一种高可用集群的异步数据流复制方法及系统
文献发布时间:2023-06-19 10:46:31
技术领域
本发明涉及基于对称方式、异步数据流复制集群高可用技术领域,特别涉及一种高可用集群的异步数据流复制方法及系统。
背景技术
单节点postgresql数据库,当数据库或服务器发生故障时,需要停机诊断、修复,使得生产系统的可靠性无法保障。流复制是从pg9版本之后使用,流复制其原理为:备库不断的从主库同步相应的数据,并在备库apply每个WAL record,这里的流复制每次传输单位是WAL日志的record(关于预写式日志WAL,是一种事务日志的实现)。事务commit后,日志在主库写入wal日志,还需要根据配置的日志同步级别,等待从库反馈的接收结果。主库通过日志传输进程将日志块传给从库,从库接收进程收到日志开始回放,最终保证主从数据一致性。
发明内容
本发明的目的在于当某一个节点或服务器发生故障时,另一个节点能够自动且立即向外提供服务,即将有故障节点上的资源转移到另一个节点上去,这样另一个节点有了资源既可以向外提供服务。
根据本发明实施例提供的一种高可用集群的异步数据流复制方法,包括:
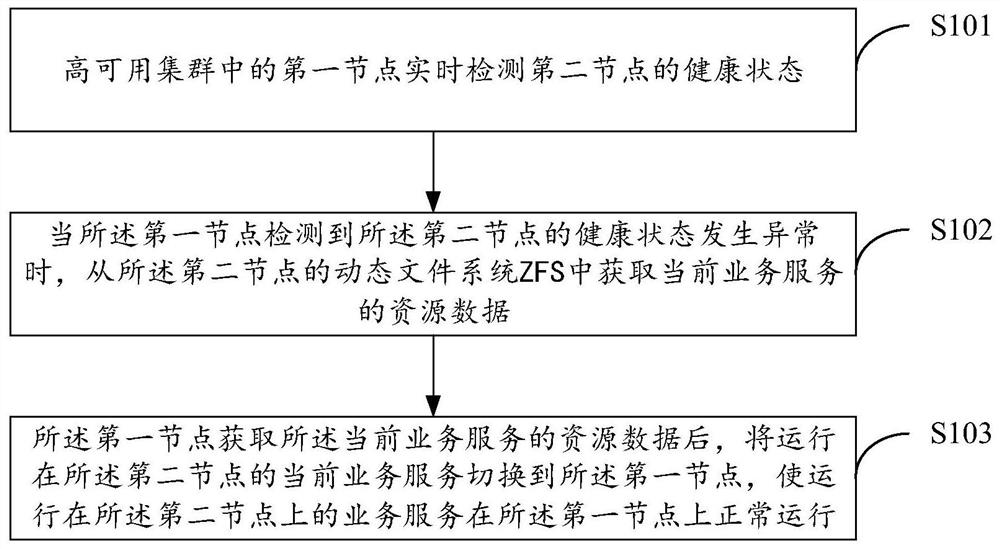
高可用集群中的第一节点实时检测第二节点的健康状态;
当所述第一节点检测到所述第二节点的健康状态发生异常时,从所述第二节点的动态文件系统ZFS中获取当前业务服务的资源数据;
所述第一节点获取所述当前业务服务的资源数据后,将运行在所述第二节点的当前业务服务切换到所述第一节点,使运行在所述第二节点上的业务服务在所述第一节点上正常运行。
优选地,所述第一节点实时检测所述第二节点的健康状态,同时所述第二节点实时监测所述第一节点的健康状态。
优选地,还包括:为所述第一节点配置第一ZFS,为所述第二节点配置第二ZFS。
优选地,所述第一节点实时检测所述第二节点的健康状态,同时运行多个不同的第一业务服务,并将每个第一业务服务的资源数据实时存储到所述第一ZFS。
优选地,所述第二节点实时检测所述第一节点的健康状态,同时运行多个不同的第二业务服务,并将每个第二业务服务的资源数据实时存储到所述第二ZFS。
优选地,当所述第一节点检测到所述第二节点的健康状态发生异常时,从所述第二节点的动态文件系统ZFS中获取当前业务服务的资源数据包括:
当所述第一节点检测到所述第二节点的健康状态发生异常时,向所述第二节点的电源开关发送断电指令,同时从所述第二节点的动态文件系统ZFS中获取当前业务服务的资源数据。
根据本发明实施例提供的一种高可用集群的异步数据流复制系统,包括第一节点和第二节点,其中第一节点包括:
检测模块,用于实时检测高可用集群中的第二节点的健康状态;
获取模块,用于当检测到所述第二节点的健康状态发生异常时,从所述第二节点的动态文件系统ZFS中获取当前业务服务的资源数据;
切换模块,用于获取所述当前业务服务的资源数据后,将运行在所述第二节点的当前业务服务切换到所述第一节点,使运行在所述第二节点上的业务服务在所述第一节点上正常运行。
优选地,所述第一节点实时检测所述第二节点的健康状态,同时所述第二节点实时监测所述第一节点的健康状态。
优选地,还包括:为所述第一节点配置第一ZFS,为所述第二节点配置第二ZFS。
优选地,所述第一节点实时检测所述第二节点的健康状态,同时运行多个不同的第一业务服务,并将每个第一业务服务的资源数据实时存储到所述第一ZFS,以及所述第二节点实时检测所述第一节点的健康状态,同时运行多个不同的第二业务服务,并将每个第二业务服务的资源数据实时存储到所述第二ZFS。
根据本发明实施例提供的方案,对称方式一般包含2个节点和一个或多个服务,其中每一个节点都运行着不同的服务且相互作为备份,两个节点互相检测对方的健康状况,这样当其中一个节点发生故障时,该节点上的服务会自动切换到另一个节点上去,保证了服务正常运行。
附图说明
此处所说明的附图用来提供对本发明的进一步理解,构成本发明的一部分,本发明的示意性实施例及其说明用于理解本发明,并不构成对本发明的不当限定。在附图中:
图1是本发明实施例提供的一种高可用集群的异步数据流复制方法的流程图;
图2是本发明实施例提供的一种高可用集群的异步数据流复制系统的示意图。
具体实施方式
以下结合附图对本发明的优选实施例进行详细说明,应当理解,以下所说明的优选实施例仅用于说明和解释本发明,并不用于限定本发明。
图1是本发明实施例提供的一种高可用集群的异步数据流复制方法的流程图,如图1所示,包括:
步骤S101:高可用集群中的第一节点实时检测第二节点的健康状态;
步骤S102:当所述第一节点检测到所述第二节点的健康状态发生异常时,从所述第二节点的动态文件系统ZFS中获取当前业务服务的资源数据;
步骤S103:所述第一节点获取所述当前业务服务的资源数据后,将运行在所述第二节点的当前业务服务切换到所述第一节点,使运行在所述第二节点上的业务服务在所述第一节点上正常运行。
优选地,所述第一节点实时检测所述第二节点的健康状态,同时所述第二节点实时监测所述第一节点的健康状态。
优选地,还包括:为所述第一节点配置第一ZFS,为所述第二节点配置第二ZFS。
优选地,所述第一节点实时检测所述第二节点的健康状态,同时运行多个不同的第一业务服务,并将每个第一业务服务的资源数据实时存储到所述第一ZFS。
优选地,所述第二节点实时检测所述第一节点的健康状态,同时运行多个不同的第二业务服务,并将每个第二业务服务的资源数据实时存储到所述第二ZFS。
优选地,当所述第一节点检测到所述第二节点的健康状态发生异常时,从所述第二节点的动态文件系统ZFS中获取当前业务服务的资源数据包括:当所述第一节点检测到所述第二节点的健康状态发生异常时,向所述第二节点的电源开关发送断电指令,同时从所述第二节点的动态文件系统ZFS中获取当前业务服务的资源数据。
图2是本发明实施例提供的一种高可用集群的异步数据流复制系统的示意图,如图2所示,包括第一节点201和第二节点202,其中第一节点201包括:检测模块,用于实时检测高可用集群中的第二节点的健康状态;获取模块,用于当检测到所述第二节点的健康状态发生异常时,从所述第二节点的动态文件系统ZFS中获取当前业务服务的资源数据;切换模块,用于获取所述当前业务服务的资源数据后,将运行在所述第二节点的当前业务服务切换到所述第一节点,使运行在所述第二节点上的业务服务在所述第一节点上正常运行。
优选地,所述第一节点201实时检测所述第二节点的健康状态,同时所述第二节点实时监测所述第一节点的健康状态。
优选地,还包括:为所述第一节点配置第一ZFS,为所述第二节点配置第二ZFS。
优选地,所述第一节点实时检测所述第二节点的健康状态,同时运行多个不同的第一业务服务,并将每个第一业务服务的资源数据实时存储到所述第一ZFS,以及所述第二节点实时检测所述第一节点的健康状态,同时运行多个不同的第二业务服务,并将每个第二业务服务的资源数据实时存储到所述第二ZFS。
本发明的目的在于当某一个节点或服务器发生故障时,另一个节点能够自动且立即向外提供服务,即将有故障节点上的资源转移到另一个节点上去,这样另一个节点有了资源既可以向外提供服务。高可用集群是用于单个节点发生故障时,能够自动将资源、服务进行切换,这样可以保证服务一直在线。在这个过程中,对于客户端来说是透明的。
具体包括以下步骤:为搭建对称分布式集群、配置归档存储节点、配置归档目录、配置NFS服务、配置虚拟IP和路由、配置standby备节点。
1、部署对称方式集群
对称方式一般包含2个节点和一个或多个服务,其中每一个节点都运行着不同的服务且相互作为备份,两个节点互相检测对方的健康状况,这样当其中一个节点发生故障时,该节点上的服务会自动切换到另一个节点上去。这样可以保证服务正常运行。
Messaging Layer:为信息层,主要的作用是传递当前节点的心跳信息,并告知给对方,这样对方就知道其他节点是否在线。如果不在线,则可以实现资源转移,这样另一台节点就可以充当主节点,并正常提供服务。传递心跳信息一般使用一根心跳线连接,该线接口可以使用串行接口也可以是以太网接口来连接。每一个节点上都包含信息层。
CRM:Cluster Resource Messager,资源管理器,主要用来提供那些不具有高可用的服务提供高可用性的。它需要借助Messaging Layer来实现工作,工作在MessagingLayer上层。资源管理器的主要工作是根据messaging Layer传递的健康信息来决定服务的启动、停止和资源转移、资源的定义和资源分配。在每一个节点上都包含一个CRM,且每个CRM都维护这一个CIB(Cluster Internet Base,集群信息库),只有在主节点上的CIB是可以修改的,其他节点上的CIB都是从主节点那里复制而来的。在CRM中还包含LRM和DC等组件。
LRM:Local Resource Messager,叫做本地资源管理器,它是CRM的一个子组件,用来获取某个资源的状态,并且管理本地资源的。例如:当检测到对方没有心跳信息时,则会启动本地相应服务。
DC:为事务协调员,这个是当多个节点之间彼此收不到对方的心跳信息时,这样各个节点都会认为对方发生故障了,于是就会产尘分裂状况(分组)。并且都运行着相关服务,因此就会发生资源争夺的状况。因此,事务协调员在这种情况下应运而生。事务协调员会根据每个组的法定票数来决定哪些节点启动服务,哪些节点停止服务。例如高可用集群有3个节点,其中2个节点可以正常传递心跳信息,与另一个节点不能相互传递心跳信息,因此,这样3个节点就被分成了2组,其中每一个组都会推选一个DC,用来收集每个组中集群的事务信息,并形成CIB,且同步到每一个集群节点上。同时DC还会统计每个组的法定票数(quorum),当该组的法定票数大于二分之一时,则表示启动该组节点上的服务;否则停止该节点上的服务。对于某些性能比较强的节点来说,它可以投多张票,因此每个节点的法定票数并不是只有一票,需要根据服务器的性能来确定。DC一般位于主节点上。
STONITH(Shoot The Other Node in the Head,”爆头“),这种方式直接操作电源开关,当一个节点发生故障时,另一个节点如果能侦测到,就会通过网络发出命令,控制故障节点的电源开关,通过暂时断电,而又上电的方式使故障节点被重启动或者直接断电,这种方式需要硬件支持。
如果备份节点在某一时刻不能收到主节点的心跳信息时,那么如果此时备份节点立刻抢占资源时,而此时主节点正好在执行写操作,备份节点一旦也执行相应的写操作,会导致文件系统错乱或者服务器崩溃,因此在抢占资源的时候可以使用资源隔离机制来防止此类事件发生。而我们常常使用stonithd(即爆头)来使主节点不在抢占资源。
2、配置归档存储节点
配置ZFS(Zettabyte File System,动态文件系统),开启压缩,同时注意写性能至少要和网卡带宽相当,否则容易造成瓶颈。一旦造成瓶颈,可能导致主库XLOG堵塞膨胀(因为归档完成的XLOG才可以重用或被删除)。zpool使用raidz1+ilog+spare的模式。
3、配置归档目录
创建归档目录,日志目录,PGHOME目录:
zfs create-o mountpoint=/pg168104zp1/pg168104
zfs create-o mountpoint=/pg_log zp1/pg_log
zfs create-o mountpoint=/pg_home zp1/pg_home
zfs create-o mountpoint=/pg_arch zp1/pg_arch
4、配置NFS(Network File System,网络文件系统)服务
配置PostgreSQL归档,例如rsync服务端,nfs,ftp等,如果使用NFS固定NFS端口。配置nfs目录,每个PG集群一个目录,存放该集群的归档文件。
#mkdir/pg_arch/pg168104
#vi/etc/exports
/pg_arch/pg168104
192.168.168.16/32(rw,no_root_squash,sync)
/pg_arch/pg168104
192.168.168.17/32(rw,no_root_squash,sync)
开启NFS服务,OR service nfs reload.
#service nfs start
#chkconfignfs on
5、配置虚拟IP,路由
主节点pg_hba.conf的配置都指向这个虚拟IP,如发生集群故障,导致节点迁移的情况,虚拟IP迁移走,主节点的pg_hba.conf可以修改。
6、配置standby备节点
配置.pgpass,设置流复制秘钥。配置主节点pg_hba.conf,允许备机的虚拟IP访问。开启standby进行恢复,使用open模式hot_standby=on或recovery模式hot_standby=off,recovery.conf中添加如下内容:
restore_command='cp--preserve=timestamps/pg_arch/pgxxxxxx/arch/*/%f%p'
尽管上文对本发明进行了详细说明,但是本发明不限于此,本技术领域技术人员可以根据本发明的原理进行各种修改。因此,凡按照本发明原理所作的修改,都应当理解为落入本发明的保护范围。
- 一种高可用集群的异步数据流复制方法及系统
- 服务器集群系统及实现服务器集群系统高可用的方法