一种基于机器学习的供应链调整方法、装置及电子设备
文献发布时间:2023-06-19 10:00:31
技术领域
本发明涉及供应链领域,更具体的说,涉及一种基于机器学习的供应链调整方法、装置及电子设备。
背景技术
为了能够更直观的了解各个企业之间的关联关系,可以构建各个企业之间的供应链。其中,供应链(Supply chain),是指生产及流通过程中,涉及将产品或服务提供给最终用户活动的上游与下游企业,所形成的网链结构。
目前,在建立供应链后,若有新的企业加入,则人工通过企业之间的买卖合同来不断完善供应链,人工完善供应链时容易受到人工误判的影响,使得完善后的供应链的准确度较低。
发明内容
有鉴于此,本发明提供一种基于机器学习的供应链调整方法、装置及电子设备,以解决人工完善供应链时容易受到人工误判的影响,使得完善后的供应链的准确度较低的问题。
为解决上述技术问题,本发明采用了如下技术方案:
一种基于机器学习的供应链调整方法,包括:
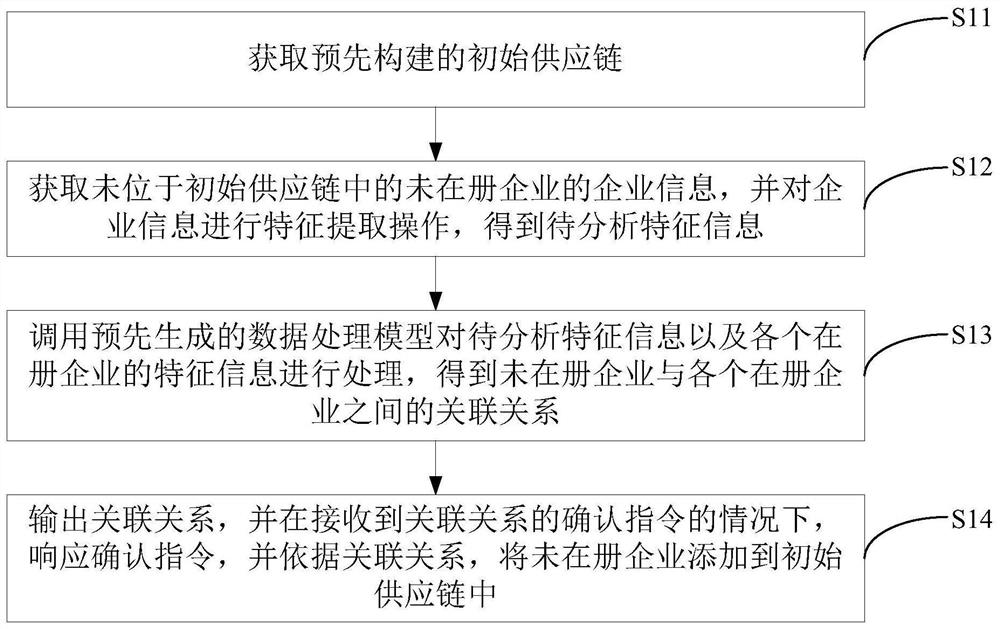
获取预先构建的初始供应链;所述初始供应链包括各个在册企业、以及各个在册企业之间的关联关系;
获取未位于所述初始供应链中的未在册企业的企业信息,并对所述企业信息进行特征提取操作,得到待分析特征信息;
调用预先生成的数据处理模型对所述待分析特征信息以及所述各个在册企业的特征信息进行处理,得到所述未在册企业与所述各个在册企业之间的关联关系;所述数据处理模型使用训练数据训练得到,所述训练数据包括特征信息样本以及所述特征信息样本之间的样本关联关系;
输出所述关联关系,并在接收到所述关联关系的确认指令的情况下,响应所述确认指令,并依据所述关联关系,将所述未在册企业添加到所述初始供应链中。
可选地,获取未位于所述初始供应链中的未在册企业的企业信息,包括:
获取未位于所述初始供应链中的未在册企业的初始企业信息;
调用预设数据清洗模型对所述初始企业信息进行数据清洗操作,得到所述未在册企业的企业信息。
可选地,对所述企业信息进行特征提取操作,得到待分析特征信息,包括:
对所述企业信息进行特征提取操作,得到各个特征信息;
对所述各个特征信息进行相关性分析,得到所述各个特征信息之间的相关性;
基于所述各个特征信息之间的相关性,从所述各个特征信息中筛选出显著特征信息,并确定为待分析特征信息。
可选地,所述数据处理模型的生成过程包括:
获取训练数据;所述训练数据包括特征信息样本以及所述特征信息样本之间的样本关联关系;
使用所述训练数据,对数据处理模型进行训练,直至所述数据处理模型的损失函数小于预设阈值时停止训练。
可选地,获取预先构建的初始供应链,包括:
获取预先构建的目标供应链,并对所述目标供应链进行图形化处理,得到初始供应链。
一种基于机器学习的供应链调整装置,包括:
供应链获取模块,用于获取预先构建的初始供应链;所述初始供应链包括各个在册企业、以及各个在册企业之间的关联关系;
信息处理模块,用于获取未位于所述初始供应链中的未在册企业的企业信息,并对所述企业信息进行特征提取操作,得到待分析特征信息;
关系确定模块,用于调用预先生成的数据处理模型对所述待分析特征信息以及所述各个在册企业的特征信息进行处理,得到所述未在册企业与所述各个在册企业之间的关联关系;所述数据处理模型使用训练数据训练得到,所述训练数据包括特征信息样本以及所述特征信息样本之间的样本关联关系;
供应链调整模块,用于输出所述关联关系,并在接收到所述关联关系的确认指令的情况下,响应所述确认指令,并依据所述关联关系,将所述未在册企业添加到所述初始供应链中。
可选地,所述信息处理模块用于获取未位于所述初始供应链中的未在册企业的企业信息时,具体用于:
获取未位于所述初始供应链中的未在册企业的初始企业信息,调用预设数据清洗模型对所述初始企业信息进行数据清洗操作,得到所述未在册企业的企业信息。
可选地,所述信息处理模块用于对所述企业信息进行特征提取操作,得到待分析特征信息时,具体用于:
对所述企业信息进行特征提取操作,得到各个特征信息,对所述各个特征信息进行相关性分析,得到所述各个特征信息之间的相关性,基于所述各个特征信息之间的相关性,从所述各个特征信息中筛选出显著特征信息,并确定为待分析特征信息。
可选地,还包括模型训练模块,所述模型训练模块具体用于:
获取训练数据;所述训练数据包括特征信息样本以及所述特征信息样本之间的样本关联关系;
使用所述训练数据,对数据处理模型进行训练,直至所述数据处理模型的损失函数小于预设阈值时停止训练。
一种电子设备,包括:存储器和处理器;
其中,所述存储器用于存储程序;
处理器调用程序并用于:
获取预先构建的初始供应链;所述初始供应链包括各个在册企业、以及各个在册企业之间的关联关系;
获取未位于所述初始供应链中的未在册企业的企业信息,并对所述企业信息进行特征提取操作,得到待分析特征信息;
调用预先生成的数据处理模型对所述待分析特征信息以及所述各个在册企业的特征信息进行处理,得到所述未在册企业与所述各个在册企业之间的关联关系;所述数据处理模型使用训练数据训练得到,所述训练数据包括特征信息样本以及所述特征信息样本之间的样本关联关系;
输出所述关联关系,并在接收到所述关联关系的确认指令的情况下,响应所述确认指令,并依据所述关联关系,将所述未在册企业添加到所述初始供应链中。
相较于现有技术,本发明具有以下有益效果:
本发明提供了一种基于机器学习的供应链调整方法、装置及电子设备,在完善供应链时,获取预先构建的初始供应链,获取未位于所述初始供应链中的未在册企业的企业信息,并对所述企业信息进行特征提取操作,得到待分析特征信息,调用预先生成的数据处理模型对所述待分析特征信息以及所述各个在册企业的特征信息进行处理,得到所述未在册企业与所述各个在册企业之间的关联关系,输出所述关联关系,并在接收到所述关联关系的确认指令的情况下,响应所述确认指令,并依据所述关联关系,将所述未在册企业添加到所述初始供应链中。即本发明能够自动进行供应链的完善,并且在供应链完善时,使用了数据处理模型,数据处理模型使用训练数据训练得到,所述训练数据包括特征信息样本以及所述特征信息样本之间的样本关联关系,则数据处理模型的处理准确度较高,进而使用数据处理模型得到未在册企业与所述在册企业之间的关联关系时,准确度较高,进而能够提高完善后的供应链的准确度。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。
图1为本发明实施例提供的一种基于机器学习的供应链调整方法的方法流程图;
图2为本发明实施例提供的另一种基于机器学习的供应链调整方法的方法流程图;
图3为本发明实施例提供的一种调整供应链的场景示意图;
图4为本发明实施例提供的一种基于机器学习的供应链调整装置的结构示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
为了能够清楚的了解各个企业之间的供应关系,可以构建各个企业之间的供应链。在供应链行业,对于核心企业来说,仅掌握了一级供应商及备案在册的部分下游供应商信息,如果能够掌握下游供应商的信息,就能对整个供应链的供需关系有一定的了解。例如,一级供应商提供变电站设备,他的二级供应商为他提供变压器等基础组件,如果核心企业能够掌握二级供应商的信息,就能够对其供应的产品质量做评估,进而去评价一级供应商供货的质量。但是目前供应链中仍有很多未在册的供应商,由于缺乏对整体供应链上下游供需关系的了解,可能导致核心企业对产品质量不能有效管控也无法实现质量追溯。
为了避免上述这种问题,需要不断对供应链进行调整,不断增加新的企业进来。在供应链构建完成后,由于企业的不断加入,则该供应链需要进行调整。本实施例中,调整之前的供应链称为初始供应链,在进行供应链的调整时,是人工根据经验进行调整,但是人工操作,容易出现误操作,则使得调整后的供应链的准确度较低。并且,还会浪费大量的人力。
为此,发明人经过研究发现,若是能够自动实现供应链的调整,则能够节省人力。进一步的,若是将机器学习引入供应链调整的方案中,使用机器学习构建模型,通过该模型得到新增加的企业与已有企业之间的关联关系,然后依据该关联关系将新增加的企业添加到初始供应链中。由于机器学习模型经过大量的数据进行训练,则其准确度较高。进而通过该模型进行供应链的调整的准确度也会较高。
另外,发明人还发现,目前的供应链金融领域,对于下游供应商来说,供应链金融门槛较高,只能服务核心企业的较小一部分一级供应商,由于缺乏核心企业的信任背书,而一级供应商又未向核心企业报备信息,导致中小企业贷款额度低、融资难等问题。为了解决这个问题,可以在供应链调整完成后,对后续供应商进行信任背书的构建,保证中小企业贷款和融资。
具体的,在上述内容的基础上,本发明提供了一种基于机器学习的供应链调整方法,参照图1,可以包括:
S11、获取预先构建的初始供应链。
在实际应用中,初始供应链可以是上述的已经构建完成、但是需要调整的供应链。初始供应链中包括各个在册企业、以及各个在册企业之间的关联关系。其中,在册企业分为两种类型,一种是核心企业,即供求关系的最初提供者,以及各级供应商,如一级供应商、二级供应商等,其中,一级供应商直接为核心企业服务,二级供应商为一级供应商服务,以此类推,直至最后一级供应商。
在实际应用中,为了提高用户观看效果,可以对上述的初始供应链进行图示化展示,此时,将上述的初始供应链称为目标供应链,对所述目标供应链进行图形化处理,得到新的初始供应链,即本实施例中后续处理的初始供应链,本实施例中,也可将后续需要进行处理的初始供应链称为商圈树。
S12、获取未位于所述初始供应链中的未在册企业的企业信息,并对所述企业信息进行特征提取操作,得到待分析特征信息。
在实际应用中,可以通过网络爬虫、图书馆查阅资料等方式,收集未在册企业,即未在册供应商的注册信息、经营资质、经营范围以及贸易背景等资料,这些内容称为未在册企业的初始企业信息。
更具体的,由于收集的注册信息、经营资质、经营范围以及贸易背景等资料可能存在数据缺失、数据规范性较差等问题,所以需要对上述收集的信息进行数据清洗操作。
具体的,可以调用预设数据清洗模型对所述初始企业信息进行数据清洗操作,得到所述未在册企业的企业信息。
其中,预设数据清洗模型可以是ETL(Extract-Transform-Load),ETL是一种数据仓库技术,将业务系统的数据经过抽取、清洗转换之后加载到数据仓库的过程,目的是将企业中的分散、零乱、标准不统一的数据整合到一起,为企业的决策提供分析依据。ETL的设计分三部分:数据抽取、数据的清洗转换、数据的加载,具体包括处理缺失值、处理偏离值、数据规范化、数据的转换等操作。
由此可知,步骤S12中的“获取未位于所述初始供应链中的未在册企业的企业信息”包括:
获取未位于所述初始供应链中的未在册企业的初始企业信息,并调用预设数据清洗模型对所述初始企业信息进行数据清洗操作,得到所述未在册企业的企业信息。
在通过ETL工具对初始企业信息进行数据清洗操作之后,可以得到未在册企业的企业信息。在得到未在册企业的企业信息之后,需要对该企业信息进行特征提取操作,得到待分析特征信息。
具体特征提取的过程可以参照图2,包括:
S21、对所述企业信息进行特征提取操作,得到各个特征信息。
在实际应用中,可以采用机器学习中的文本特征提取方法进行特征提取操作,提取的特征可以包括:企业贸易背景基本信息、应收账款、应付账款等信息。
S22、对所述各个特征信息进行相关性分析,得到所述各个特征信息之间的相关性。
在进行特征信息之间的相关性分析时,可以采用使用相关系数、卡方检验、平均互信息、条件熵、后验概率、逻辑回归权重等方法,得到各个特征信息之间的相关性。其中,相关性可以用数值表示,数值越大,说明相关性也大,数值夜宵,说明相关性越小。
S23、基于所述各个特征信息之间的相关性,从所述各个特征信息中筛选出显著特征信息,并确定为待分析特征信息。
本实施例中,预先定义了显著特征信息和非显著特征信息,其中,显著特征信息是指在进行企业关联关系确定时,较重要的特征信息。非显著特征信息是指在进行企业关联关系确定时,不太重要的特征信息。
确定显著特征信息的过程即是进行数据降维的过程,数据降维主要是为了减少冗余信息所造成的误差,寻找数据内部的本质结构特征,降低后续机器学习模型处理的数据量。
具体确定显著特征信息的过程可以包括:
筛选出与多个特征信息均相关、且相关性大于预设阈值的特征信息,并确定为显著特征信息,并将显著特征信息确定为待分析特征信息。对于非显著特征信息,则可以直接丢弃。
S13、调用预先生成的数据处理模型对所述待分析特征信息以及所述各个在册企业的特征信息进行处理,得到所述未在册企业与所述各个在册企业之间的关联关系。
本实施例中,预先构建了数据处理模型,该数据处理模型使用训练数据训练得到,所述训练数据包括特征信息样本以及所述特征信息样本之间的样本关联关系。
具体的,本实施例中,会预先确定出训练数据,所述训练数据包括特征信息样本以及所述特征信息样本之间的样本关联关系。本实施例中,特征信息样本可以是:
通过现有供应链上下游间的供需关系,得到一级供应商与二级供应商间的贸易关系,并利用产品与各个元器件间的组成关系分析贸易合同中的产品信息是否正确。若正确,则将对每一供应商的供应商信息进行特征提取,得到对应的特征信息样本。
特征信息样本之间的样本关联关系可以通过如下方式确定。
对于上述供应链中,存在贸易关系的两个供应商的特征信息样本,对该两个特征信息样本标注相关,并将两个特征信息样本中的高一级供应商的特征信息样本标注高一级,低一级供应商的特征信息样本标注低一级。
举例来说,假设有一级供应商A与二级供应商B,则将AB的特征信息样本标注相关,并将A的特征信息样本标注高一级,B的特征信息样本标注低一级,进而在进行学习时,就能够学习相关的两个特征信息样本之间的联系,以及学习两个特征信息样本之间的供应商等级关系。
在得到训练数据之后,需要对训练数据进行数据分割,将训练数据分成独立的三部分:训练数据(Train Data),验证数据(Validation Data)和测试数据(Test Data)。本次操作将60%的数据作为训练数据,剩余的部分平均分为验证数据与测试数据。利用训练数据进行算法训练模型,利用测试数据来计算生成模型的最终准确率,利用验证数据调整模型参数从而得到最优模型,在得到的模型的损失函数小于预设阈值时停止训练。
本实施例中,由于数据处理模型使用的训练数据包括特征信息样本以及所述特征信息样本之间的样本关联关系,则使用该训练数据进行训练时,数据处理模型能够学习何种样本之间会具有关联关系,进而后续就能够使用该数据处理模型找到未在册企业与所述各个在册企业之间的关联关系。
其中,数据处理模型在具体使用的过程中,处理的对象为未在册企业的待分析特征信息、以及各个在册企业的特征信息,其中,各个在册企业的特征信息可以通过上述的特征处理方法进行处理得到。
数据处理模型能够分析未在册企业的待分析特征信息、以及各个在册企业的特征信息,判断未在册企业是否与某写在册企业具有关联关系,若输出未在册企业与所述各个在册企业之间的关联关系。
举例来说,如果该未在册的供应商或企业提供的是变压器等基础组件,那么就将该供应商与在册的、需要该基础组件的上一级供应商建立初步供需关系,再经过地理位置、价格、质量等等指标,筛选出最有可能构建供需关系的三个上一级供应商,最后将该未在册供应商加入商圈树。因此,当新发现未在册供应商时,利用此模型,就可以将其加入商圈树。
需要说明的是,本实施例中的数据处理模型可以是任意机器学习模型,如可以是决策树模型、朴素贝叶斯模型以及神经网络模型。
S14、输出所述关联关系,并在接收到所述关联关系的确认指令的情况下,响应所述确认指令,并依据所述关联关系,将所述未在册企业添加到所述初始供应链中。
在实际应用中,通过数据处理模型得到关联关系之后,也可能存在不准确的问题,所以本实施例中需要人工进行二次确认,此时将关联关系输出,其中,输出可以是显示在处理的显示屏幕上,且同时显示在屏幕上的还有取消和确认按钮,用户可以通过观看确定的关联关系是否正确,若是正确,则点击确认按钮,此时处理器收到了关联关系的确认指令。若是不正确,则点击取消按钮,此时处理器收到了关联关系的取消指令。
此外,输出关联关系,还可以是输出至用户终端,如手机、平板、电脑等设备,同时在用户终端上也会有取消和确认按钮,用户可以通过观看确定的关联关系是否正确,若是正确,则点击确认按钮,此时处理器收到了关联关系的确认指令。若是不正确,则点击取消按钮,此时处理器收到了关联关系的取消指令。
在处理器接收到关联关系的确认指令之后,即认为用户也认为该关联关系正确,此时会通过该关联关系,将未在册企业添加到所述初始供应链中。
举例来说,假设未在册企业与某一二级供应商有关,且为该二级供应商提供原材料,则将该未在册企业作为该二级供应商的三级供应商。
参照图3,经过上述的数据处理模型处理后,为一级供应商D新增了一二级供应商E,为核心企业增加了一三级供应商F。
本实施例中,利用核心企业现有供应链上下游的合同数据,构建以核心企业为起始节点的供应链商圈树,即初始供应链。并利用机器学习技术,对未在册供应商的注册信息、经营资质、经营范围以及贸易背景等资料进行关联分析,判断未在册供应商与商圈树中供应商节点的贸易关系,不断完善并细化商圈树结构。
在将未在册供应商加入商圈树后,为商圈树中的中小企业提供信任背书,提高中小企业贷款额度,保证了中小企业的融资。
本发明具有三大优势:
一是汇总整合核心企业及其他各渠道供应商经营资质、经营范围、合同信息以及贸易背景等相关数据,构建了以核心企业为起始节点的供应链商圈树。
二是通过机器学习技术,对未在册供应商的贸易背景等相关资料进行关联分析,判断未在册供应商与商圈树中供应商节点的贸易关系,不断完善并细化商圈树结构,有助于核心企业掌握供应链上下游情况以及供应商间的供需关系,便于对一级供应商提供的产品服务进行全流程的质量追溯。
三是通过撮合供应商间的贸易关系,为商圈树中的中小企业提供信任背书,使得中小企业能够更加快速地获得融资福利,加快供应链资金流通速度,提升产品服务质量。
本实施例中,在完善供应链时,获取预先构建的初始供应链,获取未位于所述初始供应链中的未在册企业的企业信息,并对所述企业信息进行特征提取操作,得到待分析特征信息,调用预先生成的数据处理模型对所述待分析特征信息以及所述各个在册企业的特征信息进行处理,得到所述未在册企业与所述各个在册企业之间的关联关系,输出所述关联关系,并在接收到所述关联关系的确认指令的情况下,响应所述确认指令,并依据所述关联关系,将所述未在册企业添加到所述初始供应链中。即本发明能够自动进行供应链的完善,并且在供应链完善时,使用了数据处理模型,数据处理模型使用训练数据训练得到,所述训练数据包括特征信息样本以及所述特征信息样本之间的样本关联关系,则数据处理模型的处理准确度较高,进而使用数据处理模型得到未在册企业与所述在册企业之间的关联关系时,准确度较高,进而能够提高完善后的供应链的准确度。
可选地,在上述供应链调整方法的基础上,本发明的另一实施例提供了一种基于机器学习的供应链调整装置,参照图4,可以包括:
供应链获取模块11,用于获取预先构建的初始供应链;所述初始供应链包括各个在册企业、以及各个在册企业之间的关联关系;
信息处理模块12,用于获取未位于所述初始供应链中的未在册企业的企业信息,并对所述企业信息进行特征提取操作,得到待分析特征信息;
关系确定模块13,用于调用预先生成的数据处理模型对所述待分析特征信息以及所述各个在册企业的特征信息进行处理,得到所述未在册企业与所述各个在册企业之间的关联关系;所述数据处理模型使用训练数据训练得到,所述训练数据包括特征信息样本以及所述特征信息样本之间的样本关联关系;
供应链调整模块14,用于输出所述关联关系,并在接收到所述关联关系的确认指令的情况下,响应所述确认指令,并依据所述关联关系,将所述未在册企业添加到所述初始供应链中。
进一步,所述信息处理模块用于获取未位于所述初始供应链中的未在册企业的企业信息时,具体用于:
获取未位于所述初始供应链中的未在册企业的初始企业信息,调用预设数据清洗模型对所述初始企业信息进行数据清洗操作,得到所述未在册企业的企业信息。
进一步,所述信息处理模块用于对所述企业信息进行特征提取操作,得到待分析特征信息时,具体用于:
对所述企业信息进行特征提取操作,得到各个特征信息,对所述各个特征信息进行相关性分析,得到所述各个特征信息之间的相关性,基于所述各个特征信息之间的相关性,从所述各个特征信息中筛选出显著特征信息,并确定为待分析特征信息。
进一步,还包括模型训练模块,所述模型训练模块具体用于:
获取训练数据;所述训练数据包括特征信息样本以及所述特征信息样本之间的样本关联关系;
使用所述训练数据,对数据处理模型进行训练,直至所述数据处理模型的损失函数小于预设阈值时停止训练。
进一步,供应链获取模块具体用于:
获取预先构建的目标供应链,并对所述目标供应链进行图形化处理,得到初始供应链。
本实施例中,在完善供应链时,获取预先构建的初始供应链,获取未位于所述初始供应链中的未在册企业的企业信息,并对所述企业信息进行特征提取操作,得到待分析特征信息,调用预先生成的数据处理模型对所述待分析特征信息以及所述各个在册企业的特征信息进行处理,得到所述未在册企业与所述各个在册企业之间的关联关系,输出所述关联关系,并在接收到所述关联关系的确认指令的情况下,响应所述确认指令,并依据所述关联关系,将所述未在册企业添加到所述初始供应链中。即本发明能够自动进行供应链的完善,并且在供应链完善时,使用了数据处理模型,数据处理模型使用训练数据训练得到,所述训练数据包括特征信息样本以及所述特征信息样本之间的样本关联关系,则数据处理模型的处理准确度较高,进而使用数据处理模型得到未在册企业与所述在册企业之间的关联关系时,准确度较高,进而能够提高完善后的供应链的准确度。
需要说明的是,本实施例中的各个模块的工作过程,请参照上述实施例中的相应说明,在此不再赘述。
可选地,在上述供应链调整方法及装置的基础上,本发明的另一实施例提供了一种电子设备,包括:存储器和处理器;
其中,所述存储器用于存储程序;
处理器调用程序并用于:
获取预先构建的初始供应链;所述初始供应链包括各个在册企业、以及各个在册企业之间的关联关系;
获取未位于所述初始供应链中的未在册企业的企业信息,并对所述企业信息进行特征提取操作,得到待分析特征信息;
调用预先生成的数据处理模型对所述待分析特征信息以及所述各个在册企业的特征信息进行处理,得到所述未在册企业与所述各个在册企业之间的关联关系;所述数据处理模型使用训练数据训练得到,所述训练数据包括特征信息样本以及所述特征信息样本之间的样本关联关系;
输出所述关联关系,并在接收到所述关联关系的确认指令的情况下,响应所述确认指令,并依据所述关联关系,将所述未在册企业添加到所述初始供应链中。
进一步,获取未位于所述初始供应链中的未在册企业的企业信息,包括:
获取未位于所述初始供应链中的未在册企业的初始企业信息;
调用预设数据清洗模型对所述初始企业信息进行数据清洗操作,得到所述未在册企业的企业信息。
进一步,对所述企业信息进行特征提取操作,得到待分析特征信息,包括:
对所述企业信息进行特征提取操作,得到各个特征信息;
对所述各个特征信息进行相关性分析,得到所述各个特征信息之间的相关性;
基于所述各个特征信息之间的相关性,从所述各个特征信息中筛选出显著特征信息,并确定为待分析特征信息。
进一步,所述数据处理模型的生成过程包括:
获取训练数据;所述训练数据包括特征信息样本以及所述特征信息样本之间的样本关联关系;
使用所述训练数据,对数据处理模型进行训练,直至所述数据处理模型的损失函数小于预设阈值时停止训练。
进一步,获取预先构建的初始供应链,包括:
获取预先构建的目标供应链,并对所述目标供应链进行图形化处理,得到初始供应链。
本实施例中,在完善供应链时,获取预先构建的初始供应链,获取未位于所述初始供应链中的未在册企业的企业信息,并对所述企业信息进行特征提取操作,得到待分析特征信息,调用预先生成的数据处理模型对所述待分析特征信息以及所述各个在册企业的特征信息进行处理,得到所述未在册企业与所述各个在册企业之间的关联关系,输出所述关联关系,并在接收到所述关联关系的确认指令的情况下,响应所述确认指令,并依据所述关联关系,将所述未在册企业添加到所述初始供应链中。即本发明能够自动进行供应链的完善,并且在供应链完善时,使用了数据处理模型,数据处理模型使用训练数据训练得到,所述训练数据包括特征信息样本以及所述特征信息样本之间的样本关联关系,则数据处理模型的处理准确度较高,进而使用数据处理模型得到未在册企业与所述在册企业之间的关联关系时,准确度较高,进而能够提高完善后的供应链的准确度。
需要说明的是,本实施例中的各个步骤的具体实现过程,请参照上述实施例中的相应说明,在此不再赘述。
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
- 一种基于机器学习的供应链调整方法、装置及电子设备
- 一种基于机器学习的电子设备屏蔽效能评估方法及装置