恶意社群发现方法、装置、计算机设备和可读存储介质
文献发布时间:2023-06-19 09:43:16
技术领域
本申请涉及计算机技术领域,特别是涉及一种恶意社群发现方法、装置、计算机设备和可读存储介质。
背景技术
在电商场景中,可能存在某些社群存在刷单团伙或者黄牛团伙的情况,若不对这些社群进行恶意群体检测,会导致平台的风险控制能力过低以及运营成本过高的问题,同时,还会导致用户体验感差的问题。
在相关技术中,采用社区发现算法对社群中的恶意群体进行检测,以提高平台的风险控制能力。然而,采用这种方法只能实现单一属性节点的社群发现,仅靠单一属性节点的社群发现结果,无法准确地对社群中的恶意群体进行定位,从而无法实现对恶意群体所在社群的精准拦截。
目前针对相关技术中,无法有效地对社群中的恶意群体进行检测的问题,尚未提出有效的解决方案。
发明内容
本申请实施例提供了一种恶意社群发现方法、装置、计算机设备和可读存储介质,以至少解决相关技术中,无法有效地对社群中的恶意群体进行检测的问题。
第一方面,本申请实施例提供了一种恶意社群发现方法,包括:
获取目标用户的下单行为数据;所述下单行为数据包括多个下单行为特征;所述下单行为特征至少包括每个目标用户的用户ID、设备ID、支付账号以及收货手机号码;
根据所述下单行为数据,对所述目标用户进行分类,得到用户分类结果;
获取用户体系关系,并根据所述用户分类结果、所述用户体系关系以及所述下单行为数据,构建第一网络拓扑图;所述第一网络拓扑图表示多个类别的目标用户之间的关联关系;所述用户体系关系包括多个用户类别之间的关联关系;
根据所述第一网络拓扑图和预设标签传播规则对所述目标用户进行分类,得到目标社群集合;所述目标社群集合包括多个目标社群;
根据预设恶意检测规则对所述目标社群集合进行恶意群体检测,得到所述目标社群集合中的恶意社群。
在其中一些实施例中,所述根据所述用户分类结果、所述用户体系关系以及所述下单行为数据,构建第一网络拓扑图包括:
根据每一类别的目标用户的用户ID、设备ID、支付账号以及收货手机号码,构建每一类别对应的第二网络拓扑图;
根据所述用户体系关系,对多个类别的所述第二网络拓扑图进行关联,得到所述第一网络拓扑图。
在其中一些实施例中,所述根据所述用户分类结果、所述用户体系关系以及所述下单行为数据,构建第一网络拓扑图包括:
以每一所述下单行为特征为节点,将每一目标用户的所述下单行为特征对应的节点相连,构建多个目标用户的第三网络拓扑图;
根据所述用户体系关系和所述用户分类结果,对多个类别的目标用户的所述第三网络拓扑图进行关联,得到所述第一网络拓扑图。
在其中一些实施例中,在所述根据所述第一网络拓扑图和预设标签传播规则,得到目标社群集合之后,所述方法还包括:
根据所述目标社群集合和所述用户体系关系,确定所述目标社群集合中缺失的用户类别,并将缺失的类别作为补充信息添加至所述目标社群集合。
在其中一些实施例中,所述根据预设恶意检测规则对所述目标社群集合进行恶意检测处理,确定所述目标社群集合中的恶意社群包括:
对所述用户ID、所述设备ID、所述支付账号以及所述收货手机号码进行去重处理,并获取每一所述目标社群对应的用户ID总数、设备ID总数、支付账号总数以及收货手机号码总数;
根据所述目标社群对应的用户ID总数、设备ID总数、支付账号总数以及收货手机号码总数,得到所述目标社群对应的第一设备浓度、第一支付账号浓度和第一手机号码浓度;所述第一设备浓度表示所述设备ID总数与所述用户ID总数之间的比例;所述第一支付账号浓度表示所述支付账号总数与所述用户ID总数之间的比例;所述第一手机号码浓度表示所述收货手机号码总数与所述用户ID总数之间的比例;
根据第一预设浓度阈值以及所述目标社群的第一设备浓度、第一支付账号浓度和第一手机号码浓度,确定所述目标社群集合中的恶意社群。
在其中一些实施例中,所述根据预设恶意检测规则对所述目标社群集合进行恶意检测处理,确定所述目标社群集合中的恶意社群包括:
设置所述第一网络拓扑图中每一节点的权值系数;
针对每一所述目标社群,基于所述权值系数,分别对所述目标社群的用户ID的对应节点、设备ID的对应节点、支付账号的对应节点以及收货手机号码的对应节点进行加权求和,得到所述目标社群的用户ID加权值、设备ID加权值、支付账号加权值和收货手机号码加权值;
根据所述用户ID加权值、所述设备ID加权值、所述支付账号加权值以及所述收货手机号码加权值,得到所述目标社群的第二设备浓度、第二支付账号浓度和第二手机号码浓度;所述第二设备浓度表示所述设备ID加权值与所述用户ID加权值之间的比例;所述第二支付账号浓度表示所述支付账号加权值与所述用户ID加权值之间的比例;所述第二手机号码浓度表示所述收货手机号码加权值与所述用户ID加权值之间的比例;
根据第二预设浓度阈值以及每个所述目标社群的第二设备浓度、第二支付账号浓度和第二手机号码浓度,确定所述目标社群集合中的恶意社群。
在其中一些实施例中,所述根据所述第一网络拓扑图和预设标签传播规则,得到目标社群集合包括:
设置所述第一网络拓扑图中每一节点的原始标签;
获取当前节点对应的相邻节点标签,所述相邻节点标签表示与所述当前节点相邻的节点的标签;
统计每一所述相邻节点标签的出现次数,并将出现次数最多的所述相邻节点标签作为所述当前节点的当前标签;
获取下一节点的相邻节点标签,并根据所述下一节点的相邻节点标签对所述下一节点的原始标签进行更新,直至所有节点的当前标签不再变化或者达到最大迭代次数,停止更新,得到更新后的第一网络拓扑图;
根据更新后的第一网络拓扑图中节点的当前标签,确定所述目标社群集合。
第二方面,本申请实施例提供了一种恶意社群发现装置,包括:
数据获取模块,用于获取目标用户的下单行为数据;所述下单行为数据包括多个下单行为特征;所述下单行为特征至少包括每个目标用户的用户ID、设备ID、支付账号以及收货手机号码;
用户分类模块,用于根据所述下单行为数据,对所述目标用户进行分类,得到用户分类结果;
拓扑图构建模块,用于获取用户体系关系,并根据所述用户分类结果、所述用户体系关系以及所述下单行为数据,构建第一网络拓扑图;所述第一网络拓扑图表示多个类别的目标用户之间的关联关系;所述用户体系关系包括多个用户类别之间的关联关系;
目标社群确定模块,用于根据所述第一网络拓扑图和预设标签传播规则对所述目标用户进行分类,得到目标社群集合;所述目标社群集合包括多个目标社群;
恶意社群检测模块,用于根据预设恶意检测规则对所述目标社群集合进行恶意群体检测,得到所述目标社群集合中的恶意社群。
第三方面,本申请实施例提供了一种计算机设备,包括存储器、处理器以及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现如上述第一方面所述的恶意社群发现方法。
第四方面,本申请实施例提供了一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现如上述第一方面所述的恶意社群发现方法。
相比于相关技术,本申请实施例提供的恶意社群发现方法、装置、计算机设备和可读存储介质,通过获取目标用户的下单行为数据;下单行为数据包括多个下单行为特征;下单行为特征至少包括每个目标用户的用户ID、设备ID、支付账号以及收货手机号码;根据下单行为数据,对目标用户进行分类,得到用户分类结果;获取用户体系关系,并根据用户分类结果、用户体系关系以及下单行为数据,构建第一网络拓扑图;第一网络拓扑图表示多个类别的目标用户之间的关联关系;用户体系关系包括多个用户类别之间的关联关系;根据第一网络拓扑图和预设标签传播规则对目标用户进行分类,得到目标社群集合;目标社群集合包括多个目标社群;根据预设恶意检测规则对目标社群集合进行恶意群体检测,得到目标社群集合中的恶意社群,解决了相关技术中,无法有效地对社群中的恶意群体进行检测的问题。
本申请的一个或多个实施例的细节在以下附图和描述中提出,以使本申请的其他特征、目的和优点更加简明易懂。
附图说明
此处所说明的附图用来提供对本申请的进一步理解,构成本申请的一部分,本申请的示意性实施例及其说明用于解释本申请,并不构成对本申请的不当限定。在附图中:
图1为本申请实施例的恶意社群发现方法的流程图;
图2为本申请实施例中构建第一网络拓扑图的流程图一;
图3为本申请实施例中构建第一网络拓扑图的流程图二;
图4为本申请实施例中确定目标社群集合中的恶意社群的流程图一;
图5为本申请实施例中确定目标社群集合中的恶意社群的流程图二;
图6为本申请实施例中根据第一网络拓扑图和预设标签传播规则,得到目标社群集合的流程图;
图7为本申请具体实施例的恶意社群发现方法的构架示意图;
图8为本申请具体实施例的目标社群集合在第一网络拓扑图中的示意图;
图9为本申请实施例的恶意社群发现装置的结构框图;
图10为本申请实施例的恶意社群发现设备的硬件结构示意图。
具体实施方式
为了使本申请的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本申请进行描述和说明。应当理解,此处所描述的具体实施例仅仅用以解释本申请,并不用于限定本申请。基于本申请提供的实施例,本领域普通技术人员在没有作出创造性劳动的前提下所获得的所有其他实施例,都属于本申请保护的范围。
显而易见地,下面描述中的附图仅仅是本申请的一些示例或实施例,对于本领域的普通技术人员而言,在不付出创造性劳动的前提下,还可以根据这些附图将本申请应用于其他类似情景。此外,还可以理解的是,虽然这种开发过程中所作出的努力可能是复杂并且冗长的,然而对于与本申请公开的内容相关的本领域的普通技术人员而言,在本申请揭露的技术内容的基础上进行的一些设计,制造或者生产等变更只是常规的技术手段,不应当理解为本申请公开的内容不充分。
在本申请中提及“实施例”意味着,结合实施例描述的特定特征、结构或特性可以包含在本申请的至少一个实施例中。在说明书中的各个位置出现该短语并不一定均是指相同的实施例,也不是与其它实施例互斥的独立的或备选的实施例。本领域普通技术人员显式地和隐式地理解的是,本申请所描述的实施例在不冲突的情况下,可以与其它实施例相结合。
除非另作定义,本申请所涉及的技术术语或者科学术语应当为本申请所属技术领域内具有一般技能的人士所理解的通常意义。本申请所涉及的“一”、“一个”、“一种”、“该”等类似词语并不表示数量限制,可表示单数或复数。本申请所涉及的术语“包括”、“包含”、“具有”以及它们任何变形,意图在于覆盖不排他的包含;例如包含了一系列步骤或模块(单元)的过程、方法、系统、产品或设备没有限定于已列出的步骤或单元,而是可以还包括没有列出的步骤或单元,或可以还包括对于这些过程、方法、产品或设备固有的其它步骤或单元。本申请所涉及的“连接”、“相连”、“耦接”等类似的词语并非限定于物理的或者机械的连接,而是可以包括电气的连接,不管是直接的还是间接的。本申请所涉及的“多个”是指两个或两个以上。“和/或”描述关联对象的关联关系,表示可以存在三种关系,例如,“A和/或B”可以表示:单独存在A,同时存在A和B,单独存在B这三种情况。字符“/”一般表示前后关联对象是一种“或”的关系。本申请所涉及的术语“第一”、“第二”、“第三”等仅仅是区别类似的对象,不代表针对对象的特定排序。
本申请中描述的各种技术可以应用于各种电商风控设备、装置、系统以及平台。
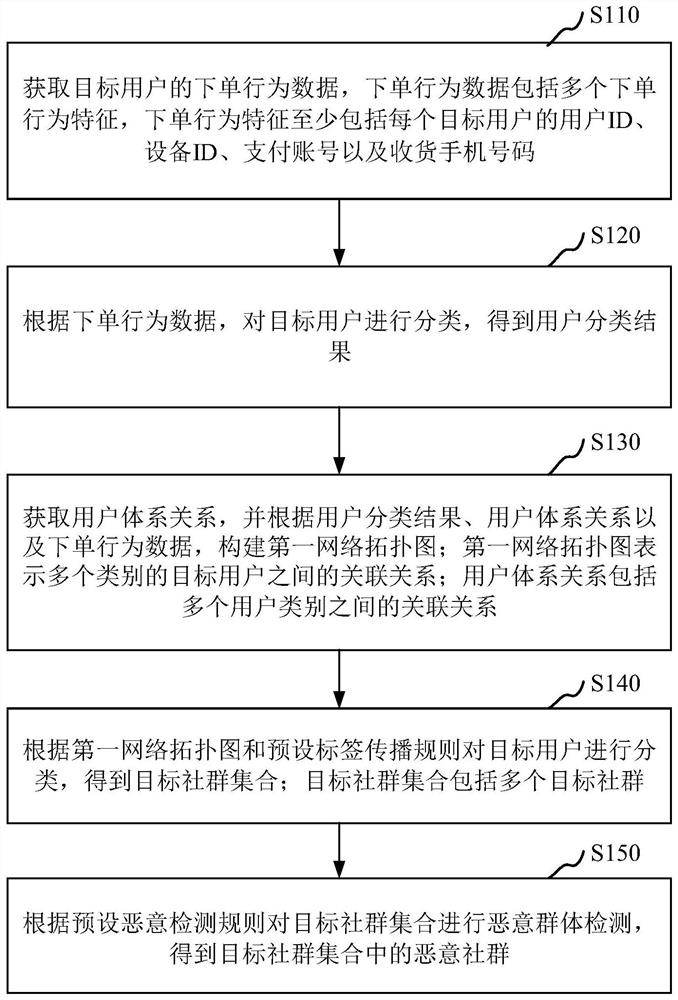
图1为本申请实施例的恶意社群发现方法的流程图,如图1所示,该流程包括如下步骤:
步骤S110,获取目标用户的下单行为数据,下单行为数据包括多个下单行为特征,下单行为特征至少包括每个目标用户的用户ID、设备ID、支付账号以及收货手机号码。
步骤S120,根据下单行为数据,对目标用户进行分类,得到用户分类结果。
具体地,基于用户ID对多个目标用户进行分类,得到多个类别的目标用户。
步骤S130,获取用户体系关系,并根据用户分类结果、用户体系关系以及下单行为数据,构建第一网络拓扑图;第一网络拓扑图表示多个类别的目标用户之间的关联关系;用户体系关系包括多个用户类别之间的关联关系。
步骤S140,根据第一网络拓扑图和预设标签传播规则对目标用户进行分类,得到目标社群集合;目标社群集合包括多个目标社群。
步骤S150,根据预设恶意检测规则对目标社群集合进行恶意群体检测,得到目标社群集合中的恶意社群。
通过上述步骤S110至步骤S150,获取目标用户的下单行为数据;根据下单行为数据,对目标用户进行分类,得到用户分类结果;获取用户体系关系,并根据用户分类结果、用户体系关系以及下单行为数据,构建第一网络拓扑图;根据第一网络拓扑图和预设标签传播规则对目标用户进行分类,得到目标社群集合;根据预设恶意检测规则对目标社群集合进行恶意群体检测,得到目标社群集合中的恶意社群。本申请通过引入多维度的下单行为数据构建第一网络拓扑图,并结合预设标签传播规则对目标用户进行分类,得到目标社群集合,在基础的标签传播规则基础上,丰富了第一网络拓扑图中节点的属性的多样性,从而细化了目标用户的分类标准,可以得到更加丰富的社群信息,进而可以实现对恶意群体的准确定位;并通过结合平台的用户体系关系,引入多个类别的目标用户之间的关联关系,进一步丰富了目标社群集合,进而可以进一步提高恶意群体的定位准确度,解决了相关技术中,无法有效地对社群中的恶意群体进行检测的问题。另外,可以将本申请提供的多属性节点的社群发现方法,推广到多属性节点的应用场景中,为风控拦截策略的制定提供更多的维度,进一步提高对恶意群体所在社群拦截的精准度。
在其中一些实施例中,图2为本申请实施例中构建第一网络拓扑图的流程图一,如图2所示,该流程包括如下步骤:
步骤S210,根据每一类别的目标用户的用户ID、设备ID、支付账号以及收货手机号码,构建每一类别对应的第二网络拓扑图。
目标用户的类别包括但不仅限于普通用户、客户经理和服务经理。
具体地,可以根据普通用户的用户ID、设备ID、支付账号以及收货手机号码,构建普通用户这一类别对应的第二网络拓扑图。同理,也可以构建客户经理这一类别对应的第二网络拓扑图以及服务经理类别对应的第二网络拓扑图,本实施例不再赘述。
需要说明的是,“类别”也可以表示为“层级”或者“级别”,本实施例不作限制。
步骤S220,根据用户体系关系,对多个类别的第二网络拓扑图进行关联,得到第一网络拓扑图。
具体地,可以基于多个用户类别之间的关联关系,对多个类别的第二网络拓扑图中的用户ID进行关联,从而可以得到第一网络拓扑图。
通过上述步骤S210至步骤S220,根据每一类别的目标用户的用户ID、设备ID、支付账号以及收货手机号码,构建每一类别对应的第二网络拓扑图;根据用户体系关系,对多个类别的第二网络拓扑图进行关联,得到第一网络拓扑图。通过本实施例,基于用户体系关系对多个类别的第二网络拓扑图进行关联,引入多个类别之间的关联关系,进一步丰富目标社群集合,可以拓宽后续恶意社群拦截的深度与广度,进一步提高对恶意群体所在社群拦截的精准度。
在其中一些实施例中,图3为本申请实施例中构建第一网络拓扑图的流程图二,如图3所示,该流程包括如下步骤:
步骤S310,以每一下单行为特征为节点,将每一目标用户的下单行为特征对应的节点相连,构建多个目标用户的第三网络拓扑图。
具体地,下单行为特征至少包括每个目标用户的用户ID、设备ID、支付账号以及收货手机号码。以每一下单行为特征为节点,将每一个目标用户的用户ID分别与设备ID、支付账号以及收货手机号码相连,构建多个目标用户的第三网络拓扑图。
步骤S320,根据用户体系关系和用户分类结果,对多个类别的目标用户的第三网络拓扑图进行关联,得到第一网络拓扑图。
具体地,可以基于多个用户类别之间的关联关系,对多个类别的第二网络拓扑图中的用户ID进行关联,从而可以得到第一网络拓扑图。
通过上述步骤S310至步骤S320,以每一下单行为特征为节点,将每一目标用户的下单行为特征对应的节点相连,构建多个目标用户的第三网络拓扑图;根据用户体系关系和用户分类结果,对多个类别的目标用户的第三网络拓扑图进行关联,得到第一网络拓扑图。通过本实施例,基于用户体系关系对多个类别的第二网络拓扑图进行关联,引入多个类别之间的关联关系,进一步丰富目标社群集合,可以提高后续恶意社群拦截的深度和广度,进一步提高对恶意群体所在社群拦截的精准度。
在其中一些实施例中,根据目标社群集合和用户体系关系,确定目标社群集合中缺失的用户类别,并将缺失的类别作为补充信息添加至目标社群集合。
例如,目标社群集合包括20个目标用户。20个用户可以在平台的用户体系关系中对应到15个普通用户和5个服务经理,其中,用户体系关系包括普通用户、客户经理和服务经理。另外还可以将用户体系关系中的客户经理作为补充信息添加至目标社群集合,进一步丰富目标社群集合。
进一步地,可以结合目标社群集合以及补充信息,确定目标社群集合中的恶意社群。例如,如果发现15个普通用户与补充信息中的客户经理存在关联下单行为,则可以将该15个普通用户与该客户经理作为可疑社群进行监控。
上述实施例,通过根据目标社群集合和用户体系关系,确定目标社群集合中缺失的用户类别,并将缺失的类别作为补充信息添加至目标社群集合,从而可以将目标社群集合与缺失的用户类别相结合,以监测目标社群集合中的某些可疑社群与缺失的用户类别之间的下单关联行为,避免遗漏与缺失的用户类别相关的恶意社群,进一步提高了恶意社群检测的可靠性以及进一步拓宽了恶意社群拦截的深度与广度。
在其中一些实施例中,图4为本申请实施例中确定目标社群集合中的恶意社群的流程图一,如图4所示,该流程包括如下步骤:
步骤S410,对用户ID、设备ID、支付账号以及收货手机号码进行去重处理,并获取每一目标社群对应的用户ID总数、设备ID总数、支付账号总数以及收货手机号码总数。
步骤S420,根据目标社群对应的用户ID总数、设备ID总数、支付账号总数以及收货手机号码总数,得到目标社群对应的第一设备浓度、第一支付账号浓度和第一手机号码浓度;第一设备浓度表示设备ID总数与用户ID总数之间的比例;第一支付账号浓度表示支付账号总数与用户ID总数之间的比例;第一手机号码浓度表示收货手机号码总数与用户ID总数之间的比例。
步骤S430,根据第一预设浓度阈值以及目标社群的第一设备浓度、第一支付账号浓度和第一手机号码浓度,确定目标社群集合中的恶意社群。
其中,第一预设浓度阈值包括第一预设设备浓度阈值、第一预设支付账号浓度阈值和第一预设手机号码浓度阈值。
具体地,可以设置当目标社群集合对应的第一设备浓度、第一支付账号浓度和第一手机号码浓度中任意一个浓度值小于对应的第一预设浓度阈值时,确定该目标社群为恶意社群。也可以设置当目标社群集合对应的第一设备浓度、第一支付账号浓度和第一手机号码浓度均小于对应的第一预设浓度阈值时,确定该目标社群为恶意社群。可以根据实际应用场景进行灵活设置,本实施例不作限制。
例如,目标社群包含20个用户ID、2个设备ID、3个支付账号、4个收货手机号。则可以计算得到该目标社群对应的第一设备浓度为2/20=0.1,第一支付账号浓度为3/20=0.15,以及第一手机号码浓度为4/20=0.2。设置第一预设设备浓度阈值为0.2。设置当第一设备浓度小于第一预设设备浓度阈值时,确定该目标社群为恶意社群。即本例中的第一设备浓度0.1小于第一预设设备浓度阈值,因此该目标社群为恶意社群。
通过上述步骤S410至步骤S430,获取每一目标社群对应的用户ID总数、设备ID总数、支付账号总数以及收货手机号码总数;根据目标社群对应的用户ID总数、设备ID总数、支付账号总数以及收货手机号码总数,得到目标社群对应的第一设备浓度、第一支付账号浓度和第一手机号码浓度;根据第一预设浓度阈值以及目标社群的第一设备浓度、第一支付账号浓度和第一手机号码浓度,确定目标社群集合中的恶意社群。本实例通过根据目标社群对应的用户ID总数、设备ID总数、支付账号总数以及收货手机号码总数,计算目标社群对应的第一设备浓度、第一支付账号浓度和第一手机号码浓度,实现根据不同属性的节点的聚集程度,设置相应的风控拦截策略,可以进一步提高恶意群体的拦截精度,降低平台的运营成本,提升用户体验感。
在其中一些实施例中,图5为本申请实施例中确定目标社群集合中的恶意社群的流程图二,如图5所示,该流程包括如下步骤:
步骤S510,设置第一网络拓扑图中每一节点的权值系数。
步骤S520,针对每一目标社群,基于权值系数,分别对目标社群的用户ID的对应节点、设备ID的对应节点、支付账号的对应节点以及收货手机号码的对应节点进行加权求和,得到目标社群的用户ID加权值、设备ID加权值、支付账号加权值和收货手机号码加权值。
步骤S530,根据用户ID加权值、设备ID加权值、支付账号加权值以及收货手机号码加权值,得到目标社群的第二设备浓度、第二支付账号浓度和第二手机号码浓度;第二设备浓度表示设备ID加权值与用户ID加权值之间的比例;第二支付账号浓度表示支付账号加权值与用户ID加权值之间的比例;第二手机号码浓度表示收货手机号码加权值与用户ID加权值之间的比例。
步骤S540,根据第二预设浓度阈值以及每个目标社群的第二设备浓度、第二支付账号浓度和第二手机号码浓度,确定目标社群集合中的恶意社群。
其中,第二预设浓度阈值包括第二预设设备浓度阈值、第二预设支付账号浓度阈值和第二预设手机号码浓度阈值。
通过上述步骤S510至步骤S540,设置第一网络拓扑图中每一节点的权值系数;基于权值系数,分别对每一目标社群的用户ID的对应节点、设备ID的对应节点、支付账号的对应节点以及收货手机号码的对应节点进行加权求和,得到目标社群的用户ID加权值、设备ID加权值、支付账号加权值和收货手机号码加权值。根据用户ID加权值、设备ID加权值、支付账号加权值以及收货手机号码加权值,得到目标社群的第二设备浓度、第二支付账号浓度和第二手机号码浓度。本实施例通过设置第一网络拓扑图中每一节点的权值系数,并基于权值系数,计算每一目标社群的第二设备浓度、第二支付账号浓度和第二手机号码浓度,从而可以进一步细化第一网络拓扑图中节点属性的多样性,提高第二设备浓度、第二支付账号浓度和第二手机号码浓度的准确度,从而可以进一步提高恶意群体的拦截精度。
在其中一些实施例中,图6为本申请实施例中根据第一网络拓扑图和预设标签传播规则,得到目标社群集合的流程图,如图6所示,该流程包括如下步骤:
步骤S610,设置第一网络拓扑图中每一节点的原始标签。
步骤S620,获取当前节点对应的相邻节点标签,相邻节点标签表示与当前节点相邻的节点的标签。
步骤S630,统计每一相邻节点标签的出现次数,并将出现次数最多的相邻节点标签作为当前节点的当前标签。
进一步地,若同时有两个出现次数最多的相邻节点标签,则分别计算当前节点与上述两个相邻节点标签对应的相邻节点之间的相似度,并将最大相似度对应的相邻节点标签作为当前节点的当前标签。
步骤S640,获取下一节点的相邻节点标签,并根据下一节点的相邻节点标签对下一节点的原始标签进行更新,直至所有节点的当前标签不再变化或者达到最大迭代次数,停止更新,得到更新后的第一网络拓扑图。
需要说明的是,通过多次迭代对第一网络拓扑图中每一节点的标签进行更新,直至所有节点的当前标签不再变化或者达到最大迭代次数,停止迭代更新,得到更新后的第一网络拓扑图。
步骤S650,根据更新后的第一网络拓扑图中节点的当前标签,确定目标社群集合。
通过上述步骤S610至步骤S650,通过多次迭代对第一网络拓扑图中每一节点的标签进行更新,直至所有节点的当前标签不再变化或者达到最大迭代次数,停止迭代更新,得到更新后的第一网络拓扑图,并根据更新后的第一网络拓扑图中节点的当前标签,确定目标社群集合。本实施例通过多次迭代对第一网络拓扑图中每一节点的标签进行更新,从而可以基于更新后的第一网络拓扑图中节点的当前标签,对目标用户进行分类,得到目标社群集合,实现简单快速地确定出目标社群集合,为后续根据目标社群集合确定恶意社群作铺垫。
下面通过具体实施例对本申请实施例进行描述和说明。
图7为本申请具体实施例的恶意社群发现方法的构架示意图,如图7所示,该方法包括如下步骤:
(1)获取目标用户的下单行为数据,下单行为数据包括每个目标用户的用户ID、设备ID、支付账号以及收货手机号码;根据用户ID对多个目标用户进行分类,得的用户分类结果。
(2)获取用户体系关系,用户体系关系包括多个用户类别之间的关联关系。以用户ID、设备ID、支付账号以及收货手机号码为节点,以用户ID-设备ID、用户ID-支付账号以及用户ID-收货手机号码为连接边,并结合Spark Graphx图计算库构建多个目标用户的第三网络拓扑图,并根据用户分类结果和用户体系关系得到第一网络拓扑图,第一网络拓扑图表示多个类别的目标用户之间的关联关系。
(3)根据第一网络拓扑图和标签传播算法(Label Propagation Algorithm,简称LPA)对目标用户进行分类,得到目标社群集合;目标社群集合包括多个目标社群。具体地,图8为本申请具体实施例的目标社群集合在第一网络拓扑图中的示意图,如图8所示,通过多次迭代对第一网络拓扑图中每一节点的标签进行更新,并将具有相同标签的节点作为同一个目标社群,从而得到目标社群集合。可以采用不同的颜色以及同一颜色的亮暗程度作为节点的标签,也可以采用其他方式的节点标签,本申请不作限制。例如,图8中的黑色的节点与浅灰色的节点表示两个不同的目标社群。
(4)对用户ID、设备ID、支付账号以及收货手机号码进行去重处理,并获取每一目标社群对应的用户ID总数、设备ID总数、支付账号总数以及收货手机号码总数;根据目标社群对应的用户ID总数、设备ID总数、支付账号总数以及收货手机号码总数,得到目标社群对应的第一设备浓度、第一支付账号浓度和第一手机号码浓度;根据第一预设浓度阈值以及目标社群的第一设备浓度、第一支付账号浓度和第一手机号码浓度,确定目标社群集合中的恶意社群。
需要说明的是,在上述流程中或者附图的流程图中示出的步骤可以在诸如一组计算机可执行指令的计算机系统中执行,并且,虽然在流程图中示出了逻辑顺序,但是在某些情况下,可以以不同于此处的顺序执行所示出或描述的步骤。
本实施例还提供了一种恶意社群发现装置,该装置用于实现上述实施例及优选实施方式,已经进行过说明的不再赘述。如以下所使用的,术语“模块”、“单元”、“子单元”等可以实现预定功能的软件和/或硬件的组合。尽管以下实施例所描述的装置较佳地以软件来实现,但是硬件,或者软件和硬件的组合的实现也是可能并被构想的。
图9为本申请实施例的恶意社群发现装置的结构框图,如图9所示,该恶意社群发现装置900包括:
数据获取模块910,用于获取目标用户的下单行为数据;下单行为数据包括多个下单行为特征;下单行为特征至少包括每个目标用户的用户ID、设备ID、支付账号以及收货手机号码。
用户分类模块920,用于根据下单行为数据,对目标用户进行分类,得到用户分类结果。
拓扑图构建模块930,用于获取用户体系关系,并根据用户分类结果、用户体系关系以及下单行为数据,构建第一网络拓扑图;第一网络拓扑图表示多个类别的目标用户之间的关联关系;用户体系关系包括多个用户类别之间的关联关系。
目标社群确定模块940,用于根据第一网络拓扑图和预设标签传播规则对目标用户进行分类,得到目标社群集合;目标社群集合包括多个目标社群。
恶意社群检测模块950,用于根据预设恶意检测规则对目标社群集合进行恶意群体检测,得到目标社群集合中的恶意社群。
在其中一些实施例中,拓扑图构建模块930包括第一拓扑图构建单元和第一拓扑图关联单元,其中:
第一拓扑图构建单元,用于根据每一类别的目标用户的用户ID、设备ID、支付账号以及收货手机号码,构建每一类别对应的第二网络拓扑图。
第一拓扑图关联单元,用于根据用户体系关系,对多个类别的第二网络拓扑图进行关联,得到第一网络拓扑图。
在其中一些实施例中,拓扑图构建模块930还包括第二拓扑图构建单元和第二拓扑图关联单元,其中:
第二拓扑图构建单元,用于以每一下单行为特征为节点,将每一目标用户的下单行为特征对应的节点相连,构建多个目标用户的第三网络拓扑图。
第二拓扑图关联单元,用于根据用户体系关系和用户分类结果,对多个类别的目标用户的第三网络拓扑图进行关联,得到第一网络拓扑图。
在其中一些实施例中,恶意社群发现装置900还包括信息补充模块,信息补充模块,用于根据目标社群集合和用户体系关系,确定目标社群集合中缺失的用户类别,并将缺失的类别作为补充信息添加至目标社群集合。
在其中一些实施例中,恶意社群检测模块950包括总数获取单元、第一浓度获取单元以及第一恶意社群确定单元,其中:
总数获取单元,用于对用户ID、设备ID、支付账号以及收货手机号码进行去重处理,并获取每一目标社群对应的用户ID总数、设备ID总数、支付账号总数以及收货手机号码总数。
第一浓度获取单元,用于根据目标社群对应的用户ID总数、设备ID总数、支付账号总数以及收货手机号码总数,得到目标社群对应的第一设备浓度、第一支付账号浓度和第一手机号码浓度;第一设备浓度表示设备ID总数与用户ID总数之间的比例;第一支付账号浓度表示支付账号总数与用户ID总数之间的比例;第一手机号码浓度表示收货手机号码总数与用户ID总数之间的比例。
第一恶意社群确定单元,用于根据第一预设浓度阈值以及目标社群的第一设备浓度、第一支付账号浓度和第一手机号码浓度,确定目标社群集合中的恶意社群。
在其中一些实施例中,恶意社群检测模块950还包括系数设置单元、加权求和单元、第二浓度获取单元和第二恶意社群确定单元,其中:
系数设置单元,用于设置第一网络拓扑图中每一节点的权值系数。
加权求和单元,用于针对每一目标社群,基于权值系数,分别对目标社群的用户ID的对应节点、设备ID的对应节点、支付账号的对应节点以及收货手机号码的对应节点进行加权求和,得到目标社群的用户ID加权值、设备ID加权值、支付账号加权值和收货手机号码加权值。
第二浓度获取单元,用于根据用户ID加权值、设备ID加权值、支付账号加权值以及收货手机号码加权值,得到目标社群的第二设备浓度、第二支付账号浓度和第二手机号码浓度;第二设备浓度表示设备ID加权值与用户ID加权值之间的比例;第二支付账号浓度表示支付账号加权值与用户ID加权值之间的比例;第二手机号码浓度表示收货手机号码加权值与用户ID加权值之间的比例。
第二恶意社群确定单元,用于根据第二预设浓度阈值以及每个目标社群的第二设备浓度、第二支付账号浓度和第二手机号码浓度,确定目标社群集合中的恶意社群。
在其中一些实施例中,目标社群确定模块940包括标签设置单元、标签获取单元、数据统计单元、标签更新单元和社群确定单元,其中:
标签设置单元,用于设置第一网络拓扑图中每一节点的原始标签。
标签获取单元,用于获取当前节点对应的相邻节点标签,相邻节点标签表示与当前节点相邻的节点的标签。
数据统计单元,用于统计每一相邻节点标签的出现次数,并将出现次数最多的相邻节点标签作为当前节点的当前标签。
标签更新单元,用于获取下一节点的相邻节点标签,并根据下一节点的相邻节点标签对下一节点的原始标签进行更新,直至所有节点的当前标签不再变化或者达到最大迭代次数,停止更新,得到更新后的第一网络拓扑图。
社群确定单元,用于根据更新后的第一网络拓扑图中节点的当前标签,确定目标社群集合。
需要说明的是,上述各个模块可以是功能模块也可以是程序模块,既可以通过软件来实现,也可以通过硬件来实现。对于通过硬件来实现的模块而言,上述各个模块可以位于同一处理器中;或者上述各个模块还可以按照任意组合的形式分别位于不同的处理器中。
另外,结合图1描述的本申请实施例恶意社群发现方法可以由恶意社群发现设备来实现。图10为本申请实施例的恶意社群发现设备的硬件结构示意图。
恶意社群发现设备可以包括处理器101以及存储有计算机程序指令的存储器102。
具体地,上述处理器101可以包括中央处理器(CPU),或者特定集成电路(Application Specific Integrated Circuit,简称为ASIC),或者可以被配置成实施本申请实施例的一个或多个集成电路。
其中,存储器102可以包括用于数据或指令的大容量存储器。举例来说而非限制,存储器102可包括硬盘驱动器(Hard Disk Drive,简称为HDD)、软盘驱动器、固态驱动器(Solid State Drive,简称为SSD)、闪存、光盘、磁光盘、磁带或通用串行总线(UniversalSerial Bus,简称为USB)驱动器或者两个或更多个以上这些的组合。在合适的情况下,存储器102可包括可移除或不可移除(或固定)的介质。在合适的情况下,存储器102可在数据处理装置的内部或外部。在特定实施例中,存储器102是非易失性(Non-Volatile)存储器。在特定实施例中,存储器102包括只读存储器(Read-Only Memory,简称为ROM)和随机存取存储器(Random Access Memory,简称为RAM)。在合适的情况下,该ROM可以是掩模编程的ROM、可编程ROM(Programmable Read-Only Memory,简称为PROM)、可擦除PROM(ErasableProgrammable Read-Only Memory,简称为EPROM)、电可擦除PROM(Electrically ErasableProgrammable Read-Only Memory,简称为EEPROM)、电可改写ROM(ElectricallyAlterable Read-Only Memory,简称为EAROM)或闪存(FLASH)或者两个或更多个以上这些的组合。在合适的情况下,该RAM可以是静态随机存取存储器(Static Random-AccessMemory,简称为SRAM)或动态随机存取存储器(Dynamic Random Access Memory,简称为DRAM),其中,DRAM可以是快速页模式动态随机存取存储器(Fast Page Mode DynamicRandom Access Memory,简称为FPMDRAM)、扩展数据输出动态随机存取存储器(ExtendedDate Out Dynamic Random Access Memory,简称为EDODRAM)、同步动态随机存取内存(Synchronous Dynamic Random-Access Memory,简称SDRAM)等。
存储器102可以用来存储或者缓存需要处理和/或通信使用的各种数据文件,以及处理器101所执行的可能的计算机程序指令。
处理器101通过读取并执行存储器102中存储的计算机程序指令,以实现上述实施例中的任意一种恶意社群发现方法。
在其中一些实施例中,恶意社群发现设备还可包括通信接口103和总线100。其中,如图10所示,处理器101、存储器102、通信接口103通过总线100连接并完成相互间的通信。
通信接口103用于实现本申请实施例中各模块、装置、单元和/或设备之间的通信。通信接口103还可以实现与其他部件例如:外接设备、图像/数据采集设备、数据库、外部存储以及图像/数据处理工作站等之间进行数据通信。
总线100包括硬件、软件或两者,将恶意社群发现设备的部件彼此耦接在一起。总线100包括但不限于以下至少之一:数据总线(Data Bus)、地址总线(Address Bus)、控制总线(Control Bus)、扩展总线(Expansion Bus)、局部总线(Local Bus)。举例来说而非限制,总线100可包括图形加速接口(Accelerated Graphics Port,简称为AGP)或其他图形总线、增强工业标准架构(Extended Industry Standard Architecture,简称为EISA)总线、前端总线(Front Side Bus,简称为FSB)、超传输(Hyper Transport,简称为HT)互连、工业标准架构(Industry Standard Architecture,简称为ISA)总线、无线带宽(InfiniBand)互连、低引脚数(Low Pin Count,简称为LPC)总线、存储器总线、微信道架构(Micro ChannelArchitecture,简称为MCA)总线、外围组件互连(Peripheral Component Interconnect,简称为PCI)总线、PCI-Express(PCI-X)总线、串行高级技术附件(Serial AdvancedTechnology Attachment,简称为SATA)总线、视频电子标准协会局部(Video ElectronicsStandards Association Local Bus,简称为VLB)总线或其他合适的总线或者两个或更多个以上这些的组合。在合适的情况下,总线100可包括一个或多个总线。尽管本申请实施例描述和示出了特定的总线,但本申请考虑任何合适的总线或互连。
该恶意社群发现设备可以基于获取到的恶意社群发现,执行本申请实施例中的恶意社群发现方法,从而实现结合图1描述的恶意社群发现方法。
另外,结合上述实施例中的恶意社群发现方法,本申请实施例可提供一种计算机可读存储介质来实现。该计算机可读存储介质上存储有计算机程序指令;该计算机程序指令被处理器执行时实现上述实施例中的任意一种恶意社群发现方法。
以上实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
以上实施例仅表达了本申请的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本申请构思的前提下,还可以做出若干变形和改进,这些都属于本申请的保护范围。因此,本申请专利的保护范围应以所附权利要求为准。
- 恶意社群发现方法、装置、计算机设备和可读存储介质
- 服务发现方法、装置、计算机可读存储介质和计算机设备