一种带有两步噪声过滤的不平衡数据混合采样算法
文献发布时间:2023-06-19 19:35:22
技术领域
本发明涉及不平衡数据分类领域,具体涉及一种带有两步噪声过滤的不平衡数据混合采样算法。
背景技术
数据不平衡也可称作数据倾斜,在实际应用中,许多领域都存在着数据不平衡,如信用卡欺诈检测问题,网络入侵检测问题,医疗诊断问题都存在着数据不平衡。数据不平衡是指在数据集中大部分数据属于多数类,只有一小部分数据属于少数类。如信用卡欺诈检测问题,网络入侵检测问题,医疗诊断问题都存在着数据不平衡。就信用卡欺诈而言,在这个数据集中正常数据的数量(比如占数据集的95%)远远多于存在着欺诈数据(比如占数据集的10%)的数量,在数据处理中,数据分类器的最终目标是实验较高的分类准确率,如果把所有的数据都分类为正常,那么分类准确率就能达到90%,但是这样的准确率是不可靠的。因为把欺诈误分类为正常的危害是巨大的。
目前常用的解决数据不平衡问题的策略是从数据处理角度的过采样方法,过采样是合成少数类数据集来使不平衡数据尽可能的达到平衡。这一策略的代表算法如SMOTE,ADASYN等。SMOTE是众多方法中最流行的一种,它通过选择最近的k个少数类邻居,从中随机的选择邻居进行样本间的线性插值。ADASYN是根据某个少数类k个最近邻中属于多数类的数量来给少数类分配权重,在实例合成时,会根据权重的大小来合成实例,权重越大,合成实例的数量越多。然而,这些方法忽略了噪声样本的影响,合成的新样本可能坐落于多数类别区域,决策边界重合等问题,使得现有技术中的数据不平衡处理方法准确度较差。
基于上述分析,如何消除噪声的影响以及减少决策边界之间的重合成了不平衡数据分类领域逐渐考虑的问题。
发明内容
本发明目的在于提供一种带有两步噪声过滤的不平衡数据混合采样算法,为达成上述目的,本发明提出如下技术方案:
一种带有两步噪声过滤的不平衡数据混合采样算法,包括以下步骤:
将原始数据集T划分为多数类数据集M和少数类数据集Q;
对所述少数类数据集Q进行第一步去噪,对每一个所述少数类数据集Q的数据样本Q
将所述少数类数据集Q
对所述少数类数据集Q
将所述多数类数据集M分为边界多数类数据集M
对所述边界少数类Q
对所述安全少数类数据集Q
将所述边界少数类数据集Q
进一步的,所述对每一个所述少数类数据集Q的数据样本Q
进一步的,所述t与所述k的值的靠近度按照所述数据样本Q
按照所述数据样本Q
进一步的,所述对每一个所述多数类数据集M的数据样本M
进一步的,对所述边界少数类数据集Q
使用带有高斯核的径向基函数来评估所述边界少数类数据集Q
计算出所述边界少数类数据集Q
对于所述边界少数类数据集Q
进一步的,对所述安全少数类数据集Q
找到所述安全少数类数据集Q
依次判断从小到大的所述w个最近邻中第几个最近邻是属于所述多数类数据集M;
若所述w个最近邻的标签都是少数类样本,则将所述w个最近邻全部归属于合格邻居数据集h;
若所述w个最近邻中第y个样本属于所述多数类数据集M,则将第1个、第2个、......、第y个归属于所述合格邻居数据集h;
利用公式S=λ(e-f),对于所述安全少数类数据集Q
一种带有两步噪声过滤的不平衡数据混合采样装置,包括:
第一划分模块,用于将原始数据集T划分为多数类数据集M和少数类数据集Q;
第一去噪模块,用于对所述少数类数据集Q进行第一步去噪,对每一个所述少数类数据集Q的数据样本Q
第二划分模块,用于将所述少数类数据集Q
第二去噪模块,用于对所述少数类数据集Q
第三划分模块,用于将所述多数类数据集M分为边界多数类数据集M
第一过采样模块,用于对所述边界少数类Q
第二过采样模块,用于对所述安全少数类数据集Q
输出模块,用于将所述边界少数类数据集Q
进一步的,所述第一过采样模块,包括:
评估模块,用于使用带有高斯核的径向基函数来评估所述边界少数类数据集Q
计算模块,用于计算出所述边界少数类数据集Q
样本生成模块,用于对于所述边界少数类数据集Q
一种电子设备,包括存储器、处理器及存储在存储器上的计算机程序,所述处理器在执行所述计算机程序时实现所述的方法。
一种计算机可读存储介质,其特征在于,其上存储有计算机程序,所述计算机程序用于执行所述的方法。
有益效果:
本发明在使用不同的采样方法来合成实例前先进行两步噪声去噪,利用不同的去噪机制更加充分地去除数据集中的噪声样本,有效的降低了噪声样本对分类性能的影响。并且把少数类样本划分为两种类别,分别为安全少数类和边界少数类,用不同的采样方法处理这两个类别,目的是为了减少合成实例与边界样本的重合,也就是减少决策边界的重合,进而提升分类器的识别性能。
应当理解,前述构思以及在下面更加详细地描述的额外构思的所有组合只要在这样的构思不相互矛盾的情况下都可以被视为本公开的发明主题的一部分。
结合附图从下面的描述中可以更加全面地理解本发明教导的前述和其他方面、实施例和特征。本发明的其他附加方面例如示例性实施方式的特征和/或有益效果将在下面的描述中显见,或通过根据本发明教导的具体实施方式的实践中得知。
附图说明
构成本申请的一部分的附图用来提供对本申请的进一步理解,本申请的示意性实施例及其说明用于解释本申请,并不构成对本申请的不当限定。在附图中:
图1是本发明实施的算法流程图;
图2是本发明与几种流行方法在KNN分类器的F-measure测度下的平均rank对比图,其中HSNF代表本专利实现算法;
图3是本发明与几种流行方法在KNN分类器的G-mean测度下的平均rank对比图,其中HSNF代表本专利实现算法;
图4是本发明与几种流行方法在KNN分类器的AUC测度下的平均rank对比图,其中HSNF代表本专利实现算法;
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例的附图,对本发明实施例的技术方案进行清楚、完整地描述。显然,所描述的实施例是本发明的一部分实施例,而不是全部的实施例。基于所描述的本发明的实施例,本领域普通技术人员在无需创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。除非另作定义,此处使用的技术术语或者科学术语应当为本发明所属领域内具有一般技能的人士所理解的通常意义。
本发明专利申请说明书以及权利要求书中使用的“第一”、“第二”以及类似的词语并不表示任何顺序、数量或者重要性,而只是用来区分不同的组成部分。同样,除非上下文清楚地指明其它情况,否则单数形式的“一个”“一”或者“该”等类似词语也不表示数量限制,而是表示存在至少一个。“包括”或者“包含”等类似的词语意指出现在“包括”或者“包含”前面的元件或者物件涵盖出现在“包括”或者“包含”后面列举的特征、整体、步骤、操作、元素和/或组件,并不排除一个或多个其它特征、整体、步骤、操作、元素、组件和/或其集合的存在或添加。“上”“下”“左”“右”等仅用于表示相对位置关系,当被描述对象的绝对位置改变后,则该相对位置关系也可能相应地改变。
需要说明的是,在不冲突的情况下,本申请中的实施例及实施例中的特征可以相互组合。下面将参考附图并结合实施例来详细说明本申请。
需要说明的是,在附图的流程图示出的步骤可以在诸如一组计算机可执行指令的计算机系统中执行,并且,虽然在流程图中示出了逻辑顺序,但是在某些情况下,可以以不同于此处的顺序执行所示出或描述的步骤。
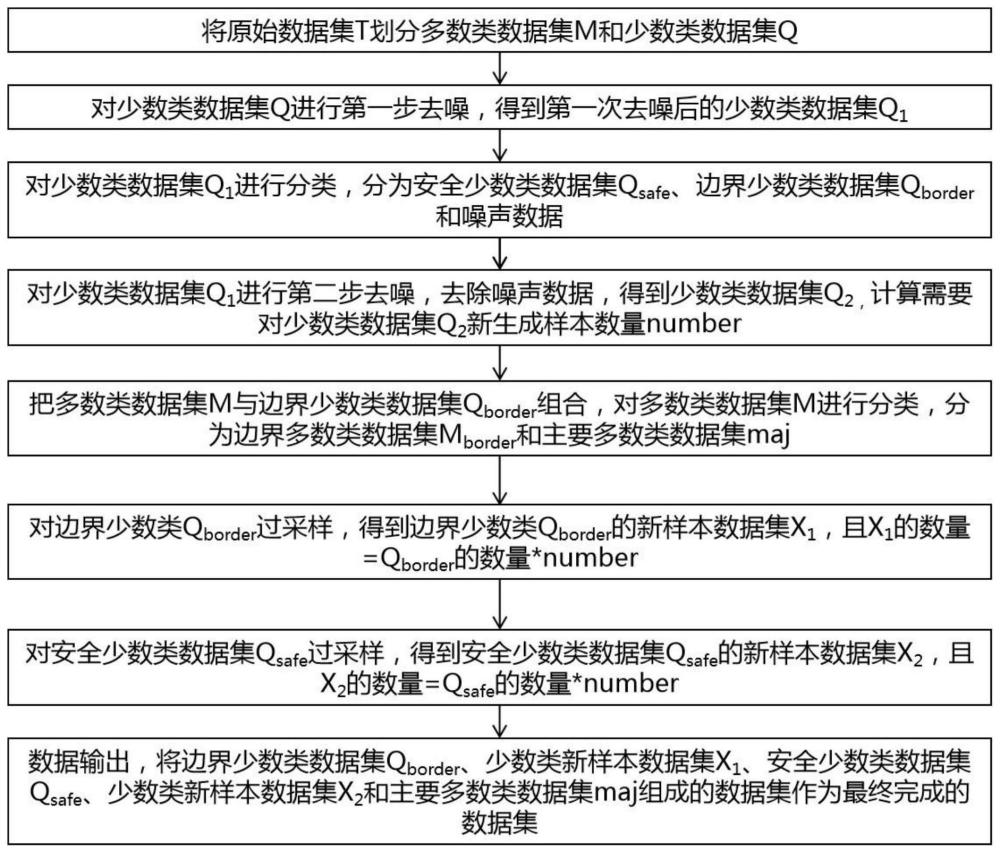
请参阅图1,为本发明实施例一种带有两步噪声过滤的不平衡数据混合采样算法,包括以下步骤:
将原始数据集T划分为多数类数据集M和少数类数据集Q;
对少数类数据集Q进行第一步去噪,对每一个少数类数据集Q的数据样本Q
将少数类数据集Q
对少数类数据集Q
将多数类数据集M分为边界多数类数据集M
对边界少数类Q
对安全少数类数据集Q
将边界少数类数据集Q
本发明实施例经过上述步骤的处理,根据不同的噪声过滤机制进行的两步噪声去噪,可以更充分的过滤数据集T中的噪声样本,减少噪声样本对数据分类性能的影响。本发明实施例把少数类数据集Q进行类别分类,分为安全少数类数据集Q
本发明实施例中,对每一个少数类数据集Q的数据样本Q
本发明实施例中,t与k的值的靠近度按照数据样本Q
按照数据样本Q
本发明实施例中,对每一个多数类数据集M的数据样本M
本发明实施例中,对边界少数类数据集Q
使用带有高斯核的径向基函数来评估边界少数类数据集Q
计算出边界少数类数据集Q
对于边界少数类数据集Q
本发明实施例中,对安全少数类数据集Q
找到安全少数类数据集Q
依次判断从小到大的w个最近邻中第几个最近邻是属于多数类数据集M;
若w个最近邻的标签都是少数类样本,则将w个最近邻全部归属于合格邻居数据集h;
若w个最近邻中第y个样本属于多数类数据集M,则将第1个、第2个、......、第y个归属于合格邻居数据集h;
利用公式S=λ(e-f),对于安全少数类数据集Q
本发明实施例提供一种带有两步噪声过滤的不平衡数据混合采样装置,包括:
第一划分模块,用于将原始数据集T划分为多数类数据集M和少数类数据集Q;
第一去噪模块,用于对少数类数据集Q进行第一步去噪,对每一个少数类数据集Q的数据样本Q
第二划分模块,用于将少数类数据集Q
第二去噪模块,用于对少数类数据集Q
第三划分模块,用于将多数类数据集M分为边界多数类数据集M
第一过采样模块,用于对边界少数类Q
第二过采样模块,用于对安全少数类数据集Q
输出模块,用于将边界少数类数据集Q
本发明实施例提供的一种带有两步噪声过滤的不平衡数据混合采样装置中的第一过采样模块,包括:
评估模块,用于使用带有高斯核的径向基函数来评估边界少数类数据集Q
计算模块,用于计算出边界少数类数据集Q
样本生成模块,用于对于边界少数类数据集Q
在本发明实施例中,提供一种电子设备,包括存储器和处理器,存储器中存储有计算机程序,处理器被设置为运行计算机程序以执行以上实施例中的带有两步噪声过滤的不平衡数据混合采样算法。
这些计算机程序也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤,对应与不同的步骤可以通过不同的模块来实现。
在本发明实施例中,提供一种计算机可读存储介质,其上存储有计算机程序,计算机程序用于执行所述的方法。上述程序可以运行在处理器中,或者也可以存储在存储器中(或称为计算机可读介质),计算机可读介质包括永久性和非永久性、可移动和非可移动媒体可以由任何方法或技术来实现信息存储。信息可以是计算机可读指令、数据结构、程序的模块或其他数据。计算机的存储介质的例子包括,但不限于相变内存(PRAM)、静态随机存取存储器(SRAM)、动态随机存取存储器(DRAM)、其他类型的随机存取存储器(RAM)、只读存储器(ROM)、电可擦除可编程只读存储器(EEPROM)、快闪记忆体或其他内存技术、只读光盘只读存储器(CD-ROM)、数字多功能光盘(DVD)或其他光学存储、磁盒式磁带,磁带磁磁盘存储或其他磁性存储设备或任何其他非传输介质,可用于存储可以被计算设备访问的信息。按照本文中的界定,计算机可读介质不包括暂存电脑可读媒体(transitory media),如调制的数据信号和载波。
以上仅为本申请的实施例而已,并不用于限制本申请。对于本领域技术人员来说,本申请可以有各种更改和变化。凡在本申请的精神和原理之内所作的任何修改、等同替换、改进等,均应包含在本申请的权利要求范围之内。
- 一种基于文本多分类混合式均分聚类采样算法的不平衡数据集文本多分类方法
- 基于密度的不平衡数据混合采样算法