一种基于时序生成的工业过程不平衡故障分类方法
文献发布时间:2024-04-18 19:58:30
技术领域
本发明属于工业过程领域,涉及一种基于时序生成的工业过程不平衡故障分类方法。
背景技术
在当今工业领域,随着信息化和大数据技术的飞速发展,工业过程的监测和管理日益趋向智能化与自动化。然而,由于工业过程的复杂性和多变性,故障仍然是影响生产效率和质量的主要因素之一。因此,开发一种高效准确的故障分类方法变得至关重要。
传统的故障分类方法通常基于人工经验和规则,受限于专家知识和经验的局限性,难以适应多样化和快速变化的工业环境。而随着工业过程中数据的不断积累,利用大数据分析和人工智能技术能够从海量的工业数据中提取潜在的关联性和规律,为故障分类提供更加可靠的依据。然而现有的一些针对图像处理和信号处理的分类方法很难直接应用到工业过程的故障分类上,因为这类方法大都是在各类别样本均匀的场景下构建的。而在故障分类问题中,故障数据量往往远小于正常数据量,不能直接套用一般的分类方法。
发明内容
针对现有技术的不足,本发明提出一种基于时序生成的工业过程不平衡故障分类方法,利用序列化罕见故障的时序数据,维护数据动态关系,复用并生成故障的时序数据等手段,能够对动态过程中出现的罕见故障进行分类,稳定性高、鲁棒性好、泛化性能优异。
为实现上述目的,本发明采用的技术方案如下:
一种基于时序生成的工业过程不平衡故障分类方法,该方法包括以下步骤:
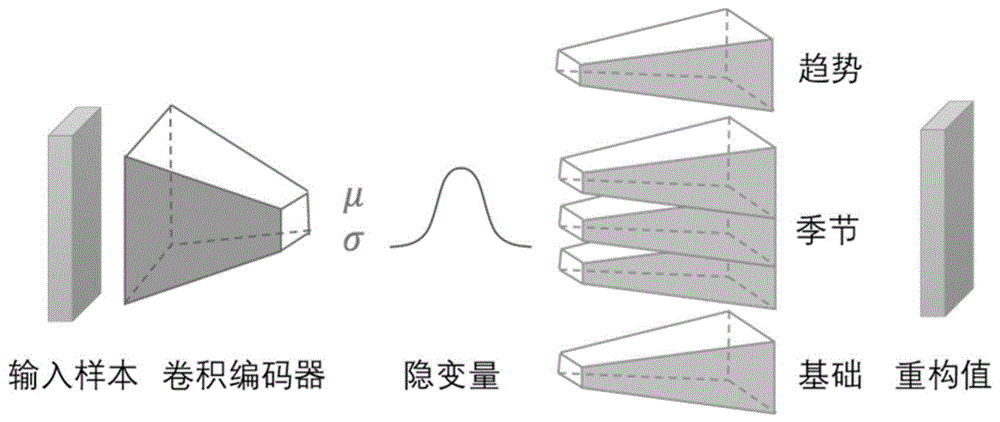
步骤一:基于时间序列的工业过程数据,针对每个故障,构建并训练一个深度生成模型,生成一定量故障的时序数据,用于平衡工业过程中正常的时序数据和故障的时序数据;所述深度生成模型包括:
将输入样本映射到隐层空间的基于卷积神经网络的卷积解码器;
将所述隐层空间的隐变量还原为时序分解的基础输出的基于卷积神经网络的卷积解码器;
将所述隐层空间的隐变量转换为趋势输出的趋势多层感知机;
将所述隐层空间的隐变量转换为多个季节中间向量,得到季节输出的多个季节多层感知机;
所述深度生成模型的输出为所述卷积解码器和所有的多层感知机的输出的和;
步骤二:基于平衡的工业过程时序数据,构建并训练分类器,进行故障分类;所述分类器包括用于提取高维空间特征的长短时记忆网络,以及用于故障分类的多层感知机和softmax函数。
进一步地,所述步骤一包括如下子步骤:
步骤(1.1):将序列化的工业过程数据分为训练集输入样本X
步骤(1.2):将输入样本通过基于卷积神经网络的卷积编码器映射到隐层空间,得到隐变量特征均值z
步骤(1.3):并列执行如下三个操作:
(1)将隐变量z通过基于卷积神经网络的卷积解码器还原为时序分解的基础输出V
(2)将隐变量z使用趋势多层感知机转换为趋势中间向量U
(3)将隐变量z使用m个季节多层感知机转换为季节中间向量
步骤(1.4):求得输入样本X的重构值
步骤(1.5):定义所述步骤(1.2)至步骤(1.4)所构建的深度生成模型损失函数为
步骤(1.6):使用步骤(1.1)中的训练集数据对步骤(1.2)至步骤(1.4)所构建的深度生成模型进行训练,利用随机梯度迭代算法,对各网络参数进行梯度迭代更新,具体策略如下所示:
卷积编码器网络参数
步骤(1.7):依据已采集的故障数据,针对每个故障构建一个所述深度生成模型,用以按需生成一定量故障的时序数据。
进一步地,所述步骤(1.7)中,某一类故障的时序数据生成过程如下:从高斯分布中随机采样得到一组隐变量z,重复步骤(1.2)至步骤(1.4),生成对应数量故障的时序数据。
进一步地,所述步骤二包括如下子步骤:
步骤(2.1):将已采集的经序列化的工业过程时序数据和步骤一中按需生成的故障时序数据作为类别平衡的工业过程时序数据;将这些数据分为训练集输入样本X
步骤(2.2):使用长短时记忆网络提取输入样本X的高维空间特征V
步骤(2.3):基于高维空间特征V
步骤(2.4):构建交叉熵L作为步骤(2.2)至步骤(2.3)所构建的分类器的损失函数,使用步骤(2.1)中的训练集数据对步骤(2.2)至步骤(2.3)所构建的分类器进行训练,利用随机梯度迭代算法,对各网络参数进行梯度迭代更新,具体策略如下所示:
长短时记忆网络参数
步骤(2.5):使用步骤(2.4)中训练得到的分类器,对工业过程时序数据进行故障分类,得到故障分类结果。
进一步地,当采集的工业过程原始数据为非时间序列的原始数据时,需要先将采集的工业过程原始数据按照时间序列长度依次进行顺序序列化,生成时间序列数据。
进一步地,工业过程的原始数据为{x
本发明的有益效果如下:
相比于正常的工业过程时序数据,故障的时序数据较为稀少。现有的分类器技术很难对不平衡故障进行准确分类。本发明提出一种基于时序生成的工业过程不平衡故障分类方法,通过深度生成模型生成时序数据,维护数据动态关系,有效地解决了故障数据稀少条件下的工业过程时序数据故障分类问题,分类准确性高,泛化性能好。
附图说明
图1为Tennessee Eastman(TE)过程流程图。
图2为深度生成网络的示意图。
图3为故障分类器的网络结构图。
具体实施方式
下面根据附图和优选实施例详细描述本发明,本发明的目的和效果将变得更加明白,应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
本发明针对工业过程中故障数据稀少问题,提出了一种基于时序生成的工业过程不平衡故障分类方法,有效地提高了工业过程故障分类的准确性。以下结合TennesseeEastman过程(以下简称TE过程)对本发明作进一步阐释和有效性说明。
图1给出了TE过程的工艺流程图,TE过程由反应器、冷凝器、分离器、压缩机和剥离器五个操作单元构成。主要产物有气体A、C、D、E,惰性气体B,液体G、H和副产品F。该过程共有41个测量变量和11个操作变量,本例选择前22个过程变量(编号1-22)和11个操作变量(编号23-33)作为工业过程数据,用于故障诊断,即样本维度n=33,具体说明参见表1。
表1:TE变量说明
本例选择的训练数据集包括了500个正常工况的样本,400个故障1的样本,300个故障2的样本,200个故障6的样本,100个故障12的样本;测试数据集包括了100个正常工况的样本,100个故障1的样本,100个故障2的样本,100个故障6的样本,100个故障12的样本。并采用准确率
表2:混淆矩阵
本实施例的基于时序生成的工业过程不平衡故障分类方法,包括如下步骤:
步骤(1),序列化工业过程数据。取时间序列长度为t=10,经序列化后可得到491个正常工况的训练样本,391个故障1的训练样本,291个故障2的训练样本,191个故障6的训练样本,91个故障12的训练样本,91个正常工况的测试样本,91个故障1的测试样本,91个故障2的测试样本,91个故障6的测试样本,91个故障12的测试样本。
步骤(2),基于步骤(1)序列化得到的工业过程时序数据,在Tensorflow平台上构建4个时序数据深度生成模型,网络结构图如图2所示。分别用于生成100个故障1的分类训练样本、200个故障2的分类训练样本、300个故障6的分类训练样本、400个故障12的分类训练样本,使得所有类别的分类训练样本均为491个,平衡了工业过程正常的时序数据和故障的时序数据。
步骤(2.1),分别准备好用于构建4个深度生成模型的原始训练数据和测试数据;
步骤(2.2),将输入样本X通过基于卷积神经网络的卷积编码器映射到隐层空间,得到隐变量特征均值z
步骤(2.3):并列执行如下三个操作:
(1)将隐变量z通过基于卷积神经网络的卷积解码器还原为时序分解的基础输出V
(2)将隐变量z使用趋势多层感知机转换为趋势中间向量U
(3)定义季节模式个数m=4,每个季节模式的季节数ns=[2,3,4,5],每个季节模式的季节长度ls=[1,1,1,1]。使用4个多层感知机分别将隐变量z转换为季节中间向量
步骤(2.4),求得输入样本X的重构值
步骤(2.5),定义前述步骤(2.2)至步骤(2.4)所构建的深度生成模型损失函数为
步骤(2.6),使用步骤(2.1)中的训练集数据对步骤(2.2)至步骤(2.4)所构建的4个深度生成模型分别进行训练,利用随机梯度迭代算法,对各网络参数进行梯度迭代更新,具体策略如下所示:
卷积编码器的网络参数
步骤(2.7),使用故障1对应的时序数据深度生成模型,从高斯分布中随机采样得到100个隐变量z,重复步骤(2.2)至步骤(2.4),生成100个故障1的分类训练样本。使用故障2时序数据深度生成模型,从高斯分布中随机采样得到200个隐变量z,重复步骤(2.2)至步骤(2.4),生成200个故障2的分类训练样本;使用故障6时序数据深度生成模型,从高斯分布中随机采样得到300个隐变量z,重复(2.2)至步骤(2.4),生成300个故障6的分类训练样本;使用故障12时序数据深度生成模型,从高斯分布中随机采样得到400个隐变量z,重复步骤(2.2)至步骤(2.4),生成400个故障12的分类训练样本。
步骤(3),基于平衡的工业过程时序数据构建分类器,网络结构如图3所示,进行故障分类。
步骤(3.1),将原始的经序列化的工业过程时序数据和步骤(2)中按需生成的故障时序数据随机混合作为类别平衡的工业过时序数据。
步骤(3.2),使用长短时记忆网络提取输入样本X的高维空间特征V
步骤(3.3):基于高维空间特征V
步骤(3.4),使用交叉熵L作为前述步骤(3.2)至步骤(3.3)所构建的分类器的损失函数。使用步骤(3.1)中所述训练集数据对步骤(3.2)至步骤(3.3)所构建的分类器进行训练,利用随机梯度迭代算法,对各网络参数进行梯度迭代更新,具体策略如下所示:
长短时记忆网络参数
步骤(3.5),使用步骤(3.4)中训练得到的分类器,对91个正常工况的测试样本,91个故障1的测试样本,91个故障2的测试样本,91个故障6的测试样本,91个故障12的测试样本进行故障分类,得到故障分类效果评价如表3所示。
表3:本例故障分类效果评价
若直接使用原始故障不平衡的训练数据训练基于softmax函数的分类器,其在同样测试集上的故障分类效果评价如表4所示。
表4:原始不平衡故障分类效果评价
相比其他故障分类方法,本发明提出的一种基于时序生成的工业过程不平衡故障分类方法通过时序数据生成方法,平衡了正常数据和故障数据的样本数量。在故障时序数据稀少的情况下,取得了更好的故障分类效果。
本领域普通技术人员可以理解,以上所述仅为发明的优选实例而已,并不用于限制发明,尽管参照前述实例对发明进行了详细的说明,对于本领域的技术人员来说,其依然可以对前述各实例记载的技术方案进行修改,或者对其中部分技术特征进行等同替换。凡在发明的精神和原则之内,所做的修改、等同替换等均应包含在发明的保护范围之内。
- 基于偏F值SELM的多变量工业过程故障分类方法
- 一种基于深度学习的智能制造过程故障分类方法及装置
- 一种基于k‑means的二叉SVM‑tree不平衡数据工业故障分类方法
- 一种基于k‑means的不平衡数据工业故障分类方法