这一类以前被称为“胰岛素依赖型糖尿病”(IDDM)或“青少年糖尿病”,
2型糖尿病开始于胰岛素抵抗,这是一种细胞无法对胰岛素做出适当反应的情况。随着病情的发展,也可能出现胰岛素缺乏。这一类以前被称为“非胰岛素依赖型糖尿病”(NIDDM)或“成人发病糖尿病”;
妊娠期糖尿病是第三种主要形式,发生在没有糖尿病病史的孕妇血糖水平升高时。
1型糖尿病必须通过胰岛素治疗才能生存。1型糖尿病是一种胰岛的自身免疫性炎症疾病。在人类1型糖尿病及其啮齿类动物模型中,产生胰岛素的胰腺β-细胞被浸润的炎性细胞选择性地破坏。
TRAIL在体内的作用可能包括抑制胰岛的自身免疫炎症。TRAIL可抑制胰岛炎并抑制自身免疫性糖尿病。
T细胞和巨噬细胞都参与介导这种疾病中的β-细胞损伤。TRAIL可以通过作用于这些细胞中的一种或两种来调节糖尿病。TRAIL还可以阻断由抗CD3抗体激活的T细胞的DNA合成和细胞周期进展。TRAIL可能介导胸腺细胞的负选择。因此,TRAIL可抑制糖尿病炎症和自身反应性T细胞激活(Lamhamedi-Cherradi et al.,Diabetes 52:2274–2278(2003))。
下面的实施例说明激活的细胞,例如肝星状细胞,可以被PEG化融合多肽缀合物TLY012特异性靶向并杀死,而不影响静止的肝星状细胞。这种治疗导致TRAIL诱导的细胞凋亡,从而防止或逆转纤维化。重要的是,通过消除这种激活的星状细胞,高度上调的纤维化相关分子可同时下调。这表明,所述化合物可用于治疗病理状态,其中公开了激活的成纤维细胞、肌纤维母细胞、肌成纤维细胞和激活的内皮细胞和上皮细胞产生或诱导过量的胞外基质,导致不需要的纤维化或瘢痕形成。瘢痕或纤维化可发生在肝脏、胰腺、肺、心脏、肾脏、肠、皮肤或动脉。
B、联合治疗
重组融合多肽、多核苷酸或融合多肽缀合物中的一种或多种可单独或与一种或多种另外的活性剂组合施用给有需要的个体。在这些实施方案中,重组融合多肽、多核苷酸或融合多肽缀合物是第一活性剂,另外的活性剂是第二活性剂。在一些实施方案中,第二活性剂是本领域已知的用于治疗增殖性疾病、自身免疫性疾病或纤维化疾病的药剂。在一些实施方案中,第二活性剂是调节宿主细胞的一种药剂,例如,调节癌细胞增殖、减少星状细胞激活或活性、增加癌细胞或星状细胞凋亡、减少胞外基质或其组分(特别是胶原蛋白)的沉积、增加胞外基质及其组分,特别是胶原蛋白或其任何组合的降解的药剂。在一些实施方案中,第一活性剂增加功效、增强效果或以其他方式改善细胞对第二活性剂的性能或敏感性。
1.第二活性剂
可与重组融合多肽、重组多核苷酸或重组融合多肽缀合物一起使用的第二活性剂可以是化疗剂或抗炎剂。
a、化疗剂
已经研究了重组融合多肽、重组多核苷酸或重组融合多肽缀合物在癌症治疗中的用途,无论是单独使用还是与常规癌症治疗如化疗剂组合使用。一些报告表明,化疗药物可以使细胞对TRAIL诱导的凋亡敏感,一些结果表明,两种药物的组合比当单独使用时的药物的作用总和更有效(Cuello,et al.,Gynecol Oncol.,81(3):380-90(2001);Wu,et al.,Vitam Horm.,67:365-83(2004))。因此,在一些实施方案中,用一种或多种重组融合多肽或一种或多种重组融合多肽缀合物和化疗剂的组合治疗所公开的个体和疾病。在一些实施方案中,个体患有癌症。在一些实施方案中,个体患有带有实体瘤的癌症。
示例性化疗药物包括但不限于阿霉素、依托泊苷、喜树碱、伊立替康、顺铂、奥沙利铂、多西紫杉醇、环磷酰胺、5-氟尿嘧啶、卡铂、氮芥、索拉非尼、苯丁酸氮芥、长春新碱、长春花碱、长春瑞滨、长春地辛、紫杉醇及其衍生物、拓扑替康、安吖啶、磷酸依托泊苷、替尼泊苷、表鬼臼毒素、曲妥珠单抗
i、免疫检查点抑制剂
第二活性剂可以包括一种或多种免疫检查点抑制剂(ICI)。通常,ICI包括与程序性细胞死亡蛋白1(PD-1)结合的小分子、抗体或抗体片段,针对PD-1配体1(PD-L1)的小分子、抗体或抗体片段和针对细胞毒性T淋巴细胞相关抗原4(CTLA-4)的小分子、抗体或抗体片段。
典型地,在一剂注射中,第二活性剂包括约0.1mg/kg患者体重和约100mg/kg患者体重之间的ICI。疫苗中ICI的合适量包括在约0.1mg/kg和约500mg/kg之间、在约0.1mg/kg和约250mg/kg之间、在约0.1mg/kg和约100mg/kg之间、在约0.1mmg/kg和约80mg/kg之间、和在约0.1mg/kg和约60mg/kg之间,例如在约0.5mg/kg和约20mg/kg之间、或在约1mg/kg和约10mg/kg之间。ICI的具体浓度包括0.1mg/kg、0.2mg/kg、0.3mg/kg、0.4μM、0.5mg/kg、0.6mg/kg、0.7mg/kg、0.8mg/kg、0.9mg/kg、1mg/kg、2mg/kg、3mg/kg、4mg/kg、5mg/kg、6mg/kg、7mg/kg、8mg/kg、9mg/kg、10mg/kg、11mg/kg、12mg/kg、13mg/kg、14mg/kg、15mg/kg、16mg/kg、17mg/kg、18mg/kg、19mg/kg、20mg/kg、21mg/kg、22mg/kg、23mg/kg、24mg/kg、25mg/kg、26mg/kg、27mg/kg、28mg/kg、29mg/kg、30mg/kg、31mg/kg、32mg/kg、33mg/kg、34mg/kg、35mg/kg、36mg/kg、37mg/kg、38mg/kg、39mg/kg、40mg/kg、41mg/kg、42mg/kg、43mg/kg、44mg/kg、45mg/kg、46mg/kg、47mg/kg、48mg/kg、49mg/kg和50mg/kg。
PD-1拮抗剂
第二活性剂可以是PD-1和/或PD-L1/PD-L2拮抗剂。
T细胞的激活通常取决于T细胞受体(TCR)与通过主要组织相容性复合体(MHC)呈现的抗原肽接触后的抗原特异性信号(antigen-specific signal),而这种反应的程度由来自多种共刺激分子的与抗原无关的正信号和负信号控制。后者通常是CD28/B7家族的成员。相反,程序性死亡-1(PD-1)是CD28受体家族的一员,当在T细胞上被诱导时,它会递送负免疫反应。PD-1与其配体之一(B7-H1或B7-DC)之间的接触诱导抑制性反应,其降低T细胞增殖和/或T细胞反应的强度和/或持续时间。美国专利号8,114,845、8,609,089和8,709,416中描述了合适的PD-1拮抗剂,包括结合并阻断PD-1配体以干扰或抑制配体与PD-1受体的结合的化合物或试剂,或直接结合并阻断该PD-1受体而不通过PD-1受体诱导抑制性信号转导的化合物或试剂。
在一些实施方案中,PD-1受体拮抗剂直接与PD-1受体结合而不触发抑制性信号转导,并与PD-1受体配体结合以减少或抑制配体通过PD-1受体触发信号转导。通过减少与PD-1受体结合并触发抑制性信号转导的配体的数量和/或量,更少的细胞被PD-1信号转导递送的负信号衰减,并且可以实现更稳健的免疫反应。
人们认为,PD-1信号是通过与PD-1配体(如B7-H1或B7-DC)紧密结合来驱动的,该配体与主要组织相容性复合物(MHC)呈现的肽抗原非常接近(例如,参见Freeman,Proc.Natl.Acad.Sci.U.S.A,105:10275-10276(2008))。
因此,防止PD-1和TCR在T细胞膜上共连接(co-ligation)的蛋白、抗体或小分子也是有用的PD-1拮抗剂。
其他PD-1拮抗剂包括与PD-1或PD-1配体结合的抗体和其他抗体。
合适的抗PD-1抗体包括但不限于以下出版物中描述的那些:PCT/IL03/00425(Hardy等,WO/2003/099196)、PCT/JP2006/309606(Korman等,WO/2006/121168)、PCT/US2008/008925(Li等,WO/2009/014708)、PCT/JP03/08420(Honjo等,WO/2004/004771)、PCT/JP04/00549(Honjo等,WO/2004/072286)、PCT/IB2003/006304(Collins等,WO/2004/056875)、PCT/US2007/088851(Ahmed等,WO/2008/083174)、PCT/US2006/026046(Korman等,WO/2007/005874)、PCT/US2008/084923(Terrett等,WO/2009/073533)和Berger等,Clin.Cancer Res.,14(10):3044-51(2008)。
抗PD-1抗体的具体实例是MDX-1106(纳武单抗,参见临床试验编号(clinicaltrial number)NCT00441337和Kosak,US 20070166281(2007年7月19日公开),第42段),其是人抗PD-1抗体,优选以3mg/kg的剂量施用。
示例性抗B7-H1抗体包括但不限于以下出版物中描述的那些:PCT/US06/022423(WO/2006/133396,2006年12月14日公开)、PCT/US07/088851(WO/2008/083174,2008年7月10日公开)、US2006/0110383(2006年5月25日公开)
抗B7-H1抗体的具体实例是MDX-1105(WO/2007/005874,2007年1月11日公开),其为人抗B7-Hl抗体。参见7,411,051、7,052,694、7,390,888和美国公布申请号2006/0099203以了解更多抗B7-DC抗体。
所述抗体可以是双特异性抗体,其包括与PD-1受体结合的抗体,所述抗体与结合PD-1的配体(例如B7-H1)的抗体桥接。在一些实施方案中,PD-1结合部分减少或抑制通过PD-1受体的信号转导。
其他示例性PD-1受体拮抗剂包括但不限于B7-DC多肽,其包括这些多肽的同源物和变体,以及上述任何一种的活性片段,以及包含这些中的任一种的蛋白。在一个优选的实施方案中,所述蛋白包括与抗体(例如人IgG)的Fc部分偶联的B7-DC可溶性部分,并且不包含人B7-DC的全部或部分跨膜部分。
PD-1拮抗剂也可以是哺乳动物B7-H1的片段,优选来自小鼠或灵长类动物,优选人类,其中该片段结合并阻断PD-1,但不导致通过PD-1的抑制性信号转导。该片段也可以是融合蛋白,例如Ig融合蛋白的一部分。
其他有用的多肽PD-1拮抗剂包括与PD-1受体的配体结合的那些。这些拮抗剂包括PD-1受体蛋白或其可结合PD-1配体的可溶性片段,如B7-H1或B7-DC,并阻止与内源性PD-1受体的结合,从而阻止抑制性信号转导。B7-H1也已被证明与蛋白B7.1结合((Butte et al,Immunity,Vol.27,pp.1 11-122,(2007))。这些片段还包括PD-1蛋白的可溶性ECD部分,该部分包括突变,如A99L突变,其增加与天然配体的结合(Molnar et al,PNAS,105:10483-10488(2008))。B7-1或其可溶性片段,其可与B7-H1配体结合并阻止与内源性PD-1受体结合,从而阻止抑制性信号转导,这也是有用的。
PD-1和B7-H1反义核酸、DNA和RNA以及siRNA分子也可以是PD-1拮抗剂。这种反义分子阻止PD-1在T细胞上的表达以及T细胞配体如B7-H1、PD-L1和/或PD-L2的产生。例如,siRNA(例如,长度约21个核苷酸,对编码PD-1或编码PD-1配体的基因具有特异性,其寡核苷酸可以很容易地商购)与载体例如聚乙烯亚胺的复合物(参见Cubillos-Ruiz et al,J.Clin.Invest.119(8):2231-2244(2009))很容易被表达PD-1以及PD-1配体的细胞摄取,并减少这些受体和配体的表达,以实现T细胞中抑制性信号转导的减少,从而激活T细胞。
CTLA-4拮抗剂
用于联合治疗的其他分子包括CTLA-4拮抗剂。例如,在一些实施方案中,分子是结合CTLA4的试剂。
抗PD-1、抗B7-Hl和抗CTLA4抗体的剂量在本领域中是已知的,在0.1mg/kg至100mg/kg的范围内,优选1mg/kg至50mg/kg的更窄范围,更优选10mg/kg至20mg/kg的范围。人类个体的合适剂量在5mg/kg至15mg/kg之间,10mg/kg的抗体(例如,人抗PD-1抗体,如MDX-1106)。
如本文所述有用的抗CTLA4抗体的具体实例是易普利姆玛,也称为MDX-010或MDX-101,一种人抗CTLA4抗体,优选以约10mg/kg的剂量施用,和曲美木单抗(Tremelimumab),一种人抗CTLA4抗体,优选以约15mg/kg的剂量施用。另参见Sammartino,et al,ClinicalKidney Journal,3(2):135-137(2010),2009年12月在线出版。
在其他实施方案中,拮抗剂是小分子。已证明一系列小的有机物与B7-1配体结合,以防止与CTLA4结合(参见Erbe et al,J.Biol.Chem.,277:7363-7368(2002))。这种小的有机物可以单独或与抗CTLA4抗体一起施用,以减少T细胞的抑制性信号转导。
二、示例性ICI
一种或多种重组融合多肽或重组融合多肽、重组多核苷酸或重组融合多肽缀合物可与一种或多种ICI组合使用。示例性ICI包括纳武单抗(靶向PD-1)、派姆单抗(靶向PD-1)、阿特朱单抗(靶向PD-L1)、阿维单抗(靶向PD-L1),德瓦鲁单抗(阻断PD-L1与PD-1(CD279)的相互作用),西米普利单抗(靶向PD-L1),匹迪珠单抗(靶向Delta样1(Delta-like 1,DLL1)作为主要结合靶,PD-1作为次要结合靶),沃普利单抗(靶向T细胞的可诱导性共刺激分子(Inducible CO-Stimulator,ICOS)以产生抗肿瘤免疫反应),danvatirsen,西妥利单抗和易普利姆玛(靶向CTLA-4)。
b、抗炎剂
与重组融合多肽、重组多核苷酸或重组融合多肽缀合物组合使用的第二活性剂可以是用于治疗炎症或自身免疫性疾病的蛋白、肽、碳水化合物、核酸、脂质、小分子或其组合。在一些实施方案中,第二活性剂是本领域已知的用于治疗炎症或自身免疫性疾病的试剂。示例性试剂包括镇痛剂、非甾体抗炎药、靶向免疫反应的成分的生物疾病修饰抗风湿药物(DMARD)。一些这样的疗法针对的是由负责组织破坏的浸润淋巴细胞释放过量的炎症介质。一些人认为TNF-α拮抗剂是治疗炎症的最有效的常规生物制剂(Audo,et al.,Cytokine,63(2):81-90(2013))。TNF家族中的其他靶点包括核因子κ-β配体的受体激活剂配体(RANKL)及其受体RANK和骨保护素(OPG)(Lamhamedi-Cherradi,et al.,Natureimmunology4(3):255-60(2003))。
总之,第二活性剂可以是调节免疫细胞的活性剂。活性剂可以减少或抑制促炎免疫细胞的增殖或活性,诱导或增加抗炎免疫细胞(例如调节性T细胞)或其任何组合的增殖或活动。在一些实施方案中,第二活性剂减少一种或多种促炎分子,包括但不限于TNF-α、IL-1α、IFN-γ、IL-2、IL-6、IL-8、IL-1β、TGF-β、IL-17、IL-6、IL-23、IL-22、IL-21、前列腺素和基质金属蛋白酶(MMP)的表达或循环。
2、联合治疗的剂量和治疗方案
治疗方法通常包括治疗疾病或其症状,或实现所需生理变化的方法,包括向动物,例如哺乳动物,尤其是人类,施用有效量的重组融合多肽,重组多核苷酸或重组融合多肽缀合物以治疗增殖性疾病、自身免疫性疾病或纤维化疾病和/或其症状。在一些实施方案中,重组融合多肽、重组多核苷酸或重组融合多肽缀合物与另外的活性剂组合。重组融合多肽、重组多核苷酸或重组融合多肽缀合物和另外的活性剂可以一起施用,如作为同一组合物的一部分,或在同一时间或不同时间单独且独立地施用(即,重组融合多肽、重组多核苷酸或重组融合多肽缀合物和第二活性剂彼此间隔有限的时间段施用)。因此,术语“组合(combination)”或“组合的(combined)”用于指重组融合多肽、重组多核苷酸或重组融合多肽缀合物和第二活性剂的伴随(concomitant)、同时或顺序施用。可以伴随(例如,作为混合物)、单独但同时(例如通过单独的静脉输注管线(intravenous line);一种试剂口服施用,而另一种试剂通过输注或注射等施用)或顺序地(例如,先施用一种试剂后施用第二种试剂)施用组合。
在优选的实施方案中,重组融合多肽、重组多核苷酸或重组融合多肽缀合物与第二活性剂联合施用获得的结果大于重组融合多肽、重组多核苷酸或重组融合多肽缀合物和第二活性剂独自或单独施用(即,通过组合获得的结果大于各组分单独获得的结果的累加)。在一些实施方案中,组合使用的一种或两种试剂的有效量低于单独施用时每种试剂的有效量。在一些实施方案中,当用于联合治疗时,一种或两种试剂的量低于在单独使用时的治疗量。
联合治疗的治疗方案可以包括一次或多次施用。
在一些实施方案中,在首次施用第二活性剂之前施用重组融合多肽、重组多核苷酸或重组融合多肽缀合物。在其他实施方案中,重组融合多肽、重组多核苷酸或重组融合多肽缀合物与首次施用的第二活性剂同时施用。在其他实施方案中,重组融合多肽、重组多核苷酸或重组融合多肽缀合物在首次施用第二活性剂之后施用。
重组融合多肽、重组多核苷酸或重组融合多肽缀合物可在施用第二活性剂之前或之后至少1、2、3、5、10、15、20、24或30小时或至少1、2、3、5、10、15、20、24或30天施用。
试剂的剂量方案或周期可以完全或部分重叠,也可以是顺序的。例如,在一些实施方案中,重组融合多肽、重组多核苷酸或重组融合多肽缀合物的所有这样的施用在施用第二活性剂之前或之后发生。或者,一剂或多剂重组融合多肽、重组多核苷酸或重组融合多肽缀合物的施用可以与第二治疗剂的施用时间暂时错开,以形成全部相同的疗程或不同的疗程,其中施用一剂或多剂重组融合多肽、重组多核苷酸或重组融合多肽缀合物,随后施用一剂或多剂第二活性剂,然后施用一剂或多剂重组融合多肽、重组多核苷酸或重组融合多肽缀合物;或施用一剂或多剂第二活性剂,随后施用一剂或者多剂重组融合多肽、重组多核苷酸或重组融合多肽缀合物,然后施用一剂或多剂第二活性剂;等等,所有这些都根据实施治疗的研究者或临床医生选择或期望的任何计划来选择。
每种试剂的有效量可作为单个单位剂量(例如,作为剂量单位)或在有限时间间隔内施用的低治疗剂量施用。这种单位剂量可以在有限的时间段内,例如至多3天、至多5天、至多7天、至多10天、至多15天、至多20天或至多25天,每天施用。
典型地,对于每种试剂,第一活性剂和第二活性剂以有效量施用。每种试剂的有效量可以为一剂注射约0.1mg/kg患者体重和约100mg/kg患者体重之间。每种试剂的合适量包括在约0.1mg/kg和约500mg/kg之间、在约0.1mg/kg和约250mg/kg之间、在约0.1mg/kg和约100mg/kg之间、在约0.1mmg/kg和约80mg/kg之间、在约0.1mg/kg和约60mg/kg之间,例如在约0.5mg/kg和约20mg/kg之间、或在约1mg/kg和约10mg/kg之间。每种试剂的具体剂量包括约0.1mg/kg、0.2mg/kg、0.3mg/kg、0.4μM、0.5mg/kg、0.6mg/kg、0.7mg/kg、0.8mg/kg、0.9mg/kg、1mg/kg、2mg/kg、3mg/kg、4mg/kg、5mg/kg、6mg/kg、7mg/kg、8mg/kg、9mg/kg、10mg/kg、11mg/kg、12mg/kg、13mg/kg、14mg/kg、15mg/kg、16mg/kg、17mg/kg、18mg/kg、19mg/kg、20mg/kg、21mg/kg、22mg/kg、23mg/kg、24mg/kg、25mg/kg、26mg/kg、27mg/kg、28mg/kg、29mg/kg、30mg/kg、31mg/kg、32mg/kg、33mg/kg、34mg/kg、35mg/kg、36mg/kg、37mg/kg、38mg/kg、39mg/kg、40mg/kg、41mg/kg、42mg/kg、43mg/kg、44mg/kg、45mg/kg、46mg/kg、47mg/kg、48mg/kg、49mg/kg和50mg/kg。
五、试剂盒
还公开了剂量试剂盒。剂量试剂盒可包括例如单独或与第二治疗剂组合的重组融合多肽、重组多核苷酸或重组融合多肽的剂量供应(dosage supply)。当与第二治疗剂组合时,活性剂可以单独供应(例如冻干),或以药物组合物(例如混合物)的形式供应。活性剂可以是单位剂量,也可以是在施用前稀释的储备物(stock)。在一些实施方案中,试剂盒包括药学上可接受的载体的供应。试剂盒还可以包括用于施用活性剂或组合物的装置,例如注射器。试剂盒可包括用于在上述用途中施用化合物的印刷说明书。
通过参考以下非限制性实施例将进一步理解本发明。
实施例
实施例1.具有高表达水平和低免疫原性的miLZ-TRAIL变体。
材料和方法
使用计算机模拟分析确定了与临床应用不兼容的结构元件(图1A,方框区域)。制作了30个表达构建体并测试了表达水平。
将构建体克隆到pSX2质粒(Scarab Genomics)中。将转化的大肠杆菌细胞(菌株SG6620;Scarab Genomics)在28℃下在TB培养基中生长,用0.02-1mM IPTG在约2个吸收度单位(absorbance unit,AU)的细胞密度下诱导蛋白表达(A600)。细胞生长不同的时间段,通过离心收集,并使用
基于可溶性蛋白表达水平的提高,选择了两个前导序列。这两个序列都在N末端没有HisTag的情况下设计,并且在iLZ结构域中进行氨基酸取代以破坏免疫原性表位(图1B和图1C,用箭头表示)。制备总量为400mg的蛋白用于进一步的聚乙二醇化实验。
使用NTA琼脂糖纯化蛋白,并测试其纯度、热力学稳定性和生物活性。裂解含有iLZ-TRAIL的细胞,通过离心制备含有高盐(1M NaCl)的上清液。使用核酸酶(benzonase)消化核酸,并在低咪唑(通常为10mM)存在下将所得细胞裂解物与Zn-NTA树脂(批次(batch)或柱(column))培养,直到树脂的结合能力相对于iLZ-TRAIL结合饱和。在低咪唑的存在下,用高盐缓冲液洗涤作为批次或柱内容物的树脂,用125-250mM咪唑洗脱iLZ-TRAIL。针对特定试验所需的缓冲液透析洗脱的蛋白。
结果
数据表明蛋白制剂的纯度高(超过95%)。与HisTag-iLZ-TRAIL蛋白原型相比,在热转移试验中观察到显著更高的热力学稳定性(图2A)。HisTag-iLZ-TRAIL产生两个峰:第一个峰在55-75℃范围内,第二个峰在75-98℃范围内。miLZ-TRAIL只有一个小的肩部而不是第一个峰,而它的第二个峰比His-tag-iLZ-TRAIL观察到的峰值大。两种前导候选物(lead candidate)在细胞活力生物测试中显示出约5倍高的(about 5-fold higher)生物活性(图2B)。表1示出了测试的多肽的IC50(nM)。
miLZ-TRAIL可以重复冷冻和冻融(测试了至多5个循环),而不会显著丧失其功能活性(细胞试验)或其IEX-HPLC谱(IEX-HPLC profile)不会发生明显变化。
表1.图2B中测试的多肽的IC50(nM)。
实施例2.体内使用的聚乙二醇化前导化合物(如TLY012前导物)的体外生物活性。
材料和方法
除了标准的物理化学特性外,还测试了前导(lead物)的靶向效力和非靶向毒性。最初,通过分别利用静止和激活的原代人肝星状细胞(HSC),在正常(非靶向)和肌成纤维细胞(靶细胞)中测试各种TLY012前导物的选择性凋亡活性。简言之,将静止和培养激活的HSC与TLY012前导物培养,并通过细胞毒性试验来确定细胞活力。
TLY012是rhTRAIL的聚乙二醇化形式,在N末端与人源化卷曲螺旋异亮氨酸“拉链”(miLZ)基因融合。它是一种DR4/DR5受体激动剂,因此已知可诱导人结肠癌细胞COLO 205凋亡,从而抑制细胞增殖。使用CELL TITER-GOLTM(Promega,WI)测量在常规荧光素酶试验系统中的发光。该试验是一种基于ATP存在的定量测试代谢活性细胞数量的均质方法(homogeneous method)。将单一试剂(
试验程序。
生长培养基为RPMI1640,含有10%FBS、谷氨酰胺、青霉素/链霉素溶液。使用12通道移液管,将细胞悬浮液(50μL/孔-2×10
数据分析。
统计分析。
Y=(A–D)/(1+(X/C)
在该方程中,Y(相对发光单位)是X(浓度)的函数,并且四个参数A、B、C(IC50)和D具有特定的解释。渐近线A指响应上限,渐近线D指响应下限,IC50指抑制50%最大信号的抑制浓度,B是与曲线本身的形状和陡度相关的标度参数(scale parameter)。通过将该模型与同一试验中分析的参考标准样品和测试样品进行拟合,当两种浓度产生相同的效果时,相对效力(relative potency,RP)计算如下:
RP=IC
使用BIOTEK软件Gen5 secure计算所有相对效力值以及EC50值和四个参数。
结果
TLY012前导物在静止星状细胞中显示出无非靶向毒性,但仅在激活的星状细胞上显示出强大的效力(图3)。重要的是,TLY012前导物在原代人肝细胞中浓度高达100nM时没有显示出任何非靶向毒性,同时在细胞活力生物测试中显示出亚纳摩尔效力(激活的HSC中为0.142nM,结肠直肠癌细胞COLO-205中为0.01545nm,图3和4)。聚乙二醇化多肽的IC50值如表2所示。
表2.图4中测试的聚乙二醇化多肽的IC50(nM)。
实施例3.miLZ-TRAIL与具有组氨酸-tag-iLZ-TRAIL的组合物相比,在大肠杆菌中具有显著提高的产量
材料和方法
将构建体克隆到pSX2质粒(Scarab Genomics)中。将转化的大肠杆菌细胞(菌株SG6620;Scarab Genomics)在28℃的TB培养基中生长,并用IPTG以约2AU(A600)的细胞密度诱导蛋白表达。细胞在TB培养基中培养过夜,通过离心收集并使用BUGBUSTER裂解。通过SDG-PAGE分析TRAIL含量。
本研究中使用了以下融合多肽:
包含序列SEQ ID NO:3(粗体)和SEQ ID NO:15(斜体)的原始His-tag-TRAIL
包含SEQ ID NO:4(粗体)和SEQ ID NO:15(斜体)的miLZ-TRAIL(克隆#5)
结果
富养培养基(rich media)(TB)中组氨酸-tag-iLZ-TRAIL(Chae,et al.,Molecular cancer therapeutics 9(6):1719-29(2010))的生产效率不超过100mg/L。在基本培养基(minimal media)中产生的组氨酸-tag-iLZ-TRAIL在细胞内不稳定,不能作为冷冻细胞块储存。
miLZ-TRAIL的生产效率约为1g/ml,并且蛋白在冷冻细胞内储存数月。
实施例4.miLZ-TRAIL具有显著增加的溶解度
材料和方法
本研究中使用的融合多肽与实施例3中的那些相同。
结果
组氨酸-tag-iLZ-TRAIL具有非常有限的溶解度。在pH 5.0的溶液中用于聚乙二醇化的His-iLZ-TRAIL的最大浓度不超过100μg/ml(Chae et al.Mol Cancer Ther.9(6):1719–1729(2010))。pH 5.0的聚乙二醇化实验在15mg/ml的miLZ-TRAIL起始浓度下进行。未观察到溶解度问题,最终产品符合所有质量控制(“QC”)要求。
实施例5.与本领域的聚乙二醇化TRAIL相比,聚乙二醇化miLZ-TRAIL显示出显著增加的溶解度和稳定性
材料和方法
本研究中使用的融合多肽与实施例4中的那些相同。
结果
聚乙二醇化miLZ-TRAIL制剂在生理浓度的盐存在下在高达25mg/ml的浓度下是稳定的。当通过IEX-HPLC分析时,该制剂保留了相同的蛋白浓度,没有显示出可检测到的沉淀,并且显示出相同的蛋白模式。稳定性研究表明,配制的聚乙二醇化miLZ-TRAIL(21-22mg/ml)在生物活性和HPLC分析中的表现方面均耐多次冻融循环。
当使用ENZO PROTEOSTAT聚集试剂盒在对蛋白聚集/变性敏感的荧光染料存在下加热蛋白时,观察到所有iLZ-TRAIL和miLZ-TRAIL变体的具有三个容易辨别的阶段的熔解/聚集曲线。
第1阶段(25-55℃)反映了弱的蛋白-染料相互作用,在pH 8.0时比在pH 6.0时更明显。这可能是由于疏水区域暴露的初始差异或电荷介导的结合背景所致。
第2阶段(pH 8.0时为60-80℃,pH 6.0时为55-75℃)和第3阶段(pH8.0时为80-98℃,pH 6.0时为75-98℃)的温度峰值与在同一缓冲液中熔解的所有变体相似。
pH 6.0的第2阶段显示出比pH 8.0的第2阶段低几度的最高信号。
与所有其他变体相比,具有最低预测免疫原性的变体miLZ-TRAIL(1876(K32E,I23V),对应于SEQ ID NO:4的miLZ序列)在pH 6.0下具有较不明显的第1阶段。
结果如图5A-5H所示。
实施例6.与具有HIS-tag的聚乙二醇化TRAIL相比,聚乙二醇化miLZ-TRAIL显示出显著增加的效力(IC50,体外)
材料和方法
本研究中使用的融合多肽与实施例4中的那些相同。
结果
当用COLO 205细胞的细胞试验进行细胞毒性测试时,最终聚乙二醇化TRAIL的生物活性比原型高9倍(9-fold higher)(图4和表2)。
实施例7.灵长类动物中聚乙二醇化miLZ-TRAIL药代动力学(PK)参数
材料和方法
研究了食蟹猴的PK参数。这是一项单剂量、平行组、剂量递增研究,研究对象为5只雄性和5只雌性正常食蟹猴,年龄在34至44个月之间。研究开始时,雄性的体重范围为2.9kg至3.9kg,雌性为2.9kg至3.2kg。表3总结了研究设计。在表3指定的时间点采集血液样本,并准备血清样本用于分析药物水平。
表3:猴子的测试药物分配和血液样本采集计划。
样品分析。
PK参数分析。
结果
静脉(IV)注射10mg/kg剂量后,TLY012血清浓度呈对数线性下降,对于一级终末消除半衰期(first order terminal elimination half-lives)(表4),雌性为30.9小时,雄性为38.0小时。血清浓度似乎以对数线性方式下降,略微偏离桶形(barrel shape),表明存在非线性消除过程(图7A-7D)。
表4.食蟹猴静脉(IV)注射施用后的TLY012药代动力学参数
在SC剂量(2、10或50mg/kg)的TLY012(第2-4组)后,达到最大(Tmax)血清浓度的时间为施用后6至72小时。2mg/kg后的血清浓度以明显的对数线性方式下降,对于一级终末消除半衰期,雄性的为34.7小时,雌性的为42.7小时。10mg/kg组的半衰期值,雄性的为20.7小时,雌性的为30.4小时,50mg/kg组的半衰期值,雄性的为43.9小时,雌性的为46.7小时。给猴子施用SC后,TLY012的绝对生物利用度似乎随着剂量的增加而增加。对雄性施用2mg/kg、10mg/kg和50mg/kg TYL012后,绝对生物利用度(F%)分别为37.4%、75.4%和77.8%。对雌性施用2mg/kg、10mg/kg和50mg/kg TYL012后,F分别为53.7%、79.6%和114%。
表5:对食蟹猴SC施用后TLY012药代动力学参数
在所研究的剂量范围(2-50mg/kg)内,最大血清(Cmax)浓度随剂量成比例增加,并且曲线下总面积(AUC)和暴露(exposure)(AUC)以大得不成比例的方式随剂量增加。剂量增加了25倍,而暴露(exposure)增加了40倍至70倍(表5)。
消除半衰期为20.7小时至46.7小时。相比之下,IV注射到猴子体内的His-iLZ-TRAIL(包含SEQ ID 3和SEQ ID 15)的t
实施例8.在PSC/ASPC-1异种移植物的体内分析中,TLY012诱导细胞凋亡并减少纤维化
材料和方法
将6周龄无胸腺裸小鼠麻醉用于所有程序,将5×10
在肿瘤样品中进行比较定量(Comparative quantitative)RT-PCR(qPCR)以检测纤维化标记物。使用快速SYBR Green Master Mix(Thermo Fisher Scientific)和StepOnePlus实时PCR系统(Thermo Fisher Scientific)对每个样品进行三次qPCR。靶基因的表达水平标准化为18s的表达,并基于比较周期阈值Ct法(comparative cyclethreshold Ct method)(2-ΔΔCt)计算。
用Masson三色染色(Masson’s Trichrome staining)和显微镜检测胶原沉积。
结果
蛋白印迹分析结果显示,与PBS处理的对照组相比,PDGF Rb、DR5、DR4和GRP78的水平显著降低。Cl.PARP-1的水平增加(图8A)。
在PSC/AsPC-1(人原代胰腺星状细胞/胰腺腺癌细胞系)荷瘤(tumor-bearing)小鼠中研究了TLY012的抗肿瘤/成纤维功效。用TLY012处理的组织样品显示出高水平的裂解的PARP-1,这是一种典型的凋亡标记物。此外,通过蛋白印迹评价,PDGF-Rb、DR5和DR4蛋白水平在肿瘤中显著降低。TLY012处理中Acta2、Pdgf-r和Tgf-βmRNA水平降低,PSC-AsPC-1混合肿瘤组织样品中胶原阳性信号高度增加,但通过Masson三色染色,TLY012处理降低了胶原水平。
与对照组相比,当标准化为GAPDH时,TLY012处理组中Acta2和Tgf-β的表达水平显著降低(图8B-8D)。
TLY012处理后,Masson三色染色胶原阳性区域的图像和数字量化显示胶原沉积显著减少。
实施例9.TLY012和索拉非尼联合治疗降低了PSC/ASPC-1异种移植物中的肿瘤尺寸。
材料和方法
将ASPC-1细胞或ASPC-1细胞与PSC CM(PSC条件培养基)一起在体外培养孔中培养24小时,然后进行对照处理(DMSO)或用100ng/mL的TLY012和1μM的索拉非尼处理8小时。培养8小时后,从培养孔中获取显微镜图像。
如实施例8所述制备小鼠异种移植物。肿瘤移植后两周,通过静脉(IV)注射TLY012(10mg/kg,每隔一天)和/或施用索拉非尼(20mg/kg,每天口服)给小鼠持续2周。当肿瘤体积达到1500mm
结果
ASPC-1细胞或ASPC-1细胞与PSC CM培养24小时,随后TLY012和索拉非尼处理8小时的图像显示,与对照处理的ASPC-1相比,用TLY012与索拉非尼处理8小时的ASPC-11细胞显示细胞数量减少。当ASPC-1细胞用PSC CM处理并用TLY012和索拉非尼处理时,ASPC-1的细胞数量减少显著更大。相对于接受对照处理的具有PSC CM的ASPC-1细胞的数量,或相对于用TLY012和索拉非尼处理8小时的ASPC-1细胞,这种显著减少具有统计学意义。结果如图9A所示。
图9B示出了对照和治疗小鼠的肿瘤重量(mg)。联合的效果是协同的。表6总结了图9B的数据。
表6.从用索拉非尼、TLY012或TLY012和索拉非尼的联合治疗的小鼠获得的ASPC-1/PSC异种移植物的肿瘤重量(mg)的量化数据。
这证实了在用来自激活的PSC的条件培养基预处理后,索拉非尼(多激酶抑制剂)对胰腺细胞的致敏显著增加了TLY012诱导的AsPC-1细胞凋亡。此外,用5×10
实施例10.DR5激动剂,TLY012诱导胰腺CAF和aPSC凋亡。
α-SMA+MFB是癌症相关成纤维细胞(CAF)和结缔织生成(desmoplasia)的主要来源之一,已知其在实体瘤中具有强大的免疫抑制特性,有助于肿瘤的发生和发展。基于TRAIL的治疗因其抗肿瘤作用而非抗纤维化功能而备受关注。此前尚未报道TRAIL信号在CAF或α-SMA+MFB的纤维化相关肿瘤微环境(TME)和免疫细胞中的潜在抗纤维化作用。癌症治疗中免疫疗法挑战的主要原因是效应T细胞反应不足和缺乏免疫原性。癌症相关成纤维细胞(CAF)是TME的主要成分,通过干扰细胞毒性T细胞的功能,参与调节先天免疫系统。基质细胞,包括星状细胞、内皮细胞和多种免疫细胞,已知是TME的来源,可用于癌症的生存和进展,具有强大的免疫抑制特性。
材料和方法
人原代胰腺星状细胞(PSC)和星状细胞培养基(SteCM)从ScienCell ResearchLaboratories(Carlsbad,CA)获得。根据制造商的说明,将PSC在聚-L-赖氨酸包被板上,在补充有2%FBS、1%星状细胞生长补充剂和1%青霉素/链霉素溶液的SteCM培养基中培养。胰腺癌相关成纤维细胞(CAF08)和保持培养基(PC00B5)从Vitro Biopharma获得。将100个PSC培养活化7天以获得融合的激活的细胞群,或将2×10
对于免疫印迹,将100个PSC在6孔板上培养活化7天,或将2×10
结果
每个孔的发光被报告为相对发光单位(RLU),数据显示,在TLY012处理后,PSC和CAF08细胞都激活了半胱天冬酶3/7,但对照处理的并非如此(图10)。
免疫印迹测试在TLY012处理的PSC和CAF08细胞中检测到Cl.PARP-1。对照处理的PSC和CAF08细胞中未检测到Cl.PARP-1。两种处理下的CAF08细胞的SMA含量显著高于两种处理下的PSC。
这证实了与激活的原代人胰腺星状细胞相比,在源自胰腺癌患者的原代癌症相关的成纤维细胞中TLY012诱导凋亡,如通过半胱天冬酶3/7活性试验和裂解的PARP-1的蛋白印迹所评价的。该研究还发现,与激活的星状细胞相比较,胰腺CAF高表达α-SMA蛋白。
实施例11.TLY012在诱导人胰腺癌相关的成纤维细胞凋亡方面优于其他癌症疗法
材料和方法
胰腺癌相关的成纤维细胞(CAF08)和保持培养基(PC00B5)从Vitro Biopharma获得,并保持在胰腺星形CAF保持培养基中(Vitro Biopharma,Cat.No.PC00B5)。如文所示,将约2×10
培养后,在30分钟平衡期平衡至室温后,将来自半胱天冬酶3/7Glo试验试剂盒(Promega,Madison USA)的50uL半胱天冬酶3/7底物/裂解缓冲液添加到每个孔中,并培养30分钟。在平板阅读器(Bio-Tek Instruments Inc)上测量每个样品的发光,参数为1分钟延迟时间和0.5秒/孔读取时间(n=3)。
对于蛋白印迹,将2×10
结果
图11示出了不同处理状况下以发光倍数增加(倍数)报告的发光结果。TLY012在激活人胰腺癌相关成纤维细胞中的半胱天冬酶3/7方面优于其他癌症疗法。
数据显示,在包括吉西他滨、阿霉素、顺铂、5-FU和伊立替康的测试的细胞毒剂中,只有TLY012诱导细胞凋亡(图11)。重要的是,如通过蛋白印迹评价的,通过TLY012处理显著降低了胰腺CAF中α-SMA的蛋白水平。
实施例12.TLY012诱导人结肠癌相关成纤维细胞凋亡,并且在诱导凋亡方面优于其他癌症治疗。
材料和方法
人结肠癌成纤维细胞HC-6231从Cell Biologics(目录号HC-6231)获得并保持在成纤维细胞培养基(Cell Biologics,目录号M2267)中。将约2×10
(a)在0ng/ml、10ng/ml、30ng/ml、100ng/ml或1000ng/ml的剂量下,以剂量依赖性方式与TLY012培养3小时;或
b)用TLY012或细胞毒剂培养,如下文所示:30ng/ml TLY012培养3小时,50μM吉西他滨培养24小时,10μM阿霉素培养24个小时,50μM顺铂培养24小时,25μg/ml 5-FU培养24小时,或10μM伊立替康培养24小时。
然后,在30分钟的平衡期平衡至室温后,向每个孔中加入50uL半胱天冬酶3/7底物/裂解缓冲液,并培养30分钟。在平板阅读器(Bio-Tek Instruments Inc)上测量每个样品的发光,参数为1分钟延迟时间和0.5秒/孔读取时间(well-read time)(n=3)。
结果
图12A示出了用不同剂量TLY012处理3小时的结肠癌成纤维细胞中激活的半胱天冬酶3/7的相对发光单位(RLU)的发光结果。图12B示出了用不同的细胞毒剂在指定的不同的剂量和时间下,处理的结肠癌成纤维细胞中半胱天冬酶3/7的激活的成倍增加(倍数,Fold)。
该研究证实了TLY012诱导源自结肠癌患者的原代癌症相关成纤维细胞的凋亡,如通过半胱天冬酶3/7活性试验所评价的(图12A)。TLY012在包括吉西他滨、阿霉素、顺铂、5-FU和伊立替康的测试的细胞毒剂中诱导了显著更多的细胞凋亡(图12B)。
实施例13.CAF高度表达成纤维标记物和PD-L1/2。
T细胞上的程序性细胞死亡蛋白1(PD-1)和肿瘤细胞上的PD-1配体PD-L1或PD-L2是肿瘤细胞逃避宿主免疫的重要因素。PD-1/PD-L1通路控制肿瘤微环境内免疫耐受的诱导和保持。PD-1及其配体PD-L1或PD-L2的活性负责癌症中的T细胞激活、增殖和细胞毒性分泌,以退化(degenerating)抗肿瘤免疫反应(Han et al.,Am J Cancer Res;10(3):727-742(2020))。通过消除CAF,TLY012打开了易受宿主抗肿瘤免疫反应影响的肿瘤微环境。系统性DR5激动剂(TLY012)与已建立的新兴免疫疗法(例如,检查点抑制剂)相结合,可以使药物和免疫细胞进入肿瘤,同时恢复肿瘤微环境中的免疫反应,从而在肝细胞癌(HCC)、结肠直肠癌或胰腺导管腺癌(PDAC)中显示出协同作用。
材料和方法
根据制造商的说明,使用Purelink RNA试剂盒(Thermo Fisher Scientific,Waltham,MA)提取培养细胞的总RNA。使用NanoDrop2000(Thermo Fisher Scientific)分光光度法测量RNA浓度。使用高容量cDNA逆转录系统(Reverse Transcription System,Thermo Fisher Scientific),将1-2μg总RNA逆转录为cDNA。使用快速SYBR Green MasterMix(Thermo Fisher Scientific)和StepOnePlus实时PCR系统(StepOnePlus Real-TimePCR System,Thermo Fisher Scientific)对每个样品进行三次比较定量RT-PCR(qPCR)。靶基因(target Gene)的表达水平标准化为18s的表达,并基于比较周期阈值Ct法(comparative cycle threshold Ct method)(2-ΔΔCt)计算。引物的序列如表7所示。
表7.用于qPCR的引物序列。
结果
图13A-13C示出了DR4或DR5(图13A)、PD-L1或PD-L2(图13B)或Acta2、TGF-β或Col1a2(图13C)的mRNA的相对表达。图13B和13C示出了CAF高度表达成纤维标记物和PD-L1/2。
该研究示出,与正常细胞、静止PSC或Conlon成纤维细胞相比,胰腺CAF和结肠CAF中Dr4、Dr5、Acta2、Tgf-b、Col1a2、PD-L1和PD-L2 mRNA的表达水平。胰腺CAF和结肠CAF均显示高水平的PD-L1或PD-L2 mRNA。与正常细胞相比,结肠CAF示出高水平Dr4/5,胰腺CAF显示显著高水平的Acta2、Tgf-b、Col1a2 mRNA成纤维标记物。总之,这些数据表明,去除纤维化是治疗癌症的有效策略。
实施例14.TLY012降低小鼠KPC细胞原位异种移植物中的纤维化水平和肿瘤体积。
材料和方法
B6.129小鼠胰腺接种KPC的方法
为了产生实体瘤,将10
对于胰腺中的原位异种移植肿瘤,通过左侧腹切口进行剖腹手术以暴露胰头,将供体肿瘤块插入受体B6.129小鼠(n=7/组)的胰腺中,并用5–0可吸收缝合线将切口闭合为两层。肿瘤移植后两周,小鼠通过腹腔途径(10mg/kg,每隔一天)注射TLY012和/或抗PD-L1(B7-H1,抗小鼠PD-L1,2.5mg/kg,每周两次),持续2周。移植动物每周成像一次,持续5周。在腹腔施用D-荧光素(150mg/kg)(GOLDBIO,St.Louis,MO,USA)后10-15分钟,使用IVIS获取生物发光图像。
对于肿瘤体积研究,在胰腺中产生原位异种移植肿瘤。通过左侧腹切口进行剖腹手术以暴露胰头,将5×10
双重免疫荧光染色
石蜡切片的KPC肿瘤样本用α-SMA和CD4或CD8进行免疫荧光染色(IF)。组织脱蜡(deparaffinized)、水合,并在柠檬酸盐缓冲液(Thermo Fisher Scientific)中通过微波加热以用于提取抗原(antigen retrieval)。洗涤载玻片,用封闭溶液(3%的正常马血清,Vectastain ABC System,Vector Labs,Burlingame,CA)处理,应用小鼠抗α-SMA抗体,以及一级抗体:兔抗CD4抗体(Abcam,ab183685)或兔抗CD8抗体(Abcam,ab217344)。将组织在4℃下培养过夜,洗涤并应用与Alexa fluor 488偶联的抗兔IgG和与Alexa fluor 633偶联的小鼠IgG(Thermo Fisher Scientific),并在室温下孵育。洗涤载玻片后,用带有DAPI的荧光安装培养基(Fluorescence Mounting Medium)安装样品,并在Axiovert显微镜(CarlZeiss Microscopy,LLC.Thornwood,NY)下捕获。
组织学研究和免疫组织化学
切除的肿瘤立即固定在10%缓冲福尔马林中,包埋在石蜡中,并以4μm厚度切割。然后对切片进行Masson三色染色或天狼星红染色,以确定胶原沉积。染色组织在光学显微镜下成像(Nikon Eclipse E600与Nikon DS-Fi2相机连接,Nikon USA)。从单个小鼠中随机选择10张染色的胰腺组织照片,并使用Image J软件(NIH,Bethesda,MD)量化阳性染色区域。
结果
TLY012降低了小鼠KPC细胞原位异种移植物中的纤维化水平和肿瘤体积(图14)。数据显示,与盐水处理组相比,仅有TLY012减少了肿瘤体积。异种移植肿瘤的组织样本显示出高水平的胶原沉积和α-SMA阳性区域,但TLY012处理降低了免疫组织化学评价的胶原水平。
TLY012的处理促进了小鼠KPC细胞原位异种移植物中细胞毒性T细胞向肿瘤部位的迁移。在肿瘤组织中检测到CD4+和CD8+细胞。该数据表明,与生理盐水处理样本相比,肿瘤组织TLY012样本中的细胞毒性T细胞(包括CD8和CD4细胞)与α-SMA细胞共定位。这种策略减少了PDAC肿瘤的纤维化并破坏了间质屏障(stromal barrier)。最后,TLY012增强了细胞毒性T细胞向肿瘤部位的浸润。
TLY012和抗PD-L1的联合治疗降低了肿瘤中的荧光素酶活性,减少了肿瘤体积,并且提高了小鼠KPC细胞原位异种移植物小鼠的存活率(图15A-15C)。结果也示出在表8-10中。
表8.从具有小鼠KPC细胞原位异种移植物的小鼠肿瘤中获得的、用PBS、抗PD-L1抗体、TLY012或用抗PD-L1抗体和TLY012的组合处理的随时间(天)的生物发光活性(总计数)。
表9.从具有小鼠KPC细胞的原位异种移植物的小鼠获得的,并用PBS、抗PD-L1抗体、TLY012或抗PD-L1抗体和TLY012的联合治疗的肿瘤的平均肿瘤体积(mm
表10.具有小鼠KPC细胞原位异种移植物,并用PBS、抗PD-L1抗体、TLY012或抗PD-L1抗体和TLY012的联合治疗的小鼠的随天数的存活率。
通过
TLY012和抗PD-L1的联合降低了胶原沉积的水平,如从胶原阳性区域的天狼星红染色的捕获图像所确定的(图16)。这证实了异种移植肿瘤的组织样品在对照小鼠中显示出高水平的胶原沉积,但与其他组相比,PD-L1和TLY012的联合治疗减少了胶原阳性面积(天狼星红)(图16)。
实施例15.肝CAF高度表达成纤维标记物
材料和方法
在DMEM中培养肝CAF(BioIVT,DT01046P1)细胞。根据制造商的说明,用PURELINKRNA试剂盒(Thermo Fisher Scientific,Waltham,MA)提取培养细胞的总RNA。使用NanoDrop 2000(Thermo Fisher Scientific)分光光度法测量RNA浓度。使用高容量cDNA逆转录系统(Thermo Fisher Scientific)将1-2μg总RNA逆转录为cDNA。使用快速SYBR GreenMaster Mix(Thermo Fisher Scientific)和Quantstudio 5实时PCR系统(Quantstudio5Real-Time PCR System)(Thermo Fisher Scientific)对每个样品进行三次比较定量RT-PCR(qPCR)。靶基因的表达水平标准化为GAPDH的表达,并基于比较周期阈值Ct法(2-ΔΔCt)计算。
结果
已证实了与静止HSC细胞相比,激活的肝星状细胞和原代肝癌相关成纤维细胞中Acta2、Col1a2、Col3a1、PDGFR和CTGF的mRNA水平(图17)。数据表明,靶向aHSC或肝CAF以消除纤维化是通过安全地消除肿瘤微环境中的原始细胞的HCC治疗策略之一。
实施例16.用肝CAF条件培养基(CM)以TLY012处理的HCC细胞中凋亡水平的增加
材料和方法
将2×10
结果
已经证实,如通过半胱天冬酶3/7活性试验所评价的,用来自原代癌症相关的成纤维细胞的条件培养基(CM)处理的Huh-7和Hep-G2的高度TRAIL抗性HCC细胞中TLY012诱导了凋亡(图18A和图18B)。
Di Modugno et al.,Journal ofExperimental and Clinical CancerResearch,38(117)(2019)中讨论了当前关于肿瘤微环境的知识,集中于T细胞、癌症相关成纤维细胞和胞外基质。与CAF和免疫细胞相互作用的TRAIL信号在纤维化相关的肿瘤微环境中发挥潜在的抗纤维化作用。
激活的PSC是癌症相关的成纤维细胞(CAF)和结缔织生成的主要来源,已知其有助于肿瘤的发生和发展,具有强大的免疫抑制特性。重要的是,PDAC具有过度的肿瘤微环境,对常规抗癌药物具有高度耐药性,因为药物递送由于穿透(penetration)而变困难。
TLY012与抗PD-L1免疫疗法的联合显示出最佳结果,可能是包括PD-1、PD-L1、CTLA-4、IDO在内的主要治疗方法。阻断(blockade)免疫检查点是迄今为止激活治疗性抗肿瘤免疫疗法最有希望的方法。程序性细胞死亡-1(PD-1)是T淋巴细胞的一个重要免疫检查点。然而,来自肿瘤细胞的PD-L1与PD-1结合,通过降低T细胞活性和增殖来抑制T淋巴细胞的抗肿瘤能力,这被称为“不要吃我的信号(don’t eat me signal)”。免疫疗法预后不佳的主要原因之一是结缔织生成,即纤维化组织过度增殖。促结缔组织增生反应诱导促进肿瘤细胞增殖和耐药性的生理和生物信号。
这里示出,TLY012具有抗纤维化功能,并靶向具有癌症相关的成纤维细胞的纤维化肿瘤,如果不进行治疗,由于纤维化细胞屏障,这些成纤维细胞对免疫疗法具有抵抗力。
除非另有定义,否则本文使用的所有技术和科学术语具有与所公开的发明所属领域的技术人员通常理解的相同含义。本文引用的出版物及其引用的材料通过引用被特别并入。
本领域技术人员将认识到,或能够仅使用常规实验来确定本文所描述的本发明的具体实施方案的许多等效物。这些等效物旨在被以下权利要求所涵盖。
<110> 赛力纤维症相关疾病医药公司(THERALY FIBROSIS, INC.)
<120> 具有降低的免疫原性的TRAIL组合物
<130> KHP222111831.1
<150> 63/035,472
<151> 2020-06-05
<150> 17/223,283
<151> 2021-04-06
<160> 56
<170> PatentIn 版本3.5
<210> 1
<211> 30
<212> PRT
<213> 人工序列
<220>
<223> 合成肽
<400> 1
Lys Gln Ile Glu Asp Lys Ile Glu Glu Ile Leu Ser Lys Ile Tyr His
1 5 1015
Ile Glu Asn Glu Ile Ala Arg Ile Lys Lys Leu Ile Gly Glu
202530
<210> 2
<211> 34
<212> PRT
<213> 人工序列
<220>
<223> 合成肽
<400> 2
Gly Arg Met Lys Gln Ile Glu Asp Lys Ile Glu Glu Ile Leu Ser Lys
1 5 1015
Ile Tyr His Ile Glu Asn Glu Ile Ala Arg Ile Lys Lys Leu Ile Gly
202530
Glu Arg
<210> 3
<211> 39
<212> PRT
<213> 人工序列
<220>
<223> 合成肽
<400> 3
Pro Gly Met Cys Gly Gly Lys Gln Ile Glu Asp Lys Ile Glu Glu Ile
1 5 1015
Leu Ser Lys Ile Tyr His Ile Glu Asn Glu Ile Ala Arg Ile Lys Lys
202530
Leu Ile Gly Glu Asp Gly Val
35
<210> 4
<211> 30
<212> PRT
<213> 人工序列
<220>
<223> 合成肽
<400> 4
Lys Gln Ile Glu Asp Lys Ile Glu Glu Ile Leu Ser Lys Ile Tyr His
1 5 1015
Val Glu Asn Glu Ile Ala Arg Ile Lys Glu Leu Ile Gly Glu
202530
<210> 5
<211> 30
<212> PRT
<213> 人工序列
<220>
<223> 合成肽
<400> 5
Lys Gln Ile Glu Asp Lys Ile Glu Glu Ile Leu Ser Lys Ile Tyr His
1 5 1015
Val Glu Asn Glu Ile Ala Arg Ile Lys Lys Leu Ile Gly Glu
202530
<210> 6
<211> 30
<212> PRT
<213> 人工序列
<220>
<223> 合成肽
<400> 6
Lys Gln Ile Glu Asp Lys Ile Glu Glu Ile Leu Ser Lys Ile Tyr His
1 5 1015
Ile Glu Asn Glu Ile Ala Arg Ile Lys Glu Leu Ile Gly Glu
202530
<210> 7
<211> 30
<212> PRT
<213> 人工序列
<220>
<223> 合成肽
<400> 7
Lys Gln Ile Glu Asp Lys Ile Glu Glu Ile Leu Ser Lys Ile Tyr His
1 5 1015
Ile Glu Asn Glu Ile Ala Arg Ile Lys Gln Leu Ile Gly Glu
202530
<210> 8
<211> 30
<212> PRT
<213> 人工序列
<220>
<223> 合成肽
<400> 8
Lys Gln Ile Glu Asp Lys Ile Glu Glu Ile Leu Ser Lys Val Tyr His
1 5 1015
Ile Glu Asn Glu Ile Ala Arg Ile Lys Glu Leu Ile Gly Glu
202530
<210> 9
<211> 281
<212> PRT
<213> 智人(Homo sapiens)
<400> 9
Met Ala Met Met Glu Val Gln Gly Gly Pro Ser Leu Gly Gln Thr Cys
1 5 1015
Val Leu Ile Val Ile Phe Thr Val Leu Leu Gln Ser Leu Cys Val Ala
202530
Val Thr Tyr Val Tyr Phe Thr Asn Glu Leu Lys Gln Met Gln Asp Lys
354045
Tyr Ser Lys Ser Gly Ile Ala Cys Phe Leu Lys Glu Asp Asp Ser Tyr
505560
Trp Asp Pro Asn Asp Glu Glu Ser Met Asn Ser Pro Cys Trp Gln Val
65707580
Lys Trp Gln Leu Arg Gln Leu Val Arg Lys Met Ile Leu Arg Thr Ser
859095
Glu Glu Thr Ile Ser Thr Val Gln Glu Lys Gln Gln Asn Ile Ser Pro
100 105 110
Leu Val Arg Glu Arg Gly Pro Gln Arg Val Ala Ala His Ile Thr Gly
115 120 125
Thr Arg Gly Arg Ser Asn Thr Leu Ser Ser Pro Asn Ser Lys Asn Glu
130 135 140
Lys Ala Leu Gly Arg Lys Ile Asn Ser Trp Glu Ser Ser Arg Ser Gly
145 150 155 160
His Ser Phe Leu Ser Asn Leu His Leu Arg Asn Gly Glu Leu Val Ile
165 170 175
His Glu Lys Gly Phe Tyr Tyr Ile Tyr Ser Gln Thr Tyr Phe Arg Phe
180 185 190
Gln Glu Glu Ile Lys Glu Asn Thr Lys Asn Asp Lys Gln Met Val Gln
195 200 205
Tyr Ile Tyr Lys Tyr Thr Ser Tyr Pro Asp Pro Ile Leu Leu Met Lys
210 215 220
Ser Ala Arg Asn Ser Cys Trp Ser Lys Asp Ala Glu Tyr Gly Leu Tyr
225 230 235 240
Ser Ile Tyr Gln Gly Gly Ile Phe Glu Leu Lys Glu Asn Asp Arg Ile
245 250 255
Phe Val Ser Val Thr Asn Glu His Leu Ile Asp Met Asp His Glu Ala
260 265 270
Ser Phe Phe Gly Ala Phe Leu Val Gly
275 280
<210> 10
<211> 243
<212> PRT
<213> 智人(Homo sapiens)
<400> 10
Thr Asn Glu Leu Lys Gln Met Gln Asp Lys Tyr Ser Lys Ser Gly Ile
1 5 1015
Ala Cys Phe Leu Lys Glu Asp Asp Ser Tyr Trp Asp Pro Asn Asp Glu
202530
Glu Ser Met Asn Ser Pro Cys Trp Gln Val Lys Trp Gln Leu Arg Gln
354045
Leu Val Arg Lys Met Ile Leu Arg Thr Ser Glu Glu Thr Ile Ser Thr
505560
Val Gln Glu Lys Gln Gln Asn Ile Ser Pro Leu Val Arg Glu Arg Gly
65707580
Pro Gln Arg Val Ala Ala His Ile Thr Gly Thr Arg Gly Arg Ser Asn
859095
Thr Leu Ser Ser Pro Asn Ser Lys Asn Glu Lys Ala Leu Gly Arg Lys
100 105 110
Ile Asn Ser Trp Glu Ser Ser Arg Ser Gly His Ser Phe Leu Ser Asn
115 120 125
Leu His Leu Arg Asn Gly Glu Leu Val Ile His Glu Lys Gly Phe Tyr
130 135 140
Tyr Ile Tyr Ser Gln Thr Tyr Phe Arg Phe Gln Glu Glu Ile Lys Glu
145 150 155 160
Asn Thr Lys Asn Asp Lys Gln Met Val Gln Tyr Ile Tyr Lys Tyr Thr
165 170 175
Ser Tyr Pro Asp Pro Ile Leu Leu Met Lys Ser Ala Arg Asn Ser Cys
180 185 190
Trp Ser Lys Asp Ala Glu Tyr Gly Leu Tyr Ser Ile Tyr Gln Gly Gly
195 200 205
Ile Phe Glu Leu Lys Glu Asn Asp Arg Ile Phe Val Ser Val Thr Asn
210 215 220
Glu His Leu Ile Asp Met Asp His Glu Ala Ser Phe Phe Gly Ala Phe
225 230 235 240
Leu Val Gly
<210> 11
<211> 241
<212> PRT
<213> 智人(Homo sapiens)
<400> 11
Glu Leu Lys Gln Met Gln Asp Lys Tyr Ser Lys Ser Gly Ile Ala Cys
1 5 1015
Phe Leu Lys Glu Asp Asp Ser Tyr Trp Asp Pro Asn Asp Glu Glu Ser
202530
Met Asn Ser Pro Cys Trp Gln Val Lys Trp Gln Leu Arg Gln Leu Val
354045
Arg Lys Met Ile Leu Arg Thr Ser Glu Glu Thr Ile Ser Thr Val Gln
505560
Glu Lys Gln Gln Asn Ile Ser Pro Leu Val Arg Glu Arg Gly Pro Gln
65707580
Arg Val Ala Ala His Ile Thr Gly Thr Arg Gly Arg Ser Asn Thr Leu
859095
Ser Ser Pro Asn Ser Lys Asn Glu Lys Ala Leu Gly Arg Lys Ile Asn
100 105 110
Ser Trp Glu Ser Ser Arg Ser Gly His Ser Phe Leu Ser Asn Leu His
115 120 125
Leu Arg Asn Gly Glu Leu Val Ile His Glu Lys Gly Phe Tyr Tyr Ile
130 135 140
Tyr Ser Gln Thr Tyr Phe Arg Phe Gln Glu Glu Ile Lys Glu Asn Thr
145 150 155 160
Lys Asn Asp Lys Gln Met Val Gln Tyr Ile Tyr Lys Tyr Thr Ser Tyr
165 170 175
Pro Asp Pro Ile Leu Leu Met Lys Ser Ala Arg Asn Ser Cys Trp Ser
180 185 190
Lys Asp Ala Glu Tyr Gly Leu Tyr Ser Ile Tyr Gln Gly Gly Ile Phe
195 200 205
Glu Leu Lys Glu Asn Asp Arg Ile Phe Val Ser Val Thr Asn Glu His
210 215 220
Leu Ile Asp Met Asp His Glu Ala Ser Phe Phe Gly Ala Phe Leu Val
225 230 235 240
Gly
<210> 12
<211> 191
<212> PRT
<213> 智人(Homo sapiens)
<400> 12
Met Ile Leu Arg Thr Ser Glu Glu Thr Ile Ser Thr Val Gln Glu Lys
1 5 1015
Gln Gln Asn Ile Ser Pro Leu Val Arg Glu Arg Gly Pro Gln Arg Val
202530
Ala Ala His Ile Thr Gly Thr Arg Gly Arg Ser Asn Thr Leu Ser Ser
354045
Pro Asn Ser Lys Asn Glu Lys Ala Leu Gly Arg Lys Ile Asn Ser Trp
505560
Glu Ser Ser Arg Ser Gly His Ser Phe Leu Ser Asn Leu His Leu Arg
65707580
Asn Gly Glu Leu Val Ile His Glu Lys Gly Phe Tyr Tyr Ile Tyr Ser
859095
Gln Thr Tyr Phe Arg Phe Gln Glu Glu Ile Lys Glu Asn Thr Lys Asn
100 105 110
Asp Lys Gln Met Val Gln Tyr Ile Tyr Lys Tyr Thr Ser Tyr Pro Asp
115 120 125
Pro Ile Leu Leu Met Lys Ser Ala Arg Asn Ser Cys Trp Ser Lys Asp
130 135 140
Ala Glu Tyr Gly Leu Tyr Ser Ile Tyr Gln Gly Gly Ile Phe Glu Leu
145 150 155 160
Lys Glu Asn Asp Arg Ile Phe Val Ser Val Thr Asn Glu His Leu Ile
165 170 175
Asp Met Asp His Glu Ala Ser Phe Phe Gly Ala Phe Leu Val Gly
180 185 190
<210> 13
<211> 190
<212> PRT
<213> 智人(Homo sapiens)
<400> 13
Ile Leu Arg Thr Ser Glu Glu Thr Ile Ser Thr Val Gln Glu Lys Gln
1 5 1015
Gln Asn Ile Ser Pro Leu Val Arg Glu Arg Gly Pro Gln Arg Val Ala
202530
Ala His Ile Thr Gly Thr Arg Gly Arg Ser Asn Thr Leu Ser Ser Pro
354045
Asn Ser Lys Asn Glu Lys Ala Leu Gly Arg Lys Ile Asn Ser Trp Glu
505560
Ser Ser Arg Ser Gly His Ser Phe Leu Ser Asn Leu His Leu Arg Asn
65707580
Gly Glu Leu Val Ile His Glu Lys Gly Phe Tyr Tyr Ile Tyr Ser Gln
859095
Thr Tyr Phe Arg Phe Gln Glu Glu Ile Lys Glu Asn Thr Lys Asn Asp
100 105 110
Lys Gln Met Val Gln Tyr Ile Tyr Lys Tyr Thr Ser Tyr Pro Asp Pro
115 120 125
Ile Leu Leu Met Lys Ser Ala Arg Asn Ser Cys Trp Ser Lys Asp Ala
130 135 140
Glu Tyr Gly Leu Tyr Ser Ile Tyr Gln Gly Gly Ile Phe Glu Leu Lys
145 150 155 160
Glu Asn Asp Arg Ile Phe Val Ser Val Thr Asn Glu His Leu Ile Asp
165 170 175
Met Asp His Glu Ala Ser Phe Phe Gly Ala Phe Leu Val Gly
180 185 190
<210> 14
<211> 187
<212> PRT
<213> 智人(Homo sapiens)
<400> 14
Thr Ser Glu Glu Thr Ile Ser Thr Val Gln Glu Lys Gln Gln Asn Ile
1 5 1015
Ser Pro Leu Val Arg Glu Arg Gly Pro Gln Arg Val Ala Ala His Ile
202530
Thr Gly Thr Arg Gly Arg Ser Asn Thr Leu Ser Ser Pro Asn Ser Lys
354045
Asn Glu Lys Ala Leu Gly Arg Lys Ile Asn Ser Trp Glu Ser Ser Arg
505560
Ser Gly His Ser Phe Leu Ser Asn Leu His Leu Arg Asn Gly Glu Leu
65707580
Val Ile His Glu Lys Gly Phe Tyr Tyr Ile Tyr Ser Gln Thr Tyr Phe
859095
Arg Phe Gln Glu Glu Ile Lys Glu Asn Thr Lys Asn Asp Lys Gln Met
100 105 110
Val Gln Tyr Ile Tyr Lys Tyr Thr Ser Tyr Pro Asp Pro Ile Leu Leu
115 120 125
Met Lys Ser Ala Arg Asn Ser Cys Trp Ser Lys Asp Ala Glu Tyr Gly
130 135 140
Leu Tyr Ser Ile Tyr Gln Gly Gly Ile Phe Glu Leu Lys Glu Asn Asp
145 150 155 160
Arg Ile Phe Val Ser Val Thr Asn Glu His Leu Ile Asp Met Asp His
165 170 175
Glu Ala Ser Phe Phe Gly Ala Phe Leu Val Gly
180 185
<210> 15
<211> 168
<212> PRT
<213> 智人(Homo sapiens)
<400> 15
Val Arg Glu Arg Gly Pro Gln Arg Val Ala Ala His Ile Thr Gly Thr
1 5 1015
Arg Gly Arg Ser Asn Thr Leu Ser Ser Pro Asn Ser Lys Asn Glu Lys
202530
Ala Leu Gly Arg Lys Ile Asn Ser Trp Glu Ser Ser Arg Ser Gly His
354045
Ser Phe Leu Ser Asn Leu His Leu Arg Asn Gly Glu Leu Val Ile His
505560
Glu Lys Gly Phe Tyr Tyr Ile Tyr Ser Gln Thr Tyr Phe Arg Phe Gln
65707580
Glu Glu Ile Lys Glu Asn Thr Lys Asn Asp Lys Gln Met Val Gln Tyr
859095
Ile Tyr Lys Tyr Thr Ser Tyr Pro Asp Pro Ile Leu Leu Met Lys Ser
100 105 110
Ala Arg Asn Ser Cys Trp Ser Lys Asp Ala Glu Tyr Gly Leu Tyr Ser
115 120 125
Ile Tyr Gln Gly Gly Ile Phe Glu Leu Lys Glu Asn Asp Arg Ile Phe
130 135 140
Val Ser Val Thr Asn Glu His Leu Ile Asp Met Asp His Glu Ala Ser
145 150 155 160
Phe Phe Gly Ala Phe Leu Val Gly
165
<210> 16
<211> 150
<212> PRT
<213> 智人(Homo sapiens)
<400> 16
Arg Ser Asn Thr Leu Ser Ser Pro Asn Ser Lys Asn Glu Lys Ala Leu
1 5 1015
Gly Arg Lys Ile Asn Ser Trp Glu Ser Ser Arg Ser Gly His Ser Phe
202530
Leu Ser Asn Leu His Leu Arg Asn Gly Glu Leu Val Ile His Glu Lys
354045
Gly Phe Tyr Tyr Ile Tyr Ser Gln Thr Tyr Phe Arg Phe Gln Glu Glu
505560
Ile Lys Glu Asn Thr Lys Asn Asp Lys Gln Met Val Gln Tyr Ile Tyr
65707580
Lys Tyr Thr Ser Tyr Pro Asp Pro Ile Leu Leu Met Lys Ser Ala Arg
859095
Asn Ser Cys Trp Ser Lys Asp Ala Glu Tyr Gly Leu Tyr Ser Ile Tyr
100 105 110
Gln Gly Gly Ile Phe Glu Leu Lys Glu Asn Asp Arg Ile Phe Val Ser
115 120 125
Val Thr Asn Glu His Leu Ile Asp Met Asp His Glu Ala Ser Phe Phe
130 135 140
Gly Ala Phe Leu Val Gly
145 150
<210> 17
<211> 281
<212> PRT
<213> 人工序列
<220>
<223> 合成肽
<400> 17
Met Ala Met Met Glu Val Gln Gly Gly Pro Ser Leu Gly Gln Thr Cys
1 5 1015
Val Leu Ile Val Ile Phe Thr Val Leu Leu Gln Ser Leu Cys Val Ala
202530
Val Thr Tyr Val Tyr Phe Thr Asn Glu Leu Lys Gln Met Gln Asp Lys
354045
Tyr Ser Lys Ser Gly Ile Ala Cys Phe Leu Lys Glu Asp Asp Ser Tyr
505560
Trp Asp Pro Asn Asp Glu Glu Ser Met Asn Ser Pro Cys Trp Gln Val
65707580
Lys Trp Gln Leu Arg Gln Leu Val Arg Lys Met Ile Leu Arg Thr Ser
859095
Glu Glu Thr Ile Ser Thr Val Gln Glu Lys Gln Gln Asn Ile Ser Pro
100 105 110
Leu Val Arg Glu Arg Gly Pro Gln Arg Val Ala Ala His Ile Thr Gly
115 120 125
Thr Arg Gly Arg Ser Asn Thr Leu Ser Ser Pro Asn Ser Lys Asn Glu
130 135 140
Lys Ala Leu Gly Arg Lys Ile Asn Ser Trp Glu Ser Ser Arg Ser Gly
145 150 155 160
His Ser Phe Leu Ser Asn Leu His Leu Arg Asn Gly Glu Leu Val Ile
165 170 175
His Glu Lys Gly Phe Tyr Tyr Ile Tyr Ser Gln Thr Tyr Phe Arg Phe
180 185 190
Gln Glu Glu Ile Lys Glu Asn Thr Lys Asn Asp Lys Gln Met Val Gln
195 200 205
Tyr Ile Tyr Lys Tyr Thr Ser Tyr Pro His Pro Ile Leu Leu Met Lys
210 215 220
Ser Ala Arg Asn Ser Cys Trp Ser Lys Asp Ala Glu Tyr Gly Leu Tyr
225 230 235 240
Ser Ile Tyr Gln Gly Gly Ile Phe Glu Leu Lys Glu Asn Asp Arg Ile
245 250 255
Phe Val Ser Val Thr Asn Glu His Leu Ile Asp Met Asp His Glu Ala
260 265 270
Ser Phe Phe Gly Ala Phe Leu Val Gly
275 280
<210> 18
<211> 281
<212> PRT
<213> 人工序列
<220>
<223> 合成肽
<400> 18
Met Ala Met Met Glu Val Gln Gly Gly Pro Ser Leu Gly Gln Thr Cys
1 5 1015
Val Leu Ile Val Ile Phe Thr Val Leu Leu Gln Ser Leu Cys Val Ala
202530
Val Thr Tyr Val Tyr Phe Thr Asn Glu Leu Lys Gln Met Gln Asp Lys
354045
Tyr Ser Lys Ser Gly Ile Ala Cys Phe Leu Lys Glu Asp Asp Ser Tyr
505560
Trp Asp Pro Asn Asp Glu Glu Ser Met Asn Ser Pro Cys Trp Gln Val
65707580
Lys Trp Gln Leu Arg Gln Leu Val Arg Lys Met Ile Leu Arg Thr Ser
859095
Glu Glu Thr Ile Ser Thr Val Gln Glu Lys Gln Gln Asn Ile Ser Pro
100 105 110
Leu Val Arg Glu Arg Gly Pro Gln Arg Val Ala Ala His Ile Thr Gly
115 120 125
Thr Arg Gly Arg Ser Asn Thr Leu Ser Ser Pro Asn Ser Lys Asn Glu
130 135 140
Lys Ala Leu Gly Arg Lys Ile Asn Ser Trp Glu Ser Ser Arg Ser Gly
145 150 155 160
His Ser Phe Leu Ser Asn Leu His Leu Arg Asn Gly Glu Leu Val Ile
165 170 175
His Glu Lys Gly Phe Tyr Tyr Ile Tyr Ser Gln Thr Tyr Phe Arg Phe
180 185 190
Gln Glu Glu Ile Lys Glu Asn Thr Lys Asn Asp Lys Gln Met Val Gln
195 200 205
Tyr Ile Tyr Lys Tyr Thr Ser Tyr Pro Tyr Pro Ile Leu Leu Met Lys
210 215 220
Ser Ala Arg Asn Ser Cys Trp Ser Lys Asp Ala Glu Tyr Gly Leu Tyr
225 230 235 240
Ser Ile Tyr Gln Gly Gly Ile Phe Glu Leu Lys Glu Asn Asp Arg Ile
245 250 255
Phe Val Ser Val Thr Asn Glu His Leu Ile Asp Met Asp His Glu Ala
260 265 270
Ser Phe Phe Gly Ala Phe Leu Val Gly
275 280
<210> 19
<211> 281
<212> PRT
<213> 人工序列
<220>
<223> 合成肽
<400> 19
Met Ala Met Met Glu Val Gln Gly Gly Pro Ser Leu Gly Gln Thr Cys
1 5 1015
Val Leu Ile Val Ile Phe Thr Val Leu Leu Gln Ser Leu Cys Val Ala
202530
Val Thr Tyr Val Tyr Phe Thr Asn Glu Leu Lys Gln Met Gln Asp Lys
354045
Tyr Ser Lys Ser Gly Ile Ala Cys Phe Leu Lys Glu Asp Asp Ser Tyr
505560
Trp Asp Pro Asn Asp Glu Glu Ser Met Asn Ser Pro Cys Trp Gln Val
65707580
Lys Trp Gln Leu Arg Gln Leu Val Arg Lys Met Ile Leu Arg Thr Ser
859095
Glu Glu Thr Ile Ser Thr Val Gln Glu Lys Gln Gln Asn Ile Ser Pro
100 105 110
Leu Val Arg Glu Arg Gly Pro Gln Arg Val Ala Ala His Ile Thr Gly
115 120 125
Thr Arg Gly Arg Ser Asn Thr Leu Ser Ser Pro Asn Ser Lys Asn Glu
130 135 140
Lys Ala Leu Gly Arg Lys Ile Asn Ser Trp Glu Ser Ser Arg Ser Gly
145 150 155 160
His Ser Phe Leu Ser Asn Leu His Leu Arg Asn Gly Glu Leu Val Ile
165 170 175
His Glu Lys Gly Phe Tyr Tyr Ile Tyr Ser Gln Thr Tyr Phe Arg Phe
180 185 190
Gln Glu Glu Ile Lys Glu Asn Thr Lys Asn Asp Lys Gln Met Val Gln
195 200 205
Tyr Ile Tyr Lys Tyr Thr Ser Tyr Pro Asp Pro Ile Leu Leu Met Lys
210 215 220
Ser Ala Arg Asn Ser Cys Trp Ser Lys Asp Ala Glu Tyr Gly Leu Tyr
225 230 235 240
Ser Ile Tyr Gln Gly Gly Ile Phe Glu Leu Lys Glu Asn Asp Arg Ile
245 250 255
Phe Val Ser Val Thr Asn Glu His Leu Ile Asp Met His His Glu Ala
260 265 270
Ser Phe Phe Gly Ala Phe Leu Val Gly
275 280
<210> 20
<211> 281
<212> PRT
<213> 人工序列
<220>
<223> 合成肽
<400> 20
Met Ala Met Met Glu Val Gln Gly Gly Pro Ser Leu Gly Gln Thr Cys
1 5 1015
Val Leu Ile Val Ile Phe Thr Val Leu Leu Gln Ser Leu Cys Val Ala
202530
Val Thr Tyr Val Tyr Phe Thr Asn Glu Leu Lys Gln Met Gln Asp Lys
354045
Tyr Ser Lys Ser Gly Ile Ala Cys Phe Leu Lys Glu Asp Asp Ser Tyr
505560
Trp Asp Pro Asn Asp Glu Glu Ser Met Asn Ser Pro Cys Trp Gln Val
65707580
Lys Trp Gln Leu Arg Gln Leu Val Arg Lys Met Ile Leu Arg Thr Ser
859095
Glu Glu Thr Ile Ser Thr Val Gln Glu Lys Gln Gln Asn Ile Ser Pro
100 105 110
Leu Val Arg Glu Arg Gly Pro Gln Arg Val Ala Ala His Ile Thr Gly
115 120 125
Thr Arg Gly Arg Ser Asn Thr Leu Ser Ser Pro Asn Ser Lys Asn Glu
130 135 140
Lys Ala Leu Gly Arg Lys Ile Asn Ser Trp Glu Ser Ser Arg Ser Gly
145 150 155 160
His Ser Phe Leu Ser Asn Leu His Leu Arg Asn Gly Glu Leu Val Ile
165 170 175
His Glu Lys Gly Phe Tyr Tyr Ile Tyr Ser Gln Thr Tyr Phe Arg Phe
180 185 190
Gln Glu Arg Ile Lys Glu Asn Thr Lys Asn Asp Lys Gln Met Val Gln
195 200 205
Tyr Ile Tyr Lys Tyr Thr Ser Tyr Pro Asp Pro Ile Leu Leu Met Lys
210 215 220
Ser Ala Arg Asn Ser Cys Trp Ser Lys Asp Ala Glu Tyr Gly Leu Tyr
225 230 235 240
Ser Ile Tyr Gln Gly Gly Ile Phe Glu Leu Lys Glu Asn Asp Arg Ile
245 250 255
Phe Val Ser Val Thr Asn Glu His Leu Ile Asp Met His His Glu Ala
260 265 270
Ser Phe Phe Gly Ala Phe Leu Val Gly
275 280
<210> 21
<211> 281
<212> PRT
<213> 人工序列
<220>
<223> 合成肽
<400> 21
Met Ala Met Met Glu Val Gln Gly Gly Pro Ser Leu Gly Gln Thr Cys
1 5 1015
Val Leu Ile Val Ile Phe Thr Val Leu Leu Gln Ser Leu Cys Val Ala
202530
Val Thr Tyr Val Tyr Phe Thr Asn Glu Leu Lys Gln Met Gln Asp Lys
354045
Tyr Ser Lys Ser Gly Ile Ala Cys Phe Leu Lys Glu Asp Asp Ser Tyr
505560
Trp Asp Pro Asn Asp Glu Glu Ser Met Asn Ser Pro Cys Trp Gln Val
65707580
Lys Trp Gln Leu Arg Gln Leu Val Arg Lys Met Ile Leu Arg Thr Ser
859095
Glu Glu Thr Ile Ser Thr Val Gln Glu Lys Gln Gln Asn Ile Ser Pro
100 105 110
Leu Val Arg Glu Arg Gly Pro Gln Arg Val Ala Ala His Ile Thr Gly
115 120 125
Thr Arg Gly Arg Ser Asn Thr Leu Ser Ser Pro Asn Ser Lys Asn Glu
130 135 140
Lys Ala Leu Gly Arg Lys Ile Asn Ser Trp Glu Ser Ser Arg Ser Gly
145 150 155 160
His Ser Phe Leu Ser Asn Leu His Leu Arg Asn Gly Glu Leu Val Ile
165 170 175
His Glu Lys Gly Phe Tyr Tyr Ile Tyr Ser Gln Thr Tyr Phe Arg Phe
180 185 190
Gln Glu Glu Ile Lys Glu Asn Thr Lys Asn Asp Lys Gln Met Val Gln
195 200 205
Tyr Ile Tyr Lys Tyr Arg Ser Tyr Pro Asp Pro Ile Leu Leu Met Lys
210 215 220
Ser Ala Arg Asn Ser Cys Trp Ser Lys Asp Ala Glu Tyr Gly Leu Tyr
225 230 235 240
Ser Ile Tyr Gln Gly Gly Ile Phe Glu Leu Lys Glu Asn Asp Arg Ile
245 250 255
Phe Val Ser Val Thr Asn Glu His Leu Ile Asp Met His His Glu Ala
260 265 270
Ser Phe Phe Gly Ala Phe Leu Val Gly
275 280
<210> 22
<211> 281
<212> PRT
<213> 人工序列
<220>
<223> 合成肽
<400> 22
Met Ala Met Met Glu Val Gln Gly Gly Pro Ser Leu Gly Gln Thr Cys
1 5 1015
Val Leu Ile Val Ile Phe Thr Val Leu Leu Gln Ser Leu Cys Val Ala
202530
Val Thr Tyr Val Tyr Phe Thr Asn Glu Leu Lys Gln Met Gln Asp Lys
354045
Tyr Ser Lys Ser Gly Ile Ala Cys Phe Leu Lys Glu Asp Asp Ser Tyr
505560
Trp Asp Pro Asn Asp Glu Glu Ser Met Asn Ser Pro Cys Trp Gln Val
65707580
Lys Trp Gln Leu Arg Gln Leu Val Arg Lys Met Ile Leu Arg Thr Ser
859095
Glu Glu Thr Ile Ser Thr Val Gln Glu Lys Gln Gln Asn Ile Ser Pro
100 105 110
Leu Val Arg Glu Arg Gly Pro Gln Arg Val Ala Ala His Ile Thr Gly
115 120 125
Thr Arg Gly Arg Pro Asn Thr Leu Ser Ser Pro Asn Ser Lys Asn Glu
130 135 140
Lys Ala Leu Gly Arg Lys Ile Asn Ser Trp Glu Ser Ser Arg Ser Gly
145 150 155 160
His Ser Phe Leu Ser Asn Leu His Leu Arg Asn Gly Glu Leu Val Ile
165 170 175
His Glu Lys Gly Phe Tyr Tyr Ile Tyr Ser Gln Thr Tyr Phe Arg Phe
180 185 190
Gln Glu Glu Ile Lys Glu Asn Thr Lys Asn Asp Lys Gln Met Val Gln
195 200 205
Tyr Ile Tyr Lys Tyr Thr Ser Tyr Pro Asp Pro Ile Leu Leu Met Lys
210 215 220
Ser Ala Arg Asn Ser Cys Trp Ser Lys Asp Ala Glu Tyr Gly Leu Tyr
225 230 235 240
Ser Ile Tyr Gln Gly Gly Ile Phe Glu Leu Lys Glu Asn Asp Arg Ile
245 250 255
Phe Val Ser Val Thr Asn Glu His Leu Ile Asp Met Asp His Glu Ala
260 265 270
Ser Phe Phe Gly Ala Phe Leu Val Gly
275 280
<210> 23
<211> 281
<212> PRT
<213> 人工序列
<220>
<223> 合成肽
<400> 23
Met Ala Met Met Glu Val Gln Gly Gly Pro Ser Leu Gly Gln Thr Cys
1 5 1015
Val Leu Ile Val Ile Phe Thr Val Leu Leu Gln Ser Leu Cys Val Ala
202530
Val Thr Tyr Val Tyr Phe Thr Asn Glu Leu Lys Gln Met Gln Asp Lys
354045
Tyr Ser Lys Ser Gly Ile Ala Cys Phe Leu Lys Glu Asp Asp Ser Tyr
505560
Trp Asp Pro Asn Asp Glu Glu Ser Met Asn Ser Pro Cys Trp Gln Val
65707580
Lys Trp Gln Leu Arg Gln Leu Val Arg Lys Met Ile Leu Arg Thr Ser
859095
Glu Glu Thr Ile Ser Thr Val Gln Glu Lys Gln Gln Asn Ile Ser Pro
100 105 110
Leu Val Arg Glu Arg Gly Pro Gln Arg Val Ala Ala His Ile Thr Gly
115 120 125
Thr Arg Gly Arg Ser Asn Thr Leu Ser Ser Pro Asn Ser Lys Asn Glu
130 135 140
Lys Ala Leu Gly Arg Lys Ile Asn Ser Trp Glu Cys Ser Arg Ser Gly
145 150 155 160
His Ser Phe Leu Ser Asn Leu His Leu Arg Asn Gly Glu Leu Val Ile
165 170 175
His Glu Lys Gly Phe Tyr Tyr Ile Tyr Ser Gln Thr Tyr Phe Arg Phe
180 185 190
Gln Glu Glu Ile Lys Glu Asn Thr Lys Asn Asp Lys Gln Met Val Gln
195 200 205
Tyr Ile Tyr Lys Tyr Thr Ser Tyr Pro Asp Pro Ile Leu Leu Met Lys
210 215 220
Ser Ala Arg Asn Ser Cys Trp Ser Lys Asp Ala Glu Tyr Gly Leu Tyr
225 230 235 240
Ser Ile Tyr Gln Gly Gly Ile Phe Glu Leu Lys Glu Asn Asp Arg Ile
245 250 255
Phe Val Ser Val Thr Asn Glu His Leu Ile Asp Met Asp His Glu Ala
260 265 270
Ser Phe Phe Gly Ala Phe Leu Val Gly
275 280
<210> 24
<211> 281
<212> PRT
<213> 人工序列
<220>
<223> 合成肽
<400> 24
Met Ala Met Met Glu Val Gln Gly Gly Pro Ser Leu Gly Gln Thr Cys
1 5 1015
Val Leu Ile Val Ile Phe Thr Val Leu Leu Gln Ser Leu Cys Val Ala
202530
Val Thr Tyr Val Tyr Phe Thr Asn Glu Leu Lys Gln Met Gln Asp Lys
354045
Tyr Ser Lys Ser Gly Ile Ala Cys Phe Leu Lys Glu Asp Asp Ser Tyr
505560
Trp Asp Pro Asn Asp Glu Glu Ser Met Asn Ser Pro Cys Trp Gln Val
65707580
Lys Trp Gln Leu Arg Gln Leu Val Arg Lys Met Ile Leu Arg Thr Ser
859095
Glu Glu Thr Ile Ser Thr Val Gln Glu Lys Gln Gln Asn Ile Ser Pro
100 105 110
Leu Val Arg Glu Arg Gly Pro Gln Arg Val Ala Ala His Ile Thr Gly
115 120 125
Thr Arg Gly Arg Ser Asn Thr Leu Ser Ser Pro Asn Ser Lys Asn Glu
130 135 140
Lys Ala Leu Gly Arg Lys Ile Asn Ser Trp Glu Ser Ser Arg Ser Gly
145 150 155 160
His Ser Phe Leu Ser Asn Leu His Leu Arg Asn Gly Glu Leu Val Ile
165 170 175
His Glu Lys Gly Phe Tyr Tyr Ile Tyr Ser Gln Thr Tyr Phe Arg Phe
180 185 190
Gln Glu Glu Ile Lys Glu Asn Thr Lys Asn Asp Lys Gln Met Val Gln
195 200 205
Tyr Ile Tyr Lys Tyr Thr Ser Tyr Pro Asp Pro Ile Leu Leu Met Lys
210 215 220
Ser Ala Arg Asn Ser Cys Trp Ser Lys Asp Ala Glu Tyr Gly Leu Tyr
225 230 235 240
Ser Ile Tyr Gln Gly Gly Ile Phe Glu Leu Lys Glu Asn Asp Arg Ile
245 250 255
Phe Val Ser Val Thr Asn Glu His Leu Ile Asp Met Asp His Glu Ala
260 265 270
Ser Phe Phe Gly Ala Phe Leu Val Gly
275 280
<210> 25
<211> 281
<212> PRT
<213> 人工序列
<220>
<223> 合成肽
<400> 25
Met Ala Met Met Glu Val Gln Gly Gly Pro Ser Leu Gly Gln Thr Cys
1 5 1015
Val Leu Ile Val Ile Phe Thr Val Leu Leu Gln Ser Leu Cys Val Ala
202530
Val Thr Tyr Val Tyr Phe Thr Asn Glu Leu Lys Gln Met Gln Asp Lys
354045
Tyr Ser Lys Ser Gly Ile Ala Cys Phe Leu Lys Glu Asp Asp Ser Tyr
505560
Trp Asp Pro Asn Asp Glu Glu Ser Met Asn Ser Pro Cys Trp Gln Val
65707580
Lys Trp Gln Leu Arg Gln Leu Val Arg Lys Met Ile Leu Arg Thr Ser
859095
Glu Glu Thr Ile Ser Thr Val Gln Glu Lys Gln Gln Asn Ile Ser Pro
100 105 110
Leu Val Arg Glu Arg Gly Pro Gln Arg Val Ala Ala His Ile Cys Gly
115 120 125
Thr Arg Gly Arg Ser Asn Thr Leu Ser Ser Pro Asn Ser Lys Asn Glu
130 135 140
Lys Ala Leu Gly Arg Lys Ile Asn Ser Trp Glu Ser Ser Arg Ser Gly
145 150 155 160
His Ser Phe Leu Ser Asn Leu His Leu Arg Asn Gly Glu Leu Val Ile
165 170 175
His Glu Lys Gly Phe Tyr Tyr Ile Tyr Ser Gln Thr Tyr Phe Arg Phe
180 185 190
Gln Glu Glu Ile Lys Glu Asn Thr Lys Asn Asp Lys Gln Met Val Gln
195 200 205
Tyr Ile Tyr Lys Tyr Thr Ser Tyr Pro Asp Pro Ile Leu Leu Met Lys
210 215 220
Ser Ala Arg Asn Ser Cys Trp Ser Lys Asp Ala Glu Tyr Gly Leu Tyr
225 230 235 240
Ser Ile Tyr Gln Gly Gly Ile Phe Glu Leu Lys Glu Asn Asp Arg Ile
245 250 255
Phe Val Ser Val Thr Asn Glu His Leu Ile Asp Met Asp His Glu Ala
260 265 270
Ser Phe Phe Gly Ala Phe Leu Val Gly
275 280
<210> 26
<211> 281
<212> PRT
<213> 人工序列
<220>
<223> 合成肽
<400> 26
Met Ala Met Met Glu Val Gln Gly Gly Pro Ser Leu Gly Gln Thr Cys
1 5 1015
Val Leu Ile Val Ile Phe Thr Val Leu Leu Gln Ser Leu Cys Val Ala
202530
Val Thr Tyr Val Tyr Phe Thr Asn Glu Leu Lys Gln Met Gln Asp Lys
354045
Tyr Ser Lys Ser Gly Ile Ala Cys Phe Leu Lys Glu Asp Asp Ser Tyr
505560
Trp Asp Pro Asn Asp Glu Glu Ser Met Asn Ser Pro Cys Trp Gln Val
65707580
Lys Trp Gln Leu Arg Gln Leu Val Arg Lys Met Ile Leu Arg Thr Ser
859095
Glu Glu Thr Ile Ser Thr Val Gln Glu Lys Gln Gln Asn Ile Ser Pro
100 105 110
Leu Val Arg Glu Arg Gly Pro Gln Arg Val Ala Ala His Ile Thr Gly
115 120 125
Thr Arg Gly Arg Ser Asn Thr Leu Ser Ser Pro Asn Ser Lys Asn Glu
130 135 140
Lys Ala Leu Gly Arg Lys Ile Asn Ser Trp Glu Ser Ser Arg Ser Gly
145 150 155 160
His Ser Phe Leu Ser Asn Leu His Leu Arg Asn Gly Glu Leu Val Ile
165 170 175
His Glu Lys Gly Phe Tyr Tyr Ile Tyr Ser Gln Thr Tyr Phe Arg Phe
180 185 190
Gln Glu Glu Ile Lys Glu Asn Thr Lys Asn Asp Lys Gln Met Val Gln
195 200 205
Tyr Ile Tyr Lys Tyr Thr Ser Tyr Pro Asp Pro Ile Leu Leu Met Lys
210 215 220
Ser Ala Arg Asn Ser Cys Trp Ser Lys Asp Ala Glu Tyr Gly Leu Tyr
225 230 235 240
Ser Ile Tyr Gln Gly Gly Ile Phe Glu Leu Lys Glu Asn Asp Arg Ile
245 250 255
Phe Val Ser Val Thr Asn Glu His Leu Ile Asp Met Asp Cys Glu Ala
260 265 270
Ser Phe Phe Gly Ala Phe Leu Val Gly
275 280
<210> 27
<211> 4
<212> PRT
<213> 人工序列
<220>
<223> 合成肽
<400> 27
Lys Gly Ser Gly
1
<210> 28
<211> 4
<212> PRT
<213> 人工序列
<220>
<223> 合成肽
<400> 28
Arg Gly Ser Gly
1
<210> 29
<211> 6
<212> PRT
<213> 人工序列
<220>
<223> 合成肽
<400> 29
Pro Gly Met Cys Gly Gly
1 5
<210> 30
<211> 203
<212> PRT
<213> 人工序列
<220>
<223> 合成肽
<400> 30
Gly Arg Met Lys Gln Ile Glu Asp Lys Ile Glu Glu Ile Leu Ser Lys
1 5 1015
Ile Tyr His Val Glu Asn Glu Ile Ala Arg Ile Lys Glu Leu Ile Gly
202530
Glu Asp Gly Val Arg Glu Arg Gly Pro Gln Arg Val Ala Ala His Ile
354045
Thr Gly Thr Arg Gly Arg Ser Asn Thr Leu Ser Ser Pro Asn Ser Lys
505560
Asn Glu Lys Ala Leu Gly Arg Lys Ile Asn Ser Trp Glu Ser Ser Arg
65707580
Ser Gly His Ser Phe Leu Ser Asn Leu His Leu Arg Asn Gly Glu Leu
859095
Val Ile His Glu Lys Gly Phe Tyr Tyr Ile Tyr Ser Gln Thr Tyr Phe
100 105 110
Arg Phe Gln Glu Glu Ile Lys Glu Asn Thr Lys Asn Asp Lys Gln Met
115 120 125
Val Gln Tyr Ile Tyr Lys Tyr Thr Ser Tyr Pro Asp Pro Ile Leu Leu
130 135 140
Met Lys Ser Ala Arg Asn Ser Cys Trp Ser Lys Asp Ala Glu Tyr Gly
145 150 155 160
Leu Tyr Ser Ile Tyr Gln Gly Gly Ile Phe Glu Leu Lys Glu Asn Asp
165 170 175
Arg Ile Phe Val Ser Val Thr Asn Glu His Leu Ile Asp Met Asp His
180 185 190
Glu Ala Ser Phe Phe Gly Ala Phe Leu Val Gly
195 200
<210> 31
<211> 204
<212> PRT
<213> 人工序列
<220>
<223> 合成肽
<400> 31
Met Gly Arg Met Lys Gln Ile Glu Asp Lys Ile Glu Glu Ile Leu Ser
1 5 1015
Lys Ile Tyr His Val Glu Asn Glu Ile Ala Arg Ile Lys Glu Leu Ile
202530
Gly Glu Asp Gly Val Arg Glu Arg Gly Pro Gln Arg Val Ala Ala His
354045
Ile Thr Gly Thr Arg Gly Arg Ser Asn Thr Leu Ser Ser Pro Asn Ser
505560
Lys Asn Glu Lys Ala Leu Gly Arg Lys Ile Asn Ser Trp Glu Ser Ser
65707580
Arg Ser Gly His Ser Phe Leu Ser Asn Leu His Leu Arg Asn Gly Glu
859095
Leu Val Ile His Glu Lys Gly Phe Tyr Tyr Ile Tyr Ser Gln Thr Tyr
100 105 110
Phe Arg Phe Gln Glu Glu Ile Lys Glu Asn Thr Lys Asn Asp Lys Gln
115 120 125
Met Val Gln Tyr Ile Tyr Lys Tyr Thr Ser Tyr Pro Asp Pro Ile Leu
130 135 140
Leu Met Lys Ser Ala Arg Asn Ser Cys Trp Ser Lys Asp Ala Glu Tyr
145 150 155 160
Gly Leu Tyr Ser Ile Tyr Gln Gly Gly Ile Phe Glu Leu Lys Glu Asn
165 170 175
Asp Arg Ile Phe Val Ser Val Thr Asn Glu His Leu Ile Asp Met Asp
180 185 190
His Glu Ala Ser Phe Phe Gly Ala Phe Leu Val Gly
195 200
<210> 32
<211> 216
<212> PRT
<213> 人工序列
<220>
<223> 合成肽
<400> 32
Met Gly His His His His His His His His Pro Gly Met Cys Gly Gly
1 5 1015
Lys Gln Ile Glu Asp Lys Ile Glu Glu Ile Leu Ser Lys Ile Tyr His
202530
Ile Glu Asn Glu Ile Ala Arg Ile Lys Lys Leu Ile Gly Glu Asp Gly
354045
Val Arg Glu Arg Gly Pro Gln Arg Val Ala Ala His Ile Thr Gly Thr
505560
Arg Gly Arg Ser Asn Thr Leu Ser Ser Pro Asn Ser Lys Asn Glu Lys
65707580
Ala Leu Gly Arg Lys Ile Asn Ser Trp Glu Ser Ser Arg Ser Gly His
859095
Ser Phe Leu Ser Asn Leu His Leu Arg Asn Gly Glu Leu Val Ile His
100 105 110
Glu Lys Gly Phe Tyr Tyr Ile Tyr Ser Gln Thr Tyr Phe Arg Phe Gln
115 120 125
Glu Glu Ile Lys Glu Asn Thr Lys Asn Asp Lys Gln Met Val Gln Tyr
130 135 140
Ile Tyr Lys Tyr Thr Ser Tyr Pro Asp Pro Ile Leu Leu Met Lys Ser
145 150 155 160
Ala Arg Asn Ser Cys Trp Ser Lys Asp Ala Glu Tyr Gly Leu Tyr Ser
165 170 175
Ile Tyr Gln Gly Gly Ile Phe Glu Leu Lys Glu Asn Asp Arg Ile Phe
180 185 190
Val Ser Val Thr Asn Glu His Leu Ile Asp Met Asp His Glu Ala Ser
195 200 205
Phe Phe Gly Ala Phe Leu Val Gly
210 215
<210> 33
<211> 663
<212> DNA
<213> 人工序列
<220>
<223> 编码融合多肽的核苷酸序列
<400> 33
catatgggcc atcatcacca ccatcatcat cacccaggca tgtgcggcgg caaacagatc 60
gaagataaga ttgaagaaat tctgtccaag atttaccaca tcgagaatga aatcgcacgt 120
atcaaaaagc tgatcggtga ggacggtgtc cgcgagcgtg gtccgcagcg tgttgcggcg 180
catatcacgg gtactcgtgg tcgcagcaac accctgagca gcccgaatag caaaaatgaa 240
aaggctctgg gtcgtaagat taactcctgg gagagcagcc gctccggtca cagcttcctg 300
agcaatctgc acttgcgtaa cggtgagctg gttattcacg agaaaggctt ctattacatt 360
tacagccaaa cctattttcg ttttcaagag gaaatcaaag agaataccaa aaacgataag 420
caaatggttc agtacatcta caagtacacc tcgtatccgg acccgatcct gttgatgaaa 480
agcgcgcgta atagctgttg gtctaaagat gcagagtatg gtctgtatag catttaccag 540
ggtggcattt tcgagctgaa agaaaacgac cgcatctttg tctctgtgac gaacgaacac 600
ctgattgaca tggatcacga agcgagcttc tttggcgcct tcctggtggg ttaataagag 660
ctc 663
<210> 34
<211> 627
<212> DNA
<213> 人工序列
<220>
<223> 编码融合多肽的核苷酸序列
<400> 34
catatgggga ggatgaagca aatagaggat aagatcgagg agatcctctc gaagatatac 60
cacgtcgaga acgagatagc ccgtatcaaa gagcttattg gggaagatgg agtcagggag 120
aggggtcccc agagagtggc agcacacatt accggtacaa gaggccgtag taataccctc 180
agtagcccta atagtaaaaa cgagaaagcc ctcggacgca agattaactc gtgggaatct 240
tctcgctccg ggcactcttt tctttcgaac ttgcatctga gaaatgggga gctggtgatt 300
cacgagaagg gattctacta catctattcc cagacgtact tccggttcca ggaggagata 360
aaagagaaca cgaagaacga caagcagatg gtccagtaca tctacaagta cacgtcttac 420
ccggacccta tcctcttaat gaagtcggcg cgtagctcct gttggtctaa agacgcagag 480
tatggattgt acagtattta ccagggaggg atattcgagc tgaaggaaaa cgatcggatc 540
ttcggatcgg ttaccgatga gcacctgata gacatggatc atgaggctag cttctttgga 600
gcatttttgg tgggataata agagctc 627
<210> 35
<211> 663
<212> DNA
<213> 人工序列
<220>
<223> 编码融合多肽的核苷酸序列
<400> 35
catatgggcc atcatcacca ccatcatcat cacccaggca tgtgcggcgg caaacagatc 60
gaagataaga ttgaagaaat tctgtccaag atttaccaca tcgagaatga aatcgcacgt 120
atcaaaaagc tgatcggtga ggacggtgtc cgcgagcgtg gtccgcagcg tgttgcggcg 180
catatcacgg gtactcgtgg tcgcagcaac accctgagca gcccgaatag caaaaatgaa 240
aaggctctgg gtcgtaagat taactcctgg gagagcagcc gctccggtca cagcttcctg 300
agcaatctgc acttgcgtaa cggtgagctg gttattcacg agaaaggctt ctattacatt 360
tacagccaaa cctattttcg ttttcaagag gaaatcaaag agaataccaa aaacgataag 420
caaatggttc agtacatcta caagtacacc tcgtatccgg acccgatcct gttgatgaaa 480
agcgcgcgta atagctgttg gtctaaagat gcagagtatg gtctgtatag catttaccag 540
ggtggcattt tcgagctgaa agaaaacgac cgcatctttg tctctgtgac gaacgaacac 600
ctgattgaca tggatcacga agcgagcttc tttggcgcct tcctggtggg ttaataagag 660
ctc 663
<210> 36
<211> 663
<212> DNA
<213> 人工序列
<220>
<223> 编码融合多肽的核苷酸序列
<400> 36
catatgggcc atcatcacca ccatcatcat cacccaggca tgtgcggcgg caaacagatc 60
gaagataaga ttgaagaaat tctgtccaag atttaccacg tggagaatga aatcgcacgt 120
atcaaagaac tgatcggtga ggacggtgtc cgcgagcgtg gtccgcagcg tgttgcggcg 180
catatcacgg gtactcgtgg tcgcagcaac accctgagca gcccgaatag caaaaatgaa 240
aaggctctgg gtcgtaagat taactcctgg gagagcagcc gctccggtca cagcttcctg 300
agcaatctgc acttgcgtaa cggtgagctg gttattcacg agaaaggctt ctattacatt 360
tacagccaaa cctattttcg ttttcaagag gaaatcaaag agaataccaa aaacgataag 420
caaatggttc agtacatcta caagtacacc tcgtatccgg acccgatcct gttgatgaaa 480
agcgcgcgta atagctgttg gtctaaagat gcagagtatg gtctgtatag catttaccag 540
ggtggcattt tcgagctgaa agaaaacgac cgcatctttg tctctgtgac gaacgaacac 600
ctgattgaca tggatcacga agcgagcttc tttggcgcct tcctggtggg ttaataagag 660
ctc 663
<210> 37
<211> 663
<212> DNA
<213> 人工序列
<220>
<223> 编码融合多肽的核苷酸序列
<400> 37
catatgggcc atcatcacca ccatcatcat cacccaggca tgtgcggcgg caaacagatc 60
gaagataaga ttgaagaaat tctgtccaag atttaccacg tggagaatga aatcgcacgt 120
atcaaaaagc tgatcggtga ggacggtgtc cgcgagcgtg gtccgcagcg tgttgcggcg 180
catatcacgg gtactcgtgg tcgcagcaac accctgagca gcccgaatag caaaaatgaa 240
aaggctctgg gtcgtaagat taactcctgg gagagcagcc gctccggtca cagcttcctg 300
agcaatctgc acttgcgtaa cggtgagctg gttattcacg agaaaggctt ctattacatt 360
tacagccaaa cctattttcg ttttcaagag gaaatcaaag agaataccaa aaacgataag 420
caaatggttc agtacatcta caagtacacc tcgtatccgg acccgatcct gttgatgaaa 480
agcgcgcgta atagctgttg gtctaaagat gcagagtatg gtctgtatag catttaccag 540
ggtggcattt tcgagctgaa agaaaacgac cgcatctttg tctctgtgac gaacgaacac 600
ctgattgaca tggatcacga agcgagcttc tttggcgcct tcctggtggg ttaataagag 660
ctc 663
<210> 38
<211> 663
<212> DNA
<213> 人工序列
<220>
<223> 编码融合多肽的核苷酸序列
<400> 38
catatgggcc atcatcacca ccatcatcat cacccaggca tgtgcggcgg caaacagatc 60
gaagataaga ttgaagaaat tctgtccaag atttaccaca tcgagaatga aatcgcacgt 120
atcaaagaac tgatcggtga ggacggtgtc cgcgagcgtg gtccgcagcg tgttgcggcg 180
catatcacgg gtactcgtgg tcgcagcaac accctgagca gcccgaatag caaaaatgaa 240
aaggctctgg gtcgtaagat taactcctgg gagagcagcc gctccggtca cagcttcctg 300
agcaatctgc acttgcgtaa cggtgagctg gttattcacg agaaaggctt ctattacatt 360
tacagccaaa cctattttcg ttttcaagag gaaatcaaag agaataccaa aaacgataag 420
caaatggttc agtacatcta caagtacacc tcgtatccgg acccgatcct gttgatgaaa 480
agcgcgcgta atagctgttg gtctaaagat gcagagtatg gtctgtatag catttaccag 540
ggtggcattt tcgagctgaa agaaaacgac cgcatctttg tctctgtgac gaacgaacac 600
ctgattgaca tggatcacga agcgagcttc tttggcgcct tcctggtggg ttaataagag 660
ctc 663
<210> 39
<211> 663
<212> DNA
<213> 人工序列
<220>
<223> 编码融合多肽的核苷酸序列
<400> 39
catatgggcc atcatcacca ccatcatcat cacccaggca tgtgcggcgg caaacagatc 60
gaagataaga ttgaagaaat tctgtccaag atttaccaca tcgagaatga aatcgcacgt 120
atcaaacaac tgatcggtga ggacggtgtc cgcgagcgtg gtccgcagcg tgttgcggcg 180
catatcacgg gtactcgtgg tcgcagcaac accctgagca gcccgaatag caaaaatgaa 240
aaggctctgg gtcgtaagat taactcctgg gagagcagcc gctccggtca cagcttcctg 300
agcaatctgc acttgcgtaa cggtgagctg gttattcacg agaaaggctt ctattacatt 360
tacagccaaa cctattttcg ttttcaagag gaaatcaaag agaataccaa aaacgataag 420
caaatggttc agtacatcta caagtacacc tcgtatccgg acccgatcct gttgatgaaa 480
agcgcgcgta atagctgttg gtctaaagat gcagagtatg gtctgtatag catttaccag 540
ggtggcattt tcgagctgaa agaaaacgac cgcatctttg tctctgtgac gaacgaacac 600
ctgattgaca tggatcacga agcgagcttc tttggcgcct tcctggtggg ttaataagag 660
ctc 663
<210> 40
<211> 663
<212> DNA
<213> 人工序列
<220>
<223> 编码融合多肽的核苷酸序列
<400> 40
catatgggcc atcatcacca ccatcatcat cacccaggca tgtgcggcgg caaacagatc 60
gaagataaga ttgaagaaat tctgtccaag atttaccacg tggagaatga aatcgcacgt 120
atcaaacaac tgatcggtga ggacggtgtc cgcgagcgtg gtccgcagcg tgttgcggcg 180
catatcacgg gtactcgtgg tcgcagcaac accctgagca gcccgaatag caaaaatgaa 240
aaggctctgg gtcgtaagat taactcctgg gagagcagcc gctccggtca cagcttcctg 300
agcaatctgc acttgcgtaa cggtgagctg gttattcacg agaaaggctt ctattacatt 360
tacagccaaa cctattttcg ttttcaagag gaaatcaaag agaataccaa aaacgataag 420
caaatggttc agtacatcta caagtacacc tcgtatccgg acccgatcct gttgatgaaa 480
agcgcgcgta atagctgttg gtctaaagat gcagagtatg gtctgtatag catttaccag 540
ggtggcattt tcgagctgaa agaaaacgac cgcatctttg tctctgtgac gaacgaacac 600
ctgattgaca tggatcacga agcgagcttc tttggcgcct tcctggtggg ttaataagag 660
ctc 663
<210> 41
<211> 25
<212> DNA
<213> 人工序列
<220>
<223> 合成引物(Synthetic primer)
<400> 41
gggaagaaga ttctcctgag atgtg 25
<210> 42
<211> 23
<212> DNA
<213> 人工序列
<220>
<223> 合成引物
<400> 42
acattgtcct cagccccagg tcg 23
<210> 43
<211> 19
<212> DNA
<213> 人工序列
<220>
<223> 合成引物
<400> 43
aagacccttg tgctcgttg 19
<210> 44
<211> 20
<212> DNA
<213> 人工序列
<220>
<223> 合成引物
<400> 44
aggtggacac aatccctctg 20
<210> 45
<211> 20
<212> DNA
<213> 人工序列
<220>
<223> 合成引物
<400> 45
ccagagccat tgtcacacac 20
<210> 46
<211> 18
<212> DNA
<213> 人工序列
<220>
<223> 合成引物
<400> 46
cagccaagca ctgtcagg 18
<210> 47
<211> 18
<212> DNA
<213> 人工序列
<220>
<223> 合成引物
<400> 47
cttccagccg aggtcctt 18
<210> 48
<211> 20
<212> DNA
<213> 人工序列
<220>
<223> 合成引物
<400> 48
ccctggacac caactattgc 20
<210> 49
<211> 20
<212> DNA
<213> 人工序列
<220>
<223> 合成引物
<400> 49
agcaggtcct tggaaacctt 20
<210> 50
<211> 20
<212> DNA
<213> 人工序列
<220>
<223> 合成引物
<400> 50
gaaaaggagt tggacttggc 20
<210> 51
<211> 20
<212> DNA
<213> 人工序列
<220>
<223> 合成引物
<400> 51
aaatggaacc tggcgaaagc 20
<210> 52
<211> 20
<212> DNA
<213> 人工序列
<220>
<223> 合成引物
<400> 52
gatgagcccc tcaggcattt 20
<210> 53
<211> 20
<212> DNA
<213> 人工序列
<220>
<223> 合成引物
<400> 53
gtcttgggag ccagggtgac 20
<210> 54
<211> 21
<212> DNA
<213> 人工序列
<220>
<223> 合成引物
<400> 54
tgaaaagtgc aaatggcaag c 21
<210> 55
<211> 20
<212> DNA
<213> 人工序列
<220>
<223> 合成引物
<400> 55
ctaccacatc caaggaagca 20
<210> 56
<211> 21
<212> DNA
<213> 人工序列
<220>
<223> 合成引物
<400> 56
tttttcgtca ctacctcccc g 21