一种基于基于频域注意力的IT设备关键性能指标时序预测方法
文献发布时间:2024-04-18 19:58:21
技术领域
本发明属于深度学习技术领域,具体涉及一种基于频域注意力的IT设备关键性能指标时序预测方法。
背景技术
KPI时序预测是以历史KPI时序数据为基础,利用数据挖掘技术学习数据中的运行规律,对将来某时刻的时序值做出做出合理的估计,从而发现其中突然出现抖动、下降、尖峰等不遵循正常模式的数据,若出现异常通常表明互联网服务的软硬件中存在潜在故障,如服务器故障、访问用户急剧减少、访问延迟增大等。及时准确地发现KPI中的异常,可以为后面的故障分析和修复节省时间,避免带来更大的损失,保证系统能够为用户提供高效可靠的网络服务,目前仍存在以下待改进的地方:
1.对于复杂的、非线性和非平稳的KPI时序数据,传统的预测模型往往难以准确预测,无法充分挖掘时序数据中的内在规律和结构。
2.传统的预测模型往往只能在单一时间尺度上进行预测,无法捕获多尺度下的上下文信息,使得模型无法充分利用时序数据中的多层次信息,影响预测精度。
3.传统的预测模型往往无法考虑时序数据中的频域信息,使得模型无法充分利用时序数据中不同频率的信息,影响预测精度。
发明内容
为解决现有技术中存在的上述问题,本发明提供了一种基于频域注意力的IT设备关键性能指标时序预测方法,
本发明的目的可以通过以下技术方案实现:
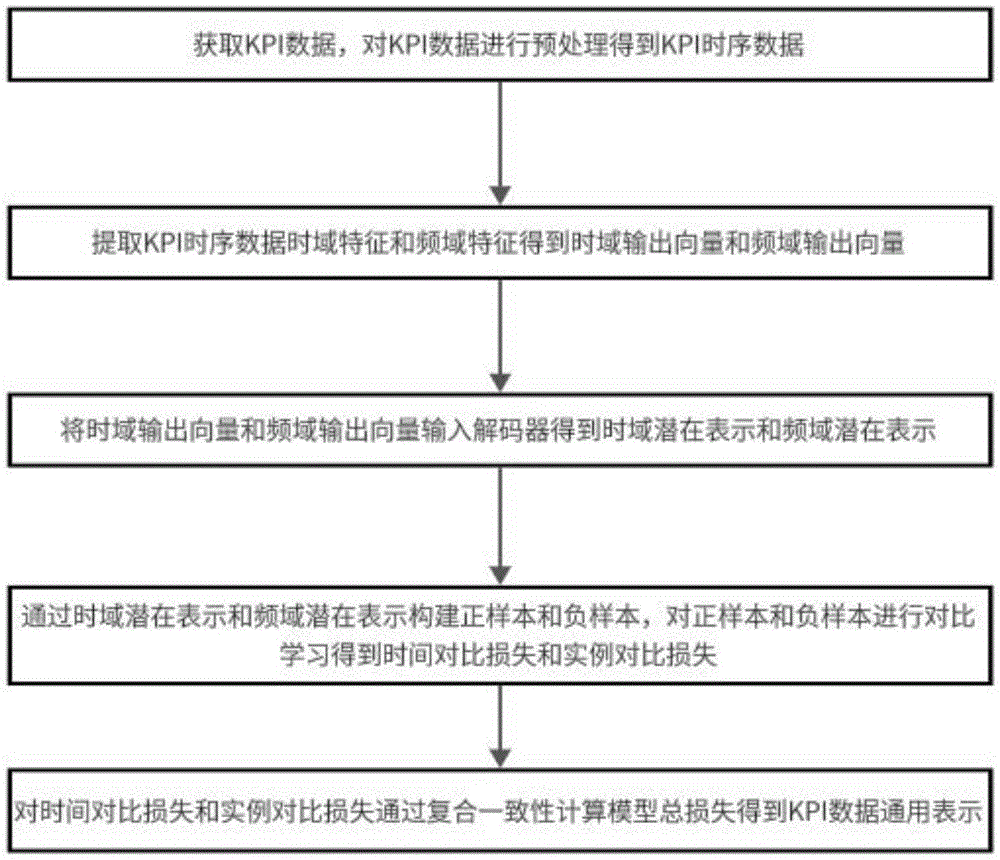
S1:获取KPI数据,对所述KPI数据进行预处理得到KPI时序数据;
S2:对所述KPI时序数据通过时域编码器提取时域特征得到时域输出向量,对所述KPI时序数据通过频域编码器提取频域特征得到频域输出向量;
S3:将所述时域输出向量和所述频域输出向量输入解码器得到时域潜在表示和频域潜在表示;
S4:通过所述时域潜在表示和所述频域潜在表示构建正样本和负样本,对比所述正样本和所述负样本差异,捕获多尺度下的上下文信息得到时间对比损失和实例对比损失;
S5:对所述时间对比损失和所述实例对比损失通过一致性度量计算模型总损失得到KPI数据通用表示模型。
具体地,所述步骤S1包括以下步骤:
S101:对所述KPI数据进行顺序排列,通过计算所述KPI数据的残差和标准差得到显着值,剔除所述显着值大于格拉布斯临界表中的临界值的KPI数据得到异常检测数据;
S102:对所述异常检测数据进行标准化得到KPI标准化数据,计算公式为:
其中,y
S103:将所述KPI标准化数据的平均值补全到所述KPI标准化数据中得到所述KPI时序数据。
具体地,所述时域编码器包括一维卷积层、批归一化层和激活层,其中所述一维卷积层对所述KPI时序数据进行增量分布分析得到尺度特性序列,计算公式为:
其中,n为观测跨度,R(n)为KPI时序数据在观测跨度内的取值范围,S(n)为标准差,E为期望,H为尺度特性序列;
所述批归一化层将所述尺度特性序列进行归一化处理得到重构序列,计算公式为:
其中,y
所述激活层将所述重构序列进行非线性变换得到所述时域输出向量。
具体地,所述频域编码器截取所述KPI时序数据生成时间序列样本,将所述时间序列样本变换到频域生成频谱,计算公式为:
其中,x(t)为时间序列样本,j为
提取所述频谱特征生成频域输出向量。
具体地,所述步骤S3包括以下步骤:
S301:将所述频域输出向量和所述时域输出向量输入解码器得到每个时间步的注意力向量,计算公式为:
其中,i为解码器时间步计数,j为编码器时间步计数,c
S302:通过所述注意力向量计算每个时间步的解码输出得到所述时域潜在表示和所述频域潜在表示,计算公式为:
x
y
其中,W
具体地,所述步骤S4包括以下步骤:
将同一个时间戳下的所述时序潜在表示和所述频域潜在表示构建为正样本,将不同时间戳下的所述时序潜在表示和所述频域潜在表示构建为负样本;
对所述正样本和所述负样本通过对比学习得到时间对比损失和实例对比损失,计算公式为:
其中,i为样本计数,t和t′为时间戳计数,
具体地,所述步骤S5包括以下步骤:
将所述时间对比损失和所述实例对比损失通过多个样本交互得到时域总损失和频域总损失,计算公式为:
其中,L1为时域总损失,N为样本总数,T为时间周期,i为样本计数,t为时间戳,
将所述时域潜在表示和频域潜在表示通过交错空间投影器映射到高位潜在的时频空间得到时间嵌入和频率嵌入;
对所述时间嵌入和所述频率嵌入通过时频一致性度量得到时频一致性损失;
结合所述时频一致性损失,所述时域总损失和所述频域总损失得到模型总损失,计算公式为:
L=x(L1+L2)+(1-x)L3
其中,L为模型总损失,L1为时域总损失,L2为频域总损失,L3为时频一致性损失,x为对比损失权重参数;
通过所述模型总损失的约束,训练预设KPI数据集得到KPI数据通用表示模型。
本发明的有益效果为:
(1)通过从时间维度和实例维度上分正样本和负样本,并通过最大池化捕获多尺度下的上下文信息,通过对比正样本和负样本之间的差异,模型可以学习到时序数据中的固有结构和规律。
(2)通过采用层次对比损失,同时利用实例层次和时间层次的对比损失联合编码时间序列分布,使得模型能够为时间数据捕获多个分辨率的上下文信息,鼓励模型学习不同语义层次下的信息,使模型学习到的通用表示能够用于不同的下游任务,提高了模型的准确性和可解释性。
(3)通过引入频域注意力机制,强化了模型对于时序数据中频域信息的提取能力,通过一个注意力机制,模型可以自适应地学习不同频率的信息对于预测的重要程度,并根据学习到的注意力权重对频域数据进行加权平均,提高了预测的精度和可靠度。
附图说明
为了便于本领域技术人员理解,下面结合附图对本发明作进一步的说明。
图1为本发明的一种基于频域注意力的IT设备关键性能指标时序预测方法的流程示意图;
具体实施方式
为更进一步阐述本发明为实现预定发明目的所采取的技术手段及功效,以下结合附图及较佳实施例,对依据本发明的具体实施方式、结构、特征及其功效,详细说明如下。
请参阅图1,一种基于频域注意力的IT设备关键性能指标时序预测方法,本发明的工作原理及使用流程:
S1:获取KPI数据,对所述KPI数据进行预处理得到KPI时序数据;
S2:对所述KPI时序数据通过时域编码器提取时域特征得到时域输出向量,对所述KPI时序数据通过频域编码器提取频域特征得到频域输出向量;
S3:将所述时域输出向量和所述频域输出向量输入解码器得到时域潜在表示和频域潜在表示;
S4:通过所述时域潜在表示和所述频域潜在表示构建正样本和负样本,对比所述正样本和所述负样本差异,捕获多尺度下的上下文信息得到时间对比损失和实例对比损失;
S5:对所述时间对比损失和所述实例对比损失通过一致性度量计算模型总损失得到KPI数据通用表示模型。
具体地,所述步骤S1包括以下步骤:
S101:对所述KPI数据进行顺序排列,通过计算所述KPI数据的残差和标准差得到显着值,剔除所述显着值大于格拉布斯临界表中的临界值的KPI数据得到异常检测数据;
S102:对所述异常检测数据进行标准化得到KPI标准化数据,计算公式为:
其中,y
S103:将所述KPI标准化数据的平均值补全到所述KPI标准化数据中得到所述KPI时序数据。
通过所述KPI数据创建数据集,使用Python进行数据预处理,导入预定义的numpy,matplotlib,pandas库,使用pandas来读取文件,使用Pandas库的iloc[]方法从数据集中提取所需的行和列,提取自变量age,sex和因变量target,计算包含任何缺失值的列或行的平均值,并将其放在缺失值的位置,变量放在相同的范围和相同的比例中,将sklearn.preprocessing库的StandardScaler类导入,将数据集标准化。
通过上述技术方案减少了每个输入时间序列之间的分布差异,使模型输入的分布更加稳定。
所述时域编码器包括:一维卷积层、批归一化层和激活层,其中所述一维卷积层对所述KPI时序数据进行增量分布分析得到尺度特性序列,计算公式为:
其中,n为观测跨度,R(n)为KPI时序数据在观测跨度内的取值范围,S(n)为标准差,E为期望,H为尺度特性序列;
所述批归一化层将所述尺度特性序列进行归一化处理得到重构序列,计算公式为:
其中,y
所述激活层将所述重构序列进行非线性变换得到所述时域输出向量。
一维卷积层由三个卷积块堆叠,设置卷积块的输出特征通道维度为{32,64,8},设置卷积核尺寸为{8,5,3},使用填充策略保持输入和输出的维度一致;求取每一个小批量训练数据的均值和方差,然后使求得的均值和方差对该批次的训练数据归一化,最后逬行尺度变换和偏移;使用Relu函数将输入特征经过非线性变化映射到另一个空间。通过上述技术方案提高了模型的泛化能力,保留了更多的全局模式信息。
具体地,所述频域编码器截取所述KPI时序数据生成时间序列样本,将所述时间序列样本变换到频域生成频谱,计算公式为:
其中,x(t)为时间序列样本,j为
提取所述频谱特征生成频域输出向量。
使用离散余弦变换将原始数据变换到频域,将原始数据等分为K段。然后对每一段子序列分别应用频域注意力机制。最后,将每个子序列的输出在通道维度上级联,得到输出特征;采用启发式探索方法,寻找最佳分数段;在训练阶段,保存每一轮的验证集损失值和当前模型内部参数,最终选取验证集损失最小值对应的模型参数作为最终参数。
通过上述技术方案改善了原始数据的特征表示,提高模型性能。
具体地,所述步骤S3包括以下步骤:
S301:将所述频域输出向量和所述时域输出向量输入解码器得到每个时间步的注意力向量,计算公式为:
其中,i为解码器时间步计数,j为编码器时间步计数,c
S302:通过所述注意力向量计算每个时间步的解码输出得到所述时域潜在表示和所述频域潜在表示,计算公式为:
x
y
其中,W
基于Transformer模型开发,输入由查询、键和值组成。通过计算所有查询和键的点积,再除以值,并应用一个softmax函数来获得这些值的权重;将原始时间序列与嵌入到神经网络中的小波系数矩阵相乘再加上相应的偏置得到原始序列的频域表示,同时所述频域表示与原始序列在时域上进行了对齐,有利于现有对比学习模型的时频一致性对比。小波变换得到的频域信息和原始时间序列的时域信息最终被映射到潜在时频空间中。
具体地,所述步骤S4包括以下步骤:
将同一个时间戳下的所述时序潜在表示和所述频域潜在表示构建为正样本,将不同时间戳下的所述时序潜在表示和所述频域潜在表示构建为负样本;
对所述正样本和所述负样本通过对比学习得到时间对比损失和实例对比损失,计算公式为:
其中,i为样本计数,t和t′为时间戳计数,
通过实例层次和时间层次的对比损失联合编码时间序列分布。对于任意子序列,它的总体表示可以通过在相应的时间戳上的最大池来获得。这使得模型能够为时间数据捕获多个分辨率的上下文信息。对于一个给定的输入时间序列样本,通过一个基于时间的增强库生成一个增强集,其中时间增强库包括抖动,缩放,时间平移,领域分割。对于输入,随机选择一个增强样本,并将其输入一个对比时间编码器,将样本映射到嵌入,通过傅里叶变换从一个时间序列样本生成频谱,采用基于频谱特性的增强方法生成增强集。利用频率编码器来将频谱映射到一个基于频率的嵌入。
通过上述技术方案使模型在模型总损失的约束下,学习到原始时间序列时域和频域下的通用表示,使所述通用表示在时间序列中具有泛化性,适用于不同的下游任务。
具体地,所述步骤S5包括以下步骤:
将所述时间对比损失和所述实例对比损失通过多个样本交互得到时域总损失和频域总损失,计算公式为:
其中,L1为时域总损失,N为样本总数,T为时间周期,i为样本计数,t为时间戳,
将所述时域潜在表示和频域潜在表示通过交错空间投影器映射到高位潜在的时频空间得到时间嵌入和频率嵌入;
对所述时间嵌入和所述频率嵌入通过时频一致性度量得到时频一致性损失;
结合所述时频一致性损失,所述时域总损失和所述频域总损失得到模型总损失,计算公式为:
L=x(L1+L2)+(1-x)L3
其中,L为模型总损失,L1为时域总损失,L2为频域总损失,L3为时频一致性损失,x为对比损失权重参数;
通过所述模型总损失的约束,训练预设KPI数据集得到KPI数据通用表示模型。
基于变换一致性构建正负样本对,利用时域对比损失和频域对比损失分别训练时域编码器和频域编码器用于提取时间序列的时域特征和频域特征。随机采用一种增强方法对原始输入序列进行变换从而得到增强时间序列,利用对比学习的思想鼓励模型学习原始时间序列与增强时间序列变换不变的表征。分别将时域特征和频域特征映射到高维潜在的时频空间,用时频一致性来识别一个在时间序列数据集上保留的一般属性,并使用它来诱导迁移学习,以进行有效的预训练。
本发明实施例的计算机存储介质,可以采用一个或多个计算机可读的介质的任意组合。计算机可读介质可以是计算机可读信号介质或者计算机可读存储介质。计算机可读存储介质例如可以是但不限于电、磁、光、电磁、红外线、或半导体的系统、装置或器件,或者任意以上的组合。计算机可读存储介质的更具体的例子(非穷举的列表)包括:具有一个或多个导线的电连接、便携式计算机磁盘、硬盘、随机存取存储器(RAM)、只读存储器(ROM)、可擦式可编程只读存储器(EPROM或闪存)、光纤、便携式紧凑磁盘只读存储器(CD-ROM)、光存储器件、磁存储器件、或者上述的任意合适的组合。在本文件中,计算机可读存储介质可以是任何包含或存储程序的有形介质,该程序可以被指令执行系统、装置或者器件使用或者与其结合使用。
计算机可读的信号介质可以包括在基带中或者作为载波一部分传播的数据信号,其中承载了计算机可读的程序代码。这种传播的数据信号可以采用多种形式,包括但不限于电磁信号、光信号或上述的任意合适的组合。计算机可读的信号介质还可以是计算机可读存储介质以外的任何计算机可读介质,该计算机可读介质可以发送、传播或者传输用于由指令执行系统、装置或者器件使用或者与其结合使用的程序。
计算机可读介质上包含的程序代码可以用任何适当的介质传输,包括但不限于无线、电线、光缆、RF等等,或者上述的任意合适的组合。可以以一种或多种程序设计语言或其组合来编写用于执行本发明操作的计算机程序代码,所述程序设计语言包括面向对象的程序设计语言—诸如Java、Smalltalk、C++,还包括常规的过程式程序设计语言—诸如“C”语言或类似的程序设计语言。程序代码可以完全地在用户计算机上执行、部分地在用户计算机上执行、作为一个独立的软件包执行、部分在用户计算机上部分在远程计算机上执行、或者完全在远程计算机或服务器上执行。在涉及远程计算机的情形中,远程计算机可以通过任意种类的网络,包括局域网(LAN)或广域网(WAN),连接到用户计算机,或者,可以连接到外部计算机(例如利用因特网服务提供商来通过因特网连接)。
以上所述,仅是本发明的较佳实施例而已,并非对本发明作任何形式上的限制,虽然本发明已以较佳实施例揭示如上,然而并非用以限定本发明,任何本领域技术人员,在不脱离本发明技术方案范围内,当可利用上述揭示的技术内容做出些许更动或修饰为等同变化的等效实施例,但凡是未脱离本发明技术方案内容,依据本发明的技术实质对以上实施例所作的任何简介修改、等同变化与修饰,均仍属于本发明技术方案的范围内。
- 一种基于自我注意力机制与时序卷积网络的工业设备故障预测方法
- 基于时序表征和多级注意力的超短期风电功率预测方法及预测系统