一种半监督的多类别Boosting分类方法
文献发布时间:2023-06-19 09:33:52
技术领域:
本发明涉及图像处理技术领域,具体涉及一种半监督的多类别Boosting分类方法。
背景技术:
随着电子设备的发展,在互联网和日常社会交往中产生的视觉图像数据或非视觉文本数据越来越多。大多数生成的数据是未分类或未标记的,因此很难使用监督方法进行图像和文档分类等操作。因此,半监督学习(SSL)在机器学习和数据挖掘研究中受到越来越多的关注。SSL的核心思想,特别是半监督分类是利用有标签和无标签的数据来学习分类模型。对于给定分类器,半监督Boosting的目标是利用标签数据的监督信息及其与无标签数据之间的关系来提高其分类性能。特别地,在现在Boosting算法中利用无标签数据可以获得更好性能的Boosted分类器。
在半监督Boosting策略中,需要相似度,如图2所示。利用相似度选择可靠的无标签样本训练新的集成(组合)分类器。由于欧氏距离计算简单,大多数策略中使用欧氏距离衡量样本间的相似度。然而,相似度(或距离度量)学习在Boosting任务中起着至关重要的作用,其原因有两个:第一,通常假设两个具有高度相似性的样本属于同一类;其次,由于数据的非线性,欧氏距离不能代表数据的结构非线性关系,特别是在高维空间。在半监督Boosting策略中,使用欧氏距离计算高斯核相似度,然而高斯核相似性中的核宽度如何设置,也是个要解决的问题。
最近,在数据相似性的自适应领域,基于稀疏编码的表示受到广泛的关注,本发明中也使用稀疏表示作为相似度的衡量。在稀疏表示学习中,当构造分类器或其他预测变量时,学习数据的可判别信息和对数据进行有效的可视化表示使得对数据提取信息特征变得更加容易。众所周知,由于传统的稀疏和低秩表示(LRRs)计算量大,不能满足实时应用的要求。此外,学习到的数据表示仍然缺乏捕捉来自不同对象的观察输入的潜在解释因子的可判别属性。而且在很多情况下,图像识别问题会因为图像被遮挡而变得复杂,例如面部图像带了墨镜、头饰、围巾、口罩、面部毛发或手。在这种情况下,使用局部图像信息的识别方法比整体直方图特征具有优势。从遮挡区域提取的特征将丢失,但从未遮挡区域提取的特征不会丢失,并且可能足以对图像进行准确分类。分类决策通常使用最近邻算法、支持向量机或Boosting策略获得。
为了解决上述问题,本发明在半监督Boosting策略中提出了一种边距结构表示的模块化的稀疏表示学习方法(MSPASEMIBOOST)来实现高效、有效地计算图像之间的相似性,本案由此而生。
发明内容:
本发明提供了一种视觉分类方法,实现了一种模块化的基于联合柔性自调整边距目标分析、判别子空间构造和概率图结构自适应的边距视觉表示学习半监督Boosting框架。确保所得到的数据表示法具有明显的判别能力,且具有接近最优的边距,提升了视觉分类的准确性。
为了实现上述目的,本发明所采用的技术方案为:
一种半监督的多类别Boosting分类方法,内容包括如下步骤:
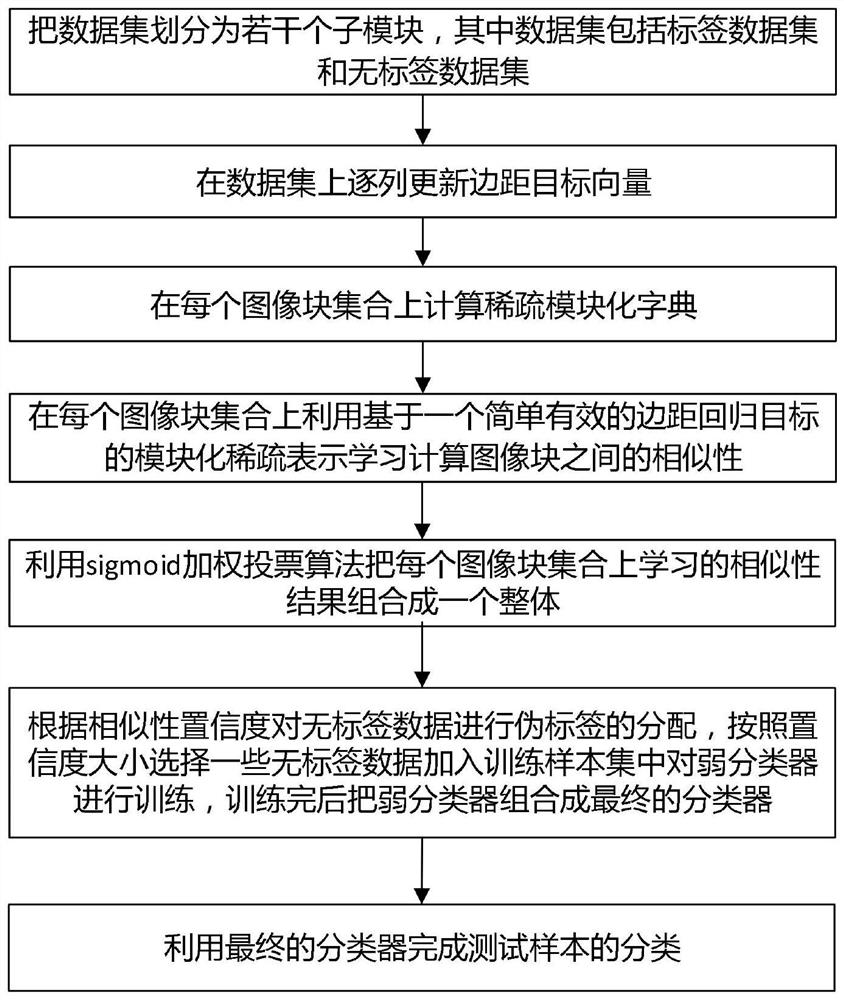
步骤1:把数据集划分为若干个子模块,其中数据集包括标签数据集和无标签数据集;
步骤2:在数据集上逐列更新边距目标向量;
步骤3:在每个图像块集合上计算稀疏模块化字典;
步骤4:在每个图像块集合上利用基于边距回归目标的模块化稀疏表示学习计算图像块之间的相似性;
步骤5:利用sigmoid加权投票算法把每个图像块集合上学习的相似性结果组合成一个整体;
步骤6:根据相似性置信度对无标签数据进行伪标签的分配,按照置信度大小选择一些无标签数据加入训练样本集中并对弱分类器进行训练,训练完后把弱分类器组合成最终的分类器;
步骤7:利用最终的分类器完成测试样本的分类。
进一步,所述步骤1中将数据集X划分为M个子模块,其中包含n
进一步,所述步骤2中在数据集上逐列更新边距目标向量的内容包括以下步骤:
输入:数据集X、字典D、真实的类标签编号c,其中c∈{1,...,1,2,...,2,...,C,...,C},C为数据的总类别数目;
步骤2.1:设表达式如下:W=D
步骤2.2:当j≤C循环;
若j≠c,
若ψ′(ζ)>0,则ζ=ζ+g
j=j+1;
步骤2.3:ζ=ζ/(1+t);
步骤2.4:通过下式逐列更新边距目标向量S的第j列,即S
其中,
输出:边距目标向量S。
进一步,所述步骤3中在每个图像块集合上计算稀疏模块化字典,包含以下步骤:
输入:数据集X,划分为M个子模块,其中n
步骤3.1:设iter=0,在数据集X上使用KSVD初始化字典D
步骤3.2:循环;
步骤3.3:令变量m=1;
步骤3.4:循环;
步骤3.5:Z=F
步骤3.6:
步骤3.7:D
步骤3.8:[U,∑,V
步骤3.9:F=UV
步骤3.10:使用权利要求1所述的步骤2逐列更新边距目标向量S;
步骤3.11:使用下式逐行更新P
其中,p
步骤3.12:更新E=diag(sum(P
步骤3.13:m=m+1;
步骤3.14:直到m>M;
步骤3.15:iter=iter+1;
步骤3.16:直到iter>30或满足收敛条件;
输出:稀疏模块化字典D
进一步,所述步骤4中在每个图像块集合上利用基于边距回归目标的模块化稀疏表示学习计算图像块之间的相似性,以及步骤5中利用sigmoid加权投票算法把每个图像块集合上学习的相似性结果组合成一个整体,具体内容包括如下步骤:
输入:稀疏模块化字典D
步骤5.1:用正交匹配追踪算法求解测试样本y的M个子模块稀疏系数,即
步骤5.2:利用式
步骤5.3:构造y
步骤5.4:使用式
步骤5.5:使用式
步骤5.6:使用sigmoid函数
步骤5.7:使用sigmoid函数
步骤5.8:使用式
步骤5.9:计算子模块y
步骤5.10:将测试样本y的第k个子模块的残差ry
步骤5.11:通过将测试样本y的所有模块上每类获得的总票数进行加权求和,计算每类获得总票数
步骤5.12:计算
输出:测试样本y的稀疏表示系数
进一步,所述步骤6中根据相似性置信度对无标签数据进行伪标签的分配,按照置信度大小选择一些无标签数据加入训练样本集中并对弱分类器进行训练,训练完后把弱分类器组合成最终的分类器,上述具体内容包括如下步骤:
输入:数据集X,划分为M个子模块,其中具有n
步骤6.1:分别计算权值:
步骤6.2:初始化分类器H(X)=0;
步骤6.3:使用权利要求1所述的步骤4求出数据集X的稀疏系数O
步骤6.4:计算无标签数据x
步骤6.5:把x
步骤6.6:使用式
步骤6.7:更新分类器:H(X)=H(X)+αh(x
输出:最终的分类器H(X)。
进一步,所述步骤7中利用最终的分类器完成测试样本的分类内容如下:
首先,根据最终分类器计算测试样本归为第k类的置信度,k=1,2,...,C;
其次,测试样本的标签就是最大置信度对应的k值。
本发明所公开的视觉分类方法,边距回归目标学习没有使用固定的0-1矩阵作为回归目标,而是直接构建了具有较好的近似最优边距约束的自调整回归目标,可以更准确地测量回归结果;为了捕获具有数据连通性的潜在结构,使用概率图形结构自适应指导边距回归目标的构建,回归结果进一步在数据的判别潜在子空间中进行预测,从而捕捉潜在的相关模式;由此得到的数据表示法具有明显的判别能力,且具有接近最优的边距,进而提升了视觉分类的准确性。
附图说明:
图1为本发明的视觉分类方法的流程示意图;
图2为本发明的视觉分类方法的半监督Boosting策略;
图3为本发明的图像块残差度的权重函数图;
图中:ry
图4为本发明的图像块稀疏度的权重函数图;
图中sy
图5为一组本实施例Extended YaleB人脸数据集的示意图;
图6为一组本实施例CMU PIE人脸的示意图;
图7为一组本实施例AR人脸的示意图;
图8为一组本实施例COIL-100数据集的示意图;
图9为本实施例在Extended YaleB人脸集上与其他算法比较的结果图;
图10为本实施例在CMP PIE人脸集上与其他算法比较的结果图;
图11为本实施例在AR人脸集上与其他算法比较的结果图;
图12为本实施例在COIL-100数据集上与其他算法比较的结果图。
具体实施方式:
本实施例公开一种半监督的多类别Boosting分类方法,如图1至图4所示,该方法的内容介绍如下:
步骤1:把数据集X划分为M个子模块,其中包含n
标签数据集表示为X
步骤2:在数据集上逐列更新边距目标向量,具体方法如下:
输入:数据集X、字典D、真实的类标签编号c,其中c∈{1,...,1,2,...,2,...,C,...,C},C为数据的总类别数目;
步骤2.1):设表达式如下:W=D
步骤2.2):当j≤C循环;
若j≠c,
若ψ′(ζ)>0,则ζ=ζ+g
j=j+1;
步骤2.3):ζ=ζ/(1+t);
步骤2.4):通过下式逐列更新边距目标向量S的第j列,即S
其中,
输出:边距目标向量S。
步骤3:在每个图像块集合上计算稀疏模块化字典,具体方法如下:
输入:数据集X,划分为M个子模块,其中n
步骤3.1):设iter=0,在数据集X上使用KSVD初始化字典D
步骤3.2):循环;
步骤3.3):令变量m=1;
步骤3.4):循环;
步骤3.5):Z=F
步骤3.6):
步骤3.7):D
步骤3.8):[U,∑,V
步骤3.9):F=UV
步骤3.10):使用权利要求1所述的步骤2逐列更新边距目标向量S;
步骤3.11):使用下式逐行更新P
其中,p
步骤3.12):更新E=diag(sum(P
步骤3.13):m=m+1;
步骤3.14):直到m>M;
步骤3.15):iter=iter+1;
步骤3.16):直到iter>30或满足收敛条件;
输出:稀疏模块化字典D
步骤4:在每个图像块集合上利用基于边距回归目标的模块化稀疏表示学习计算图像块之间的相似性;
步骤5:利用sigmoid加权投票算法把每个图像块集合上学习的相似性结果组合成一个整体;
上述步骤4和步骤5的具体操作方法详述如下:
输入:稀疏模块化字典D
步骤5.1):用正交匹配追踪算法求解测试样本y的M个子模块稀疏系数,即
步骤5.2):利用式
步骤5.3):构造y
步骤5.4):使用式
步骤5.5):使用式
步骤5.6):使用sigmoid函数
步骤5.7):使用sigmoid函数
步骤5.8):使用式
步骤5.9):计算子模块y
步骤5.10):将测试样本y的第k个子模块的残差ry
步骤5.11):通过将测试样本y的所有模块上每类获得的总票数进行加权求和,计算每类获得总票数
步骤5.12):计算
输出:测试样本y的稀疏表示系数
步骤6:根据相似性置信度对无标签数据进行伪标签的分配,按照置信度大小选择一些无标签数据加入训练样本集中并对弱分类器进行训练,训练完后把弱分类器组合成最终的分类器;此步骤具体内容说明如下:
输入:数据集X,划分为M个子模块,其中具有n
步骤6.1):分别计算权值:
步骤6.2):初始化分类器H(X)=0;
步骤6.3):使用权利要求1所述的步骤4求出数据集X的稀疏系数O
步骤6.4):计算无标签数据x
步骤6.5):把x
步骤6.6):使用式
步骤6.7):更新分类器:H(X)=H(X)+αh(x
输出:最终的分类器H(X)。
步骤7:利用最终的分类器完成测试样本的分类,具体内容如下:
首先,根据最终分类器计算测试样本归为第k类的置信度,k=1,2,...,C;
其次,测试样本的标签就是最大置信度对应的k值。
为了验证上述本发明所公开的分类方法其相对于现有其他算法的优越性,本实施例中分别在Extended YaleB人脸集、CMP PIE人脸集、AR人脸集、COIL-100数据集上应用本发明方法与其他算法进行了比较,以下将以实际验证实施例加以展示(如图5至图12所示)。
在对比实施例中,数据集划分的M个子模块中将M设置为9,Extended YaleB数据集类别数C为38,CMU PIE数据集类别数C为68,AR数据集类别数C为126,COIL-100数据集类别数C为100。每种数据集分别进行四次试验,对于Extended YaleB和CMU PIE,从每名受试者中随机选择10、15、20和25张图像作为训练集,其余的图像作为测试集;对于AR数据集,从每名受试者中随机选择8、11、14和17幅图像作为训练集,其余的图像作为测试集;对于COIL-100数据集,随机选择每个对象10、15、20、25张图像作为训练样本,其余图像作为测试样本。按照上述给出的方法进行步骤3时,本实施例中λ
将本发明所公开的视觉分类方法分别与DLSR算法(S.Xiang,F.Nie,G.Meng,C.Panand C.Zhang,“Discriminative least squares regression for multiclassclassification and feature selection,”IEEE Trans.Neural Netw.Learn.Syst.,vol.23,no.11,pp.1738-1754,Nov.2012,10.1109/TNNLS.2012.2212721)、SLRM算法(L.Jing,L.Yang,J.Yu and M.K.Ng,“Semi-supervised low-rank mapping learning formulti-label classification,”in Proc.IEEE Conf.Comput.Vis.Pattern Recognit.,Boston,MA,USA,2015,pp.1483–1491.)、MSRL算法(Z.Zhang,L.Shao,Y.Xu,L.Liu and JianYang,“Marginal Representation Learning With Graph Structure Self-Adaptation,”IEEE Transactions On Neural Networks And Learning Systems,vol.29,no.10,pp.4645-4659,Dec.2018,10.1109/TNNLS.2017.2772264.)、XGBOOST算法(T.Chen and C,Guestrin,“Xgboost:A scalable tree boosting system,”in Proc.ACM SIGKDDInt.Conf.Knowl.Discovery Data Mining,San Francisco,CA,USA,2016,pp.785–794.)进行了对比,如图9至图12所示,附图中的MSPASEMIBOOST表示采用本发明方法。
由图9所展示实验发现,在Extended YaleB人脸数据集上,本发明方法得到的平均的识别率为97.05%,DLSR方法得到的平均的识别率为92.71%,SLRM方法得到的平均的识别率为89.6%,MSRL方法得到的平均的识别率为94.97%,XGBOOST方法得到的平均的识别率为93.78%,与其他算法相比,采用本发明方法识别率平均提升了大约2%,可以看出本发明方法优于其余方法。
由图10所展示实验发现,在CMU PIE人脸数据集上,本发明方法得到的平均的识别率为94.43%,DLSR方法得到的平均的识别率为90.12%,SLRM方法得到的平均的识别率为88.81%,MSRL方法得到的平均的识别率为92.83%,XGBOOST方法得到的平均的识别率为90.63%,与其他算法相比,采用本发明方法识别率平均提升了大约1.6%,可以看出本发明方法优于其余方法。
由图11所展示实验发现,在AR人脸数据集上,本发明方法得到的平均的识别率为97.72%,DLSR方法得到的平均的识别率为91.88%,SLRM方法得到的平均的识别率为92.11%,MSRL方法得到的平均的识别率为94.87%,XGBOOST方法得到的平均的识别率为92.61%,与其他算法相比,采用本发明方法识别率平均提升了大约3%,可以看出本发明方法优于其余方法。
由图12所展示实验发现,在COIL-100人脸数据集上,本发明方法得到的平均的识别率为96.90%,DLSR方法得到的平均的识别率为88.24%,SLRM方法得到的平均的识别率为89.04%,MSRL方法得到的平均的识别率为93.22%,XGBOOST方法得到的平均的识别率为92.10%,与其他算法相比,采用本发明方法识别率平均提升了大约4%,可以看出本发明方法优于其余方法。
本实施例所展示的一种视觉分类方法,在半监督Boosting框架中利用模块化稀疏表示计算无标签样本与标签样本之间的相似性,无缝地将回归目标的局部一致性和全局一致性合并到一个处理数据表示问题的公共框架中。从数据中学习的边距目标为拟合回归任务提供了足够的灵活性。同时,利用数据的潜在信息进行目标预测。与本发明所述的其他表示方法相比,所述学习数据表示方法具有更强的信息和判别能力。通过迭代优化策略有效地解决了问题。此外,在四个数据集上的实验结果表明,本实施例所述的方法优于其他的数据表示算法,这表明了本实施例所述的方法的有效性。
在此说明书中,本发明已参照其特定的实施例作了描述。但是,很显然仍可以作出各种修改和变换而不背离本发明的精神和范围。因此,说明书和附图应被认为是说明性的而非限制性的。
- 一种半监督的多类别Boosting分类方法
- 基于地物类别隶属度评分的高光谱遥感图像半监督分类方法